
- 1基于Python爬虫河北石家庄酒店宾馆数据可视化系统设计与实现(Django框架) 研究背景与意义、国内外研究现状
- 2资源 | Python可视化系列文章资源(源码+数据)_python爬取数据+数据可视化源码
- 3维普与知网:谁的重复率更高?深度解析与全面比较
- 4论文笔记--GPT-4 Technical Report_gpt-4 technical report 论文引用
- 5表征与特征的关系_特征 表征
- 6排序学习(LTR)经典算法:RankNet、LambdaRank和LambdaMart
- 7苹果个人开发者账号申请+获取证书+上架应用商城_苹果开发者账号登录
- 8Chatgpt取代客服?取代客服的其实另有其人_gpt客服
- 93DGS(3D Guassian Splatting)部署验证+个人数据训练_3dgs制作数据集
- 10Learning From Noisy Labels with Deep Neural Networks: A survey
Python可视化分析项目高分课设_python可视化项目
赞
踩
今天给大家分享一个基于python的django框架结合爬虫以及数据可视化和数据库的项目,该项目总体来说还是挺不错的,下面针对这个项目做具体介绍。
1:项目涉及技术:
项目后端语言:python
项目页面布局展现:前端(html,css,javascript)
项目数据可视化呈现:echars.js
项目数据操作:mysql数据库
项目数据获取方式:爬虫(selenium,Xpath)
2:项目功能:
爬取数据后启动项目会把数据都存放在数据库里(数据库有3个表,一个工作岗位信息表,一个用用户信息表,一个工作收藏表),然后进入项目的登陆注册页面,以及会对用户的账号密码经行校验和存储,校验成功后进入首页:
2.1:注册信息如果为空则自定义404报错页面

2.2: 注册登录成功进入首页:

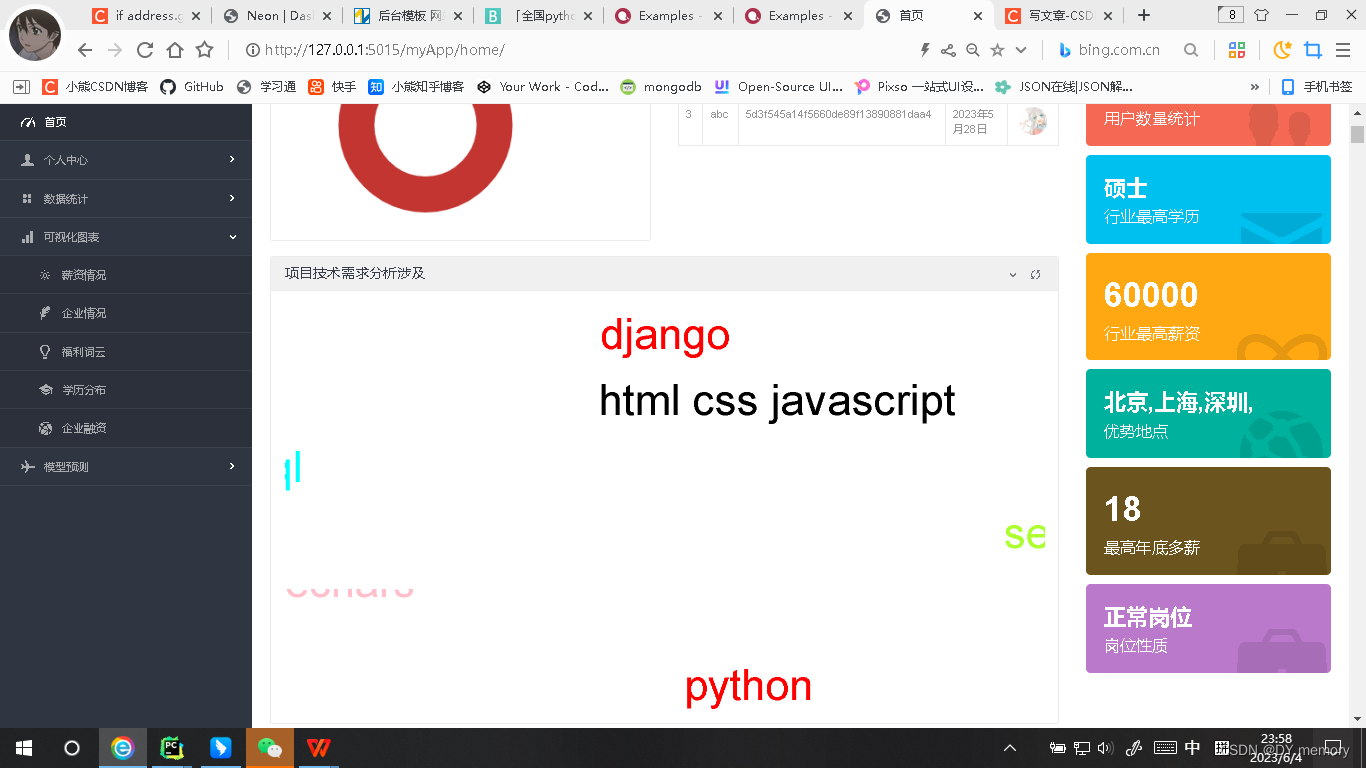
左侧为导航状态栏,个人中心有修改个人信息和修改密码的子页面,数据统计有数据总览和岗位收藏的子页面,数据可视化有 薪资,公司信息,员工人数以及企业融资等信息的可视化页面。
中间是一个饼图,可视化的数据为用户的创建时间,饼图右侧是一个用户信息表的展示,接着再右侧是一个对爬取信息的统计(如数据条目总数,用户量,最高学历,最高工资,热门城市以及做多月薪等信息展示),下面是一个技术涉及的跑马灯效果,最后下面就是员工所有信息数据的展示。
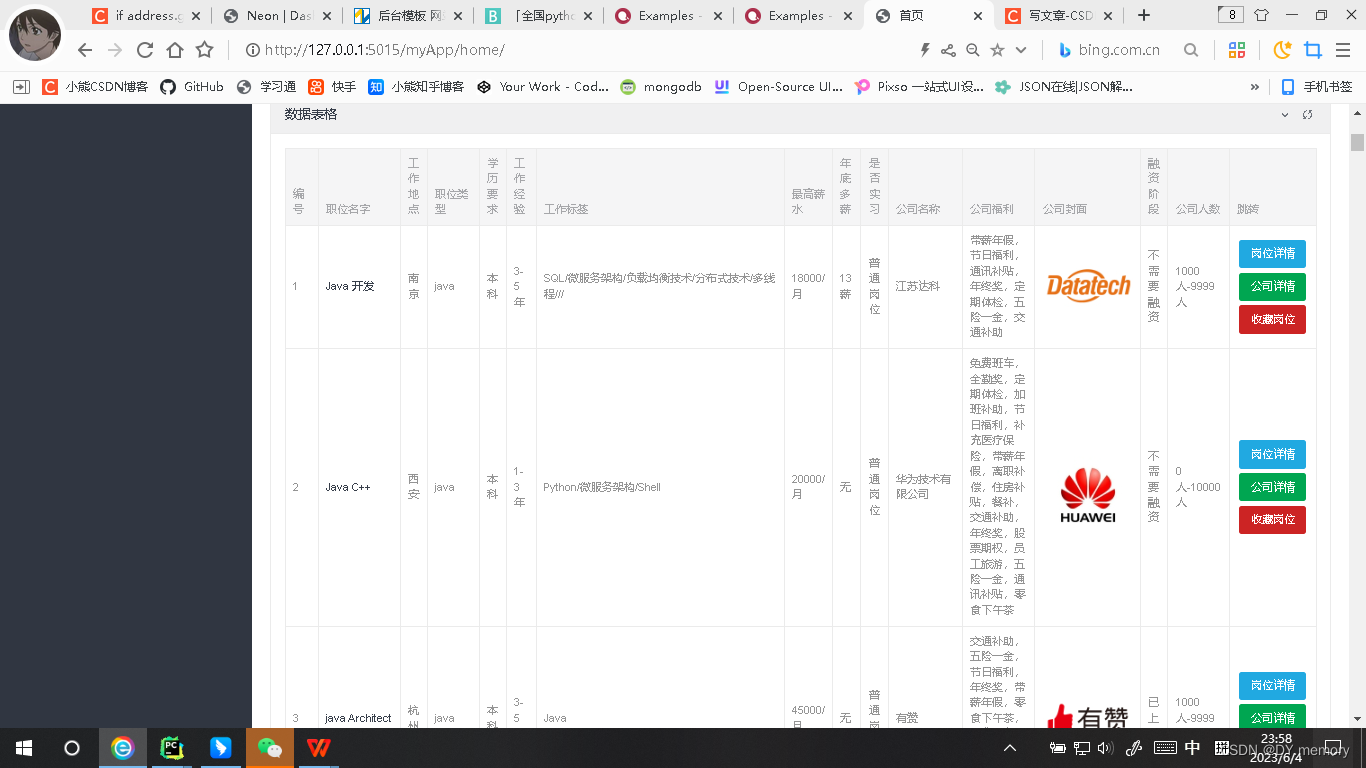
2.3:然后是个人信息的展示:
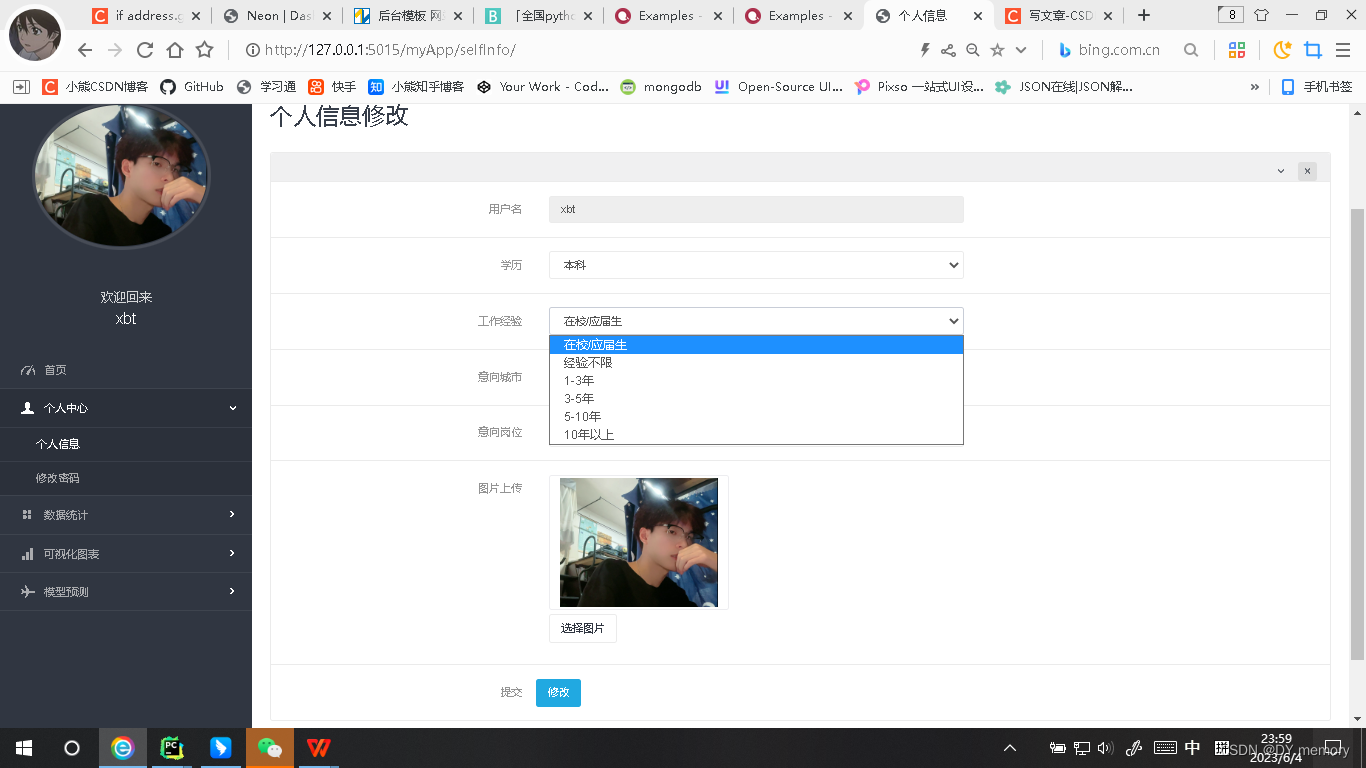
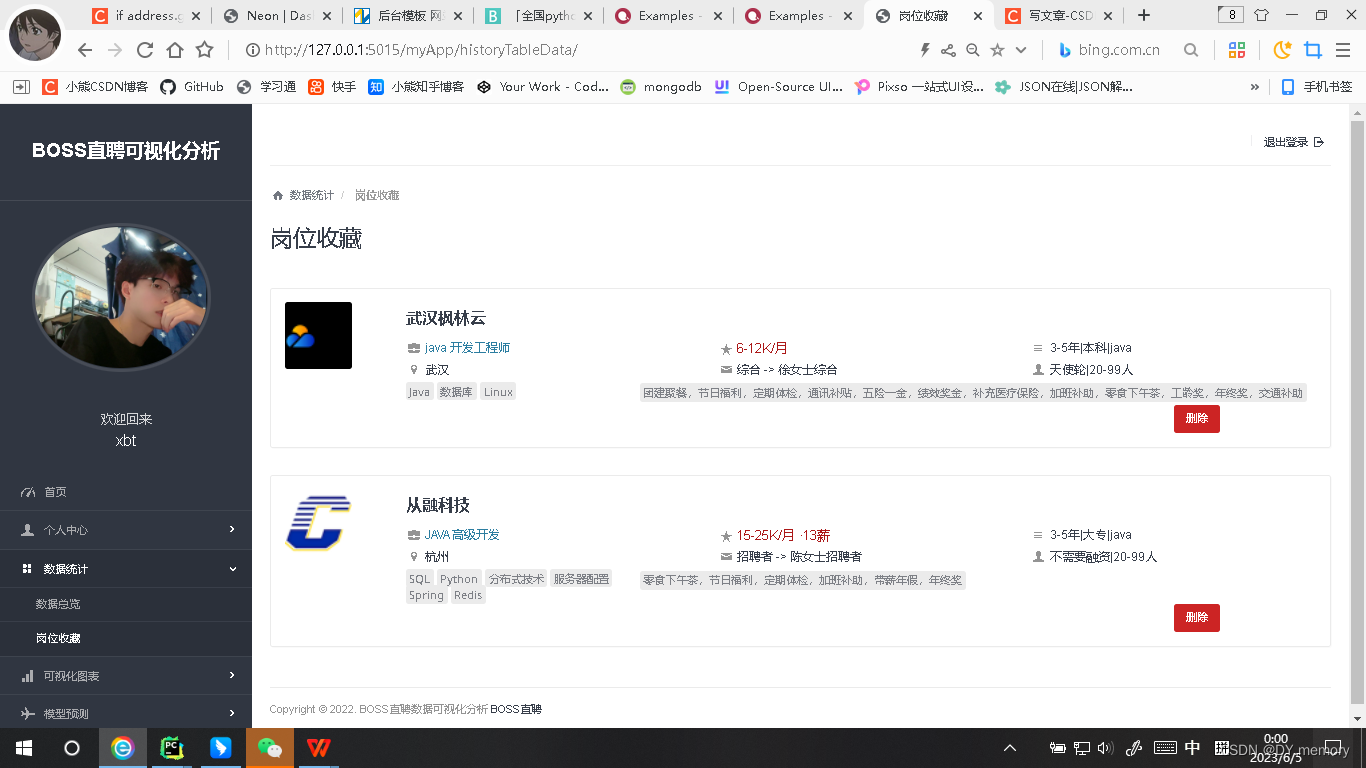
2.4:数据总览:用django内置的paginator分页系统对数据经行分页处理


2.5:数据可视化:在前端中使用echars.js对数据经行各种可视化分析,我们只需要把数据库的数据使用django模板语法在js的series字典的data属性经行信息渲染即可。
echars.js官网:Examples - Apache ECharts


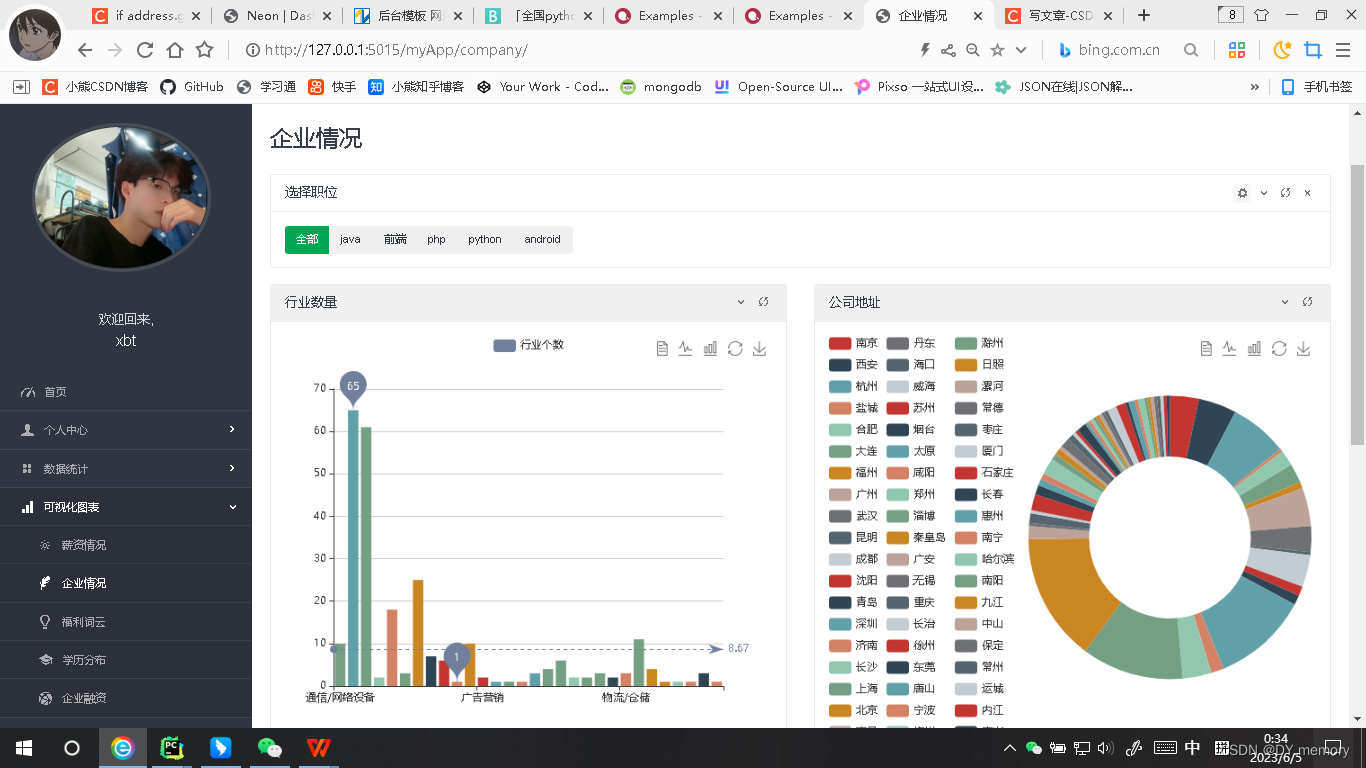
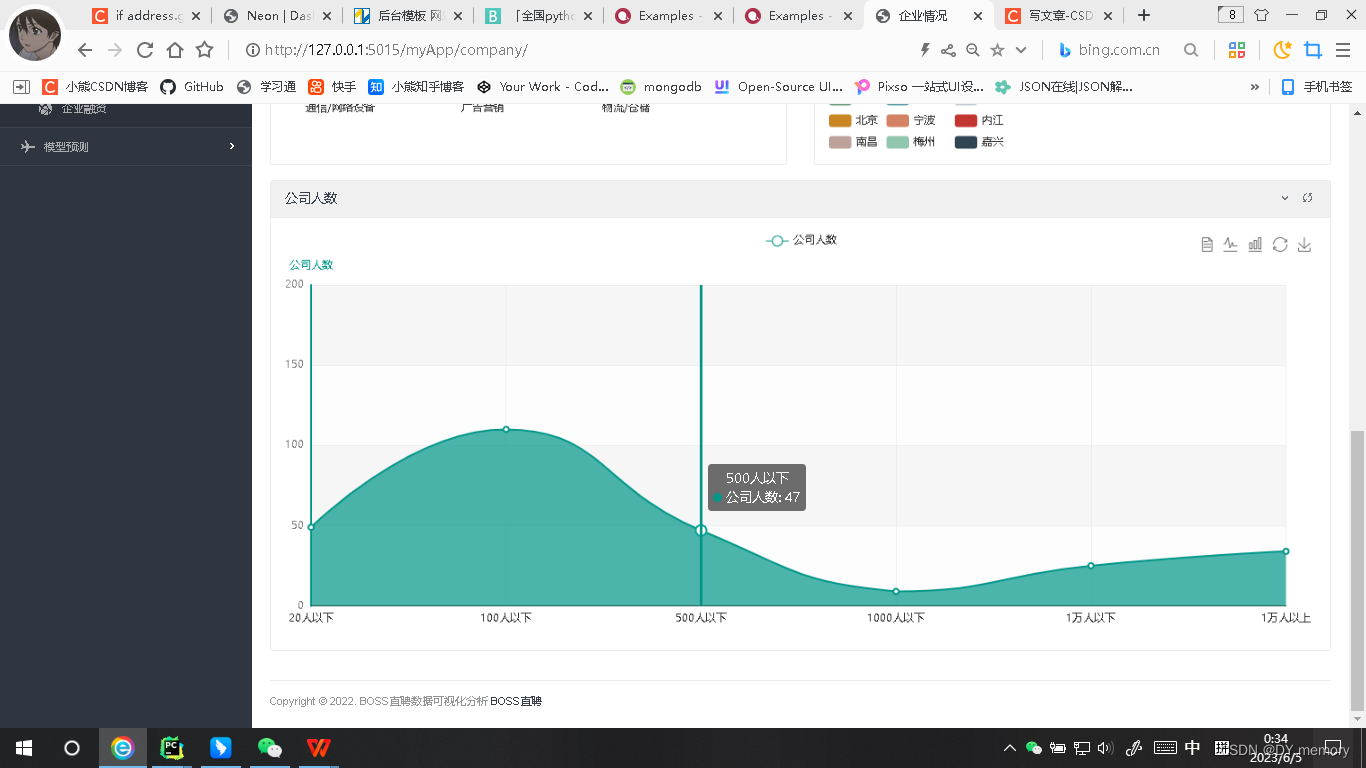
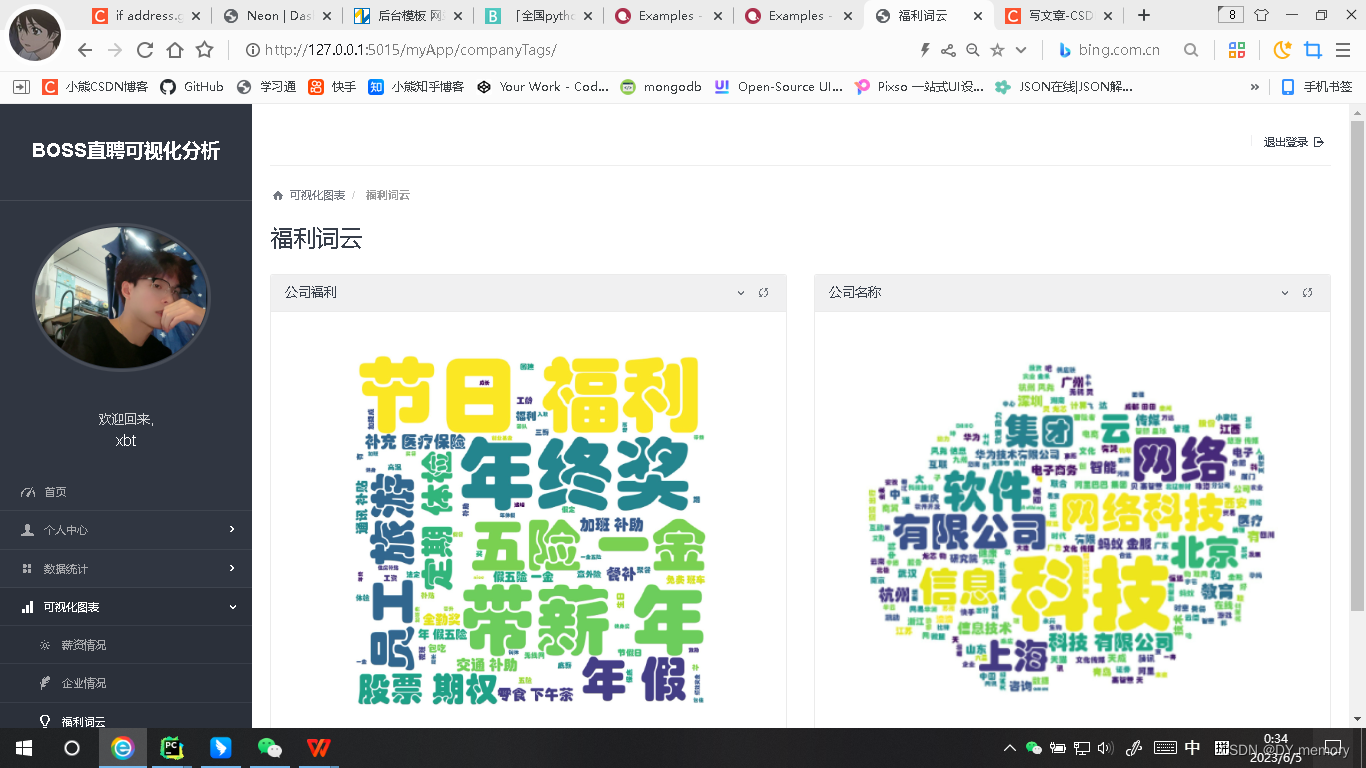
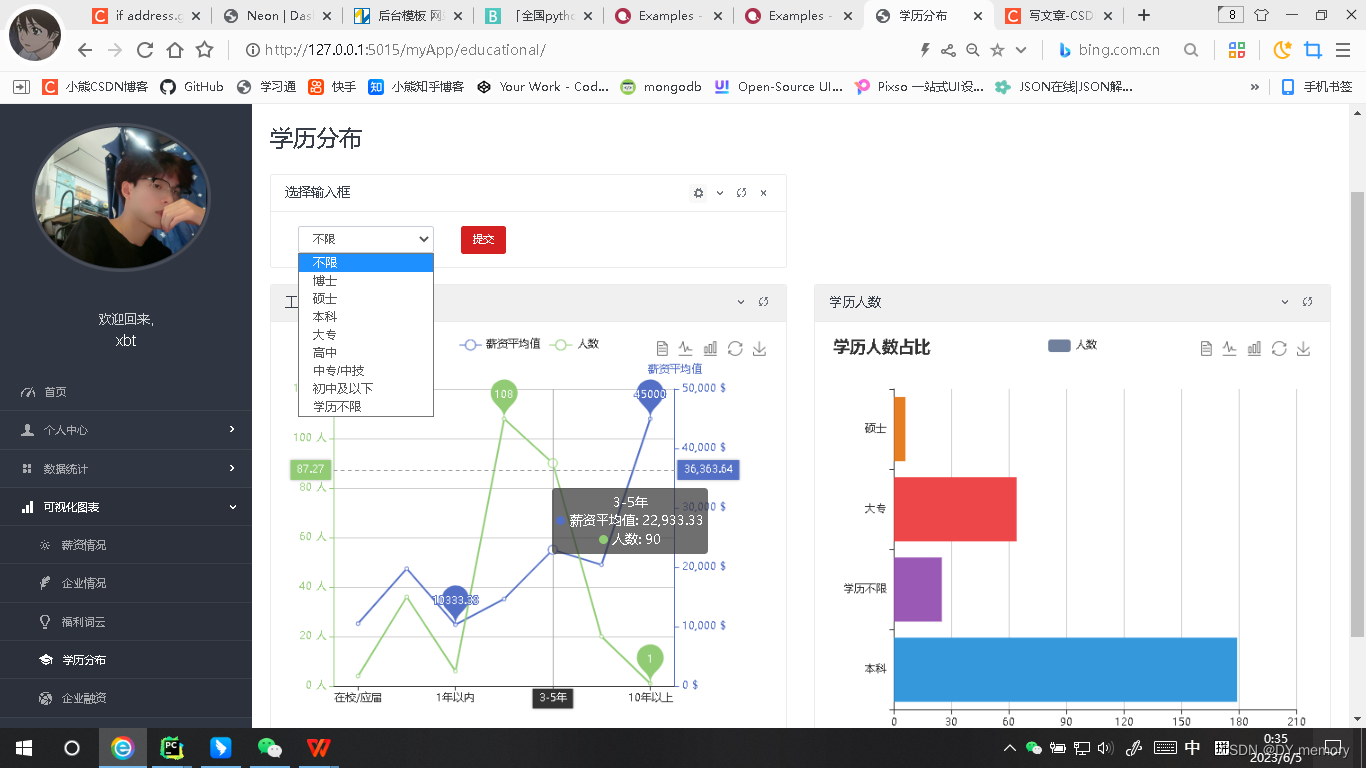
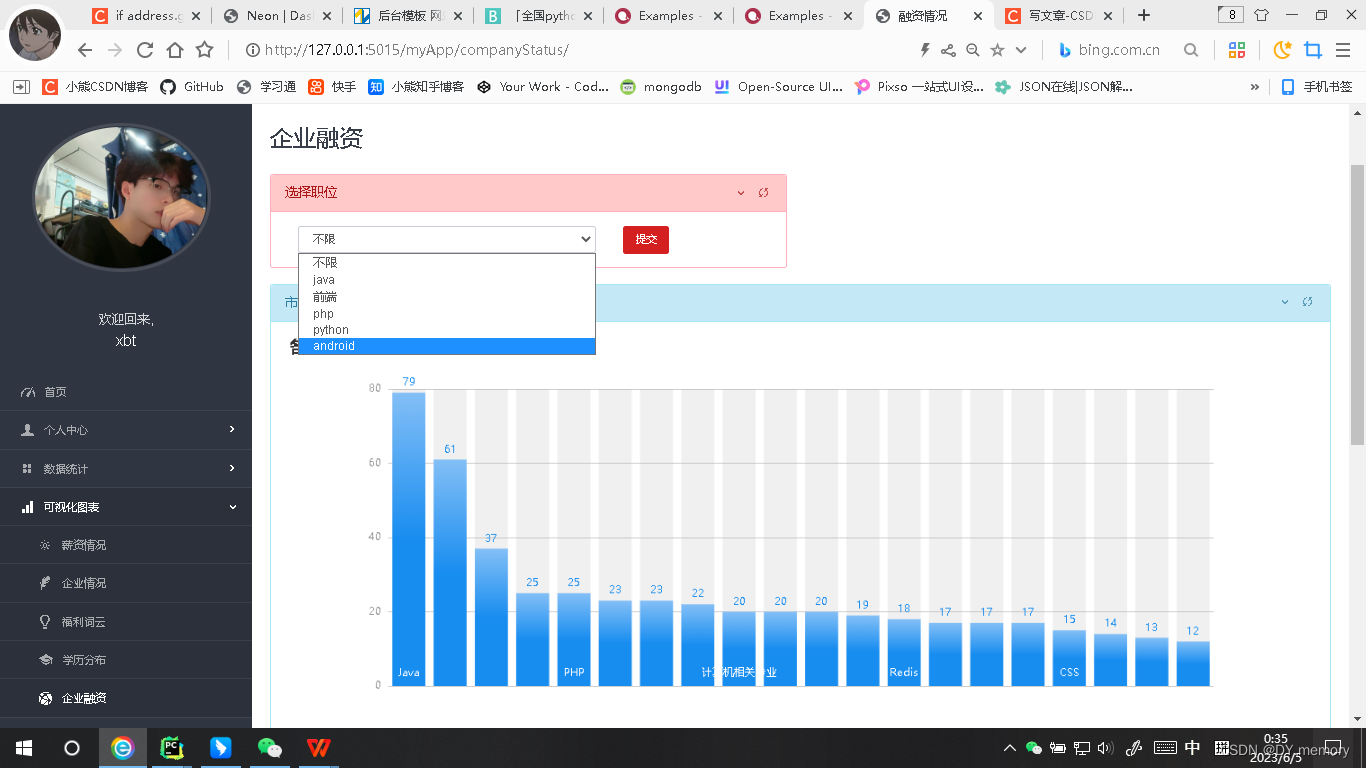

部分项目内部展示:
3:项目实现技术流程分析:
3.1:数据爬取:
数据针对boss直聘网站所获取,获取的内容对象为title工作名字,address工作城市,type工作类型,educational学历,workExperience工作经验,workTag工作标签,salary工资,salaryMonth多薪,companyTag公司福利,hrWorkHR岗位,hrNameHR姓名,pratice是否实习,companyTitle公司名字,companyAvatar公司头像,companyNature公司性质,companyStatus公司融资,companyPeopl公司人数,detailUrl岗位详情链接,companyUrl公司详情链接,dist行政区。
我们先从官网拿来两条页面的数据,照片如下:
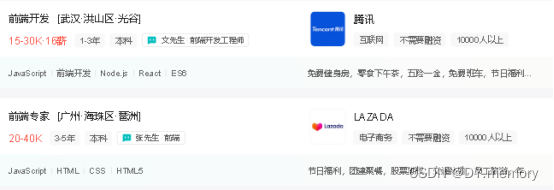
上面的数据和我们想要存放在数据库里的数据格式有点不一样,对此我们对个人数据样式需要做一些处理。
比如薪资信息,如15-30k我们在数据库要展示的类型为[15000,30000],处理过程为首先判断该职位是不是实习岗位,因为实习岗位是没有月薪的,实习的职位是多少多少元/天,我们先用Xpath路径解析来获取该薪资标签的text文本内容也就是15-30k·16薪,可以通过判断该文本字符串内容是否包含K来知道该职位是否实习岗位,包含k则为非实习岗位,然后python分隔符split(·)来把工资和多薪分开,然后用len()方法来获取其长度,如果为1则说明其没有多薪,我们设置为0薪,否则说明为多薪,至于对少薪,我们可以用python的切片来获取并将其多少薪赋值给一个salaryMonth的变量。
对于工资值的转换如何从15-30k转换为[15000,30000],代码首先从 salaries 列表中获取第一个元素,并在该元素中将 "K" 替换为空字符串。接着,代码使用 split('-') 方法将该元素按照 "-" 进行分割,得到一个列表。最后,代码使用 map() 函数将该列表中的每个元素都转换成整数,并乘以 1000,得到一个整数类型的列表。例如,如果 salaries[0] 的值为 "10K-20K",那么经过该代码处理后,salary 的值将为 [10000, 20000]。
另外对于address城市和dist行政区的赋值就是用xpath来获取去地址标签的文本如武汉市·洪山区·光谷,那我们是需要用ython的切片简单处理就好。
公司融资情况也需要做处理,因为我们浏览网站的数据不难发现有些有些公司的融资情况为无,有的显示已上市或者融资对象等等,例如:下面的融资情况为无,有的为有的为融资对象。


所以我们需要做些处理再放入到数据库,处理过程为:先用selenium库的find_element方法获取王者中的标签元素,遍历标签元素数量,提取公司的性质、融资状态以及公司规模等信息。具体而言,它首先判断网页中是否同时存在包含公司性质、融资状态和公司规模的标签,如果存在,就按顺序提取出它们的文本信息;否则,就认为公司的融资状态为“未融资”,然后提取公司规模信息,这里的公司人数也要做些处理。
公司人数也要做处理网站上显示的类型比如为20-99人,我们想要在数据库展示的是[20,99],则处理的过程和上面一样,使用 Selenium 库的 find_element 方法找到网页中符合条件的 HTML 元素,然后使用 split 和 replace 方法对元素的文本进行处理,最终将公司规模信息转化为一个包含两个整数的列表 companyPeople。如果在处理过程中出现异常,比如无法获取到元素或者元素的文本不符合预期,那么这段代码就会跳转到 except 语句块中,使用默认值 [0, 10000] 来代替 companyPeople。
公司福利也需要在传入数据库前经行处理因为我们发现有的公司并没有贴上福利内容比如:

这个时候只需要做简单的内容存在判断即可,如果不存在就把字符串“无”赋值即可,避免mysql不允许插入空值的问题。
数据爬取处理完毕之后给数据赋值变量后,将其放入到一个jobData的列表,调用os模块的writerow方法写入将其写入到csv里面,接着再对数据做最后的处理JobInfo.objects.create,将其
将其存入数据库里,到此爬取的数据已按照要求全部存入数据库。
3.2:登录注册:
注册内容就是纯粹的前端知识,建立一个form表单,把input输入框内容放在里面,建立一个属性为submit的button标签,在view.py视图写入后台逻辑代码,如果request.method == “GET”则键入url对应的地址(注册界面),如果请求方法为request.method == “POST”即提交表单,同时获取输入框提交的内容,然后用数据库User对象User.objects.create方法将数据写入到数据库的用户表里,使用md5 = hashlib.md5() .update(pwd.encode())对数据库的密码经行MD5加盐加密处理同时跳转到登录的url地址页面(检验注册是的账号以及密码就是简单的数据校验弹出提示或报错页面显示就不再说明了)
3.3:首页:
3.3.1:首页-时间&欢迎用户语:
time.localtime()获取当前时间,year = timeFormat.tm_year,month = timeFormat.tm_mon,day = timeFormat.tm_mday获取年月日,由于获取的月份是数字形式,而我们想要的是(June 1,2023)这种格式,所以在此我们创建一个列表放入1-12月的英文monthList=["January","February","March","April","May","June","July","August","September","October","November","December"]
,然后我们需要的月份便可以用monthlist[得到的数字-1]表示,同时欢迎语中的用户名便可使用使用django模板在前端html语法{{ username }}表示即可。
3.3.2:首页-用户创建时间饼状图:
在echars官网找到需要的数据展示图拿来源码在series列表的data字典里把用户时间字段属性值userTime写入即可,为了防止转义在后面加上 | safe,tooltip: { trigger: 'item'},legend: { top: '5%',left: 'center'},则用来实现数据布置图的鼠标悬停动态显示和顶部导航的.
3.3.3:首页-最新用户信息表展示:
前端table标签实现布局就不过多说明,主要说一下数据库中的用户数据的我获取展示,首先用户数据类User.objects.all()来获取数据库中用户的所有对象信息,赋值给Newuser对象里,然后用item.用户字段属性来获取用户字段的值,然后在首页前端页面写入规范的django模板循环语法{% for item in newUser %}即可遍历,记得放在tr标签里一起循环,且用户信息的数据展示规定显示5条且按照创建时间以此显示time.mktime(time.strptime(str(item.createTime),'%Y-%m-%d'))使用time模块中的strptime函数将时间字符串转换为struct_time类型的时间元组,然后再使用mktime函数将时间元组转换为时间戳。时间戳(Timestamp)是指某个特定时间点的标识,通常表示为从某个固定的起点(比如1970年1月1日00:00:00 UTC)开始到该时间点所经过的时间长度,单位可以是秒、毫秒、微秒等。时间戳可以用来表示事件发生的时间、计算事件之间的时间间隔等。在计算机系统中,时间戳通常以整数形式或浮点数形式存储。list(sorted(users,key=sort_fn,reverse=True))[:6]使用sort对时间戳经行排序且切片范围为前5个(包括第5个)
3.3.4:首页-项目技术需求涉及展示:
只需要在前端页面对应的div区域标签引入marquee文字滚动标签设置相关属性如方向,速度,字体大小等,即可改展现的文字内容“跑马灯效果”
3.3.5:首页-右侧数据(数据总量,用户数量,最高学历,最高工资,优势地点,最高多薪,岗位兴致)实现:
数据总量:获取数据库的用户对象,使用len()方法即可同理用户数量。
最高学历:创建一个educations = {"博士": 1, "硕士": 2, "本科": 3, "大专": 4, "高中": 5, "中专/中技": 6, "初中及以下":7,"学历不限": 8}字典,educations[job.educational]<educations[educationsTop]: educationsTop = job.educational对工作数据库的工作经行遍历,创建的educations 字典[工作学历]可以得到所创字典的value数值,用此来和每一个工作表里的工作条目的学历经行比较,找到最大的value数值也即对应所创字典最高的学历,最后就在前端使用django模板语法{{ 最高学历的变量 }}即可。
优势地点:if address.get(job.address,-1) == -1:address[job.address] = 1
else:address[job.address] += 1对job的对象的地址和经验进行计数,如果job对象的地址和经验在字典中不存在,则将其添加到字典中并赋值为1;如果已存在,则将其对应的值加1,这样便可得到如下形式{“地点a”:数值1,“地点b”:数值2.等等}然后调用内置的items()方法将其返回字典的所有键值对,最后addressStr=sorted(address.items(),key=lambda x:x[1],reverse=True)[:3]对其数值经行降序排列且切片到前3个地址并将其连接表示赋值给一个addressstr变量最后在前端规划写入django模板语法{{ addressstr }}即可,最高多薪以及岗位性质同理。
最高薪资:遍历工作表的每一个工资经行对比,找出最高的赋值即可。
3.3.6:首页的数据表格展示:
Jobs=JobInfo.objects.all(),对jobs经行遍历得到每一个job,在前端页面的tbale里经行数据渲染,但对于工资数据表里的是[xk,xk]我们这里要显示的是最高工资每月,所以job.salary = json.loads(i.salary)[1]用json的loads方法把字典里的字符串转换为python对象然后拿到后面(最高工资值)即可,是否实习也要经行个简单处理,因为我们数据库放的是0或者1来表示是否实习的,这里我们只需要做个if else语句即可,以及人数,我们数据库使用[a,b]来表示的,这里我们要展示为a人-b人, json.loads(i.companyPeople)把数据库的属性人数的值拿过来转换python对象,i.companyPeople = list(map(lambda x:str(x) + '人',然后再使用'-'.join(i.companyPeople)把列表里的的两个数用-号连接,便可得到需要的结果形式。
3.4:个人中心:
3.4.1:个人中心-个人信息:
学历,工作经验以及意向岗位选择下拉框的实现是在select标签里循环数据库的学历,工作经验以及岗位类型字段对呀的值,用for 循环来遍历 educations 列表中的每一个元素 e,并使用 if 和 else 语句来判断当前遍历到的元素是否等于 userInfo.educational,如果等于则输出一个选中状态的 option 标签,否则输出一个普通的 option 标签。其中 educations 和 userInfo.educational 都是从后端传递到前端的数据。这段代码的作用是生成一个下拉框,让用户可以选择自己的教育程度。其中educations列表为我们定义的educations 列表= ["博士","硕士","本科","大专","高中","中专/中技","学历不限"]
userInfo.educationa为数据库的学历字段对应的内容值,工作经验和意向岗位选取原理同上。
图片的选取是调用了前端的文件input type=“file”
然后接着便是提交form表单执行后端视图的post方法调用修改信息函数,该函数接受两个参数newInfo和FileInfo,其中newInfo是一个字典,包含用户的新个人信息,FileInfo是一个字典,包含用户上传的文件信息。该函数使用Django框架中的ORM(对象关系映射)方式来更新用户的个人信息。具体地说,它首先通过get方法从数据库中获取指定用户名的User对象,然后更新该对象的educational、workExpirence、address和work属性。如果FileInfo中的avatar属性不为None,则将其设置为该User对象的avatar属性。最后,使用save方法将更新后的User对象保存回数据库。
3.4.2:个人中心-修改密码:
原理同上.
3.5可视化图标-
3.5.1:薪资情况:
遍历所有非实习的工作,将其岗位类型添加到jobsType里,将其薪资信息中的第二项加入到 jobsType 中对应类型的列表中。形式为{Java:[1,2,4,3]}这里列表的内容是java的各个工资合集
接着,代码创建了一个空字典 barData,并遍历 jobsType 中的每个类型,将其薪资列表按照一定区间进行分组,并统计各个区间的数量,将结果存储在 barData 中。最后,代码返回 salaryList、barData 和 barData 的键列表。此时barData形式为{java:[1,2,3,4]}此时列表的内容为不同薪资段的人数。
然后引入echars,在js代码的series: [ {% for k,v in barData.items %}
{ name: '{{ k }}', type: 'bar', data: {{ v }}, }, {% endfor %}]即可展现效果,其中的鼠标悬停的动态效果是tooltip字段。
输入框的选择筛选根据前端页面的option的选择将值传入后端,然后对数据库的工作岗位的每一个对象内容经行object。fillter(筛选条件)即可获取需要的数据然后用前面所说的echars展示即可。
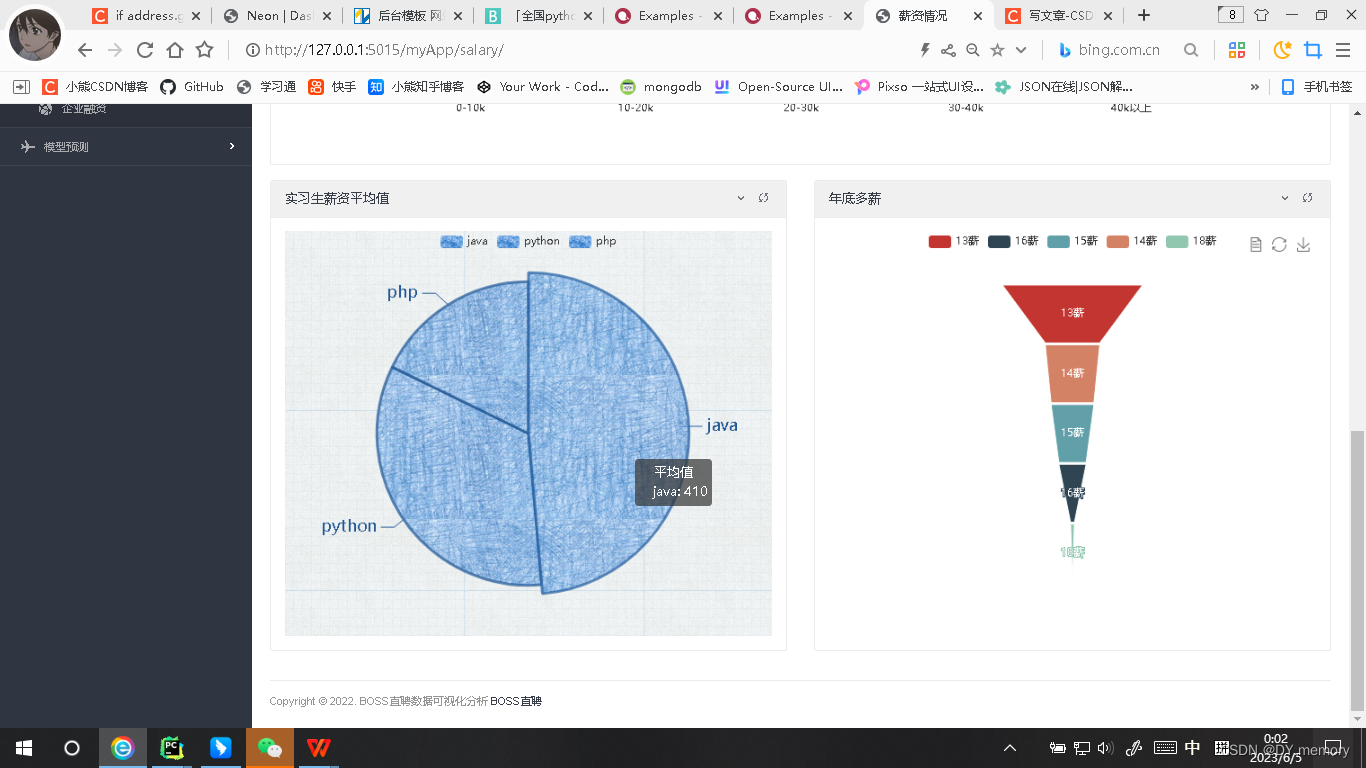
实习生薪资平均值饼图数据展示:使用Django 的 ORM 模块从数据库中获取 JobInfo 对象的所有实例。然后,它创建一个空字典 jobsType 用于存储每种工作类型以及对应的月平均工资,并遍历所有工作信息,筛选出实习经验(pratice=1(实习))的工作信息,并将它们的月平均工资添加到 jobsType 中。
接着创建一个空列表 result,用于存储每种工作类型的月平均工资的总和,然后遍历 jobsType 中的每个键值对,用 自定义的addLis函数(求平均)函数将该工作类型的月平均工资求和。最后,将每种工作类型的名称和月平均工资总和添加到 result 中,并将 result 返回。此时result形式为[{工作类型:该类型薪资均值}]最后在前端的js代码的series将其写入即可。
至于多薪图标的展示,处理JobInfo的对象,筛选出薪资月份数量大于 0 的工作信息,并统计每种薪资月份的数量,返回一个列表和一个字典。其中,列表包含所有薪资月份的字符串,字典包含每种薪资月份及其对应数量的键值对。然后在引入的echars的series列表的data字段设置 {{ louDouData | safe}}即可。
后问部分篇幅略.......................................................................................................................
代码(一小小小部分)就当走个代码量吧,不然博客不好通过热门:
数据库创建:
- from django.db import models
-
- # Create your models here.
-
- class JobInfo(models.Model):
- id = models.AutoField('id',primary_key=True)
- title = models.CharField('工作名',max_length=255,default='')
- address = models.CharField('地址',max_length=255,default='')
- type = models.CharField('类型',max_length=255,default='')
- educational = models.CharField('学历',max_length=255,default='')
- workExperience = models.CharField('工作经验',max_length=255,default='')
- workTag = models.CharField('工作标签',max_length=2555,default='')
- salary = models.CharField('薪资',max_length=255,default='')
- salaryMonth = models.CharField('年终奖',max_length=255,default='')
- companyTags = models.CharField('公司标签',max_length=2555,default='')
- hrWork = models.CharField('人事职位',max_length=255,default='')
- hrName = models.CharField('人事名字',max_length=255,default='')
- pratice = models.BooleanField('是否为实习单位',max_length=255,default='')
- companyTitle = models.CharField('公司名称',max_length=255,default='')
- companyAvatar = models.CharField('公司头像',max_length=255,default='')
- companyNature = models.CharField('公司性质',max_length=255,default='')
- companyStatus = models.CharField('公司状态',max_length=255,default='')
- companyPeople = models.CharField('公司人数',max_length=255,default='')
- detailUrl = models.CharField('详情地址',max_length=2555,default='')
- companyUrl = models.CharField('公司详情地址',max_length=2555,default='')
- createTime = models.DateField('创建时间',auto_now_add=True)
- dist = models.CharField('行政区',max_length=255,default='')
- class Meta:
- db_table = "jobInfo"
-
- class User(models.Model):
- id = models.AutoField('id',primary_key=True)
- username = models.CharField('用户名',max_length=255,default='')
- password = models.CharField('密码',max_length=255,default='')
- educational = models.CharField('学历',max_length=255,default='')
- workExpirence = models.CharField('工作经验',max_length=255,default='')
- address = models.CharField('意向城市',max_length=255,default='')
- work = models.CharField('意向岗位',max_length=255,default='')
- avatar = models.FileField("用户头像",upload_to="avatar",default="avatar/default.png")
- createTime = models.DateField("创建时间",auto_now_add=True)
-
- class Meta:
- db_table = "user"
-
- class History(models.Model):
- id = models.AutoField('id',primary_key=True)
- job = models.ForeignKey(JobInfo,on_delete=models.CASCADE)
- user = models.ForeignKey(User,on_delete=models.CASCADE)
- count = models.IntegerField("点击次数",default=1)
- class Meta:
- db_table = "histroy"
-

爬虫代码:
- import json
- import time
- from selenium import webdriver
- from selenium.webdriver.chrome.service import Service
- from selenium.webdriver.common.by import By
- import csv
- import pandas as pd
- import os
- import django
- os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'boss直聘数据可视化分析.settings')
- django.setup()
- # 但是还是需要在文件开头添加两行配置环境变量的配置语句,让程序知道该去哪儿寻找 models 中的文件。
- from myApp.models import *
-
- class spider(object):
- def __init__(self,type,page):
- self.type = type
- self.page = page
- self.spiderUrl = "https://www.zhipin.com/web/geek/job?query=%s&city=100010000&page=%s"
-
- def startBrower(self):
- option = webdriver.ChromeOptions()
- # option.add_experimental_option("debuggerAddress", "localhost:9222")
- option.add_experimental_option("excludeSwitches", ['enable-automation'])
- # s = Service("./chromedriver.exe")
- # browser = webdriver.Chrome(service=s, options=option)
- browser=webdriver.Chrome(executable_path='./chromedriver.exe',options=option)
- return browser
-
- def main(self,**info):
- if info['page'] < self.page:return
- brower = self.startBrower()
- print('页表页面URL:' + self.spiderUrl % (self.type,self.page))
- brower.get(self.spiderUrl % (self.type,self.page))
- time.sleep(15)
- # return
- job_list = brower.find_elements(by=By.XPATH, value="//ul[@class='job-list-box']/li")
- for index,job in enumerate(job_list):
- try:
- print("爬取的是第 %d 条" % (index + 1))
- jobData = []
- # title 工作名字
- title = job.find_element(by=By.XPATH,
- value=".//div[contains(@class,'job-title')]/span[@class='job-name']").text
- # address 地址
- addresses = job.find_element(by=By.XPATH,
- value=".//div[contains(@class,'job-title')]//span[@class='job-area']").text.split(
- '·')
- address = addresses[0]
- # dist 行政区
- if len(addresses) != 1:dist = addresses[1]
- else: dist = ''
- # type 工作类型
- type = self.type
-
- tag_list = job.find_elements(by=By.XPATH,
- value=".//div[contains(@class,'job-info')]/ul[@class='tag-list']/li")
- if len(tag_list) == 2:
- educational = job.find_element(by=By.XPATH,
- value=".//div[contains(@class,'job-info')]/ul[@class='tag-list']/li[2]").text
- workExperience = job.find_element(by=By.XPATH,
- value=".//div[contains(@class,'job-info')]/ul[@class='tag-list']/li[1]").text
- else:
- educational = job.find_element(by=By.XPATH,
- value=".//div[contains(@class,'job-info')]/ul[@class='tag-list']/li[3]").text
- workExperience = job.find_element(by=By.XPATH,
- value=".//div[contains(@class,'job-info')]/ul[@class='tag-list']/li[2]").text
- # hr
- hrWork = job.find_element(by=By.XPATH,
- value=".//div[contains(@class,'job-info')]/div[@class='info-public']/em").text
- hrName = job.find_element(by=By.XPATH,
- value=".//div[contains(@class,'job-info')]/div[@class='info-public']").text
-
- # workTag 工作标签
- workTag = job.find_elements(by=By.XPATH,
- value="./div[contains(@class,'job-card-footer')]/ul[@class='tag-list']/li")
- workTag = json.dumps(list(map(lambda x: x.text, workTag)))
-
- # salary 薪资
- salaries = job.find_element(by=By.XPATH,
- value=".//div[contains(@class,'job-info')]/span[@class='salary']").text
- # 是否为实习单位
- pratice = 0
- if salaries.find('K') != -1:
- salaries = salaries.split('·')
- if len(salaries) == 1:
- salary = list(map(lambda x: int(x) * 1000, salaries[0].replace('K', '').split('-')))
- salaryMonth = '0薪'
- else:
- # salaryMonth 年底多薪
- salary = list(map(lambda x: int(x) * 1000, salaries[0].replace('K', '').split('-')))
- salaryMonth = salaries[1]
- else:
- salary = list(map(lambda x: int(x), salaries.replace('元/天', '').split('-')))
- salaryMonth = '0薪'
- pratice = 1
-
- # companyTitle 公司名称
- companyTitle = job.find_element(by=By.XPATH, value=".//h3[@class='company-name']/a").text
- # companyAvatar 公司头像
- companyAvatar = job.find_element(by=By.XPATH,
- value=".//div[contains(@class,'job-card-right')]//img").get_attribute(
- "src")
- companyInfoList = job.find_elements(by=By.XPATH,
- value=".//div[contains(@class,'job-card-right')]//ul[@class='company-tag-list']/li")
- if len(companyInfoList) == 3:
- companyNature = job.find_element(by=By.XPATH,
- value=".//div[contains(@class,'job-card-right')]//ul[@class='company-tag-list']/li[1]").text
- companyStatus = job.find_element(by=By.XPATH,
- value=".//div[contains(@class,'job-card-right')]//ul[@class='company-tag-list']/li[2]").text
- try:
- companyPeople = list(map(lambda x: int(x), job.find_element(by=By.XPATH,
- value=".//div[contains(@class,'job-card-right')]//ul[@class='company-tag-list']/li[3]").text.replace(
- '人', '').split('-')))
- except:
- companyPeople = [0, 10000]
- else:
- companyNature = job.find_element(by=By.XPATH,
- value=".//div[contains(@class,'job-card-right')]//ul[@class='company-tag-list']/li[1]").text
- companyStatus = "未融资"
- try:
- companyPeople = list(map(lambda x: int(x), job.find_element(by=By.XPATH,
- value=".//div[contains(@class,'job-card-right')]//ul[@class='company-tag-list']/li[2]").text.replace(
- '人', '').split('-')))
- except:
- companyPeople = [0, 10000]
- # companyTag 公司标签
- companyTag = job.find_element(by=By.XPATH,
- value="./div[contains(@class,'job-card-footer')]/div[@class='info-desc']").text
- if companyTag:
- companyTag = json.dumps(companyTag.split(','))
-
- else:
- companyTag = '无'
-
- # 详情地址
- detailUrl = job.find_element(by=By.XPATH,
- value="./div[@class='job-card-body clearfix']/a").get_attribute('href')
- # 公司详情
- companyUrl = job.find_element(by=By.XPATH, value="//h3[@class='company-name']/a").get_attribute('href')
-
- jobData.append(title)
- jobData.append(address)
- jobData.append(type)
- jobData.append(educational)
- jobData.append(workExperience)
- jobData.append(workTag)
- jobData.append(salary)
- jobData.append(salaryMonth)
- jobData.append(companyTag)
- jobData.append(hrWork)
- jobData.append(hrName)
- jobData.append(pratice)
- jobData.append(companyTitle)
- jobData.append(companyAvatar)
- jobData.append(companyNature)
- jobData.append(companyStatus)
- jobData.append(companyPeople)
- jobData.append(detailUrl)
- jobData.append(companyUrl)
- jobData.append(dist)
-
- self.save_to_csv(jobData)
- except:
- pass
-
- self.page += 1
- self.main(page=info['page'])
-
- def save_to_csv(self,rowData):
- with open('./temp.csv', 'a', newline='', encoding='utf-8') as f:
- writer = csv.writer(f)
- writer.writerow(rowData)
-
- def clear_numTemp(self):
- with open('./numTemp.txt','w',encoding='utf-8') as f:
- f.write('')
-
- def init(self):
- if not os.path.exists('./temp.csv'):
- with open('./temp.csv','a',newline='',encoding='utf-8') as f:
- writer = csv.writer(f)
- writer.writerow(["title","address","type","educational","workExperience","workTag","salary","salaryMonth",
- "companyTags","hrWork","hrName","pratice","companyTitle","companyAvatar","companyNature",
- "companyStatus","companyPeople","detailUrl","companyUrl","dist"])
-
- def save_to_sql(self):
- data = self.clearData()
- for job in data:
- JobInfo.objects.create(
- title=job[0],
- address = job[1],
- type = job[2],
- educational = job[3],
- workExperience = job[4],
- workTag = job[5],
- salary = job[6],
- salaryMonth = job[7],
- companyTags = job[8],
- hrWork = job[9],
- hrName = job[10],
- pratice = job[11],
- companyTitle = job[12],
- companyAvatar = job[13],
- companyNature = job[14],
- companyStatus = job[15],
- companyPeople = job[16],
- detailUrl = job[17],
- companyUrl = job[18],
- dist=job[19]
- )
- print("导入数据库成功")
- os.remove("./temp.csv")
-
- def clearData(self):
- df = pd.read_csv('./temp.csv')
- df.dropna(inplace=True)
- df.drop_duplicates(inplace=True)
- df['salaryMonth'] = df['salaryMonth'].map(lambda x:x.replace('薪',''))
- print("总条数为%d" % df.shape[0])
- return df.values
-
- if __name__ == '__main__':
- spiderObj = spider("go",1);
- spiderObj.init()
- spiderObj.main(page=10)
- spiderObj.save_to_sql()
首页后台函数:
- from myApp.models import User,JobInfo
- from .publicData import *
- import time
- import json
- # 首页时间+欢迎语
- def getNowTime():
- timeFormat = time.localtime()
- year = timeFormat.tm_year
- month = timeFormat.tm_mon
- day = timeFormat.tm_mday
- monthList = ["January","February","March","April","May","June","July","August","September","October","November","December"]
- return year,monthList[month - 1],day
-
- # 首页右侧7指标
- def getTagData():
- jobs = getAllJobInfo()
- users = getAllUser()
- educationsTop = "学历不限"
- salaryTop = 0
- salaryMonthTop = 0
- address = {}
- pratice = {}
- for job in jobs:
- if educations[job.educational] < educations[educationsTop]:
- educationsTop = job.educational
- # 仅仅针对非实习岗位
- if not job.pratice:
- salary = json.loads(job.salary)[1]
- if salaryTop < salary:
- salaryTop = salary
- if int(job.salaryMonth) > salaryMonthTop:
- salaryMonthTop = int(job.salaryMonth)
- # 这段代码的作用是判断一个字典 address 中是否包含 key 为 job.address 的元素。
- # 如果不包含,则向字典中添加一个 key 为 job.address,value 为 1 的元素。如果包含,则不进行任何操作。
- if address.get(job.address,-1) == -1:
- address[job.address] = 1
- else:
- address[job.address] += 1
- if pratice.get(job.pratice,-1) == -1:
- pratice[job.pratice] = 1
- else:
- pratice[job.pratice] += 1
- addressStr = sorted(address.items(),key=lambda x:x[1],reverse=True)[:3]
- addressTop = ""
- for i in addressStr:
- addressTop += i[0] + ","
- praticeMax = sorted(pratice.items(),key=lambda x:x[1],reverse=True)
- # a = "普通岗位" ? praticeMax[0][0] == False : "实习岗位"
- return len(jobs),len(users),educationsTop,salaryTop,salaryMonthTop,addressTop,praticeMax[0][0]
-
- def getUserCreateTime():
- users = getAllUser()
- data = {}
- for u in users:
- if data.get(str(u.createTime),-1) == -1:
- data[str(u.createTime)] = 1
- else:
- data[str(u.createTime)] += 1
- result = []
- for k,v in data.items():
- result.append({
- 'name':k,
- 'value':v
- })
- return result
-
- def getUserTop5():
- users = getAllUser()
- def sort_fn(item):
- return time.mktime(time.strptime(str(item.createTime),'%Y-%m-%d'))
- users = list(sorted(users,key=sort_fn,reverse=True))[:6]
- return users
-
- def getAllJobsPBar():
- jobs = getAllJobInfo()
- tempData = {}
- for job in jobs:
- if tempData.get(str(job.createTime),-1) == -1:
- tempData[str(job.createTime)] = 1
- else:
- tempData[str(job.createTime)] += 1
- def sort_fn(item):
- item = list(item)
- return time.mktime(time.strptime(str(item[0]), '%Y-%m-%d'))
- result = list(sorted(tempData.items(),key=sort_fn,reverse=False))
- def map_fn(item):
- item = list(item)
- item.append(round(item[1] / len(jobs),3))
- return item
- result = list(map(map_fn,result))
- return result
-
- def getTableData():
- jobs = getAllJobInfo()
- for i in jobs:
- i.workTag = '/'.join(json.loads(i.workTag))
- if i.companyTags != "无":
- i.companyTags = '/'.join(json.loads(i.companyTags))
-
- i.companyPeople = json.loads(i.companyPeople)
- i.companyPeople = list(map(lambda x:str(x) + '人',i.companyPeople))
- i.companyPeople = '-'.join(i.companyPeople)
- i.salary = json.loads(i.salary)[1]
- return jobs
- # jobs[0].workTags = '/'.join(json.loads(jobs[0].workTag))
- # def map_fn(item):
- # item.workTag = "/".join()
- # jobs = list(map(map_fn,jobs))
-
-
说明:由于代码量较多,详细介绍流程会占用不少时间和篇幅,项目对应的word文档我已经全部写好了,需要的话我会把项目文件包含word文档说明一起打包给你们的,另外如果那么跑不出来,我可以远程给你们操作,确保你们都能跑出来的。

