- 1【华为OD机试】游戏分组、王者荣耀【C卷|100分】
- 2Pytorch(gpu),cuda,cudnn安装_pip install cudatoolkit
- 3如何下载马斯克的grok-1预训练模型_grok-1下载
- 4两会 | 陈智敏:要尽快转变数字安全工作的思路_陈智敏 数据安全
- 5ssm“最多跑一次”微信小程序
- 6【微服务】- 服务调用 - OpenFeign_微服务openfeign 调用
- 7flask框架之请求扩展、请求生命周期_flask生命周期
- 8李洪强漫谈iOS开发[C语言-009] - C语言关键字
- 9linux 网络状态表 /proc/net/tcp 各项参数说明
- 10python如何下载os库_python 自带库---os库
4.4 序列化与反序列化_python 怎么让序列化和反序列化的版本保持一致?
赞
踩
1.概述
-
序列化 ObjectOutputStream
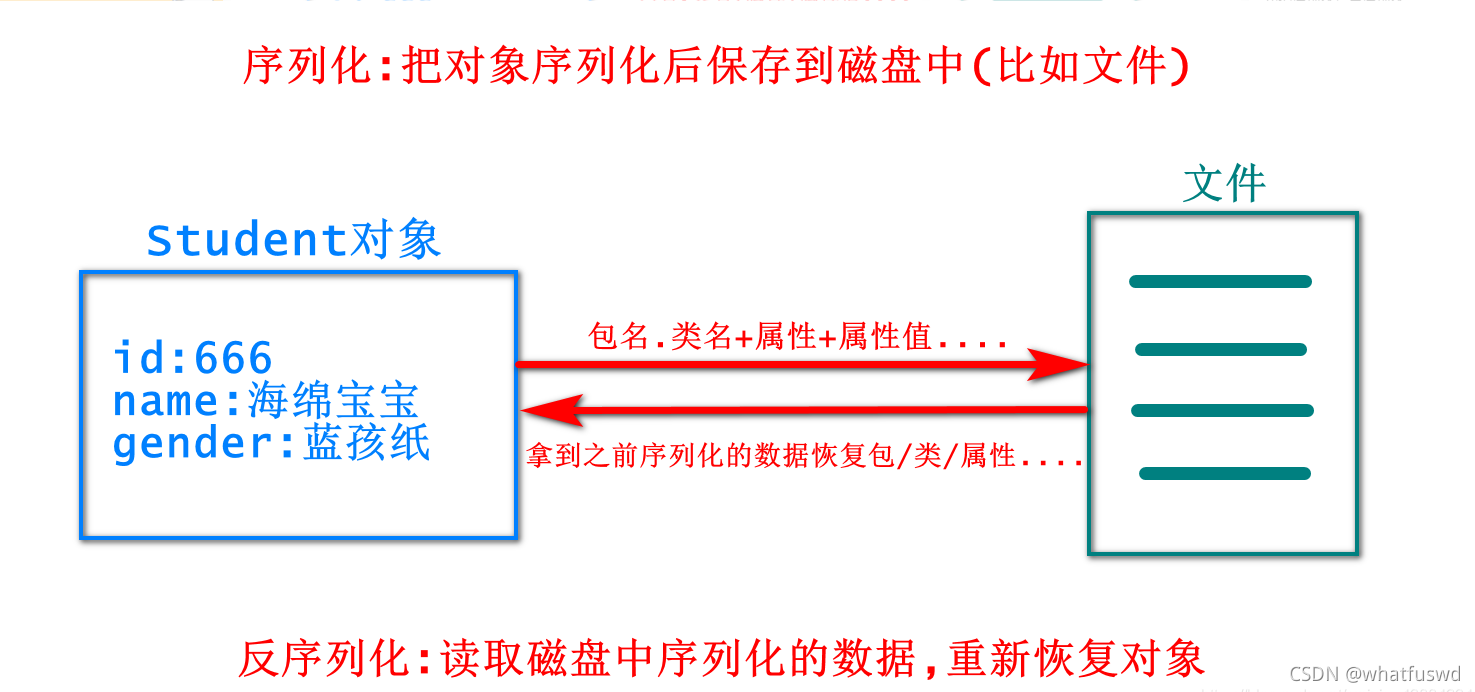
- 是指把程序中的java对象,通过序列化流oos输出到磁盘的文件中,相当于数据写出的过程,利用ObjectOutputStream,把对象的信息,按照固定的格式转成一串字节值输出并持久保存到磁盘
- 方向是OUT,使用的流是ObjectOutputStream
- 使用的方法是out.writeObject(目标对象);
- 注意:如果一个类的对象想要被序列化,那么这个类必须实现Serializable接口
-
反序列化 ObjectInputStream
- 是指把之前已经保存在文件中的对象的相关数据,通过反序列化流ois读到内存中的过程中,并把读到的数据恢复成对象,利用ObjectInputStream,读取磁盘中之前序列化好的数据,重新恢复成对象
- 相当于数据读取的过程,方向是in,使用的流是ObjectInputStream
- 使用的方法是in.readObject();
- 注意:反序列化指定的文件路径,必须与序列化输出的文件路径一致
- 注意:一次序列化操作对应一次反序列化操作,或者UID必须保持一致,如果不一致,会报错
2.特点/应用场景
- 需要序列化的文件必须实现Serializable接口,用来启用序列化功能
- 不需要序列化的数据可以修饰成static,原因:static资源属于类资源,不随着对象被序列化输出
- 每一个被序列化的文件都有一个唯一的id,如果没有添加此id,编译器会自动根据类的定义信息计算产生一个
- 在反序列化时,如果和序列化的版本号(UUID)不一致,无法完成反序列化
- 常用与服务器之间的数据传输,序列化成文件,反序列化读取数据
- 常用使用套接字流在主机之间传递对象
- 不需要序列化的数据也可以被修饰成transient(临时的),只在程序运行期间在内存中存在,不会被序列化持久保存
3.涉及到的流对象
序列化:Object OutputStream
ObjectOutputStream 将 Java 对象的基本数据类型写入 OutputStream,通过在流中使用文件可以实现对象的持久存储。如果流是网络套接字流,则可以在另一台主机上或另一个进程中重构对象。
构造方法:
ObjectOutputStream(OutputStream out)
创建写入指定 OutputStream 的 ObjectOutputStream
普通方法:
writeObject(Object obj)
将指定的对象写入 ObjectOutputStream
反序列化:ObjectInputStream
ObjectInputStream对以前使用ObjectOutputStream写入的基本数据和对象进行反序列化重构对象。
构造方法:
ObjectInputStream(InputStream in) 创建从指定 InputStream 读取的 ObjectInputStream
普通方法:
readObject() 从 ObjectInputStream 读取对象
4.代码实现序列化与反序列化
4.1 步骤1:创建学生类Student2
package partThree; /*本类用于序列化测试的物科类*/ public class Student2 implements Serializable { //定义学生相关的属性并进行封装 private String name; //姓名 private int age; //年龄 private String addr; //地址 private char gender;//性别 //2.1 创建本类的无参构造--注意必须手动提供无参构造,否则会被覆盖 public Student2() { System.out.println("我是Student的无参构造"); } //2.2创建全参构造 public Student2(String name, int age, String addr, char gender) { super();//默认调用父类的无参构造 this.name = name; this.age = age; this.addr = addr; this.gender = gender; System.out.println("我是Student的全参构造"); } //3.属性封装后,需要本类提供公共的属性访问与设置方式get()&set() /** * 自动创建get()&set(),右键-->Source-->Generate Getters and Setters... */ public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } public String getAddr() { return addr; } public void setAddr(String addr) { this.addr = addr; } public char getGender() { return gender; } public void setGender(char gender) { this.gender = gender; } //如果不想查看对象的地址值,而是想查看类型 属性 属性值 //可以在子类中添加重写的toString() @Override public String toString() { return "Student{" + "name='" + name + '\'' + ", age=" + age + ", addr='" + addr + '\'' + ", gender=" + gender + '}'; } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
4.2 步骤2:创建序列化测试类
package partThree; import java.io.*; /* 本类用于测试对象的序列化与反序列化 * 序列化 ObjectOutputStream * 是指把程序中的java对象,通过序列化流oos输出到磁盘的文件中,相当于数据写出的过程 * 反序列化 ObjectInputStream * 是指把之前已经保存在文件中的对象的相关数据,通过反序列化流ois读到内存中的过程中 * 相当于数据读取的过程*/ public class TestSerializable { public static void main(String[] args) { method1(); //本方法用来完成序列化的功能 method2(); //本方法用于完成反序列化功能 } private static void method2() { //1.定义一个在本方法中都生效的局部变量,注意初始化 ObjectInputStream in = null; //2.由于IO操作可能会产生异常,所以完成try-catch-finally结构 try{ //3.创建反序列化流ois in = new ObjectInputStream(new FileInputStream("E:\\ready\\1.txt")); //4.通过反序列化流,读取文件中的数据,并把读到的数据,回复成数据 Object o = in.readObject(); System.out.println(o); //将接到的对象打印 System.out.println("恭喜您,反序列化成功!"); }catch(Exception e){ System.out.println("很抱歉,反序列化失败!"); e.printStackTrace(); }finally { try { in.close(); } catch (IOException e) { e.printStackTrace(); } } } private static void method1() { //定义一个在本方法中都生效的局部变量,注意初始化 ObjectOutputStream out = null; try { //1.创建流对象--需要try-catch,需要设置FileOutputStream子类, // 并设置传输文件路径表明要把序列化后的对象数据输出到哪个文件中 out = new ObjectOutputStream(new FileOutputStream("E:\\ready\\1.txt")); //2.使用流对象 //2.1 指定一个要序列化输出的对象,并设置属性 Student2 s = new Student2("海绵宝宝",3,"海里",'男'); //2.2 序列化输出对象s到文件中 out.writeObject(s); System.out.println("恭喜您,序列化成功!"); //成功后,我们可以在目标文件里看到序列化输出的数据,但注意,这个数据是为了底层保存对象和传输使用的,我们看不懂 //有些类似于我们字节码文件中的数据 } catch (IOException e) { System.out.println("很抱歉,序列化失败!"); e.printStackTrace(); }finally { //3.关闭流对象 try { out.close(); } catch (IOException e) { e.printStackTrace(); } } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
5.测试案例中常见的几种编译错误类型
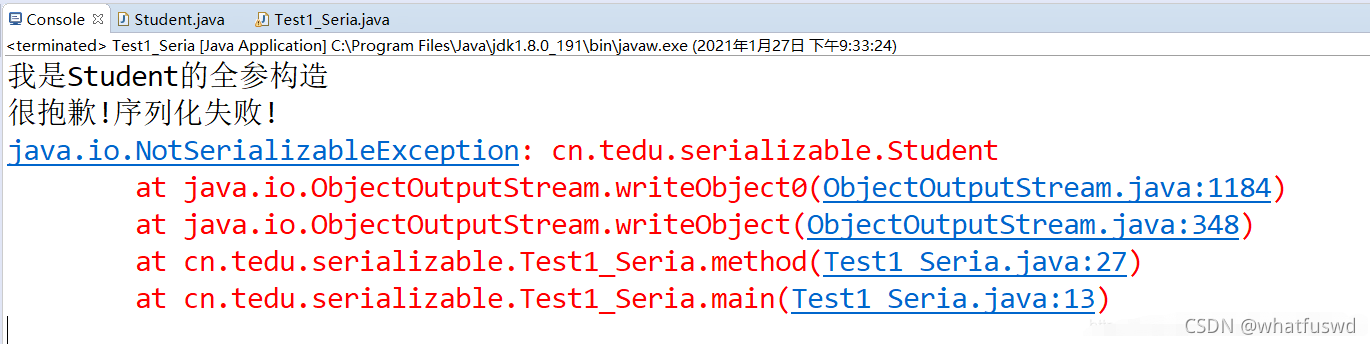
NotSerializableException:报错原因:要序列化对象所在的类并没有实现序列化接口
解决方案:实现序列化接口
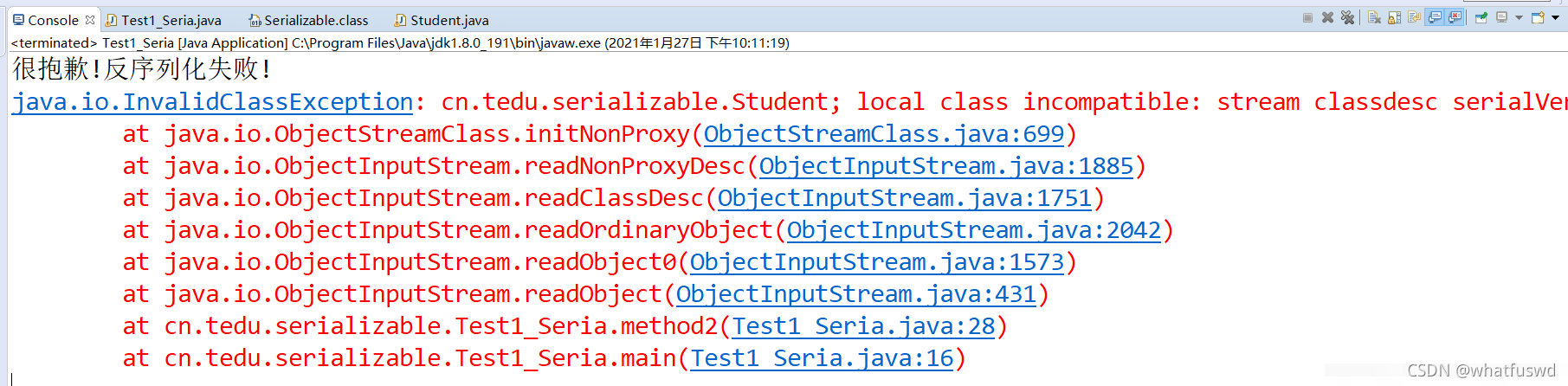
InvalidClassException:报错原因:更改子类数据后,会导致本次反序列化时使用的UID与序列化时的UID不匹配
解决方案:反序列化时的UID与序列化时的UID要保持一致,或者测试时一次序列操作对应一次反序列化操作,否则不匹配就报错,重新进行一次序列化后,再进行反序列化即可;
6.为什么反序列化版本号需要与序列化版本号一致?
我们在反序列化时,JVM会拿着反序列化流中的serialVersionUID与序列化时相应的实体类中的serialVersionUID来比较,如果不一致,就无法正常反序列化,出现序列化版本不一致的异常InvalidClassException。
而且我们在定义需要序列化的实体类时,如果没有手动添加UID,
Java序列化机制会根据编译的class自动生成一个,那么只有同一次编译生成的class才是一样的UID。
如果我们手动添加了UID,只要这个值不修改,就可以不论编译次数,进行序列化和反序列化操作。
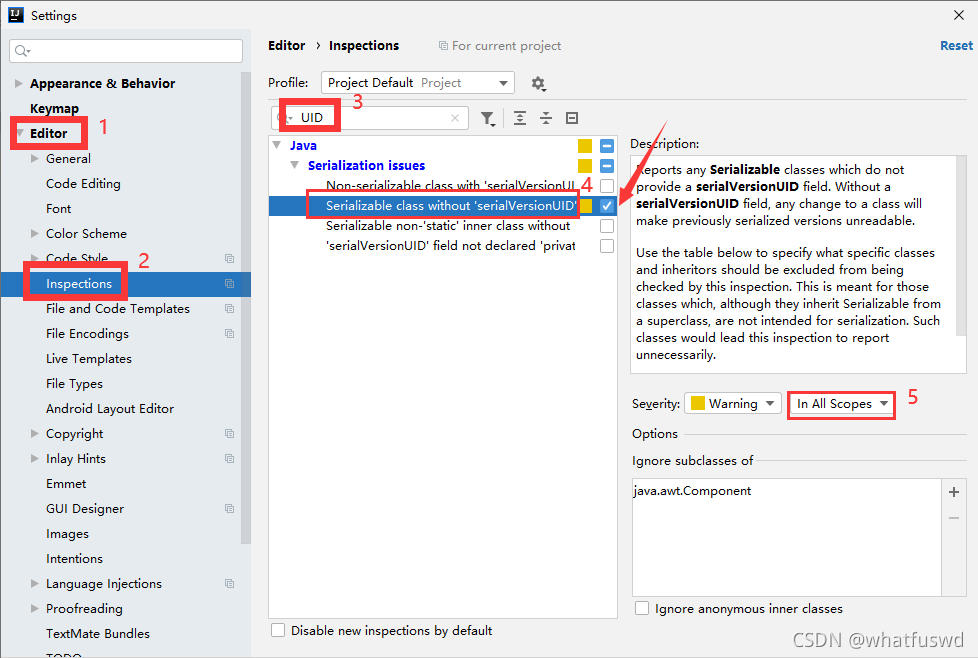
7.自动提示 生成UID 链接的设置