
nlp 预训练模型
内置AI NLP365(INSIDE AI NLP365)
Project #NLP365 (+1) is where I document my NLP learning journey every single day in 2020. Feel free to check out what I have been learning over the last 257 days here. At the end of this article, you can find previous papers summary grouped by NLP areas :)
项目#NLP365(+1)是我记录我的NLP的学习之旅的每一天在2020年随时检查出什么,我一直在学习,在过去257天这里。 在本文的结尾,您可以找到按NLP领域分组的以前的论文摘要:)
Today’s NLP paper is SCIBERT: A Pretrained Language Model for Scientific Text. Below are the key takeaways of the research paper.
今天的NLP论文是SCIBERT:科学文本的预训练语言模型。 以下是研究论文的主要内容。
目标与贡献 (Objective and Contribution)
Released SCIBERT, a pretrained language model trained on multiple scientific corpuses to perform different downstream scientific NLP tasks. These tasks include sequence tagging, sentence classification, dependency parsing, and many more. SCIBERT has achieved new SOTA results on few of these downstream tasks. We also performed extensive experimentation on the performance of fine-tuning vs task-specific architectures, the effect of frozen embeddings, and the effect of in-domain vocabulary.
发布了SCIBERT,这是一种在多种科学语料库上进行过训练的预训练语言模型,可以执行不同的下游科学NLP任务。 这些任务包括序列标记,句子分类,依存关系解析等等。 SCIBERT在其中一些下游任务上取得了新的SOTA结果。 我们还针对微调与任务特定的体系结构的性能,冻结嵌入的效果以及域内词汇的效果进行了广泛的实验。
方法 (Methodology)
SCIBERT与BERT有何不同?(How is SCIBERT different from BERT?)
- Scientific vocabulary (SCIVOCAB) 科学词汇(SCIVOCAB)
- Train on scientific corpuses 训练科学语料库
SCIBERT is based on the BERT architecture. Everything is the same as BERT except it is pretrained on scientific corpuses. BERT uses WordPiece to tokenise input text and build the vocabulary (BASEVOCAB) for the model. The vocabulary contains the most frequent words / subword units. We use the SentencePiece library to construct a new WordPiece vocabulary (SCIVOCAB) on scientific corpuses. There’s a 42% overlap between BASEVOCAB and SCIVOCAB, showcasing the need for a new vocabulary for dealing with scientific text.
SCIBERT基于BERT架构。 一切都与BERT相同,除了它是经过科学语料库训练的。 BERT使用WordPiece标记输入文本并为模型构建词汇表(BASEVOCAB)。 词汇表包含最频繁的单词/子单词单位。 我们使用SentencePiece库构建关于科学语料库的新WordPiece词汇表(SCIVOCAB)。 BASEVOCAB和SCIVOCAB之间有42%的重叠,这表明需要一种新的词汇来处理科学文本。
SCIBERT is trained on 1.14M papers from Semantic Scholar. Full text of the papers are used, including the abstracts. The papers have the average length of 154 sentences and sentences are split using ScispaCy.
SCIBERT接受了来自语义学者的114万篇论文的培训。 使用了论文的全文,包括摘要。 这些论文的平均长度为154个句子,并且使用ScispaCy对句子进行拆分。
实验装置 (Experimental Setup)
下游NLP任务是什么?(What are the downstream NLP tasks?)
- Named Entity Recognition (NER) 命名实体识别(NER)
- PICO Extraction (PICO) PICO提取(PICO)
- Text Classification (CLS) 文字分类(CLS)
- Relation Extraction (REL) 关系提取(REL)
- Dependency Parsing (DEP) 依赖解析(DEP)
PICO extraction is a sequence labelling task that extracts spans within the text that describes Participants, Interventions, Comparisons, and Outcomes in a clinical trial paper.
PICO提取是一种序列标记任务,可提取描述临床试验论文中参与者,干预措施,比较和结果的文本中的跨度。
型号比较 (Models comparison)
- Two BERT-Base models. The normal BERT with BASEVOCAB cased and uncased versions 两种基于BERT的模型。 普通的BERT,带BASEVOCAB装箱和无箱装版本
- Four SCIBERT models. Cased and uncased and with BASEVOCAB and SCIVOCAB versions 四种SCIBERT模型。 装箱和不装箱以及BASEVOCAB和SCIVOCAB版本
Cased models are used for NER and uncased models are used for all the other tasks.
案例模型用于NER,非案例模型用于所有其他任务。
微调BERT (Finetuning BERT)
We follow the same methods in finetuning BERT for various downstream tasks. For CLS and REL, we feed the final BERT vector for the [CLS] token into a linear layer. For sequence labelling (NER and PICO), we feed the final BERT vector of each token into a linear layer. For dependency parsing, we use a model with dependency tag and arc embeddings and biaffine matrix attention over BERT vectors.
在为各种下游任务微调BERT时,我们采用相同的方法。 对于CLS和REL,我们将[CLS]令牌的最终BERT向量馈入线性层。 对于序列标记(NER和PICO),我们将每个标记的最终BERT向量馈入线性层。 对于依赖项解析,我们使用具有依赖项标签和弧嵌入以及BERT向量上的仿射矩阵注意的模型。
冻结的BERT嵌入 (Frozen BERT embeddings)
We explore using BERT as a pretrained contextualised word embeddings on top of simple task-specific models to see how it performs on these NLP tasks. For text classification, it is a 2-layer BiLSTM with a multi-layer perceptron. For sequence labelling, it is a 2-layer BiLSTM and a conditional random field (CRF). For dependency parsing, it is the same model as above with a 2-layer BiLSTM.
我们探索在简单的特定于任务的模型之上使用BERT作为预训练的上下文化单词嵌入,以查看其如何在这些NLP任务上执行。 对于文本分类,它是带有多层感知器的2层BiLSTM。 对于序列标记,它是一个2层BiLSTM和一个条件随机字段(CRF)。 对于依赖项解析,它与上面使用2层BiLSTM的模型相同。
结果 (Results)
The results are split into three sections: biomedical domain, computer science domain, and multiple domains. The high-level results showcase SCIBERT outperforming BERT-Base on scientific text and achieve new SOTA on many of the downstream tasks.
结果分为三个部分:生物医学领域,计算机科学领域和多个领域。 高层结果显示,SCIBERT在科学文本方面的表现优于BERT-Base,并在许多下游任务上实现了新的SOTA。
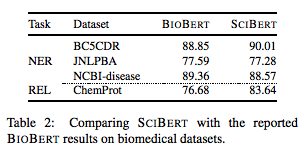
For biomedical domain, SCIBERT outperformed BERT on all seven biomedical datasets, achieved SOTA results on four datasets and underperformed SOTA on the other three datasets. In the figure below, we did a direct comparison between SCIBERT and BIOBERT (a larger model) and found that SCIBERT outperformed BIOBERT on two datasets and performed competitively on the other two datasets as shown below:
在生物医学领域,SCIBERT在所有七个生物医学数据集上均胜过BERT,在四个数据集上均获得了SOTA结果,而在其他三个数据集上均不及SOTA。 在下图中,我们对SCIBERT和BIOBERT(一个较大的模型)进行了直接比较,发现SCIBERT在两个数据集上的性能均优于BIOBERT,在其他两个数据集上的表现也很出色,如下所示:
For computer science and multiple domains, SCIBERT outperformed BERT and achieved SOTA results on all five datasets. All the results discussed above are shown below:
对于计算机科学和多个领域,SCIBERT的表现优于BERT,并且在所有五个数据集上均获得了SOTA结果。 上面讨论的所有结果如下所示:
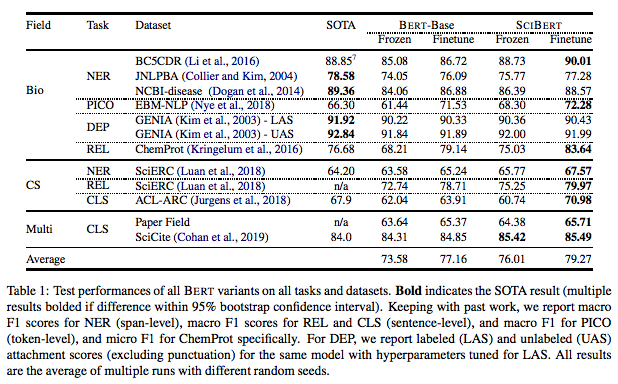
The results also showcase the strong effect of finetuning BERT rather than task-specific architectures on top of frozen embeddings. Fine-tuned BERT consistently outperformed frozen embedded models and outperformed most of SCIBERT with frozen embeddings except two datasets. We also assess the importance of an in-domain vocabulary and observed an 0.60 increase in F1 when using SCIVOCAB. The magnitude of improvement showcase that although in-domain vocabulary is useful, it is not the key driver. The key driver is the pretraining process on scientific text.
结果还展示了在冻结嵌入之上微调BERT而不是特定于任务的体系结构的强大效果。 精细调整的BERT始终优于冻结的嵌入式模型,并且除两个数据集外,在冻结嵌入方面,SCIBERT的性能均优于大多数SCIBERT。 我们还评估了域内词汇的重要性,并观察到使用SCIVOCAB时F1的增加0.60。 改进的幅度表明,尽管域内词汇很有用,但它不是关键驱动因素。 关键驱动因素是科学文本的预培训过程。
结论与未来工作 (Conclusion and Future Work)
On top of achieveing SOTA results on few downstream tasks, SCIBERT also scored competitively against BIOBERT on biomedical tasks. In future work, we would release a larger version of SCIBERT (matching BERT-Large) and experiment with papers from different domains with the goal of training a single summarisation model that works across multiple domains.
除了在少数下游任务上获得SOTA结果之外,SCIBERT在生物医学任务上也与BIOBERT竞争得分。 在以后的工作中,我们将发布更大版本的SCIBERT(与BERT-Large匹配),并尝试使用来自不同领域的论文,以训练可在多个领域使用的单一汇总模型为目标。
资源: (Source:)
[1] Beltagy, I., Lo, K. and Cohan, A., 2019. SciBERT: A pretrained language model for scientific text. arXiv preprint arXiv:1903.10676.
[1] Beltagy,I.,Lo,K.和Cohan,A.,2019年。SciBERT:科学文本的预训练语言模型。 arXiv预印本arXiv:1903.10676 。
Originally published at https://ryanong.co.uk on April 24, 2020.
最初于2020年4月24日在https://ryanong.co.uk上发布。
nlp 预训练模型

