
- 1DevOps 的分与合_azure devops合并冲突
- 2 那些让程序员崩溃又想笑的程序命名...
- 3‘pyrcc5‘ 不是内部或外部命令,也不是可运行的程序 或批处理文件。_pyrcc5不是内部命令
- 4C++ tuple 的使用
- 5元组中数组_TypeScript 4.0发布,新增可变参数元组类型等
- 63月面试了一个4年的测试,一问三不知,还反怼我..._java面试一问三不知怎么办
- 7大语言模型在金融领域的应用与挑战
- 8python-中文分词词频统计
- 9Untracked Files Prevent Checkout Move or commit them before checkout
- 10【论文解读】GFPGAN:基于生成式面部先验的真实世界盲脸修复_基于生成式人脸先验
论 大模型量化_大模型量化有什么用?
赞
踩
大模型量化的原因
模型部署有一个永恒的目标,让模型的memory usage更少,运行更快。量化(Quantize)既可以减少模型的memory usage(比如,weight的type由FP32转成Int8,可以让memory usage减少到原来的四分之一),又可以使模型运行的更快(比如,整型运算要比浮点型运算快的多),如此优秀。
但是,对量化的约束就是,要保证量化后的性能不变(或者性能损失可以忽略)。量化自然有量化误差(quantization error),量化误差会传播(spread),至于对性能的影响,一般是恶化的。
量化的知识
公式
f ∈ [ f min , f max ] f \in [f_{\text{min}}, f_{\text{max}}] f∈[fmin,fmax], q ∈ [ q min , q max ] q \in [q_{\text{min}}, q_{\text{max}}] q∈[qmin,qmax],于是
q = clip ( round ( f s ) + z , q m i n , q m a x ) q = \text{clip} \left( \text{round}\left(\frac{f}{s} \right) + z , q_{min}, q_{max} \right) q=clip(round(sf)+z,qmin,qmax)
其中,
s
=
f
max
−
f
min
q
max
−
q
min
s = \frac{f_{\text{max}} - f_{\text{min}}}{q_{\text{max}} - q_{\text{min}}}
s=qmax−qminfmax−fmin
z = q min − round ( f min s ) z = q_{\text{min}} - \text{round}\left(\frac{f_{\text{min}}}{s} \right) z=qmin−round(sfmin)
与之对应的Dequantize函数:
f
=
(
q
−
z
)
⋅
s
f = (q - z) \cdot s
f=(q−z)⋅s
大模型量化策略
基本思路
对于 q min q_{\text{min}} qmin 和 q max q_{\text{max}} qmax 的选择,一般先上 int8/uint8,性能可以下探至 int4,性能不行提升到 int16/uint16。如下列表显示 int16/uint16/int8/uint8/int4 的 q q q 的取值范围:
| q q q | q min q_{\text{min}} qmin | q max q_{\text{max}} qmax |
|---|---|---|
| int16 | -32768 | 32767 |
| uint16 | 0 | 65535 |
| int8 | -128 | 127 |
| uint8 | 0 | 255 |
| int4 | -8 | 7 |
统计待量化的变量的数值分布特征,包括histogram、min、max、average、medium等,结合 q q q 的范围选出合适的 f min f_{\text{min}} fmin和 f max f_{\text{max}} fmax,需要用到一些度量量化误差的方法。记待量化的变量的数值集合为 { f i } \{ f_i \} {fi}, u = min ( f i ) u = \min(f_i) u=min(fi), v = max ( f i ) v = \max(f_i) v=max(fi)。
min-max策略
min-max策略的效果不是很好,主要是因为会出现extreme large magnitude value,导致量化精度比较低。
non-symmetric
f min = u , f max = v f_{\text{min}} = u, f_{\text{max}} = v fmin=u,fmax=v
symmetric
f min = − max ( ∣ u ∣ , ∣ v ∣ ) , f max = max ( ∣ u ∣ , ∣ v ∣ ) f_{\text{min}} = -\max(|u|, |v|), f_{\text{max}} = \max(|u|, |v|) fmin=−max(∣u∣,∣v∣),fmax=max(∣u∣,∣v∣)
MMSE策略
带量化的变量的 histogram 作为近似的概率分布,根据后面介绍的算法搜索出若干对 ( f min , f max ) (f_{\text{min}}, f_{\text{max}}) (fmin,fmax)的candidate,计算量化前的原始数据与量化后的数据的 Mean Squared Error 作为 Quantization Error,最终保留量化误差最小的candidate。
搜索算法
- 可以想象出 histogram 的大致样子:两侧frequency低,中间frequency高,类似于正态分布。
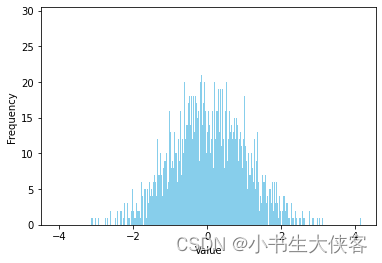
- 主要思路就是,沿着两侧向中间,去除占比少的bin,认为这些bin里的数据是outlier。
- 具体的见如下 pseudocode:
# inputs
import numpy as np
histogram = np.array([...]) # 记录的就是直方图里从左到右的bin的frequency
u, v = ... # 待统计变量的最小值u,和最大值v
# solution
tot_freq = np.sum(histogram) # 待统计变量的数值sample的总个数
n_bins = len(histogram) # bin的总个数
bin_width = (v - u) / n_bins # 每个bin覆盖的数值范围
ratio_thr_lower = 0.0 # 直方图左侧剔除的bin的frequency的占比上限
ratio_thr_upper = 0.0 # 直方图右侧剔除的bin的frequency的占比上限
ratio_step = 1e-5 # 尝试的过程就是不断增加上限值,上限值的增量step
index_bin_lower = 0 # 对于某一次尝试而言,左侧的起始搜索bin的index
index_bin_upper = n_bins - 1 # 对于某一次尝试而言,右侧的起始搜索bin的index
min_quant_error = float("inf") # 最小的量化误差
min_index_bin_lower = 0 # 记录最小的量化误差对应的左侧bin的index
min_index_bin_upper = n_bins - 1 # 记录最小的量化误差对应的右侧bin的index
while index_bin_lower < index_bin_upper:
next_ratio_thr_lower = ratio_thr_lower + ratio_step
next_ratio_thr_upper = ratio_thr_upper + ratio_step
l = index_bin_lower
while l < (n_bins - 1) and np.sum(histogram[:l+1]) < next_ratio_thr_lower * tot_freq:
l = l + 1
r = index_bin_upper
while r > 0 and np.sum(histogram[r:]) < next_ratio_thr_upper * tot_freq:
r = r - 1
if (l - index_bin_lower) > (index_bin_upper - r):
ratio_thr_lower = next_ratio_thr_lower
index_bin_lower = l
else:
ratio_thr_upper = next_ratio_thr_upper
index_bin_upper = r
quant_error = calculate_quant_error(..., index_bin_lower, index_bin_upper, ...) # 使用选择出的新的f_min和f_max去计算
if quant_error < min_quant_error:
min_quant_error = quant_error
min_index_bin_lower = index_bin_lower
min_index_bin_upper = index_bin_upper
else:
break
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47

