
- 1【leetcode面试经典150题】37. 矩阵置零(C++)
- 2arm64汇编ldr和ldur和ldp指令在xcode中传入地址调用方法
- 3搭建Pytorch虚拟环境基础教程(Windous)_pytorch创建虚拟环境
- 4设计模式学习笔记 - 开源实战二(上):从Unix开源开发学习应对大型复杂项目开发
- 5SSM+基于SSM的智慧社区宠物医院 毕业设计-附源码211621_宠物医院管理系统er图
- 6Windows配置Java环境_java windows
- 7UE4 FBX静态网格物体通道_uv通道包含退化的三角形
- 8一文详解MySQL——索引篇_分布式mysql索引
- 9新版 Redis 将不再“开源”引争议:本想避免云厂商“白嫖”,却让开发者遭到“背刺”!_rsalv2
- 10Generative Adversarial Text to Image Synthesis --- 根据文字描述生成对应的图片_generative adversarial text to image synthesis.
ChatGLM-6B部署和微调实例_chatglm-6b微调环境搭建
赞
踩
前言
ChatGLM-6B ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。ChatGLM-6B是本人尝试使用和微调的第一个大语言模型,自我感觉该模型很适合作为大语言模型的入门级选手,无论是部署配置还是推理微调都十分方便。本文主要介绍如何配置部署ChatGLM-6B,以及ChatGLM-6B推理和P-tuning v2微调基本步骤,希望可以帮助大家使用ChatGLM-6B。
一、ChatGLM-6B安装
1.1 下载
ChatGLM-6B项目仓库地址为 GitHub,模型文件下载地址为Huggingface,将下载好的模型文件chatglm-6b文件放至项目仓库中的ptuning文件目录下(如下图所示)。整个下载时间的长短根据网速和是否使用远程服务器因人而异,本人因使用的是远程服务器,下载时间共约5个小时。
1.2 环境安装
服务器的版本为RTX 3090,内存为24GB。Python版本为3.8.16,ubuntu的版本为20.04,Cuda的版本为11.6。
| 库名 | 版本 |
|---|---|
| transformers | 4.27.1 |
| torch | 1.13.1 |
详情可见requirements.txt,其中gradio库有的时候会安装失败,如果后续不考虑前端交互的平台的构建,此库可以先不安装,并不影响模型推理和微调。环境配置步骤如下代码所示:
conda create -n test python=3.8.16 -y
source activate test
pip install -r requirements.txt
cd ChatGLM
- 1
- 2
- 3
- 4
二、ChatGLM-6B推理
ChatGLM-6B推理部分,只要找到cli_demo.py文件运行即可。
tokenizer = AutoTokenizer.from_pretrained("ptuning/chatglm-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("ptuning/chatglm-6b", trust_remote_code=True).half().cuda()
model = model.eval()
- 1
- 2
- 3
以下是推理部分的展示:

当然我们也想要批量式询问ChatGLM-6B,这里我自己写了一个批量调用的py文件:
import torch from transformers import AutoTokenizer, AutoModel import torch import sys import pandas as pd model_path="ptuning/chatglm-6b" tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True) model = AutoModel.from_pretrained("ptuning/chatglm-6b",trust_remote_code=True).float() #model =model.to("cpu") model = model.eval() data = pd.read_csv('Q1.csv') MC = data['Question'].tolist() j = -1 for i in MC: j = j+1 input1 = f"{i}" print(input1) response,history = model.chat(tokenizer,input1,history=[],temperature=1) print(response) print("--------------------------------------------------") data['Answer'].loc[j] = response data.to_csv('Q1.csv',index = False,encoding='utf_8_sig')

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
最终Q1.csv的结果为:

三、P-tuning 微调
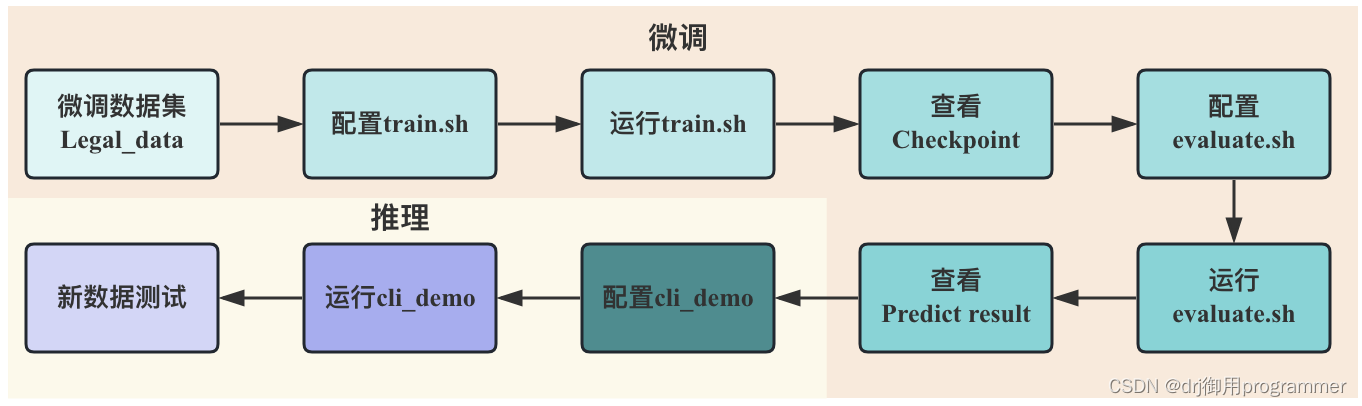
下图展示出ChatGLM-6B进行P-tuning v2微调的大致流程,首先需要构建好微调模型使用的数据集(包括训练集,验证集和测试集),接着是配置运行train.sh,进行数小时的训练之后将会得到模型参数权重文件Checkpoint,然后对evaluate.sh进行参数配置和运行,将会得到一系列的测试集结果,到此便是微调部分。为了检测微调后的模型在新数据上的效果,可以对cli_demo.py文件进行配置和运行。
3.1微调数据集
我的课题是研究法律判决预测任务,因此我的微调数据集的输入为案情陈述,输出为罪行判决。ChatGLM-6B的微调数据集有很多的格式可以选择,这里是经典的content+summary格式。以下是一个例子
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

