
- 1OpenHarmony网络组件-Mars
- 2navicate 连接虚拟机的mysql_navicat连接虚拟机mysql
- 320240407 每日AI必读资讯_octopus v2
- 4今天聊聊基于知识增强预训练技术ERNIE_预训练模型知识增强技术有哪些
- 5单片机采集的MPU6050原始数据对应关系
- 6企业老员工管理最有效的七个办法_管理学案例老员工
- 7lifecycleScope Unresolved reference_lifecyclescope.launch找不到
- 8大厂字节程序员薪资曝光:排行世界第五厉害了_大厂程序员年薪排名
- 9数字图像处理入门-邻域、连通性、通路和距离_数图路径的长度
- 10【Android Studio】Gradle版本 Gradle 插件 版本 Java版本 Androd studio版本统一问题_the specified gradle distribution
服务稳定性保障手段与规范_服务稳定性维护
赞
踩
服务的稳定性,对于任何一个在线提供服务给用户的公司来说,都是非常重要的。任何一次线上事故,都可能会给公司带来显而易见的损失。因为相比于其他部门,负责基础技术、公共服务的同学,发生事故的时候很容易暴露在风口浪尖之中,一个小小的变更,都可能会使得多个业务部门服务不可用,因此服务的稳定性保障则显得更加重要。
隐患发现
主动发现——故障演练
参考阿里云的故障演练产品:
故障演练是一款遵循混沌工程实验原理并融合了阿里巴巴内部实践的产品,提供丰富故障场景,能够帮助分布式系统提升容错性和可恢复性。
流程
故障演练建立了一套标准的演练流程,包含准备阶段、执行阶段、检查阶段和恢复阶段。通过四阶段的流程,覆盖用户从计划到还原的完整演练过程,并通过可视化的方式清晰的呈现给用户。

适用场景
故障演练可适用于以下典型场景:
- 衡量微服务的容错能力:通过模拟调用延迟、服务不可用、机器资源满载等,查看发生故障的节点或实例是否被自动隔离、下线,流量调度是否正确,预案是否有效,同时观察系统整体的QPS或RT是否受影响。在此基础上可以缓慢增加故障节点范围,验证上游服务限流降级、熔断等是否有效。最终故障节点增加到请求服务超时,估算系统容错红线,衡量系统容错能力。
- 验证容器编排配置是否合理:通过模拟杀服务Pod、杀节点、增大Pod资源负载,观察系统服务可用性,验证副本配置、资源限制配置以及Pod下部署的容器是否合理。
- 测试PaaS层是否健壮:通过模拟上层资源负载,验证调度系统的有效性;模拟依赖的分布式存储不可用,验证系统的容错能力;模拟调度节点不可用,测试调度任务是否自动迁移到可用节点;模拟主备节点故障,测试主备切换是否正常。
- 验证监控告警的时效性:通过对系统注入故障,验证监控指标是否准确,监控维度是否完善,告警阈值是否合理,告警是否快速,告警接收人是否正确,通知渠道是否可用等,提升监控告警的准确和时效性。
- 定位与解决问题的应急能力:通过故障突袭,随机对系统注入故障,考察相关人员对问题的应急能力,以及问题上报、处理流程是否合理,达到以战养战,锻炼人定位与解决问题的能力。
被动发现——监控告警
通过建立完善的监控告警机制,提前预知故障风险,减少故障持续时间
常见的监控有
网络分析与监控
站点监控
监控各云服务资源的监控指标,探测云服务ECS和运营商站点的可用性,并针对指定监控指标设置报警。使您全面了解阿里云上资源的使用情况和业务运行状况,并及时对故障资源进行处理,保证业务正常运行。
站点监控的典型应用场景如下:
- 运营商网络质量分析通过站点监控的探测点,模拟最终用户的访问行为,可以获得全国各地到目标地址的访问数据,从而知晓各地域、各运营商的网络质量,针对性进行网络优化。
- 性能分析通过创建站点监控任务,可以获得访问目标地址的DNS域名解析时间、建连时间、首包时间、下载时间等,从而分析服务的性能瓶颈。
拨测运营商探测点
从不同地域运营商网络的探测点发起HTTP、Ping、DNS或路由追踪的网络拨测,以便了解不同地域网络环境访问检测目标的情况。
事件监控
事件监控汇集产品故障、运维事件以及用户业务异常事件,提供按产品、级别、名称、应用分组汇总统计事件,便于关联资源和复盘问题。
日志监控
日志监控提供对日志数据实时分析、监控图表可视化展示和报警服务。常见的架构如下

自定义监控
自定义监控提供了自定义监控项和报警规则的功能,通过上报监控数据接口,将自己关心的业务指标上报至云监控,并在云监控上添加监控图表和设置报警规则,对于故障指标发送报警通知,便于及时处理故障,保障业务的正常运行。
制定稳定性规范
业务重大活动提前同步
活动通知邮件->运维及下游服务(配合压测及扩容)->运维评估确认->活动结束->运维评估确认(缩容)
定义故障标准
P0故障 ● 定义:业务关键流程不可用 ○ 业务关键流程界定 ■ 会造成资损的:交易支付相关核心流程(如:下单流程,支付流程等) ■ 会造成客诉的:用户体验相关核心流程(如:用户高频访问功能点) ● 定级参考度量方向 ○ 故障时长 ○ 影响用户规模 ○ 客诉/资损数量 处理规范 原则 1. 恢复第一:快速恢复服务可用为主,定位根本原因彻底解决为次,最小化故障影响是第一目标 2. 情况通报:情况通报须贯穿整个处理全流程,故障情况应当定时向集团消防队和相关群组通报 3. 恢复确认:故障恢复需要在多个确认方交叉验证通过,且建议设置合适的过渡观察期确认 4. 复盘&改进:故障必须复盘并产出优化方案,方案须细化为可验收的Action并指派负责人

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
定义故障处理规范

熟悉故障处理可用工具
- 链路平台:查询应用的链路日志
- 日志平台:提供应用日志的存储查询功能
- 监控平台:观测应用多个维度的指标表现
- arthas:arthas
- 堆栈分析:CPU过高、内存过高等
故障分析定位
分析最近发生的变化
- 故障系统最近是否有更改发布
- 依赖的系统是否更改发布
- 依赖的基础平台与资源是否升级过?
- 运营是否在系统内做过运营变更?
- 最近的业务量是否涨了?
- 运营方是否有促销活动?
故障排查流程
可参考下图

分析监控数据
应用层面监控
- JVM内存
- GC
- 各种连接池状态
系统层面监控包括
- 系统的 CPU 使用率
- Load average
- Memory
- I/O (网络与磁盘)
- SWAP 使用情况
- 线程数
- File Description 文件描述符等
中间件层面监控包括数据库、缓存、消息队列。
- 对数据库的负载、慢查询、连接数等监控
- 对缓存的连接数、占用内存、吞吐量、响应时间等监控
- 消息队列的响应时间、吞吐量、负载、堆积情况等监控
故障复盘规范
参与人员
主持人:故障模块/系统的研发TL担任,主导整个复盘会的流程节奏
汇报人:故障处理人负责汇报整个故障过程
其他人员:故障模块/系统的研发、运维、稳定性人员
复盘时间
故障修复后的3个工作日内(尽量早,以便大家总结经验)
复盘会由主持人发起,具体时间由主持人协调确定
故障定级
参考定级标准确定故障级别
故障命名
故障日期
−
{故障日期}-
故障日期−{业务线}-
模块
/
系统
−
{模块/系统}-
模块/系统−{故障现象}
复盘流程
主持人简单介绍故障情况(问题模块、故障时长、影响范围等)
处理人汇报故障发生、反馈、处理、修复、验证整体过程情况
主持人&处理人分析故障产生具体原因并以此提出优化方案供与会人员共同讨论
根据优化方案,与会人员共同细化分解任务并确定落实人员(一个主导人)和时间
会后主持人依据故障报告模板产出故障报告并邮件抄送所有与会人员
故障报告模板
故障名称:
故障发生时间:
故障报告时间:
故障恢复时间:
故障持续时间:
故障影响范围:
故障等级:
故障处理人:
故障责任人:
故障描述:
故障处理过程:
故障原因分析:
改进方案(任务、落实人、落实时间):
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
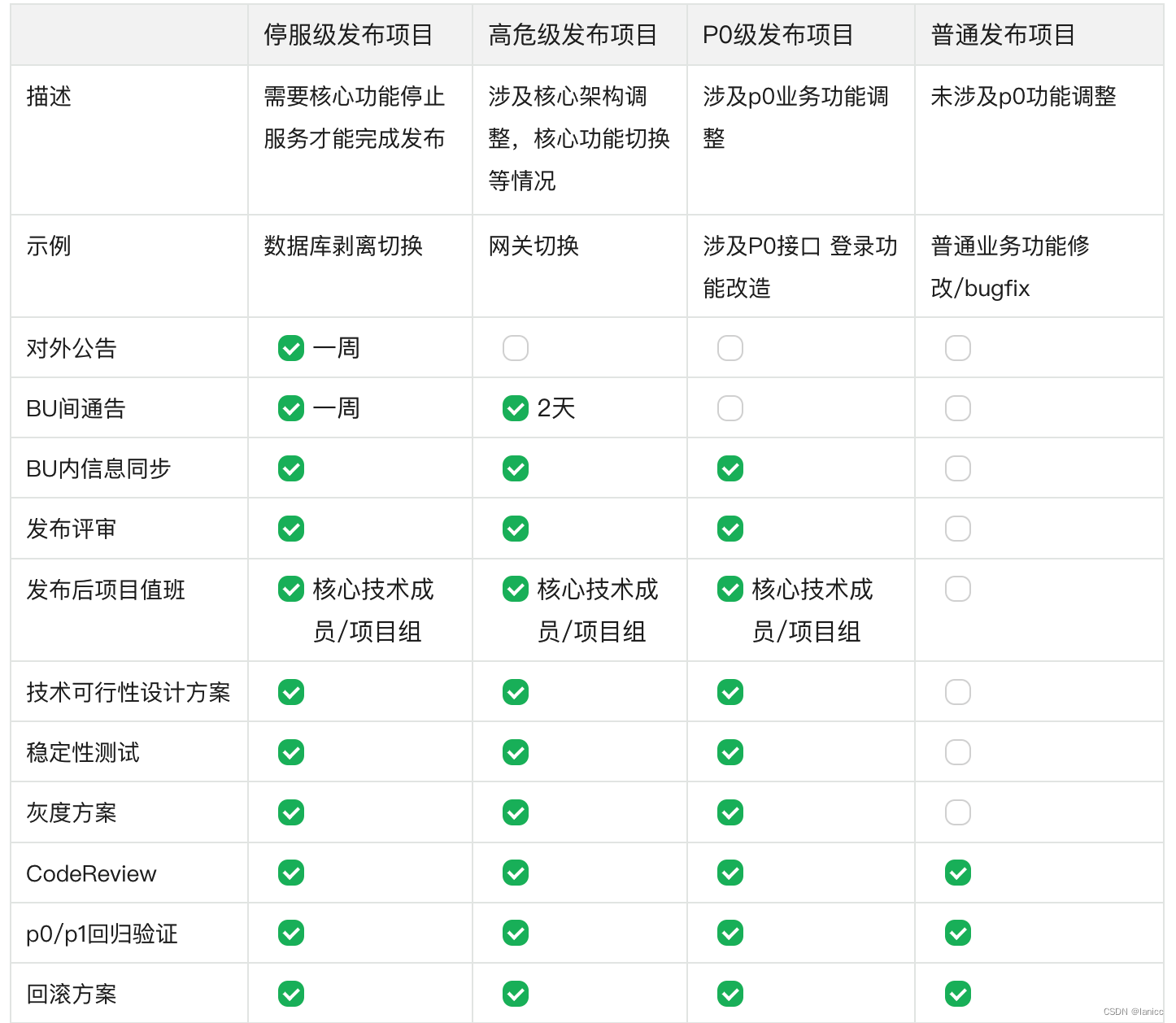
线上变更规范
除遵循通常的发布流程外,还应当对可能产生的故障做以下准备和检查:
checklist
总结
先保证基础设施的完备——完善的监控告警机制,配合主动发现,减少应用服务的故障隐患,再建立稳定性规范,将可能发生的故障减到最少,故障时长降到最低。

