
- 1/etc/security/cacerts 只读权限_cp: /system/etc/security/cacerts/9a5ba575.0: read-
- 2(十)VUE侧边菜单栏导航--基于SpringBoot+MySQL+Vue+ElementUI+Mybatis前后端分离面向小白管理系统搭建_elementui侧边导航栏
- 3Python 使用mysql.connector、pymysql和 MYSQLdb(MysqlClient)操作MySQL数据库_python使用mysqlclient
- 4蓝桥杯嵌入式第十五届省赛模拟赛第三场——程序设计部分_蓝桥杯嵌入式15届模拟题
- 5【Protobuf协议】003-嵌套类型、更新一个消息类型、Any、Oneof、Map(映射)、包_protobuf any
- 6估值一亿的AI核心代码现已开源_7-2 估值一亿的ai核心代码 c语言
- 7idea中怎么忽略(ignore)掉 .idea等文件(亲测)_idea忽略.idea文件
- 8【Git】说说Git中开发测试的使用&Git分支&Git标签的使用场景_git 什么时候使用标签什么时候使用分支
- 9spring计划任务 向webSocket发送心跳包_spring websocket 心跳
- 10花 2 个月备战字节跳动Java岗,3 轮面试拿下 60W Offer_字节跳动java面试几轮
Enhancing Label Correlation Feedback in Multi-Label Text Classification via Multi-Task Learning_label correlation embedding guided network for mul
赞
踩
ACL2021 finding
本文引入了一种新的多任务学习方法来增强标签相关反馈。首先利用一种联合嵌入(JE)机制来同时获取文本和标签的表示,并借助注意力机制对其进行增强。此外,提出了两个辅助的标签共现预测任务来提高标签相关学习:1)两两标签共现预测(Pairwise label Co-occurrence Prediction,PLCP)和2)条件标签共现预测(Conditional label Co-occurrence Prediction,CLCP),分别捕捉多标签之间的一阶相关性和高阶相关性。
Method

Document-Label Joint Embedding(JE)
JE类似于Prompt学习,将标签与文本联合起来构建新的模型输入。具体来说,将输入转化为: [ C L S ] ; x 1 ; . . . ; x m ; [ S E P ] ; y 1 ; . . . ; y n ; [ S E P ] [CLS]; x1;...;x_m; [SEP]; y1;...; yn; [SEP] [CLS];x1;...;xm;[SEP];y1;...;yn;[SEP]。借助JE,模型可以更加关注两个方面:1)文档与标签之间的相关性。不同的文档对特定的标签有不同的影响,而同一文档片段可能影响多个标签。2)标签之间的相关性。标签的语义信息是相互关联的,标签共现表明它们之间存在很强的语义相关性。
Multi-Label Text Classification
分类的过程包括Document-Label Cross Attention (CA) and Label Predication两部分。
Document-Label Cross Attention (CA)
首先,通过点积度量标签-单词对的兼容性:

H
D
H_D
HD表示文本序列的嵌入,
H
Y
H_Y
HY是标签序列的嵌入,
M
∈
R
m
∗
n
M\in \mathcal{R}^{m*n}
M∈Rm∗n,用于表示每一段文本与标签之间的相关性。考虑到连续词之间的语义信息,本文借助CNN对上下文进行进一步推广,也就是与某一个标签对应的文档应该由其上下文
M
i
−
r
;
i
+
r
M_{i-r;i+r}
Mi−r;i+r进行决定。之后,在上下文应用带有Relu的CNN获取local聚合的特征,并使用最大池化+双曲正切激活函数的方式获取最终的相关性(注意力权重)表示。上述操作可以用
Ω
\Omega
Ω表示:

Label Predication
分类在
c
⃗
\vec{c}
c
的基础上使用一个简单变换:

Binary Cross Entropy作为损失函数:

Multi-Task Learning with Label Correlations
针对标签之间的一阶(两两之间)相关性以及高阶相关性(多个标签之间),设计了两个额外的辅助任务,对标签相关性进行显性预测。
Pairwise Label Co-occurrence Prediction (PLCP)
假定文档
D
D
D有相关标签
Y
+
Y^+
Y+以及不相关的标签
Y
−
Y^-
Y−,并对相关标签以及不相关标签进行采样,然后预测标签对是否相关(二分类)。本文设定了IsCo-occur和NotCo-occur的比例为
γ
\gamma
γ,并使用两个标签表示的拼接作为预测的输入:

其中
p
i
j
=
p
(
y
j
∣
D
;
y
i
)
p_{ij} = p(y_j|D; yi)
pij=p(yj∣D;yi)表示标签对共现的输出概率,
q
i
,
j
=
1
q_{i,j}=1
qi,j=1表示实际标签的共现。
Conditional Label Co-occurrence Prediction (CLCP)
这一步随机从
Y
+
Y^+
Y+中选出子集
Y
G
Y^G
YG,预测
Y
Y
Y的剩余标签是否与它们相关。将样本标签对应向量的平均值
h
y
G
h_y^G
hyG以及另外的所有非样本标签的特征进行拼接,然后分别进行预测:

n
−
s
n-s
n−s表示剔除采样的
s
s
s个样本。
最终训练的损失函数为联合损失:

Experiments
数据集是常用的两个多标签分类数据:

总体实验结果如下:
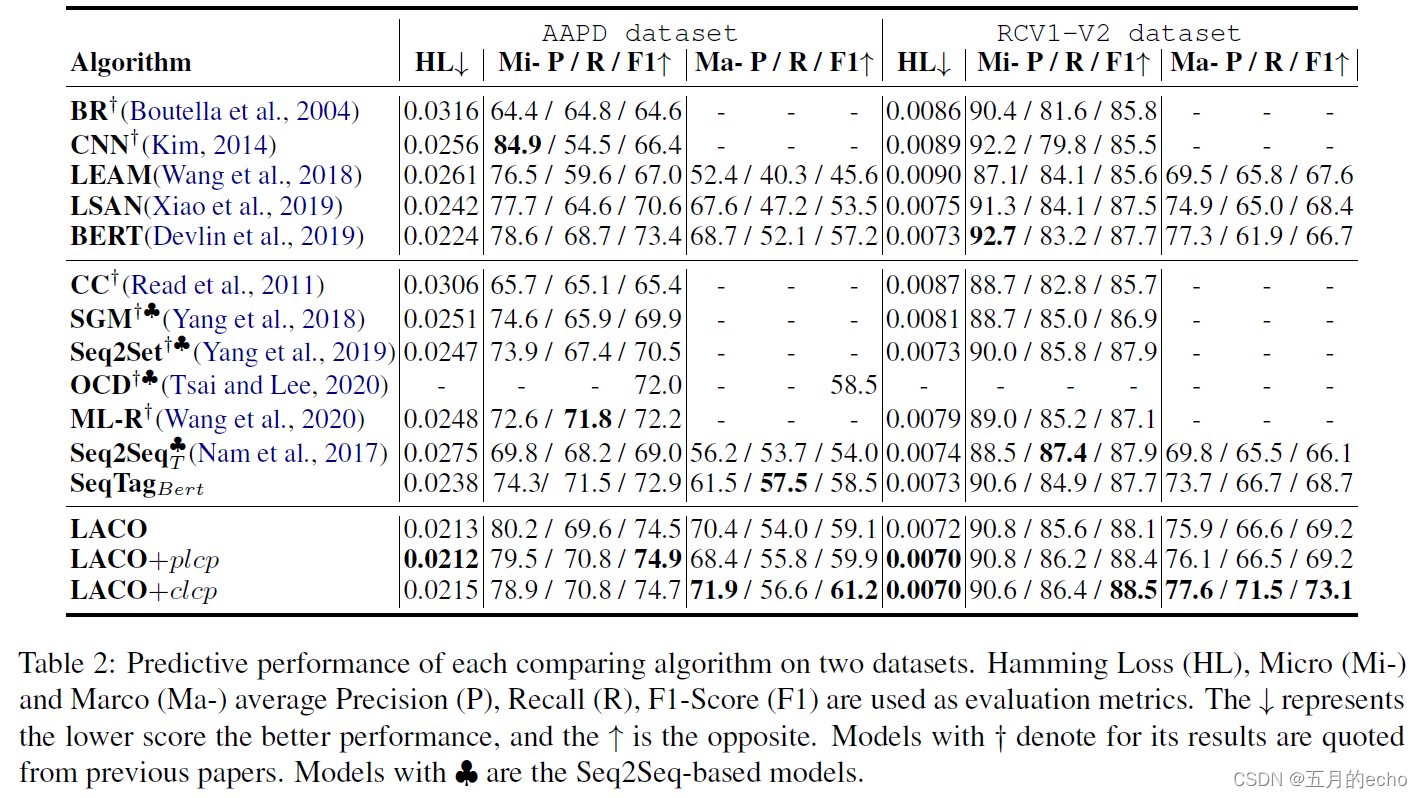
不同组件的消融实验:

不同标签频率下的性能(当然还是高频的标签效果更好):

不同方法对相关性的捕捉能力(使用KL散度衡量模型预测分布与训练/测试数据集上的ground-truth分布之间的关系):

Seq方法拟合训练的效果很好但是推广到测试集则会变差。
所有标签都被正确分类的样本的百分比:

模型的收敛速度(本文将标签信息融入输入,因此收敛速度更快):



