- 1CSS的属性【all:inherit】有什么奥秘?
- 2Git版本控制管理——分支_git show-branch
- 3php其他反序列化知识学习
- 4gitconfig 配置文件[credential]使用记录
- 5git clone 出现"error: RPC failed; curl 56 GnuTLS recv error (-9): A TLS packet with unexpected length ...
- 6java基于ssm奶茶店进销存系统_奶茶进销存
- 7【MySQL】数据的导入导出及.sql文件执行_导出数据库脚本的命令
- 8【字符集二】多字节字符vs宽字符
- 9[ project.config.json 文件内容错误] project.config.json: libVersion 字段需为
- 10IO多路复用之POLL【内附可运行代码注释完整】_c io复用 poll
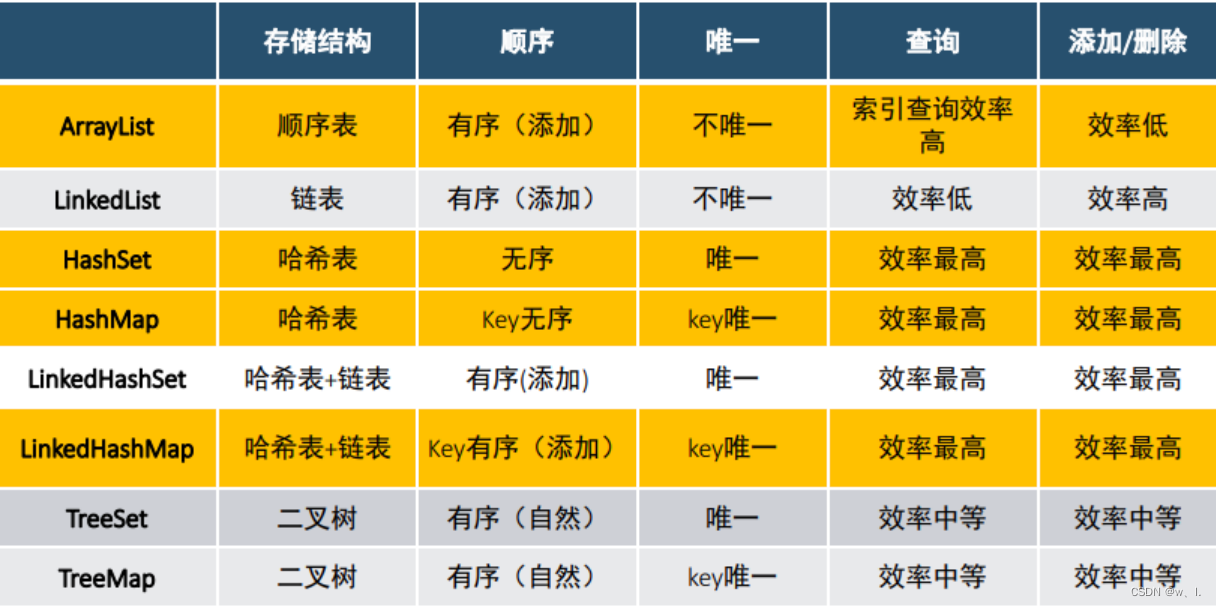
详解链表、栈、队列等数据结构_链表和队列
赞
踩
目录
一、数据结构是用来干什么的?
简单的来说,数据结构是把大量的数据按照一定的规范和约束,放到一起。方便我们查找和二次使用。
二、我们接触过哪些数据结构?
线性表和树状图
三、线性表有哪些?
顺序表、链表、栈和队列
顺序表:
顺序表是我们最常见的数据结构,数组的存储就是使用顺序表。
说明:里面存储的元素,他们的类型,都是存在相同类型的关系,并且紧挨着连接起来的。除掉首元素和尾元素,每个元素前后都有相邻的元素。这样的我们就叫做顺序表
特点:查询快,因为是数组,直接下标出。插入和移除就比较慢了。因为要移动、复制数组,很麻烦。

例如:ArrayList本质上就是数组,他就是使用的顺序表。下面我们详细看看他的源码。
/**
* The array buffer into which the elements of the ArrayList are stored.
* The capacity of the ArrayList is the length of this array buffer. Any
* empty ArrayList with elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA
* will be expanded to DEFAULT_CAPACITY when the first element is added.
存储arrayList数组的缓冲区
*/
transient Object[] elementData; // non-private to simplify nested class access
/**
* The size of the ArrayList (the number of elements it contains).
*
* @serial
*/
private int size;
构造方法
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
add元素到尾部
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!! 判断数组的大小,不够的话,自动扩容
elementData[size++] = e;
return true;
}
add元素到指定位置
public void add(int index, E element) {
rangeCheckForAdd(index); // 检查插入位置有没有超过数组大小
ensureCapacityInternal(size + 1); // Increments modCount!!
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element; // 扩容后,将插入点后面的元素往后移动一个位置,通过System.arraycopy复制方式实现
size++;
}

remove移除
public E remove(int index) {
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work
return oldValue;
}
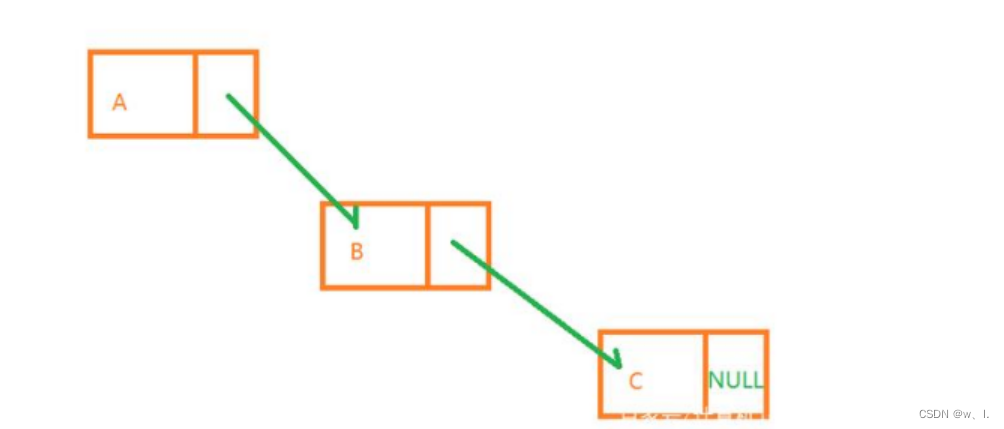
链表
任何的数据类型都可以通过最基本的数组和指针构造。链表也不例外,相比于数组,数组则是定长的,不管存储的满否,都申请了一定大小的内存空间,而链表则不是,链表的空间是随用随申请,数据的位置相比于数组,其实不连续的,一般来说,需要在元素上指定下一个元素的指针,来达成链接关系。
说明:每个元素上都有一块位置用于指向下一个元素(指针)
链表还是比较适合于快速增加、删除、不适合于索引。因为需要全盘遍历
下面就是一个单项链表
链表在JAVA 当中最具代表性的就是 LinkedList(双向链表),就是每个元素会带有它的上一个节点和下一个节点的指针
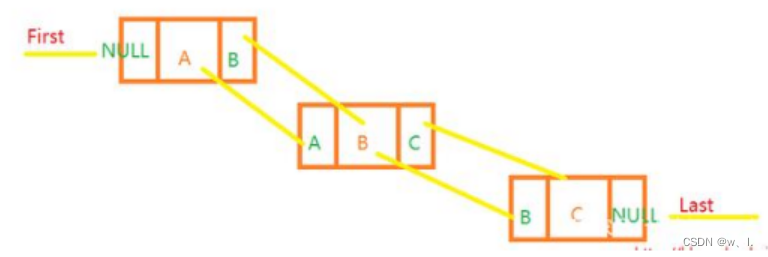
三个重要的属性
transient int size = 0;
/**
* Pointer to first node.
* Invariant: (first == null && last == null) ||
* (first.prev == null && first.item != null)
*/
transient Node<E> first; // 集合的第1个节点
/**
* Pointer to last node.
* Invariant: (first == null && last == null) ||
* (last.next == null && last.item != null)
*/
transient Node<E> last; // 集合的最后一个节点
单个节点node内容
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
头部插入和尾部插入一个节点
/**
* Links e as first element.
*/
private void linkFirst(E e) {
final Node<E> f = first; // 拿到原来的第一个节点
final Node<E> newNode = new Node<>(null, e, f); // 创建一个新的节点
first = newNode; // 第一个节点变成新增的
if (f == null)
last = newNode;
else
f.prev = newNode; // 原来的第一个节点的前置节点设置为新增的节点
size++;
modCount++;
}
/**
* Links e as last element.
*/
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
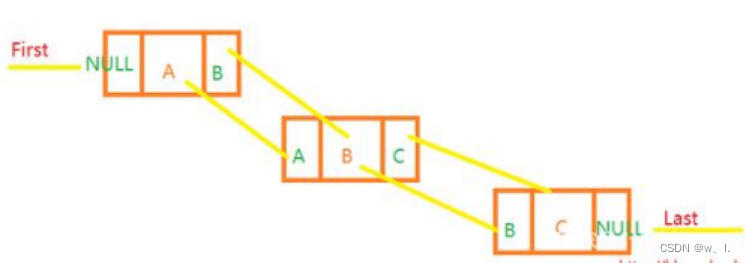
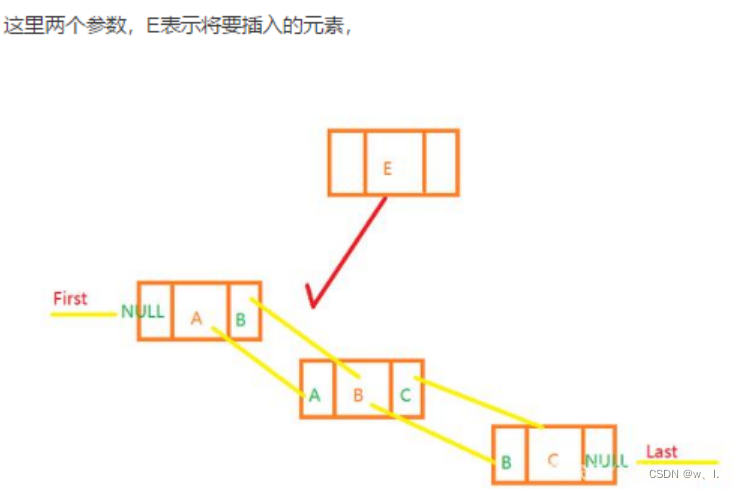
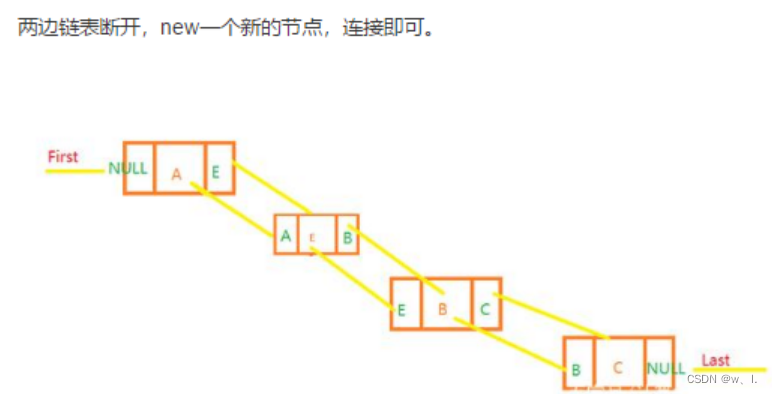
指定位置插入新的节点
/**
* Inserts element e before non-null Node succ.
*/
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
final Node<E> pred = succ.prev;
final Node<E> newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}
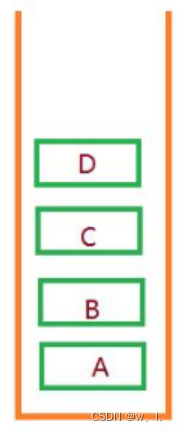
栈(stack)
栈还是按照数组为基础实现的,只不过它是一个半开的数组,怎么理解这个半开的数组呢,如图,就好像一个瓶子一样,往里面丢元素,先进后出原则。
方法a{
方法b{
方法c{
方法d{
}
}
}
}
入栈 push
将一个元素加入的栈里面,此时的元素是最外层的一个元素,此时执行出栈命令,则这个元素会被删除并返回
出栈 pop
删除此堆栈顶部的对象,并将该对象作为此函数的值返回。
查看 peek
通过 peek 查看当前栈顶的元素,只是查看,并不执行删除
队列 Queue
队列遵循先进先出原则
队列还提供额外的插入,提取和检查操作。这些方法中的每一种都有两种形式:如果操作失败,则抛出一个异常,另一种返回一个特殊值(null或false,具体取决于操作)。

这里使用 ArrayBlockingQueue 以数组实现的阻塞队列
BlockingQueue<String> strings = new ArrayBlockingQueue<String>(2);
一个有限的blocking queue由数组支持。 这个队列排列元素FIFO(先进先出)。 队列的头部是队列中最长的元素。 队列的尾部是队列中最短时间的元素。 新元素插入队列的尾部,队列检索操作获取队列头部的元素。
这是一个经典的“有界缓冲区”,其中固定大小的数组保存由生产者插入的元素并由消费者提取。 创建后,容量无法更改
入队 add()/offer()/put()
add 和 offer 都可以将元素加入到队列中。但是add 在超过队列容量的时候会抛出异常,offer 则会返回false
而put 操作则会在队列没有空间的时候阻塞,直到队列有空间执行
出队 poll()/take()
poll检索并删除此队列的头,如果此队列为空,则返回 null 。
take 在没有元素的时候则会阻塞