
- 1arm-none-linux-gnueabi-gcc 版本下载_arm-none-linux-gnueabi-gcc下载
- 2matlab 工具函数 —— normalize(归一化数据)_matlab normalize函数
- 3Taro 在小程序和H5的踩坑记录_taro.getapp
- 4深圳牵头打造鸿蒙原生应用软件生态 | 百能云芯
- 5玩转电脑|带你了解如何快速查看电脑开关机时间_电脑开关机记录查询
- 6程序调用Excel组件时报错-2147024703 Automation error %1 is not a valid Win32 > application或者-2147024894_error -2147024713
- 7rk3568 安卓11双屏异显,隐藏副屏的导航栏
- 8AD常用快捷键记录_ad快捷键
- 9微信小程序分销商城制作源码系统:全部搭建好直接使用 带完整的安装代码包以及搭建教程_小程序商城分销模式源码
- 10Xceed Toolkit Plus for WPF_wpf xceed
主流强化学习算法论文综述:DQN、DDPG、TRPO、A3C、PPO、SAC、TD3_td3比ppo强吗
赞
踩
文章目录
- [DQN] Playing Atari with Deep Reinforcement Learning[1]
- [DDPG] Continuous Control with Deep Reinforcement Learning[2]
- [TRPO] Trust Region Policy Optimization[3]
- [Prioritized Experience replay] Prioritized Experience Replay
- [A2C/A3C]Asynchronous Methods for Deep Reinforcement Learning[4]
- [ACER] Sample efficient actor critic with experience replay
- [PPO]Proximal Policy Optimization Algorithms
- 算法描述
- [SAC] Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor[5]
- [TD3] Addressing Function Approximation Error in Actor-Critic Methods[6]
- 算法描述
强化学习自从15年开始DQN的成功应用得到了雨后春笋般成长,获得学术界极高的关注。在此之间,强化学习主要以model based模型为主,其特点为问题针对性强,需要大量的人为假设,且对于不同问题需要特定的模型套入。而现在开始model free的模型有极大的通用性,一个算法吃遍天下所有任务,因此也提高了之间的可比较性,也促成了学术界的井喷。主流的两个思路为Q-learning和Policy gradient,综述将从最经典的几个算法原论文出发,相互比较并总结心得。
[DQN] Playing Atari with Deep Reinforcement Learning[1]
Off-policy,Discrete action space,model free,2015
主要思路:
如果我们能够穷尽表征state,action和reward的联合分布,那么一切问题迎刃而解。困难出现于state过于复杂和高维,穷举变得不可实现。因此采取一个reward-to-go (Q function或者Value function)的思维来解决状态表征。
结合之前TD-gammon的算法和CNN,并同时利用了on-line训练,即并非等到一个回合完全结束再更新参数,产生了Q-learning。使用一个Replay buffer储存之前的交互样本,随机采样历史数据进行参数更新,达到增强样本效率的结果,并避免近期的采样数据关联性过高的问题。
算法描述:

这个表达式由Bellman表征得来,如果Q网络是完美的话,上式应该为0。即r+γ max(a’ )Q(s’,a’ )=Q(s,a) 。这里的s‘代表下一个时间的状态。问题就出现在θ并不是完美的(甚至可能根本没有解),我们通过online的方法,逐步更新Q函数的参数,以达到网络对整体环境的认知。

算法关键点描述:
- ϵ-greedy,保留ϵ概率选择一个完全随机的action选择,避免agent过度陷入“自我沉醉”
- 因为用1-ϵ概率选择Q-value(神经网络构成的函数拟合)最大值对应的action,因此在选择action的时候需要尝试所有可能的action,带入Q网络,造成算法只能在discrete的action space中使用
- 针对上一个问题,本文的实际操作方法是使用一个multi output的Q网络,输出维度和action维度相同,这样就可以保证一次输入state,直接得到所有action的Q value。避免了对于每个action都forward pass一次。
实验结果
实验于Atari2600平台进行
结论及评价
本文作为深度强化学习的开山鼻祖,引用量非凡,在Atari游戏中表现出不俗的战绩(在测试中有六个超越过去的算法,有三个超过了人类水平)
对于γ这个discount factor的使用,主要有两点:1. 为了让agent相对更贪心一点,对眼前的回报予以更大的权重,稳定policy。2. 对于一个reward是bounded情况,加一个小于一的factor可以保证未来的reward累积和收敛,从而避免Q value的发散。
文中提及使用experience replay,过去的经验依旧可以拿出来更新当前网络,(不至于跑过的地方就只用一次,用完便忘记)从而可以提高样本效率;同时作者提到采取随机采样可以避免过分依赖最近的样本,从而避免state,action的高correlation。而后期实验证明,往往通过一个prioritize replay buffer避免久远的概率分布不能更好的表征当前状态,效果会更好些
实验中,开始真正训练前,采用完全随机的action与环境交互几步有利于稳定Q value的估值。
探索率ϵ一般要随着训练逐步减小
[Double DQN] Deep Reinforcement Learning with Double Q-learning
由于嫌弃DQN对于Q值得高估,因此Double DQN采用了一种异步更新Q网络的做法:即,对于选择动作和对拟合目标使用的Q网络使用的参数并不是同一堆参数,而是不同时刻的参数
以下是2015年版本的DQN(不是DDQN)

而DDQN得唯一改变就是,我们在选取a‘的时候,先选出来,然后再用target network来做evaluation
[DDPG] Continuous Control with Deep Reinforcement Learning[2]
Model free, off policy, continuous action, 2015
主要思路
针对之前的DQN算法,由于需要在运动空间中选取最大的Q值,只能够在离散的运动空间中使用,若强行使用到连续空间,如果自由度过大将无法高效应用。Actor Critic通常能够提高稳定性,因此采取了actor和critic两条路子来更新策略网络。文章基于Deterministic policy gradient (Silver 2014)提出了Deep DPG。
算法描述
算法详解:
Q,Q’和μ,μ’都是异策略更新的重点特征,事实上我们以一种一次变化τ的方式逐步更新μ’ 和 Q’。 μ和Q的更新是直接根据每一步更新的gradient直接作用于之前一步的网络参数上。
真正的Actor Policy在执行的时候是采取当前策略网络给出的预测值μ加上一个随机过程(Ornstein Uhlenbeck process基本可以认为是布朗运动的一种)与环境进行交互,即内循环的第一行:

从而避免exploration不足的问题(DQN采用ϵ- greedy)
实验结果
在Atari2600的比较中,DDPG基本完胜DQN,在样本效率上甚至达到了几乎20倍的效能。
结论及评价
- Off policy的可行性是将policy带入Q值后形成的bellman方程中后,基于MDP假设,发现最佳策略实际上可以与下一步action无关, 从而说明不需要于环境实时交互也可以得到最佳策略。
- Action repeat的使用,即一个动作做N遍,然后把所有过程图片抽出来喂给网络可以简化问题,加速了训练过程。
- 在机器学习中的优化问题,我们应假设batch之间是independent的,但是在RL种,这种independency是很勉强的,采取off policy的方式可以提供一个replay buffer降低batch之间的关联度,实现更好的监督学习(对于值函数的更新)。
- 使用batch normalization可以缓解不同的任务之间观测的scale不同的问题。
- 在之前的学术中证明在强化学习中,non-linear function approximators意味着不再有理论上的convergence保证,
- Target network tracker的思路大大增加了off policy的稳定性,即θ_Q’ =(1-τ) θ_Q’+θ_Q τ ,包括policy network也是采用了类似的更新策略。
- Q网络总是会高估回报值(Double Q给出的结论)
- 文章提到了Levine团队的GPS,简单阐述为1.将高位图片通过CNN压缩到二维(x,y),加上机器人自身关节的低维度的信息,放进FCN,2. 通过一个低维度的直接最优解。其实现原理大致是:1.对于特定轨迹进行局部的线性,全观测模型拟合;2. 使用最优控制器给出最优控制信号;3.使用监督学习训练一个神经网络控制
- 文章提到PILCO,通过高斯过程学习概率分布的模型,原论文值得一看。Model based的强化学习样本效率非常高,大约在真实的环境中,利用数据甚至在几个episode就能实现一个任务的学习,不过对于高纬度数据输入通常会失效。
- 文章非常谦虚地和各种算法进行讨论,承认了model free的不足,从整体的论证是非常严谨的,可以算得上一篇很好的文章
[TRPO] Trust Region Policy Optimization[3]
Model free, on policy, discrete and continuous action, 2015
主要思路
普通的策略梯度方法有两个问题:一是sample efficiency不行,每次更新一点点都要重新sample,与环境交互次数太多,浪费;二是更新的时候π网络的参数每次更新多少,learning rate是多大,会不会一不小心就跑遍了,或者当前的更新方式不够激进,TRPO用一个二阶方法给出了一个更好的步长。
算法描述

算法抄自Spinning Up,需要注意的是gradient的算法有误导,按照上面的写法,这是一个完全的on-policy算法,实际操作中采用importance sampling形成了一种局部off policy的状态,这里对importance sampling进行讲解
究竟为什么要使用importance sampling呢?
- 1
一般来讲,IS出现于统计里面,对于难以直接sample但是知道分布函数的一种分布,可以采用另一种分布来采样,这样获得的expectation是没有bias的。另一个作用是给不同的区域给不同的sample权重,比如我更想知道某个局部的准确分布,就可以用IS。
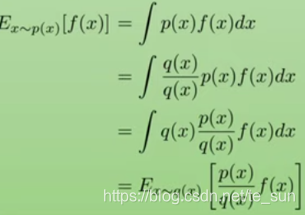
RL中的IS作用是什么?
Importance sampling最直接的作用是化on policy为局部off policy,提升sample efficiency。假设我们有两个时间点t_1和t_2。

总结一句话,就是虽然我已知他的PDF,但是sample太贵了,相比而言computation更便宜,我就倾向于用已知的sample数据来计算当前的expectation,而且还是unbiased。
TRPO的实际操作是在做一个constrain的optimization,对于目标函数,采用一阶线性展开,对于constraint的优化,作者使用一个二阶进行展开,最终把更新量“沿着”gradient的方向缩短回constraint的满足的更新步长。
理论支撑主要由现有不等式

随后,作者对于α进行调整,通过证明(文章的附录)换为一个与两个policy有关的一个divergence量(variation divergence),再通过Pinsker’s不等式,把variation divergence放缩为KL divergence,从而把这个不等式的超参数给搞掉。
这个过程中,作者又发现理论给出的前面的这个常系数通常给出的更新步长太小了,更新策略不够激进,且两个项(L和后面的一坨)数值大小往往不一,造成优化的困难。作者干脆将后面的减数做了constraint,最终将问题转换为一个约束性优化问题。
对于约束求解,作者使用Fisher information matrix,事实上就是一个Hessian矩阵的线性方程组求解,但是作者用了一些奇怪的手法来优化计算,从实际的implementation来看,并没有最终使用。
算法还给出了single path和vine的两个思路,single path就是按照一条路走到黑,而vine是指在给定的s_t多次sample action,从而生成一个Monte Carlo树,实验中看到,vine的策略稍微好些,但是可能得不偿失(计算量大,难以并行),在实际代码层面,baselines并没有用vine的方式。
数据及性能分析
Mujoco,Gym Atari,文章没有给出很多与其他RL算法的比较。
结论及评价
TRPO帮助policy gradient扳回一程,样本效率相比于A3C还是有不小的提升,唯一令人头疼的是过于繁琐的数学过程和巨大的运算量,虽然作者说计算二阶可以与一阶类似的计算量,这也是基于忽略了很多矩阵乘法的计算量、第一次计算均值处的二阶矩阵的计算量,实际的代码层面更是根本没用他的策略,导致实际clock time运行速度略微慢了点,他的多线程版本也是近期出现。
- 最近高评分论文Implementation Matters in Deep RL: A Case Study on PPO and TRPO对PPO的clip技巧进行批评,事实上TRPO的sample efficiency不见得比PPO差,而是PPO在代码层面有了更多的优化。该文的作者也呼吁RL的研究员们不要随便改改就说我的好,而是要把Deep RL的每一个部分都boost到极致,达到更客观的算法性能评价
- 给出了很多heavy的数学想法,建议有机会阅读一下MM的优化算法。
- 文章中最后提到,对于model based的算法,采用trust region思想可能也可以获得更好的性能
[Prioritized Experience replay] Prioritized Experience Replay
主要思路:
在Q网络中,TD误差就是目标Q网络计算的目标Q值和当前Q网络计算的Q值之间的差距,对于TD误差比较大的样本我们需要更多的去pay attention,多采样这样的样本,因此Q网络更新会更加快
[A2C/A3C]Asynchronous Methods for Deep Reinforcement Learning[4]
A2C, A3C, on policy, Discrete and continuous action space, 2016
主要思路
Off policy的主要问题是需要大量的内存,并且和环境交互一次需要计算很多的时间,稳定性也并不是很好,这里提出了异步更新的方式,一个critic多个actor和复制的环境进行交互,在clock time上大大加速了训练过程。
算法描述
文章提供的A3C被最多传唱,主要算法如下

算法中有两个网络π和V,在文章训练过程中并没有让这两个网络共享结构参数
Advantage体现在对于π网络的更新上,目标是扩大R-V而不是单独的R
对于每一个thread,我们采取了一个multi-step的异步更新
multi-steps体现在倒数第七行开始的循环里,事实上用了一个“半”off line的办法,对于贝尔曼形式的局部应用:
R
(
t
−
2
)
t
a
r
g
e
t
=
r
(
t
−
2
)
+
γ
R
(
s
(
t
−
1
)
,
θ
)
R_(t-2)^target=r_(t-2)+γR(s_(t-1),θ)
R(t−2)target=r(t−2)+γR(s(t−1),θ)
随后用R_(t-2)^target和R(s_(t-2),θ)得到一个关于θ的梯度,累加存起来,作为mini batch的gradient
异步体现在不同线程下θ在每次分布运算开始前大家共享,而对于参数的更新也是等所有人都算完以后用每个线程累积起来的gradient更新
这个算法是唯一可以共同运用到discrete和continuous的算法,因为他是value based和policy输出action。离散的action,π只需要输出一堆softmax,而连续的action就输出一个μ和σ^2(注意,方差需要用一个softPlus的activation来保证它是正的,在normal distribution的预测中常用)。
文章还提出了asynchronous one-step Sarsa, Asynchronous n-step Q learning 和Asynchronous one-step Q learning。
实验结果
使用了Atari, Labyrinth, Torch环境,以及MuJoCo环境。训练从结果上来讲,大大提升了训练速度,即clock time,但是从data efficiency上并没有给出很大的讨论。
从上表格可以看到不同数量的线程,到达相同水平的reward所需要的时间统计,看到除了A3C,训练效率得到超出线性的增长,可能Q value的估计会因为multi threads减小bias。正常情况下,我们大致可以期待比线性增长略差的threads-samples number的关系函数。
结论及评价
文章整体提供了四种框架,基本上都是给分布式运算提供了框架参考。对于强化学习算法本身并没有太多的深究,框架带来的提速给训练大大加速,尤其是A3C的框架基本上被所有的on policy算法所继承
论文提到添加policy entropy会提升算法效率,尤其是对于hierarchical的任务,对于离散的情况使用cross entropy,对于连续的情况使用normal distribution的entropy计算。
对于参数的更新,不再使用θ_Q’ =(1-τ) θ_Q’+θ_Q τ的策略,而是采用了异步更新,不知道如果再把异步更新的更新量用这种思路更新参数会不会得到更好的效果,不过确实会浪费更多的步数。(TD3文章中说这种思路并没有很好的效果,这是由于这个慢速改变的θ’在actor critic设定中与θ太相似了,看不出明显提升)
Asynchronous one-step Q learning貌似并没有最终得到广泛的应用,它企图用multi thread的方法来减缓policy, state之间的correlation。
文章对于Q learning不stable的原因给出了一个有趣的批评:因为每次更新Q值只会更新当前从experience replay 中sample出来的{s_i}的Q值,那些没有被sample出来的state,agent还会以为Q值是以前的,因此会产生不stable。
[ACER] Sample efficient actor critic with experience replay
ACER, Off policy, Both discrete continuous action space, 2016
主要思路:
对于actor critic的on policy方法,样本效率并不让人满意,而针对off policy的high variance和instability,文章采用重要性采样的方式。ACER基于A3C的架构对算法进行提升。
主要技巧是1. Truncated importance sampling with bias correction, 2. Efficient trust region optimization, 3.stochastic dueling networks(其实就是在计算Q值的时候使用value function和advantage两个来算,但是advantage采取了采样的策略来稳定Q值估计。)
使用了TRPO的思路,不过转换为off policy,并且对于KL divergence使用了penalty。
[PPO]Proximal Policy Optimization Algorithms
PPO, on policy, actor critic, Both discrete continuous action space, 2017
主要思路:
作为TRPO的作者,自己都看不下去复杂的implementation,作对对标的主要论文,PPO把TRPO里面的policy KL constraint换成了一个在更新的policy直接的clip处理,来减少gradient更新的时,对于能够提升advantage方向太激进的更新step。
算法描述

文章给出了两个优化的方法,一个是直接对于importance sampling的policy ratio做一个clip处理;另一个是对policy的KL做一个adaptive系数的penalty。作者说直接的clip来的更快且实际效果更好。另外在实际的应用中,PPO还添加了value function的loss,添加了policy entropy的鼓励。
Clip version,使得对于能够提升advantage的policy格外注意,对于这些policy,我们给他提供的奖励信息是有限的:如果advantage是负的,那么能够减小这个action概率的policy更新,我们并不给予实际的policy ratio,也就是再激进的更新策略,对于扩大目标值作用也被bounded了;相反,如果某个action的advantage是大于零,那么我们也限制住大幅增加选择这个action概率的policy所能带来的影响。简而言之,我们让policy的更新变得更悲观、谨慎。
Adaptive KL penalty把policy KL divergence直接减在了objective function上,当当前policy于之前的KL太大,我们就增加KL penalty前面的系数,从而起到限制policy做大变化更新。
代码实现层面,作者又在objective上面添加了value function network的误差和policy entropy
数据集及性能
超过了之前所有的on policy算法,而且clock time的表现很棒,对于actor critic的架构来说,没有什么复杂的计算,只有一个clip。
评论
这篇文章有点耍流氓,你不能因为TRPO是自己写的,就不解释背景了,就好像默认所有作者都看过TRPO和A3C,有点突兀。
再次强调ICRL 2020论文批评了PPO说优化来自于clip,而实际上代码优化可能才是重点。
从这篇来看,强化学习很大的一个问题是exploration不够,exploitation太狠,对于前面的问题,我们通常添加一个cross entropy,对于后面的我们就一般采取trust region或者clip的类似策略。
ACER说,truncated importance sampling会带来bias, 确实是,但是PPO正好是利用了这种bias来鼓励policy更谨慎。
[SAC] Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor[5]
SAC, Off-policy, continuous action space, 2018,论文源码:https://github.com/haarnoja/sac
主要思路:
出发思路基于DDPG,利用了off policy的样本效率比较高和maximum entropy增加探索,把actor critic放入算法中,结合了on policy的stable性质。将policy entropy放入reward中,共同maximize,鼓励agent在reward大区域内增加探索。
算法描述:
将最大化的目标加入policy entropy,鼓励agent探索。
算法框架:
 其中:D是replay buffer,action的提取是根据π给出的值由一个sample parameter ϵ进行sample出来
其中:D是replay buffer,action的提取是根据π给出的值由一个sample parameter ϵ进行sample出来
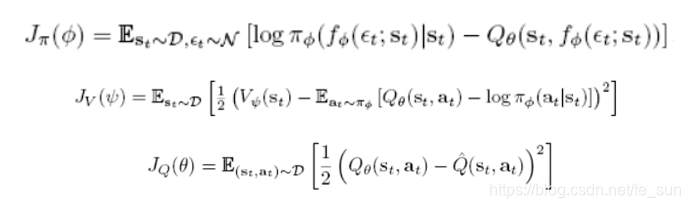
π网络事实上做做一个KL拟合Q值分布,即,让Q值大的地方概率大。
内部网络包含:π_ϕ ,V_ψ,Q_θ。其中:1. 对于Q值估计我们使用两个独立的但是共同更新的网路,做evaluation的时候我们是用数值给出更小的Q输出。2. 对于action输出,我们使用一个gaussian distribution ℵ(π[1],π[2])来sample(π的输出是mean和variance)。这里的V函数拟合的目标为一个soft value,即包含了policy entropy的价值函数,鼓励agent进行探索。
τ是一个target smoothing coefficient,用来跟踪历史的value function,不让他一次性变化太大,类似于gradient descent里面的momentum。
a_t=f_ϕ (ϵ_t;s_t),ϵ是一个学习的参数用于从策略π中sample样本的一个参数
实验结果
实验采用Atari和Mujoco进行比对,比DDPG赢了一大截,和TD3优势相当,比PPO通常要更快。
结论及评价:
论文中解释引用另一个value function的原因:直接使用Q网络和action事实上可以得到一个unbiased estimator,不过引入价值函数在实际操作中可以让训练过程更加稳定,并且加速训练速度(算短clock time)
在做训练的时候采用stochastic来采样action而在evaluation的时候直接采用正态分布的均值而不用再采样,这样再evaluation的时候reward效果会更好。
需要调的参数:reward在这个算法中极其重要,它扮演了权衡exploitation和exploration的关键,如果reward的量级太小,那么agent就只会去做exploration,如果reward太大,那么就恢复到以前DDPG的类型,没有policy entropy的影响了
实验中还采取了“与环境交互一步,更新网络数步”的策略,这样可以获得更精准的value function和Q function但是会增加运算量
[TD3] Addressing Function Approximation Error in Actor-Critic Methods[6]
TD3, off policy, only continuous action space, 2018
主要思路
虽然actor critic的方法可以一定程度的依靠policy-value function的interplay来修正overestimation,但是随着步数的增加,这种error可能导致accumulation。文章主要针对value function的overestimation进行了修正,再DDPG的网络结构基础上,添加了clipped double q learning 的思路来修正过高的估值。
算法描述
采用了double deep q learning的思路,用两个独立的Q网络来更新,一起来拟合一个目标:

Clipped是指对于action的加噪上进行clip,让加噪后的action不要太远离policy给出的结果,使用这个加噪后的action带入慢更新的两个Q值网络,再选择那个Q值更小的作为拟合目标。
与原始的double Q Learning相比,clipped double Q的拟合目标只有一个,降低了计算量
Min(Q1,Q2)的引入,可以降低variance,因为高variance会导致这个min值更小(在同expectation的时候),从而让policy更加exploration来对环境学习,逐步再提高Q值,因此policy和value function的相互作用促使variance更小
有一篇文章Nachum提出的加噪音是加在从replay buffer中sample出来的action而不是加再target Q value中使用的action,产生效果类似
批评:作者加的噪音是一个超参数,即ϵ~N(0,0.2),为什么不能让policy network直接输出一个variance作为加噪音的使用
- 去掉了DDPG里面花里胡哨的Ornstein-Uhlenbeck(对于actor的action加的噪音)过程,验证其实简单的normal distribution就足够了。
数据及实验结果 - 与OpenAI baseline进行打架,效果超越之前的算法,对DDPG进行了结构优化和再调参。
结论及评价 - Double DQN确实是一个很好的方式,能够提升对Q值得估值精准度,减少overestimation,从而降低variance,提高Q-learning的稳定性
- 文章中用实验,验证了θ_Q’ =(1-τ) θ_Q’+θ_Q τ的实用性,可以大大提高稳定性,但也会减慢学习过程。
- 其实线性减小的learning rate(在openai baselines里面是这样的implementation)并不能够保证Q值网络的收敛,因为不能满足 ,但是我们依旧在这么用
- 文章给出了clipped double Q收敛性证明
- 效果图 [详细] -->
赞
踩

