
- 1华为手表开发:WATCH 3 Pro(17)传感器订阅指南针_鸿蒙指南针测量磁场
- 234 动态组件(切换组件)保存状态input值_vue3 保存input值
- 3SAP BASIS ADM100 中文版 Unit 10(1)_sap adm100
- 4卡刷rom轻松转线刷rom_常见的第三方REC卡刷过程总结
- 5List、Map、Set三个接口存取元素时,各有什么特点?_list、map、set 三个接口,存取元素时,各有什么特点
- 6VMware16安装macOS12的几个问题解决:循环重启等_vmware安装macos13无限重启
- 7天猫用户重复购买预测(速通一)_天猫复购预测-挑战baseline用户信息表、用户行为表、用户购买数据表查看整体数据
- 8CentOS系统中使用yum快速安装python3_centos yum python3
- 9Node.js安装及环境配置(简单易懂全面!)_nodejs安装及环境配置
- 10马斯克最新深度采访:我一年只休三天,7000字聊透九大热点_马斯克不能接受和家人相处时间过长的事情
【AI绘图】 ControlNet教程,ControlNet v1.1来了, 更新更精细的模型
赞
踩
前一段时间忙其他事情了,AI绘图的介绍相对少了一点,还请各位谅解。
之前比较重要的消息就是ControlNet的模型已经更新了,增加了一些新的更有趣有用的功能.
当然这里再介绍一下ControlNet作用
知识再现
ControlNet是一个神经网络结构,通过添加额外的条件来控制扩散模型,是人工智能图像生成的游戏规则改变者。它为稳定扩散带来了前所未有的控制水平。
ControlNet的革命性之处在于它对空间一致性问题的解决方案。以前根本没有有效的方法来告诉人工智能模型要保留输入图像的哪些部分,而ControlNet通过引入一种方法,使稳定扩散模型能够使用额外的输入条件,告诉模型到底要做什么,从而改变了这一现状。
在我们实际画图中通常使用ControlNet中的一些模型,这些模型可以得到原图的线稿,深度图,再利用得到的这种图进行调节,从而生成新的图,而这新的图就是我们"control"之后的,可以用来解决人物手部显示等问题.
而这里的升级版本主要也是值得模型升级,所以对于我们使用的stable diffusion web ui(现在用的一般是Automatic1111开发的,但是被人嫌弃更新维护太慢,很多人又改用vladmandic开发的,后者优化了速度同时也内置了很多功能包括ControlNet和Lora训练,后面可能会写一个vlad版的安装),所以我们只需要更新一下web ui扩展,重点是需要下载新的模型.
升级模型
现在,ControlNet 1.1的所有14个型号都在进行测试。
下载模型地址以及文章中的一些引用信息都在参考资料中
需要下载以".pth "结尾的模型文件。
把模型放在你的 "stable-diffusion-webui/extensions\sd-webui-controlnet/models "中。现在我们已经包含了所有的 "yaml "文件。你只需要下载 "pth "文件。
插件更新

本人通过web ui下载或者更新插件时经常出错,但是如果用Git从Github上下载倒还是正常,所以如果更新ControlNet插件时遇到上面的问题可以在插件目录通过Git克隆仓库下载,或者更新的话直接git pull即可

插件更新的特性
- 新的controlnet插件增加了对于新模型 T2I Adapter Models的支持
- 对于面部修复又更好的支持
现在,如果你在A1111的web ui中打开High-Res Fix,每个控制网将输出两个不同的控制图像:一个小的和一个大的。小的是为你的基本生成,大的是为你的高清晰度修复生成。这两个控制图像是由一种叫做 "超高质量控制图像重采样 "的智能算法计算出来的。这在默认情况下是打开的,你不需要改变任何设置。
- 对于inpaint有更好支持
现在ControlNet对A1111的不同类型的遮罩进行了广泛的测试,包括 “Inpaint masked”/“Inpaint not masked”,以及 “Whole picture”/“Only masked”,和 “Only masked padding”&“Mask blur”。调整大小与A1111的 “只是调整大小”/“裁剪和调整大小”/"调整大小和填充 "完美匹配。这意味着你可以在A1111用户界面的几乎所有地方毫无困难地使用ControlNet
- 增加Pixel Perfect
现在,如果你打开了像素完美模式,你就不需要手动设置预处理器(注释器)的分辨率。ControlNet会自动为你计算出最佳的注释器分辨率,以便每个像素都能完美地匹配稳定扩散。
- UI中选项命名和设置布局更友好
- 原本的Guess Mode改为Control Mode
下载新模型
下面介绍一下新模型特性

这是模型命名规则.新版本模型增加了如下的新模型,像Depth、Normal、Canny、Scribble、MLSD、HED这种原本就有的,所以不多解释.
control_v11p_sd15_canny
control_v11p_sd15_mlsd
control_v11f1p_sd15_depth
control_v11p_sd15_normalbae
control_v11p_sd15_seg
control_v11p_sd15_inpaint
control_v11p_sd15_lineart
control_v11p_sd15s2_lineart_anime
control_v11p_sd15_openpose
control_v11p_sd15_scribble
control_v11p_sd15_softedge
control_v11e_sd15_shuffle
control_v11e_sd15_ip2p
control_v11f1e_sd15_tile
主要介绍一下新的模型.
Lineart模型,这个模型是在awacke1/图像到线性图上训练的。该预处理器可以从图像中生成详细或粗略的线性图(Lineart和Lineart_Coarse)。该模型的训练有足够的数据增量,可以接收手动绘制的线性图。
Lineart_anime模型,你需要一个基础模型 "anything-v3-full.safetensors "来运行。
这是一个长提示模型。除非你使用LoRAs,否则长提示的结果会更好。
这个模型不支持猜测模式。
Lineart_anime模型只需要线稿就能给图形上色,效果不错.

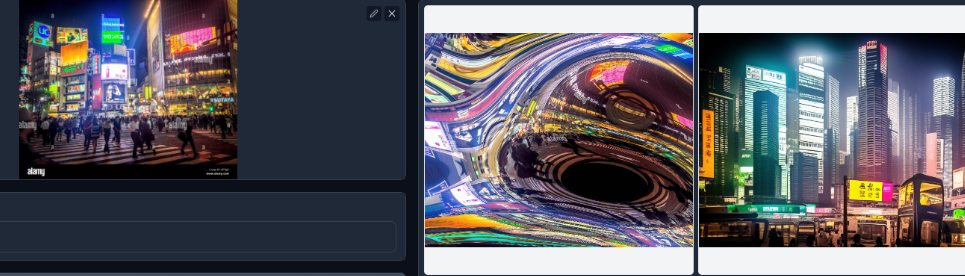
Shuffle模型,该模型被训练为重组图像,用来绘制一些克苏鲁图可能不错.
Instruct Pix2Pix模型,与官方的Instruct Pix2Pix不同,这个模型是用50%的指令提示和50%的描述提示来训练的。例如,"一个可爱的男孩 "是一个描述提示,而 "让男孩变得可爱 "是一个指令提示。
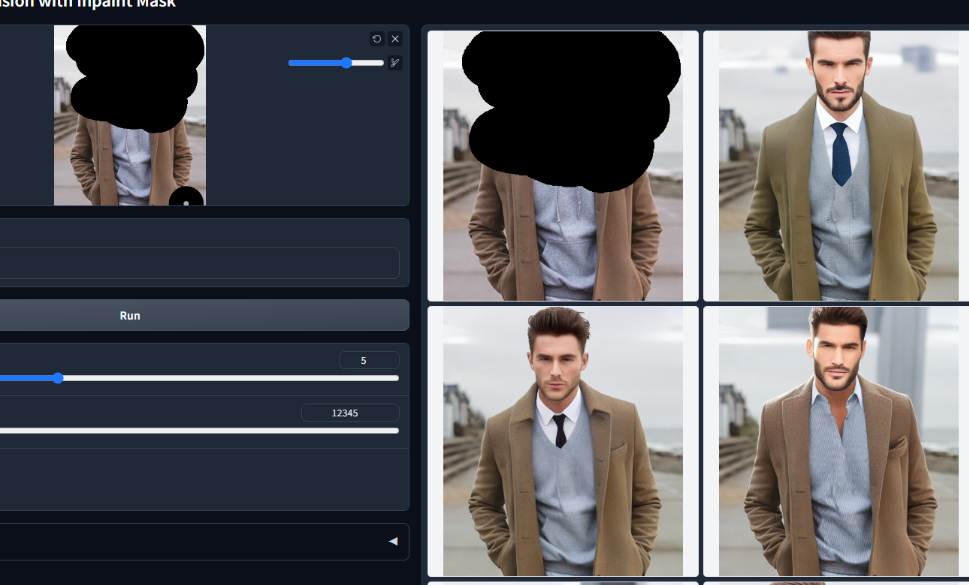
Inpaint模型,这个画中画控制网是用50%的随机掩码和50%的随机光流遮蔽掩码训练的。这意味着该模型不仅可以支持画中画的应用,还可以在视频光流扭曲上工作。
这个模型功能看起来跟Inpaint类似,也是我比较喜欢的一个模型,用来修改图像的某个部分很有用.
Openpose模型 增加了对面部和手部的支持
Tile模型,该模型可以以多种方式使用。总的来说,该模型有两种行为:
忽略图像中的细节,生成新的细节。如果本地语义和提示不匹配,则忽略全局提示,用本地背景引导扩散。
注意下载时需要pth文件,而yaml文件最新的ControlNet插件已经帮助我们下载了,在\extensions\sd-webui-controlnet\models中,这里我下载了lineart_anime模型,一个模型1.45G也不小,也放在这个目录中
实战
下载好新的模型后,从网站找个线稿图,这里我提供一张用来测试.

启用ControlNet,本人这里只有4G显存开启低显存模式和Pixel Perfect,不输入任何Prompt,
预处理器使用linear_anime,模型选择刚才下载的linear_anime.
当然由于我们这里本身使用的是线稿图,其实可以不使用预处理器,但是如果不使用预处理的话,效果特别差

再加点prompt比如1girl, silver hair, legwear, cinematic lighting,4k, 8k, extremely detailed,,服装时露肩衣
生成图片如下,还是不错的.
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ngEdAX5V-1682822846491)(null)]
最后介绍一个插件SD-paint,可以进行实时绘画,主要也是利用ControlNet的模型,自己画草稿然后更新生成图像,欢迎关注我,后面更新这个插件使用效果.
参考资料
- ControlNet - Control Diffusion Models (stablediffusionweb.com)
- lllyasviel/ControlNet-v1-1-nightly: Nightly release of ControlNet 1.1 (github.com)
- Mikubill/sd-webui-controlnet: WebUI extension for ControlNet (github.com)
- Vladmandic vs AUTOMATIC1111. Vlad’s UI is almost 2x faster : r/StableDiffusion (reddit.com)
- vladmandic/automatic: Opinionated fork/implementation of Stable Diffusion (github.com)
- houseofsecrets/SdPaint: Stable Diffusion Painting (github.com)

