
- 1解决git@github.com: Permission denied (publickey). Could not read from remote repository
- 2spring boot 2.7 -> 3.0升级指南_springboot2.7升级3
- 3【MATLAB图像处理】傅里叶变换--幅度谱、相位谱、逆变换_用matlab在已知相位和幅值的情况下进行傅里叶逆变换
- 4Cortex-M0的内核架构_m0内核
- 5php页面链接无线网络,电脑怎么添加无线网络连接
- 6《多GPU大模型训练与微调手册》_多卡微调
- 7AI生成-浏览器渲染页面流程_网页渲染图生成
- 8【go从入门到精通】精通并发编程-WaitGroup
- 9基于 LoRa 无线通信技术的电气火灾监控系统的具体应用_lora 应急通信
- 10Github标星51K 阿里P8熬了700个小时,终于肝出32W字Java面试手册_github标星51k 阿里p8熬了700个小时,终于肝出32w字java面试手册
深度学习的关键术语
赞
踩
深度学习已经成为编程界的一股潮流,因为其在许多领域取得了令人难以置信的成功,使其在研究和工业领域广受欢迎。那么到底什么是深度学习呢?深度学习是应用深层神经网络技术:即利用具有多个隐藏层的神经网络结构来解决问题的过程。深度学习是一个过程,如数据挖掘,它采用深度神经网络架构,它是特定类型的机器学习算法。
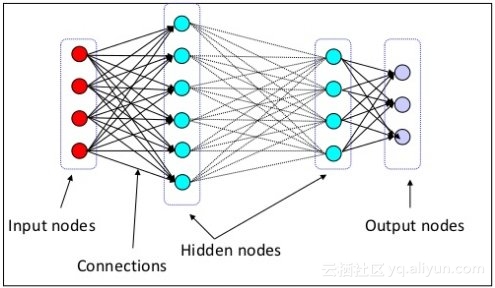
深度学习最近取得了令人吃惊的成就。但,至少在我看来,谨记一些事情是很重要的:
1. 深度学习不是万能的——它不是一个解决所有问题的万能的解决方案。
2.它不是传说中的王牌算法——深度学习不会取代所有其他机器学习算法和数据科学技术、或者至少它还没有证明如此。
3.有期望是必要的——尽管最近它在所有类型的分类问题上取得了很大进展,特别是计算机视觉和自然语言处理以及强化学习和其他领域,当代深度学习并没有扩展到处理非常复杂的问题,如“解决世界和平”。
5.深度学习可以通过附加的过程和工具来帮助解决问题,从而为数据科学提供了极大的帮助。当从这个角度观察时,深度学习对数据科学领域是非常有价值的补充。
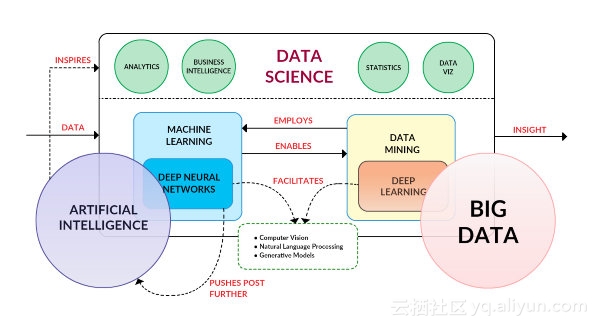
如上图所示,深度学习其本质就是数据挖掘,因为(深度)神经网络是机器学习(过程与体系结构)。同样可以看到的事实是,深度神经网络与当代人工智能有很大关系,至少两者可以交织在一起(然而,它们不是同一事物,人工智能是具有许多其他算法以及超越神经网络的技术)。还需要注意的是深度学习/深度神经网络与计算机视觉、自然语言处理和生成模型之间的联系,鉴于近年来在这些领域取得的巨大进步,深度学习和神经网络技术的联系是微妙的,但这种联系具有特别重要的意义。
那么,让我们来看看一些与深度学习相关的术语。
1. 深度学习:
如上所述,深度学习是应用深度神经网络技术解决问题的过程。深度神经网络是具有最小隐藏层的神经网络(见下文)。像数据挖掘一样,深度学习是指一个过程,它采用深层神经网络体系结构,其是特定类型的机器学习算法。
2. 人工神经网络(ANN):
机器学习架构最初是由深度学习的脑神经(尤其是神经元)所启发的。实际上,单独的人工神经网络(非深度变种)已经存在了很长时间,并且历史上能够解决某些类型的问题。然而,相对最近,神经网络架构被设计出来,其中包括隐藏的神经元层(不仅仅是输入层和输出层),而且这种复杂程度增加了深度学习的能力,并提供了一套更强大的问题解决工具。
人工神经网络在结构上与深度神经网络有很大的不同,因此没有明确的神经网络定义。所有人工神经网络通常引用的特征是拥有自适应加权集合,以及将输入的非线性函数逼近神经元的能力。
3. 生物神经元
通常,生物神经网络和人工神经网络之间存在明确的联系。流行的出版物宣传了人工神经网络在某种程度上是人类(或其他生物)大脑中发生的确切复本,但这显然是不准确的。充其量,早期的人工神经网络受到生物学的启发。两者之间的抽象关系不比原子与太阳系的组成和功能之间的抽象比较明确。
也就是说,如果仅仅了解人工神经网络的灵感,它确实能让我们看到生物神经元如何在很高的水平上工作。
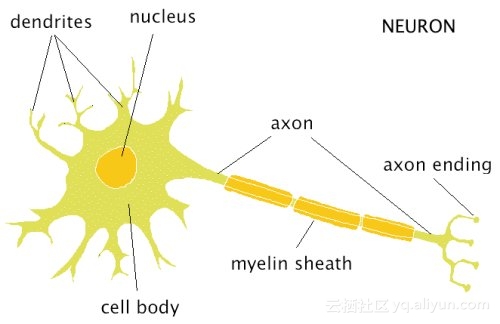
我们感兴趣的生物神经元的主要组成部分是:
· 核:保存遗传信息(即,DNA)。
· 细胞主体:处理输入激活,并将其转换成输出激活。
· 树突:从其他神经元接受激活。
· 轴突:传递激活到其他神经元。
· 轴突末梢:与相邻的树突形成神经元之间的突触。
被称为神经递质的化学物质然后扩散穿过轴突末端和邻近的树突之间的突触间隙,构成神经传递。神经元的基本操作是激活神经元,处理,然后通过其轴突末端再传播出轴突,穿过突触间隙并到达许多接受神经元的树突,重复这个过程。
4. 感知器
感知器是一个简单的线性二元分类器。感知器获取输入和相关权重(表示相对输入重要性),并将它们组合以产生输出,然后用于分类。感知器已经存在了很长时间,早期的实现可以追溯到20世纪50年代,其中第一个涉及早期的ANN实现。
5. 多层感知机(MLP)
多层感知机(MLP)是几个完全相邻连接的感知机层的实现,形成一个简单的前馈神经网络(见下文)。这种多层感知机具有单感知机不具备的非线性激活功能的优势。
6. 前馈神经网络
前馈神经网络是神经网络结构的最简单形式,其中的连接是非周期性的。原始的人工神经网络,前馈网络中的信息从输入节点(隐藏层)向输出节点单向前进,没有周期存在。前馈网络不同于后来的经常性网络架构(RNN)(见下文),其中连接形成有向循环。
7. 经常性神经网络(RNN)
与上述前馈神经网络相比,递归神经网络的连接形成有向循环。这种双向流动允许使用内部的时间状态表示,这反过来又允许序列处理,并且提供了识别语音和手写的能力。
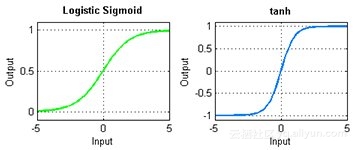
8. 激活函数
在神经网络中,激活函数通过组合网络的加权输入产生输出决策边界。激活函数的范围是从线性到sigmoid(逻辑)再到双曲线(相切)和超越。为了采用反向传播(见下文),网络中必须利用可区分的激活函数。
9. 反向传播
我曾经遇到过的最简洁、最基本的反向传播定义是数据科学家Mikio L. Braun 对Quora给出了以下答案:
BP只是个别错误的渐变下降,你可以将神经网络的预测与期望的输出进行比较,然后根据神经网络的权重计算误差的梯度。这将给你一个参数权重空间的方向,在这个空间中误差会变小。
10. 成本函数
在训练神经网络时,必须评估网络输出的正确性。由于我们知道训练数据的正确输出,所以可以比较训练的输出。成本函数衡量实际产出与训练产出之间的差异。实际产出和预期产出之间的零成本意味着网络一直在尽可能地进行训练,这显然是理想的。
那么,通过什么机制来调整成本函数,并将其最小化呢?
11. 梯度消失
梯度下降是一种用于寻找局部函数最小值的优化算法。尽管不能保证全局最小值,但梯度下降法对于精确求解或者难以求解的函数特别有用,例如将导数设置为零并求解。
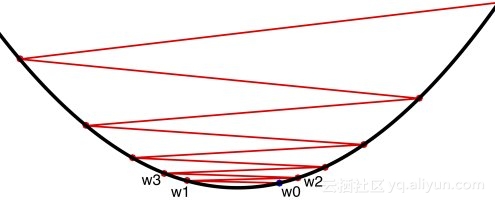
如上所述,在神经网络的情况下,随机梯度下降用于对网络参数做出明智的调整,目的是最小化成本函数,从而使网络的实际输出更接近于迭代地达到预期的输出。这种迭代最小化成本过程采用的是微积分,即微分。在训练步骤之后,网络权重根据成本函数的梯度和网络的当前权重来接收更新,以便下一个训练步骤的结果可能更接近正确(通过较小的成本函数测量)。反向传播(错误的后向传播)是用于将这些更新分发给网络的方法。
12. 消失渐变问题
反向传播使用链式规则来计算梯度,其中朝向n层神经网络的“前”(输入)的层将其小数更新的梯度值乘以n倍,然后将该稳定值用作更新。这意味着梯度将呈指数形式下降,这是一个n值较大的问题,而前面的层次需要越来越多的时间进行有效训练。
13. 卷积神经网络
通常与计算机视觉和图像识别相关联,卷积神经网络(CNN)采用卷积的数学概念来模拟生物视觉皮层的神经连接网格。
首先,如Denny Britz所描述的那样,卷积可以被认为是图像矩阵表示上的滑动窗口(参见下文)。
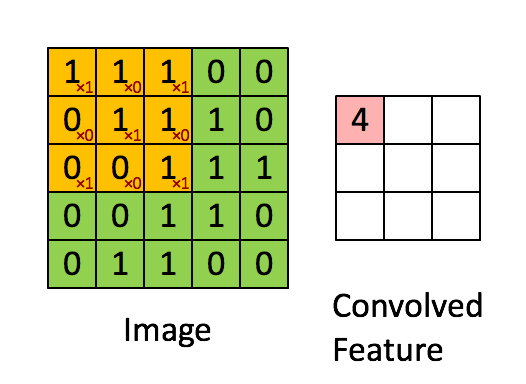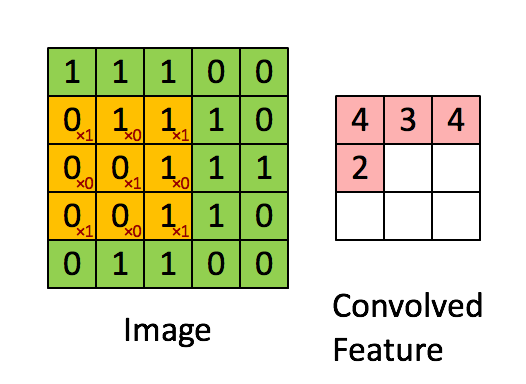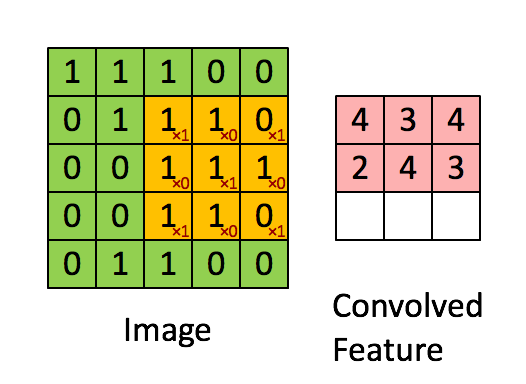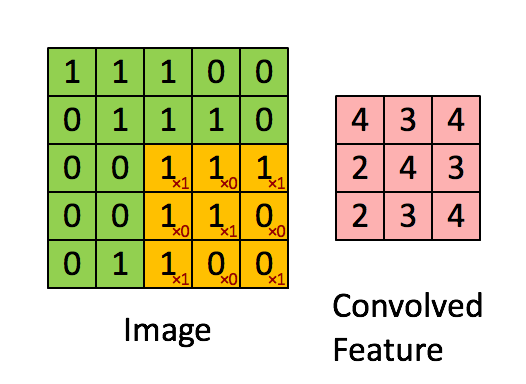
这个概念在神经网络结构中的实现导致神经元集合专用于处理图像部分,至少在计算机视觉中被使用时。在其他领域(如自然语言处理)中使用时,也可以使用相同的方法,因为输入(单词,句子等)可以排列在矩阵中并以类似的方式处理。
14. 长短期记忆网络(LSTM)
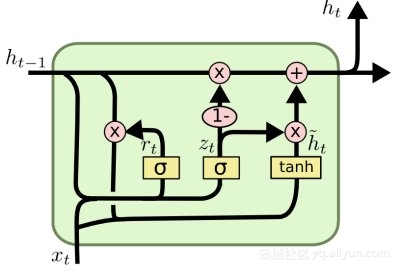
长短期记忆网络(LSTM)是一种经常性神经网络,它经过优化,可以从相关事件之间的时间相关数据中学习,这些数据可能具有未定义或未知的时间长度。他们特殊的架构允许持久性,给ANN带来“记忆”。LSTM网络最近在手写识别和自动语音识别方面取得了突破。
这只是深度学习术语的一小部分,并且随着你对机器学习研究了解,许多其他的概念正在等待你的探索。
本文由阿里云云栖社区组织翻译。
文章原标题《deep-learning-key-terms-explained》
作者:Matthew Mayo
译者:虎说八道,审校:。
文章为简译,更为详细的内容,请查看原文

