- 1MySQL数据库系列(六):MySQL之索引数据结构分析_索引文件数据分析
- 2termux+cpolar+codeserver 自启动 打造远程开发环境_cpolar code server
- 3虹科Pico汽车示波器 | 免拆诊断案例 | 2006 款林肯领航员车发动机怠速抖动
- 4oracle的基本使用(建表,操作表等)_oracle建表
- 5发那科机器人上位机,C#,语音识别控制,FANUC_c#发那科机器人
- 6RabbitMQ和RocketMQ区别 | RabbitMQ和RocketMQ优缺点解析 | 消息队列中间件对比:RabbitMQ vs RocketMQ - 选择哪个适合您的业务需求?_rabbitmq rocketmq
- 7CrossOver 24.0.0 for mac 震撼发布 2024最新下载安装详细图文教程_codeweavers crossover 24下载
- 8【GitHub项目推荐--推荐,一个虚拟服装试穿开源AI项目】【转载】_ootdiffusion模型下载
- 9医院手术室麻醉信息管理系统源码 自动生成麻醉的各种医疗文书(手术风险评估表、手术安全核查表)
- 10idea中git基本操作命令_idea拉去指定分支
大数据开源框架之基于Spark的气象数据处理与分析_spark编程计算各城市的平均气温实训
赞
踩
Spark配置请看:
目录
实验说明:
本次实验所采用的数据,从中央气象台官方网站(网址:http://www.nmc.cn/)爬取,主要是最近24小时各个城市的天气数据,包括时间整点、整点气温、整点降水量、风力、整点气压、相对湿度等。正常情况每个城市对应24条数据(每个整点一条)。数据规模达到2412个城市,57888条数据,有部分城市部分时间点数据存在缺失或异常。特别说明:实验所用数据均为网上爬取,没有得到中央气象台官方授权使用,使用范围仅限本次实验使用,请勿用于商业用途。
实验要求:
1.数据获取,最后保存的各个城市最近24小时整点天气数据(passed_weather_ALL.csv)每条数据各字段含义如下所示,这里仅列出实验中使用部分:
| 字段 含义 | 字段 含义 |
| province 城市所在省份(中文) | province 城市所在省份(中文) |
| city_index 城市序号(计数) | city_index 城市序号(计数) |
| city_name 城市名称(中文) | city_name 城市名称(中文) |
| city_code 城市编号 | city_code 城市编号 |
| time 时间点(整点) | time 时间点(整点) |
| temperature 气温 | temperature 气温 |
| rain1h 过去1小时降雨量; | rain1h 过去1小时降雨量; |
2. 数据分析,主要使用Spark SQL相关知识与技术,对各个城市过去24小时累积降雨量和当日平均气温进行计算和排序;
3. 数据可视化,数据可视化使用python matplotlib库,版本号1.5.1。可使用pip命令安装。绘制过程大体如下:
第一步,应当设置字体,这里提供了黑体的字体文件simhei.tff。否则坐标轴等出现中文的地方是乱码。
第二步,设置数据(累积雨量或者日平均气温)和横轴坐标(城市名称),配置直方图。
第三步,配置横轴坐标位置,设置纵轴坐标范围
第四步,配置横纵坐标标签
第五步,配置每个条形图上方显示的数据
第六步,根据上述配置,画出直方图。。
根据上述实验任务,设计相应内容与具体执行步骤,并对相应关键步骤的执行结果给出截图。
实验步骤:
数据获取:
思路:
首先利用urllib.request获取url的数据,然后利用json.loads变为json格式

再编写函数写入表头和数据:

利用上述函数组合,编写两个get函数获取城市和省份,导出CSV文件:
最后获取天气数据,导出passed_weather_ALL.csv
每个字段获取方式是:
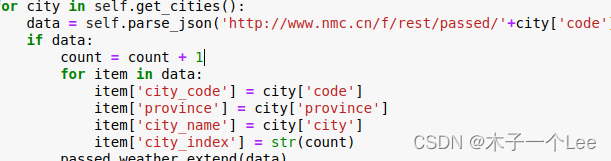
city_code就是city.csv的code,province就是city.csv里边的province,city_name就是city.csv里边的city,city_index就是第几个城市(设置count变量计数,每个城市加1),
其他直接通过爬取表头获得:
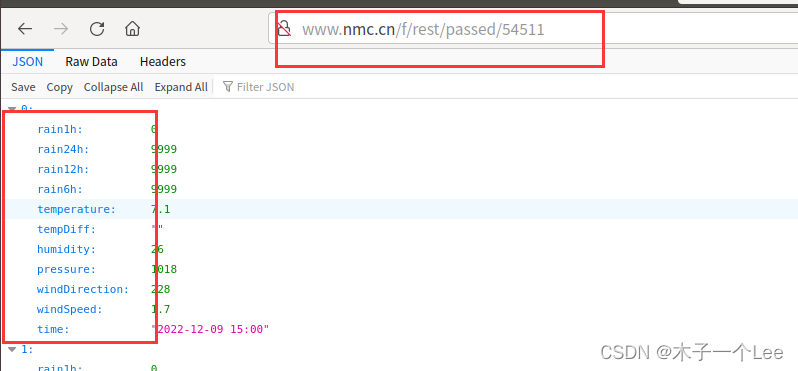
在主函数里运行:
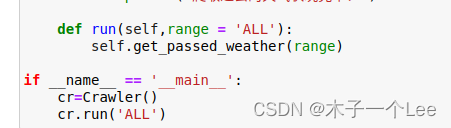
部分代码:
- def get_passed_weather(self,province):
- weather_passed_file = 'input/passed_weather_' + province + '.csv'
- if os.path.exists(weather_passed_file):
- return
- passed_weather = list()
- count = 0
- if province == 'ALL':
- print ("开始爬取过去的天气状况")
- for city in self.get_cities():
- data = self.parse_json('http://www.nmc.cn/f/rest/passed/'+city['code'])
- if data:
- count = count + 1
- for item in data:
- item['city_code'] = city['code']
- item['province'] = city['province']
- item['city_name'] = city['city']
- item['city_index'] = str(count)
- passed_weather.extend(data)
- if count % 50 == 0:
- if count == 50:
- self.write_header(weather_passed_file,passed_weather)
- else:
- self.write_row(weather_passed_file,passed_weather)
- passed_weather = list()
- if passed_weather:
- if count <= 50:
- self.write_header(weather_passed_file,passed_weather)
- else:
- self.write_row(weather_passed_file,passed_weather)
- print ("爬取过去的天气状况完毕!")
- else:
- print ("开始爬取过去的天气状况")
- select_city = filter(lambda x:x['province']==province,self.get_cities())
- for city in select_city:
- data = self.parse_json('http://www.nmc.cn/f/rest/passed/'+city['code'])
- if data:
- count = count + 1
- for item in data:
- item['city_index'] = str(count)
- item['city_code'] = city['code']
- item['province'] = city['province']
- item['city_name'] = city['city']
- passed_weather.extend(data)
- self.write_csv(weather_passed_file,passed_weather)
- print ("爬取过去的天气状况完毕!")
-
- def run(self,range = 'ALL'):
- self.get_passed_weather(range)
数据分析:
思路:
首先创建spark对象,然后使用select函数选择所需列的数据进行筛选,分组(累计降雨量按照省份、城市和城市代码分组,气温还得考虑时间date)求和、sort函数排序,

分析气温还需要进行筛选4个时刻,然后再进行分组求和排序

最后生成相应的csv或json文件,返回所需要的前20个或前10个数据。


部分代码:
- def passed_rain_analyse(filename): #计算各个城市过去24小时累积雨量
- print ("开始分析累积降雨量")
- #spark = SparkSession.builder.master("spark://master:7077").appName("passed_rain_analyse").getOrCreate()
- #spark = SparkSession.builder.master("local[4]").appName("passed_rain_analyse").getOrCreate()
- spark = SparkSession.builder.master("local").appName("passed_rain_analyse").getOrCreate()
-
- df = spark.read.csv(filename,header = True)
-
- df_rain = df.select(df['province'],df['city_name'],df['city_code'],df['rain1h'].cast(DecimalType(scale=1))) .filter(df['rain1h'] < 1000) #筛选数据,去除无效数据
- df_rain_sum = df_rain.groupBy("province","city_name","city_code") .agg(F.sum("rain1h").alias("rain24h")) .sort(F.desc("rain24h")) # 分组、求和、排序
- df_rain_sum.cache()
- df_rain_sum.coalesce(1).write.csv("file:///home/lee/lab5/passed_rain_analyse.csv")
- #spark.catalog.refreshTable(filename)
- print ("累积降雨量分析完毕!")
- return df_rain_sum.head(20)#前20个
-
- def passed_temperature_analyse(filename):
- print ("开始分析气温")
- #spark = SparkSession.builder.master("spark://master:7077").appName("passed_temperature_analyse").getOrCreate()
- spark = SparkSession.builder.master("local").appName("passed_temperature_analyse").getOrCreate()
- #spark = SparkSession.builder.master("local[4]").appName("passed_rain_analyse").getOrCreate()
- df = spark.read.csv(filename,header = True)
- df_temperature = df.select( #选择需要的列
- df['province'],
- df['city_name'],
- df['city_code'],
- df['temperature'].cast(DecimalType(scale=1)),
- F.date_format(df['time'],"yyyy-MM-dd").alias("date"), #得到日期数据
- F.hour(df['time']).alias("hour") #得到小时数据
- )
- # 筛选四点时次
- #df_4point_temperature = df_temperature.filter(df_temperature['hour'].isin([2,4,6,8]))
- df_4point_temperature = df_temperature.filter(df_temperature['hour'].isin([2,8,14,20]))
- #df_4point_temperature = df_temperature.filter(df_temperature['hour'].isin([1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24]))
- df_avg_temperature = df_4point_temperature.groupBy("province","city_name","city_code","date") .agg(F.count("temperature"),F.avg("temperature").alias("avg_temperature")) .filter("count(temperature) = 4") .sort(F.asc("avg_temperature")) .select("province","city_name","city_code","date",F.format_number('avg_temperature',1).alias("avg_temperature"))
- df_avg_temperature.cache()
- avg_temperature_list = df_avg_temperature.collect()
- df_avg_temperature.coalesce(1).write.json("file:///home/lee/lab5/passed_temperature.json")
- print ("气温分析完毕")
- return avg_temperature_list[0:10]#最低的10个
可视化:
思路:
使用python matplotlib库进行绘图,
第一步,应当设置字体,这里提供了黑体的字体文件simhei.tff。否则坐标轴等出现中文的地方是乱码。
![]()
第二步,设置数据(累积雨量或者日平均气温)和横轴坐标(城市名称),配置直方图。
![]()
![]()
第三步,配置横轴坐标位置,设置纵轴坐标范围
![]()
![]()
第四步,配置横纵坐标标签
![]()
![]()
第五步,配置每个条形图上方显示的数据


第六步,根据上述配置,画出直方图。(见下方,按住CTRL点我去)
其他个性化代码:
直方图颜色
![]()
color=’ckrmgby’,一个七种颜色,分别对应青、黑、红、洋红、绿、蓝、黄
字体大小、颜色:
大小使用fontsize属性,颜色仍然是color属性
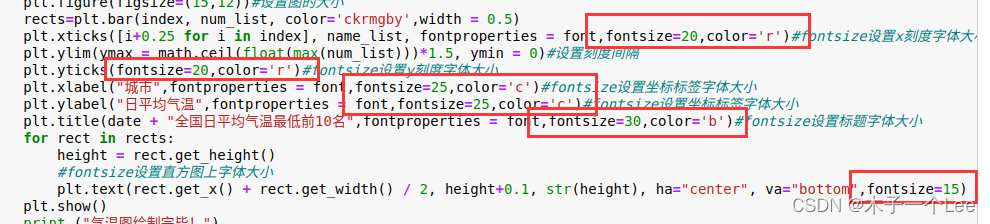
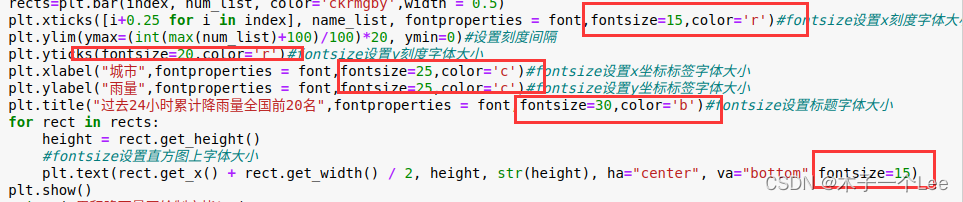
设置图的大小:使用figsize属性
![]()
部分代码:
- def draw_rain(rain_list):
- print ("开始绘制累积降雨量图")
- font = FontProperties(fname='ttf/simhei.ttf') # 设置字体
- name_list = []
- num_list = []
- for item in rain_list:
- name_list.append(item.province[0:2] + '\n' + item.city_name)
- num_list.append(item.rain24h)
- index = [i+0.25 for i in range(0,len(num_list))]
- plt.figure(figsize=(15,12))#设置图的大小
- rects=plt.bar(index, num_list, color='ckrmgby',width = 0.5)
- plt.xticks([i+0.25 for i in index], name_list, fontproperties = font,fontsize=15,color='r')#fontsize设置x刻度字体大小
- plt.ylim(ymax=(int(max(num_list)+100)/100)*20, ymin=0)#设置刻度间隔
- plt.yticks(fontsize=20,color='r')#fontsize设置y刻度字体大小
- plt.xlabel("城市",fontproperties = font,fontsize=25,color='c')#fontsize设置x坐标标签字体大小
- plt.ylabel("雨量",fontproperties = font,fontsize=25,color='c')#fontsize设置y坐标标签字体大小
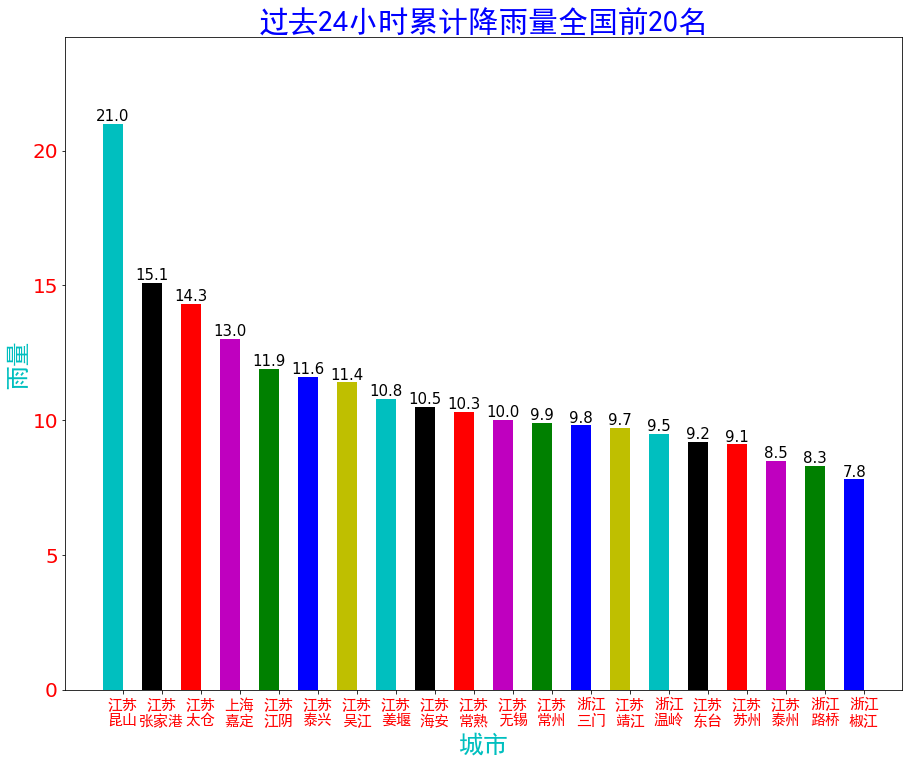
- plt.title("过去24小时累计降雨量全国前20名",fontproperties = font,fontsize=30,color='b')#fontsize设置标题字体大小
- for rect in rects:
- height = rect.get_height()
- #fontsize设置直方图上字体大小
- plt.text(rect.get_x() + rect.get_width() / 2, height, str(height), ha="center", va="bottom",fontsize=15)
- plt.show()
- print ("累积降雨量图绘制完毕!")
-
- def draw_temperature(temperature_list):
- print ("开始绘制气温图")
- font = FontProperties(fname='/home/lee/lab5/ttf/simhei.ttf')
- name_list = []
- num_list = []
- #print(temperature_list[1])
- date = temperature_list[1].date
- for item in temperature_list:
- name_list.append(item.province[0:2] + '\n' + item.city_name)
- num_list.append(float(item.avg_temperature))
- index = [i+0.25 for i in range(0,len(num_list))]
- plt.figure(figsize=(15,12))#设置图的大小
- rects=plt.bar(index, num_list, color='ckrmgby',width = 0.5)
- plt.xticks([i+0.25 for i in index], name_list, fontproperties = font,fontsize=20,color='r')#fontsize设置x刻度字体大小
- plt.ylim(ymax = math.ceil(float(max(num_list)))*1.5, ymin = 0)#设置刻度间隔
- plt.yticks(fontsize=20,color='r')#fontsize设置y刻度字体大小
- plt.xlabel("城市",fontproperties = font,fontsize=25,color='c')#fontsize设置坐标标签字体大小
- plt.ylabel("日平均气温",fontproperties = font,fontsize=25,color='c')#fontsize设置坐标标签字体大小
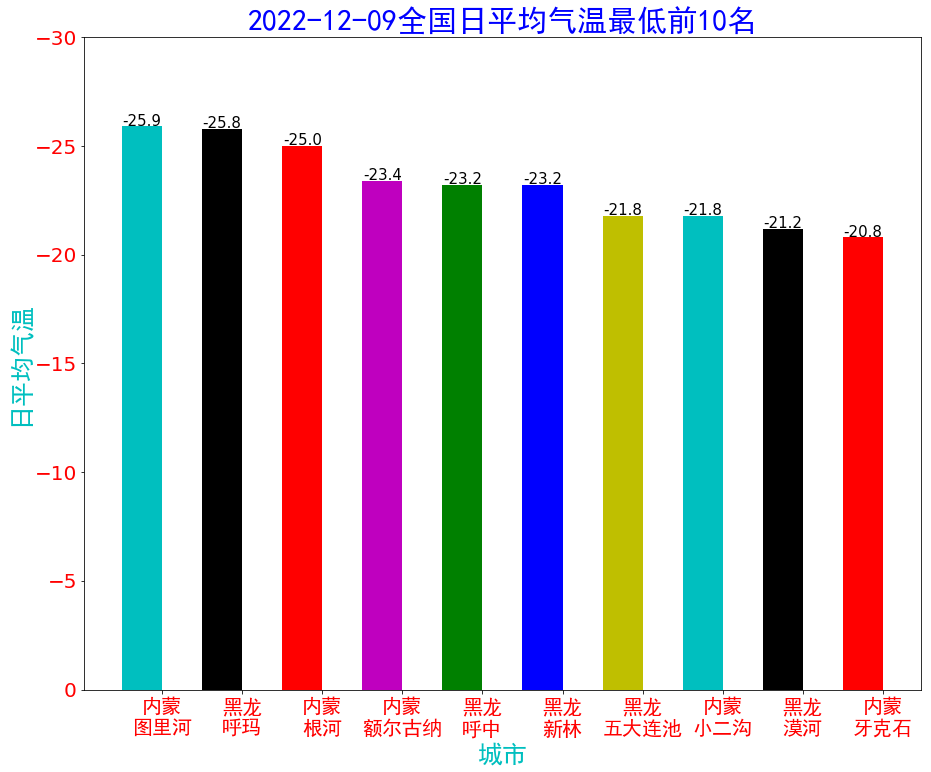
- plt.title(date + "全国日平均气温最低前10名",fontproperties = font,fontsize=30,color='b')#fontsize设置标题字体大小
- for rect in rects:
- height = rect.get_height()
- #fontsize设置直方图上字体大小
- plt.text(rect.get_x() + rect.get_width() / 2, height+0.1, str(height), ha="center", va="bottom",fontsize=15)
- plt.show()
- print ("气温图绘制完毕!")
参考代码(适用于python3):
完整代码
- #Crawler类(数据获取):
- #!/usr/bin/env python
- # coding: utf-8
-
- # In[7]:
-
-
- import urllib.request,urllib.error
- import json
- import csv
- import chardet
- import codecs
- import os
- import time
-
- import importlib,sys
- importlib.reload(sys)
-
- class Crawler:
- def get_html(self,url):
- request = urllib.request.Request(url)
- response = urllib.request.urlopen(request)
- return response.read().decode()
- def parse_json(self,url):
- obj = self.get_html(url)
- if obj:
- json_obj = json.loads(obj)
- else:
- json_obj = list()
- return json_obj
-
- def write_csv(self,file,data):
- if data:
- print ("开始写入 " + file)
- with open(file,'a+',encoding='utf-8-sig') as f:#utf-8-sig 带BOM的utf-8
- f_csv = csv.DictWriter(f,data[0].keys())
- #if not os.path.exists(file):
- f_csv.writeheader()
- f_csv.writerows(data)
- print ("结束写入 " + file)
-
- def write_header(self,file,data):
- if data:
- print ("开始写入 " + file)
- with open(file,'a+',encoding='utf-8-sig') as f:
- f_csv = csv.DictWriter(f,data[0].keys())
- f_csv.writeheader()
- f_csv.writerows(data)
- print ("结束写入 " + file)
-
- def write_row(self,file,data):
- if data:
- print ("开始写入 " + file)
- with open(file,'a+',encoding='utf-8-sig') as f:
- f_csv = csv.DictWriter(f,data[0].keys())
- if not os.path.exists(file):
- f_csv.writeheader()
- f_csv.writerows(data)
- print ("结束写入 " + file)
-
- def read_csv(self,file):
- print ("开始读取 " + file)
- with open(file,'r+',encoding='utf-8-sig') as f:
- data = csv.DictReader(f)
- print ("结束读取 " + file)
- return list(data)
-
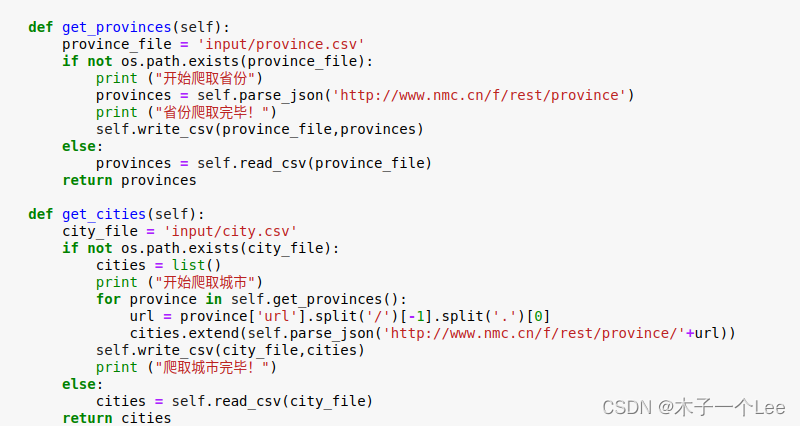
- def get_provinces(self):
- province_file = 'input/province.csv'
- if not os.path.exists(province_file):
- print ("开始爬取省份")
- provinces = self.parse_json('http://www.nmc.cn/f/rest/province')
- print ("省份爬取完毕!")
- self.write_csv(province_file,provinces)
- else:
- provinces = self.read_csv(province_file)
- return provinces
-
- def get_cities(self):
- city_file = 'input/city.csv'
- if not os.path.exists(city_file):
- cities = list()
- print ("开始爬取城市")
- for province in self.get_provinces():
- url = province['url'].split('/')[-1].split('.')[0]
- cities.extend(self.parse_json('http://www.nmc.cn/f/rest/province/'+url))
- self.write_csv(city_file,cities)
- print ("爬取城市完毕!")
- else:
- cities = self.read_csv(city_file)
- return cities
-
- def get_passed_weather(self,province):
- weather_passed_file = 'input/passed_weather_' + province + '.csv'
- if os.path.exists(weather_passed_file):
- return
- passed_weather = list()
- count = 0
- if province == 'ALL':
- print ("开始爬取过去的天气状况")
- for city in self.get_cities():
- data = self.parse_json('http://www.nmc.cn/f/rest/passed/'+city['code'])
- if data:
- count = count + 1
- for item in data:
- item['city_code'] = city['code']
- item['province'] = city['province']
- item['city_name'] = city['city']
- item['city_index'] = str(count)
- passed_weather.extend(data)
- if count % 50 == 0:
- if count == 50:
- self.write_header(weather_passed_file,passed_weather)
- else:
- self.write_row(weather_passed_file,passed_weather)
- passed_weather = list()
- if passed_weather:
- if count <= 50:
- self.write_header(weather_passed_file,passed_weather)
- else:
- self.write_row(weather_passed_file,passed_weather)
- print ("爬取过去的天气状况完毕!")
- else:
- print ("开始爬取过去的天气状况")
- select_city = filter(lambda x:x['province']==province,self.get_cities())
- for city in select_city:
- data = self.parse_json('http://www.nmc.cn/f/rest/passed/'+city['code'])
- if data:
- count = count + 1
- for item in data:
- item['city_index'] = str(count)
- item['city_code'] = city['code']
- item['province'] = city['province']
- item['city_name'] = city['city']
- passed_weather.extend(data)
- self.write_csv(weather_passed_file,passed_weather)
- print ("爬取过去的天气状况完毕!")
-
- def run(self,range = 'ALL'):
- self.get_passed_weather(range)
-
- if __name__ == '__main__':
- cr=Crawler()
- cr.run('ALL')
- #SparkSql类(分析+可视化,引入Crawler类之后也可以爬取,前提是passed_weather_ALL.csv不存在;每次运行前需要删除passed_temperature.json和passed_rain_analyse.csv这两个文件夹)
-
- import findspark
- findspark.init()
- from pyspark.sql import SparkSession
- from pyspark.sql import functions as F
- from pyspark.sql.types import DecimalType,TimestampType
- import matplotlib as mpl
- import matplotlib.pyplot as plt
- from matplotlib.font_manager import FontProperties
- import os
- import math
- from Crawler import *
- import importlib,sys
- importlib.reload(sys)
-
- def passed_rain_analyse(filename): #计算各个城市过去24小时累积雨量
- print ("开始分析累积降雨量")
- #spark = SparkSession.builder.master("spark://master:7077").appName("passed_rain_analyse").getOrCreate()
- #spark = SparkSession.builder.master("local[4]").appName("passed_rain_analyse").getOrCreate()
- spark = SparkSession.builder.master("local").appName("passed_rain_analyse").getOrCreate()
-
- df = spark.read.csv(filename,header = True)
-
- df_rain = df.select(df['province'],df['city_name'],df['city_code'],df['rain1h'].cast(DecimalType(scale=1))) .filter(df['rain1h'] < 1000) #筛选数据,去除无效数据
- df_rain_sum = df_rain.groupBy("province","city_name","city_code") .agg(F.sum("rain1h").alias("rain24h")) .sort(F.desc("rain24h")) # 分组、求和、排序
- df_rain_sum.cache()
- df_rain_sum.coalesce(1).write.csv("file:///home/lee/lab5/passed_rain_analyse.csv")
- #spark.catalog.refreshTable(filename)
- print ("累积降雨量分析完毕!")
- return df_rain_sum.head(20)#前20个
-
- def passed_temperature_analyse(filename):
- print ("开始分析气温")
- #spark = SparkSession.builder.master("spark://master:7077").appName("passed_temperature_analyse").getOrCreate()
- spark = SparkSession.builder.master("local").appName("passed_temperature_analyse").getOrCreate()
- #spark = SparkSession.builder.master("local[4]").appName("passed_rain_analyse").getOrCreate()
- df = spark.read.csv(filename,header = True)
- df_temperature = df.select( #选择需要的列
- df['province'],
- df['city_name'],
- df['city_code'],
- df['temperature'].cast(DecimalType(scale=1)),
- F.date_format(df['time'],"yyyy-MM-dd").alias("date"), #得到日期数据
- F.hour(df['time']).alias("hour") #得到小时数据
- )
- # 筛选四点时次
- #df_4point_temperature = df_temperature.filter(df_temperature['hour'].isin([2,4,6,8]))
- df_4point_temperature = df_temperature.filter(df_temperature['hour'].isin([2,8,14,20]))
- #df_4point_temperature = df_temperature.filter(df_temperature['hour'].isin([1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24]))
- df_avg_temperature = df_4point_temperature.groupBy("province","city_name","city_code","date") .agg(F.count("temperature"),F.avg("temperature").alias("avg_temperature")) .filter("count(temperature) = 4") .sort(F.asc("avg_temperature")) .select("province","city_name","city_code","date",F.format_number('avg_temperature',1).alias("avg_temperature"))
- df_avg_temperature.cache()
- avg_temperature_list = df_avg_temperature.collect()
- df_avg_temperature.coalesce(1).write.json("file:///home/lee/lab5/passed_temperature.json")
- print ("气温分析完毕")
- return avg_temperature_list[0:10]#最低的10个
-
-
- def draw_rain(rain_list):
- print ("开始绘制累积降雨量图")
- font = FontProperties(fname='ttf/simhei.ttf') # 设置字体
- name_list = []
- num_list = []
- for item in rain_list:
- name_list.append(item.province[0:2] + '\n' + item.city_name)
- num_list.append(item.rain24h)
- index = [i+0.25 for i in range(0,len(num_list))]
- plt.figure(figsize=(15,12))#设置图的大小
- rects=plt.bar(index, num_list, color='ckrmgby',width = 0.5)
- plt.xticks([i+0.25 for i in index], name_list, fontproperties = font,fontsize=15,color='r')#fontsize设置x刻度字体大小
- plt.ylim(ymax=(int(max(num_list)+100)/100)*20, ymin=0)#设置刻度间隔
- plt.yticks(fontsize=20,color='r')#fontsize设置y刻度字体大小
- plt.xlabel("城市",fontproperties = font,fontsize=25,color='c')#fontsize设置x坐标标签字体大小
- plt.ylabel("雨量",fontproperties = font,fontsize=25,color='c')#fontsize设置y坐标标签字体大小
- plt.title("过去24小时累计降雨量全国前20名",fontproperties = font,fontsize=30,color='b')#fontsize设置标题字体大小
- for rect in rects:
- height = rect.get_height()
- #fontsize设置直方图上字体大小
- plt.text(rect.get_x() + rect.get_width() / 2, height, str(height), ha="center", va="bottom",fontsize=15)
- plt.show()
- print ("累积降雨量图绘制完毕!")
-
- def draw_temperature(temperature_list):
- print ("开始绘制气温图")
- font = FontProperties(fname='/home/lee/lab5/ttf/simhei.ttf')
- name_list = []
- num_list = []
- #print(temperature_list[1])
- date = temperature_list[1].date
- for item in temperature_list:
- name_list.append(item.province[0:2] + '\n' + item.city_name)
- num_list.append(float(item.avg_temperature))
- index = [i+0.25 for i in range(0,len(num_list))]
- plt.figure(figsize=(15,12))#设置图的大小
- rects=plt.bar(index, num_list, color='ckrmgby',width = 0.5)
- plt.xticks([i+0.25 for i in index], name_list, fontproperties = font,fontsize=20,color='r')#fontsize设置x刻度字体大小
- plt.ylim(ymax = math.ceil(float(max(num_list)))*1.5, ymin = 0)#设置刻度间隔
- plt.yticks(fontsize=20,color='r')#fontsize设置y刻度字体大小
- plt.xlabel("城市",fontproperties = font,fontsize=25,color='c')#fontsize设置坐标标签字体大小
- plt.ylabel("日平均气温",fontproperties = font,fontsize=25,color='c')#fontsize设置坐标标签字体大小
- plt.title(date + "全国日平均气温最低前10名",fontproperties = font,fontsize=30,color='b')#fontsize设置标题字体大小
- for rect in rects:
- height = rect.get_height()
- #fontsize设置直方图上字体大小
- plt.text(rect.get_x() + rect.get_width() / 2, height+0.1, str(height), ha="center", va="bottom",fontsize=15)
- plt.show()
- print ("气温图绘制完毕!")
-
- def main():
- sourcefile = "input/passed_weather_ALL.csv"
- if not os.path.exists(sourcefile):
- crawler = Crawler()
- crawler.run('ALL')
- rain_list = passed_rain_analyse('file:///home/lee/lab5/' + sourcefile)
- draw_rain(rain_list)
- temperature_list = passed_temperature_analyse('file:///home/lee/lab5/' + sourcefile)
- draw_temperature(temperature_list)
-
- if __name__ == '__main__':
- main()
运行结果:
数据获取:

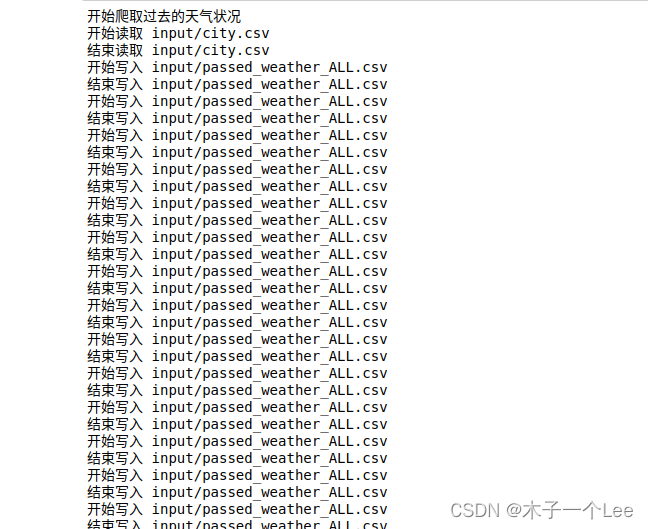
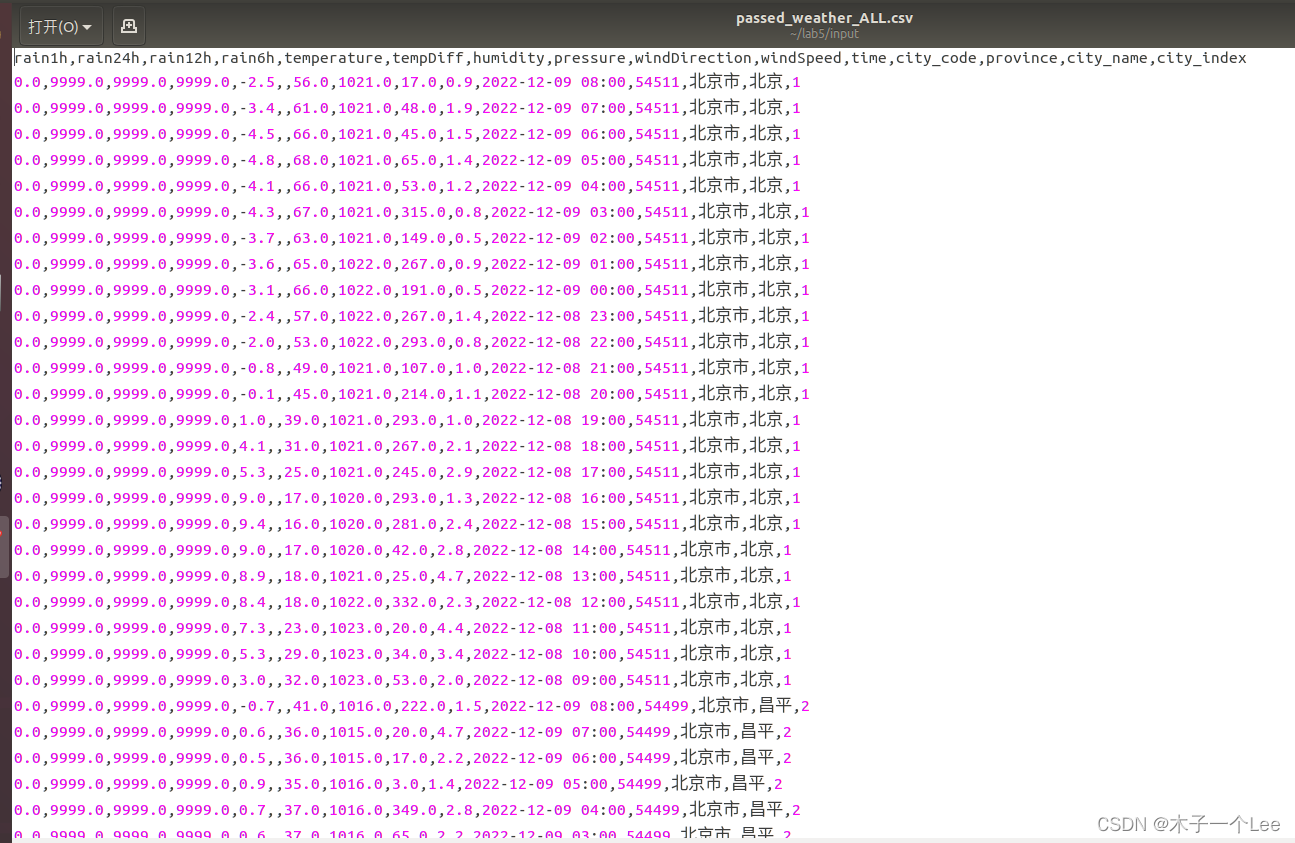
数据分析:


数据可视化:大图在下边
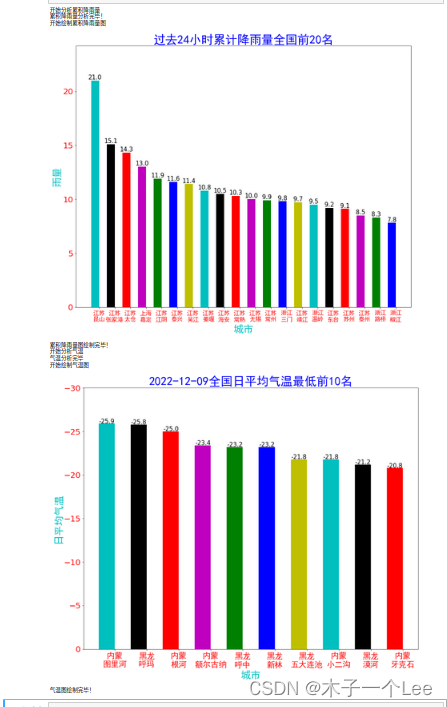
大图在下边:
分别对应rain.png和temperature.png