
热门标签
热门文章
- 12023年pythonB组省赛题解_2023蓝桥杯省赛pythonb组第二题啥意思
- 2Android Studio 实现天气预报App (简单方便展示内容超多)_android天气预报案例
- 3大模型综述来了!一文带你理清全球AI巨头的大模型进化史_代码大模型梳理
- 4Edge插件推荐_edge 如何安装ublock plugin
- 5异或和 蓝桥杯2024python省赛 题解_蓝桥杯2024 python
- 6软件测试技术之【自动化测试】_软件自动化测试
- 7移动端安全框架:MobSF:概要与使用_opensecurity/mobile-security-framework-mobsf
- 8EI级 | Matlab实现TCN-LSTM-MATT、TCN-LSTM、TCN、LSTM多变量时间序列预测对比
- 9工作中Git如何切换远程仓库地址_git切换上游仓库地址
- 10VSCode 连接远程 GitHub仓库 教程_vscode中项目怎么关联仓库
当前位置: article > 正文
python S-G (Savitzky–Golay filter) 平滑滤波和kalman滤波滤掉噪声实现实例,有可视化结果_s-g 滤波算法
作者:花生_TL007 | 2024-04-27 03:50:31
赞
踩
s-g 滤波算法
1、不讲理论推导,直接上实例,传参即用,欢迎咨询
s-g滤波有滞后性,需要缓存一定的数据,kalman滤波则无需缓存数据,可达到实时效果
- import pandas as pd
- from scipy.signal import savgol_filter as sg
- import numpy as np
- from matplotlib import pyplot as plt
-
- # sg 滤波算法 scipy中有集成不需自己定义
- # kalman 滤波算法 需要自己定义手写
-
-
- def kalman_filter(data, q=0.0001, r=0.01):
- # 后验初始值
- x0 = data[0] # 令第一个估计值,为当前值
- p0 = 1.0
- # 存结果的列表
- x = [x0]
- for z in data[1:]: # kalman 滤波实时计算,只要知道当前值z就能计算出估计值(后验值)x0
- # 先验值
- x1_minus = x0 # X(k|k-1) = AX(k-1|k-1) + BU(k) + W(k), A=1,BU(k) = 0
- p1_minus = p0 + q # P(k|k-1) = AP(k-1|k-1)A' + Q(k), A=1
- # 更新K和后验值
- k1 = p1_minus / (p1_minus + r) # Kg(k)=P(k|k-1)H'/[HP(k|k-1)H' + R], H=1
- x0 = x1_minus + k1 * (z - x1_minus) # X(k|k) = X(k|k-1) + Kg(k)[Z(k) - HX(k|k-1)], H=1
- p0 = (1 - k1) * p1_minus # P(k|k) = (1 - Kg(k)H)P(k|k-1), H=1
- x.append(x0) # 由输入的当前值z 得到估计值x0存入列表中,并开始循环到下一个值
- return x
-
-
- if __name__ == '__main__':
- path = r'xx.txt'
- txttable = pd.read_table(path, sep=' ', header=None)
- zz = np.array(txttable.iloc[:, 115]) # 原始数据
- res_sg = sg(x=zz, window_length=31, polyorder=1) # sg滤波, 直接调用scipy.signal中的savgol_filter函数, window_length 需要为正奇数, polyorder 最小二乘法拟合阶数
- res_kalman = kalman_filter(zz) # 自己定义个函数
-
- # 可视化两个效果
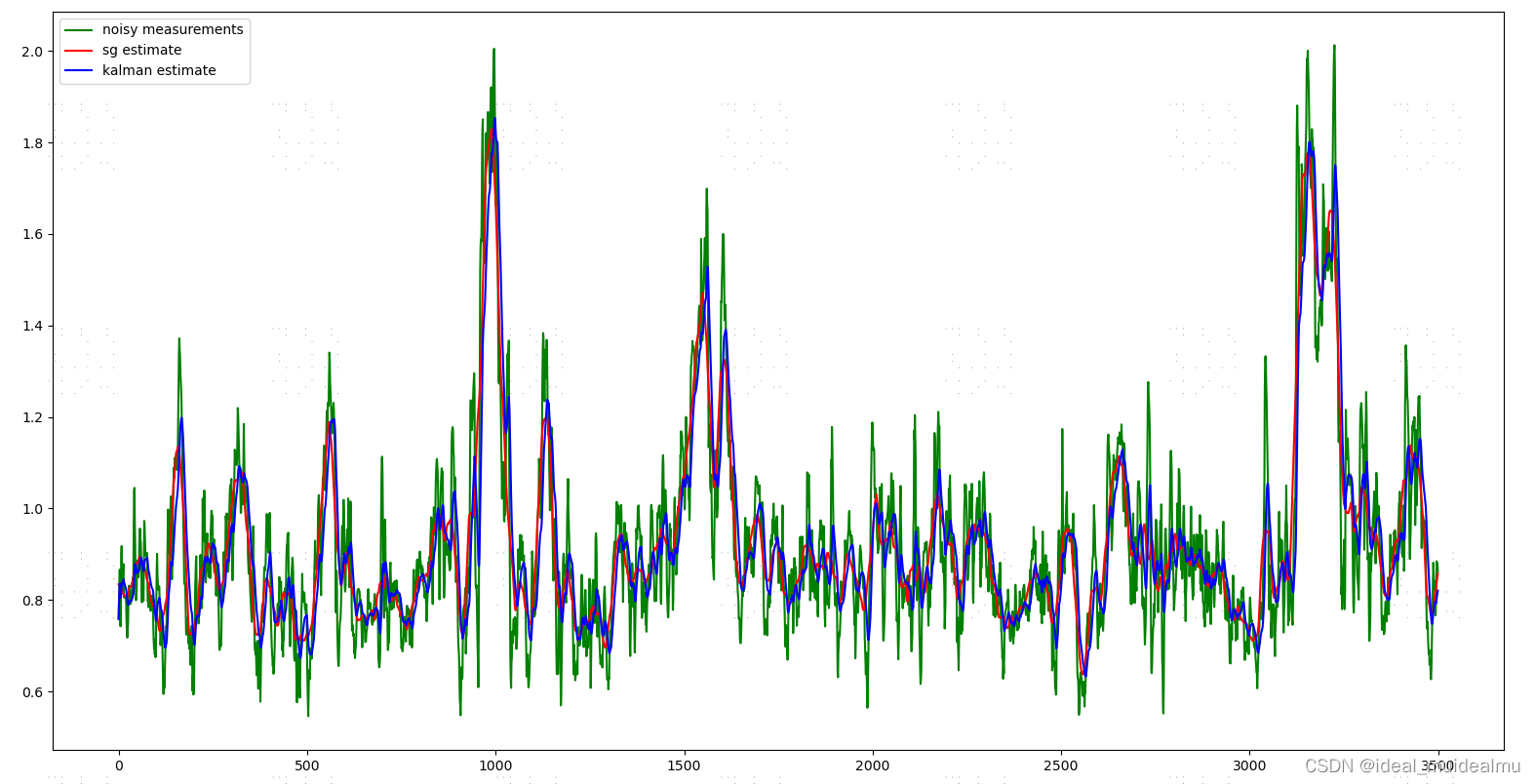
- plt.plot(zz, 'g', label='noisy measurements') # 真实值
- plt.plot(res_sg, 'r', label='sg estimate') # sg 估计值
- plt.plot(res_kalman, 'b-', label='kalman estimate') # kl 估计值
- plt.legend()
- plt.show()
2、结果
两种算法都在一定程度上对数据进行了噪声滤波处理,一定程度上滤除了噪声,保留了瞬态值
3、算法说明
S-G滤波器 S-G 滤波器(Savitzky–Golay filter),它的核心思想是对一定长度窗口内的数据点进行 k 阶多项式拟合 。因此他有一个问题,无法实时处理数据,需要window_length的数据长度作为缓存来拟合数据,也就是需要前后各window_length//2个数据,因此对实时数据会滞后15帧。这也是weindow_length为奇数的原因 kalman 滤波器: 当 Q 较大时,表明预测状态的方差较大,使得我们比较相信测量值;而当 Q 较小时,我们则比较相信预测值,提高了滤波结果的平滑性,但也增大了滤波结果的滞后性。因此在实际应用中,应当特别注意 Q 和 R 值的选择。 Q:预测状态协方差,越小系统越容易收敛,我们对模型预测的值信任度越高;但是太小则容易发散,如果 Q 为零,那么我们只相信预测值;Q 值越大我们对于预测的信任度就越低,而对测量值的信任度就变高;如果 Q 值无穷大,那么我们只信任测量值; R:观测状态协方差,如果 R 太大,则表现它对新测量值的信任度降低而更愿意相信预测值,从而使得 kalman 的滤波结果会表现得比较规整和平滑,但是其响应速度会变慢而出现滞后; P:误差协方差初始值,表示我们对当前预测状态的信任度。它越小说明我们越相信当前预测状态;它的值决定了初始收敛速度,一般开始设一个较小的值以便于获取较快的收敛速度。随着卡尔曼滤波的迭代,P的值会不断的改变,当系统进入稳态之后P值会收敛成一个最小的估计方差矩阵,这个时候的卡尔曼增益也是最优的,所以这个值只是影响初始收敛速度。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/花生_TL007/article/detail/494656
推荐阅读
相关标签

