
- 1ModuleNotFoundError: No module named‘ pymysql ‘异常的正确解决方法
- 2一个Boss直聘机器人, 自动回复发简历
- 3毕业设计:基于深度学习的图像分类识别系统 人工智能_深度学习图像识别毕设总体概述
- 4数字逻辑电路复习资料_数字逻辑电路空翻和反转的区别
- 5uniapptabbar的高度是多少_Uniapp-tabbar选择及适配
- 6揭秘爬虫个股投资机会,轻松赚钱!_爬虫炒股有用吗
- 7【无人机编队】基于matlab二阶一致性多无人机协同编队控制(考虑通信半径和碰撞半径)【含Matlab源码 4215期】_多无人机协同任务规划matlab
- 8Dubbo源码(4)-Zookeeper注册中心源码解析_o.a.d.r.zookeeper.zookeeperregistry.unsubscribe -
- 9Adobe Lightroom Classic v13.1 (macOS, Windows) - 桌面照片编辑器_lightroom 13.1
- 10Seagull License Server 9.4 SR3 2781 完美激活(解决不能打印问题)
深入探究音视频开源库WebRTC中NetEQ音频抗网络延时与抗丢包的实现机制_开源音频处理web
赞
踩
目录
C++软件异常排查从入门到精通系列教程(专栏文章列表,欢迎订阅,持续更新...)![]() https://blog.csdn.net/chenlycly/article/details/125529931C/C++基础与进阶(专栏文章,持续更新中...)
https://blog.csdn.net/chenlycly/article/details/125529931C/C++基础与进阶(专栏文章,持续更新中...)![]() https://blog.csdn.net/chenlycly/category_11931267.htmlVC++常用功能开发汇总(专栏文章列表,欢迎订阅,持续更新...)
https://blog.csdn.net/chenlycly/category_11931267.htmlVC++常用功能开发汇总(专栏文章列表,欢迎订阅,持续更新...)![]() https://blog.csdn.net/chenlycly/article/details/124272585C++软件分析工具从入门到精通案例集锦(专栏文章,持续更新中...)
https://blog.csdn.net/chenlycly/article/details/124272585C++软件分析工具从入门到精通案例集锦(专栏文章,持续更新中...)![]() https://blog.csdn.net/chenlycly/article/details/131405795开源组件及数据库技术(专栏文章,持续更新中...)
https://blog.csdn.net/chenlycly/article/details/131405795开源组件及数据库技术(专栏文章,持续更新中...)![]() https://blog.csdn.net/chenlycly/category_12458859.html网络编程与网络问题分享(专栏文章,持续更新中...)
https://blog.csdn.net/chenlycly/category_12458859.html网络编程与网络问题分享(专栏文章,持续更新中...)![]() https://blog.csdn.net/chenlycly/category_2276111.html 音视频软件随着应用场景和使用环境的变化,对音频的质量要求越来越高,要实现高质量的音频效果,可以借鉴音视频领域一些成熟的解决方案。WebRTC正是目前解决话音质量最先进的语音引擎之一,其中NetEQ网络均衡器模块很好地解决了音频数据在低带宽下出现的延迟、抖动与丢包问题。本文将详细分析WebRTC中NetEQ网络均衡器的实现原理、处理流程以及丢包补偿处理机制。
https://blog.csdn.net/chenlycly/category_2276111.html 音视频软件随着应用场景和使用环境的变化,对音频的质量要求越来越高,要实现高质量的音频效果,可以借鉴音视频领域一些成熟的解决方案。WebRTC正是目前解决话音质量最先进的语音引擎之一,其中NetEQ网络均衡器模块很好地解决了音频数据在低带宽下出现的延迟、抖动与丢包问题。本文将详细分析WebRTC中NetEQ网络均衡器的实现原理、处理流程以及丢包补偿处理机制。
1、引言
由于IP网络主要用于数据传输业务,与传统的电话占用独立的逻辑或物理线路不同,因此没有服务质量(Qos)保证,存在包乱序到达、延迟、丢包和抖动等问题。对于丢包,业务上可以采用重传或者多倍发送机制,但音视频软件都是实时业务,对带宽、时延和抖动有严格的要求,所以必须有一定的Qos保证。
音视频软件中影响音频质量主要有两个因素:时延抖动和丢包处理。一般通过抖动缓冲区来消除网络传输所带来的不良影响,抖动缓冲区技术直接影响丢包处理。接收缓冲区可以用来消除时延抖动,但如果发生丢包,会卡顿或者填静音或者插值补偿,但在时延大、抖动大、丢包严重的网络中,效果都不理想。

如何借用WebRTC中的NetEQ网络均衡器的技术来提高软件的音频质量,首先需要分析分解NetEQ的原理和处理流程,其次是了解丢包补偿算法的原理和使用场景,然后就是将之有效到应用到软件产品的设计中去。
2、WebRTC简介
在详细介绍WebRTC中的NetEQ网络均衡器之前,我们先来大概地了解以下WebRTC。
WebRTC(Web Real-Time Communication)是一个由Google发起的实时音视频通讯C++开源库,其提供了音视频采集、编码、网络传输,解码显示等一整套音视频解决方案,我们可以通过该开源库快速地构建出一个音视频通讯应用。
一个实时音视频应用软件一般都会包括这样几个环节:音视频采集、音视频编码(压缩)、前后处理(美颜、滤镜、回声消除、噪声抑制等)、网络传输、解码渲染(音视频播放)等。其中每一个细分环节,还有更细分的技术模块。
虽然其名为WebRTC,但是实际上它不光支持Web之间的音视频通讯,还支持Windows、Android以及iOS等移动平台。WebRTC底层是用C/C++开发的,具有良好的跨平台性能。
- WebRTC主要使用C++开发实现,代码中大量使用了C++11及以上的新特性,在阅读源码之前需要大概地了解C++的这些新特性。
- 学习C++11新特性很有必要,不仅在C++开源代码中会频繁地使用到新特性,在跳槽时的笔试面试时也会经常被问到。
- 推荐大家仔细研读一下新版的、免费公开的《Google 开源项目风格指南(zh-google-styleguide)》,它不仅仅是Googe的编码规范,它不仅告诉你编码时要怎么做,还告诉你为什么要这么做!对于学习C++11及以上的新特性也很有好处!这本项目风格指南,我们项目大组去年系统地研读过,收获很大,很有参考价值!
WebRTC因为其较好的音视频效果及良好的网络适应性,目前已被广泛的应用到视频会议、实时音视频直播等领域中。在视频会议领域,腾讯会议、华为WeLink、字节飞书、阿里钉钉、小鱼易连、厦门亿联等国产厂商均提供了基于WebRTC方案的视频会议。
大家熟知的音视频专业服务商声网(Agora),更是基于开源WebRTC库,提供了社交直播、教育、游戏电竞、IoT、AR/VR、金融、保险、医疗、企业协作等多个行业的音视频互动解决方案。使用声网服务的企业包括小米、陌陌、斗鱼、哔哩哔哩、新东方、小红书、HTC VIVE 、The Meet Group、Bunch、Yalla等遍布全球的巨头、独角兽及创业企业。除了头部公司声网之外,也陆续有多家公司基于开源的WebRTC,开发出了多个音视频应用,提供了多个领域的音视频通信解决方案。
3、什么是NetEQ?
NetEQ 本质上就是一个音频的 JitterBuffer(抖动缓冲器),全称是 Network Equalizer(网络均衡器)。
GIPS 语音引擎的两大核心技术之一就是包含丢包隐藏算法的高级自适应抖动缓冲器技术,称作 NetEQ。2010 年谷歌公司以6820万美元收购Global IP Solutions公司而获得的这项技术,另一个核心技术就是3A算法。随后,谷歌在2011年将其集成到 WebRTC 中对外开源发布。
NetEQ 集成了自适应抖动控制算法和语音丢包隐藏算法,并且与解码器进行集成,所以 NetEQ 能够在较高的丢包环境下始终能够保持较好的语音质量。
在这里,给大家重点推荐一下我的几个热门畅销专栏:
专栏1:(该精品技术专栏的订阅量已达到430多个,专栏中包含大量项目实战分析案例,有很强的实战参考价值,广受好评!专栏文章持续更新中,预计更新到200篇以上!)
C++软件异常排查从入门到精通系列教程(专栏文章列表,欢迎订阅,持续更新...)![]() https://blog.csdn.net/chenlycly/article/details/125529931
https://blog.csdn.net/chenlycly/article/details/125529931
本专栏根据多年C++软件异常排查的项目实践,系统地总结了引发C++软件异常的常见原因以及排查C++软件异常的常用思路与方法,详细讲述了C++软件的调试方法与手段,以图文并茂的方式给出具体的项目问题实战分析实例(很有实战参考价值),带领大家逐步掌握C++软件调试与异常排查的相关技术,适合基础进阶和想做技术提升的相关C++开发人员!
考察一个开发人员的水平,一是看其编码及设计能力,二是要看其软件调试能力!所以软件调试能力(排查软件异常的能力)很重要,必须重视起来!能解决一般人解决不了的问题,既能提升个人能力及价值,也能体现对团队及公司的贡献!
专栏中的文章都是通过项目实战总结出来的,包含大量项目问题实战分析案例,有很强的实战参考价值!专栏文章还在持续更新中,预计文章篇数能更新到200篇以上!
专栏2:
C/C++基础与进阶(专栏文章,持续更新中...)![]() https://blog.csdn.net/chenlycly/category_11931267.html
https://blog.csdn.net/chenlycly/category_11931267.html
以多年的开发实战经验为基础,总结并讲解一些的C/C++基础与进阶内容,以图文并茂的方式对C++相关知识点进行详细地展开与剖析!专栏涉及了C/C++开发领域多个方面的内容,同时给出C/C++及网络方面的常见笔试面试题,并详细讲述Visual Studio常用调试手段与技巧!
专栏3:
VC++常用功能开发汇总![]() https://blog.csdn.net/chenlycly/article/details/124272585
https://blog.csdn.net/chenlycly/article/details/124272585
专栏将10多年C++开发实践中常用的功能,以高质量的代码展现出来,并对相关功能的实现细节进行了详细的说明。这些常用的代码,其质量与稳定性是有保证的,可以直接拿过去使用,可以有效地解决C++软件开发过程中遇到的问题。
4、NetEQ技术详解
4.1、NetEQ概述
NetEQ处理中包括了自适应抖动控制算法和语音丢包补偿算法。自适应抖动算法能够快速适应不断变化的网络环境,而语音丢包补偿算法能够保证一定的音质和清晰度且缓冲延迟最小,另外对NetEQ算法的模拟测试有助于评估音质效果和如何与现有软件设计的有机结合。
NetEQ处理中包括了自适应抖动控制算法和语音丢包补偿算法。自适应抖动算法能够快速适应不断变化的网络环境,而语音丢包补偿算法能够保证一定的音质和清晰度且缓冲延迟最小,另外对NetEQ算法的模拟测试有助于评估音质效果和如何与现有软件设计的有机结合。
NetEQ的模块概要图如下所示:
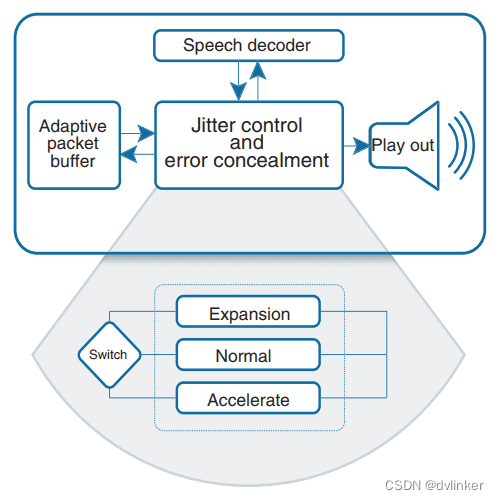
从上图可以看出,NetEQ分为4部分:自适应缓冲(Adaptive packet buffer)、语音解码器(Speech decoder)、抖动控制和丢包补偿(Jitter control and error concealment)和播放(Play out)。其中抖动控制和丢包补偿模块是NetEQ的核心算法,既控制着自适应缓冲,又控制着解码器和丢包补偿算法,并且将最终的计算结果交给声卡去播放。
首先,NetEQ是目前最为完善的抖动消除技术。与固定抖动缓冲和传统的自适应抖动缓冲相比,NetEQ能够快速适应不断变化的网络环境,因此保证了更小的延迟和更少的丢包。NetEQ自适应抖动算法性能比较如下图所示:

其次,抖动控制和和丢包补偿模块由三大操作所组成,即Expansion、Normal和Accelerate:
Expansion:扩展操作,即对语音时长的拉伸,其中包括expand和preemptive_expand两种模式。前者为NetEQ的丢包补偿处理,其作用是等待延迟包并补偿丢包;后者为优先扩展,即在原有数据的基础上拉伸语音时长,其作用是实现减速播放。
Normal:正常播放操作,即网络环境正常且相对平稳时的操作。
Accelerate:加速操作,即实现快速播放。
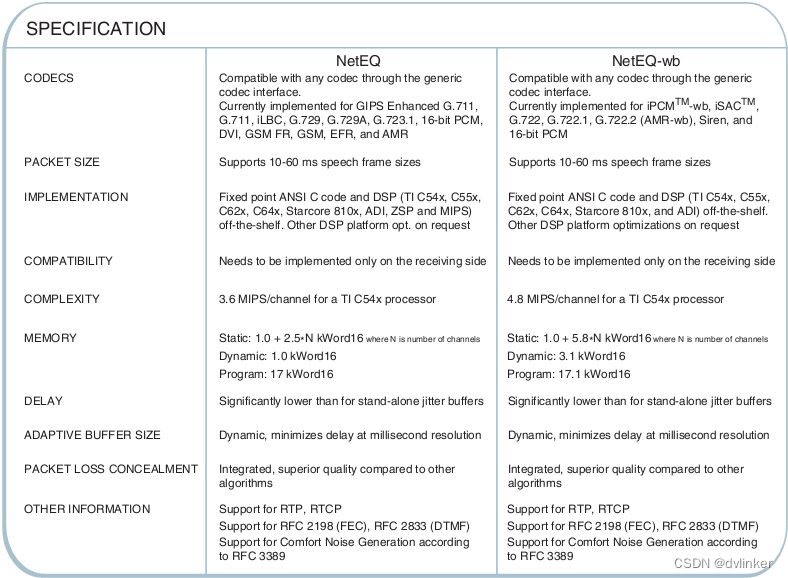
综上所述,本文主要讨论NetEQ的抖动消除和丢包补偿技术,并结合模拟测试和产品设计分析来进一步提高视频会议产品的通话音质。NetEQ性能列表如下所示:
有两种抖动的定义:
抖动定义1:指由于各种延迟的变化导致网络中的数据分组到达速率的变化。具体地说,可将抖动定义为数据流在发送端发送间隔与接收端接收间隔之差,适用于可变码率场景。
抖动定义2:接收端某个数据包到达间隔与平均数据包达到间隔之差定义为该数据包的延时抖动,使用于恒定码率场景。
抖动是一个零均值的随机序列,是由排队IP包的延迟时间差构成的。数据包堆积时意味着数据包提前到达,虽然保证了语音的完整性,但是容易造成接收端缓存溢出并且会增大端到端延迟。数据包超时时意味着数据包经过网络传输后,一段时间后仍未到达接收端,说明数据包可能会延迟到达或者丢包。由于溢出和超时均可导致丢包,会增加端到端的丢包概率。因此,必须对抖动进行有效的控制,以减少由此引起的丢包。
抖动通常采用抖动缓冲技术来消除,即在接收方建立一个缓冲区,语音包到达接收端时首先进入缓冲区暂存,随后系统再以平稳的速率将语音包从缓冲区提取出来,经解压后从音频端口播放。抖动消除的理想状态为:每个数据包在网络传输中的延迟与缓冲区中的所有缓冲数据的延迟应该相等,而缓冲区的大小应该与每个数据包提前到达的抖动加上缓冲数据的延迟之和相等。
抖动缓冲控制算法包括静态抖动缓冲和自适应缓冲抖动控制算法两类:
静态抖动控制算法:缓冲区的延时和大小在语音通话建立后一直到通话结束,均为固定值,对于超时和抖动超出缓冲区大小的数据将会被丢弃。该算法模型简单,易于实现;但网络延时大、抖动大时,丢包率较高,而网络延时和抖动小时,语音延迟较大,不能根据网络状况动态改变缓冲区的延时和大小,而且初始值限定了适用的网络状况。
自适应抖动控制算法:缓冲区的延时和大小随着实际网络的抖动情况而变化。接收端将当前收到的数据包的延迟与算法中保存的延迟信息相比较,得到当前网络的最大抖动,从而选择恰当的缓冲区延时和大小。该算法的优点是:网络抖动大时丢包率小,网络抖动小时延时小;缺点是算法多样且相对复杂。
考虑到当前网络的复杂多变,一般采用自适应抖动算法,NetEQ的抖动消除也属于这类算法。
4.3、丢包补偿技术
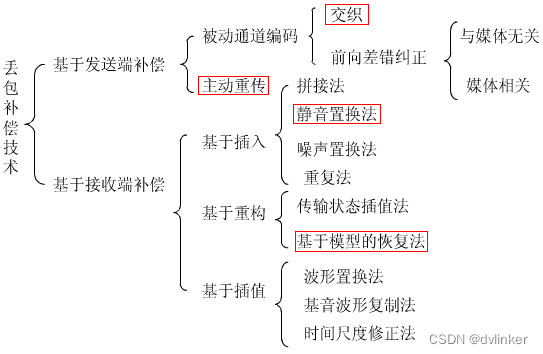
丢包补偿又称为丢包隐藏,即Packet Loss Concealment,简称为PLC,可以分为两类:基于发送端补偿和基于接收端补偿。丢包补偿技术构成如下:
基于发送端的补偿也称为丢包恢复,即Packet Loss Recovery。一般来说,基于发送端的补偿要比基于接收端的补偿效果要好,但会增加网络带宽和时延。
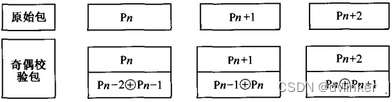
FEC(Forward Error Correction,前向纠错技术)是目前最看好的一种改善VoIP语音质量的冗余编码技术,目的在于提高语音数据传输时的可靠性。为此FEC不仅要传输原始数据,同时还要根据相关性,传输一些冗余数据,以便使解码端根据数据之间的相关性重构丢失的数据包。在VoIP中最简单是奇偶校验码。这种方法是每个n-1个数据包就传输一个包含前面n个数据包的异或操作的校验码,当网络每n个数据包只丢失一个包时,可从别的n-1个数据包重构丢失的数据包。基于奇偶校验包的FEC如下所示:
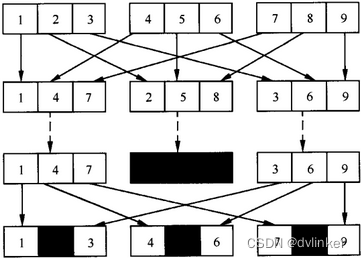
当发生连续丢包时,FEC等各种补偿技术的效果都不理想。为了抵抗大段的突发连续语音丢失,可采用交织(interleaving)技术。交织技术不是真正的丢包恢复技术,因为它不能恢复已经丢失的数据包,但是这种技术能够减少丢包带来的损失。交织技术是通过把原始数据分成若干个比IP包小的单元,在发送前,重新排序这些单元的顺序,使得每个IP包中的数据来自不同的语音帧,当发生丢帧时,只是每一帧的一部分数据丢失,不会出现一帧数据全部丢失现象,在接收端这些单元再重新排序。交织技术利用了人脑能够利用听觉感知自动恢复丢失的一部分数据的功能。当每帧数据只丢失少量数据时,对人耳听觉的影响较小,从而提高音质。由于没有输出额外的信息,所以不会增加带宽,但是由于需要在接收端重新排序,所以会增加时延,达到一定程度也会让人无法忍受。GSM系统就采用了交织技术。
交织技术如下:
低比特率冗余编码(Low-rate Redundant Coding)是一种冗余技术,每个数据包除了包含自身的数据外,还包含前一帧数据经过压缩后的复制,该复制质量低,占用比特数少。当接收端丢包后,可从后面的数据包利用这个复制快速重构丢失包。不像FEC增加的比特数与前后帧具有相关性,它只是简单的在后续包中一份复制,所以也会增加带宽和时延,但是在网络拥塞时与FEC一样,对于连续丢包不适用,会导致丢包更严重。G.729A就采用了冗余编码技术。冗余编码恢复丢包示意图如下:

接收端丢包补偿技术的基本原理是产生一个与丢失的语音包相似的替代语音,这种技术的可行性是基于语音的短时相似性和人耳的掩蔽效应,可以处理较小的丢包率(<15%)和较小的语音包(4~40ms)。接收端的丢包补偿无法替代发送端的补偿,因为不能精确恢复丢失数据。因此网络丢包率较大的时候需要依赖发送端补偿技术,但是丢包率过大的时候只能优化网络。
基于插入的方法是指在丢包处插入一个简单的波形隐藏丢包的方法,这个波形通常与丢失的波形没有相关性,包括静音、白噪声和复制等。
静音替代使用范围非常有限,在丢包率低于2%且语音帧小于4ms时效果较好。白噪声或者舒适噪声利用了人脑下意识用正确语音修复丢失波形的能力,比静音效果好。
复制是GSM系统采用的方法,在发生连续丢包时,补偿的波形用上一帧数据通过逐渐衰减来生成,由于没有考虑语音的前后帧相关性,效果也不是很理想。插值技术是指在丢包时用相似的波形来补偿,这种技术相对复杂,利用丢包前后的数据对丢失数据进行估计,然后用最相似的波形替代丢失波形,所以效果比插入技术更好。
帧间插值技术是一种传统的误码隐藏技术。对于变换编码或线性预测编码的语音编码器,解码器可以基于语音信号的短时平稳性和相邻帧间参数的相关性,根据上一帧的参数进行插值来补偿。G.723.1就采用了参数插值技术,对LSP系数和激励信号分别进行帧间插值来补偿丢失帧;G.729也是利用上一帧的参数进行插值来隐藏错误帧的,利用上一帧的线性预测系数(LPC)和增益衰减系数来补偿丢失帧。
基于重构的补偿技术是通过丢包前后的解码信息来重构产生一个补偿包,计算量最大,效果最好。在接收端完成,不需要发送端的参与和额外的比特流,所以能够满足实时传输的要求,在现代网络传输中更具有有效性和实用性。
基于基音检测的波形替代技术是通过计算基音周期,然后根据基音周期对该帧进行清浊音判断,如果是清音,则用丢包前最近的波形替代,否则用丢包之前长度为基音周期的一段合适的波形来替代,再结合短时能量和过零率来恢复丢失语音,效果由于插入技术,但相对复杂。
数字语音信号处理的基本单位是基音,基音指物体振动时所发出的频率最低的音,其余为泛音。也就是发声体振动时,携带语音中的大部分能量,这种声带振动的频率称为基频,相应的周期为基音周期。基音周期的估计称为基音检测,其目的是得出和声带振动频率完全一致的基音周期长度。
采用波形编码的G.711编码器中没有使用丢包补偿技术,但为了提高语音质量,G.711协议附录中增加了基于基音检测的波形替代技术来补偿丢帧,它利用解码的上一帧数据来估计当前语音信号的基音周期,将最近的一个基音周期和它之前的1/4基音周期的数据用于补偿丢失数据。其中前1/4基音周期的数据用于与丢帧前的语音信号进行重叠相加,保证原始信号和补偿信号之间平滑过渡。若下一帧数据没有丢失,为了保证平滑过渡,则再拓展1/4基音周期数据与正常解码数据进行重叠相加。若下一帧仍然丢失,则多提取一个基音周期的数据用于补偿,最多可提取3个基音周期。丢帧越多,补偿语音与实际语音相差越大。因此,除第一帧外,连续丢帧补偿时,要以20%的速度逐帧衰减。由于语音信号是准平稳的时间序列,尤其是浊音信号,具有一定的周期性,因此采用丢帧前的语音数据重构丢帧数据效果更好。
时域修正技术采用缺口两侧的波形向切口方向延展来填充缺口,在缺口的任一侧找到基音周期的交叠矢量,偏移它们来覆盖缺口,交叠部分求均值。这种方式避免了缺口边界相位不连续的现象,在丢包结合处听不到爆破音,主观效果优于基音检测的波形替代。
WebRTC中NetEQ的丢包补偿技术是采用融合了iLBC算法的丢包补偿技术。iLBC全称为Internet Low Bit rate Codec,是GIPS开发的一种专为包交换网络通信设计的编解码算法,采样率为8khz,有20ms和30ms两种编码时长,码率分别为15.2kbps和13.3kbps,在丢包时具有强大健壮性。iLBC的丢包补偿只在解码端进行处理,采用基于模型恢复法产生补偿包,其具体步骤为:
1)重建线性预测系数(LPC),即采用最后一帧的LPC系统来重建。因为无论空间上还是时间上,最后一帧都与当前丢失帧的LPC具有最相关性,但是这种简单的复制在处理连续丢帧时,显然会引入更大的失真。
2)重建残差信号。残差信号通常可以分为两部分:准周期成分和类噪声成分。其中准周期成分可以根据上一帧的基音周期来近似得到,而类噪声成分则可以通过产生随机噪声得到,二者的能量比例也可以借鉴上一帧的比例关系。因此,首先要对上一帧进行基音检测,然后以基音同步的方式重建丢失帧的话音信号,接着利用相关性得到类噪声增益,最后进行混合以重建整个残差信号。
3)在连续丢帧的情况下,PLC所补偿的各个语音帧具有相同的频谱特性(相同的LPC)和基音频率,为了减少各个补偿帧之间的相关性,会将能量进行逐帧递减。
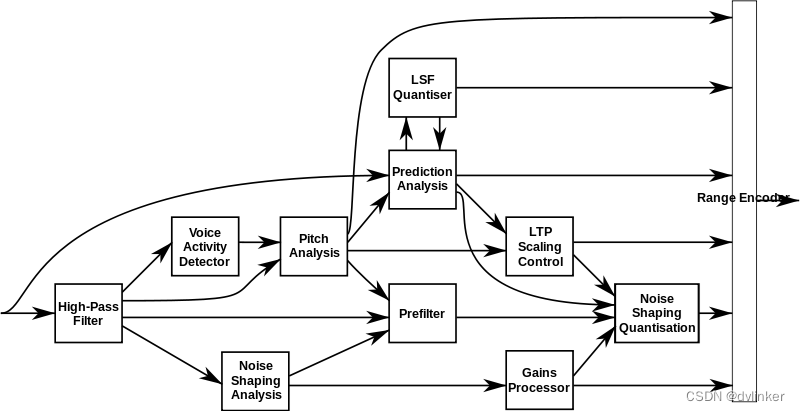
OPUS的丢包补偿分为两种模式:CELT和SILK。OPUS编解码器是由互联网工程任务组(IETF)设计用于互联网的交互式语音和音频输出的,融合了Skype的SILK(与Skype现有SILK算法不兼容)和Xiph.Org的CELT技术。其中CELT模式的丢包补偿与iLBC的类似。

SILK编码器模块框架如下所示:
4.4、NetEQ概要设计
NetEQ模块主要包括MCU和DSP两大处理单元,其中MCU(Micro Control Unit)模块是抖动缓冲区的控制单元,由于抖动缓冲区的作用是暂存接收数据,所以MCU主要作用是负责数据包的插入和控制数据包的输出。抖动消除技术包含在MCU控制模块中。
NetEQ概要设计如下:

抖动缓冲区中设置240个插槽,每个从网络中传输过来的原始数据包都会在抖动缓冲区中选择一个合适的插槽进行放置,主要存储数据包的时间戳、序列号、数据类型等信息,而真正的数据载体存放于一个内存缓冲区中。当有新的数据包到达后,才在内存缓冲区中分配空间存放其载体,从而实现抖动消除。
DSP模块主要负责对从MCU中读取的数据包进行算法处理,包括解码、信号处理、数据输出等,丢包补偿技术包含在DSP模块中。

语音缓冲区中存储的是经过解码及信号处理的待播放数据,可以存储565个样本,curPosition表示待播放数据的起点,sampleLefe为待播放样本数。
共享内存、解码缓冲区和算法缓冲区都是临时数据缓冲区,其中共享内存用于暂存从抖动缓冲区中读取的待解码数据,并且存储样本丢失数量及MCU控制命令;解码缓冲区暂存解码后的数据;NetEQ算法缓冲区暂存DSP算法处理后的数据,用于补充语音缓冲区的新数据;播放缓冲区是播放驱动的数据缓冲区,用于从语音缓冲区中读取数据并播放。
4.5、NetEQ的命令机制
NetEQ的处理流程由各种命令来进行控制,根据接收数据包的状况,来决定采用什么命令:
1)上一帧和当前帧都正常接收:这时数据包进入正常的处理流程,并将解码后的数据按照是否有抖动消除的需要来选择Normal、Accelerate或者Preemptive Expand。
2)仅当前帧丢包或超时:如果当前帧丢包或超时,那么进入PLC处理重建LPC和残差信号,即Expand操作。NetEQ最多会为超时、丢包帧等待100ms,超过该时间则直接提取播放下一帧。
3)连续多帧超时或丢包:如果连续多帧丢包,那么就需要多次进行PLC操作,这时越靠后的数据越难以准确重建补偿包,所以对连续丢包的补偿能量增益采取逐帧减少的方式,以避免引入更大的失真。
4)上一帧丢失,当前帧正常:上一帧丢失,那么播放的上一帧数据是PLC补偿的。为了使经过PLC补偿的帧与正常解码的帧保持语音连续,需要根据前后帧的相关性进行平滑,这时选择Normal或者Merge。
此外,当NetEQ第一次接收到数据包或者整个NetEQ重置之后,会重置解码器。另一方面,当NetEQ接收超过延迟超过3.75s的数据包时,不会将其视为超时包丢弃,而是将其插入抖动缓冲区,并重置缓冲区状态。
4.6、NetEQ的播放机制
WebRTC的语音引擎运行时启动两个线程:一个线程接收数据包并插入抖动缓冲区;另一个线程每隔10ms从语音缓冲区中读取10ms数据进行播放。
NetEQ会结合语音缓冲区中的数据存量和抖动缓冲区中的数据存量来决定是否从抖动缓冲区中读取数据:
1)控制命令为Normal、Expand、解码器重置或者packet buffer状态重置,且SampleLeft大于等于10ms时,则不从抖动缓冲区读取数据,DSP进行Normal操作。
2)控制命令为Normal、解码器重置或者packet buffer状态重置,且SampleLeft小于10ms时,从抖动缓冲区读取数据后,DSP进行Normal操作。
3)控制命令为Expand且SampleLeft小于10ms时,则不从抖动缓冲区读取数据,DSP进行Expand操作。
4)控制命令为Merge时,从抖动缓冲区读取数据后,DSP进行Merge操作。
5)控制命令为Accelerate时,当SampleLeft大于等于30ms,不从抖动缓冲区读取数据,DSP进行Accelerate操作;当SampleLeft大于等于10ms且小于30ms时,不同抖动缓冲区读取数据,DSP进行Normal操作;当SampleLeft小于10ms时,从抖动缓冲区读取数据后,DSP进行Accelerate操作。
6)控制命令为Preemptive Expand时,当SampleLeft大于等于10ms时,不从抖动缓冲区读取数据,DSP进行Preemptive Expand操作;当SampleLeft小于10ms时,从抖动缓冲读取数据后,DSP进行Preemptive Expand操作。
上面的命令处理中,由于考虑到防止在语音缓冲区中增加额外的通话延迟,因此SampleLeft大于等于10ms时不需要从抖动缓冲区读取数据,只有在其小于等于10ms时才会读取数据,保持语音缓冲区中适量的数据;当控制命令为Merge时,任何时候都需要从抖动缓冲区读取数据,这是为了保证前后数据的连贯性;当控制命令为Expand时,丢包补偿会产生一定量的数据,因此任何都是都不需要从抖动缓冲区读取数据,但SampleLeft大于等于10ms时也不进行Expand操作,因为语音缓冲区中有足够的数据用于播放,只进行Normal操作。
4.7、MCU的控制机制
NetEQ的抖动算法中用Blo(optBufferLevel)基于遗忘因子算法来计算预测网络的抖动,用BLc(bufferLevelFit)基于自适应平均算法来计算预测抖动缓冲区的抖动。MCU的控制机制根据已播放数据的时间戳(playedOutTS,记为TSplay)、待读取数据包的时间戳(availableTS,记为TSavail)、Blo和Blc的关系来选择操作命令。TSplay和TSavail的关系来判断网络数据是否正常。
Blo和Blc的比较如下所示:
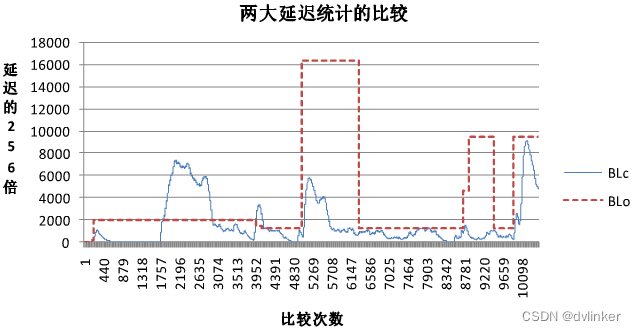
上图中Blo和Blc的关系来判断选择Accelerate、Preemptive Expand、Expand和Merge操作。
简而言之,NetEQ中抖动消除主要由网络延迟和抖动缓冲区延迟的关系发送不同的命令通知DSP执行对应的操作来完成。
4.8、DSP的算法处理
DSP模块是NetEQ中的语音信号处理模块,其操作命令受MCU控制。WebRTC中采用自相关函数法,由于语音信号是非平稳信号,所以对信号的处理都使用短时自相关函数。短时自相关函数法的基因检测主要是利用短时自相关函数在信号周期处最大的特点,通过比较原始信号和它位移后的信号之间的相似性来确定基音周期,如果位移距离等于基音周期,那么两个信号便具有最大相似性。经典的短时自相关函数进行基音检测时,使用一个窗函数,窗不动,语音信号移动。窗长度至少要大于基音周期的两倍,窗长度越长,得出的基音周期越准确,但计算量也会相应的增加。
WebRTC中加速和减速操作基于WSOLA算法来实现语音时长的调整,就是要在不改变语音的音调并保证良好音质的前提下,使语音在时间轴上被压缩或者拉伸,即通常所说的变速不变调。语音时长调整算法分为时域和频率两类,时域以重叠区波形相似性(WSOLA)算法为代表,对于语音信号来说可以获得较高的语音质量,且相对频率算法运算量较小。而对于频率变化剧烈的音频,如音乐信号,时域算法则通常难以获得较高的语音质量,此时通常采用计算量较大的频率算法,如子带WSOLA算法。由于GIPS针对VoIP业务设计的NetEQ,所以数据以语音信号为主,频域变化较小,因此采用时域算法WSOLA。
DSP处理是实现抖动消除、丢包补偿并使得播放的语音实现低时延和较好音质的关键,下面分别介绍DSP的各个操作:
1)加速:将一个语音包的样本数减少,减少的数据是根据语音样本的相关性所得到的基音周期。将两个样本周期的语音数据经过平滑处理,转变为一个基音周期的数据。加速操作以30ms为一帧,只有相关性非常强(>0.9)或者为信号能量很低时才会加速,算法与减速处理类似。如下图所示:
2)减速:将一个语音包的样本数增加,增加的数据是根据语音样本的相关性所得到的基音周期。将两个样本周期的语音数据经过平滑处理,插入两个样本周期之间。减速操作以30ms为一帧,且待播放数据至少有0.625ms,否则重复播放上一帧;当解码后数据缓存不足30ms时,直接拷贝至播放缓存。基音周期的范围为2.5ms至15ms,所以最多延长15ms。如下图所示:
3)插帧:采用iLBC的丢包补偿算法,即重建线性预测系统、重建残差信号和将补偿帧能量逐帧递减。插帧操作时待播放缓存要小于播放读取时长(10ms)。如下图所示:
4)融合:上一帧丢包之后会进行插帧操作,当新的数据解码后,为了提高语音数据的连贯,对新的解码数据和插帧数据进行平滑处理,能量渐强。融合操作生成的数据中间数据较大,需要预留最大空间。如下图所示:
5)正常:这时新的解码数据正常输出播放,但如果上一帧数据是插帧数据,需要先插帧再平滑。



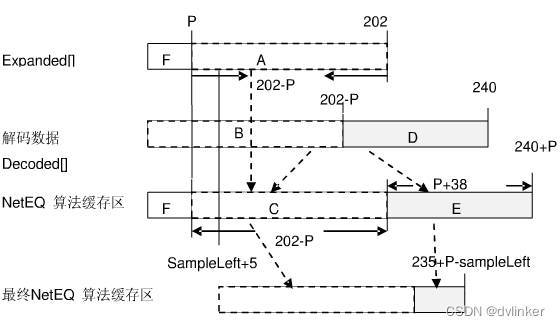
4.9、DSP算法的模拟测试
针对以上DSP算法操作,本文分别对间断的语音信号(Test1)、连续的语音信号(Test2)和音乐信号(Test3)在不同丢包率下进行了模拟测试,并采用ITU-T P563客观测量标准进行MOS值估计,LostData为丢包时填补静音,Expand为丢包时插帧,Expand+Merge为丢包时先插帧再融合。
| 测试 序列 | 输出帧 时长 | 丢包率 | MOS(P563) | ||
| LostData | Expand | Expand+Merge | |||
| test1 | 10ms | 10.00% | 2.131 | 2.163 | 2.377 |
| 11.11% | 2.237 | 3.085 | 3.073 | ||
| 12.50% | 1.717 | 2.930 | 3.231 | ||
| 14.29% | 2.159 | 3.138 | 3.348 | ||
| 16.67% | 1.656 | 2.650 | 3.275 | ||
| 20.00% | 2.364 | 2.161 | 2.333 | ||
| 25.00% | 1.838 | 3.001 | 3.033 | ||

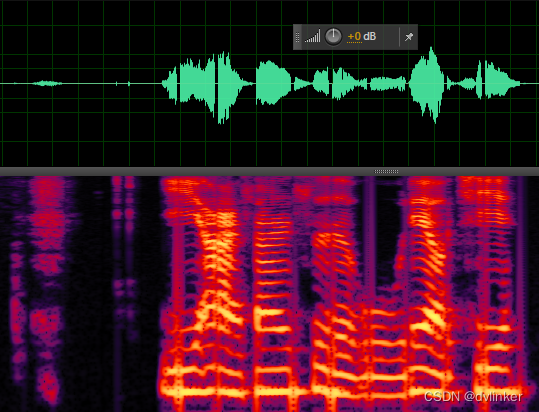
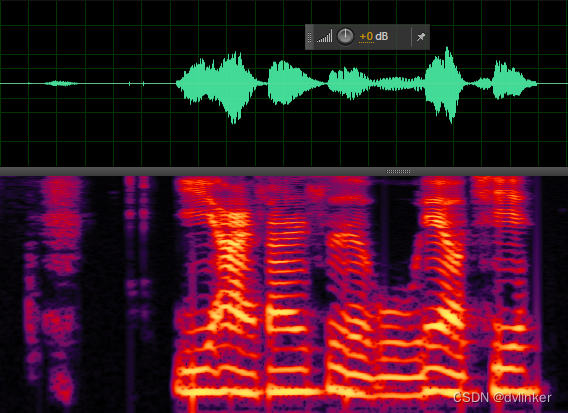
间断话音信号对丢包率的变化不是很敏感,因为丢包的时候没有丢失太多语音时MOS值就会比较好,丢包时产生的爆破音在丢包补偿之后都有明显改善,主观感受良好。
| 测试 序列 | 输出帧 时长 | 丢包率 | MOS(P563) | ||
| LostData | Expand | Expand+Merge | |||
| test2 | 10ms | 10.00% | 2.656 | 2.872 | 3.598 |
| 11.11% | 2.568 | 2.997 | 2.926 | ||
| 12.50% | 2.634 | 3.162 | 3.038 | ||
| 14.29% | 2.530 | 3.169 | 3.007 | ||
| 16.67% | 2.290 | 2.903 | 2.980 | ||
| 20.00% | 2.522 | 3.206 | 3.108 | ||
| 25.00% | 1.952 | 2.943 | 2.952 | ||

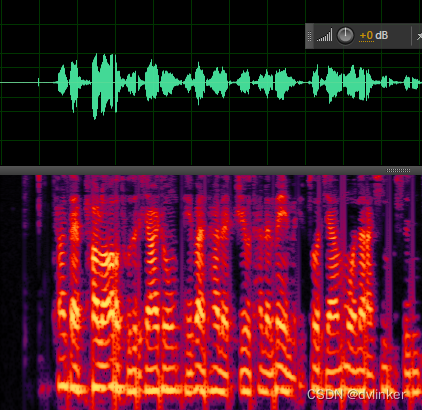
连续话音信号跟随丢包率呈现出逐渐下降的趋势,丢包补偿的效果与Test1相近,爆破音明显改善,主观感受良好。
| 测试 序列 | 输出帧 时长 | 丢包率 | MOS(P563) | ||
| LostData | Expand | Expand+Merge | |||
| Test3 | 10ms | 10.00% | 2.428 | 2.658 | 2.855 |
| 11.11% | 2.577 | 2.708 | 2.663 | ||
| 12.50% | 3.420 | 2.478 | 2.739 | ||
| 14.29% | 3.552 | 2.444 | 2.863 | ||
| 16.67% | 3.251 | 2.421 | 2.792 | ||
| 20.00% | 1.000 | 2.208 | 2.527 | ||
| 25.00% | 1.099 | 1.993 | 2.474 | ||
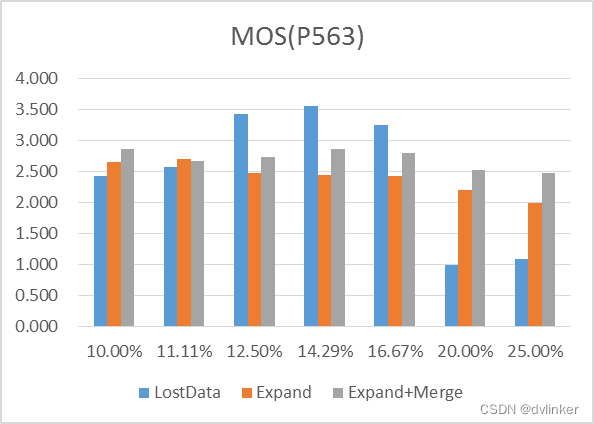
音乐信号选取的是久石让的《天空之城》,整个频谱变化较大,丢包率较小时补偿效果不错,丢包率越大补偿的主观效果越差。
加速、减速和正常操作就不一一对比了,其中加速和减速操作在不丢包时对消除抖动的音质效果非常好,保持语音信号的完整性。

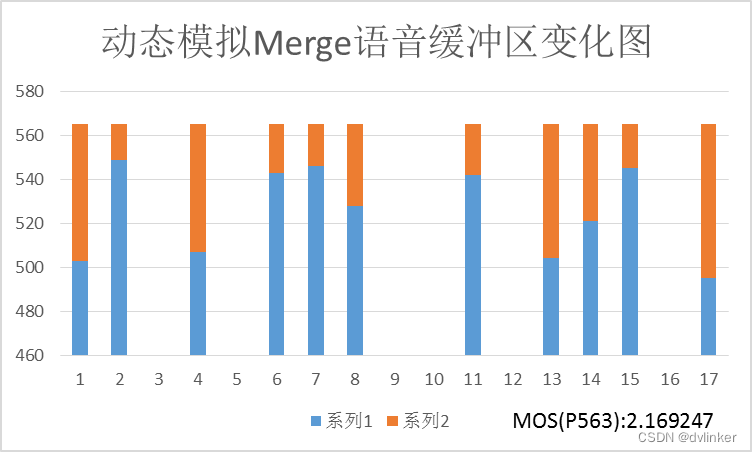
上图中动态模拟的初始值为37个样本,即初始时待播放样本为37个。Expand之后Merge得到的MOS值下降,有两个可能的原因:1、Expand前待播放字节数较少,导致插帧数据音质不高;2、Merge前Expand补偿的数据较多影响Merge后的音质,理想情况应该是Expand和Merge一一对应。
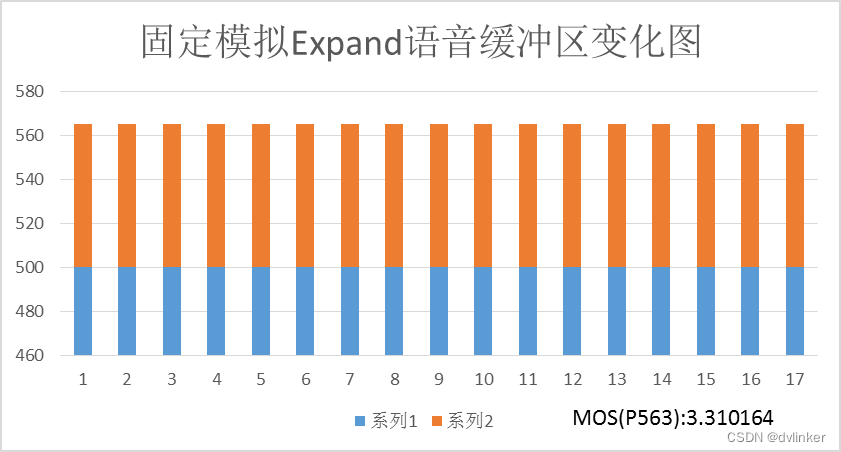

上图中固定模拟的固定值为500个样本,即待播放样本保持为500个。这时Expand得到的MOS值有较大提升,之后每次都进行Merge操作,帮助提高MOS值。
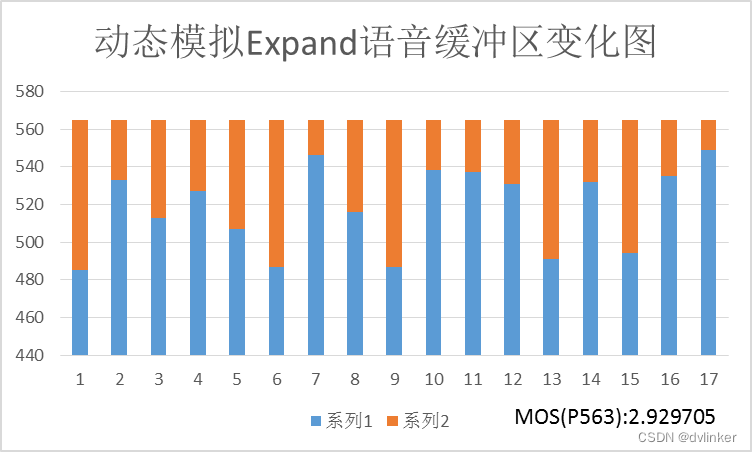
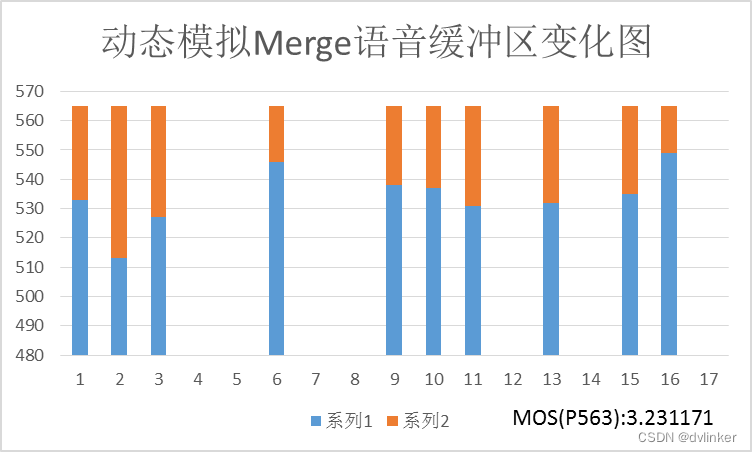
上图中动态模拟的初始值为0,即初始时待播放样本为0个。这时Expand之前待播放样本减少导致Expand插帧数据的MOS值降低,之后虽然不是Expand和Merge一一对应,但是每次Merge之前待播放数据较少,所以需要平滑的数据就会更少,帮助提高MOS值。
P563标准的几个重要参数为:信噪比(SNR)、静音间隔和平均基音周期等,没有参考相位变化,但是相位变化对听觉的主观影响很大,比如在插帧数据之后相位不连续的波形有可能会产生爆音,这时会影响音质,所以插帧与融合虽然采用P563的MOS值估计有时相差无几,但是融合的主观感受要明显好于插帧。
5、NetEQ源文件说明
mcu_dsp_common.h:NetEQ实例。
neteq_error_codes.h:NetEQ错误码。
neteq_statistics.h:NetEQ PLC统计信息。
dsp.h:dsp上PLC操作的头文件。
accelerate.c:加速操作以减少延时。当信号的相关性很强且信号能量很弱的时候进行处理。
expand.c:生成音频信号并生成背景噪声。
preemptive_expand.c:减速以增加延时。
normal.c:正常播放。
merge.c:将新的一帧数据与扩展的上一帧数据做平滑处理。
bgn_update.c:背景噪声估计和更新。
cng_internal.c:生成舒适背景噪声。
dsp.c:dsp操作的初始化函数和常量表的定义。
recin.c:添加RTP数据包。
recout.c:解码输出PCM。
dsp_helpfunctions.h
dsp_helpfunctions.c:两个dsp的函数,频率是8k的倍数和降采样到4k。
min_distortion.c:最小失真计算。
correlator.c:计算信号的相关性。
peak_detection.c:相关性峰值检测和定位。
mix_voice_unvoice.c:混音
mute_signal.c:静音(减弱)
unmute_signal.c:关闭静音(渐强)
random_vector.c:随机向量。
codec_db_defines.h
codec_db.c:管理算法库的数据库。
dtmf_buffer.h
dtmf_buffer.c:DTMF消息和解码。
dtmf_tonegen.h
dtmf_tonegen.c:生成DTMF信号。
mcu.h:MCU侧操作。
mcu_address_init.c:MCU地址初始化。
mcu_dsp_common.c:MCU和DSP之间的通信。
mcu_reset.c:重置MCU侧的数据。
set_fs.c:DTMF采样率。
signal_mcu.c:通知MCU数据可用并请求一个PLC命令。
split_and_insert.c:分拆RTP头并添加到数据包缓冲。
rtcp.h
rtcp.c:RTCP统计。
rtp.h
rtp.c:RTP函数。
automode.h
automode.c:动态缓存策略。
packet_buffer.h
packet_buffer.c:数据包缓存管理。
buffer_stats.h
bufstats_decision.c:根据缓存抖动来给出PLC命令。
webrtc_neteq.h
webrtc_neteq_help_macros.h:NetEQ宏定义
webrtc_neteq.c:NetEQ API。
webrtc_neteq_internal.h:NetEQ内部函数
webrtc_neteq_unittest.cc:NetEQ单元测试。
6、参考文档
《GIPS NetEQ》,Global IP Solutions
《WebRTC语音引擎中NetEQ技术的研究》,吴江锐
《WebRTC语音引擎中分组缓存技术研究》,肖洪亮
《VoIP丢包处理技术的研究发展》,李如玮,鲍长春
《ITU-T P.563 Single-ended method for objective speech quality assessment in narrow-band telephony application》,国际电联ITU(International Telecommunication Union)

