
- 1k8s学习--资源控制器StatefulSet详细解释与应用
- 2Transformer模型-数据预处理,训练,推理(预测)的简明介绍_transformer部署 训练 推理
- 3STM32 处理 MPU6050 数据实现智能手环步数计算_stm32 mpu6050 计步
- 4音频视频基础知识学习_音频视频文件的基础知识论文
- 5《深度学习进阶:自然语言处理(第1章)》-读书笔记
- 6在Ubuntu上将Linux安装到USB硬盘_ubuntu挂载usb硬盘
- 7sop8封装的8脚蓝牙芯片KT6368A的低功耗测试说明_8引脚蓝牙芯片
- 8win10 git bash执行 make命令_git bash执行makefile
- 9arduino智能闹钟_暑期创客与人工智能夏令营课程
- 10【计算机视觉 | 图像分割】arxiv 计算机视觉关于图像分割的学术速递(8 月 29 日论文合集)_图形分割最新文献
java集合HashMap、HashTable、HashSet详解_java hashmap hashset hashtable
赞
踩
一、Set和Map关系
Set代表集合元素无序,集合元素不可重复的集合,Map代表一种由多个key-value组成的集合,map集合是set集合的扩展只是名称不同,对应如下

二、HashMap的工作原理
HashMap基于hashing原理,通过put()和get()方法储存和获取对象。
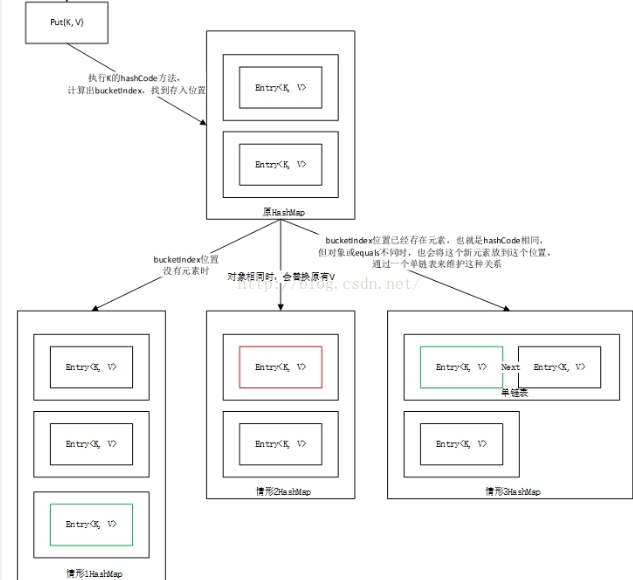
put()方法: 它调用键对象的hashCode()方法来计算hashcode值,系统根据hashcode值决定该元素在bucket位置。如果两个对象key的hashcode返回值相同,那他们的存储位置相同,如果这两个Entry的key通过equals比较返回true,新添加Entry的value将覆盖集合中原有Entry的value,但key不会覆盖;如果这两个Entry的key通过equals比较返回false,新添加的Entry将与集合中原有Entry形成Entry链,而且新添加Entry位于Entry链的头部。put源码如下:


put方法三种情况,如图:
get()方法:当HashMap的每个bucket里存储的Entry只是单个Entry,即没有通过指针产生Entry链时,此时HashMap具有最好的性能。当程序通过key取出对应value时,系统先计算出该key的hashCode()返回值,再根据该hashCode返回值找出该key在table数组中的索引,然后取出该索引处的Entry,最后返回该key对应的value值。get源码如下:
HashMap有两个参数影响其性能:
1. 初始容量和加载因子。默认初始容量是16,加载因子是0.75。容量是哈希表中桶(Entry数组)的数量,初始容量只是哈希表在创建时的容量。加载因子是哈希表在其容量自动增加之前可以达到多满的一种尺度。当哈希表中的条目数超出了加载因子与当前容量的乘积时,通过调用rehash 方法将容量翻倍。
2. 加载因子过高虽然减少了空间开销,但同时也增加了查询成本(加载因子是表示Hsah表中元素的填满的程度.若:加载因子越大,填满的元素越多,好处是,空间利用率高了,但:冲突的机会加大了.反之,加载因子越小,填满的元素越少,好处是:冲突的机会减小了,但:空间浪费多了)。在设置初始容量时应该考虑到映射中所需的条目数及其加载因子,以便最大限度地降低rehash 操作次数。如果初始容量大于最大条目数除以加载因子(实际上就是最大条目数小于初始容量*加载因子),则不会发生 rehash 操作。
3.HashMap存放的元素越来越多,到达临界值(阀值)threshold时,就要对Entry数组扩容,这是Java集合类框架最大的魅力,HashMap在扩容时,新数组的容量将是原来的2倍,由于容量发生变化,原有的每个元素需要重新计算bucketIndex,再存放到新数组中去,也就是所谓的rehash。HashMap默认初始容量16,加载因子0.75,也就是说最多能放16*0.75=12个元素,当put第13个时,HashMap将发生rehash,rehash的一系列处理比较影响性能,所以当我们需要向HashMap存放较多元素时,最好指定合适的初始容量和加载因子,否则HashMap默认只能存12个元素,将会发生多次rehash操作。
三、HashMap和Hashtable的区别
HashMap和Hashtable都实现了Map接口,主要的区别有:线程安全性,同步(synchronization),以及速度。HashMap几乎可以等价于Hashtable,除了HashMap是非synchronized的,并可以接受null(HashMap可以接受为null的键值(key)和值(value),而Hashtable则不行)。
HashMap是非synchronized,而Hashtable是synchronized,意味着Hashtable是线程安全的,多个线程可以共享一个Hashtable;而多个线程是不能共享HashMap的。Java 5提供了ConcurrentHashMap,它是HashTable的替代,比HashTable的扩展性更好。另一个区别是HashMap的迭代器(Iterator)是fail-fast迭代器,而Hashtable的enumerator迭代器。HashMap可以通过下面的语句进行同步:Map m = Collections.synchronizeMap(hashMap);
(一)继承的历史不同
- public class Hashtable extends Dictionary implements Map
- public class HashMap extends AbstractMap implements Map
- 1
- 2
Hashtable是继承自Dictionary类的,而HashMap则是Java 1.2引进的Map接口的一个实现。
(二)安全性不同
HashMap是非synchronized,而HashTable在默认的情况下是synchronized,这意味着HashTable是线程安全的,多个线程可以共享一个HashTable;而如果没有正确的同步的话,多个线程是不能共享HashMap的。Java 5以后提供了ConcurrentHashMap,它是HashTable的替代,比HashTable的扩展性更好。当然,我们可以通过以下方法让HashMap同步:
Map m = Collections.synchronizeMap(hashMap);- 1
(三)是否可为空值的异同
HashMap可以让你将空值作为一个表条目的key或value。HashMap中只有一条记录可以是一个空的key,但任意数量的条目可以是空的value。这就是说,如果在表中没有发现搜索键,或者如果发现了搜索键,但它是一个空的值,那么get()将返回null;而HashTable则不行,key和value都不允许出现null值。
(四)二者的遍历方式的内部实现上不同
Hashtable、HashMap都使用了 Iterator迭代器,HashMap的迭代器(Iterator)是fail-fast迭代器,而HashTable的enumerator迭代器不是fail-fast的。而由于历史原因,Hashtable还使用了Enumeration的方式 。
(五)哈希值的使用不同
HashTable直接使用对象的hashCode,而HashMap则需要重新计算hash值。
(六)二者内部实现方式的数组的初始大小和扩容的方式不同
HashTable中hash数组默认大小是11,增加的方式是 old*2+1;HashMap中hash数组的默认大小是16,而且一定是2的指数。
四、HashMap和HashSet的区别
HashSet实现了Set接口,它不允许集合中有重复的值,HashMap实现了Map接口,Map接口对键值对进行映射。
HashSet扩展了HashMap,所以底层还是用到map存储,存储实现同map一致,HashMap储存键值,HashSet存储对象。
那么hashMap的工作原理是什么?
当系统开始初始化HashMap的时候,系统会创建一个长度为capacity的Entry数组。这个数组存储的元素是一个系列元素的索引,也称为“桶”,当一个元素要增加的时候,会计算他的hashcode,然后再数组中寻找他的位置,比如,他的位置有元素占据了,那么会在该元素上,扩展出一条索引链,将数据插入到这个索引链上。
HashSet和HashMap的区别
| *HashMap* | *HashSet* |
| HashMap实现了Map接口 | HashSet实现了Set接口 |
| HashMap储存键值对 | HashSet仅仅存储对象 |
| 使用put()方法将元素放入map中 | 使用add()方法将元素放入set中 |
| HashMap中使用键对象来计算hashcode值 | HashSet使用成员对象来计算hashcode值,对于两个对象来说hashcode可能相同,所以equals()方法用来判断对象的相等性,如果两个对象不同的话,那么返回false |
| HashMap比较快,因为是使用唯一的键来获取对象 | HashSet较HashMap来说比较慢 |

