
热门标签
热门文章
- 1网络安全简答题
- 2社交媒体数据治理:Facebook的隐私与透明度
- 3脉冲神经网络-基于IAF神经元的手写数字识别_脉冲神经网络 可视化
- 4用 Python 轻松实现机器学习_python做machine learning
- 5怎样用Excel搜索表格内的内容?_excel表格怎么查找内容
- 6机器学习-周志华-课后习题答案-决策树_试选择 4 个 uci 数据集,对上述 3 种算法所产生的未剪枝、预剪枝、后剪枝决策树进
- 7kibana 查询ES 的一些语法_kibana查询es基本语法
- 8解密目前主流的机器人导航方法
- 9LSTM神经网络详解
- 10复试专业前沿问题问答合集7-2——神经网络与强化学习_复试问及卷积神经网络
当前位置: article > 正文
keras—VGG19(一)
作者:花生_TL007 | 2024-03-30 13:26:12
赞
踩
vgg19
数据和模型 https://blog.csdn.net/u010986753/article/details/98526886
一、 VGG介绍
1.1 VGG19 结构图
''' 每一个块内包含若干卷积层和一个池化层。并且同一块内,卷积层的通道(channel)数是相同的, block1中包含2个卷积层,每个卷积层用conv3-64表示,即卷积核为:3×3,通道数都是64,卷积核有64个, 共有[输入通道3×卷积核(3 × 3)]× 卷积和通道64 = 1728个参数。 共有[输入通道64×卷积核(3 × 3)]× 卷积和通道64 = 36864个参数。 输入224×224×3,2卷积后224×224×64,池化输出:112×112×64 block2中包含2个卷积层,每个卷积层用conv3-128表示,即卷积核为:3×3,通道数都是128, 共有[输入通道64×卷积核(3 × 3)]× 卷积和通道128 = 73728个参数。 共有[输入通道128×卷积核(3 × 3)]× 卷积和通道128 = 147456个参数。 输入112×112×64,2卷积后112×112×128,池化输出:56×56×128 block3中包含4个卷积层,每个卷积层用conv3-256表示,即卷积核为:3×3,通道数都是256, 共有[输入通道128×卷积核(3 × 3)]× 卷积和通道256 = 294912个参数。 共有[输入通道256×卷积核(3 × 3)]× 卷积和通道256 = 589824个参数。 共有[输入通道256×卷积核(3 × 3)]× 卷积和通道256 = 589824个参数。 共有[输入通道256×卷积核(3 × 3)]× 卷积和通道256 = 589824个参数。 输入56×56×128,3卷积后56×56×256,池化输出:28×28×256 Block4中包含4个卷积层,每个卷积层用conv3-512表示,即卷积核为:3×3,通道数都是512, 共有[输入通道256×卷积核(3 × 3)]× 卷积和通道512 = 1179648个参数。 共有[输入通道512×卷积核(3 × 3)]× 卷积和通道512 = 2359296个参数。 共有[输入通道512×卷积核(3 × 3)]× 卷积和通道512 = 2359296个参数。 共有[输入通道512×卷积核(3 × 3)]× 卷积和通道512 = 2359296个参数。 输入28×28×256,3卷积后28×28×512,池化输出:14×14×512 block5中包含4个卷积层,每个卷积层用conv3-512表示,即卷积核为:3×3,通道数都是512, 共有[输入通道512×卷积核(3 × 3)]× 卷积和通道512 = 2359296个参数。 共有[输入通道512×卷积核(3 × 3)]× 卷积和通道512 = 2359296个参数。 共有[输入通道512×卷积核(3 × 3)]× 卷积和通道512 = 2359296个参数。 共有[输入通道512×卷积核(3 × 3)]× 卷积和通道512 = 2359296个参数。 输入14×14×512,3卷积后14×14×512,池化输出:7×7×512 ''' '''权重参数:所包含的权重数目很大,达到了惊人的138 357 544 个参数 全连接层的权重参数数目的方法为:前一层节点数×本层的节点数。 FC(1×1×4096)参数:7×7×512×4096=102760448,memory4096 FC(1×1×4096)参数:4096×4096=16777216,memory4096 FC(1×1×1000)参数:4096×1000=4096000,memory1000 '''

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
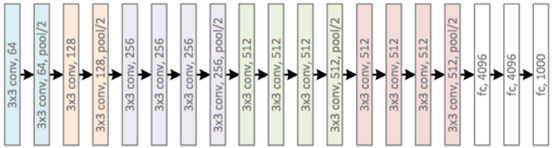
1.2 VGG16 和 VGG19 对比

二、 VGG-19 参数文件解析
2.1 分析模型文件
总共有很多参数,我们只关心我们需要关注的,W和B在哪里就行了,注意这里还有一个mean(平均值),因为VGG使用了图像预处理方式是 input - mean,当然这种处理方式在现在看来不怎么好,但是现在我们用人家的模型,需要遵照人家的意思.
- 从下面的图看到存储的43个参数
- 注意里面的Relu是没有数据的,因为Relu就是一个函数
- 注意Pool的参数是固定的,因为大小为:[1,2,2,1],步长[1,2,2,1],这里可以自己写,也可以读取参数
- Weight Bias是存放在Relu Pool 中间的,而且两个值存在一起的.
- mean值查看 vgg[“normalization”][0][0][0][0][0]
- layers查看 data[‘layers’][0][i][0][0][0][0])
2.2 imagenet-vgg-verydeep-19
imagenet-vgg-verydeep-19.mat 文件有500多兆。注意19只包含了卷积层,没有算池化、Relu和最后的FC-1000,而在下载的模型参数中这些层都有包含。

from scipy.io import loadmat import os import numpy as np import scipy.misc vgg = loadmat('CNN/keras/VGG19_h5/imagenet-vgg-verydeep-19.mat') print('type(vgg)',type(vgg)) #先显示一下数据类型,发现是dict,type(vgg) <class 'dict'> print('vgg.keys()',vgg.keys()) # vgg.keys() dict_keys(['__header__', '__version__', '__globals__', 'layers', 'classes', 'normalization']) # 进入layers字段,我们要的权重和偏置参数应该就在这个字段下 layers = vgg['layers'] # 打印下layers发现输出一大堆括号,好复杂的样子:[[ array([[ (array([[ array([[[[ ,顶级array有两个[[ # 所以顶层是两维,每一个维数的元素是array,array内部还有维数 print(layers,type(layers)) #输出一下大小,发现是(1, 43),存储的43个参数,说明虽然有两维,但是第一维是”虚的”,也就是只有一个元素 #根据模型可以知道,这43个元素其实就是对应模型的43层信息(conv1_1,relu,conv1_2…),Vgg-19没有包含Relu和Pool,那么看一层就足以, #而且我们现在得到了一个有用的index,那就是layer,layers[layer] print("layers.shape:",layers.shape)#layers.shape: (1, 43) layer = layers[0] print('layer',layer) print("layer.shape:",layer.shape,type(layer))#layer.shape: (43,) #输出的尾部有dtype=[('weights', 'O'), ('pad', 'O'), ('type', 'O'), ('name', 'O'), ('stride', 'O')]) #可以看出顶层的array有5个元素,分别是weight(含有bias), pad(填充元素,无用), type, name, stride信息, #然后继续看一下shape信息 print("layer[0][0].shape:",layer[0][0].shape)#layer[0][0].shape: (1,)说明只有一个元素 print("layer[0][0][0].shape:",layer[0][0][0].shape) #layer[0][0][0].shape: () print("len(layer[0][0][0]):",len(layer[0
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/花生_TL007/article/detail/340839
推荐阅读
相关标签

