
- 1jmeter连接mysql数据库驱动_Jmeter连接Mysql数据库
- 2程序员一般通过什么途径接私活?_计算机哪里接私活
- 3stable diffusion 安装xFormers 报错:Couldn‘t install open_clip._no module 'xformers'. proceeding without it.
- 4使用vue和web3创建你的第一个以太坊APP
- 5论文研读 | 大模型时序应用——基于对比学习的时序数据embedding_时序数据与大模型的推理
- 6手机照片彻底删除了还能找回来吗_手机相册的照片彻底删除了怎么恢复
- 7基于SpringBoot+Vue学生宿舍管理系统的设计与实现_基于springboot和vue框架的学生宿舍管理系统设计与实现
- 8专用计算机是为某种特定目的而设计的计算机,下列关于专用计算机的描述中,不正确的是____。A.为某种特定目的而设计B.针对性强、效率高C.用...
- 9基于JSP的网上购书系统_使用jsp 实现一个网上书店功能。(使用 mxsal 数据库。
- 10数据结构----顺序表
【本地大模型部署与微调】ChatGLM3-6b、m3e、one-api、Fastgpt_chatglm3微调最大输入上下文
赞
踩
先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Linux运维全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

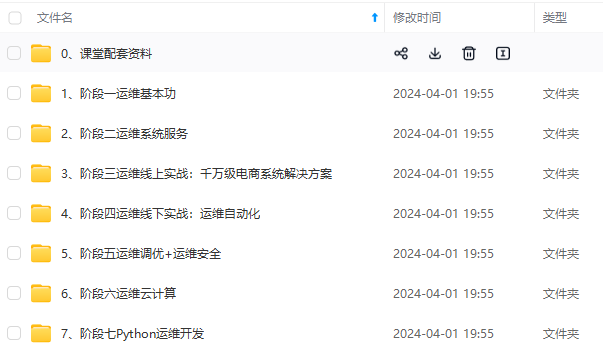
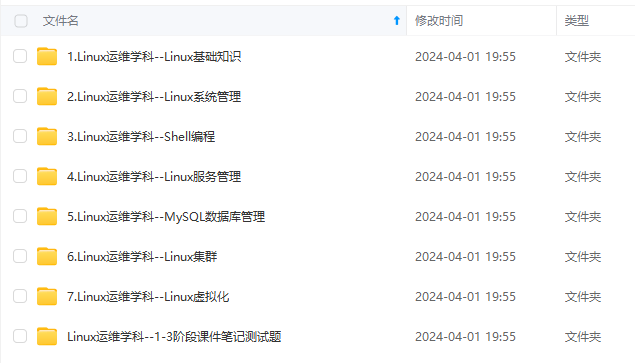
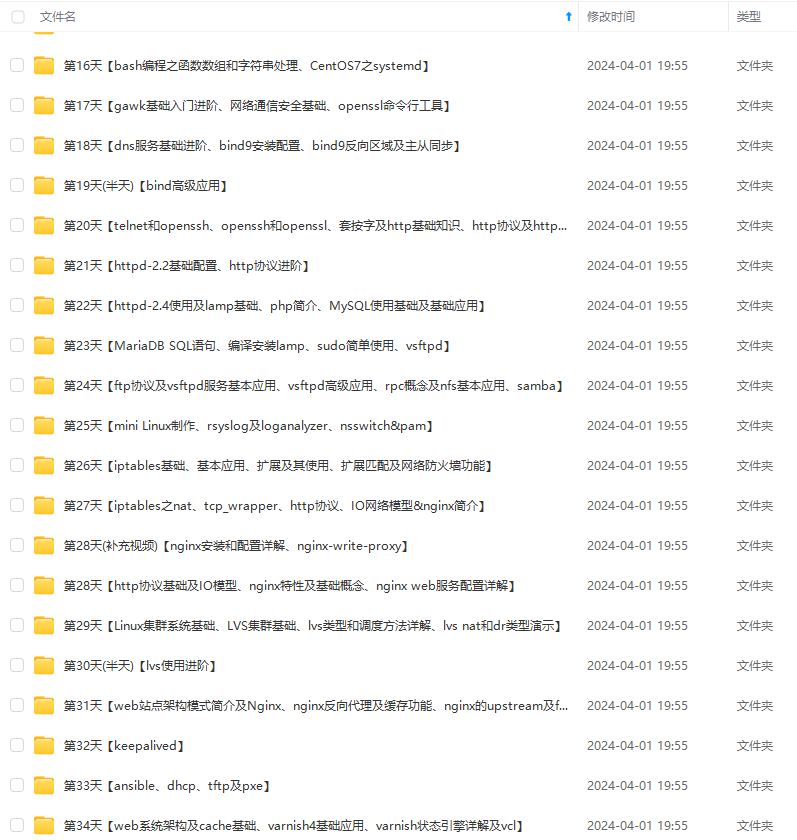
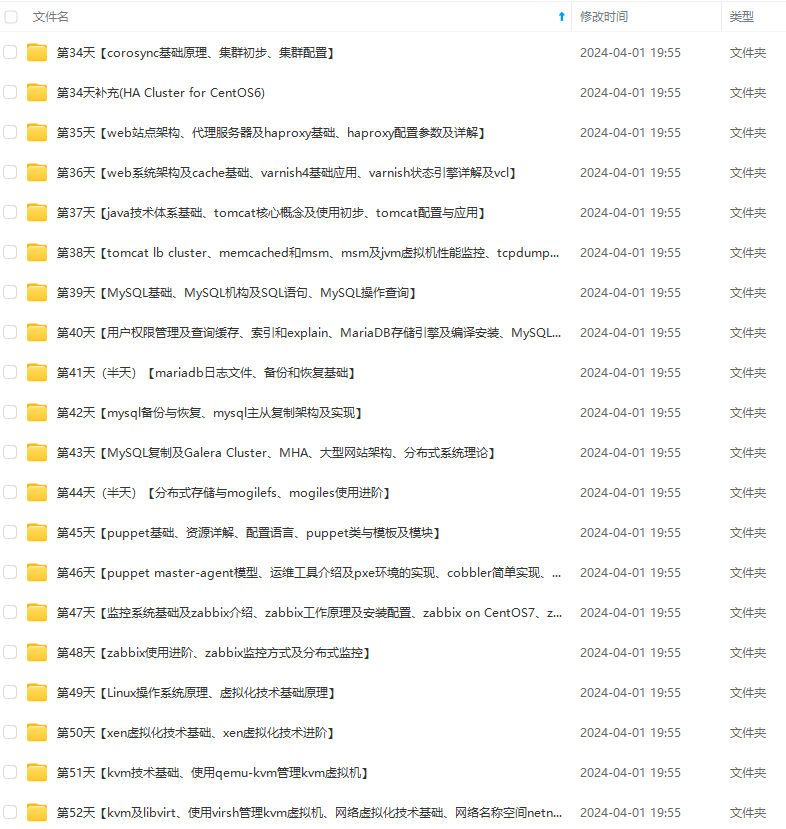
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上运维知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024b (备注运维)

正文
cd basic_demo
streamlit run web_demo_streamlit.py
**首次运行的话到1.4这停止,目的是为了测试大模型是否跑通.**
**下面的1.5 后面会有使用的时机**
#### 1.5 修改api\_server.py文件
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
cd ChatGLM3/openai_api_demo
然后找到api_server.py文件夹
修改里面的MODEL_PATH 和 EMBEDDING_PATH 为本地的大模型地址和向量模型地址
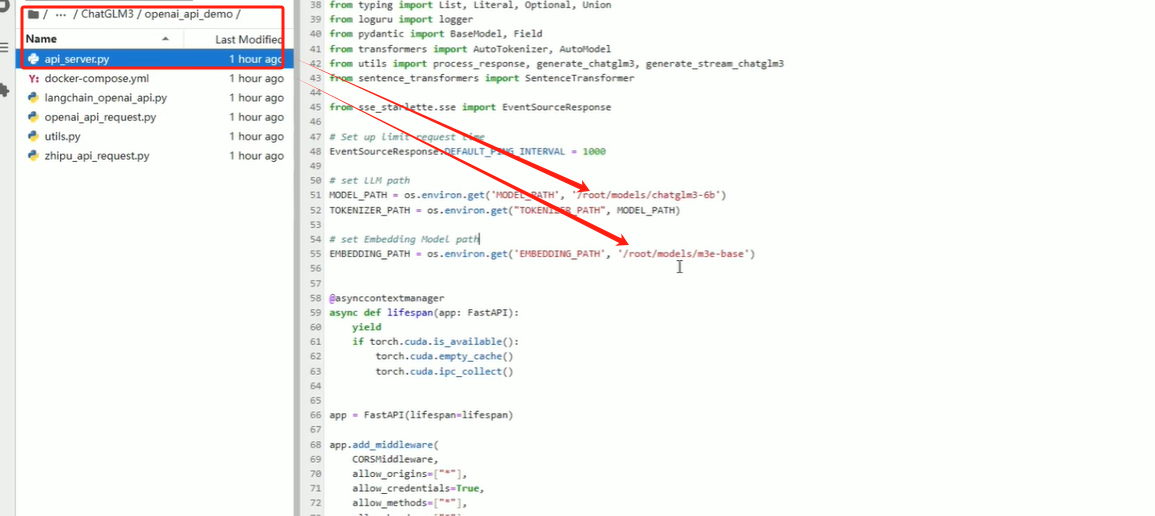
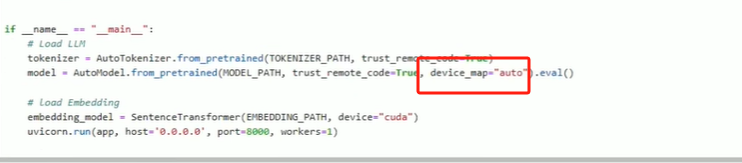
修改文件最下面的`device_map="cuda"`
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
model = AutoModel.from_pretrained(MODEL_PATH,trust_remote_code=True,device_map=“cuda”).eval()
### 2.下载docker和docker compose
- 1
- 2
- 3
- 4
- 5
安装 Docker
curl -fsSL https://get.docker.com | bash -s docker --mirror Aliyun
systemctl enable --now docker
安装 docker-compose
curl -L https://github.com/docker/compose/releases/download/v2.20.3/docker-compose-uname -s-uname -m -o /usr/local/bin/docker-compose
chmod +x /usr/local/bin/docker-compose
验证安装
docker -v
docker-compose -v
如失效,自行百度~
### 3.使用docker部署one-api项目
- 1
- 2
- 3
- 4
- 5
docker run --name one-api -d --restart always -p 3080:3000 -e TZ=Asia/Shanghai -v /home/ubuntu/data/one-api:/data justsong/one-api
#### 3.1 修改大模型运行端口 **把1.4运行的项目停止** **而后查看1.5的运行方式** #### 3.2添加chatglm3的渠道 **Base\_URL是部署大模型的服务器的ip地址,端口号为启动大模型的端口号.** **秘钥随便填** 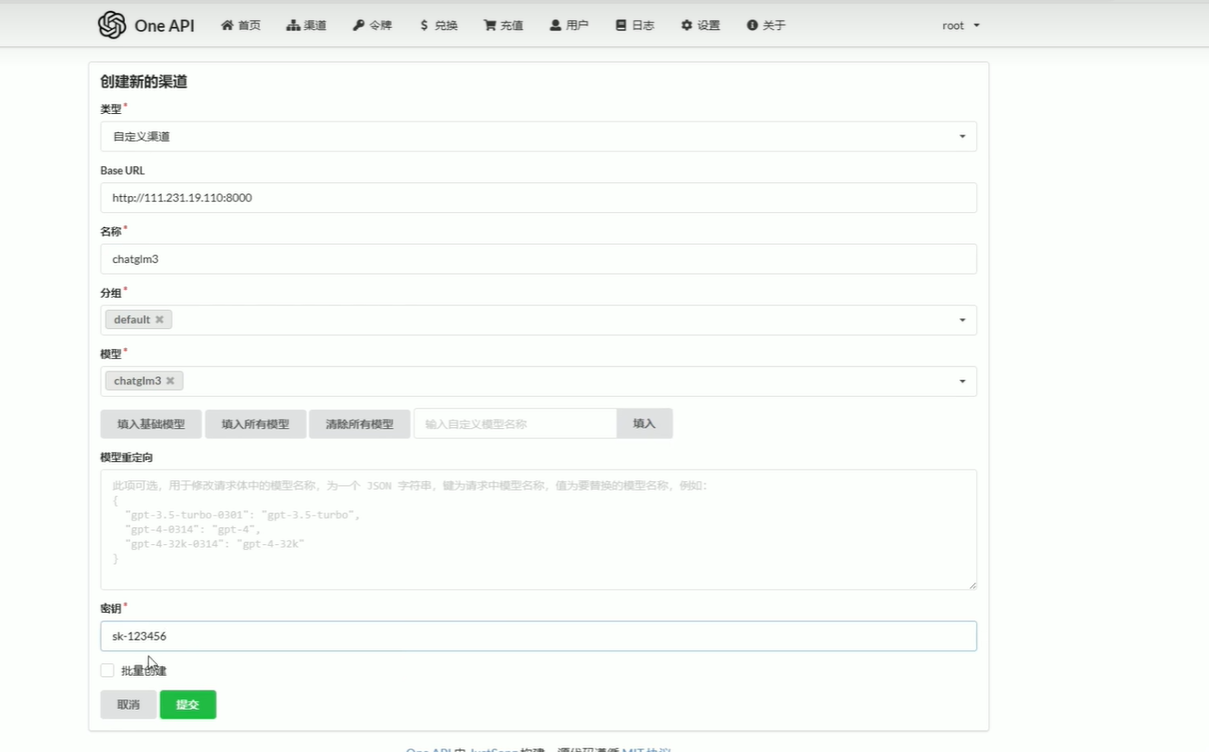 #### 3.3添加m3e渠道 同上 #### 3.4测试渠道是否跑通 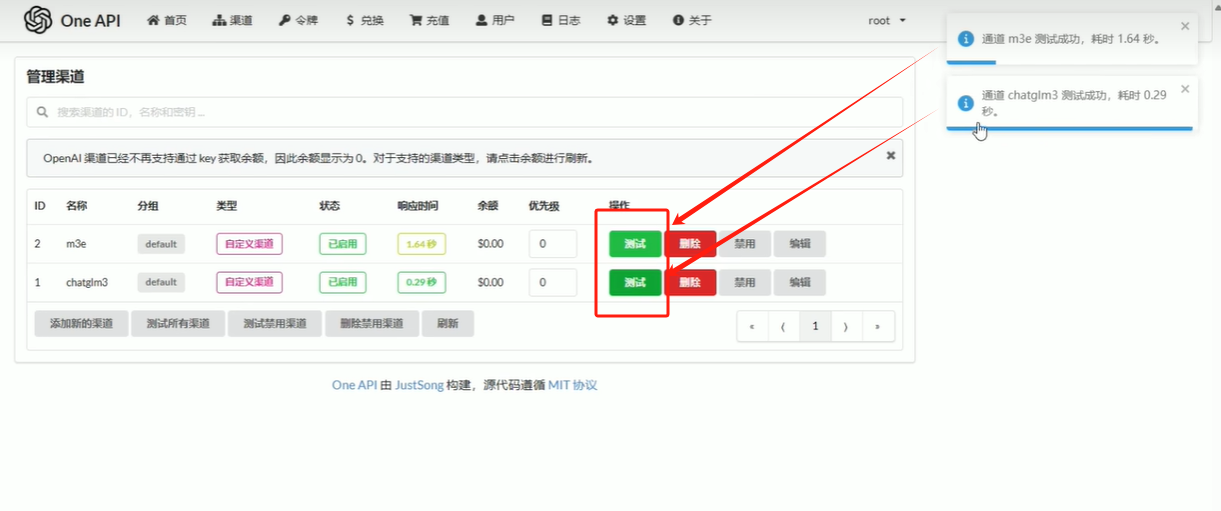 #### 3.5添加令牌  ### 4.部署fastgpt

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
mkdir fastgpt
cd fastgpt
curl -O https://raw.githubusercontent.com/labring/FastGPT/main/files/deploy/fastgpt/docker-compose.yml
curl -O https://raw.githubusercontent.com/labring/FastGPT/main/projects/app/data/config.json
#### 4.1修改docker-compose.yml
修改docker-compose.yml中的OPENAI\_BASE\_URL(API 接口的地址,需要加/v1)和CHAT\_API\_KEY(API 接口的凭证)。
使用 OneAPI 的话,OPENAI\_BASE\_URL=OneAPI访问地址/v1;CHAT\_API\_KEY=令牌
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
非 host 版本, 不使用本机代理
(不懂 Docker 的,只需要关心 OPENAI_BASE_URL 和 CHAT_API_KEY 即可!)
version: ‘3.3’
services:
pg:
image: ankane/pgvector:v0.5.0 # git
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/pgvector:v0.5.0 # 阿里云
container_name: pg
restart: always
ports: # 生产环境建议不要暴露
- 5432:5432
networks:
- fastgpt
environment:
# 这里的配置只有首次运行生效。修改后,重启镜像是不会生效的。需要把持久化数据删除再重启,才有效果
- POSTGRES_USER=username
- POSTGRES_PASSWORD=password
- POSTGRES_DB=postgres
volumes:
- ./pg/data:/var/lib/postgresql/data
mongo:
image: registry.cn-hangzhou.aliyuncs.com/fastgpt/mongo:5.0.18
container_name: mongo
restart: always
ports:
- 27017:27017
networks:
- fastgpt
command: mongod --keyFile /data/mongodb.key --replSet rs0
environment:
- MONGO_INITDB_ROOT_USERNAME=myusername
- MONGO_INITDB_ROOT_PASSWORD=mypassword
volumes:
- ./mongo/data:/data/db
entrypoint:
- bash
- -c
- |
openssl rand -base64 128 > /data/mongodb.key
chmod 400 /data/mongodb.key
chown 999:999 /data/mongodb.key
exec docker-entrypoint.sh $$@
fastgpt:
container_name: fastgpt
image: ghcr.io/labring/fastgpt:latest # git
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt:latest # 阿里云
ports:
- 3000:3000
networks:
- fastgpt
depends_on:
- mongo
- pg
restart: always
environment:
# root 密码,用户名为: root
- DEFAULT_ROOT_PSW=1234
# 中转地址,如果是用官方号,不需要管。务必加 /v1
- OPENAI_BASE_URL=https://api.openai.com/v1
- CHAT_API_KEY=sk-xxxx
- DB_MAX_LINK=5 # database max link
- TOKEN_KEY=any
- ROOT_KEY=root_key
- FILE_TOKEN_KEY=filetoken
# mongo 配置,不需要改. 用户名myusername,密码mypassword。
- MONGODB_URI=mongodb://myusername:mypassword@mongo:27017/fastgpt?authSource=admin
# pg配置. 不需要改
- PG_URL=postgresql://username:password@pg:5432/postgres
volumes:
- ./config.json:/app/data/config.json
networks:
fastgpt:
#### 4.2 修改config.json
需要注意的是llmModels中datasetProcess必须设置为true知识库才会生效,否则知识库会出问题
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
{
“systemEnv”: {
“vectorMaxProcess”: 15,
“qaMaxProcess”: 15,
“pgHNSWEfSearch”: 100 // 向量搜索参数。越大,搜索越精确,但是速度越慢。设置为100,有99%+精度。
},
“llmModels”: [
{
“model”: “chatglm3”, // 模型名
“name”: “chatglm3”, // 别名
“maxContext”: 16000, // 最大上下文
“maxResponse”: 4000, // 最大回复
“quoteMaxToken”: 13000, // 最大引用内容
“maxTemperature”: 1.2, // 最大温度
“charsPointsPrice”: 0,
“censor”: false,
“vision”: false, // 是否支持图片输入
“datasetProcess”: true, // 是否设置为知识库处理模型(QA),务必保证至少有一个为true,否则知识库会报错
“usedInClassify”: true, // 是否用于问题分类(务必保证至少有一个为true)
“usedInExtractFields”: true, // 是否用于内容提取(务必保证至少有一个为true)
“usedInToolCall”: true, // 是否用于工具调用(务必保证至少有一个为true)
“usedInQueryExtension”: true, // 是否用于问题优化(务必保证至少有一个为true)
“toolChoice”: true, // 是否支持工具选择(分类,内容提取,工具调用会用到。目前只有gpt支持)
“functionCall”: false, // 是否支持函数调用(分类,内容提取,工具调用会用到。会优先使用 toolChoice,如果为false,则使用 functionCall,如果仍为 false,则使用提示词模式)
“customCQPrompt”: “”, // 自定义文本分类提示词(不支持工具和函数调用的模型
“customExtractPrompt”: “”, // 自定义内容提取提示词
“defaultSystemChatPrompt”: “”, // 对话默认携带的系统提示词
“defaultConfig”:{} // LLM默认配置,可以针对不同模型设置特殊值(比如 GLM4 的 top_p
},
],
“vectorModels”: [
{
“model”: “m3e”,
“name”: “m3e”,
“charsPointsPrice”: 0,
“defaultToken”: 700,
“maxToken”: 3000,
“weight”: 100,
“defaultConfig”:{} // 默认配置。例如,如果希望使用 embedding3-large 的话,可以传入 dimensions:1024,来返回1024维度的向量。(目前必须小于1536维度)
}
],
“reRankModels”: [],
“audioSpeechModels”: [
{
“model”: “tts-1”,
“name”: “OpenAI TTS1”,
“charsPointsPrice”: 0,
“voices”: [
{ “label”: “Alloy”, “value”: “alloy”, “bufferId”: “openai-Alloy” },
{ “label”: “Echo”, “value”: “echo”, “bufferId”: “openai-Echo” },
{ “label”: “Fable”, “value”: “fable”, “bufferId”: “openai-Fable” },
{ “label”: “Onyx”, “value”: “onyx”, “bufferId”: “openai-Onyx” },
{ “label”: “Nova”, “value”: “nova”, “bufferId”: “openai-Nova” },
{ “label”: “Shimmer”, “value”: “shimmer”, “bufferId”: “openai-Shimmer” }
]
}
],
“whisperModel”: {
“model”: “whisper-1”,
“name”: “Whisper1”,
“charsPointsPrice”: 0
}
}
#### 4.3 启动容器
- 1
- 2
- 3
- 4
- 5
进入项目目录
cd 项目目录
启动容器
docker-compose pull
docker-compose up -d
#### 4.4 初始化Mongo副本集(4.6.8以前可忽略)
- 1
- 2
- 3
- 4
- 5
查看 mongo 容器是否正常运行
docker ps
进入容器
docker exec -it mongo bash
连接数据库(这里要填Mongo的用户名和密码)
mongo -u myusername -p mypassword --authenticationDatabase admin
初始化副本集。如果需要外网访问,mongo:27017 可以改成 ip:27017。但是需要同时修改 FastGPT 连接的参数(MONGODB_URI=mongodb://myname:mypassword@mongo:27017/fastgpt?authSource=admin => MONGODB_URI=mongodb://myname:mypassword@ip:27017/fastgpt?authSource=admin)
rs.initiate({
_id: “rs0”,
members: [
{ _id: 0, host: “mongo:27017” }
]
})
检查状态。如果提示 rs0 状态,则代表运行成功
rs.status()
#### 4.5 访问fastGPT 目前可以通过 ip:3000 直接访问(注意防火墙)。登录用户名为 root,密码为docker-compose.yml环境变量里设置的 DEFAULT\_ROOT\_PSW。 如果需要域名访问,请自行安装并配置 Nginx。 ### 5.微调大模型 **微调大模型的时候,需要把运行中的大模型服务停止,否则会出现运行显存不足的错误.** #### 5.1环境搭建(可跳过)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
git clone https://github.com/hiyouga/LLaMA-Factory.git
conda create -n llama_factory python=3.10
conda activate llama_factory
cd LLaMA-Factory
pip install -r requirements.txt
#### 5.2取sha1值 为了做好运维面试路上的助攻手,特整理了上百道 **【运维技术栈面试题集锦】** ,让你面试不慌心不跳,高薪offer怀里抱! 这次整理的面试题,**小到shell、MySQL,大到K8s等云原生技术栈,不仅适合运维新人入行面试需要,还适用于想提升进阶跳槽加薪的运维朋友。**  本份面试集锦涵盖了 * **174 道运维工程师面试题** * **128道k8s面试题** * **108道shell脚本面试题** * **200道Linux面试题** * **51道docker面试题** * **35道Jenkis面试题** * **78道MongoDB面试题** * **17道ansible面试题** * **60道dubbo面试题** * **53道kafka面试** * **18道mysql面试题** * **40道nginx面试题** * **77道redis面试题** * **28道zookeeper** **总计 1000+ 道面试题, 内容 又全含金量又高** * **174道运维工程师面试题** > 1、什么是运维? > 2、在工作中,运维人员经常需要跟运营人员打交道,请问运营人员是做什么工作的? > 3、现在给你三百台服务器,你怎么对他们进行管理? > 4、简述raid0 raid1raid5二种工作模式的工作原理及特点 > 5、LVS、Nginx、HAproxy有什么区别?工作中你怎么选择? > 6、Squid、Varinsh和Nginx有什么区别,工作中你怎么选择? > 7、Tomcat和Resin有什么区别,工作中你怎么选择? > 8、什么是中间件?什么是jdk? > 9、讲述一下Tomcat8005、8009、8080三个端口的含义? > 10、什么叫CDN? > 11、什么叫网站灰度发布? > 12、简述DNS进行域名解析的过程? > 13、RabbitMQ是什么东西? > 14、讲一下Keepalived的工作原理? > 15、讲述一下LVS三种模式的工作过程? > 16、mysql的innodb如何定位锁问题,mysql如何减少主从复制延迟? > 17、如何重置mysql root密码? **网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。** **需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注运维)**  **一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!** 么叫网站灰度发布? > 12、简述DNS进行域名解析的过程? > 13、RabbitMQ是什么东西? > 14、讲一下Keepalived的工作原理? > 15、讲述一下LVS三种模式的工作过程? > 16、mysql的innodb如何定位锁问题,mysql如何减少主从复制延迟? > 17、如何重置mysql root密码? **网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。** **需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注运维)** [外链图片转存中...(img-TAwcbW8k-1713206123897)] **一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92

