
- 1武汉科技大学自动控制原理2007_武汉科技大学各专业历年考研专业课真题汇编...
- 2微信小程序| 打造ChatGPT英语四六级背单词小程序_小程序搭建chatapp
- 3yolov8 tracking编码为web 和 rtsp流输出_yolov8 rtsp
- 4Spring Boot 快速实现 IP 地址解析!_springboot获取ip地址
- 5wsl装ubuntu的home目录在哪,如何更改home?_wsl ubuntu 安装路径
- 6react+ echarts 轮播饼图
- 7人机协同的“星火”,何时能有燎原之势?
- 8数据结构学习(考研408)
- 9remix Web3 provider连接不上探究_remix没有web3
- 10报错解决error: OpenCV(4.8.0) D:\a\opencv-python\opencv-python\opencv\modules\highgui\src\window.cpp:1255_error: opencv(4.9.0) d:\a\opencv-python\opencv-pyt
十大排序——11.十大排序的比较汇总及Java中自带的排序算法
赞
踩
这篇文章对排序算法进行一个汇总比较!
目录
0.十大排序汇总
0.1概述
一图以蔽之:
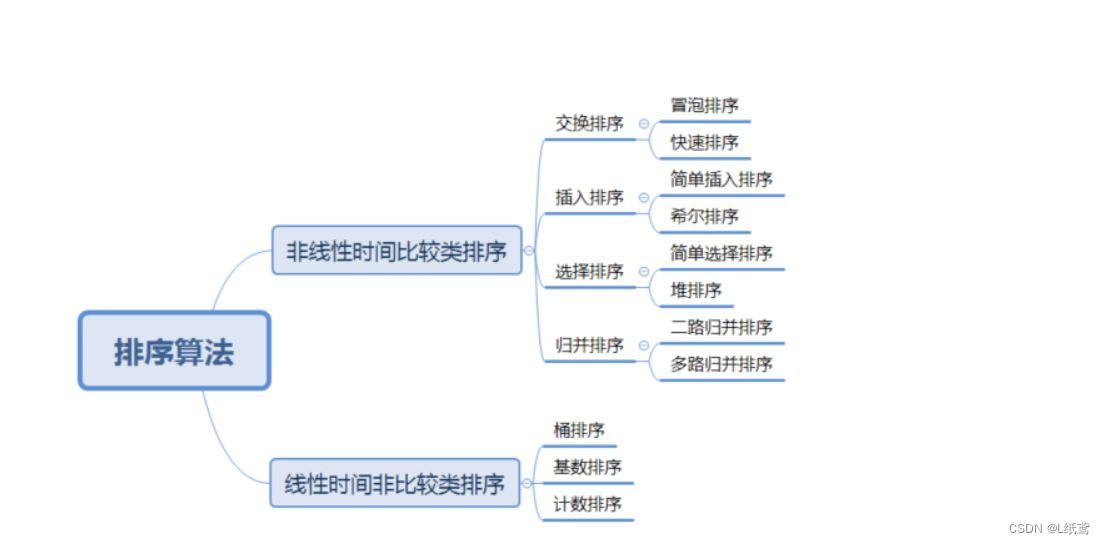
0.2比较和非比较的区别
常见的快速排序、归并排序、堆排序、冒泡排序等属于比较排序。在排序的最终结果里,元素之间的次序依赖于它们之间的比较。每个数都必须和其他数进行比较,才能确定自己的位置。
在冒泡排序之类的排序中,问题规模为 n,又因为需要比较 n 次,所以平均时间复杂度为O(n²)。
在归并排序、快速排序之类的排序中,问题规模通过分治法消减为 logN 次,所以时间复杂度平均O(nlogn)。
比较排序的优势是:适用于各种规模的数据,也不在乎数据的分布,都能进行排序。可以说,比较排序适用于一切需要排序的情况。
计数排序、基数排序、桶排序则属于非比较排序。非比较排序是通过确定每个元素之前,应该有多少个元素来排序。针对数组 arr,计算 arr 之前有多少个元素,则唯一确定了 arr 在排序后数组中的位置。
非比较排序只要确定每个元素之前的已有的元素个数即可,所有一次遍历即可解决。算法时间复杂度O(n)。
非比较排序时间复杂度底,但由于非比较排序需要占用空间来确定唯一位置。所以对数据规模和数据分布有一定的要求。
0.3基本术语
稳定:如果a原本在b前面,而a=b,排序之后a仍然在b的前面;
不稳定:如果a原本在b的前面,而a=b,排序之后a可能出现在b的后面;
内排序:所有的排序操作都在内存中完成;
外排序:由于数据太大,因此把数据放在磁盘中,而排序通过磁盘和内存的数据传输才能进行;
时间复杂度:一个算法执行所消耗的时间;
空间复杂度:运行完一个程序所需内存的大小。
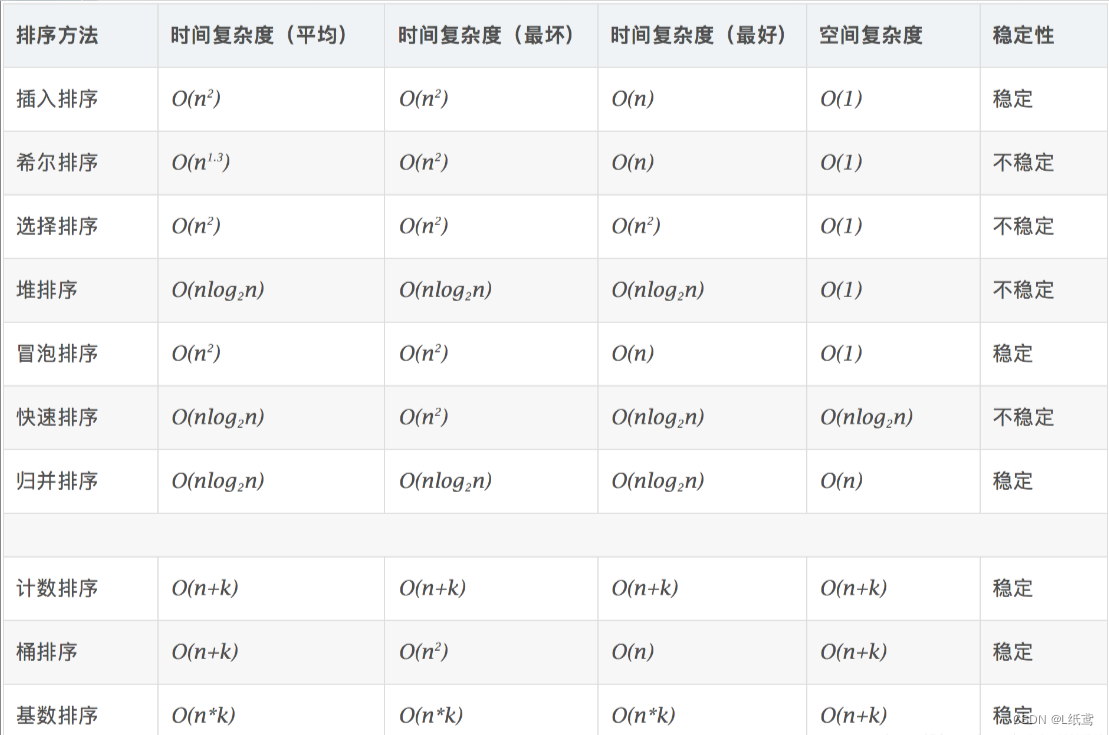
0.4排序算法的复杂度及稳定性
1.冒泡排序
算法简介
1. 从左向右依次对比相邻元素,将较大值交换到右边;
2. 每一轮循环可将最大值交换到最左边
3. 重复1.2两个步骤,直至完成整个数组。
动图演示
代码演示
- package Sorts;
-
- import java.util.Arrays;
- //冒泡排序
- public class MaoPaoSort {
- public static void main(String[] args) {
- int[] arr = new int []{5,9,2,7,3,1,10};
- maoPaoSort(arr);
- System.out.println(Arrays.toString(arr));
- }
-
- public static void maoPaoSort(int[]arr){
- for (int i = 0; i <arr.length ; i++) {
- for (int j = 0; j <arr.length-1 ; j++) {
- if (arr[j] > arr[j+1]){//这是比较相邻的元素
- int temp = arr[j];
- arr[j]=arr[j+1];
- arr[j+1]=temp;
- }
- }
- }
- }
- }

应用场景
一般在学习的时候作为理解排序原理的时候使用,在实际应用中不会使用
算法分析
最佳情况:T ( n ) = O ( n )
最差情况:T ( n ) = O ( n^2 )
平均情况:T ( n ) = O ( n^2 )
2.快速排序
算法简介
- 选择一个元素赋值给中间元素temp,默认选择左边第一个元素,这样左边第一个元素的位置就空出来了;
- 先从最右边的元素开始依次跟temp比较大小,大于等于temp元素的原地不动,遇到小于temp元素的则终止循环,把该元素赋值到左侧空出来的位置,同时左侧索引值自增,这是该元素原来的位置就空出;
- 然后左侧元素开始依次跟temp比较大小,小于等于temp元素的原地不动,遇到大雨temp元素的则终止循环,把该元素赋值到右侧空出来的位置,同时右侧索引值自减;
- 依次循环2,3步,直至左侧索引等于右侧索引,则完成一轮循环,把哨兵赋值到该索引的位置。
- 在分别递归地对 temp 左右两侧的子数组进行1234步,直至递归子数组只有一个元素则排序完成
动图演示
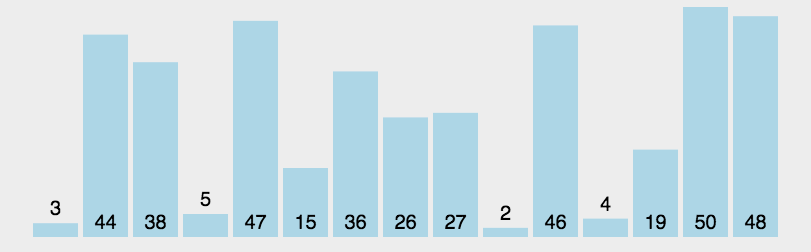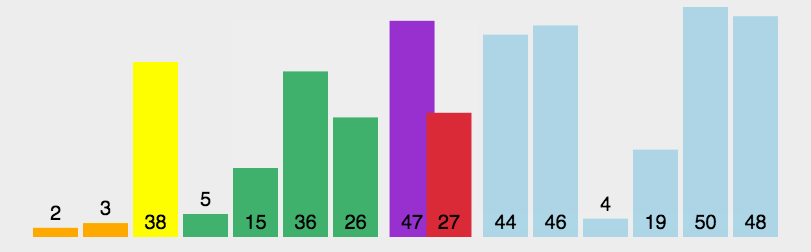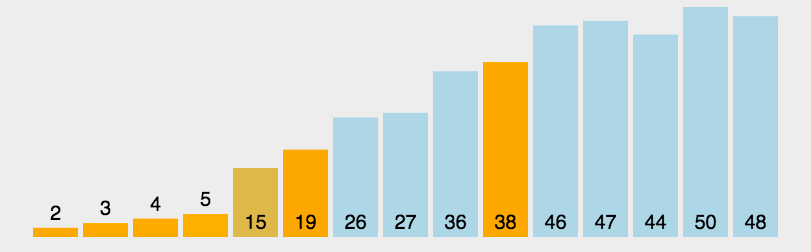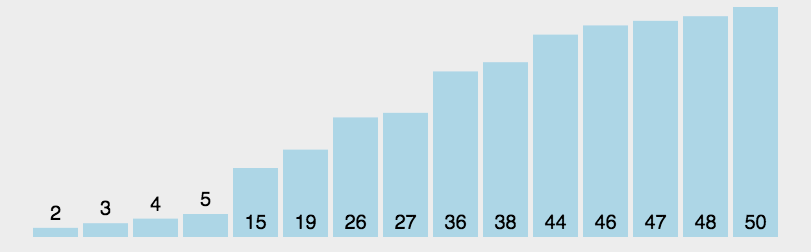
代码演示
- package Sorts;
-
- import java.util.Arrays;
- import java.util.concurrent.ThreadLocalRandom;
- //快排
- public class QuickSort {
- public static void main(String[] args) {
- int[] array = {16,13,7,15,28,11,9,32,22,19};
- int[] array1 = {4,2,1,3,2,4};
- System.out.println("排序前:"+ Arrays.toString(array1));
- sort(array1);
- System.out.println("排序后:"+ Arrays.toString(array1));
-
- }
- /**
- * 交换操作
- * */
- private static void swap(int[] array,int i,int j){
- int t = array[i];
- array[i] = array[j];
- array[j] = t;
- }
- /**
- * 排序的函数
- * */
- private static void sort(int[] array) {
- quick(array,0,array.length-1);
- }
- /**
- * 递归的函数
- * */
- private static void quick(int[] array, int left, int right) {
- //结束递归的条件,如果我们左边的索引大于或等于右边的索引了(最多只能等于,不可能大于),那说明就只有一个元素的了,那就不用递归了
- if (left>=right){
- return;
- }
- int p = partition4(array,left,right); //p代表基准点元素的索引
- quick(array,left,p-1); // 对基准点左边的区进行递归操作
- quick(array,p+1,right); // 对基准点右边的区进行递归操作
- }
- /**
- * 分区并进行比较然后排序的函数(这部分是核心代码)
- * 单边快排
- * */
- private static int partition1(int[] array, int left, int right) {
- int pv = array[right]; //基准点的值
- int i = left;
- int j = left;
- while (j<right){ //当j小于右边届的时候,j就要+1
- if (array[j]<pv){ //j找到比基准点小的值
- if (i!=j){
- swap(array,i,j);
- }
- /**
- * 这里多说一点
- * i与j都是从left开始的,初始指向是一致的,i找大的,j找小的
- * 进入这个判断,就是说明j找到小的了
- * 没进入这个判断,就是说明j没有找到小的,也就是说此时j指向的值大于等于基准值
- * 因为i与j的指向在初始时是一致的
- * 所以没进入这个判断时,i指向的值就比基准值大了
- * 所以i就找到了,不用+1了
- * 但是j没有找到
- * 所以j要+1
- * 这就是i++在里面;j++在外面的原因
- * 如果进入这个判断,即j找到小的了,此时i在哪?
- * i在j前面或者和i在同一个位置,看代码就能想清楚
- * 有没有可能j找到小的了,然后不走了,i没找到继续走,然后在j后面找到大的了?
- * 这种情况就没必要交换了,并且这种情况进不来这个判断
- * */
- i++;
- }
- j++;
- }
- swap(array,i,right); //交换基准点与i的位置,此时i记录的就是基准点的位置
- return i;
- }
- /**
- * 双边快排
- * */
- private static int partition2(int[] array, int left, int right) {
- int pv = array[left]; //基准点的值
- int i = left; //游标i,从最左边开始,找大的
- int j = right; //游标j,从最右边开始,找小的
-
- while (i < j){ //i<j的时候进行循环,一旦i=j或i>j,就要退出循环
- while (i < j && array[j] > pv){//找比基准点小的值,没找到j就--,一旦找到,就退出循环
- j--;
- }
- // while (i<j && array[i]<pv)
- while (i<j && array[i]<=pv){//找比基准点大的值,没找到i就++,一旦找到,就退出循环
- i++;
- }
- swap(array,i,j);//交换
- }
- swap(array,left,i);
- return i;
- }
- /**
- * 定义随机的基准点
- * */
- private static int partition3(int[] array, int left, int right) {
- int idx = ThreadLocalRandom.current().nextInt(right-left+1)+left;//生成范围内的随机数
- swap(array,idx,left);//交换随机数与left的值
- int pv = array[left];//基准点的值
- int i = left; //游标i,从最左边开始,找大的
- int j = right; //游标j,从最右边开始,找小的
-
- while (i < j){ //i<j的时候进行循环,一旦i=j或i>j,就要退出循环
- while (i < j && array[j] > pv){//找比基准点小的值,没找到j就--,一旦找到,就退出循环
- j--;
- }
- while (i<j && array[i]<=pv){//找比基准点大的值,没找到i就++,一旦找到,就退出循环
- i++;
- }
- swap(array,i,j);//交换
- }
- swap(array,left,i);
- return i;
- }
- /**
- * 改进后的算法
- * 为了处理重复的元素
- * */
- private static int partition4(int[] array, int left, int right) {
- int pv = array[left];//基准点的值
- int i = left+1; //游标i,从left+1开始,找大的
- int j = right; //游标j,从最右边开始,找小的
-
- while (i <= j){ //i<=j的时候进行循环,一旦i>j,就要退出循环,当i=j的时候也要进入循环
- while (i <= j && array[j] > pv){//找比基准点小或等于的值,没找到j就--,一旦找到,就退出循环
- j--;
- }
- while (i<=j && array[i] < pv){//找比基准点大或相等的值,没找到i就++,一旦找到,就退出循环
- i++;
- }
- if (i<=j){
- swap(array,i,j);//交换
- i++;
- j--;
- }
- }
- swap(array,left,j);
- return j;
- }
- }
应用场景
略
算法分析
最佳情况:T ( n ) = O ( nlogn )
最差情况:T ( n ) = O ( n^2 )
平均情况:T ( n ) = O ( nlogn )
3.插入排序
算法简介
- 左边第一个元素可作为有序子数组;
- 从第二个元素开始,依次向前比较,大于该元素的则向右移一位,直到比该元素小的元素,插入其后;
- 依次向后推进,直至整个数组成为有序数组
动图演示
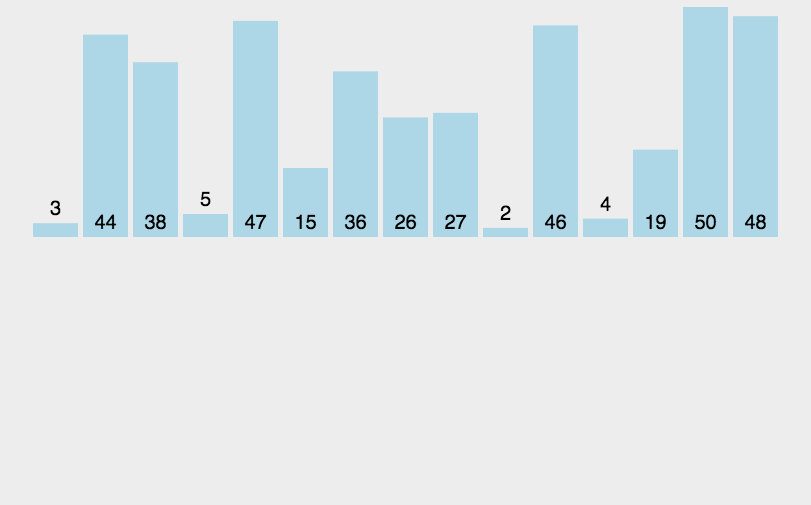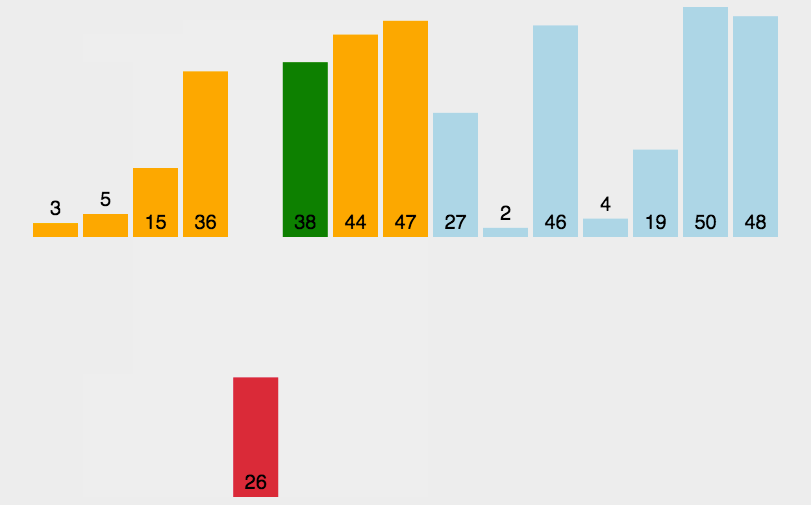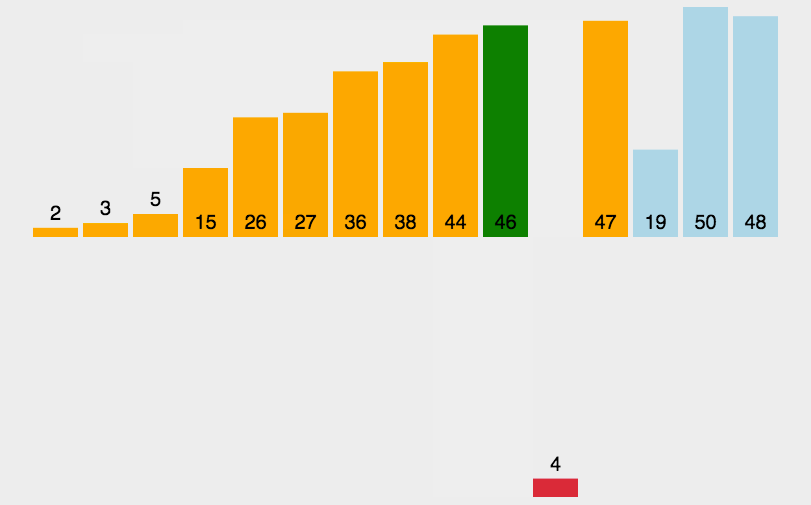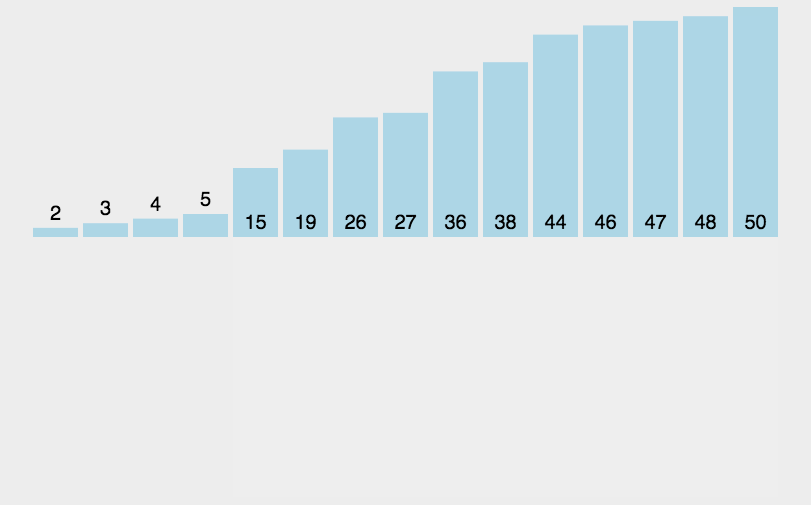
代码演示
- package Sorts;
-
- import java.util.Arrays;
- //插入排序
- public class InsertSort {
- public static void main(String[] args) {
- int [] arr = new int[]{5,9,2,7,3,1,10};
- Insert2(arr);
- System.out.println(Arrays.toString(arr));
- }
- //递归版的方法
- public static void Insert1(int[]arr, int low){
- if (low == arr.length)
- return;
- int t = arr[low];
- int i = low-1;
- //从右向左找插入位置,如果比待插入元素大,则不断右移,空出插入位置
- while (i >= 0 && t <arr[i]){
- arr[i+1] = arr[i];
- i--;
- }
- //找到插入位置
- if (i+1 != low){
- arr[i+1] = t;
- }
- Insert1(arr,low+1);
- }
-
- public static void Insert2(int[]arr){
- for (int low = 1; low < arr.length-1 ; low++) {
- int t = arr[low];
- int i = low-1;
- //从右向左找插入位置,如果比待插入元素大,则不断右移,空出插入位置
- while (i >= 0 && t <arr[i]){
- arr[i+1] = arr[i];
- i--;
- }
- //找到插入位置
- if (i+1 != low){
- arr[i+1] = t;
- }
- }
- }
- }
应用场景
如果大部分数据距离它正确的位置很近或者近乎有序?例如银行的业务完成的时间
如果是这样的话,插入排序是更好的选择。
算法分析
最佳情况:T ( n ) = O ( n )
最坏情况:T ( n ) = O ( n^2 )
平均情况:T ( n ) = O ( n^2 )
4.选择排序
算法简介
首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。
动图演示
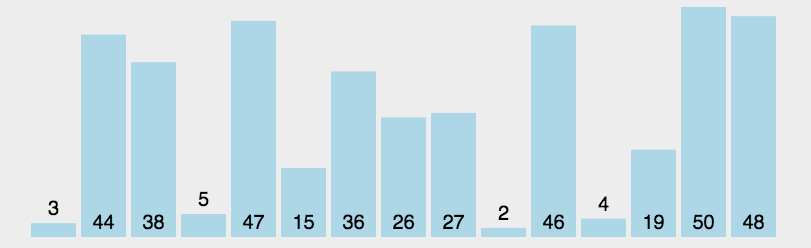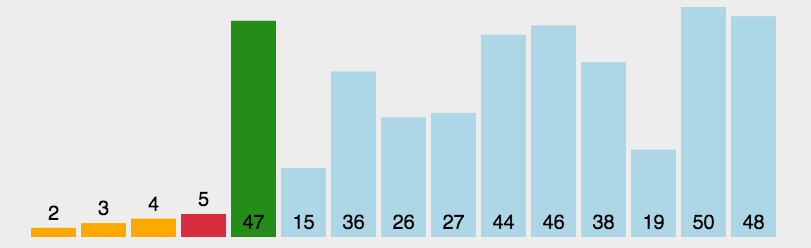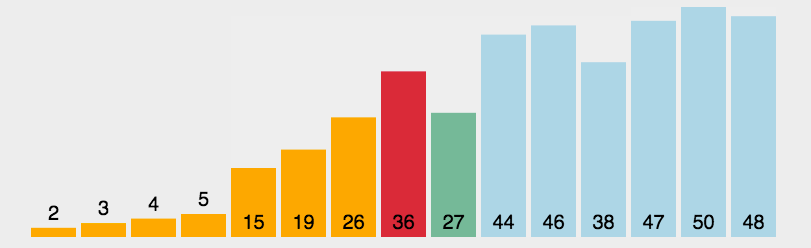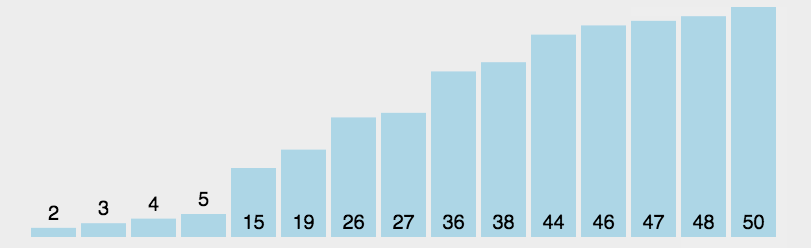
代码演示
- package Sorts;
-
- import java.util.Arrays;
- //选择排序
- public class ChooseSort {
- public static void main(String[] args) {
- int [] arr = new int [] {5,9,2,7,3,1,10};
- sort(arr);
- System.out.println(Arrays.toString(arr));
- }
-
- public static void sort(int []arr){
- for (int i = 0; i <arr.length ; i++) {//从第一个索引开始,遍历数组
- for (int j = i; j <arr.length ; j++) {//从当前索引位置开始,遍历后面的数组
- if (arr[j]<arr[i]){//后面的数组元素比它小,就交换他两的位置(这两元素不相邻)
- int temp = arr[i];
- arr[i]=arr[j];
- arr[j]=temp;
- }
- }
- }
- }
- }
应用场景
当数据量较小的时候适用
算法分析
最佳情况:T ( n ) = O ( n^2 )
最差情况:T ( n ) = O ( n^2 )
平均情况:T ( n ) = O ( n^2 )
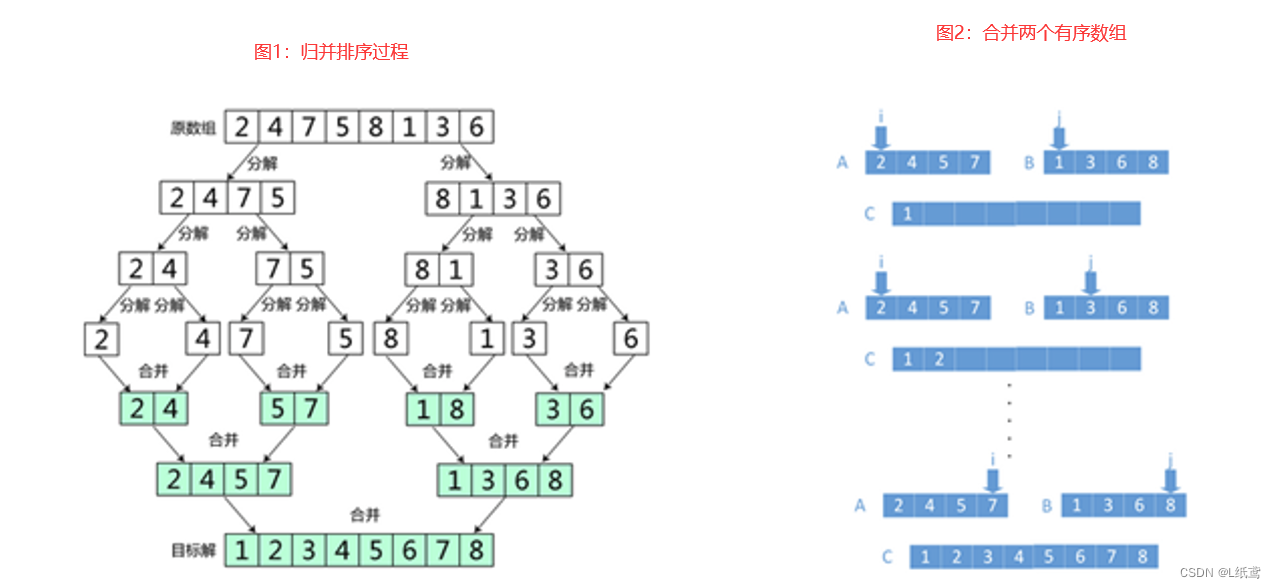
5.归并排序
算法简介
分:
- 一直分两组,分别对两个数组进行排序(根据上层对下层在一组的数据通过临时数组排序,再将有序数组挪回上层数组中)。
- 循环第一步,直到划分出来的“小组”只包含一个元素,只有一个元素的数组默认为已经排好序。
合:(合并时,站在上层合并下层(使组内有序))
- 将两个有序的数组合并到一个大的数组中。
- 从最小的只包含一个元素的数组开始两两合并。此时,合并好的数组也是有序的。最后把小组合成一个组。
图片演示
代码演示
- package Sorts;
-
- import java.util.Arrays;
- //归并排序
- public class Merge {
- public static void main(String[] args) {
- int[] array = new int[]{13,56,2,8,19,34,29};
- System.out.println("排序前:"+ Arrays.toString(array));
- mergeSort(array,0,array.length-1);
- System.out.println("排序后:"+Arrays.toString(array));
- }
- public static void mergeSort(int[] array, int low, int height){
- if (low >= height)
- return;
- int mid = (low+height)>>>1;
- mergeSort(array,low,mid);
- mergeSort(array,mid+1,height);
- merge(array,low,mid,height);
- }
- public static void merge(int[] array,int low,int mid,int height){
- int[] ret = new int[height-low+1];
- int i = 0;//新数组的索引
- int s1 = low;//前一个分段的初始位置
- int s2 = mid+1;//后一个分段的初始位置
-
- while (s1<=mid && s2<=height){
- if (array[s1]<=array[s2]){//比较元素的大小
- ret[i++] = array[s1++];//赋值给新数组,然后索引++
- }else {
- ret[i] = array[s2];
- i++;
- s2++;
- }
- }
- while (s1<=mid){//将前半段剩下的全部赋值到新数组中
- ret[i++] = array[s1++];
- }
- while (s2<=height){//将后半段剩下的全部赋值到新数组中
- ret[i++] = array[s2++];
- }
- for (int j = 0; j < ret.length; j++) {//将新数组中的元素全部挪到原数组中
- array[j+low] = ret[j];
- }
- }
- }
应用场景
内存空间不足的时候使用归并排序,能够使用并行计算的时候使用归并排序。
算法分析
最佳情况:T ( n ) = O ( n )
最差情况:T ( n ) = O ( nlogn )
平均情况:T ( n ) = O ( nlogn )
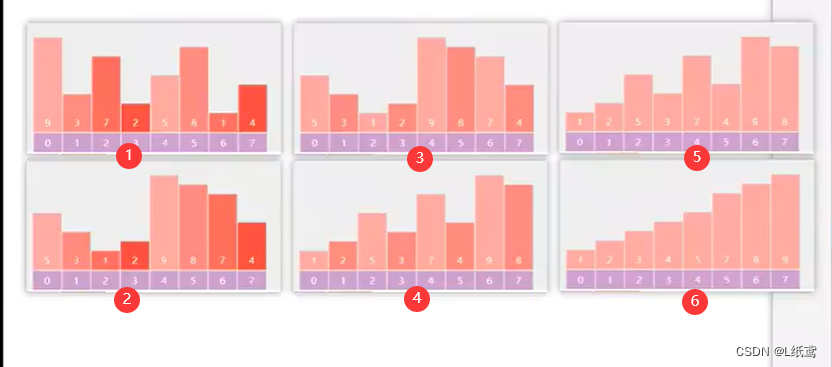
6.希尔排序
算法简介
- 首先选择一个步长值gap,以步长值为间隔把数组分为gap个子数组gap=length/2
- 对每个子数组进行插入排序;
- 逐步减小步长 gap = gap/2,重复对数组进行1,2 步骤;
- 当步长值减为1时,相当于对数组进行一次直接插入排序。
图片演示
代码演示
- package Sorts;
-
- import java.util.Arrays;
- //希尔排序
- public class XiErSort {
- public static void main(String[] args) {
- int [] arr = new int []{5,9,2,7,3,1,10};
- xiEr(arr);
- System.out.println(Arrays.toString(arr));
- }
- public static void xiEr(int arr[]){
- for (int gap = arr.length/2; gap >0 ; gap /=2) {
- for (int low = gap; low <arr.length ; low++) {
- int t = arr[low];
- int i = low - gap;
- //自右向左找插入位置,如果比待插入的元素大,则不断右移,空出插入位置
- while (i >= 0 && t < arr[i]){
- arr[i+gap] = arr[i];
- i-=gap;
- }
- //找到插入位置
- if(i != low-gap){
- arr[i+gap] = t;
- }
- }
- }
- }
- }
应用场景
相对于直接插入排序,希尔排序要高效很多,因为当gap 值较大时,对子数组进行插入排序时要移动的元素很少,元素移动的距离很大,这样效率很高;在gap逐渐减小过程中,数组中元素已逐渐接近排序的状态,所以需要移动的元素逐渐减少;当gap为1时,相当于进行一次直接插入排序,但是各元素已接近排序状态,需要移动的元素很少且移动的距离都很小。
算法分析
最佳情况:T ( n ) = O ( nlog2 n )
最坏情况:T ( n ) = O ( nlog2 n )
平均情况:T ( n ) = O ( nlog2 n )
7.堆排序
算法简介
堆排序(Heapsort)是指利用堆这种数据结构所设计的一种排序算法。堆积是一个近似完全二叉树的结构,并同时满足堆积的性质:即子结点的键值或索引总是小于(或者大于)它的父节点。
堆排序可以说是一种利用堆的概念来排序的选择排序。
分为两种方法:
- 大顶堆:每个节点的值都大于或等于其子节点的值,在堆排序算法中用于升序排列;
- 小顶堆:每个节点的值都小于或等于其子节点的值,在堆排序算法中用于降序排列;
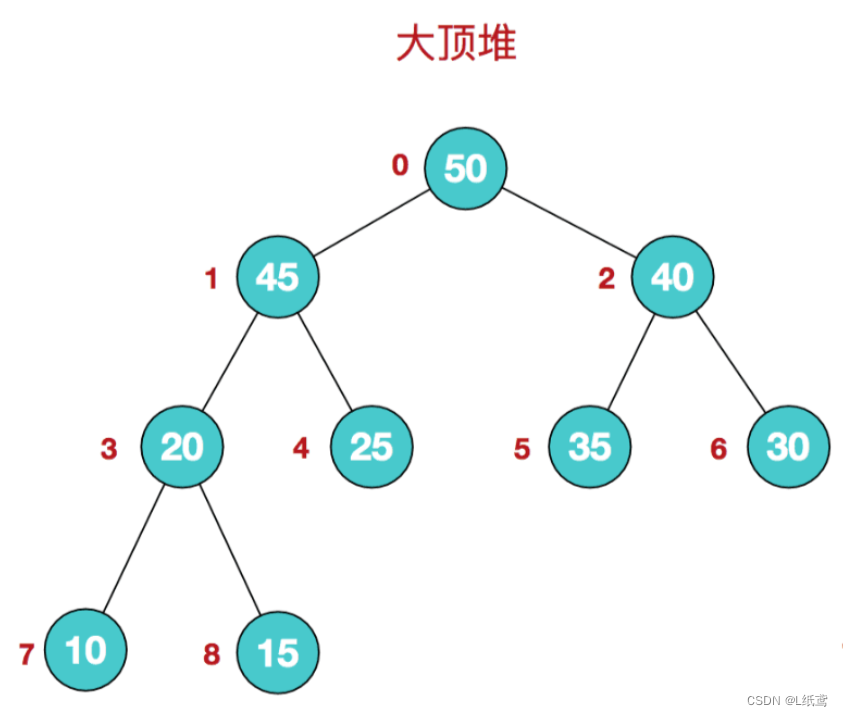
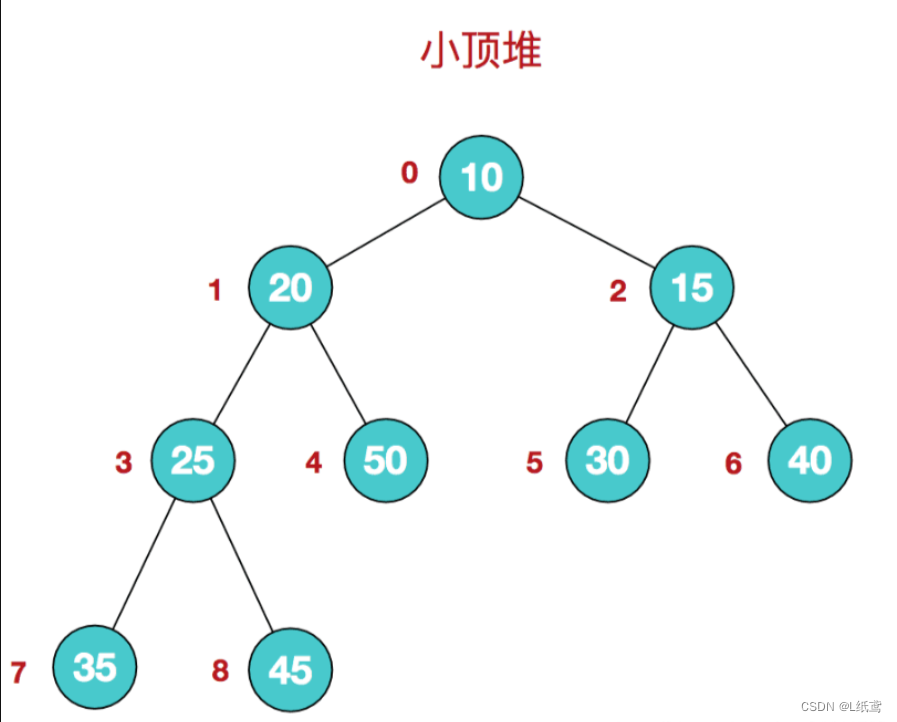
图片演示
步骤一 :构造初始堆。将给定无序序列构造成一个大顶堆(一般升序采用大顶堆,降序采用小顶堆)。
a.假设给定无序序列结构如下
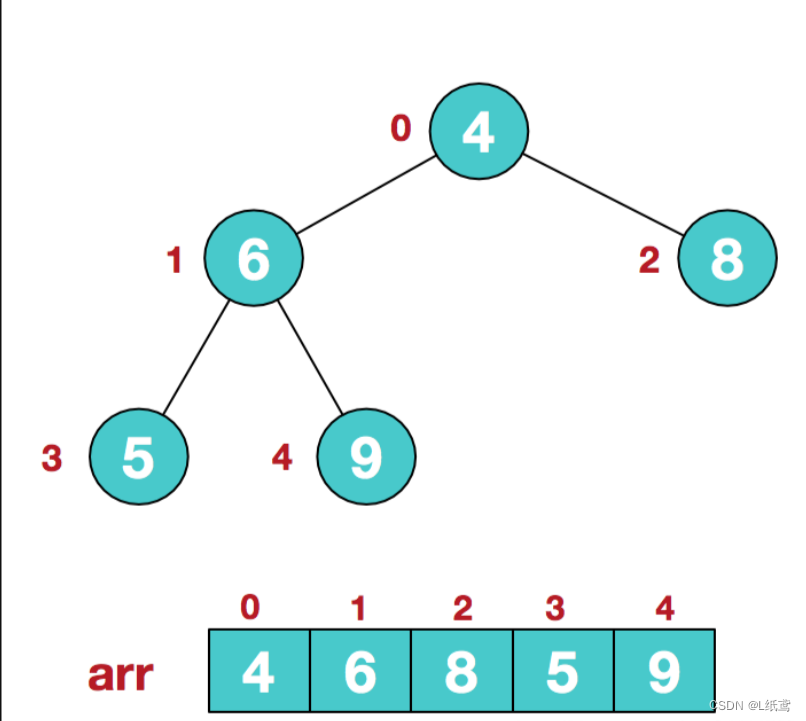
此时我们从最后一个非叶子结点开始(叶结点自然不用调整,第一个非叶子结点 arr.length/2-1=5/2-1=1,也就是下面的6结点),从左至右,从下至上进行调整。
此处必须注意,我们把 6 和 9 比较交换之后,必须考量 9 这个节点对于其子节点会不会产生任何影响?因为其是叶子节点,所以不加考虑;
但是,一定要熟练这种思维,写代码的时候就比较容易理解为什么会出现一次非常重要的交换了。
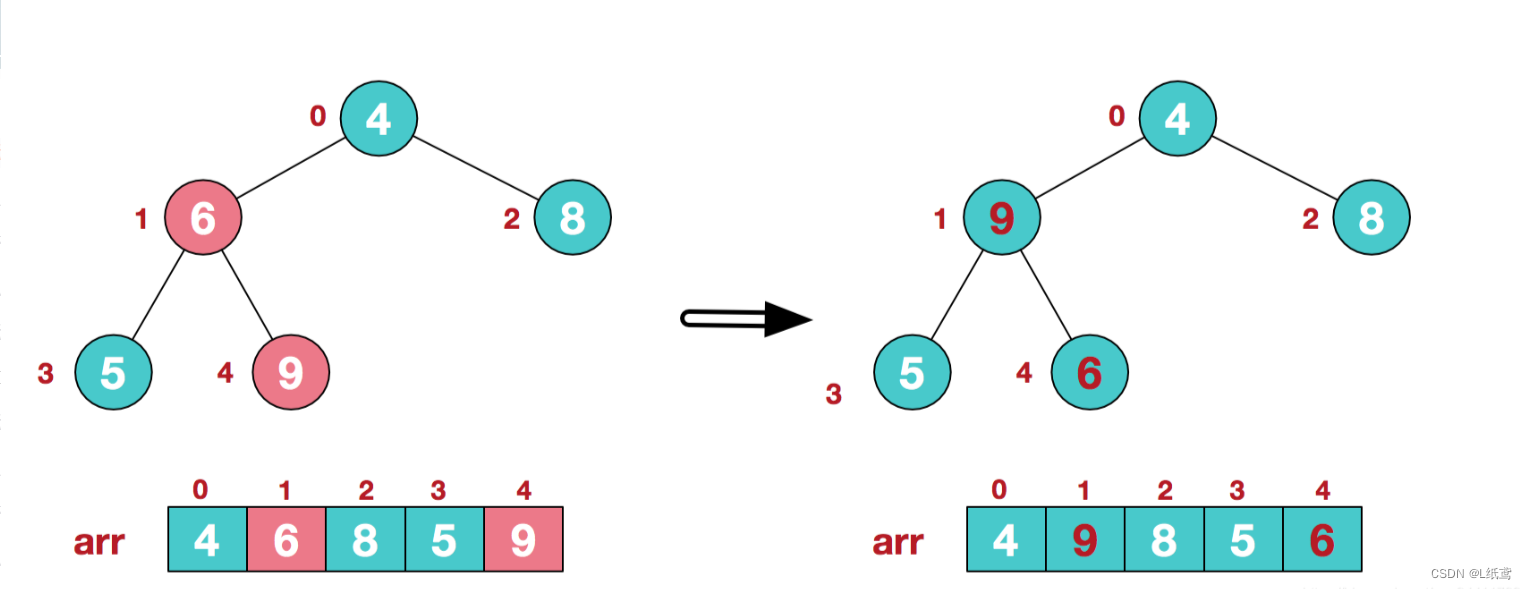
找到第二个非叶节点4,由于[4,9,8]中9元素最大,4和9交换。
在真正代码的实现中,这时候4和9交换过后,必须考虑9所在的这个节点位置,因为其上的值变了,必须判断对其的两个子节点是否造成了影响,这么说不合适,实际上就是判断其作为根节点的那棵子树,是否还满足大根堆的原则,每一次交换,都必须要循环把子树部分判别清楚。
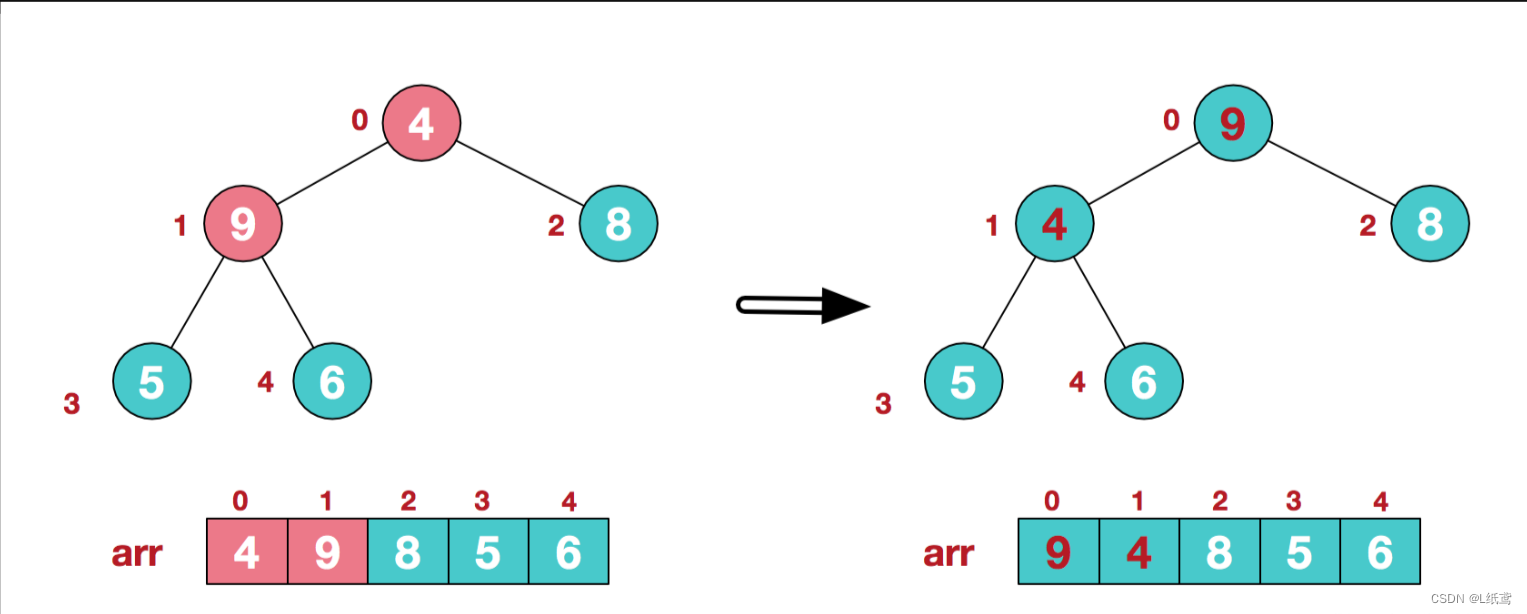
这时,交换导致了子根[4,5,6]结构混乱,继续调整,[4,5,6]中6最大,交换4和6。
牢记上面说的规则,每次交换都要把改变了的那个节点所在的树重新判定一下,这里就用上了,4和9交换了,变动了的那棵子树就必须重新调整,一直调整到符合大根堆的规则为截。
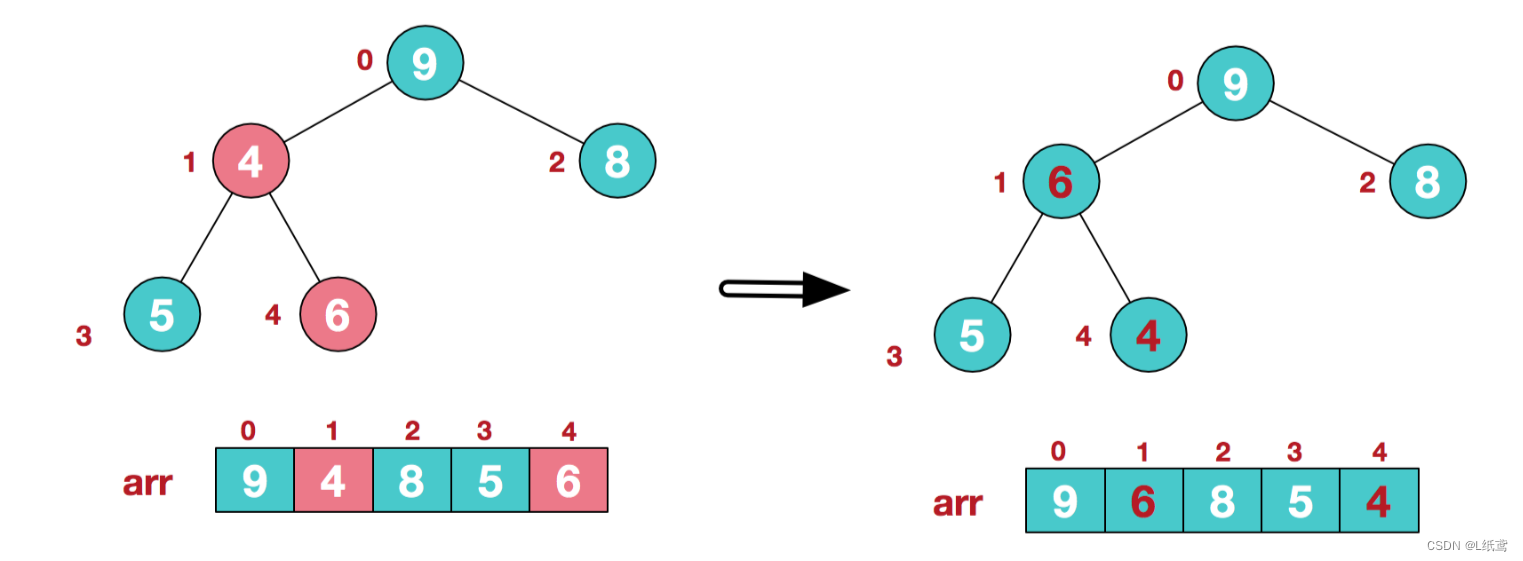
此时,我们就将一个无序序列构造成了一个大顶堆。
步骤二 :将堆顶元素与末尾元素进行交换,使末尾元素最大。然后继续调整堆,再将堆顶元素与末尾元素交换,得到第二大元素。如此反复进行交换、重建、交换。
将堆顶元素9和末尾元素4进行交换
这里,必须说明一下,所谓的交换,实际上就是把最大值从树里面拿掉了,剩下参与到排序的树,其实只有总结点的个数减去拿掉的节点个数了。所以图中用的是虚线。
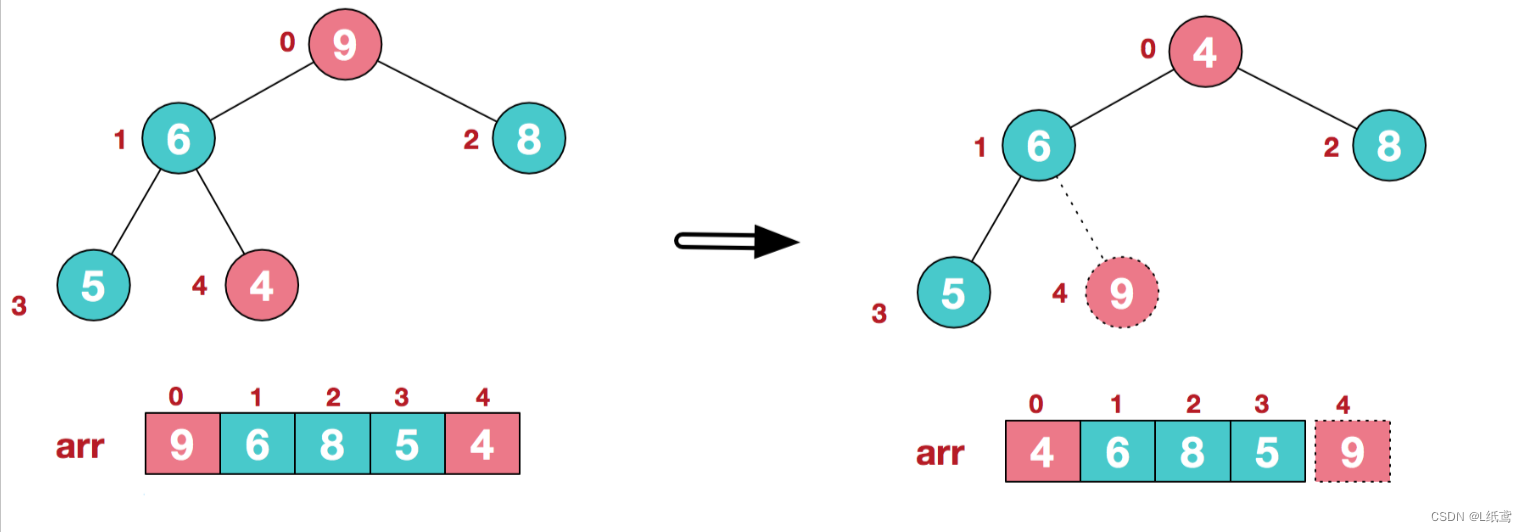
重新调整结构,使其继续满足堆定义
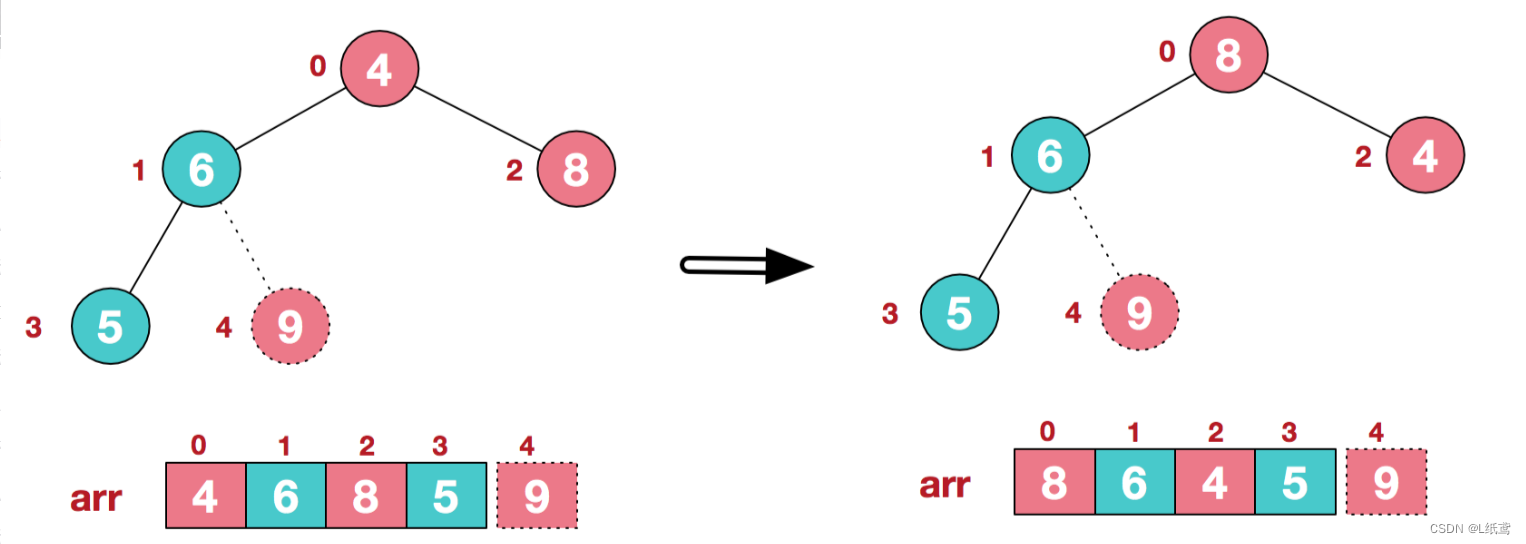
再将堆顶元素8与末尾元素5进行交换,得到第二大元素8.
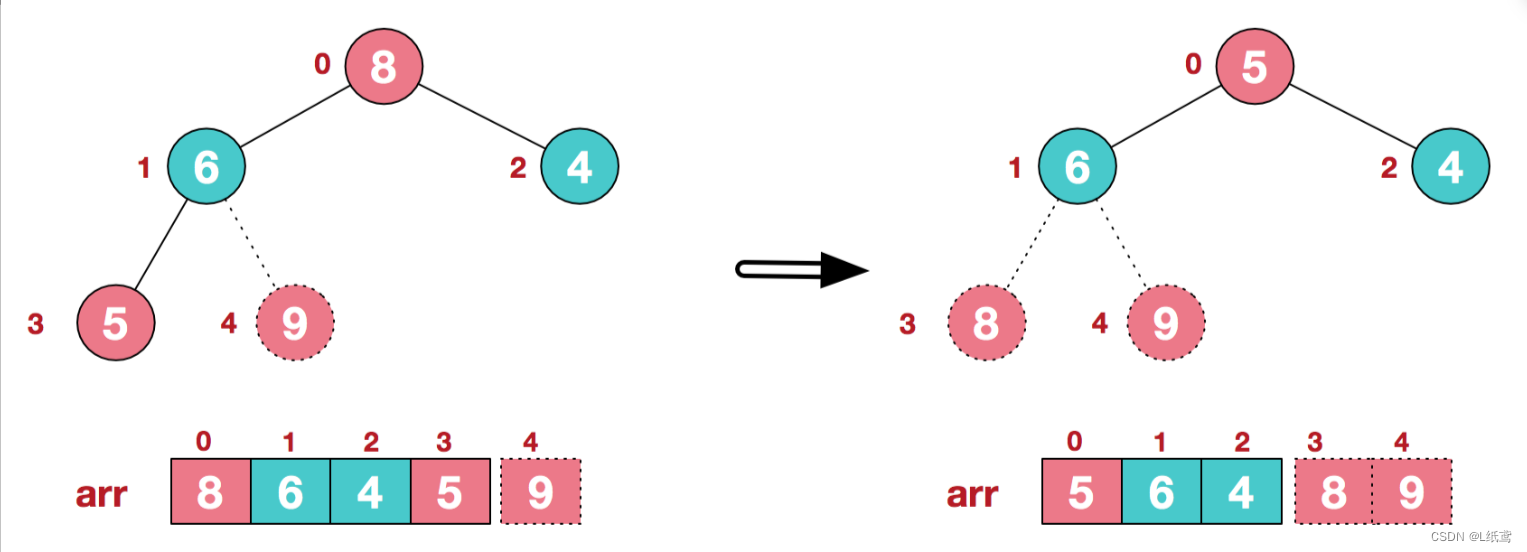
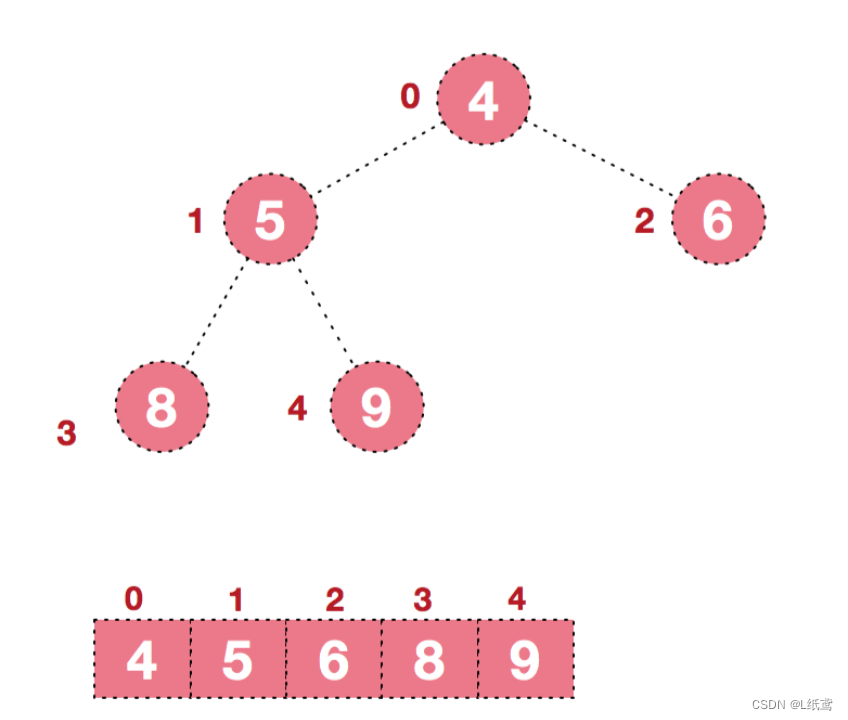
后续过程,继续进行调整,交换,如此反复进行,最终使得整个序列有序
代码演示
- package Sorts;
- //堆排
- public class HeapSort {
- public static void main(String[] args) {
- int[] arr = {16, 7, 3, 20, 17, 8};
- heapSort(arr);
- for (int i : arr) {
- System.out.print(i + " ");
- }
- }
- /**
- * 创建堆
- */
- private static void heapSort(int[] arr) {
- //创建堆
- for (int i = (arr.length - 1) / 2; i >= 0; i--) {
- //从第一个非叶子结点从下至上,从右至左调整结构
- adjustHeap(arr, i, arr.length);
- }
-
- //调整堆结构+交换堆顶元素与末尾元素
- for (int i = arr.length - 1; i > 0; i--) {
- //将堆顶元素与末尾元素进行交换
- int temp = arr[i];
- arr[i] = arr[0];
- arr[0] = temp;
- //重新对堆进行调整
- adjustHeap(arr, 0, i);
- }
- }
- /**
- * 调整堆
- * @param arr 待排序列
- * @param parent 父节点
- * @param length 待排序列尾元素索引
- */
- private static void adjustHeap(int[] arr, int parent, int length) {
- //将temp作为父节点
- int temp = arr[parent];
- //左孩子
- int lChild = 2 * parent + 1;
- while (lChild < length) {
- //右孩子
- int rChild = lChild + 1;
- // 如果有右孩子结点,并且右孩子结点的值大于左孩子结点,则选取右孩子结点
- if (rChild < length && arr[lChild] < arr[rChild]) {
- lChild++;
- }
- // 如果父结点的值已经大于孩子结点的值,则直接结束
- if (temp >= arr[lChild]) {
- break;
- }
- // 把孩子结点的值赋给父结点
- arr[parent] = arr[lChild];
- //选取孩子结点的左孩子结点,继续向下筛选
- parent = lChild;
- lChild = 2 * lChild + 1;
- }
- arr[parent] = temp;
- }
- }
应用场景
堆排序适合于数据量非常大的场合(百万数据)。
堆排序不需要大量的递归或者多维的暂存数组。这对于数据量非常巨大的序列是合适的。比如超过数百万条记录,因为快速排序,归并排序都使用递归来设计算法,在数据量非常大的时候,可能会发生堆栈溢出错误。
堆排序会将所有的数据建成一个堆,最大的数据在堆顶,然后将堆顶数据和序列的最后一个数据交换。接下来再次重建堆,交换数据,依次下去,就可以排序所有的数据。
算法分析
最佳情况:T ( n ) = O ( nlogn )
最差情况:T ( n ) = O ( nlogn )
平均情况:T ( n ) = O ( nlogn )
8.计数排序
算法分析
找出待排序的数组中最大和最小的元素;
统计数组中每个值为 i 的元素出现的次数,存入数组C的第 i 项;
对所有的计数累加(从C中的第一个元素开始,每一项和前一项相加);
反向填充目标数组:将每个元素i放在新数组的第C( i ) 项,每放一个元素就将C( i ) 减去1。
动图演示
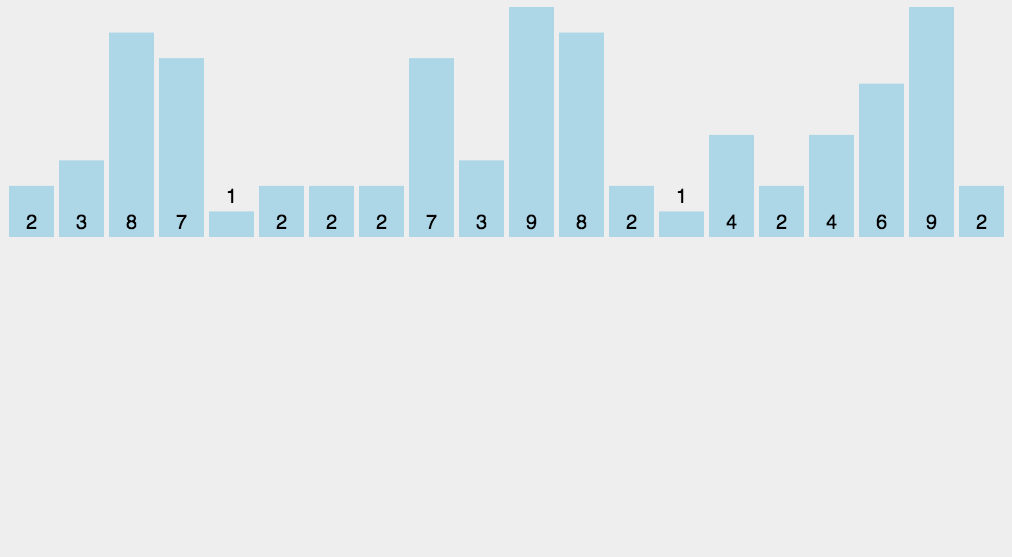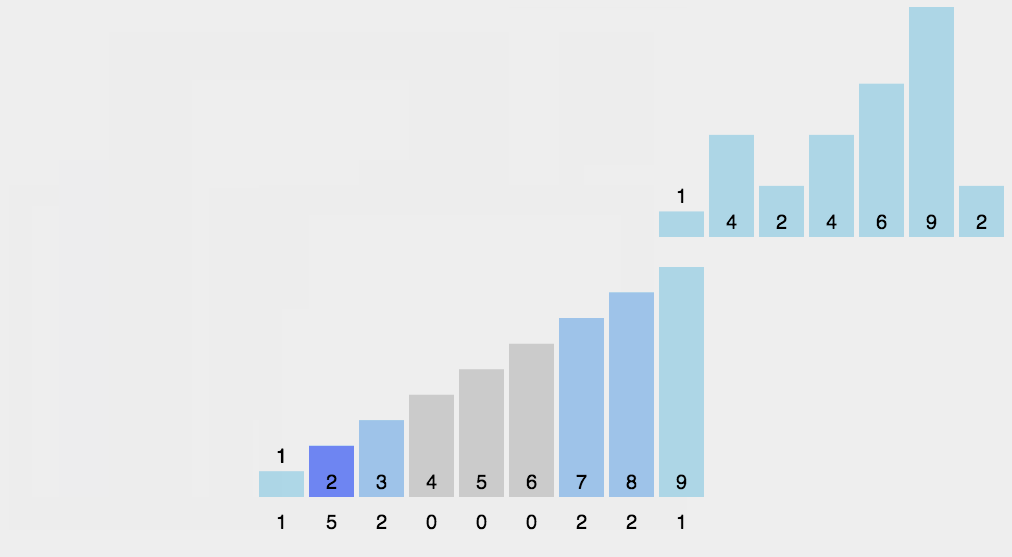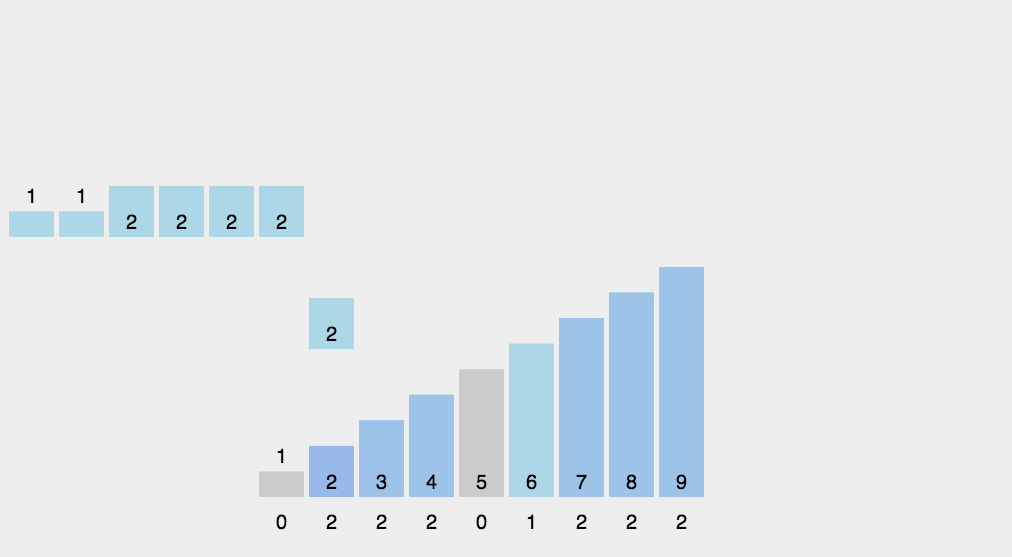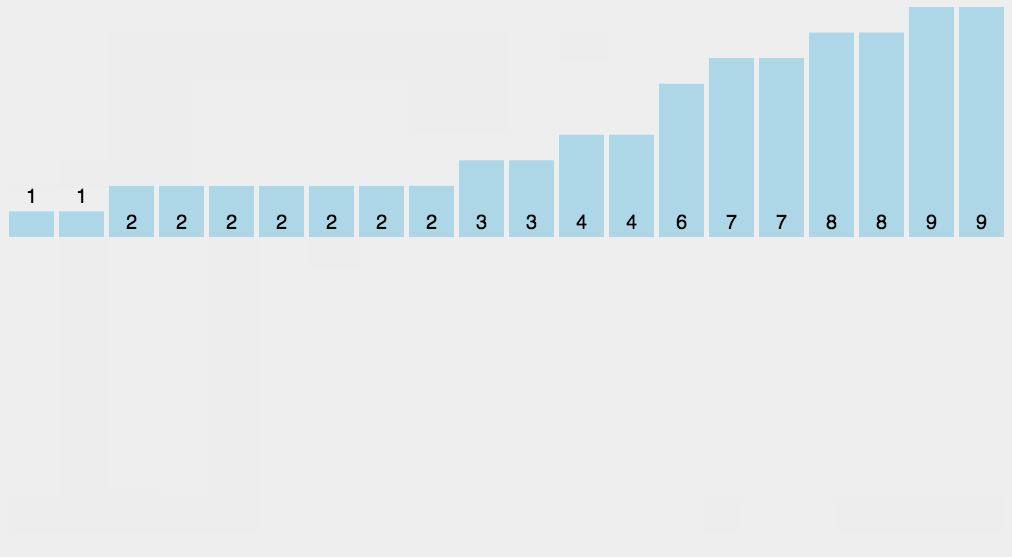
代码演示
- package Sorts;
-
- import java.util.Arrays;
-
- //计数排序
- public class CountSort {
-
- public static void main(String[] args) {
- int[] arr = {5,1,1,1,3,0};
- System.out.println(Arrays.toString(arr));
- countSort1(arr);
- System.out.println(Arrays.toString(arr));
- }
-
- //数组中元素>=0
- private static void countSort1(int[] arr) {
- int max = arr[0];
- for (int i = 1; i < arr.length; i++) {
- if (arr[i] > max)
- max = arr[i];
- }
-
- int[] count = new int[max+1];
-
- for (int v : arr) { //原始数组的元素
- count[v]++;
- }
- int k = 0;
- for (int i = 0; i < count.length; i++) {
- // i 代表原始数组中的元素,count[i]代表出现次数
- while (count[i]>0){
- arr[k++] = i;
- count[i]--;
- }
- }
- }
-
- //不限制数组中元素的大小,可以有负数
- private static void countSort2(int[] arr) {
- //让数组中的最小值映射到数组的count[0]位置,最大值映射到count的最右侧
- int min = arr[0];
- int max = arr[0];
- for (int i = 1; i < arr.length; i++) {
- if (arr[i] > max)
- max = arr[i];
- if (arr[i] < min)
- min = arr[i];
- }
-
- int[] count = new int[max - min + 1];
-
- //原始数组元素 - 最小值 = count 索引
- for (int v : arr) { //原始数组的元素
- count[v - min]++;
- }
- int k = 0;
- for (int i = 0; i < count.length; i++) {
- // i+min 代表原始数组中的元素,count[i]代表出现次数
- while (count[i]>0){
- arr[k++] = i + min;
- count[i]--;
- }
- }
- }
- }
应用场景
计数排序需要占用大量空间,它仅适用于数据比较集中的情况。比如 [0,100],[10000,19999] 这样的数据。
算法分析
最佳情况:T ( n ) = O ( n+k )
最差情况:T ( n ) = O ( n+k )
平均情况:T ( n ) = O ( n+k )
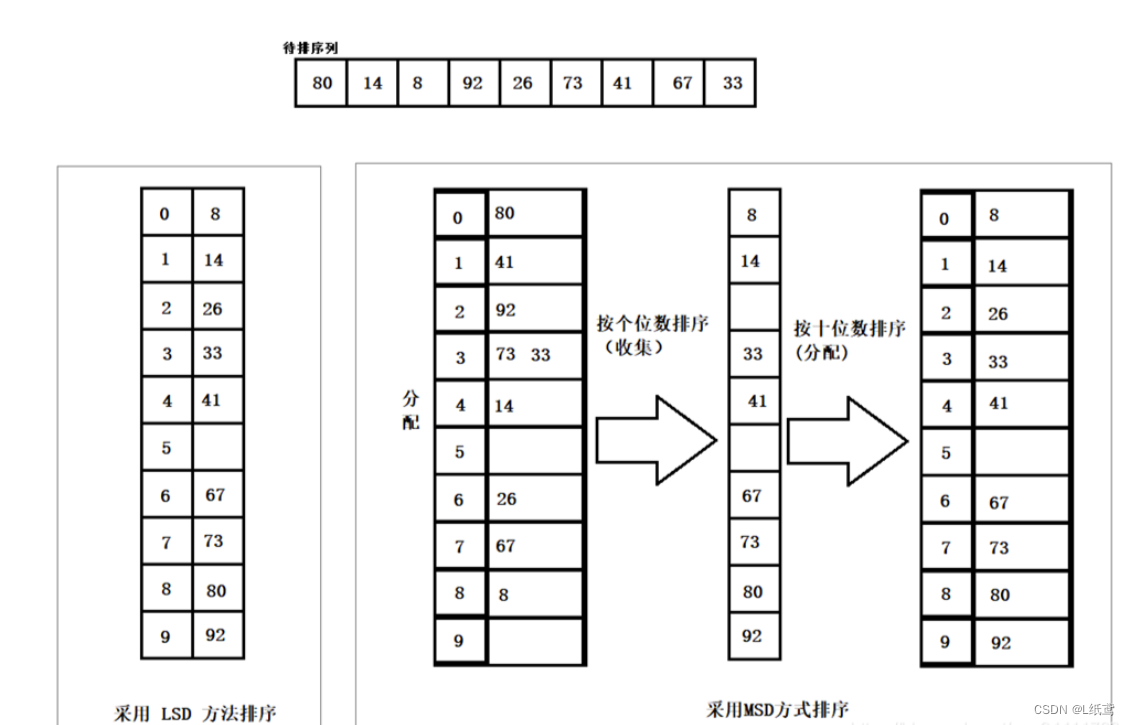
9.基数排序
算法分析
相比其它排序,主要是利用比较和交换,而基数排序则是利用分配和收集两种基本操作。基数排序是一种按记录关键字的各位值逐步进行排序的方法。此种排序一般适用于记录的关键字为整数类型的情况。所有对于字符串和文字排序不适合。
实现:将所有待比较数值(自然数)统一为同样的数位长度,数位较短的数前面补零。然后,从最低位开始,依次进行一次排序。这样从最低位排序一直到最高位排序完成以后, 数列就变成一个有序序列。
基数排序的两种方式:
高位优先,又称为最有效键(MSD),它的比较方向是由右至左;
低位优先,又称为最无效键(LSD),它的比较方向是由左至右;
动图演示

代码演示
- package Sorts;
-
- import java.util.Arrays;
-
- //基数排序
- public class RadixSort {
-
- public static void main(String[] args) {
- int [] arr = new int[]{193,255,12,6,78,50,31,564};
- radixSort(arr);;
- System.out.println(Arrays.toString(arr));
-
- }
-
- public static void radixSort(int[] array) {
- if (array == null || array.length <= 1) {
- return;
- }
-
- int length = array.length;
-
- // 每位数字范围0~9,基为10
- int radix = 10;
- int[] aux = new int[length];
- int[] count = new int[radix + 1];
- // 以关键字来排序的轮数,由位数最多的数字决定,其余位数少的数字在比较高位时,自动用0进行比较
- // 将数字转换成字符串,字符串的长度就是数字的位数,字符串最长的那个数字也拥有最多的位数
- int x = Arrays.stream(array).map(s -> String.valueOf(s).length()).max().getAsInt();
-
- // 共需要d轮计数排序, 从d = 0开始,说明是从个位开始比较,符合从右到左的顺序
- for (int d = 0; d < x; d++) {
- // 1. 计算频率,在需要的数组长度上额外加1
- for (int i = 0; i < length; i++) {
- // 使用加1后的索引,有重复的该位置就自增
- count[digitAt(array[i], d) + 1]++;
- }
- // 2. 频率 -> 元素的开始索引
- for (int i = 0; i < radix; i++) {
- count[i + 1] += count[i];
- }
-
- // 3. 元素按照开始索引分类,用到一个和待排数组一样大临时数组存放数据
- for (int i = 0; i < length; i++) {
- // 填充一个数据后,自增,以便相同的数据可以填到下一个空位
- aux[count[digitAt(array[i], d)]++] = array[i];
- }
- // 4. 数据回写
- for (int i = 0; i < length; i++) {
- array[i] = aux[i];
- }
- // 重置count[],以便下一轮统计使用
- for (int i = 0; i < count.length; i++) {
- count[i] = 0;
- }
-
- }
- }
-
- //Description: 根据d,获取某个值的个位、十位、百位等,d = 0取出个位,d = 1取出十位,以此类推。对于不存在的高位,用0补
- private static int digitAt(int value, int d) {
- return (value / (int) Math.pow(10, d)) % 10;
- }
- }
应用场景
略
算法分析
最佳情况:T ( n ) = O ( n * k )
最差情况:T ( n ) = O ( n * k )
平均情况:T ( n ) = O ( n * k )
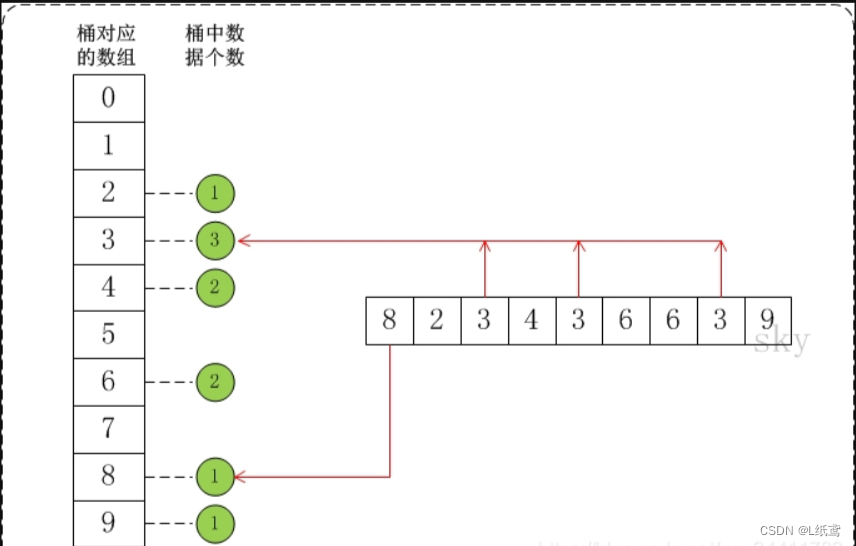
10.桶排序
算法分析
桶排序(Bucket Sort)的原理很简单,它是将数组分到有限数量的桶子里。
假设待排序的数组a中共有N个整数,并且已知数组a中数据的范围[0, MAX)。在桶排序时,创建容量为MAX的桶数组r,并将桶数组元素都初始化为0;将容量为MAX的桶数组中的每一个单元都看作一个"桶"。
在排序时,逐个遍历数组a,将数组a的值,作为"桶数组r"的下标。当a中数据被读取时,就将桶的值加1。例如,读取到数组a[3]=5,则将r[5]的值+1。
动图演示
代码演示
- package Sorts;
-
- import java.util.*;
-
- //桶排
- public class BucketSort {
- public static void main(String[] args) {
- int [] arr = new int[]{193,255,12,6,78,50,31,564};
- bucketSort(arr);;
- System.out.println(Arrays.toString(arr));
-
- }
-
- public static void bucketSort(int[] array) {
- if (array == null || array.length <= 1) {
- return;
- }
-
- // 建立桶,个数和待排序数组长度一样
- int length = array.length;
-
- LinkedList<Integer>[] bucket = (LinkedList<Integer>[]) new LinkedList[length];
-
- // 待排序数组中的最大值
- int maxValue = Arrays.stream(array).max().getAsInt();
- // 根据每个元素的值,分配到对应范围的桶中
- for (int i = 0; i < array.length; i++) {
- int index = toBucketIndex(array[i], maxValue, length);
- // 没有桶才建立桶(延时)
- if (bucket[index] == null) {
- bucket[index] = new LinkedList<>();
- }
- // 有桶直接使用
- bucket[index].add(array[i]);
- }
-
- // 对每个非空的桶排序,排序后顺便存入临时的List,则list中已经有序)
- List<Integer> temp = new ArrayList<>();
- for (int i = 0; i < length; i++) {
- if (bucket[i] != null) {
- Collections.sort(bucket[i]);
- temp.addAll(bucket[i]);
- }
- }
-
- // 将temp中的数据写入原数组
- for (int i = 0; i < length; i++) {
- array[i] = temp.get(i);
- }
- }
-
- private static int toBucketIndex(int value, int maxValue, int length) {
- return (value * length) / (maxValue + 1);
- }
-
- /**
- *
- public static void bucketSort(int arr[] ){
- //定义二维数组
- int [][] bucket = new int[10][arr.length];
- //定义记录桶中数据个数的数组
- int [] bucketElement = new int[10];
- for (int i = 0; i <arr.length ; i++) {
- int element = arr[i] % 10;
- bucket[element][bucketElement[element]] = arr[i];
- bucketElement[element]++;
- }
- int index = 0;
- for (int k = 0; k <bucketElement.length ; k++) {
- if (bucketElement[k]!=0){
- for (int l = 0; l <bucketElement [k] ; l++) {
- arr[index] = bucket[k][l];
- index++;
- }
- }
- bucketElement[k]=0;
- }
- }
- */
- }
应用场景
略
算法分析
桶排序最好情况下使用线性时间O(n),桶排序的时间复杂度,取决与对各个桶之间数据进行排序的时间复杂度,因为其它部分的时间复杂度都为O(n)。很显然,桶划分的越小,各个桶之间的数据越少,排序所用的时间也会越少。但相应的空间消耗就会增大。
最佳情况:T ( n ) = O ( n+k )
最差情况:T ( n ) = O ( n+k )
平均情况:T ( n ) = O ( n^2 )
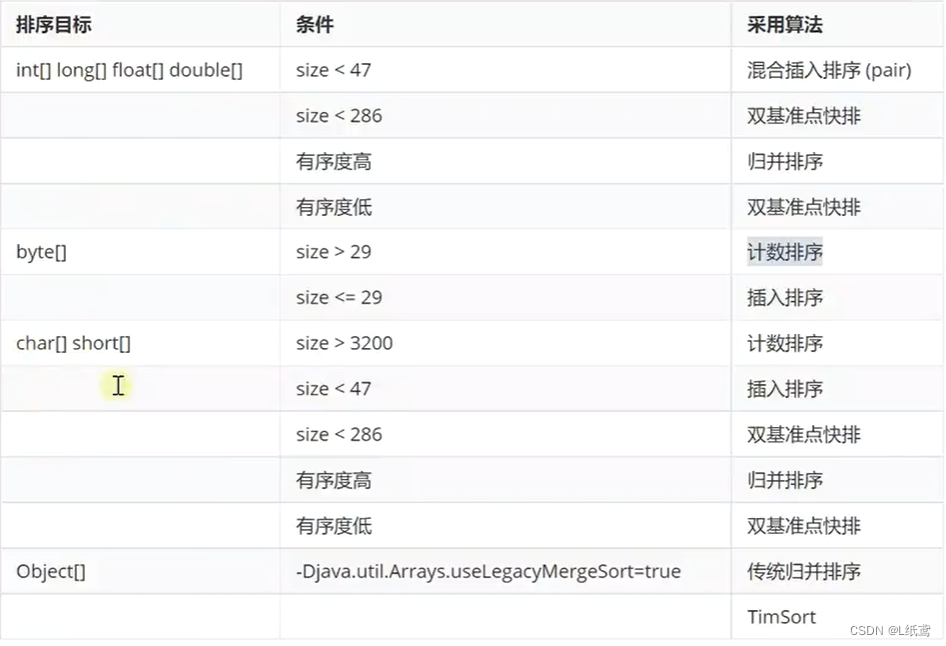
11.Java自带的排序算法
JDK7-13:
JDK14-20:
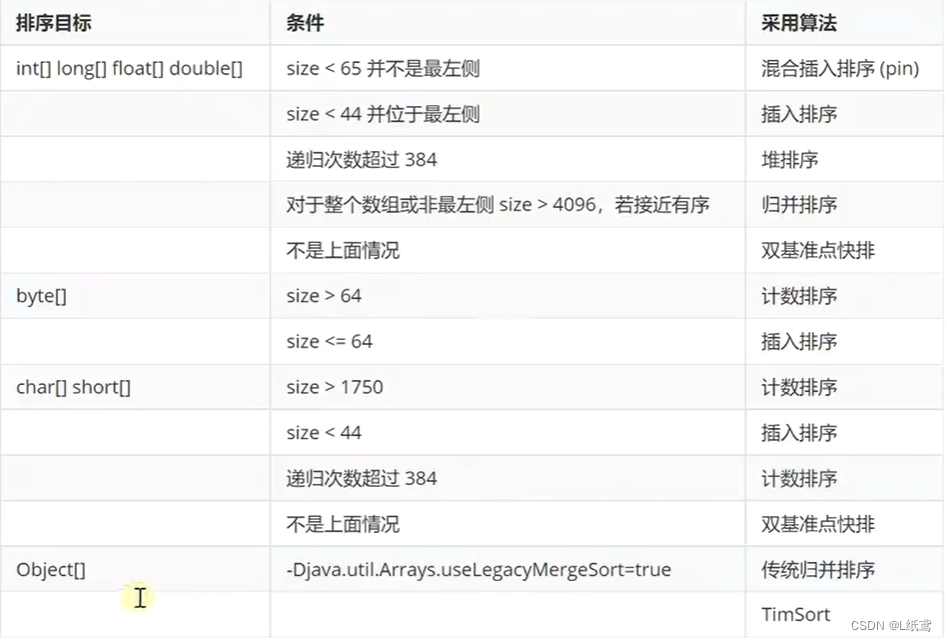
- 其中TimSort是用归并 + 二分插入排序的混合排序算法
- 值得注意的是从JDK8开始支持 Arrays.parallelSort 并行排序
- 根据最新的提交记录来看JDK21可能会引入基数排序等优化


