
- 1手把手做一个公众号GPT智能客服【二】实现微信公众号回复(订阅送源码!)_微信公众号回复消息接入大模型
- 2一文教你如何在ThinkPHP6中玩转路由,提升开发效率!_thinkphp6路由
- 32023第三届人工智能与机器学习国际学术会议(ICMLAI 2023)_icmlca 2023 收费
- 4Hugging Face——MLM预训练掩码语言模型方法_掩码语言预训练
- 5探索PyTorch的自然语言理解与知识图谱
- 6机器学习技术(三)——机器学习实践案例总体流程_机器学习案例实习
- 7《自然语言处理综论(Speech and Language Processing)》第九章笔记_自然语言处理综论中文版
- 8基于深度学习LSTM+NLP情感分析电影数据爬虫可视化分析推荐系统(深度学习LSTM+机器学习双推荐算法+scrapy爬虫+NLP情感分析+数据分析可视化)_基于lstm的电影推荐系统
- 9文献学习-23-MRM:用于遗传学医学图像预训练的掩码关系建模
- 10OpenCV联通组件扫描
海量数据实时分析引擎 Apache Flink_大数据中间件flink
赞
踩
摘要:当系统出现大量或者重大的错误却不被人感知,将会对业务产生影响,从而导致资产损失。当竞争对手实施了新战术,却无法及时感知,跟不上竞争对手的节奏,总是追着对方尾巴走。当要做决策的时候,海量的业务数据增长却无法实时看到聚合结果,决策总是凭借过往经验或者过时的数据分析之上。
可以看到如果没有数据分析,我们的系统大部分时间处于黑盒状态,对业务的决策也只能凭借过往经验。实时与批量的数据分析可以帮助企业洞察错误,改善服务,进行决策。数据分析也是营销、运维、决策的重要支撑,越来越多的企业和部门已经意识到实时与批量数据的分析价值,开始进行数据分析系统的建设。
而在做数据分析时候要考虑数据的时效性,需要根据场景来选择离线数据分析或者是实时数据分析。
离线数据分析一般是根据固定的周期,比如每天统计一次,每周统计一次等类似于定时任务执行的场景,一般大家称为“批处理” 。
实时数据分析一般基于数据事件,数据产生了就立即处理,数据在源源不断的产生,计算也在不停地运行,就像是一直流动的水流一样经过层层的管道计算处理,一般大家称为”流处理“。
批处理和流处理各有优缺点
批处理更有利于对历史数据,最终数据状态等场景的处理,可有效的计算出比较准确的结果,但是数据分析结果的实时性不太好。批处理的场景:例如我们的微信运动排名、信用卡的月账单等。
流处理的数据实时性是非常好的,数据所见即所得,不过实时的数据分析与计算对资源消耗比较大,如果后续数据发生了改变前期无法计算数据的最终状态。流处理的场景:例如小视频的实时个性化推荐、双十一实时金额的滚动大盘等。
可以看到一般情况下批处理更关注的是海量离线数据的完整性和对海量数据快速计算处理的能力,流处理更关注的是数据的时效性和快速计算处理能力。不过一个完备的大数据批处理和流处理中间件不仅仅需要关注高吞吐量、低延迟这样的基础性能相关的功能,更需要支持状态和故障恢复等高可用的能力 。
Apache Flink 正是一个具备高性能和高可用的批流处理大数据中间件,同时还具备批流一体的处理能力,流处理也在业界处于领先水平。被广大互联网公司使用,下面我们就来进入正题看下关于 Apache Flink 的一些内容吧。
Apache Flink 是什么?
根据官网的介绍:Apache Flink 是一个在有界数据流和无界数据流上进行有状态计算的分布式处理引擎和框架。Flink 设计旨在所有常见的集群环境中运行,以任意规模和内存级速度执行计算。下面两个图是来自官方首页的Flink 批流处理的架构图,可以整体来看一下。


整体来看Flink这样的流批系统主要包含了采集数据(source),处理数据(process),导出数据(sink) 三个部分。采集数据方式包含了实时数据的流处理和历史数据的批处理方式。数据源可以来源于应用、设备、日志,数据库等其他数据,导出数据与导入数据一样可以将数据导出到各种类别的接收数据的服务。除了采集数据和导出数据,Flink中最核心的内容还有中间通过流式计算来处理有状态和无状态的数据这一部分,下面就来看一看。
在 Flink 中,应用程序由用户自定义算子转换而来的流式 dataflows 所组成。这些流式 dataflows 形成了有向图,以一个或多个源(source)开始,并以一个或多个汇(sink)结束,如下图所示。

其中 Flink 的流处理在业界处于领先水平,对于流处理的一些概念有必要再深入了解一下。
流
前面已经简单介绍过流处理的一些概念下面就来看下与流相关的其他名词。
有界和无界的数据流
无界流 有定义流的开始,但没有定义流的结束。它们会无休止地产生数据。无界流的数据必须持续处理,即数据被摄取后需要立刻处理。我们不能等到所有数据都到达再处理。
有界流 有定义流的开始,也有定义流的结束。有界流可以在摄取所有数据后再进行计算。有界流所有数据可以被排序,所以并不需要有序摄取。有界流处理通常被称为批处理。

流可以是无界的,也可以是有界的,例如固定大小的数据集Flink 在无界的数据流处理上拥有诸多功能强大的特性,同时也针对有界的数据流开发了专用的高效算子。
实时和历史记录的数据流
所有的数据都是以流的方式产生,但用户通常会使用两种截然不同的方法处理数据。或是在数据生成时进行实时的处理;亦或是先将数据流持久化到存储系统中——例如文件系统或对象存储,然后再进行批处理。Flink 的应用能够同时支持处理实时以及历史记录数据流。
状态
状态这个词语 ChatGPT 的解释如下:
在计算机科学中,状态是指在特定时间点上,系统或程序的所有变量和值的集合。
Flink 官网是这样解释的如下:
任何运行基本业务逻辑的流处理应用都需要在一定时间内存储所接收的事件或中间结果,以供后续的某个时间点(例如收到下一个事件或者经过一段特定时间)进行访问并进行后续处理。

对于状态管理是非常实用的,一般情况下我们都期望我们的应用是无状态的随时可以重启或者扩容,但是实际场景很多时候我们计算的数据需要有一定的记录来保证幂等或者数据处理的位置。Fink已经为我们提供了这样的状态管理机制直接使用即可。
时间
时间是流处理应用另一个重要的组成部分。因为事件总是在特定时间点发生,所以大多数的事件流都拥有事件本身所固有的时间语义。例如窗口聚合、会话计算、模式检测和基于时间的 join。流处理的一个重要方面是应用程序如何衡量时间,即区分事件时间(event-time)和处理时间(processing-time)。
三种时间语义:
- 事件时间(event time): 事件产生的时间,记录的是设备生产(或者存储)事件的时间。
- 摄取时间(ingestion time): Flink 读取事件时记录的时间。
- 处理时间(processing time): Flink pipeline 中具体算子处理事件的时间。
Flink 提供了 watermarks 机制 — 它们定义何时停止等待较早的事件。
watermarks 给了开发者流处理的一种选择,它们使开发人员在开发应用程序时可以控制延迟和完整性之间的权衡。
窗口
在数据处理的时候很多数据并非是简单的累加操作,很多时候需要我们借助时间窗口进行聚合处理,比如计算最近 5 分钟的数据的平均值。窗口可以使时间驱动的也可以是数据驱动的,下面是 Flink 提供的几种窗口概念可以了解一下。
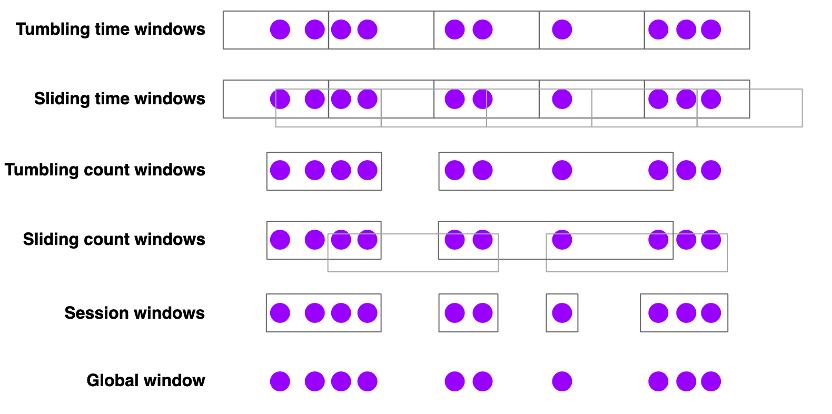
- 滚动时间窗口
- 每分钟页面浏览量
- TumblingEventTimeWindows.of(Time.minutes(1))
- 滑动时间窗口
- 每 10 秒钟计算前 1 分钟的页面浏览量
- SlidingEventTimeWindows.of(Time.minutes(1),Time.seconds(10))
- 会话窗口
- 每个会话的网页浏览量,其中会话之间的间隔至少为 30 分钟
- EventTimeSessionWindows.withGap(Time.minutes(30))
运维与部署
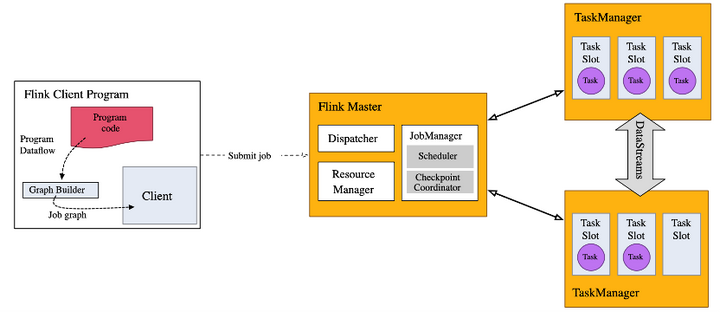
Flink 是一个多功能的框架,以混搭的方式支持许多不同的部署场景。
Flink 是一个分布式系统,需要有效分配和管理计算资源才能执行流应用程序。它集成了所有常见的集群资源管理器,例如 Hadoop YARN,但也可以设置作为独立集群甚至库运行。
客户端总是在某处运行。它获取 Flink 应用程序的代码,将其转换为 JobGraph 并将其提交给 JobManager。
JobManager 将工作分配到 TaskManager 上,实际的运算符(例如源、转换和接收器)来运行。
入门教程
Java 环境
需要安装 Java 8 或者 Java 11
安装包
下载文件:
wget https://www.apache.org/dyn/closer.lua/flink/flink-1.17.0/flink-1.17.0-bin-scala_2.12.tgz解压命令如下所示:
- $ tar -xzf flink-1.17.0-bin-scala_2.12.tgz
- $ cd flink-1.17.0-bin-scala_2.12.tgz
启动命令如下:
- $ ./bin/start-cluster.sh
- Starting cluster.
- Starting standalonesession daemon on host.
- Starting taskexecutor daemon on host.
启动成功后可以看到下图所示提示:

提交作业(Job)
Flink 的 Releases 附带了许多的示例作业。你可以任意选择一个,快速部署到已运行的集群上。
- $ ./bin/flink run examples/streaming/WordCount.jar
- $ tail log/flink-*-taskexecutor-*.out
- (nymph,1)
- (in,3)
- (thy,1)
- (orisons,1)
- (be,4)
- (all,2)
- (my,1)
- (sins,1)
- (remember,1)
- (d,4)
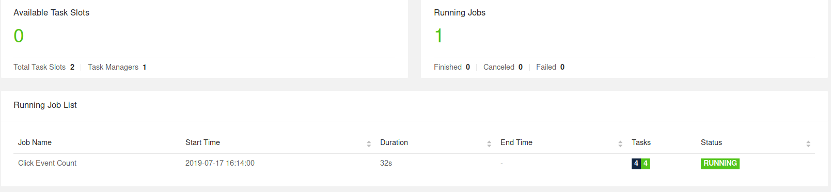
WebUI 中观察作业
打开UI控制台可以看到如下JOB的运行状态:
控制台地址:http://localhost:8081/
停止集群
$ ./bin/stop-cluster.sh总结
从业务角度看
Apache Flink 是一个分布式流处理引擎,可以用于解决许多与数据处理相关的问题,包括:
- 实时数据处理:Flink 可以处理实时数据流并对其进行计算和分析,可以处理数据的实时窗口和时序分析等应用场景。
- 批处理:Flink 也支持批处理,可以处理大规模的离线数据,实现高效的数据分析和计算。
- 机器学习:Flink 提供了机器学习库 FlinkML,可以在分布式集群上训练和测试机器学习模型。
- 事件驱动应用程序:Flink 可以处理事件驱动应用程序,如应用程序状态管理、流式事件处理和复杂事件处理。
- 实时数据仓库:Flink 可以将实时数据流转换为数据仓库的数据模型,用于实时的 OLAP 分析。
总之,Flink 可以用于解决实时和离线数据处理的许多问题,包括数据流处理、批处理、机器学习和事件驱动应用程序等。
从技术角度看
Apache Flink 是一种高性能、低延迟的分布式数据流处理框架,它具有以下优点,因此成为数据分析和处理的重要工具之一:
- 高性能:Flink 在处理数据时可以保证非常高的吞吐量和低延迟,可以在处理实时数据时实现毫秒级的响应。
- 分布式处理:Flink 可以在分布式环境下运行,可以处理大规模数据集,并能够自动进行数据分区和负载均衡。
- 可靠性:Flink 具有高可靠性,可以处理丢失的数据并保证结果的准确性。
- 灵活性:Flink 支持多种数据源和数据格式,并提供了丰富的 API 和库,可以方便地进行数据处理和分析。
- 处理复杂事件:Flink 支持复杂事件处理,可以识别和处理包含多个事件的复杂事件。
- 支持多种部署方式:Flink 可以在本地环境、YARN、Mesos、Kubernetes 等不同的环境下运行,便于部署和管理。
基于这些优点,Flink 被广泛应用于各大互联网公司。
作者|宋小生
本文为阿里云原创内容,未经允许不得转载。

