
- 1「面试题」20+Vue面试题整理_vue数组面试题
- 2RoBERTa, DeBERTa (v1, v2, v3)_debertav3
- 3TypeScript系列学习笔记-命名空间namespace_declare namespace
- 4AI工程化—— 如何让AI在企业多快好省的落地?_ai所面临的工程化问题
- 5【Kafka】kafka-eagle几个指标含义_kafka-eagle 几个指标含义
- 6python自然语言处理入门-新手上路_自然语言处理编程
- 7【审稿意见】科研菜鸟如何攥写审稿意见?万能模板!!!_审稿意见模板
- 8【讲解下Docker in Docker的原理与实践】
- 9在SpringBoot中整合使用Netty框架_springboot整合netty框架
- 10deepfake 图片_一个模型击溃12种AI造假,各种GAN与Deepfake都阵亡 | 伯克利Adobe新研究...
阿里云EMR 2.0:定义下一代云原生智能数据湖_阿里云数据湖
赞
踩
摘要:本文整理自阿里云高级技术专家/数据湖存储负责人郑锴(铁杰);阿里云高级技术专家/开源大数据OLAP负责人范振(辰繁)在 阿里云EMR2.0线上发布会 的分享。
本篇内容主要介绍了阿里云云原生数据湖分析解决方案的三个核心要素:
1.全托管,湖存储;
2.一站式,湖管理;
3.多模态,湖计算
阿里云云原生数据湖分析解决方案全面重磅升级,经中国信通院评测,它是目前国内唯一满分的数据湖方案。它有三个核心要素构成:
- 全托管,湖存储:全面兼容支持 HDFS/POSIX 协议,无缝对接大数据和AI一体化生态;
- 一站式,湖管理:提供全面的数据库存储管理能力;
- 多模态,湖计算:基于一湖多架构,能够同时实现离线湖、实时湖、湖仓分析。
一、全托管 - 湖存储(OSS-HDFS)
1、第三代数据湖存储 OSS-HDFS
- 第一代数据湖存储是开源的 HDFS;
- 标准对象存储如阿里云OSS,被认为是第二代数据库存储;
- 阿里云融合前两代数据湖存储上的优势,推出第三代数据湖存储:OSS-HDFS。
2、OSS-HDFS 生态支持
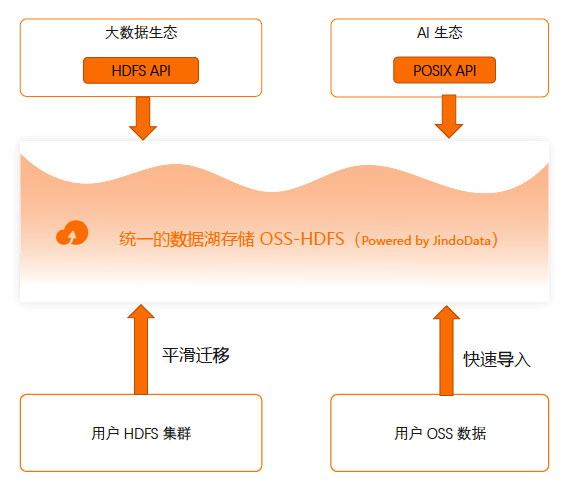
新的数据湖存储解决方案 OSS-HDFS,通过 HDFS API 和 POSIX API,实现对数据湖存储之上丰富的大数据和AI计算场景的完整支持,这是第三代数据湖存储的核心命题。
- 通过提供充分的、完全的 HDFS 接口兼容,充分对接 Hadoop、Spark 这类大数据生态;
- 同时,对新兴的湖仓分析计算场景也提供了充分的支持;
- 对于蓬勃发展的AI生态,通过 POSIX 提供兼容支持。
3、性能优势
在存储服务的核心能力方面,如性能、规模和成本上,阿里云云原生数据湖分析解决方案具备显著的优势。
- 性能:高
- 原子性和毫秒级目录操作 rename、delete
- 超大目录 du/count 毫秒级返回
- 规模:大
- 热文件(10 亿)+ 温冷(40亿)vs 4亿
- OSS 带宽水平扩展
- 成本:低
- 标准(30%)+ 低频(30%)+ 归档(40%)
- 免运维
几十PB甚至上百PB的数据库,按照二八定律,20%的数据是热数据,80%的数据是温数据或者冷数据,利用 OSS 的分层存储和归档能力,OSS-HDFS 实现了 HDFS 的分层存储管理策略,可以将20%的热数据实施标准存储策略,80%的温数据和冷数据分别按照低频和归档的存储策略来存储,整体降低了存储成本。
OSS-HDFS 作为全托管的存储服务,相比较开源自建的 HDFS,具备免运维、低人工的维护成本,在性能、规模、成本上具备显著的性能优势。
对于用户自建的 HDFS 集群,阿里云云原生数据湖分析解决方案在业界首次提供了"三不"平滑迁移方案,不改业务代码,不改文件路径,不停存储服务。对于用户已经在 OSS 上面的数据,支持快速导入,方便用户享受 OSS-HDFS 提供的对于计算访问加速的优势。
二、一站式 - 数据湖管理(DLF)
阿里云云原生数据湖分析解决方案,通过 Data Lake Formation 这个全托管的数据湖管理产品,提供一站式数据湖管理能力。

Data Lake Formation 能够对众多的计算产品提供统一的元数据访问,具有全景的、完整的数据访问统计视图,提供诸多存储分析和成本优化方案,如智能识别温数据、冷数据和热数据,提供分层存储管理策略;如针对 Deltalake 提供自动优化策略等。
1、统一元数据服务
- 全托管、高可用、高性能、可扩展、免运维;
- 兼容开源 HMS 协议,无缝对接和兼容开源;
- 支持 Multi-Catalog、多版本管理;
2、权限与安全
- 支持库、表、列、函数级别细粒度权限控制;
- 支持和兼容 Apache Ranger 鉴权;
- 支持数据访问日志审计;
3、存储成本优化
- 存储分析与成本优化;
- 湖格式自动优化策略;
- 数据生命周期管理;
4、存储访问加速
- 全场景:大数据分析加速、AI 海量小文件训练加速;
- 策略全:读缓存、写缓存、元数据缓存、分层缓存;
- 同时支持计算透明和数据编排。
三、多模态 - 湖计算
EMR2.0遵循的是一湖多架构的计算模式,然后通过开源引擎引入组合成不同的用户场景。接下来介绍几种典型的场景:离线湖,实时湖,湖仓分析。
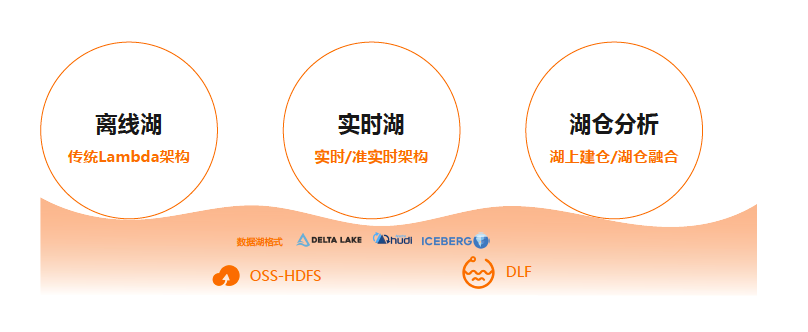
1、离线湖
离线湖即 Hadoop 场景,主要解决的是数仓的分层模式,一般用在T+1场景。

(离线湖)
- OSS-HDFS:通过提供 HDFS 接口,以及 OSS 对象存储,能够做到分层存储和智能存储,可扩展性高,成本低;
- 引入全托管的 DLF:解决了 HIVE+MySQL 这种传统元数据模式的一些痛点,包括稳定性,可扩展性等;
- 数据湖三剑客:DELTA LAKE、HUDI、ICEBERG,这三种引擎近年来发展得非常好,在后面实时湖的部分重点介绍;
- 计算资源层:这里一般分为 ECS 和 ACK,经过 EMR2.0 引入的这个全新开发的底座,对 ECS 和 ACK 的支持都非常好,在弹性的速度、可靠性、免运维等方面,对比上一个版本有了质的提升,
- 计算引擎:计算引擎逐渐由 Hive on MR、Hive on Tez 迁移到 Spark。Spark 作为近十年来的一个明星产品,阿里云对 Spark 进行了深度的自研优化,在性能上比开源提升了100%。在此基础上,阿里云自研了 Remote Shuffle Service,并把它捐献到了 Apache 社区(名字为 Celeborn),Remote Shuffle Service 把所有的 Shuffle 数据放在一个 Service 上而不是依赖于本地盘,解决了 Spark 常见的 Stage 不稳定、大作业的加速等问题。
离线大数据经过十多年的发展,目前仍经久不衰,T+1的场景被用户大规模使用,这主要是因为以下几点:
- 离线数仓的模型理论基础已经非常的完善;
- 固定的、有界的数据对于计算引擎的复杂度要求没有那么高,可以比较方便的进行数据重跑;
- Spark 被市场广泛接受,是一个非常稳定的产品。
2、实时湖
离线数据湖虽然被大规模使用,但它解决不了一些问题,如实时和准实时的问题,这就引出了实时湖。

(实时湖)
- OSS-HDFS 和 DLF(见离线湖部分);
- 数据湖的增量存储部分:数据湖三剑客 DELTA LAKE、HUDI、ICEBERG,这三种引擎近年来发展得非常好,这种表格式慢慢的也会演化成不同的方向,但它们着重解决的是同一类问题;
- 第一,要解决的是增量模式,需要做 ACID 的事务保证,由于引入了 ACID 事务保证,实际上每一个 commit 就是一个 version,那么可以在同一套系统里去做批、做流的处理;
- 第二,引入了自闭环元数据的结构,实际上解决的问题是大规模的元数据的扩展性以及性能问题。它所依赖的是对象存储,而不是类似Hive这种体系,所以在可扩展性上是有非常大的提高;
- 第三,一旦引入 ACID,就可以做 update 这种场景,而要反映到大数据里面,可以通过增量表格式的研发来解决,包括常见的订单系统、对于数据回溯等状态变化的场景,也包括一些高级的特性如 Schema Evolution,Time Travel 等,对整个业务会有非常大的提升,这是增量数据湖带给我们的一些好处和能解决的一些业务痛点。
- 计算引擎:
- Flink:Flink 是流引擎的最明星产品,所有客户涉及到实时的产品都在用,最近主打的理念就是批流一体;
- Presto和Trino也在往不同的方向走,比如Presto,它目前推出了一些能够进行native计算的领域,包括Velox,包括对ETL的一些补充,以及一些容错的方向,它可以做一些原先Spark才能做的工作,很多客户也在用Presto或Trino来做一些简单的ETL加工,虽然它原来标榜的是纯内存计算;
- Trino主要的处理的方向是做connector,进行所谓的联盟查询,而且它对细粒度的优化做得非常不错。Presto和Trino主要解决的是湖数据的准实时的处理,即在几十秒或者分钟级别的查询。
实时湖通过表格式的方式去解决一些问题和痛点,其业务的可拓展性和可发展性非常强。
3、湖仓分析
一般在纯实时的场景下引入湖仓分析。

(湖仓分析)
数据湖里的数据链路,如果想被 OLAP 系统查询到,或者说被秒级的 Ad-hoc 查询,或者说被高并发查询,目前没有一种引擎可以非常完美解决。但可以把它放到一种仓里,比如常见 StarRocks,Doris,ClickHouse,可以解决实时报表,实时数仓,大屏展示等。
湖仓直接分析是因为如果把数据全部导入到 StarRocks,会有数据重复,也会增加存储成本。
为了平衡成本与性能,通过 StarRocks 统一技术栈,既可以做仓内的查询,也可以做仓外的湖查询,通过缓存机制,能够使得仓外的查询,也就是说 connector 查询,能够达到几乎和仓内查询一样的速度。
StarRocks 看起来像是现代化的云 Lakehouse,自从开源以来,从2.X版本执行引擎的性能提升,全面的向量化,查询规划优化,全新 CBO 优化,主键模型,雾物化视图等等,都是在打造仓内部,后续 StarRocks 兼容轻量的 ETL,在仓内去做分层数仓模型。
从2.4、2.5版本开始,StarRocks 逐渐转化为对于湖上数据的优化,包括提供对 DELTA LAKE、HUDI、ICEBERG 的全面支持,通过统一的技术栈,即去查询仓内数据,又去查询仓外数据,这样整个架构就会非常顺滑,客户用起来也非常轻松。
4、Serverless
Serverless StarRocks产品已开启邀测,预计3月底公测,后续还会推出 Serverless Spark、Serverless Presto/Trino;
通过 Serverless 进行存算分离架构演进,计算资源可以按需扩展,具备极致的弹性和极致的成本压缩;
通过 OSS-HDFS,DLF,Serverless,实现免运维,99.9% SLA保障,NoteBook/Dataworks 对接等,为用户提供端到端的全托管体验。
本文为阿里云原创内容,未经允许不得转载。

