
热门标签
热门文章
- 1RabbitMQ解决大量unacked问题_rabbitmq出现很多unack
- 2SparkStreaming设置日志级别_sparkstreaming 设置日志级别
- 3「C/C++」封装函数时提高效率的方法_c++ 代码优化 封装
- 4Spring Security OAuth2.0笔记_login/oauth2/code/
- 5android seekbar线条大小,android中ProgressBar的使用SeekBar的使用和RatingBar的使用
- 6Llama2训练与数据资料链接_llama2 本地知识库 zhihu
- 7阿里云可观测 2024 年 3 月产品动态
- 8供应链领域主题:生产制造关键术语和系统
- 9LeetCode第27题,移除元素_leetcode27
- 10mysql 磁盘空间100%
当前位置: article > 正文
字节面试官: 让你设计一个MQ每秒要抗几十万并发,怎么做?_让你设计一个mq每秒要抗几十万并发,怎么做
作者:花生_TL007 | 2024-04-09 23:19:43
赞
踩
让你设计一个mq每秒要抗几十万并发,怎么做
目录
- 1、页缓存技术 + 磁盘顺序写
- 2、零拷贝技术
- 3、最后的总结
这篇文章来聊一下Kafka的一些架构设计原理,这也是互联网公司面试时非常高频的技术考点。
Kafka是高吞吐低延迟的高并发、高性能的消息中间件,在大数据领域有极为广泛的运用。配置良好的Kafka集群甚至可以做到每秒几十万、上百万的超高并发写入。
那么Kafka到底是如何做到这么高的吞吐量和性能的呢?这篇文章我们来一点一点说一下。
1、页缓存技术 + 磁盘顺序写
首先Kafka每次接收到数据都会往磁盘上去写,如下图所示。
那么在这里我们不禁有一个疑问了,如果把数据基于磁盘来存储,频繁的往磁盘文件里写数据,这个性能会不会很差?大家肯定都觉得磁盘写性能是极差的。
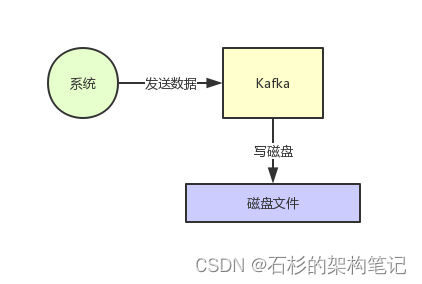
没错,要是真的跟上面那个图那么简单的话,那确实这个性能是比较差的。
但是实际上Kafka在这里有极为优秀和出色的设计,就是为了保证数据写入性能,首先Kafka是基于操作系统的页缓存来实现文件写入的。
操作系统本身有一层缓存,叫做page cache,是在内存里的缓存,我们也可以称之为os cache,意思就是操作系统自己管理的缓存。
你在写入磁盘文件的时候,可以直接写入这个os cache里,也就是仅仅写入内存中,接下来由操作系统自己决定什么时候把os cache里的数据真的刷入磁盘文件
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/花生_TL007/article/detail/395421
推荐阅读

相关标签

