
- 1FPGA时钟资源详解(1)——时钟Buffer的选择
- 2鸿蒙原生应用/元服务开发-代理提醒说明(一)
- 3upload-labs通关
- 4Centos7用户管理_在centos7中用户分为哪几种
- 5【机器学习】:脑电数据时域特征提取_mne.io.read_epochs_eeglab
- 6实现字符串的拷贝_实现字符串的拷贝。 void my_strcpy(char * destination,char *
- 7Flutter 数据存储 SharedPreferences_flutter sharedpreferences
- 8鸿蒙HarmonyOS实战-ArkUI组件(Button)_鸿蒙 button
- 9MySQL的zerofill 零填充_mysql中zerofill什么意思
- 10【附源码+论文】基于微信小程序的毕业设计——排课管理系统_网上选排课毕业论文
数据湖概念_数据湖用什么数据库
赞
踩
1.什么是数据湖
数据湖是一个集中式的存储库,允许你以任意规模存储多个来源、所有结构化和非结构化数据,可以按照原样存储数据,无需对数据进行结构化处理,并运行不同类型的分析对数据进行加工,以指导做出更好地决策。
Wikipedia 定义:
数据湖是一类存储数据自然/原始格式的系统或存储,通常是对象块或者文件。数据湖通常是企业中全量数据的单一存储。全量数据包括原始系统所产生的原始数据拷贝以及为了各类任务而产生的转换数据,各类任务包括报表、可视化、高级分析和机器学习。数据湖中包括来自于关系型数据库中的结构化数据(行和列)、半结构化数据(如 CSV、日志、XML、JSON)、非结构化数据(如 email、文档、PDF 等)和二进制数据(如图像、音频、视频)。数据沼泽是一种退化的、缺乏管理的数据湖,数据沼泽对于用户来说要么是不可访问的要么就是无法提供足够的价值。
关于数据湖的定义其实很多,但是基本上都围绕着以下几个特性展开:
- 数据湖需要提供足够用的数据存储能力,保存企业/组织中的所有数据。
- 数据湖可以存储海量的任意类型的数据,包括结构化、半结构化和非结构化数据。
- 数据湖中的数据是原始数据。
- 数据湖需要具备完善的数据管理能力(完善的元数据),可以管理各类数据相关的要素,包括数据源、数据格式、连接信息、数据 schema、权限管理等。
- 数据湖需要具备多样化的分析能力,包括但不限于批处理、流式计算、交互式分析以及机器学习;同时,还需要提供一定的任务调度和管理能力。
- 数据湖需要具备完善的数据生命周期管理能力。不光需要存储原始数据,还需要能够保存各类分析处理的中间结果,并完整的记录数据的分析处理过程,能帮助用户完整详细追溯任意一条数据的产生过程。
- 数据湖需要具备完善的数据获取和数据发布能力。数据湖需要能支撑各种各样的数据源,并能从相关的数据源中获取全量/增量数据;然后规范存储。数据湖能将数据分析处理的结果推送到合适的存储引擎中,满足不同的应用访问需求。
- 对于大数据的支持,包括超大规模存储以及可扩展的大规模数据处理能力。
综上,个人认为数据湖应该是一种不断演进中、可扩展的大数据存储、处理、分析的基础设施;以数据为导向,实现任意来源、任意速度、任意规模、任意类型数据的全量获取、全量存储、多模式处理与全生命周期管理;并通过与各类外部异构数据源的交互集成,支持各类企业级应用。

这里需要再特别指出两点:
可扩展是指规模的可扩展和能力的可扩展,即数据湖不但要能够随着数据量的增大,提供“足够”的存储和计算能力;还需要根据需要不断提供新的数据处理模式,例如可能一开始业务只需要批处理能力,但随着业务的发展,可能需要交互式的即席分析能力;又随着业务的实效性要求不断提升,可能需要支持实时分析和机器学习等丰富的能力。
以数据为导向,是指数据湖对于用户来说要足够的简单、易用,帮助用户从复杂的 IT 基础设施运维工作中解脱出来,关注业务、关注模型、关注算法、关注数据。数据湖面向的是数据科学家、分析师。
AWS定义数据湖:
1.什么是数据湖?
数据湖是一个集中式存储库,允许您以任意规模存储所有结构化和非结构化数据。您可以按原样存储数据(无需先对数据进行结构化处理),并运行不同类型的分析 – 从控制面板和可视化到大数据处理、实时分析和机器学习,以指导做出更好的决策。
2.为什么需要数据湖?
领导者能够进行新类型的分析,例如通过日志文件、来自点击流的数据、社交媒体以及存储在数据湖中的互联网连接设备等新来源的机器学习。这有助于他们通过吸引和留住客户、提高生产力、主动维护设备以及做出明智的决策来更快地识别和应对业务增长机会。
3.数据湖和分析解决方案的基本要素
组织构建数据湖和分析平台时,他们需要考虑许多关键功能,包括:
数据移动
数据湖允许您导入任何数量的实时获得的数据。
安全地存储和编目数据
数据湖允许您存储关系数据和非关系数据。最后,必须保护数据以确保您的数据资产受到保护。
分析
数据湖允许组织中的各种角色(如数据科学家、数据开发人员和业务分析师)通过各自选择的分析工具和框架来访问数据。这包括 Apache Hadoop、Presto 和 Apache Spark 等开源框架,以及数据仓库和商业智能供应商提供的商业产品。数据湖允许您运行分析,而无需将数据移至单独的分析系统。
机器学习
数据湖将允许组织生成不同类型的见解,包括报告历史数据以及进行机器学习(构建模型以预测可能的结果),并建议一系列规定的行动以实现最佳结果。
4.数据湖的价值
能够在更短的时间内从更多来源利用更多数据,并使用户能够以不同方式协同处理和分析数据,从而做出更好、更快的决策。数据湖具有增值价值的示例包括:
改善客户互动
数据湖可以将来自 CRM 平台的客户数据与社交媒体分析相结合,有一个包括购买历史记录和事故单的营销平台,使企业能够了解最有利可图的客户群、客户流失的原因以及将提升忠诚度的促销活动或奖励。
改善研发创新选择
数据湖可以帮助您的研发团队测试其假设,改进假设并评估结果 – 例如在产品设计中选择正确的材料从而提高性能,进行基因组研究从而获得更有效的药物,或者了解客户为不同属性付费的意愿。
提高运营效率
物联网 (IoT) 引入了更多方式来收集有关制造等流程的数据,包括来自互联网连接设备的实时数据。使用数据湖,可以轻松地存储,并对机器生成的 IoT 数据进行分析,以发现降低运营成本和提高质量的方法。
5.数据湖的挑战
数据湖架构的主要挑战是存储原始数据而不监督内容。对于使数据可用的数据湖,它需要有定义的机制来编目和保护数据。没有这些元素,就无法找到或信任数据,从而导致“数据沼泽”的出现。 满足更广泛受众的需求需要数据湖具有管理、语义一致性和访问控制。
2.数据湖有哪些特征
1. 数据方面的特征
-
“保真性”。数据湖中对于业务系统中的数据都会存储一份“一模一样”的完整拷贝。同时,数据湖应该能够存储任意类型/格式的数据。
-
“灵活性”:上表一个点是 “写入型 schema” v.s.“读取型 schema”,“写入型 schema”背后隐含的逻辑是数据在写入之前,就需要根据业务的访问方式确定数据的 schema,然后按照既定 schema,完成数据导入,带来的好处是数据与业务的良好适配;但是这也意味着数仓的前期拥有成本会比较高,特别是当业务模式不清晰、业务还处于探索阶段时,数仓的灵活性不够。数据湖强调的“读取型 schema”,背后的潜在逻辑则是认为业务的不确定性是常态:我们无法预期业务的变化,那么我们就保持一定的灵活性,将设计去延后。
-
“可管理”:数据湖应该提供完善的数据管理能力。数据湖中会存在两类数据:原始数据和处理后的数据。数据湖中的数据会不断的积累、演化。因此,对于数据管理能力也会要求很高,至少应该包含以下数据管理能力:数据源、数据连接、数据格式、数据 schema(库/表/列/行)。同时,数据湖是单个企业/组织中统一的数据存放场所,因此,还需要具有一定的权限管理能力。
-
“可追溯”:数据湖是一个组织/企业中全量数据的存储场所,需要对数据的全生命周期进行管理,包括数据的定义、接入、存储、处理、分析、应用的全过程。一个强大的数据湖实现,需要能做到对其间的任意一条数据的接入、存储、处理、消费过程是可追溯的,能够清楚的重现数据完整的产生过程和流动过程。
2. 计算方面的特征
-
丰富的计算引擎。从批处理、流式计算、交互式分析到机器学习,各类计算引擎都属于数据湖应该囊括的范畴。
-
多模态的存储引擎。理论上,数据湖本身应该内置多模态的存储引擎,以满足不同的应用对于数据访问需求。但是,在实际的使用过程中,数据湖中的数据通常并不会被高频次的访问,而且相关的应用也多在进行探索式的数据应用,为了达到可接受的性价比,数据湖建设通常会选择相对便宜的存储引擎(如 S3/OSS/HDFS/OBS)。
3.为什么需要数据湖
传统的离线数据仓库中对记录级别的数据进行更新是非常麻烦的,需要对待更新的数据所属的整个分区,甚至是整个表进行全面覆盖才行。
根据数仓架构演变过程,在Lambda架构中含有离线处理与实时处理两条链路,其架构图如下:
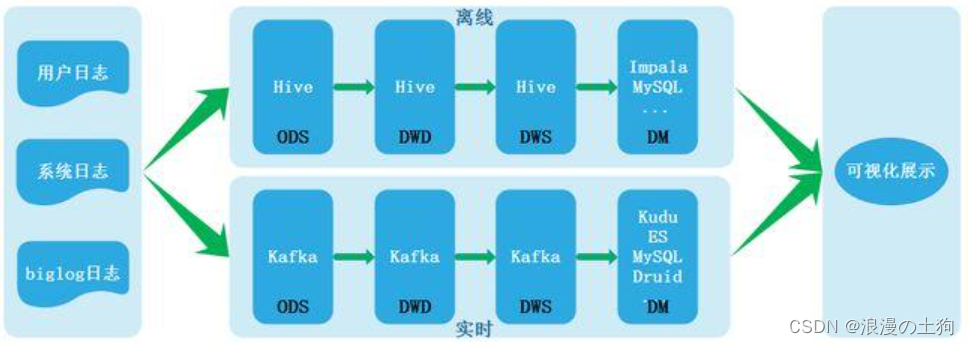
由于两条链路处理数据导致数据不一致等一些列问题所以才有了Kappa架构,Kappa架构如下:
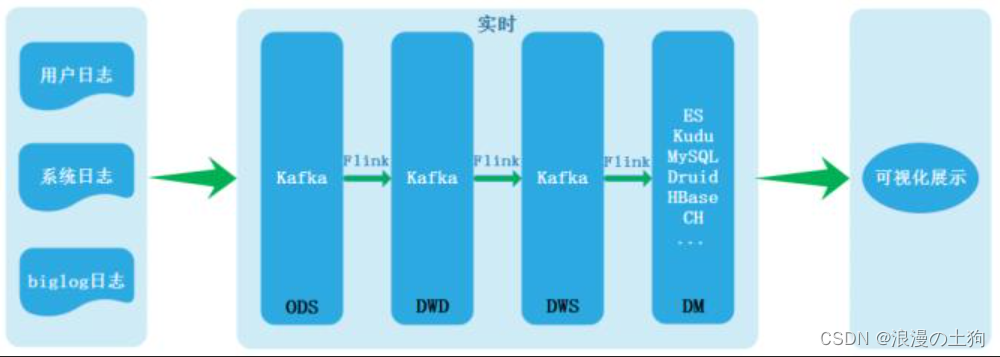
Kappa架构可以称为真正的实时数仓,目前在业界最常用实现就是Flink + Kafka,然而基于Kafka+Flink的实时数仓方案也有几个非常明显的缺陷:
Kafka无法支持海量数据存储。Kafka一般只能存储非常短时间的数据。
Kafka无法支持高效的OLAP查询,Kafka无法支持在DWD\DWS层的即席查询。
无法复用基于离线数仓的数据血缘、数据质量管理体系。
Kafka不支持update/upsert,目前Kafka仅支持append。
为了解决Kappa架构的痛点问题,业界最主流是采用“批流一体”方式,这里批流一体可以理解为批和流使用SQL同一处理,也可以理解为处理框架的统一,例如:Spark、Flink,但这里更重要指的是存储层上的统一,只要存储层面上做到“批流一体”就可以解决以上Kappa遇到的各种问题。数据湖技术可以很好的实现存储层面上的“批流一体”,这就是为什么大数据中需要数据湖的原因。
4.数据湖与数仓的区别
数据仓库与数据湖主要的区别在于如下两点:
-
存储数据类型
数据仓库是存储数据,进行建模,存储的是结构化数据;
数据湖以其本源格式保存大量原始数据,包括结构化的、半结构化的和非结构化的数据,主要是由原始的、混乱的、非结构化的数据组成。
-
数据处理模式
加载到数据仓库中的数据,首先需要定义好它,这叫做写时模式(Schema-On-Write)。
对于数据湖,只需加载原始数据,然后,当您准备使用数据时,就给它一个定义,这叫做读时模式(Schema-On-Read)。数据湖是在数据使用时再定义模型结构,因此提高了数据模型定义的灵活性,可满足更多不同上层业务的高效率分析诉求。
5.数据湖技术架构演进
1.Lambda架构痛点
数据治理成本高:
1.一套离线数据治理体系
2.一套实时数据治理体系
3.二者不能复用
开发维护成本高:
1.同一逻辑需要开发维护两套代码
2.离线数据刷数成本高
数据口径不一致:
1.数据延迟造成口径不一
2.统计时间不同,数据结果不同
2.Kappa架构 痛点
数据回溯能力弱:
1.数仓层级多,链路复杂
2.对接的数据库繁多
OLAP分析能力弱:
1.顺序存储系统OLAP能力弱
2.不支持谓词下推计算
数据时序性问题:
1.多层数仓模型,时序性难以保障
2.消息队列存储成本高
3.大数据架构痛点总结
传统T+1任务:
1.海量的TB级 T+ 1 任务延迟导致下游数据产出时间不稳定
2.任务遇到故障重试恢复代价昂贵
3.数据架构在处理去重和exactly-once语义能力方面比较吃力
4.架构复杂,涉及多个系统协调,靠调度系统来构建任务依赖关系
Lambda架构痛点:
1.同时维护实时平台和离线平台两套引擎,开发成本高
2.维护成本高
3.数据有两条不同链路,容易造成数据的不一致性
4.数据更新成本大,需要重跑8链路
Kappa架构痛点:
1.对消息队列存储要求高,消息队列的回溯能力不及离线存储
2.消息队列本身对数据存储有时效性,且当前无法使用OLAP引警直接分析消息队列中的数据
3.全链路依赖消息队列的实时计算可能因为数据的时序性导致结果不正确
4.实时数仓建设需求
实际上是可以通过对Kappa架构进行升级,以解决Kappa架构中遇到的一些问题,接下来主要分享当前比较火的数据湖技术。
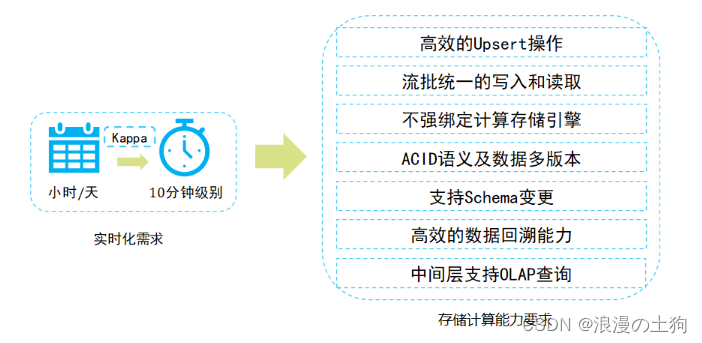
5.数据湖架构
5.1 数据湖理念
数据湖是一个集中式存储库,可以存储结构化和非结构化数据。可以按业务数据的原样存储,并运行不同类型的分析 – 从控制面板和可视化到大数据处理、实时分析和机器学习,以指导做出更好的决策。
一、存储原始数据
1.非结构化数据
2.半结构化数据
3.结构化数据
二、灵活的底层存储
1.大规模数据存储能力
2.多种存储平台
3.多种数据存储格式
4.数据缓存加速
三、丰富的计算引擎
1.实时数据计算引擎
2.批量数据计算引擎
3.交互式数据查询
四、完善的数据治理
1.元数据管理
2.数据生命周期管理
3.数据获取能力
4.数据发布能力
5.2 数据湖架构
LakeHouse是基于存算分离的架构来构建的。数据湖的架构图,主要分为四层:

1 分布式文件系统
第一层是分布式文件系统,对于选择云上技术的用户,通常会选择S3和阿里云;选择开源技术的用户一般采用HDFS。
2 数据加速层
第二层是数据加速层。数据湖架构是一个典型的存储计算分离架构,远程读写的性能损耗非常大。我们常见的做法是,把经常访问的数据(热点数据)缓存在计算节点本地,从而实现数据的冷热分离。这样做的好处是,提高数据的读写性能,节省网络带宽。我们可以选择开源的Alluxio,或者阿里云的Jindofs。
3 Table format 层
第三层是Table format层,把数据文件封装成具有业务含义的表,数据本身提供ACID、snapshot、schema、partition等表级别的语义。
Delta、Iceberg、Hudi是构建数据湖的一种技术,它们本身并不是数据湖。
4 计算引擎
第四层是各种数据计算引擎。
6.从数据仓库看数据湖
1.对比
数据仓库
计划经济,原始信息耗损大,标准化程度高、性能强、共享性强,适合高度结构化的报表和BI
数据湖
市场经济、原始信息耗损低,个性化强,创新性强,适合挖掘、探索和预测
每个公司需要数据仓库和数据湖,因为它们分别满足不同的需要和使用案例:
1.数据仓库是一个优化后的数据库,用于分析来自事务系统和业务线应用系统的关系型数据。事先定义好数据结构和Schema,以便提供快速的SQL查询。原始数据经过一些列的ETL转换,为用户提供可信任的“单一数据结果”。
2.数据湖有所不同,因为它不但存储来自业务线应用系统的关系型数据,还要存储来自移动应用程序、IoT设备和社交媒体的非关系型数据。捕获数据时,不用预先定义好数据结构或Schema。这意味着数据湖可以存储所有类型的数据,而不需要精心设计数据结构。可以对数据使用不同类型的分析方式(如SQL查询、大数据分析、全文搜索、实时分析和机器学习)。
| 特性 | 数据仓库 | 数据湖 |
|---|---|---|
| 数据 | 来自事务系统、运营数据库和业务线应用程序的关系数据 | 来自 IoT 设备、网站、移动应用程序、社交媒体和企业应用程序的非关系和关系数据 |
| Schema | 设计在数据仓库实施之前(写入型 Schema) | 写入在分析时(读取型 Schema |
| 性价比 | 更快查询结果会带来较高存储成本 | 更快查询结果只需较低存储成本 |
| 数据质量 | 可作为重要事实依据的高度监管数据 | 任何可以或无法进行监管的数据(例如原始数据) |
| 用户 | 业务分析师 | 数据科学家、数据开发人员和业务分析师( 使用监管数据) |
| 分析 | 批处理报告、BI 和可视化 | 机器学习、预测分析、数据发现和分析 |
上表介绍了数据湖与传统数据仓库的区别
2.写时模式和读时模式
写时模式
数据仓库的“写入型Schema”背后隐藏的逻辑就是在数据写入之前,必须确认好数据的Schema,然后进行数据导入,这样做的好处是:可以把业务和数据很好的结合在一起;不足就是在业务模式不清晰,还处于探索阶段时,数仓的灵活性不够。
读时模式
数据湖强调的是“读取型Schema”,背后潜在的逻辑是,认为业务的不确定性是常态:既然我们无法预测业务的发展变化,那么我们就保持一定的灵活性。将结构化设计延后,让整个基础设施具备使数据“按需”贴合业务的能力。因此,数据湖更适合发展、创新型企业。
数据湖采用的是灵活,快速的“读时模式”
3.数据湖的架构方案 这套架构可以解决Lambda架构和Kappa架构的痛点问题:
Lambda+Kappa架构痛点:
1.数据治理体系不能复用
2.同时维护实时平台和离线平台两套引擎
3.两条数据链路,容易造成数据不一致
4.离线链路数据更新成本高
5对消息队列存储要求高,消息队列的回溯能力弱
6.无法使用OLAP引擎直接分析消息队列中的数据。
7.数据仓库分层会打乱Kafka数据的时序性。
改进后:
数据湖Iceberg的优势:
1.同一套数据开发、维护、治理体系
2.开放的框架,既独立于上层计算引擎又独立于下层存储。
3.通过Iceberg的Snapshot机制,保证数据读取的ACID。
4.迟到数据可以轻松Merge Into到ceberg表中
5.支持多种数据计算引擎,彻底解决不能对中间结果数据进行0LAP分析的问题。
6.可以实现按分钟粒度直接入库Iceberg
1 解决Kafka存储数据量少的问题
目前所有数据湖基本思路都是基于HDFS之上实现的一个文件管理系统,所以数据体量可以很大。
2 支持OLAP查询
同样数据湖基于HDFS之上实现,只需要当前的OLAP查询引擎做一些适配,就可以对中间层数据进行OLAP查询。
3 数据治理一体化
批流的数据在HDFS、S3等介质上存储之后,就完全可以复用一套相同的数据血缘、数据质量管理体系。
4 流批架构统一
数据湖架构相比Lambad架构来说,schema统一,数据处理逻辑统一,用户不再需要维护两份数据。
5 数据统计口径一致
由于采用统一的流批一体化计算和存储方案,因此数据一致性得到了保证。
4.孰优孰劣 数据湖和数据仓库,不能说谁更好谁更差,大家都有可取之处:

1、湖和仓的元数据无缝打通,互相补充,数据仓库的模型反哺到数据湖(成为原始数据一部分),湖的结构化应用沉淀到数据仓库。
2、统一开发湖和仓,存储在不同系统的数据,可以通过平台进行统一管理。
3、数据湖与数据仓库的数据,根据业务的发展需要决定哪些数据放在数仓,哪些放在数据湖,进而形成湖仓一体化。
4、数据在湖,模型在仓,反复演练转换。

