
- 1ChatGPT 用不了?一文分享国内好用大语言模型合集_国内可以用的语言大模式
- 2springboot大学新生小助手小程序毕业设计-附源码060917_软件工程毕业设计选题基于springboot的迎新小程序
- 3大模型 AI Agent 详细介绍_大模型 agent是什么技术
- 4YOLOV5+deepsort+rknn(rk3588进行实时目标跟踪)_yolov5_deepsort_rknn源码解读
- 5两台windows电脑互相备份_goodsnyc 类似软件
- 6nxp的wifi热点不能够打开和关闭的bug_failed to remove networks on exiting connect mode
- 7备战24年春招,腾讯T4为你梳理2023年面试出现频率最高Java面试题及答案_java春招面试题
- 8分支界限法 任务分配问题_任务分配问题用分支限界法画解空间树。
- 9基于yolov5-v7.0开发构建裸土实例分割检测识别模型_yolov7能不能做图像分割
- 10git 使用详解(8)—— 分支HEAD、branch/checkout
强化学习大规模应用还远吗?Youtube推荐已强势上线
赞
踩

来源 | 转载自深度传送门
导读:本文将介绍在深度学习的强力驱动下,给推荐系统工业界所带来的最前沿的变化。本文主要根据几大顶会2019的最新论文,总结一下深度强化学习给推荐系统以及CTR预估工业界带来的最新进展。
凡是Google出品,必属精品。遥想当年(其实也就近在2016),YoutubeDNN[1]以及WDL[2]的横空出世引领了推荐系统以及CTR预估工业界潮流至今,掀起了召回层与排序层算法大规模优雅而高效地升级深度学习模型的浪潮。发展至今其实已经形成了工业界推荐系统与广告CTR预估的庞大家族群,具体可以参见下文中的家族图谱。
https://zhuanlan.zhihu.com/p/69050253
当然,本文的重点不是回首往事。好汉不提当年勇,而是立足当下看看接下来推荐系统和CTR预估工业界的路在何方。起因就在于Google先后在WSDM 2019和IJCAI 2019发表了极具工业界风格应用强化学习的论文,而且声称已经在Youtube推荐排序层的线上实验中相对线上已有的深度学习模型获得了显著的收益。因此,本文就总结一下几大顶会2019上强化学习应用于推荐系统和CTR预估工业界的最新进展,也欢迎各位有经验的同行多多交流共同进步。
众所周知,强化学习虽然在围棋、游戏等领域大放异彩,但是在推荐系统以及CTR预估上的应用一直有很多难点尚未解决。一方面是因为强化学习与推荐系统结合的探索刚刚开始,目前的方案尚未像传统机器学习升级深度学习那样效果显著,升级强化学习在效果上相对已有的深度学习模型暂时还无法做到有质的飞跃;另外一方面,就是离线模型训练与线上实验在线学习环境搭建较为复杂。这就造成了目前在工业界应用强化学习模型性价比并不高。而且尴尬的是,很多论文在升级RL比较效果的时候使用的Baseline都是传统机器学习算法而不是最新的深度学习模型,其实从某种程度上来说是很难让人信服的。
所以,Google这两篇强化学习应用于YouTube推荐论文的出现给大家带来了比较振奋人心的希望。首先,论文中宣称效果对比使用的Baseline就是YouTube推荐线上最新的深度学习模型;其次,两篇论文从不同的指标维度都带来了比较明显的效果增长。而且其中一篇论文的作者Minmin Chen大神在Industry Day上也提到线上实验效果显示这个是YouTube单个项目近两年来最大的reward增长。这虽然不代表着强化学习与推荐系统的结合方案已经很成熟了,至少给大家带来了一些在工业界积极尝试的动力。
Top-K Off-Policy Correction for a REINFORCE Recommender System,WSDM 2019
本文的主要亮点是提出了一种Top-K的Off-Policy修正方案将RL中Policy-Gradient类算法得以应用在动作空间数以百万计的Youtube在线推荐系统中。
众所周知[1],Youtube推荐系统架构主要分为两层:召回和排序。本文中的算法应用在召回侧。建模思路与RNN召回类似,给定用户的行为历史,预测用户下一次的点击item。受限于On-Policy方法对系统训练架构要求复杂,所以本文中转而采用Off-Policy的训练策略。也就是说并不是根据用户的交互进行实时的策略更新,而是根据收集到日志中用户反馈进行模型训练。
这种Off-Policy的训练方式会给Policy-Gradient类的模型训练带来一定的问题,一方面策略梯度是由不同的policy计算出来的;另一方面同一个用户的行为历史也收集了其他召回策略的数据。所以文中提出了一种基于importance weighting的Off-Policy修正方案,针对策略梯度的计算进行了一阶的近似推导。
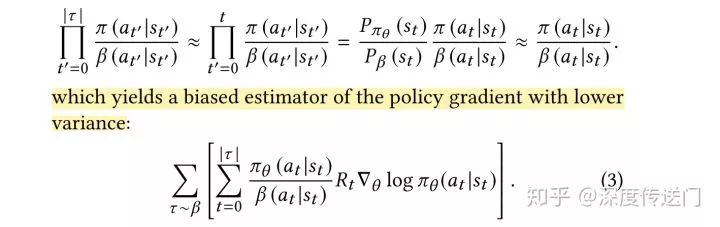
因为是基于用户的交互历史预测下一个用户点击的item,所以文中也采用RNN针对用户State的转换进行建模。文中提到实验了包括LSTM、GRU等RNN单元,发现Chaos Free的RNN单元因为稳定高效而使用起来效果最好。
在上述的策略修正公式(3)中最难获取到的是用户的行为策略,理想情况下是收集日志的时候同时把用户相应的用户策略也就是点击概率给收集下来,但由于策略不同等客观原因文中针对用户的行为策略使用另外一组θ'参数进行预估,而且防止它的梯度回传影响主RNN网络的训练。
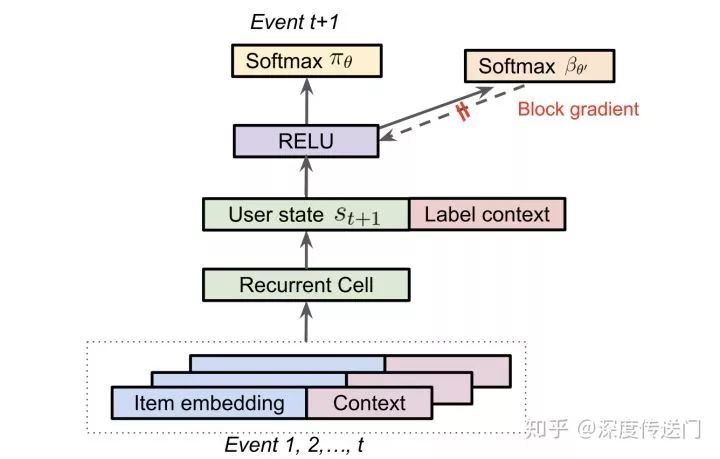
另外,由于在推荐系统中,用户可以同时看到k个展示给用户的候选item,用户可能同时与一次展示出来的多个item进行交互。因此需要扩展策略根据用户的行为历史预测下一次用户可能点击的top-K个item。
假设同时展示K个不重复item的reward奖励等于每个item的reward的之和,根据公式推导我们可以得到Top-K的Off-Policy修正的策略梯度如下,与上面Top 1的修正公式相比主要是多了一个包含K的系数。也就是说,随着K的增长,策略梯度会比原来的公式更快地降到0。

从实验结果的角度,文中进行了一系列的实验进行效果比较和验证,其中Top-K的Off-Policy修正方案带来了线上0.85%的播放时长提升。而且前文也提到过,Minmin Chen大神在Industry Day上也提到线上实验效果显示这个是YouTube单个项目近两年来最大的reward增长。
另外,在最新一期的Google AI Blog[3]上,宣布提出了一种基于强化学习Off-Policy的分类方法,可以预测出哪种机器学习模型会产生最好结果。感兴趣的可以继续延伸阅读一下。
Reinforcement Learning for Slate-based Recommender Systems: A Tractable Decomposition and Practical Methodology,IJCAI 2019
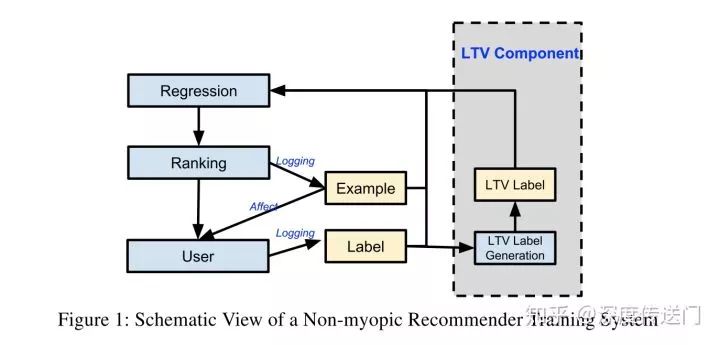
这篇文章相比于第一篇文章时间要晚一点,提出的方法也不尽相同,不过类似的是都宣称在Youtube线上推荐系统上取得了不错的效果。主要贡献是提出了一种名为SLATEQ的Q-Learning算法,优化推荐系统里面同时展示给用户多个item情况的长期收益LTV(Long-term Value)。
这里首先讲一下这篇文章与第一篇文章的不同,首先,第一篇文章假设了在推荐系统中同时展示K个不重复item(本文中称为Slate)的奖励reward等于每个item的reward的之和,这个在本文中认为实际上是不合理的,因此建模了Slate的LTV和单个item的LTV之间的关系;其次,本文显式的建模与评估了整个系统LTV的收益。
从系统架构的角度,本文扩展了Youtube现有的只注重即时收益的ranker,也就是针对CTR等指标以及长期收益LTV进行多目标前向深度网络学习。值得注意的是,为了保证线上实验的公正性,这里除了多目标外,其他与Youtube线上的特征以及网络参数都完全一样。
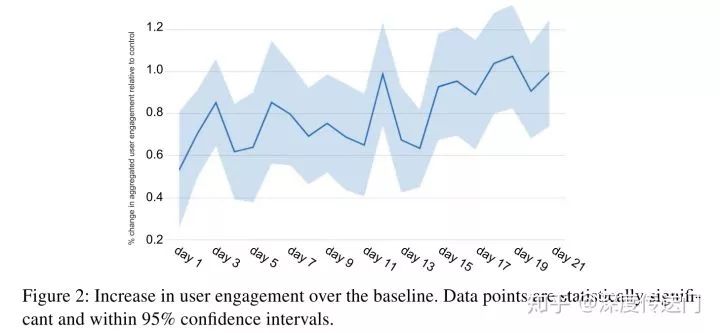
最后实验部分,本文中评估的是User engagement,可以从下图中看到效果提升是明显且稳定的。
其他业界进展
除了Google的上述两篇论文外,工业界其他公司也在积极尝试强化学习在推荐系统中的实战,下面主要简要列出来一些到目前为止的进展:
Generative Adversarial User Model for Reinforcement Learning Based Recommendation System,ICML 2019
在蚂蚁金服被 ICML 2019 接收的这篇论文中,作者们提出用生成对抗用户模型作为强化学习的模拟环境,先在此模拟环境中进行线下训练,再根据线上用户反馈进行即时策略更新,以此大大减少线上训练样本需求。此外,作者提出以集合(set)为单位而非单个物品(item)为单位进行推荐,并利用 Cascading-DQN 的神经网络结构解决组合推荐策略搜索空间过大的问题[1]。
Virtual-Taobao: Virtualizing real-world online retail environment for reinforcement learning,AAAI 2019
阿里 at AAAI 2019,“虚拟淘宝”模拟器,利用RL与GAN规划最佳商品搜索显示策略,在真实环境中让淘宝的收入提高2%。美中不足的是baseline仍然是传统监督学习而不是深度学习方案。
Large-scale Interactive Recommendation with Tree-structured Policy Gradient,AAAI 2019
参考文献
[1] Deep Neural Networks for YouTube Recommendations, RecSys 2016
[2] Wide & Deep Learning for Recommender Systems,
[3] ai.googleblog.com/2019/
[4] Reinforcement Learning to Optimize Long-term User Engagement in Recommender Systems
[5] 阿里的《 强化学习在阿里的技术演进与业务创新》
[6] 京东的 Deep Reinforcement Learning for Page-wise Recommendations
原文链接:https://zhuanlan.zhihu.com/p/69559974F
(*本文为 AI科技大本营转载文章,转载请联系原作者)
◆
精彩推荐
◆
《程序员大本营》6月刊来啦~
更多福利限时免费领取:CSDN重磅技术大会精选视频以及200+PPT;机器学习、知识图谱、计算机视觉、区块链等100+技术公开课及PPT全奉送...

推荐阅读:
 你点的每个“在看”,我都认真当成了喜欢
你点的每个“在看”,我都认真当成了喜欢

