
热门标签
当前位置: article > 正文
机器学习之L1正则化和L2正则化(附源码解析)_lq正则化重构代码
作者:花生_TL007 | 2024-05-15 19:31:55
赞
踩
lq正则化重构代码
前言
今天还是机器学习的基础知识内容,也是最基础的哈。首先说一下什么是正则化,其实它就是一个减少方差的策略。那么什么是方差呢?在这里也引入一个和方差相辅相成的概念--偏差。
- 偏差度量了学习算法的期望预测与真实结果的偏离程度, 即刻画了学习算法本身的拟合能力
- 方差度量了同样大小的训练集的变动所导致的学习性能的变化,即刻画了数据扰动所造成的影响
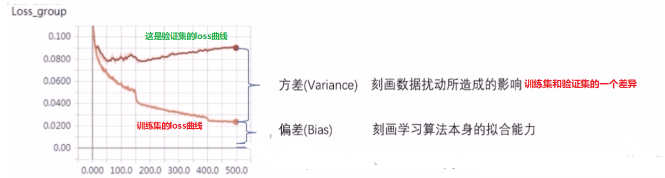
我们通常所说的过拟合现象,也就是指的高方差,就是模型在训练集上训练的超级好,几乎全部都能拟合。 但是这种情况如果换一个数据集往往就会非常差, 正则化的思想就是在我们的目标函数中价格正则项, 即:
![]()
在这里正则项有两种,分别是L1和L2,先来看一下两者的表达式:

如果加上这种正则项,就是希望我们的代价函数小,同时也希望我们这里的<
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/花生_TL007/article/detail/574654
推荐阅读
相关标签

