
水果识别系统Python,基于TensorFlow卷积神经网络算法_水果识别网络
赞
踩
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
提示 面对水果识别系统Python,基于TensorFlow卷积神经网络算---深度学习算法:
提示:以下是本篇文章正文内容,下面案例可供参考
一、项目含义背景
果蔬识别系统,使用Python作为主要开发语言,使用深度学习 TensorFLOw框架,Django框架,搭建卷积神经网络算法,并通过对数据进行训练,最后得到一个识别精度较高的模型,并且使用网站网页端操作平台,实现用户上传一张图片识别。
二、数据集
1:使用的是CIFAR-10数据集, 包含10个类别的60000张像素的彩色图像集。

三、读取数据——预处理
1:读取数据
代码如下(示例):
- 导入 pathlib-----pathlib 模块提供了表示文件系统路径的类,可适用于不同的操作系统。使用 pathlib 模块,相比于 os 模块可以写出更简洁,易读的代码。
import pathlib
data_dir = "./dataset/"
data_dir = pathlib.Path(data_dir)
image_count = len(list(data_dir.glob('*/*')))
print("图片总数为:",image_count)
- 1
- 2
- 3
- 4
- 5
- 6
2.数据处理调配
batch_size = 12 img_height = 224 img_width = 224 train_ds = tf.keras.preprocessing.image_dataset_from_directory( data_dir, validation_split=0.2, subset="training", seed=12, image_size=(img_height, img_width), batch_size=batch_size) val_ds = tf.keras.preprocessing.image_dataset_from_directory( data_dir, validation_split=0.2, subset="validation", seed=12, image_size=(img_height, img_width), batch_size=batch_size) class_names = train_ds.class_names print("数据类别有:",class_names)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
2.检查数据
for image_batch, labels_batch in train_ds:
print(image_batch.shape)
print(labels_batch.shape)
break
- 1
- 2
- 3
- 4
3.配置数据集
AUTOTUNE = tf.data.AUTOTUNE def train_preprocessing(image,label): return (image/255.0,label) train_ds = ( train_ds.cache() # .shuffle(2000) .map(train_preprocessing) # 这里可以设置预处理函数 # .batch(batch_size) # 在image_dataset_from_directory处已经设置了batch_size .prefetch(buffer_size=AUTOTUNE) ) val_ds = ( val_ds.cache() # .shuffle(2000) .map(train_preprocessing) # 这里可以设置预处理函数 # .batch(batch_size) # 在image_dataset_from_directory处已经设置了batch_size .prefetch(buffer_size=AUTOTUNE) )
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
四.网络结构
| 框架 | 作用 |
|---|---|
| tensorflow | Tensorflow是一个编程系统,使用图(graphs)来表示计算任务,图(graphs)中的节点称之为op(operation |
| Django | Django 是用Python开发的一个免费开源的Web框架,可以用于快速搭建高性能,优雅的网站!采用了MVC的框架模式,即模型M,视图V和控制器C,也可以称为MVT模式,模型M,视图V,模板T |
- 网络结构图:
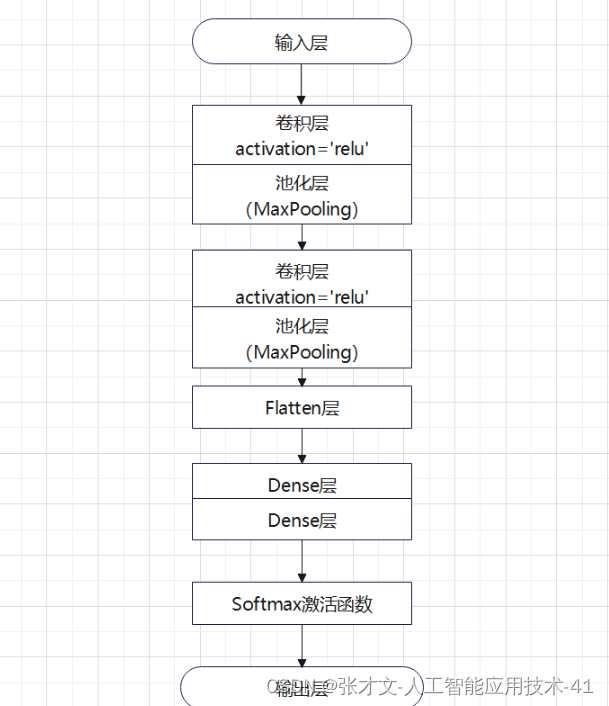
1.数字图像识别主要是在计算机视觉的基础上,通过收集图像的轮廓、特征、色彩、纹理等信息来进行识别。一般的图像识别流程如图所示。
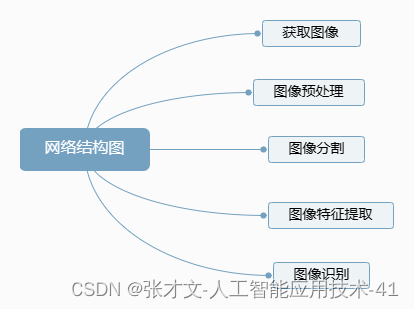
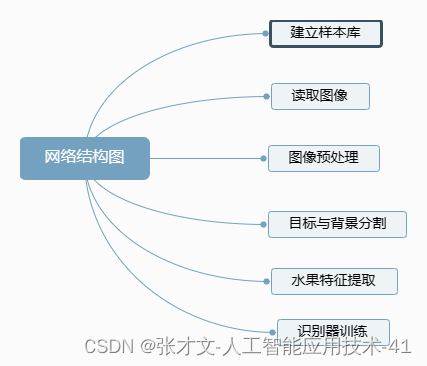
2.水果识别的设计主要分为六大步骤,具体的流程图如图所示
3.调用预训练的ResNet50模型并在新的数据集上进行训练和识别。这里我们将使用CIFAR-10数据集,一个包含10个类别的60000张32x32像素的彩色图像集。(部分代码)
<1>我们定义了一个模型,其中包括预训练的ResNet50模型和一些额外的全连接层。这些全连接层是用来根据我们的新任务(在这个例子中是CIFAR-10分类)来学习特定的特征。我们指定ResNet50模型的权重来自Imagenet预训练,并且不包括顶部的全连接层(因为我们要添加自己的全连接层)。
# 构建模型
base_model = ResNet50(weights='imagenet', include_top=False, input_shape=(32, 32, 3))
model = models.Sequential()
model.add(base_model)
model.add(layers.Flatten())
model.add(layers.Dense(1024, activation='relu'))
model.add(layers.Dropout(0.5))
model.add(layers.Dense(10, activation='softmax')) # 这里的 10 是 CIFAR10 数据集的类别数量
# 冻结预训练模型的卷积层,避免在训练过程中破坏预训练的权重
for layer in base_model.layers:
layer.trainable = False
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
五.模型的训练
1.损失函数(loss function)或 代价函数 (cost function)是将随机事件或其有关随机变量的取值映射为非负实数以表示该随机事件的“风险”或“损失”的函数。
2.在定义了模型结构之后,我们编译模型,指定优化器、损失函数和评价指标。(如下代码)
# 构建模型 base_model = ResNet50(weights='imagenet', include_top=False, input_shape=(32, 32, 3)) model = models.Sequential() model.add(base_model) model.add(layers.Flatten()) model.add(layers.Dense(1024, activation='relu')) model.add(layers.Dropout(0.5)) model.add(layers.Dense(10, activation='softmax')) # 这里的 10 是 CIFAR10 数据集的类别数量 # 冻结预训练模型的卷积层,避免在训练过程中破坏预训练的权重 for layer in base_model.layers: layer.trainable = False # 编译模型 model.compile(optimizer=optimizers.Adam(), loss='categorical_crossentropy', metrics=['accuracy']) # 训练模型 history = model.fit(train_images, train_labels, validation_data=(test_images, test_labels), batch_size=64, epochs=5) # 评估模型 test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2) print('\nTest accuracy:', test_acc)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
3.接着,我们使用训练数据和标签对模型进行训练,设置了批量大小和训练轮数,并使用验证数据集对模型进行验证。
4.训练完成后,我们在测试集上评估模型的性能,打印出测试集上的精度。
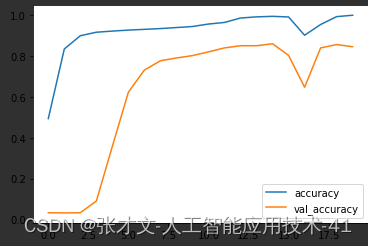
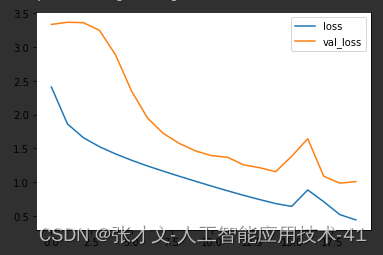
六.成品展示
1.代码运行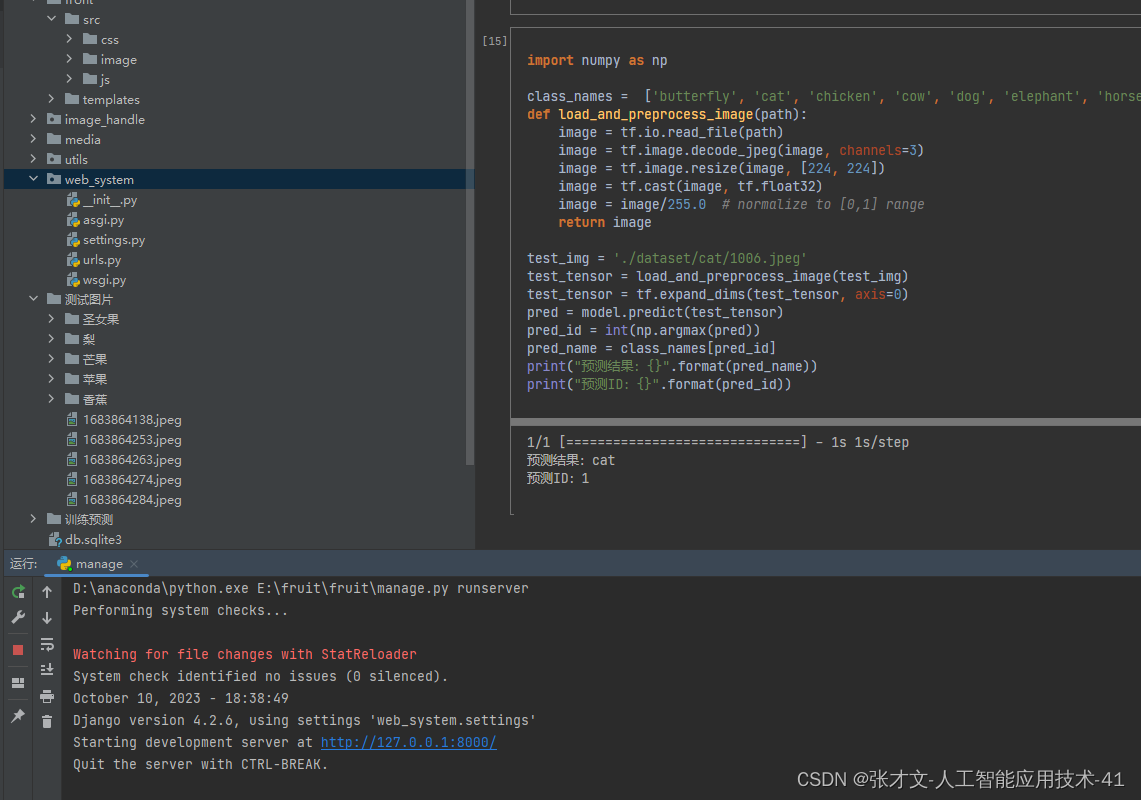
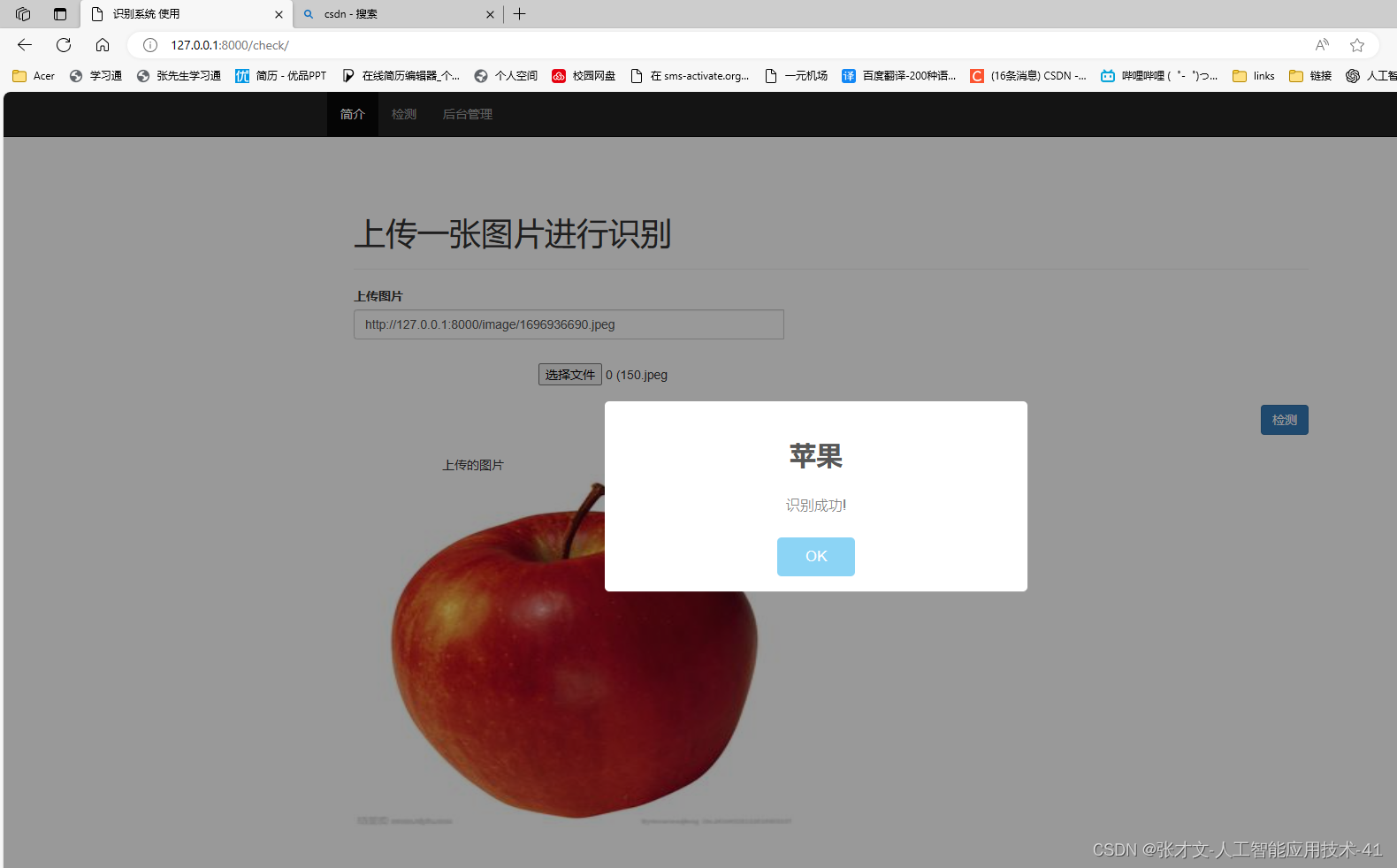
2.基于Django框架,开发网页端操作平台----预测
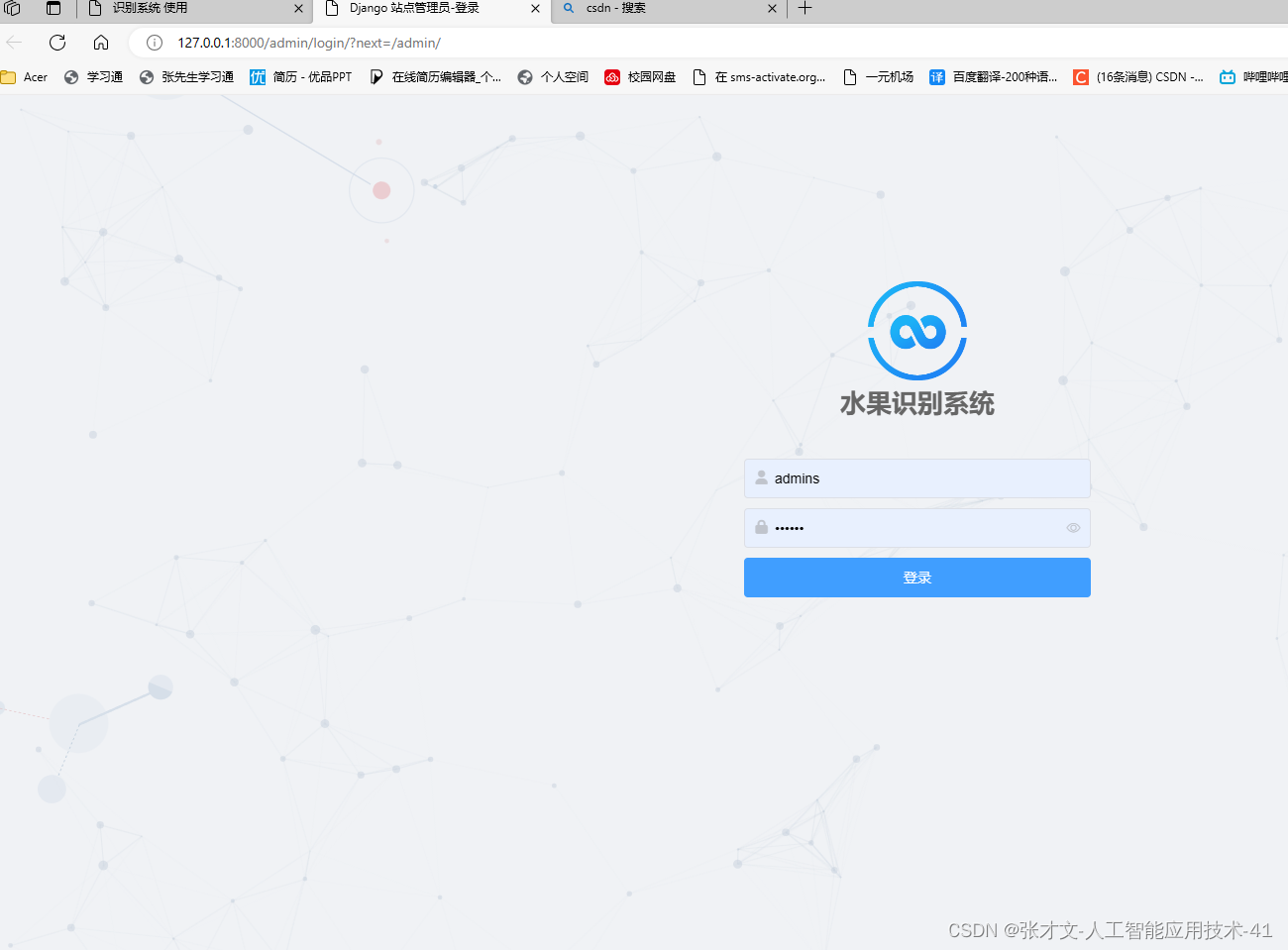
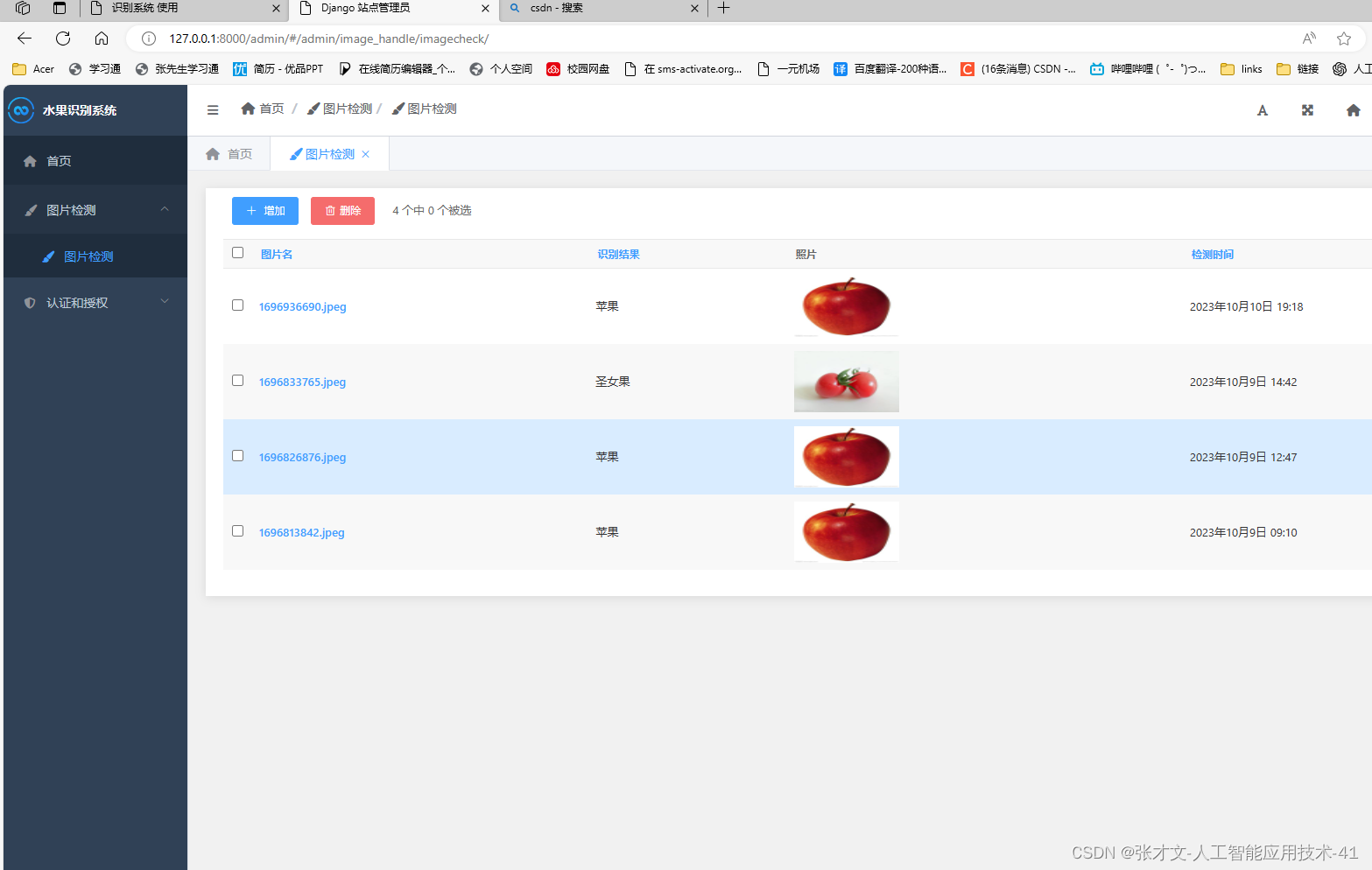
3.后台管理----数据库存储
总结
提示:本文章只用于参考,谢谢鉴赏。

