
- 1【机器学习】决策树特征选择准则 信息增益、信息增益率、基尼系数的计算及其python实现_机器学习增益率计算题
- 2Git 中强行拉取,覆盖本地修改_git强制将远程覆盖到本地
- 3图像处理ASIC设计方法 笔记18 轮廓跟踪算法的硬件加速方案
- 4【深入浅出Spring原理及实战】「Web请求读取系列」如何构建一个可重复读取的Request的流机制_javaweb 请求流重复读取
- 5面向中文大模型价值观的评估与对齐研究:给AI的100瓶毒药
- 6uni.app开发小程序如何获取当前经纬度、位置信息以及如何重新发起授权定位_uniapp获取当前经纬度
- 7VHDL仿真ModelSim使用简介_modelsim vhdl
- 8mvc控制器html返回json,asp.net-mvc – 如何从MVC控制器返回Json对象到视图
- 9Meta 新推出的实时语音翻译模型 Seamless_seamless expressive
- 10华纳云:ubuntu中fdisk找不到硬盘怎么解决?
【注册中心】ZooKeeper
赞
踩
概述
Zookeeper 是一个开源的分布式 协调服务框架,它是一个为分布式应用提供一致性服务的软件。
Zookeeper 致力于提供一个高性能、高可用,且具备严格的顺序访问控制能力的分 布式协调服务,是雅虎公司创建,是 Google 的 Chubby 一个开源的实现。
Zookeeper的应用场景
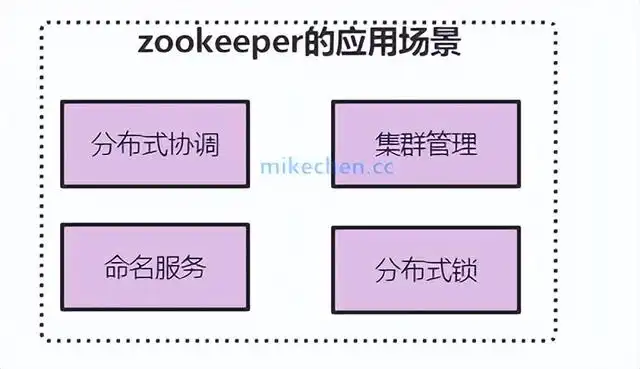
1.命名服务Name Service
依赖Zookeeper可以生成全局唯一的节点ID,来对分布式系统中的资源进行管理。
2.分布式协调
这是Zookeeper的核心使用了。利用Wather的监听机制,一个系统的某个节点状态发生改变,另外系统可以得到通知。
3.集群管理
分布式集群中状态的监控和管理,使用Zookeeper来存储。
4.分布式锁
利用Zookeeper创建临时顺序节点的特性。
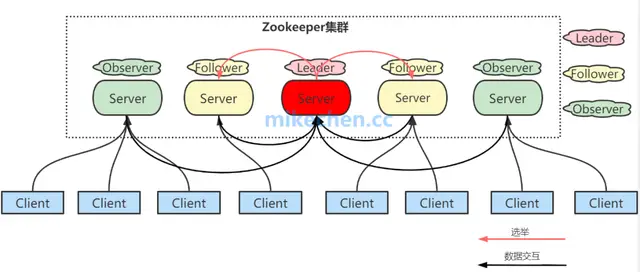
Zookeeper的角色
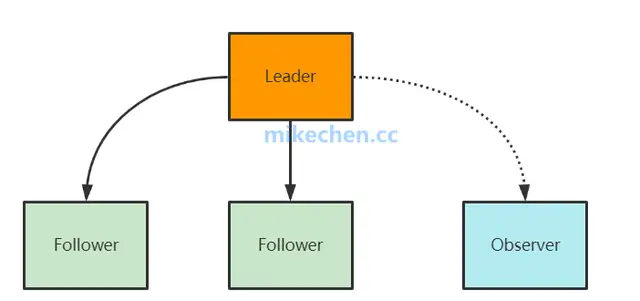
- leader角色
处理所有的事务请求(写请求),可以处理读请求,集群中只能有一个Leader
- Follower角色
只能处理读请求,同时作为 Leader的候选节点,即如果Leader宕机,Follower节点要参与到新的Leader选举中,有可能成为新的Leader节点。
- Observer角色
Observer:只能处理读请求,不能参与选举。
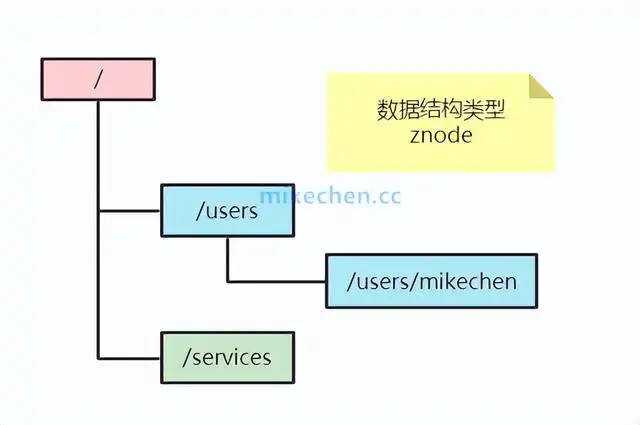
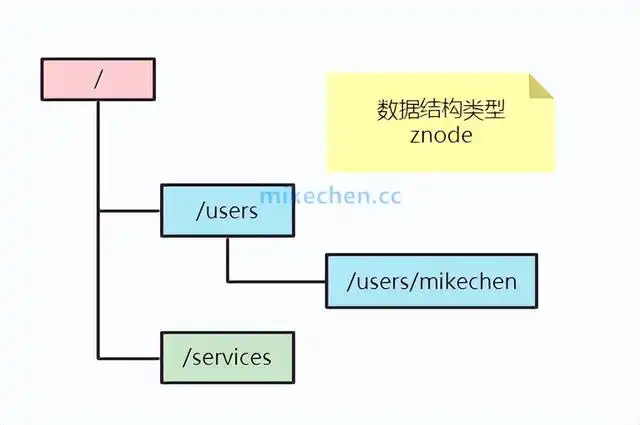
Zookeeper 的数据模型
在 Zookeeper 中,可以说 Zookeeper 中的所有存储的数据是由 znode 组成的,节点也称为 znode,并以 key/value 形式存储数据。
整体结构类似于 linux 文件系统的模式以树形结构存储,其中根路径以 / 开头。
提供了四种类型的数据节点 Znode:
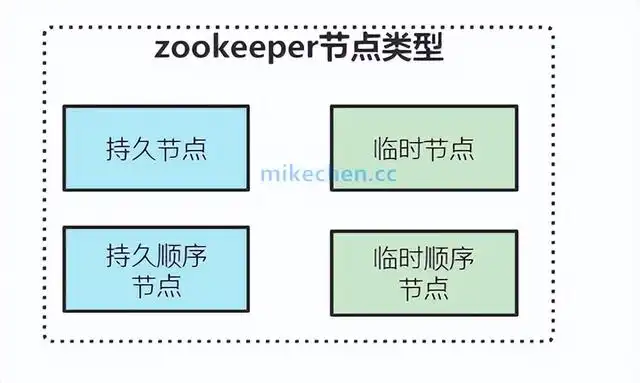
1.持久节点
除非手动删除,否则节点一直存在于Zookeeper上
2.持久顺序节点
基本特性同持久节点,只是增加了顺序属性,节点名后边会追加一个由父节点维护的自增整型数字
3.临时节点
客户端与Zookeeper断开连接后,该节点被删除
4.临时顺序节点
基本特性同临时节点,增加了顺序属性,节点名后边会追加一个由父节点维护的自增整型数字
zookeeper客户端常用命令
1)、连接zookeeper服务端(Linux): ./zkCli.sh -server ip:port
2)、断开zookeeper服务端的连接: quit
3)、查看帮助: help
4)、查询所有的目录节点: ls /
5)、创建目录节点: create /节点名 值(可写可不写)
6)、设置目录节点的值(修改时也可以): set /节点名 值
7)、删除单个目录节点: delete /节点名
8)、删除带有子节点的目录: deleteall /节点名
9)、创建临时目录节点: create -e /节点名 值(可写可不写)
10)、创建持久化目录节点: create -s /节点名 值(可写可不写)
11)、查询目录节点的详情信息: ls -s /节点名
Zookeeper的核心功能
虽然可以用Zookeeper实现很多功能,但是主要提供了三个核心功能:
1.文件系统
zk的存储的数据的结构,类似于一个文件系统。
每个节点称为znode,每个znode都是一个类似于KV的结构,每个节点名称相当于key,每个节点中都保存了对应的数据,类似于Key对应的value。每个znode下面都可以有多个子节点,就这样一直延续下去,构成了类似于Linux文件系统的架构。
2.通知机制
当某个client监听某个节点时,当该节点发生变化时(有可能是增加子节点,或者节点值变了等),zk就会通知监听该节点的客户端来处理。
3.集群管理机制
zk本身是一个集群结构,有一个leader节点,负责写请求,多个follower负责响应读请求。并且在leader节点故障时,会自动根据选举机制从剩下的follower中选出新的leader。
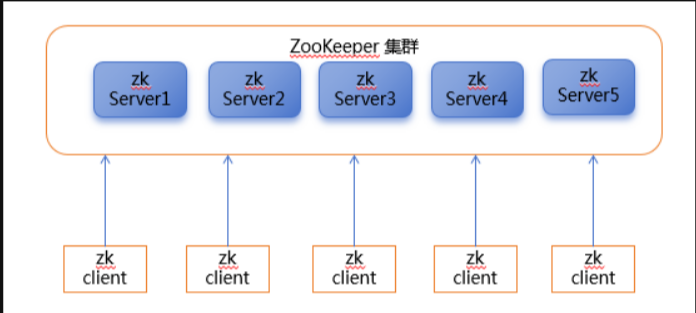
Zookeeper的架构与集群规则
集群为2N+1台,N>0,比如N为1的情况就是3台。
为什么是3台而不是2台呢?因为集群需要一半以上的机器可用,所以,3台挂掉1台还能工作,2台不能。
Leader选举:
• Serverid :服务器 ID
比如有三台服务器,编号分别是1,2,3。
编号越大在选择算法中的权重越大。
- 1
• Zxid :数据 ID
服务器中存放的最大数据ID.值越大说明数据 越新,在选举算法中数据越新权重越大。
• 在 Leader 选举的过程中,如果某台 ZooKeeper
获得了超过半数的选票,
则此ZooKeeper就可以成为Leader了
- 1
Zookeeper的工作模式
1.Zookeeper从设计模式的角度理解,是一个基于观察者模式设计的分布式服务管理框架。
2.基于事件监听通知,监听注册到上面的节点的动向(修改、新增、删除),会实时的通知访问客户端。
3.选举机制,中心化思想,分为主从操作,进行分布式控制所有slave之间的同步决策。
Zab 协议的原理可细分为四个阶段:选举(Leader Election)、发现(Discovery)、同步(Synchronization)和广播(Broadcast)。
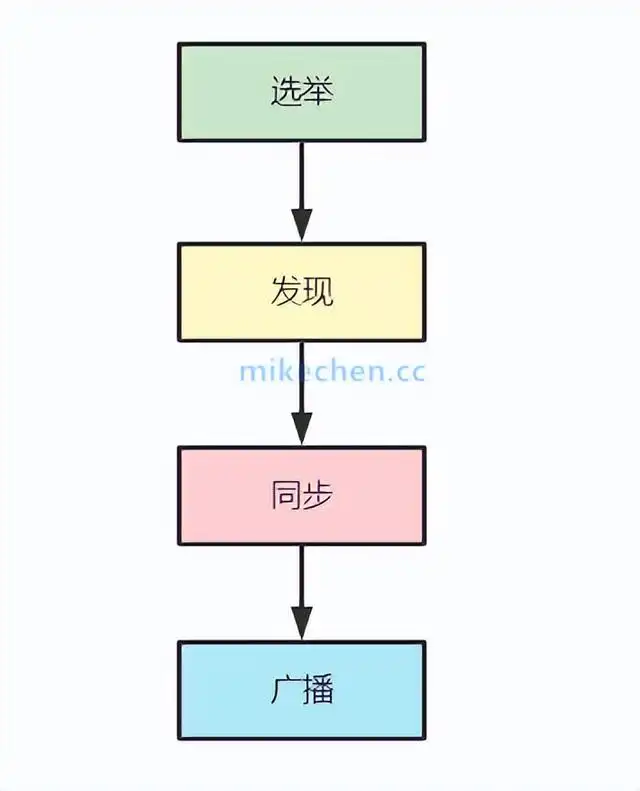
1.Leader election(选举阶段)
节点在一开始都处于选举阶段,只要有一个节点得到超过半数节点的票数,它就可以当选准 Leader。
2.Discovery(发现阶段)
在这个阶段,Followers跟准Leader进行通信,同步Followers最近接收的事务提议。
3.Synchronization(同步阶段)
同步阶段主要是利用Leader前一阶段获得的最新提议历史,同步集群中所有的副本。同步完成之后准Leader才会成为真正的Leader。
4.Broadcast(广播阶段)
到了这个阶段,Zookeeper集群才能正式对外提供事务服务,并且Leader 可以进行消息广播。同时如果有新的节点加入,还需要对新节点进行同步。
Zookeeper如何实现分布式锁
常见的分布式锁实现方案里面,除了使用redis来实现之外,使用Zookeeper也可以实现分布式锁。
Zookeeper 分布式锁是基于 临时顺序节点 来实现的,锁可理解为 Zookeeper 上的一个节点,当需要获取锁时,就在这个锁节点下创建一个临时顺序节点。
如下图所示:
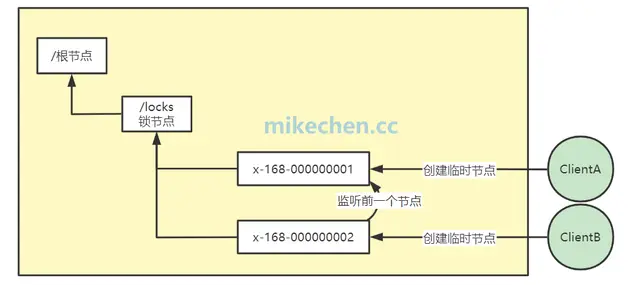
当存在多个客户端同时来获取锁,就按顺序依次创建多个临时顺序节点,但只有排列序号是第一的那个节点能获取锁成功。
其他节点则按顺序分别监听前一个节点的变化,当被监听者释放锁时,监听者就可以马上获得锁。
Zookeeper JavaAPI(Curator)
1、简介
Apache Curator 是一个用于Apache ZooKeeper 的Java 客户端框架。 Curator 提供了一组易于使用的API和工具,简化了与ZooKeeper 的交互,同时提供了更高级别的抽象和功能。
2、搭建和使用Curator(以下环境使用的是spring boot)
1)、引入Curator支持
<!-- zookeeper支持 --> <dependency> <groupId>org.apache.zookeeper</groupId> <artifactId>zookeeper</artifactId> <version>3.6.4</version> </dependency> <!-- curator-recipes --> <dependency> <groupId>org.apache.curator</groupId> <artifactId>curator-recipes</artifactId> <version>5.5.0</version> </dependency> <!-- curator-framework --> <dependency> <groupId>org.apache.curator</groupId> <artifactId>curator-framework</artifactId> <version>5.5.0</version> </dependency>

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
2)、连接zookeeper客户端
//超时重试(连接间隔时间和超时连接次数)
RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000, 5);
//连接zookeeper对象
client = CuratorFrameworkFactory.newClient(
"ip:port",
1000,
60*1000,
retryPolicy);
//开始连接
client.start();
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
3)、创建节点
//1、创建节点并赋值
String path = client.create().forPath("/zuxia","helloworld".getBytes());
System.out.println("创建节点:"+path);
//2、创建节点带子节点(如果不给子节点赋值,子节点的值默认为当前系统的IP地址)
String path = client.create().creatingParentsIfNeeded().forPath("/zuxia/abc");
System.out.println("创建节点:"+path);
//3、创建临时节点(当断开连接时临时节点会自动删除,withMode中的属性可选择)
String path =client.create().withMode(CreateMode.EPHEMERAL).forPath("/a","helloworld".getBytes());
System.out.println("创建节点:"+path);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
4)、查询节点
//1、查询节点的数据
byte[] bytes = client.getData().forPath("/zuxia");
System.out.println(new String(bytes));
//2、查询节点的数据(详情信息)
Stat stats=new Stat();
System.out.println(stats);//为了区分两个结果的不同
byte[] be = client.getData().storingStatIn(stats).forPath("/zuxia");
System.out.println(stats);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
5)、更新节点
//给节点赋值(返回值为Stat,可写可不写)
client.setData().forPath("/ab", "hello".getBytes());
- 1
- 2
6)、删除节点
//1、删除节点
System.out.println("删除节点:"+client.delete().forPath("/wjh"));
//2、删除带有子节点的目录节点
System.out.println("删除子节点:"+client.delete().deletingChildrenIfNeeded().forPath("/zuxia"));
- 1
- 2
- 3
- 4
- 5
7)、Watch事件监听
•ZooKeeper 允许用户在指定节点上注册一些Watcher,并且在一些特定事件触发的时候,ZooKeeper 服务端会将事件通知到感兴趣的客户端上去,该机制是 ZooKeeper 实现分布式协调服务的重要特性。
•ZooKeeper 中引入了Watcher机制来实现了发布/订阅功能能,能够让多个订阅者同时监听某一个对象,当一个对象自身状态变化时,会通知所有订阅者。
•ZooKeeper提供了三种Watcher:
NodeCache : 只是监听某一个特定的节点
PathChildrenCache : 监控一个ZNode的子节点.
TreeCache : 可以监控整个树上的所有节点,类似于PathChildrenCache和NodeCache的组合
1、NodeCache 监听事件
@Test void testNodeCache() throws Exception { // 1. 创建NodeCache NodeCache nodeCache = new NodeCache(client, "/ab"); // 2. 注册监听 nodeCache.getListenable().addListener(new NodeCacheListener() { @Override public void nodeChanged() throws Exception { System.out.println("/ab节点发生变更"); byte[] dataBytes = nodeCache.getCurrentData().getData(); System.out.println("节点修改后的数据:" + new String(dataBytes)); } }); // 3. 开启监听,如果设置为true,则开启监听时,加载缓冲数据 nodeCache.start(true); while(true){} }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
2、PathChildrenCache 监听事件
@Test void testPathChildrenCache() throws Exception { //创建监听对象(监听指定节点下的) PathChildrenCache pathChildrenCache= new PathChildrenCache(client, "/zuxia", true); //注册监听事件 pathChildrenCache.getListenable().addListener(new PathChildrenCacheListener() { @Override public void childEvent(CuratorFramework cf, PathChildrenCacheEvent event) throws Exception { System.out.println("节点发生变化了"); PathChildrenCacheEvent.Type type = event.getType(); //当前判断的是当节点发生更新时进入改方法,可以选择添加或者删除的方法 if (type.equals(PathChildrenCacheEvent.Type.CHILD_UPDATED)){ byte[] bytes = event.getData().getData(); System.out.println("节点修改后的数据"+new String(bytes)); } } }); //开启监听 pathChildrenCache.start(); while (true){} }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
3、TreeCache 监听事件
@Test void testTreeCache() throws Exception { //创建监听对象 TreeCache treeCache = new TreeCache(client, "/zuxia"); //注册监听 treeCache.getListenable().addListener(new TreeCacheListener() { @Override public void childEvent(CuratorFramework curatorFramework, TreeCacheEvent treeCacheEvent) throws Exception { System.out.println("节点发生变化了"); TreeCacheEvent.Type type = treeCacheEvent.getType(); if (type.equals(TreeCacheEvent.Type.NODE_ADDED)){ System.out.println("节点添加了"); } } }); //开启监听 treeCache.start(); while (true){} }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
8)、分布式锁实现
- 首先我们要了解什么是分布式锁?
在我们进行单机应用开发,涉及并发同步的时候,我们往往采用synchronized或者Lock的方式来解决多线程间的代码同步问题,这时多线程的运行都是在同一个JVM之下,没有任何问题。
但当我们的应用是分布式集群工作的情况下,属于多JVM下的工作环境,跨JVM之间已经无法通过多线程的锁解决同步问题。
那么就需要一种更加高级的锁机制,来处理种跨机器的进程之间的数据同步问题——这就是分布式锁。
- 其次也要悉知分布式锁的原理:
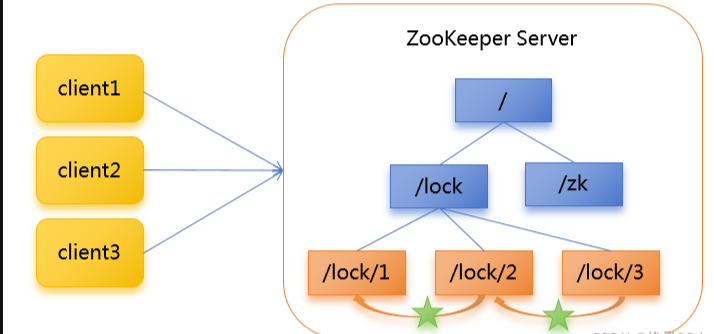
核心思想:当客户端要获取锁,则创建节点,使用完锁,则删除该节点。
1.客户端获取锁时,在lock节点下创建临时顺序节点。
2.然后获取lock下面的所有子节点,客户端获取到所有的子节点之后,如果发现自己创建的子节点序号最小,那么就认为该客户端获取到了锁。使用完锁后,将该节点删除。
3.如果发现自己创建的节点并非lock所有子节点中最小的,说明自己还没有获取到锁,此时客户端需要找到比自己小的那个节点,同时对其注册事件监听器,监听删除事件。
4.如果发现比自己小的那个节点被删除,则客户端的
Watcher会收到相应通知,此时再次判断自己创建的节点
是否是lock子节点中序号最小的,如果是则获取到了锁,
如果不是则重复以上步骤继续获取到比自己小的一个节点
并注册监听。
- 案例操作----模拟12306售票:
•在Curator中有五种锁方案:
•InterProcessSemaphoreMutex:分布式排它锁(非可重入锁)
•InterProcessMutex:分布式可重入排它锁
•InterProcessReadWriteLock:分布式读写锁
•InterProcessMultiLock:将多个锁作为单个实体管理的容器
•InterProcessSemaphoreV2:共享信号量
方法类:
package com.wjh; import org.apache.curator.RetryPolicy; import org.apache.curator.framework.CuratorFramework; import org.apache.curator.framework.CuratorFrameworkFactory; import org.apache.curator.framework.recipes.locks.InterProcessMutex; import org.apache.curator.retry.ExponentialBackoffRetry; import java.util.concurrent.TimeUnit; public class TickTest implements Runnable{ private int x=10;//票数 //创建分布式可重入排它锁对象 private InterProcessMutex lock; CuratorFramework client; //当前方法的构造方法 public TickTest() { //超时重试(连接间隔时间和超时连接次数) RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000, 5); //连接zookeeper对象 client = CuratorFrameworkFactory.newClient( "ip:port", 1000, 60*1000, retryPolicy); //开始连接 client.start(); //创建分布式可重入排它锁对象连接zookeeper注册中心客户端 //客户端中不用创建,这里会自动创建 lock = new InterProcessMutex(client, "/lock"); } @Override public void run() { try { //设置锁 lock.acquire(3, TimeUnit.SECONDS); while (true) { if(x>0){ //输出的调用线程的对象以及票数的数量 System.out.println(Thread.currentThread()+"票数:" + x); //间隔200毫秒输出一次 Thread.sleep(200); x--; } } } catch (Exception e) { throw new RuntimeException(e); }finally { try { //释放锁 lock.release(); } catch (Exception e) { throw new RuntimeException(e); } } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
测试类:
package com.wjh; public class MaiTest { //使用main方法调用 public static void main(String[] args) { //实现线程方法 TickTest tick = new TickTest(); //创建线程对象 Thread t1 = new Thread(tick,"携程"); Thread t2 = new Thread(tick,"飞猪"); //启动线程 t1.start(); t2.start(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16

