
热门标签
热门文章
- 1C和C++相互调用 error LNK2001: unresolved external symbol_c++unresolved什么意思
- 2利用低代码从0到1开发一款小程序_小程序低代码
- 3Claude 2 解读 ChatGPT 4 的技术秘密:细节:参数数量、架构、基础设施、训练数据集、成本_gpt-4的层数和训练参数
- 4使用org.apache.commons.io.FileUtils,IOUtils;工具类操作文件
- 5shell命令-find常用命令_shell find -exec
- 6Gradle 安装和配置教程_gradle-8.3-bin.zip放哪个位置
- 7《最长的一帧》理解01_场景渲染
- 8负载均衡_用户将请求发送给负载均衡
- 9Apriori算法中使用Hash树进行支持度计数_hash树在apriori算法中的作用
- 10glance服务器上传的镜像支持,openstack-理解glance组件和镜像服务
当前位置: article > 正文
torchtext 0.12 中文语料加载_build_vocab_from_iterator
作者:花生_TL007 | 2024-04-06 14:43:36
赞
踩
build_vocab_from_iterator
前言
蛮久前写过一篇torchtext加载数据,不过官方不久前升级了torchtext,移除了蛮多东西。数据加载也和之前不一样了。
看官方文档,似乎更推荐用torchdata装载数据,不过本文还是先用dataset做。
由于现在网上都没什么新版本教程,一个人看文档摸索的,有错请谅解
……
数据集准备
数据集随意,选用了自己常用的数据集作为例子。基本就如图所示:
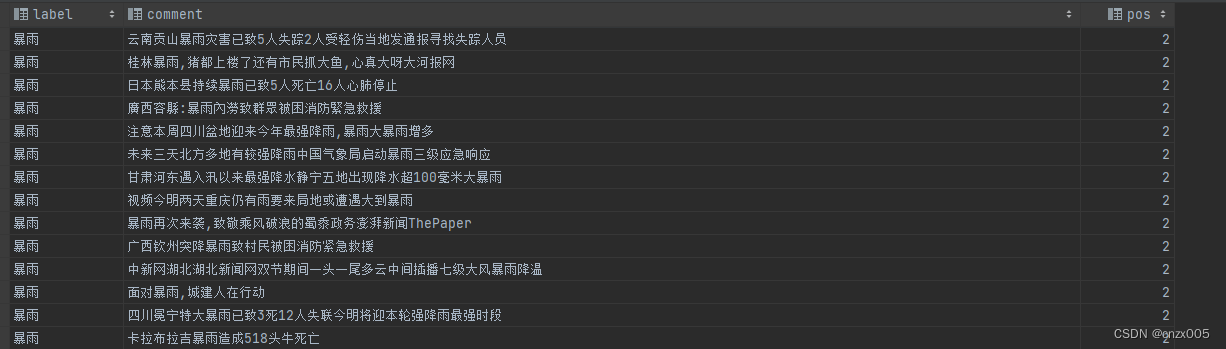
torchtext流程
新版本将之前的Field, TabularDataset,BucketIterator都删去了,流程略有不同。
词表装载
build_vocab_from_iterator 在 torchtext 中建立词表序列
主要参数如下
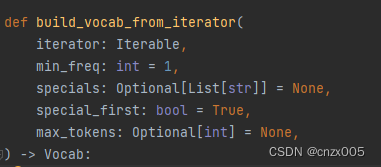
iterator 接受组成词表的迭代器
min_freq 是构成词表的最小频率
specials 是特殊词表符号
import pandas as pd import pkuseg from torchtext.vocab import build_vocab_from_iterator seg = pkuseg.pkuseg() def tokenizer(text): return seg.cut(text) def yield_tokens(data_iter): for _, text in data_iter.iterrows(): yield tokenizer(text['comment']) train_iter = pd.read_csv('./data/news_train.csv') vocab = build_vocab_from_iterator(yield_tokens(train_iter), min_freq=5, specials=['<unk>', '<pad>']) vocab.set_default_index(vocab["<unk>"])

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
dataloder
看了官方上的实例,先用dataset装载数据(我猜)
class TextCNNDataSet(Dataset):
def __init__(self, data, data_targets):
self.content = data
self.pos = data_targets
def __getitem__(self, index):
return self.content[index], self.pos[index]
def __len__(self):
return len(self.pos)
train_iter = TextCNNDataSet(list(train_iter['comment']), list(train_iter['pos']))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
然后用dataloder装载dataset数据
train_loader = DataLoader(train_iter, batch_size=8, shuffle=True, collate_fn=collate_batch)
- 1
collate_batch 为自定义的处理数据函数
def collate_batch(batch): label_list, text_list = [], [] truncate = Truncate(max_seq_len=20) # 截断 pad = PadTransform(max_length=20, pad_value=vocab['<pad>']) for (_text, _label) in batch: label_list.append(label_pipeline(_label)) text = text_pipeline(_text) text = truncate(text) text = torch.tensor(text, dtype=torch.int64) text = pad(text) text_list.append(text) label_list = torch.tensor(label_list, dtype=torch.int64) text_list = torch.vstack(text_list) return label_list.to(device), text_list.to(device)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
Truncate , PadTransform 分别为 torchtext 中 截断 与 填充 的函数
试着跑一下
for i, batch in enumerate(train_loader):
pos, content = batch[0], batch[1]
print(pos)
print(content)
- 1
- 2
- 3
- 4
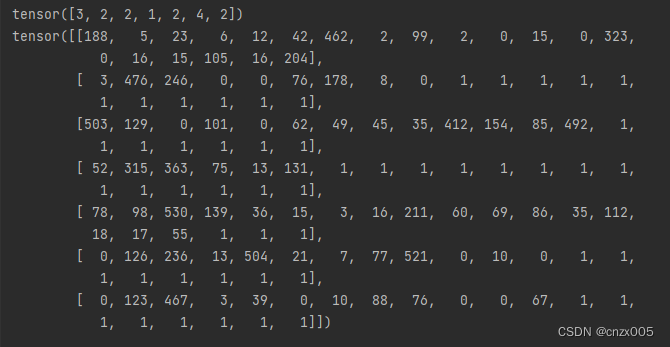
装载完成
后续
可能之后会用torchdata试一下torchtext,也可能不会,torchtext更新感觉跨度好大,指不定下次又更新什么,又得重新写了
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/花生_TL007/article/detail/372566
推荐阅读
相关标签

