
- 1Java安全(应付面试)
- 2python123选择题答案_30题Python基础知识点测试题答案
- 3SourceTree for windows安装并跳过注册_source tree for windows
- 4《大数据原理与应用》林子雨:一. 大数据基础_大数据技术基础 林子雨
- 5全网最新巨魔商店2TrollStore2的最全安装教程,支持不同版本
- 62024年软件测试岗,“我“也碰上了求职危机..._2024年互联网软件测试就业会更难吗
- 7芯片资深IC设计工程师面经系列(五)低功耗设计_逻辑门hvt lvt
- 8Vivado时序仿真波形的保存与读取_vivado 打开之前保存的仿真波形文件
- 9盘点十大开源大模型_开源模型
- 10SAP MM学习笔记16-在库品目评价_sap评估类
Flink 系例 之 电商项目 - 购物订单大屏监控实战 (示例)_flink项目实战
赞
踩
1. 前言
如果有看我写的 Flink 系例的前期文章,大部份是写 Flink 各算子、窗口、方法、Table&SQL、连接器等的直接用法与示例,那是为了尽可能的将学习知识点的基础应用简化成直接的示例成果,将概念通过单一示例展现,将复杂度降低增加学习的简易性,以免一开始看到一堆的概念算子就心生退意。程序员嘛,大部份时候,习惯于短平快的内容,希望 10 分钟能看完的东西,别婆婆妈妈扯个把小时,但往往这样,只能撑握皮毛,确无法深入理解,这算是行业人的通病吧,但各有所爱也无法统一,就这样吧多说无益。
本章以模拟一个电商平台的日常订单数据统计系统为设计基础,将电商平台的实时订单通过 Flink 实时流计算能力,按聚合维度实时计算,输出订单流计算结果,再通过监控大屏展示,实时快速撑握电商平台订单数据趋势、分类占比、销量排行等,从而全局了解电商平台业务运行状态,为电商平台高层决策、运营、分析、成长等提供最基础、最实时的数据依据。
其实上述计算模式通过其它第三方框架或平台等进行离线计算也一样是可以完成,如:sprak、hodoop 等,但 Flink 的优势就是实时数据流计算,不需要等待数据批量入仓后再进行统一清洗、加工、计算、存储等,Flink 的实时流计算引擎可以将数据分段(按时间或数量)快速计算,就像水龙头一样打开(数据)水流入到桶内,对装满不同大小桶的(数据)水进行计算,如:体积、重量等(窗口内聚合计算),则水龙头源源不断的流出水,从而保证了当前看到数据即为最新计算结果,效率和体验都是最佳选择。
2. 项目介绍
以电商项目运作模式为起点,将电商平台中对各维度计算的应用场景,再结合我们学习的 Flink 流式计算技术,融合到真实业务中,通过技术加速业务成长,通过业务检验新技术的可行性,从而推动新技术的落地与大面积的应用,技术嘛是科学生产的第一动力!
根据电商项目的作业场景,我们选取以订单系统系统进行实时维度统计,将数据流按以下几个场景,采用 Flink 流式实时计算能力进行开发实现:
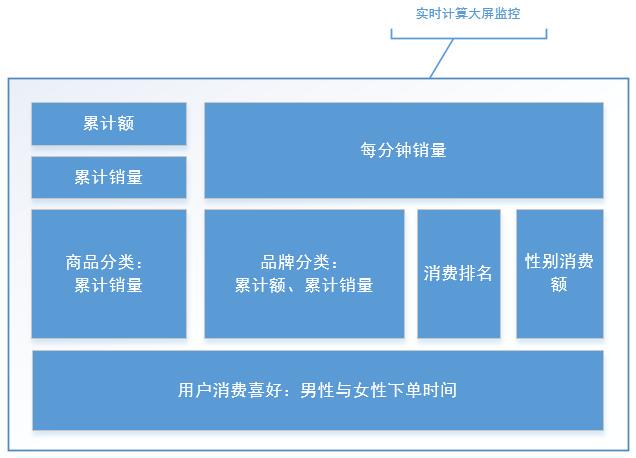
1. 商品累计销售总额(按分钟刷新)
2. 商品累计销售总量(按分钟刷新)
3. 每分钟商品销售流量
4. 每分钟商品分类销售量排名
5. 品牌营销能力:按累计销量、累计销售额计算
6. 消费前十排名用户(按分钟刷新)
7. 性别购买能力(按分钟刷新,统计各性别购买总额与占比)
8. 每 10 分钟商品销量(统计各性别分时段购买总量)
3. 目的
1. 将前期学习的算子、方法、窗口、连接器、Table&SQLAPI、水印等知识点串连汇集
2. 根据电商项目特点,结合业务需求,将 Flink 能力特性与业务流程融合到项目实践中
3. 检验前期学习的知识,加强动手能力,通过编码成果来验证设计目标、运作流程等满足业务需求目标;
4. 通过学习新的技术知识或设计新业务流程架构,实现架构知识与设计能力提升。
注:其实最终目标,就是学习嘛,肯定要实践,否则一切都是空谈。
4. 运行流程
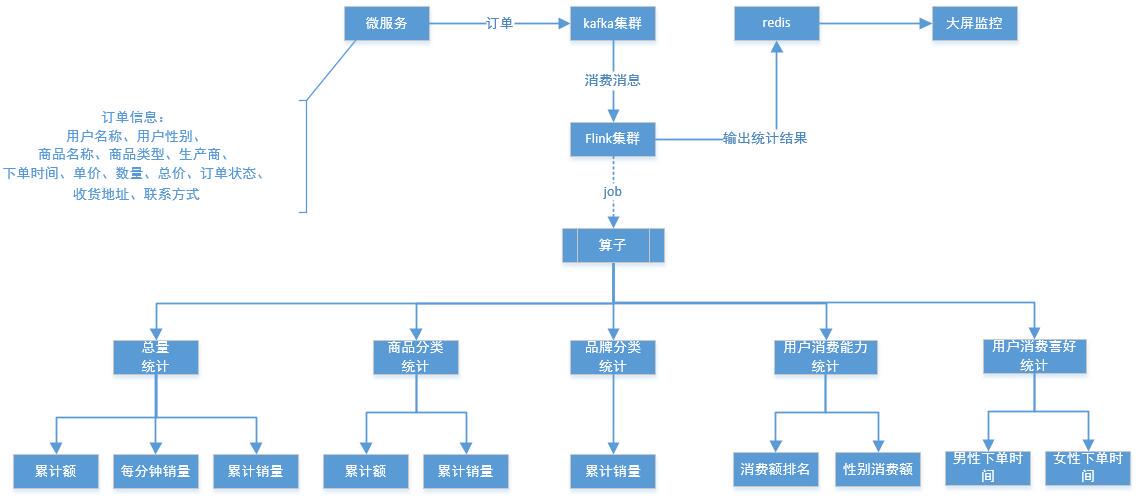
项目采用技术点如下:
flink 开发库
kafka 集群
vue2 + element.ui + echarts (大屏显示)
spring boot webflux (大屏后端服务)
redis 存储实时计算数据(生产因该考虑数据同步落库到 mysql 进行持久化)
项目流程:
1. 一个正常流程的电商订单系统,会将先所有用户的订单发送到订单表或订单队列中,我们此处的 “微服务” 则是用示例代码模拟订单系统,将订单推送到 kafka 集群中,用来做业务削峰与订单缓存。
2. 通过集成 Flink 库,开发多维度实时流计算客户端,上传到 Flink 集群中,提交启动运行 Task JOB 服务。
3.Flink 客户端从 kafka 中获取订单数据,实时计算各窗口限定颗粒度的数据流对象,将算子结果输出到 redis 中。
4. 大屏监控服务实时或定时轮询获取 Redis 的最新实时计算结果,并对维度数据进行格式化,输出到前端,前端根据各维度要求生成对应图表效果;
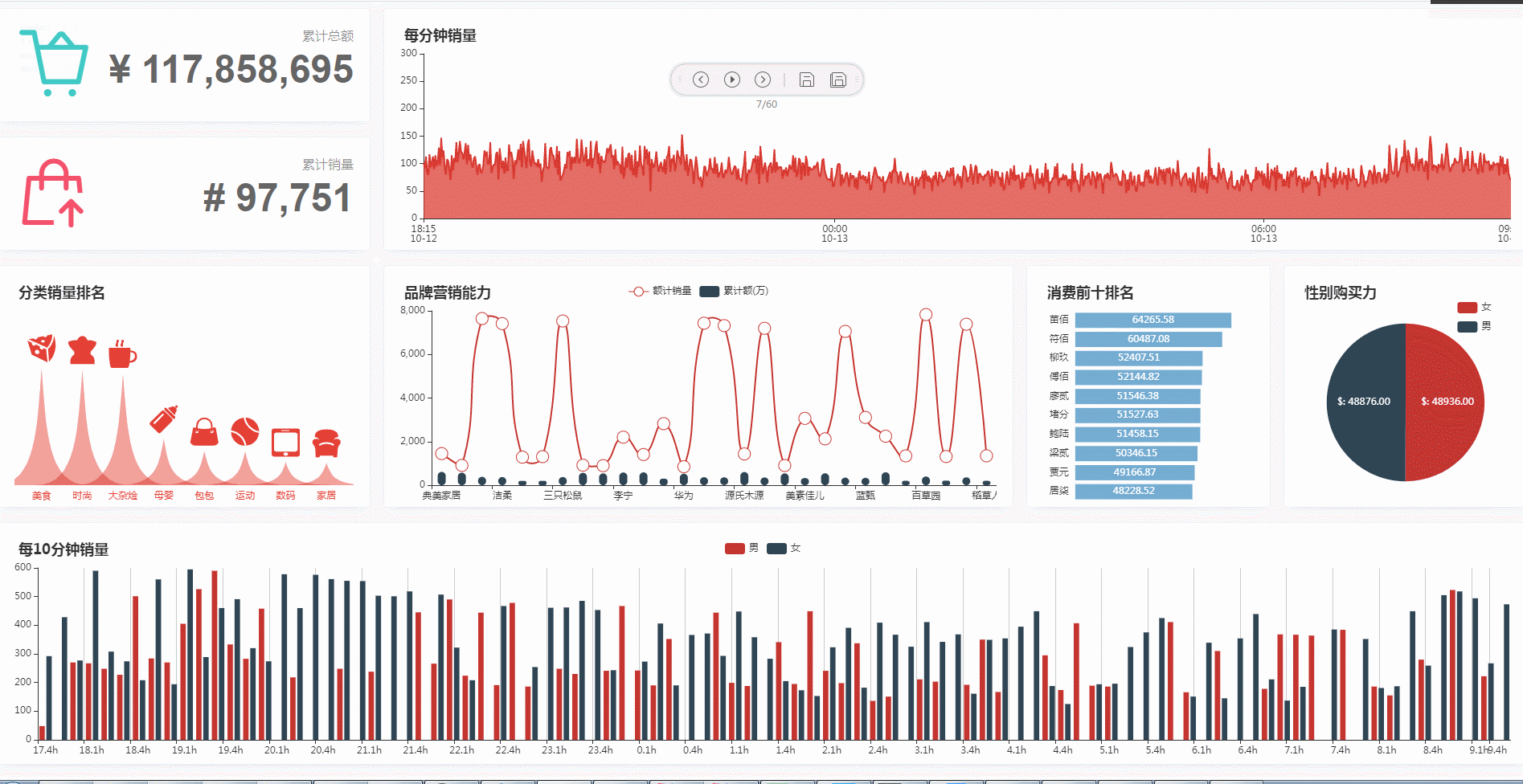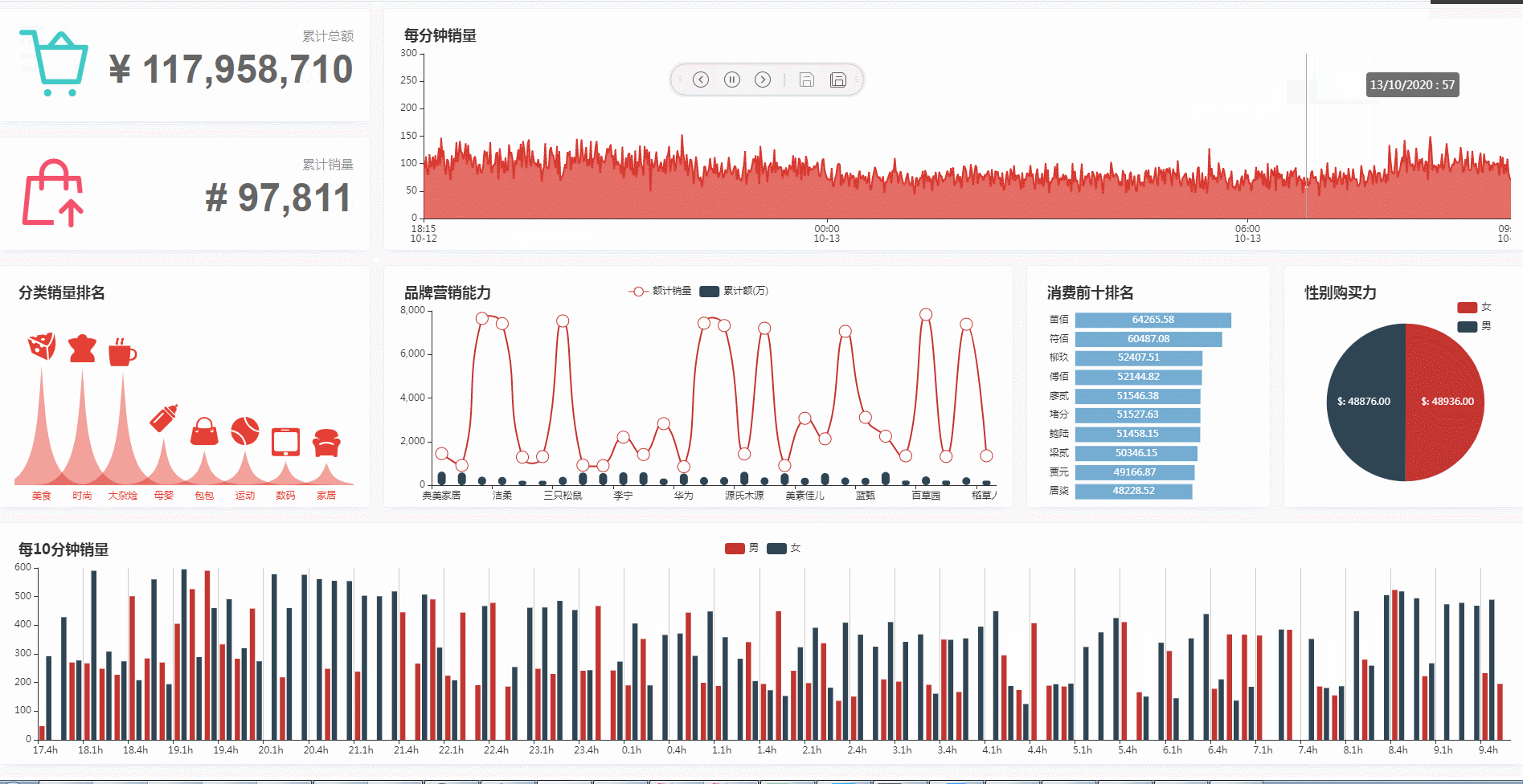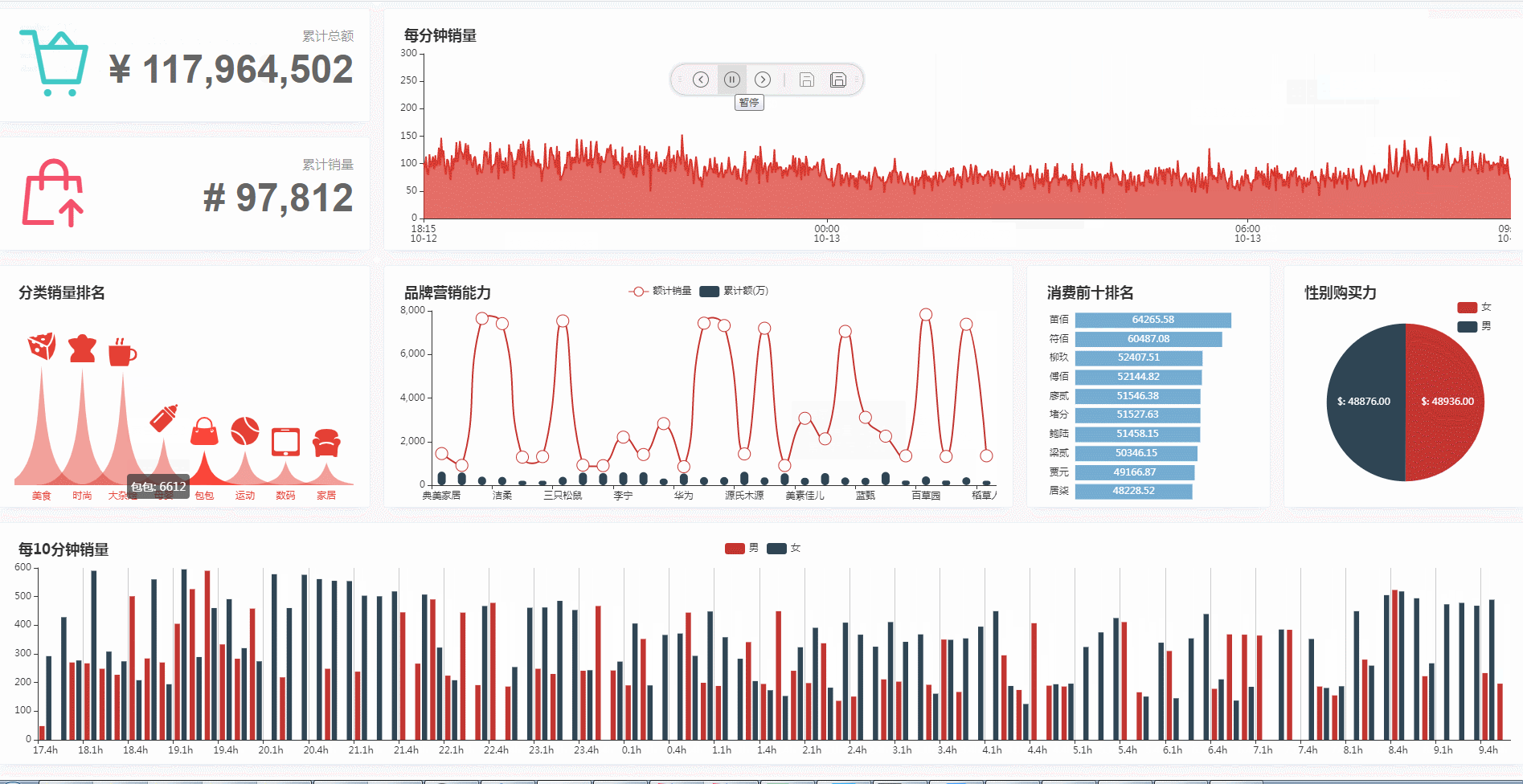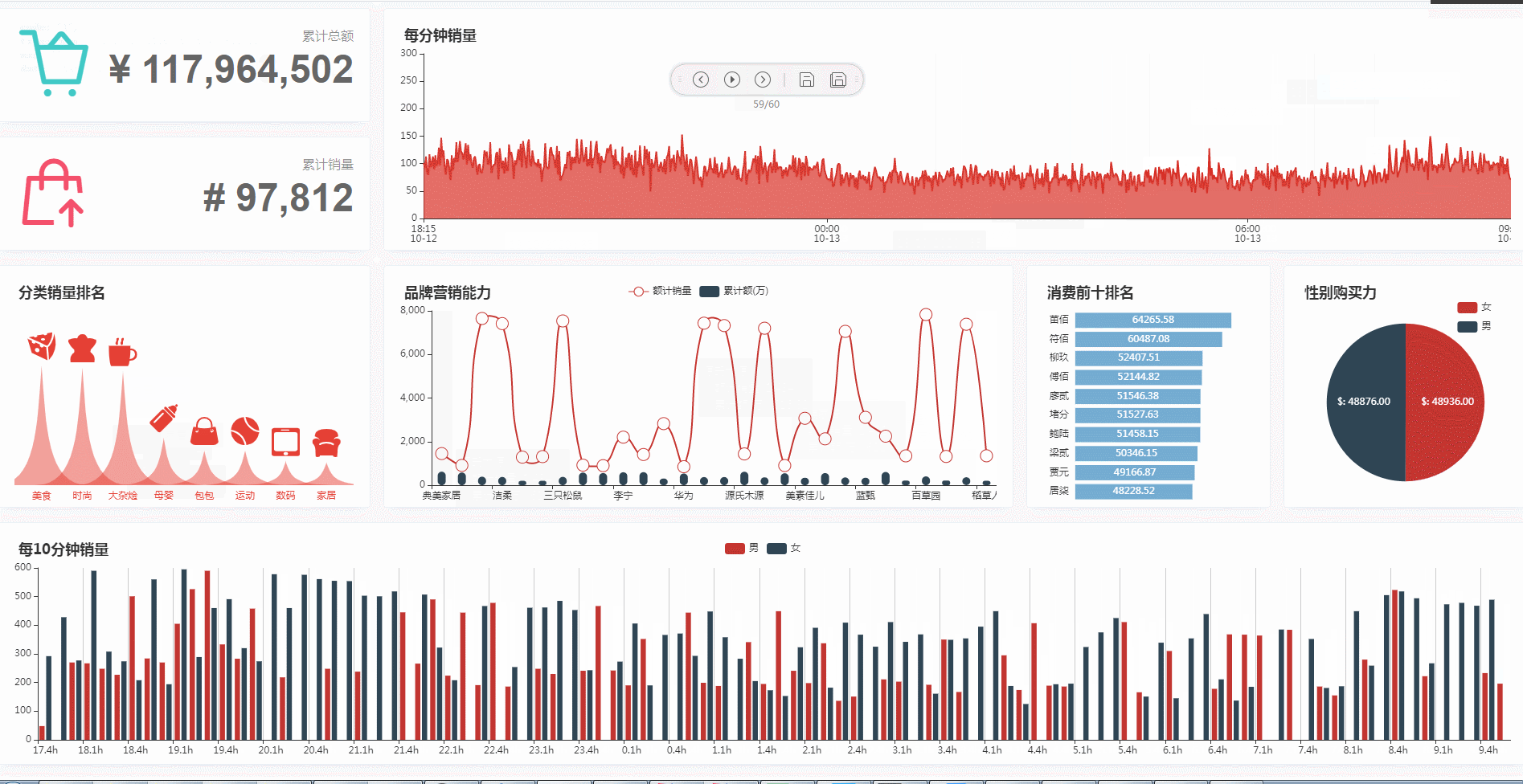
5. 运行效果
6. 项目实战
6.1 前端开发
前端采用 vue2.x + element.ui
主要用到图表展示组件 echarts
进入前端项目根目录,下载安装依赖模块
npminstall安装完毕后,再命令运行前端项目
npmrun dev或打包后上传到 nginx 服务中做静态资源
npmrun build工程目录结构
6.2 后端开发
后端项目与整个 flink 项目示例整合在一个工程项目包内,工程名称叫 flink-examples,其中划分不同的业务模块,以下为工程结构:
flink-examples
------ connectors(中件间连接器示例模块)
------ examples (模拟电商订单数据并推送到 kafka 中,以及 flink 核心流处理客户端)
------ stream(数据流与算子、方法、窗口等示例代码)
------ tableapi(table&sql 与中件间的使用示例代码)
------ web(获取 flink 算子计算后的存储结果,提供给前端展示)
工程依赖
jdk 1.8
springboot 2.3.4.RELEASE
redis 3.x
flink 1.11.1
工程目录结构
工程打包
因工程示例本地已开发完毕,直接进行打包;
# 清理mvnclean -f pom.xml# 打包mvnpackage -f pom.xml模块打包成 jar 包,其中的 examples 模块打包后是独立可运行的客户端,也是上传到 flink 集群平台执行 TaskJOB 的客户端 jar 包;
运行 Flink
启动 Flink 的 Standalone 模式集群服务;
主机:192.168.110.35(master)、192.168.110.35(slaves)
flink 安装目录: /opt/flink-1.11.1
由于已提前搭建好 Standalone 模式集群,则直接进入 master 下直接启动集群。如果未搭建 flink 的 Standalone 模式集群, 参见另一文章: linux 安装 flink 1.11.1
- # 启动flink - cluster
- /opt/flink-1.11.1/bin/start-cluster.sh
- # 停止flink - cluster
- /opt/flink-1.11.1/bin/top-cluster.sh
只需要在 master 主机下启动 flink-cluster 集群,在 master 主服务启动过程中,会执行远程命令启动所有 slaves 从服务;
运行 kafka
启动 Kafka 中件间服务,整个工程项目中,电商平台订单数据存放在 kafka 消息队列中,集成 Flink 的 job 客户端将从 Kafka 消息队列中拉取订单数据;
主机:192.168.110.35(单节点)
kafka 安装目录:/opt/kafka_2.11-2.2.2
由于已提前搭建好 Kafka 中间件,则直接进入安装目录启动消息服务。如果未搭建 Kafka 消息中件间服务, 参见另一文章: linux 安装 kafka 2.2.1
- # 启动zookeeper(单节点)
- bin/zookeeper-server-start.sh -daemon config/zookeeper.properties
- # 后台启动kafka(单节点)bin/kafka-server-start.sh config/server.properties &
- # 停止服务bin/kafka-server-stop.sh config/server.properties
完成此步后,接下来可以访问 flink 平台,运行客户端;
注意问题
在打包后提交到 flink 平台运行过程中有一个 jar 执行错误,如下:
- ERROR org.apache.flink.runtime.webmonitor.handlers.JarRunHandler [] - Unhandled exception.
- java.util.concurrent.CompletionException: org.apache.flink.client.program.ProgramInvocationException: The program's entry point class 'com.flink.examples.StartFlinkKafkaServer' caused an exception during initialization: Invalid signature file digest for Manifest main attributes
原因:是在 mavne 打包过程中某些依赖 jar 包执行出错,以及 jar 包重复引用等,在打成 jar 过程中,META-INF 中多了一些 *.SF,*.DSA,*.RSA 文件导致的(签名摘要文件);
解决方案:
1. 手动解压 jar 包,将 META-INF 中的 *.SF,*.DSA,*.RSA 文件删除后,重新打成 jar 包上传到 Flink 平台;
2. 或者在 pom.xml 中配置 maven 打包插件做过滤
- <plugin>
- <groupId>org.apache.maven.plugins</groupId>
- <artifactId>maven-shade-plugin</artifactId>
- <executions>
- <execution>
- <phase>package</phase>
- <goals>
- <goal>shade</goal>
- </goals>
- </execution>
- </executions>
- <!-- 排除打包过程META-INF目录中多的*.SF,*.DSA,*.RSA文件(签名摘要文件) -->
- <configuration>
- <filters>
- <filter>
- <artifact>*:*</artifact>
- <excludes>
- <exclude>META-INF/*.SF</exclude>
- <exclude>META-INF/*.DSA</exclude><exclude>META-INF/*.RSA</exclude>
- </excludes>
- </filter>
- </filters>
- </configuration>
- </plugin>

6.3 客户端运行
访问管理平台
地址栏访问 flink 管理平台:http://192.168.110.35:8083/
访问端口可在 /opt/flink-1.11.1/conf/flink-conf.yaml 配置中直接修改,本平台配置为 8083;
进入主页
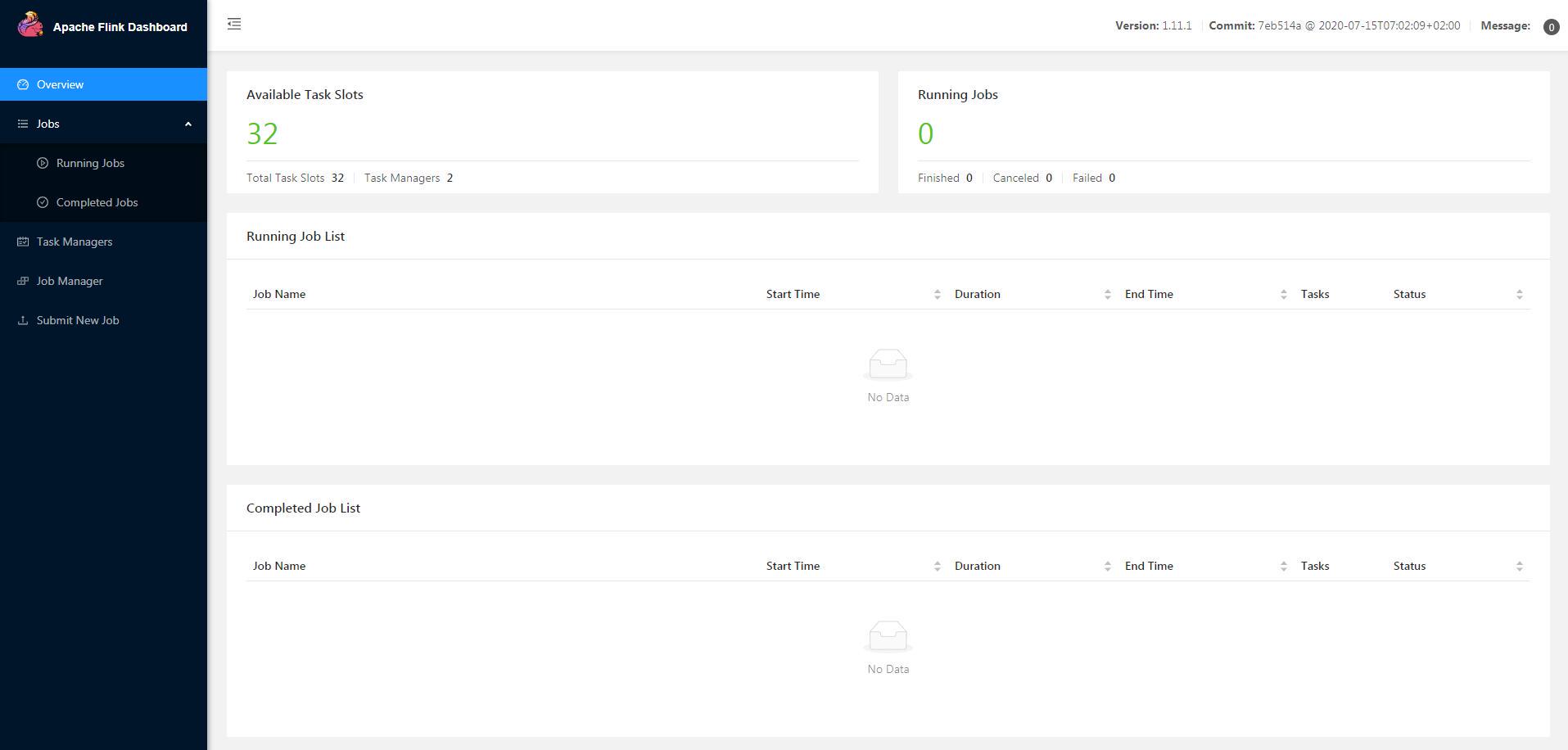
默认进入的是客户端主页,在主页中显示 Available Task Slots = 32(翻译过来叫可用的任务槽),是 Flink 根据 /opt/flink-1.11.1/conf/flink-conf.yaml 配置文件中的 taskmanager.numberOfTaskSlots: 16,识别当前集群的可用总任务数。两台主机的配置相同,CPU 均为 8 核 16 进程,按照一个 Task Slots 分配一个 CPU 进程。因此两台主机累计可用 CPU 核心进程为 32 进程,Total Task Slots 则 Master 和 Slaves 各配置为 16,合计 Total Task Slots = 32,后续在提交运行 Jar 客户端时,需要配置的并行度,即指的就是当前 Available Task Slots 范围内的可用数。但 Available Task Slots 与 Task JOB 的并行度,并不太容易理清关系,按照网上有一个 Flink Task Slots 计算公式:
Flink Available Task Slots = Total Task Slots - 每个任务中的最大并行数(Parallelism)
但我个人的理解,即当前 TaskJOB 中所有算子并行度合计的最大可用数,即为 Flink Available Task Slots 的剩余数;
这个我没有认真去求证,但有一篇博文件可以作为参考来理解 slot ,链接地址 戳我
所以实际生产使用,需要评估 job 客户端 Slots 使用量,以免无法最大化发挥与利用平台有效资源;
新建 Job 客户端
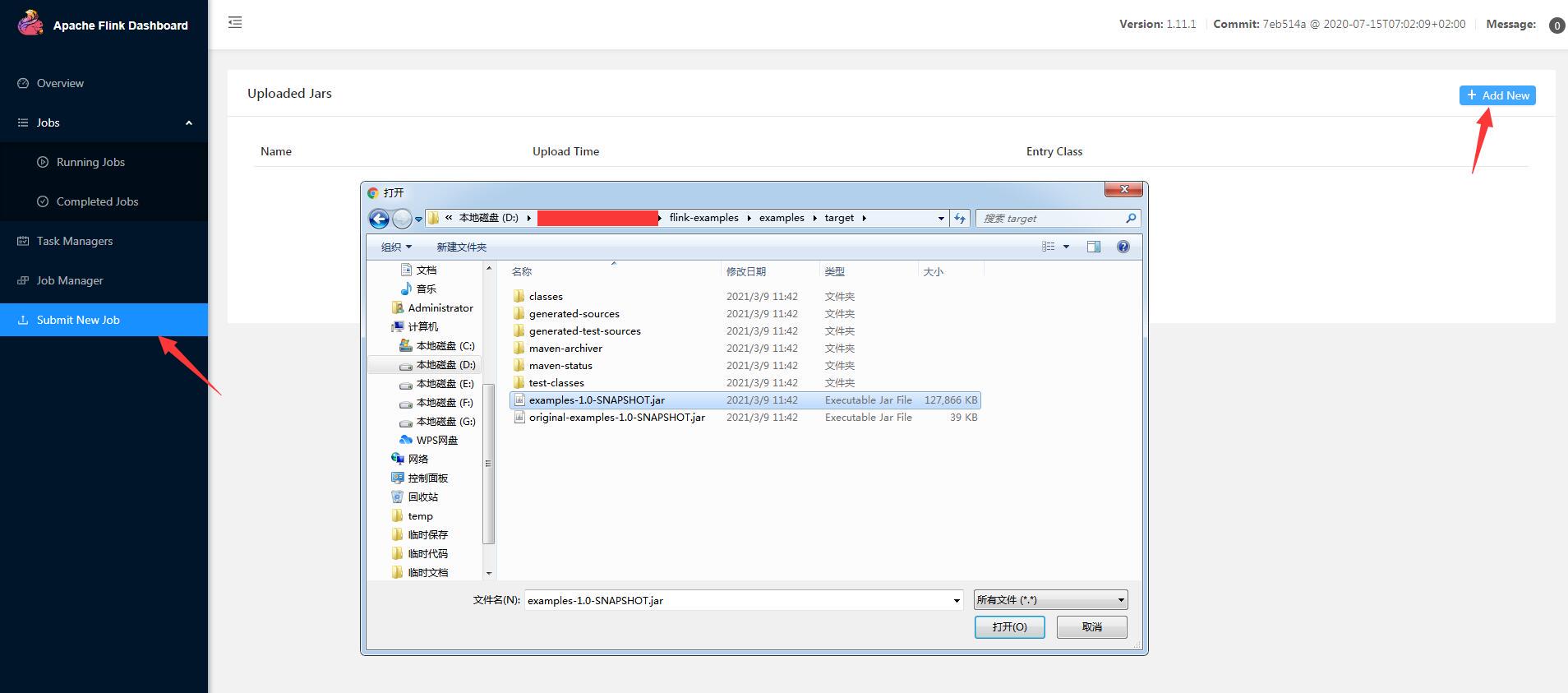
从左侧 Submit New Job 菜单进入,点击 Add New 按钮,在弹出窗口中选择我们上一步打包的 Job 客户端,即 examples 的打包后的 jar 文件,该 jar 文件包含了 flink 开发库、kafka 客户端、redis 客户端等依赖包;点击打开后,开始上传 jar 包,上传速度与网络以及包大小有关;
生产订单

打工本地工程,在 examples 模块源码 的 src》test》java》com.flink.test.CreateKafkaMsg 类中,直接右键》run ,该类模拟创建订单数据并向 kafka 发送订单消息的示例,假设不间断产生电商平台订单数据;
数据结构如下:
消息发送成功:{"orderId":"202103091448348079597","userName":"农元","gender":"男","goods":"家居商品710","goodsType":"家居","brand":"林氏木业","orderTime":"2021-02-19 12:48:34","orderTimeSeries":1615272514807,"price":6999.59,"num":1,"totalPrice":6999.59,"status":"待支付","address":"广西壮族自治区","phone":130000000710}提交 Job

选择 examples-1.0-SNAPSHOT.jar 客户端,在展开的输入框中,按以下内容输入;
Entry Class:com.flink.examples.StartFlinkKafkaServer
Parallelism:16(并行度)
Program Arguments: 参数(无)
Savepoint Path: 打印输出文件路径(无)
点击 Submit,提交 Task Job 作业,Flink 平台分配资源进行执行;
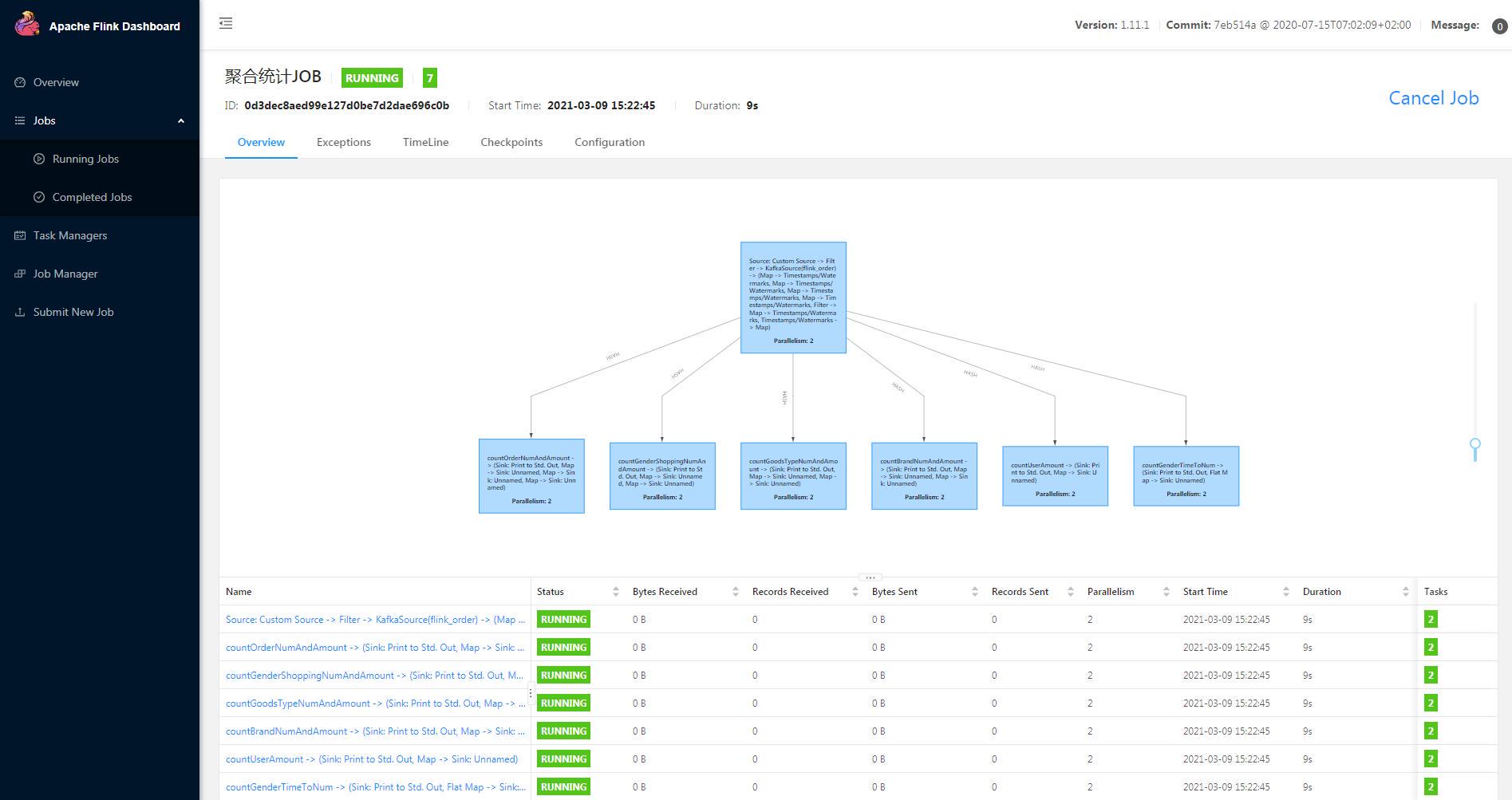
通过平台显示,当前运行算子数量有为 7,其中子节点的 6 个为算子,起始根节点为 source 数据流加载算子方法,采用 flink-kafka 中间件连接器从 kafka 消息队列中获取 mq 订单数据源,分配给不同的业务算子,进行聚合计算;在每个算子的方法中,会将窗口统计数据存储到 redis 中,提供给大屏监控服务的后台使用;
大屏监控

在运行前端项目后,访问 http://127.0.0.1:8010 即后看到大屏监控从后端服务中(后端服务从 redis 中加载指标数据)获取数据生成各维度指标图标。界面在展示过程中,会定时轮询后台服务接口,获取更新数据,刷新前端图表;
6.4 过程分析
采用了一个 Demo 专门模拟生成电商订单数据,不停向 Kafka 推送结构化订单数据,目的是为仿照电商平台架构中的订单生成与数据削峰缓存处理过程;在由 Flink 平台获取 kafka 中的数据流,放到算子中进行聚合计算,输出结果到 redis 中,大屏不停的轮询后台应用获取数据进行展示;流程简单而言:订单》Kafka》Flink》Redis《后台《前端
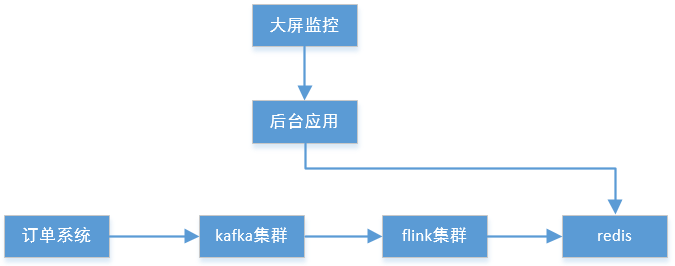
模拟创建订单并推送到 Kafka
CreateKafkaMsg.java
- package com.flink.test;
-
- import com.flink.examples.vo.Order;
- import com.google.gson.Gson;
- import org.apache.commons.lang3.RandomUtils;
- import org.apache.commons.lang3.StringUtils;
- import org.apache.commons.lang3.time.DateFormatUtils;
-
- import java.math.BigDecimal;
- import java.util.Calendar;
- import java.util.HashMap;
- import java.util.Map;
- import java.util.concurrent.TimeUnit;
-
- /**
- * @Description 向kafka发送测试模拟订单数据
- */
- public classCreateKafkaMsg{
-
- staticString upperNames = "赵,钱,孙,李,周,吴,郑,王,冯,陈,褚,卫,蒋,沈,韩,杨,朱,秦,尤,许,何,吕,施,张,孔,曹,严,华,金," +
- "魏,陶,姜,戚,谢,邹,喻,柏,水,窦,章,云,苏,潘,葛,奚,范,彭,郎,鲁,韦,昌,马,苗,凤,花,方,俞,任,袁,柳,酆,鲍,史,唐," +
- "费,廉,岑,薛,雷,贺,倪,汤,滕,殷,罗,毕,郝,邬,安,常,乐,于,时,傅,皮,卞,齐,康,伍,余,元,卜,顾,孟,平,黄,和,穆,萧," +
- "尹,姚,邵,湛,汪,祁,毛,禹,狄,米,贝,明,臧,计,伏,成,戴,谈,宋,茅,庞,熊,纪,舒,屈,项,祝,董,梁,杜,阮,蓝,闵,席,季," +
- "麻,强,贾,路,娄,危,江,童,颜,郭,梅,盛,林,刁,钟,徐,邱,骆,高,夏,蔡,田,樊,胡,凌,霍,虞,万,支,柯,昝,管,卢,莫,经," +
- "房,裘,缪,干,解,应,宗,丁,宣,贲,邓,郁,单,杭,洪,包,诸,左,石,崔,吉,钮,龚,程,嵇,邢,滑,裴,陆,荣,翁,荀,羊,於,惠," +
- "甄,曲,家,封,芮,羿,储,靳,汲,邴,糜,松,井,段,富,巫,乌,焦,巴,弓,牧,隗,山,谷,车,侯,宓,蓬,全,郗,班,仰,秋,仲,伊," +
- "宫,宁,仇,栾,暴,甘,钭,厉,戎,祖,武,符,刘,景,詹,束,龙,叶,幸,司,韶,郜,黎,蓟,薄,印,宿,白,怀,蒲,邰,从,鄂,索,咸," +
- "籍,赖,卓,蔺,屠,蒙,池,乔,阴,胥,能,苍,双,闻,莘,党,翟,谭,贡,劳,逄,姬,申,扶,堵,冉,宰,郦,雍,郤,璩,桑,桂,濮,牛," +
- "寿,通,边,扈,燕,冀,郏,浦,尚,农,温,别,庄,晏,柴,瞿,阎,充,慕,连,茹,习,宦,艾,鱼,容,向,古,易,慎,戈,廖,庾,终,暨," +
- "居,衡,步,都,耿,满,弘,匡,国,文,寇,广,禄,阙,东,欧,殳,沃,利,蔚,越,夔,隆,师,巩,厍,聂,晁,勾,敖,融,冷,訾,辛,阚," +
- "那,简,饶,空,曾,毋,沙,乜,养,鞠,须,丰,巢,关,蒯,相,查,後,荆,红,游,竺,权,逯,盖,益,桓,公";
- staticString upperNums = "壹,贰,叁,肆,伍,陆,柒,捌,玖,拾,佰,仟,万,亿,元,角,分,零";
- staticString [] genders = newString[]{"男", "女"};
- staticString [] goodsTypes = newString[]{"数码", "美食", "时尚", "家居", "运动", "母婴", "大杂烩", "包包"};
- staticMap<String,String> brandMap = new HashMap<String,String>(){
- {
- put("数码","苹果,华为,小米,三星,OPPO");
- put("美食","三只松鼠,百草园,周黑鸭");
- put("时尚","韩衣都舍,南极人,冠军");
- put("家居","林氏木业,典美家居,源氏木源");
- put("运动","乔丹,361度,李宁");
- put("母婴","贝佳美,美素佳儿,蓝甄");
- put("大杂烩","洁柔,云南白药,手巾");
- put("包包","LV,老人头,高尔夫,金狐狸,稻草人");
- }
- };
- staticString [] statuss = newString [] {"待支付","已支付","配送中","已完成"};
- staticString [] addresss = newString [] {"河北省","山西省","辽宁省","吉林省","黑龙江省","江苏省","浙江省","安徽省",
- "福建省","江西省","山东省","河南省","湖北省","湖南省","广东省","海南省","四川省","贵州省","云南省","陕西省",
- "甘肃省","青海省","台湾省","北京市","天津市","上海市","重庆市","广西壮族自治区","内蒙古自治区","西藏自治区",
- "宁夏回族自治区","新疆维吾尔自治区"};
-
- /**
- * 订单信息:
- * 订单ID、用户名称、用户性别、商品名称、商品类型、生产商、下单时间、单价、数量、总价、订单状态、 收货地址、联系方式
- * @param args
- */
- public staticvoid main(String[] args) throws Exception {
- String [] userNames = StringUtils.split(upperNames, ",");
- String [] nums = StringUtils.split(upperNums, ",");
- Map<String, String> genderMap = new HashMap<>();
- Map<String, String> addressMap = new HashMap<>();
-
- //生产者发送消息
- KafkaUtils.KafkaStreamServer kafkaStreamServer = KafkaUtils.bulidServer().createKafkaStreamServer("192.168.xxx.xxx", 9092);
- String topic = "flink_order";
-
- //模拟不停电创建模拟订单
- int i=0;
- while(true){
- String orderId = DateFormatUtils.format(System.currentTimeMillis(), "yyyyMMddHHmmssSSS") + RandomUtils.nextInt(1000 , 9999);
- String userName = userNames[RandomUtils.nextInt(0, userNames.length)] + nums[RandomUtils.nextInt(0, nums.length)];
- String gender = genderMap.get(userName);
- if (gender == null){
- gender = genders[i%2];
- genderMap.put(userName, gender);
- }
-
- String address = addressMap.get(userName);
- if (address == null){
- address = addresss[RandomUtils.nextInt(0, addresss.length)];
- addressMap.put(userName, address);
- }
-
- String goodsType = goodsTypes[RandomUtils.nextInt(0, goodsTypes.length)];
- String goods = goodsType + "商品"+ i;
- String [] brands = brandMap.get(goodsType).split(",");
- String brand = brands[RandomUtils.nextInt(0, brands.length)];
-
- Double price ;
- Integer num ;
- if (goodsType.equals("数码")){
- price = RandomUtils.nextDouble(400.00, 12000.00);
- num = RandomUtils.nextInt(1, 2);
- }elseif (goodsType.equals("家居")){
- price = RandomUtils.nextDouble(300.00, 7000.00);
- num = RandomUtils.nextInt(1, 2);
- }elseif (goodsType.equals("运动")){
- price = RandomUtils.nextDouble(200.00, 4000.00);
- num = RandomUtils.nextInt(1, 3);
- }elseif (goodsType.equals("包包")){
- price = RandomUtils.nextDouble(100.00, 3000.00);
- num = RandomUtils.nextInt(1, 3);
- }elseif (goodsType.equals("母婴")){
- price = RandomUtils.nextDouble(50.00, 2000.00);
- num = RandomUtils.nextInt(1, 4);
- }else {
- price = RandomUtils.nextDouble(20.00, 1000.00);
- num = RandomUtils.nextInt(1, 10);
- }
- BigDecimal priceBig = new BigDecimal(price);
- price = priceBig.setScale(2, BigDecimal.ROUND_HALF_UP).doubleValue();
- //创建总价
- BigDecimal totalPriceBig = new BigDecimal(price * num);
- Double totalPrice = totalPriceBig.setScale(2, BigDecimal.ROUND_HALF_UP).doubleValue();
- //订单生成时间
- Long orderTimeSeries = System.currentTimeMillis();
- String orderTime = DateFormatUtils.format(orderTimeSeries, "yyyy-MM-dd HH:mm:ss");
-
- String status = statuss[RandomUtils.nextInt(0, statuss.length)];
- String phone = String.format("13%s%09d", (i+1)%9, i);
- //订单ID、用户名称、用户性别、商品名称、商品类型、生产商、下单时间、单价、数量、总价、订单状态、 收货地址、联系方式
- Order order = new Order(orderId, userName, gender, goods, goodsType, brand, orderTime, orderTimeSeries , price, num, totalPrice, status, address, Long.parseLong(phone));
- String orderJson = new Gson().toJson(order);
- //System.out.println(orderJson);
- i++;
- //向kafka队列发送数据
- kafkaStreamServer.sendMsg(topic, orderJson);
- //模拟不同时间段的消费量
- Calendar calendar = Calendar.getInstance();
- calendar.setTimeInMillis(orderTimeSeries);
- int h = calendar.get(Calendar.HOUR_OF_DAY);
- int startInt = 700;
- if (8 > h){
- startInt = 1500;
- }elseif (h>=8 && h<18){
- startInt = 300;
- }elseif(h >= 18 && h < 22) {
- startInt = 100;
- }
- //线程休眠
- TimeUnit.MILLISECONDS.sleep(RandomUtils.nextInt(startInt, 3000));
- }
- }
- }
KafkaUtils.java
- package com.flink.test;
-
- import org.apache.kafka.clients.consumer.ConsumerConfig;
- import org.apache.kafka.clients.consumer.ConsumerRecord;
- import org.apache.kafka.clients.consumer.ConsumerRecords;
- import org.apache.kafka.clients.consumer.KafkaConsumer;
- import org.apache.kafka.clients.producer.KafkaProducer;
- import org.apache.kafka.clients.producer.ProducerConfig;
- import org.apache.kafka.clients.producer.ProducerRecord;
- import org.apache.kafka.clients.producer.RecordMetadata;
- import org.apache.kafka.common.serialization.StringDeserializer;
- import org.apache.kafka.common.serialization.StringSerializer;
-
- import java.util.Collections;
- import java.util.Properties;
- import java.util.concurrent.Future;
-
- /**
- * @Description kafka工具类,提供消息发送与监听
- */publicclassKafkaUtils{
-
- /**
- * 获取实始化KafkaStreamServer对象
- * @return
- */publicstatic KafkaStreamServer bulidServer(){
- returnnew KafkaStreamServer();
- }
-
- /**
- * 获取实始化KafkaStreamClient对象
- * @return
- */publicstatic KafkaStreamClient bulidClient(){
- returnnew KafkaStreamClient();
- }
-
- publicstaticclassKafkaStreamServer{
- KafkaProducer<String, String> kafkaProducer = null;
-
- privateKafkaStreamServer(){}
-
- /**
- * 创建配置属性
- * @param host
- * @param port
- * @return
- */public KafkaStreamServer createKafkaStreamServer(String host, int port){
- String bootstrapServers = String.format("%s:%d", host, port);
- if (kafkaProducer != null){
- returnthis;
- }
- Properties properties = new Properties();
- //kafka地址,多个地址用逗号分割
- properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
- properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
- properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
- kafkaProducer = new KafkaProducer<>(properties);
- returnthis;
- }
-
- /**
- * 向kafka服务发送生产者消息
- * @param topic
- * @param msg
- * @return
- */public Future<RecordMetadata> sendMsg(String topic, String msg){
- ProducerRecord<String, String> record = new ProducerRecord<String, String>(topic, msg);
- Future<RecordMetadata> future = kafkaProducer.send(record);
- System.out.println("消息发送成功:" + msg);
- return future;
- }
-
- /**
- * 关闭kafka连接
- */publicvoidclose(){
- if (kafkaProducer != null){
- kafkaProducer.flush();
- kafkaProducer.close();
- kafkaProducer = null;
- }
- }
- }
-
- publicstaticclassKafkaStreamClient{
- KafkaConsumer<String, String> kafkaConsumer = null;
- privateKafkaStreamClient(){}
-
- /**
- * 配置属性,创建消费者
- * @param host
- * @param port
- * @return
- */public KafkaStreamClient createKafkaStreamClient(String host, int port, String groupId){
- String bootstrapServers = String.format("%s:%d", host, port);
- if (kafkaConsumer != null){
- returnthis;
- }
- Properties properties = new Properties();
- //kafka地址,多个地址用逗号分割
- properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
- properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
- properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
- properties.put(ConsumerConfig.GROUP_ID_CONFIG, groupId);
- kafkaConsumer = new KafkaConsumer<String, String>(properties);
- returnthis;
- }
-
- /**
- * 客户端消费者拉取消息,并通过回调HeaderInterface实现类传递消息
- * @param topic
- * @param headerInterface
- */publicvoidpollMsg(String topic, HeaderInterface headerInterface){
- kafkaConsumer.subscribe(Collections.singletonList(topic));
- while (true) {
- ConsumerRecords<String, String> records = kafkaConsumer.poll(100);
- for (ConsumerRecord<String, String> record : records) {
- try{
- headerInterface.execute(record);
- }catch(Exception e){
- e.printStackTrace();
- }
- }
- }
- }
-
- /**
- * 关闭kafka连接
- */publicvoidclose(){
- if (kafkaConsumer != null){
- kafkaConsumer.close();
- kafkaConsumer = null;
- }
- }
- }
-
- @FunctionalInterfaceinterfaceHeaderInterface{
- voidexecute(ConsumerRecord<String, String> record);
- }
-
- /**
- * 测试示例
- * @param args
- * @throws InterruptedException
- */publicstaticvoidmain(String[] args)throws InterruptedException {
- //生产者发送消息
- // KafkaStreamServer kafkaStreamServer = KafkaUtils.bulidServer().createKafkaStreamServer("192.168.xxx.xxx", 9092);
- // int i=0;
- // while (i<10) {
- // String msg = "Hello," + new Random().nextInt(100);
- // kafkaStreamServer.sendMsg("test", msg);
- // i++;
- // Thread.sleep(500);
- // }
- // kafkaStreamServer.close();
- // System.out.println("发送结束");
-
- System.out.println("接收消息");
- KafkaStreamClient kafkaStreamClient = KafkaUtils.bulidClient().createKafkaStreamClient("192.168.xxx.xxx", 9092, "consumer-45");
- kafkaStreamClient.pollMsg("test", new HeaderInterface() {
- @Overridepublicvoidexecute(ConsumerRecord<String, String> record){
- System.out.println(String.format("topic:%s,offset:%d,消息:%s", record.topic(), record.offset(), record.value()));
- }
- });
-
- }
-
- }
实时聚合计算
从 Kafka 中获取数据,将源源不断的数据流分别按不同的统计业务场景,分别在不同的算子与窗口下进行聚合计算。
StartFlinkKafkaServer.java
- package com.flink.examples;
-
- import com.flink.examples.service.FlinkCountService;
- import com.flink.examples.service.QuotaEnum;
- import com.flink.examples.sink.RedisDataRichSink;
- import com.flink.examples.source.KafkaSourceFunction;
- import com.flink.examples.vo.Order;
- import com.google.gson.Gson;
- import org.apache.commons.lang3.time.DateFormatUtils;
- import org.apache.commons.lang3.time.DateUtils;
- import org.apache.flink.api.common.eventtime.WatermarkStrategy;
- import org.apache.flink.api.common.functions.FilterFunction;
- import org.apache.flink.api.common.functions.FlatMapFunction;
- import org.apache.flink.api.common.functions.MapFunction;
- import org.apache.flink.api.common.typeinfo.Types;
- import org.apache.flink.api.java.functions.KeySelector;
- import org.apache.flink.api.java.tuple.Tuple2;
- import org.apache.flink.api.java.tuple.Tuple3;
- import org.apache.flink.streaming.api.CheckpointingMode;
- import org.apache.flink.streaming.api.TimeCharacteristic;
- import org.apache.flink.streaming.api.datastream.DataStream;
- import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
- import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
- import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
- import org.apache.flink.streaming.api.windowing.time.Time;
- import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
- import org.apache.flink.streaming.connectors.redis.common.mapper.RedisCommand;
- import org.apache.flink.util.Collector;
- import org.slf4j.Logger;
- import org.slf4j.LoggerFactory;
-
- import java.math.BigDecimal;
- import java.time.Duration;
- import java.util.*;
-
- /**
- * @Description Flink数据流实时计算示例:启动对接kafka数据流处理flink业务服务job,模拟对用户消费订单信息多维度聚合统计;
- */publicclass StartFlinkKafkaServer {
- static Logger logger = LoggerFactory.getLogger(StartFlinkKafkaServer.class);
- /**
- * 窗口事件时间
- */static final int EVENT_TIME = 5;
-
- /**
- * 主进程方法
- * @param args
- * @throws Exception
- */publicstaticvoid main(String[] args) {
- System.out.println("out:开始启动StartFlinkKafkaServer服务");
- logger.info("开始启动StartFlinkKafkaServer服务");
- //无界数据流
- StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
- //设置并行度
- env.setParallelism(2);
- //每隔5000ms进行启动一个检查点
- env.enableCheckpointing(5000);
- //设置模式为exactly-once
- env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
- // 确保检查点之间有进行500 ms的进度
- env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);
- //注意此处,必需设为TimeCharacteristic.EventTime,表示采用数据流元素事件时间(可以是元素时间字段、也可以自定义系统时间)
- env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
- //读取数据源
- KafkaSourceFunction kafkaSourceFunction = new KafkaSourceFunction();
- DataStream<Order> source = kafkaSourceFunction.run(env, "flink_order");
- //统计订单总量和总额、最新订单窗口总量
- countOrderNumAndAmount(source);
- //按性别统计订单总量和总额
- countGenderShoppingNumAndAmount(source);
- //按商品类型统计订单总量和总额
- countGoodsTypeNumAndAmount(source);
- //按品牌统计订单总量和总额
- countBrandNumAndAmount(source);
- //统计用户消费总额
- countUserAmount(source);
- //按性别统计每10分钟消费订单总量
- countGenderTimeToNum(source);
- System.out.println("out:执行job任务");
- logger.info("执行job任务");
- //执行JOBtry {
- env.execute("聚合统计JOB");
- }catch(Exception e){
- logger.error("聚合统计JOB,执行异常!", e);
- }
- }
-
- /**
- * 统计销量和销售额、最新订单窗口总量
- * @param orderDataStream
- */privatestaticvoid countOrderNumAndAmount(DataStream<Order> orderDataStream){
- DataStream<Tuple3<String, Integer, BigDecimal>> output =
- FlinkCountService.commonCount("countOrderNumAndAmount", QuotaEnum.DEFAULT, orderDataStream, RedisCommand.SET,"FLINK_ORDER_TOTAL_NUM", "FLINK_ORDER_TOTAL_PRICE", true);
- //保存每次窗口统计总销量结果到redis中,注意此数据只取窗口最新值,将会复盖db存储中的值
- output.map(new MapFunction<Tuple3<String, Integer, BigDecimal>, Tuple2<String,String>>() {
- @Overridepublic Tuple2<String,String> map(Tuple3<String, Integer, BigDecimal> t3) throws Exception {
- return Tuple2.of(null, System.currentTimeMillis() + ":" + t3.f1);
- }
- }).addSink(new RedisDataRichSink("FLINK_ORDER_TIME_NUM", RedisCommand.SET, false));
- }
-
- /**
- * 按性别统计总量和累计额
- * @param orderDataStream
- */privatestaticvoid countGenderShoppingNumAndAmount(DataStream<Order> orderDataStream){
- FlinkCountService.commonCount("countGenderShoppingNumAndAmount", QuotaEnum.GENDER, orderDataStream, RedisCommand.HSET,"FLINK_ORDER_GENDER_TOTAL_NUM", "FLINK_ORDER_GENDER_TOTAL_PRICE", true);
- }
-
- /**
- * 按商品分类统计总量和累计额
- * @param orderDataStream
- */privatestaticvoid countGoodsTypeNumAndAmount(DataStream<Order> orderDataStream){
- FlinkCountService.commonCount("countGoodsTypeNumAndAmount", QuotaEnum.GOODS_TYPE, orderDataStream, RedisCommand.HSET,"FLINK_ORDER_GOODS_TYPE_TOTAL_NUM", "FLINK_ORDER_GOODS_TYPE_TOTAL_PRICE", true);
- }
-
- /**
- * 按品牌统计总量和累计额
- * @param orderDataStream
- */privatestaticvoid countBrandNumAndAmount(DataStream<Order> orderDataStream){
- FlinkCountService.commonCount("countBrandNumAndAmount", QuotaEnum.BRAND, orderDataStream, RedisCommand.HSET, "FLINK_ORDER_BRAND_TOTAL_NUM", "FLINK_ORDER_BRAND_TOTAL_PRICE", true);
- }
-
- /**
- * 统计用户消费累计额
- * @param orderDataStream
- */privatestaticvoid countUserAmount(DataStream<Order> orderDataStream){
- //单次消费低于3000的不入库(有可能会存在,用户持续消费,但每次小于1000,实际累计额较大的情况,可根据需要调整)
- orderDataStream = orderDataStream.filter((FilterFunction<Order>) value -> value.getTotalPrice() > 3000.0);
- FlinkCountService.commonCount("countUserAmount", QuotaEnum.USER, orderDataStream, RedisCommand.HSET, null, "FLINK_ORDER_USER_RANKING", true);
- }
-
- /**
- * 按性别统计每5分钟下单总量,并计录下单时间(单独流处理)
- * @param orderDataStream
- */privatestaticvoid countGenderTimeToNum(DataStream<Order> orderDataStream){
- DataStream<Map<String, Map<String,Integer>>> output = orderDataStream
- .assignTimestampsAndWatermarks(
- WatermarkStrategy.<Order>forBoundedOutOfOrderness(Duration.ofSeconds(5))
- .withTimestampAssigner((element, timestamp) -> {
- return element.getOrderTimeSeries();
- })
- )
- .map(new MapFunction<Order, Tuple3<String, Integer, Long>>() {
- @Overridepublic Tuple3<String, Integer, Long> map(Order order) throws Exception {
- return Tuple3.of(order.getGender(), order.getNum(), order.getOrderTimeSeries());
- }
- })
- .returns(Types.TUPLE(Types.STRING, Types.INT, Types.LONG))
- .keyBy((KeySelector<Tuple3<String, Integer, Long>, String>) k ->k.f0)
- //按5分钟为一个滚动窗口
- .window(TumblingEventTimeWindows.of(Time.minutes(EVENT_TIME)))
- //处理窗口下的所有数据
- .process(new ProcessWindowFunction<Tuple3<String,Integer,Long>, Map<String, Map<String,Integer>>, String, TimeWindow>() {
- /**
- * 按每10分钟时间分区统计,计算一次性别下各自订单总量
- * @param k keyBy分区字段
- * @param context 上下文对象
- * @param input 窗口输入数据集合
- * @param out 输出的数据集合
- * @throws Exception
- */@Overridepublicvoid process(String k, Context context, Iterable<Tuple3<String, Integer, Long>> input, Collector<Map<String, Map<String,Integer>>> out) throws Exception {
- long start = context.window().getStart();
- long end = context.window().getEnd();
- System.err.println("计算窗口时间周期,startTime:" + DateFormatUtils.format(start, "yyyy-MM-dd HH:mm:ss") + ", endTime:" + DateFormatUtils.format(end, "yyyy-MM-dd HH:mm:ss"));
-
- Iterator<Tuple3<String, Integer, Long>> iterator = input.iterator();
- Map<String, Map<String,Integer>> map= new HashMap<>();
- Tuple3<String, Integer, Long> tuple3;
- String key;
- Integer val;
- Integer num;
- Date orderTime;
- Map<String,Integer> genderMap;
- while (iterator.hasNext()){
- tuple3 = iterator.next();
- val = null;
- num = tuple3.f1;
- orderTime = newDate();
- long h = DateUtils.getFragmentInHours(orderTime, Calendar.DAY_OF_YEAR);
- long m = DateUtils.getFragmentInMinutes(orderTime, Calendar.HOUR_OF_DAY);
- //key = 1.2h
- key = h +"."+(m>9 ? (m/10+1) : 1) + "h";
- genderMap = map.get(key) ;
- if (genderMap == null){
- genderMap = new HashMap<>(2);
- }else {
- val = genderMap.get(k);
- }
- val = (val == null) ? 0 : val;
- genderMap.put(k, val.intValue() + num.intValue());
- //key = 1.2h, value = {男:11,女:22}
- map.put(key, genderMap);
- }
- out.collect(map);
- }
- })
- .name("countGenderTimeToNum");
- output.print();
-
- //数据结构:key,1h,{男:11,女:22}
- //保存到redis中
- output.flatMap(new FlatMapFunction<Map<String,Map<String,Integer>>, Tuple2<String,String>>() {
- @Overridepublicvoid flatMap(Map<String, Map<String, Integer>> input, Collector<Tuple2<String, String>> out) throws Exception {
- input.forEach((k,v) -> out.collect(Tuple2.of(k, new Gson().toJson(v))));
- }
- }).addSink(new RedisDataRichSink("FLINK_ORDER_GENDER_TIME_NUM", RedisCommand.HSET, true));
- }
-
- }
其它略..... 以工程源码为主;
JOB 任务管理
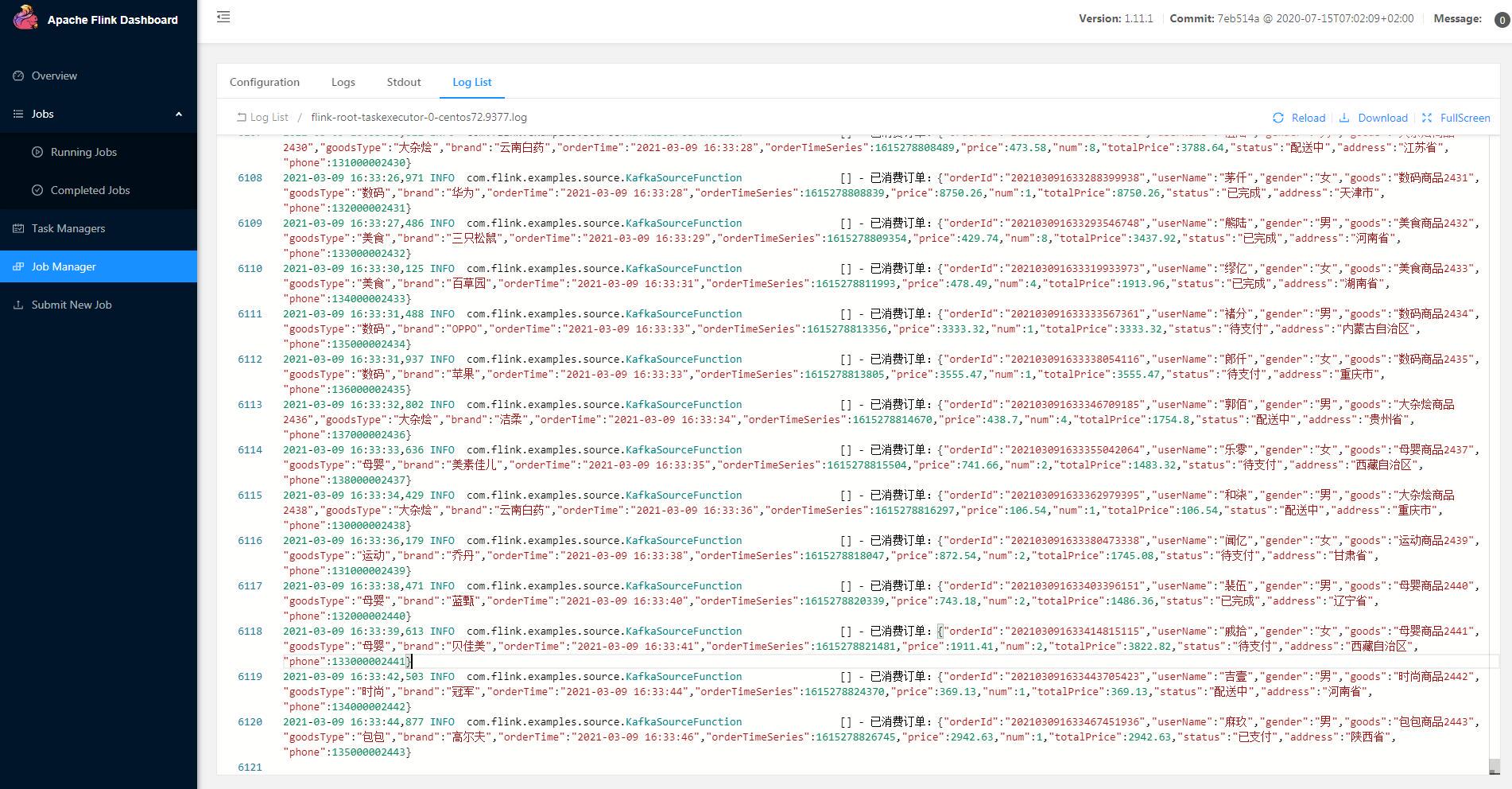
当 JOB 作业提交到到 Flink 平台后,为了确认 Jar 客户端的运行情况,除了在 Job 作业详情总览界面上查看算子运行状态外,还可以在 Jar 客户端正常运行过程中,从 Flink Dashboard 平台 JobManager 中查看作业的执行日志,用于分析与排查 TaskJob 作业的执行情况,也可以将开发过程中,需要的程序日志信息等在此功能窗口中打印用于数据跟踪;
7. 总结
整个学习与开发过程,几乎没有的理论性的长篇总结,主要以场景为切入点,通过示例实践了解整个流程:
1.flink 客户端可以在本地开发环境上运行,同理也可以部署在独立服务器上单节点运行,但采用 flink 通常需要考虑大规则的数据应用场景,服务架构以集群为主,分为 on Yarn 和 Standalone 两种集群模式。
2.flink 提供中间件连接器,可以将一个中间件的数据做为输入通道,如:es,mysql,redis,mq 等,做为源源不断的数据来源,写入到 Flink 的数据(批)流中,通过将数据流按窗口、水印等放到一个或分多个计算算子中,进行聚合计算,在将计算结果进行合并或归类,再通过中间件连接器将结果输出到中间件中(es,mysql,redis 等);
3. 一旦提交启用 Flink 客户端后,Flink 会一直处于运行中(无输出源,则批流处理完毕打印日志后 JOB 停止),不断的按时长或数量等窗口分段滑动或滚动模式计算周期内的数据。
4.flink 可以通过 dataStreamApi 开发客户端算子和数输流输入输出功能,也同样可以用 Table SQL 开发相同功能;
此示例只是为了演示一个电商平台的数据流实时处理过程,但生产环境下实时计算方案大同小异,相差的只是业务场景的不一样;
8. 工程源码
Gitee: https://gitee.com/omsgit/flink-examples
内容未做仔细审稿,如有错误,敬请指出;
技术无止境,学的越多,忘的越多 (^_^)!,了解的越多,也越觉得自已很渺小;长路漫漫,与君共勉!

