
- 1PyFlink核心知识点_pyflink richsourcefunction
- 23038. 相同分数的最大操作数目 I(Rust模拟击败100%Rust用户)
- 3Git——本地分支&远程分支_本地分支和远程分支
- 4OneDrive 遇到的坑--0x8004deed,目前的免费网盘分析
- 5嵌入式技术学习——c51——串口_c51 rs485tong
- 6瑞典保险公司百万客户数据泄露_保险公司用户数据泄露
- 7git的push以及遇到冲突解决_git push 冲突解决办法
- 8最强开源模型来了!一文详解 Stable Diffusion 3 Medium 特点及用法_sd3微调模型
- 9机器人操作系统ROS(十):机器人建模URDF_urdf机器人建模
- 10HarmonyOS开发案例:【音乐播放器】_鸿蒙开发音乐播放器
数据分析方法--回归分析方法((SPSS建模:多元线性回归案例)_spss多项式回归
赞
踩
回归定义
回归分析是一种预测性的建模技术,它研究的是因变量(目标)和自变量(预测器)之间的关系。这种技术通常用于预测分析,时间序列模型以及发现变量之间的因果关系。
使用曲线/线来拟合这些数据点,在这种方式下,从曲线或线到数据点的距离差异最小。
最常用回归方法
一、线性回归(Linear Regression)
线性回归通常是人们在学习预测模型时首选的技术之一。在这种技术中,因变量是连续的,自变量可以是连续的也可以是离散的,回归线的性质是线性的。线性回归使用最佳的拟合直线(也就是回归线)在因变量(Y)和一个或多个自变量(X)之间建立一种关系。
用一个方程式来表示它,即 Y=a+b*X + e,其中a表示截距,b 表示直线的斜率,e 是误差项。这个方程可以根据给定的预测变量(s)来预测目标变量的值。
使用最小二乘法得到一个最佳的拟合线,对于观测数据,它通过最小化每个数据点到线的垂直偏差平方和来计算最佳拟合线。因为在相加时,偏差先平方,所以正值和负值没有抵消。
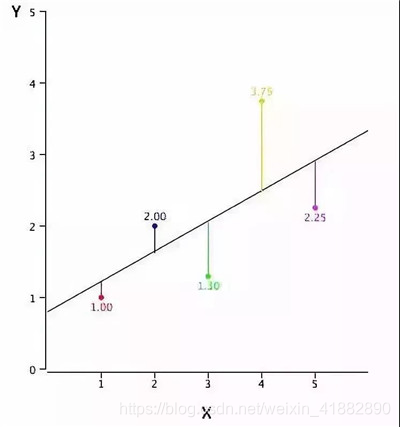
可以使用R-square指标来评估模型性能。
- 要点:
自变量与因变量之间必须有线性关系。
多元回归存在多重共线性,自相关性和异方差性。
线性回归对异常值非常敏感。它会严重影响回归线,最终影响预测值。
多重共线性会增加系数估计值的方差,使得在模型轻微变化下,估计非常敏感。结果就是系数估计值不稳定,在多个自变量的情况下,我们可以使用向前选择法,向后剔除法和逐步筛选法来选择最重要的自变量。
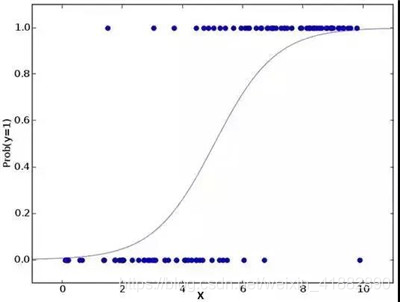
二、逻辑回归(Logistic Regression)
逻辑回归是用来计算「事件=Success」和「事件=Failure」的概率。当因变量的类型属于二元(1 / 0,真/假,是/否)变量时,我们就应该使用逻辑回归。这里,Y的值从0到1,它可以用下方程表示。
odds= p/ (1-p) = probability of event occurrence / probability of not event occurrence
ln(odds) = ln(p/(1-p))
logit§ = ln(p/(1-p)) = b0+b1X1+b2X2+b3X3…+bkXk
上述式子中,p表述具有某个特征的概率。你应该会问这样一个问题:我们为什么要在公式中使用对数log呢?
因为在这里我们使用的是的二项分布(因变量),我们需要选择一个对于这个分布最佳的连结函数。它就是Logit函数。在上述方程中,通过观测样本的极大似然估计值来选择参数,而不是最小化平方和误差(如在普通回归使用的)。
- 要点:
它广泛的用于分类问题。
逻辑回归不要求自变量和因变量是线性关系。它可以处理各种类型的关系,因为它对预测的相对风险指数OR使用了一个非线性的log转换。
为了避免过拟合和欠拟合,我们应该包括所有重要的变量。有一个很好的方法来确保这种情况,就是使用逐步筛选方法来估计逻辑回归。它需要大的样本量,因为在样本数量较少的情况下,极大似然估计的效果比普通的最小二乘法差。
自变量不应该相互关联的,即不具有多重共线性。然而,在分析和建模中,我们可以选择包含分类变量相互作用的影响。
如果因变量的值是定序变量,则称它为序逻辑回归;如果因变量是多类的话,则称它为多元逻辑回归。
三、多项式回归(Polynomial Regression)
对于一个回归方程,如果自变量的指数大于 1,那么它就是多项式回归方程。如下方程所示:y=a+b*x^2
在这种回归技术中,最佳拟合线不是直线。而是一个用于拟合数据点的曲线。
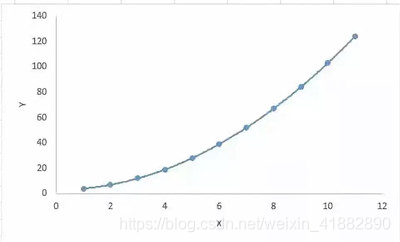
- 重点:
虽然会有一个诱导可以拟合一个高次多项式并得到较低的错误,但这可能会导致过拟合。你需要经常画出关系图来查看拟合情况,并且专注于保证拟合合理,既没有过拟合又没有欠拟合。
下面是一个图例,可以帮助理解:
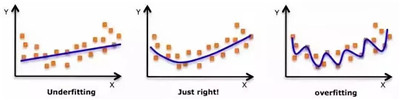
明显地向两端寻找曲线点,看看这些形状和趋势是否有意义。更高次的多项式最后可能产生怪异的推断结果。
四、逐步回归(Stepwise Regression)
在处理多个自变量时,我们可以使用这种形式的回归。在这种技术中,自变量的选择是在一个自动的过程中完成的,其中包括非人为操作。
这一壮举是通过观察统计的值,如 R-square,t-stats 和 AIC 指标,来识别重要的变量。逐步回归通过同时添加/删除基于指定标准的协变量来拟合模型。
- 最常用的逐步回归方法:
标准逐步回归法做两件事情。即增加和删除每个步骤所需的预测。
向前选择法从模型中最显著的预测开始,然后为每一步添加变量。
向后剔除法与模型的所有预测同时开始,然后在每一步消除最小显着性的变量。
这种建模技术的目的是使用最少的预测变量数来最大化预测能力。这也是处理高维数据集的方法之一。
五、岭回归(Ridge Regression)
岭回归分析是一种用于存在多重共线性(自变量高度相关)数据的技术。在多重共线性情况下,尽管最小二乘法(OLS)对每个变量很公平,但它们的差异很大,使得观测值偏移并远离真实值。岭回归通过给回归估计上增加一个偏差度,来降低标准误差。
上面,我们看到了线性回归方程。还记得吗?它可以表示为:y=a+ bx
这个方程也有一个误差项。完整的方程是:
y=a+bx+e (error term), [error term is the value needed to correct for a prediction error between the observed and predicted value]
=> y=a+y= a+ b1x1+ b2x2+…+e, for multiple independent variables.
在一个线性方程中,预测误差可以分解为2个子分量。一个是偏差,一个是方差。预测错误可能会由这两个分量或者这两个中的任何一个造成。在这里,我们将讨论由方差所造成的有关误差。
岭回归通过收缩参数 λ(lambda)解决多重共线性问题。看下面的公式:
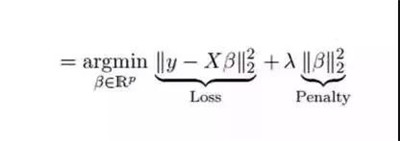
在这个公式中,有两个组成部分。第一个是最小二乘项,另一个是 β2(β-平方)的 λ 倍,其中 β 是相关系数。为了收缩参数把它添加到最小二乘项中以得到一个非常低的方差。
- 要点:
除常数项以外,这种回归的假设与最小二乘回归类似;它收缩了相关系数的值,但没有达到零,这表明它没有特征选择功能,这是一个正则化方法,并且使用的是L2正则化。
六、套索回归(Lasso Regression)
它类似于岭回归。Lasso (Least Absolute Shrinkage and Selection Operator)也会惩罚回归系数的绝对值大小。此外,它能够减少变化程度并提高线性回归模型的精度。看看下面的公式:
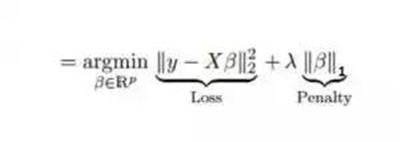
Lasso 回归与 Ridge 回归有一点不同,它使用的惩罚函数是绝对值,而不是平方。这导致惩罚(或等于约束估计的绝对值之和)值使一些参数估计结果等于零。使用惩罚值越大,进一步估计会使得缩小值趋近于零。这将导致我们要从给定的n个变量中选择变量。
- 要点:
除常数项以外,这种回归的假设与最小二乘回归类似;
它收缩系数接近零(等于零),确实有助于特征选择;
这是一个正则化方法,使用的是L1正则化;
如果预测的一组变量是高度相关的,Lasso 会选出其中一个变量并且将其它的收缩为零。
七、回归(ElasticNet)
ElasticNet 是 Lasso 和 Ridge 回归技术的混合体。它使用 L1 来训练并且 L2 优先作为正则化矩阵。当有多个相关的特征时,ElasticNet 是很有用的。Lasso 会随机挑选他们其中的一个,而 ElasticNet 则会选择两个。
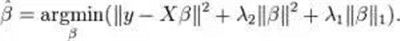
在高度相关变量的情况下,它会产生群体效应;选择变量的数目没有限制,它可以承受双重收缩。
除了这 7 个最常用的回归技术,你也可以看看其他模型,如 Bayesian、Ecological 和 Robust 回归。
如何正确选择回归模型?
在多类回归模型中,基于自变量和因变量的类型,数据的维数以及数据的其它基本特征的情况下,选择最合适的技术非常重要。以下是你要选择正确的回归模型的关键因素:
1.数据探索是构建预测模型的必然组成部分。在选择合适的模型时,比如识别变量的关系和影响时,它应该首选的一步。
2.比较适合于不同模型的优点,我们可以分析不同的指标参数,如统计意义的参数,R-square,Adjusted R-square,AIC,BIC 以及误差项,另一个是 Mallows’ Cp 准则。这个主要是通过将模型与所有可能的子模型进行对比(或谨慎选择他们),检查在你的模型中可能出现的偏差。
3.交叉验证是评估预测模型最好额方法。在这里,将你的数据集分成两份(一份做训练和一份做验证)。使用观测值和预测值之间的一个简单均方差来衡量你的预测精度。
4.如果你的数据集是多个混合变量,那么你就不应该选择自动模型选择方法,因为你应该不想在同一时间把所有变量放在同一个模型中。
5.它也将取决于你的目的。可能会出现这样的情况,一个不太强大的模型与具有高度统计学意义的模型相比,更易于实现。
6.回归正则化方法(Lasso,Ridge和ElasticNet)在高维和数据集变量之间多重共线性情况下运行良好。
新手可以按照这个逻辑选择:如果结果是连续的,就使用线性回归。如果是二元的,就使用逻辑回归!
SPSS实操
- SPSS 做因子分析,输出结果中有一项 Kaiser-Meyer-Olkin Measure of Sampling Adequacy. 它的值是在 [ 0, 1] 范围内,这个值大于 0.5 就证明原数据中的指标适合使用因子分析算法进行建模,小于 0.5 要不重新计算指标,要不换算法。SPSS 做多元线性回归,输出结果中的拟合度过低,说明指标与结果之间的相关性并不明显,要不重新计算指标,要不换算法。
- 多元线性回归分析理论详解及SPSS结果分析
第一步:导入数据
路径:【文件】–【打开】–【数据】–【更改文件类型,找到你的数据】–【打开】–【然后会蹦出下图左中的筛选框,基本使用默认值就行,点确定】
第二步:数据分析
【分析】–【回归】–【线性】–【将因变量与自变量添加到对应的地方】–【其他都使用默认值】–【确定】
第三步:结果分析
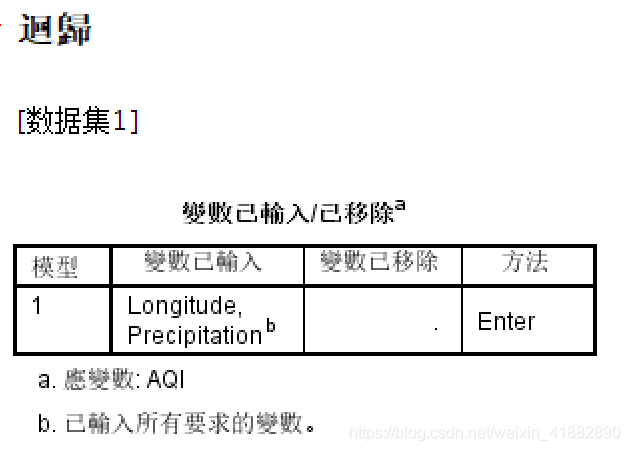
第一项输出结果:输入/移去的变量
第二项输出结果:模型汇总
1.R表示拟合优度(goodness of fit),用来衡量模型的拟合程度,越接近 1 越好;
2.R方表示决定系数,用于反映模型能够解释的方差占因变量方差的百分比,越接近 1 越好;
3.调整R方是考虑自变量之间的相互影响之后,对决定系数R方的校正,比R方更加严谨,越接近 1 越好;
4.标准估计的误差是误差项 ε 的方差 σ2的一个估计值,越小越好;
一般认为:
小效应:R (0.1~0.3),对应 R方(0.01~0.09);
中等效应:R (0.3~0.5),对应 R方(0.09~0.25);
大效应:R (0.5~1),对应 R方(0.25~1);

该例属中等效应,偏斜错误数值稍稍有点高。
第三项输出结果:变异数分析
Anova表示方差分析结果,主要看 F 和 显著性值,为方差分析的结果,F检验的重点在 显著性值,具体大小不重要,其 F 值对应的显著性值小于 0.05 就可以认为回归方程是有用的。
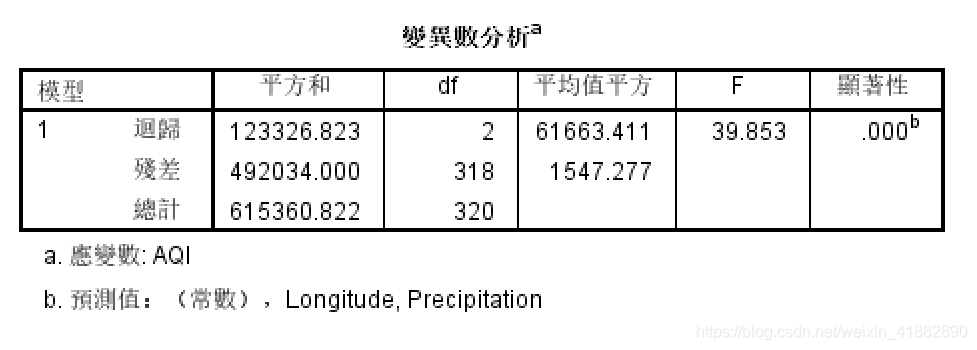
显著性值为0小于0.05,该方程可用。
第四项输出结果:系数
系数表列出了自变量的显著性检验结果,
- 非标准化系数中的 B 表示自变量的系数与常数项;
- 标准系数给出的自变量系数与非标准化系数中的明显不同,这是因为考虑到不同自变量之间的量纲和取值范围不同;
- t 值 与显著性值 是自变量的显著性检验结果,其 t 值对应的显著性 值小于 0.05 代表自变量对因变量具有显著影响,下图中,自变量Precipitation 对 因变量具有显著影响,而自变量Longitude的影响程度相对而言就弱了很多。
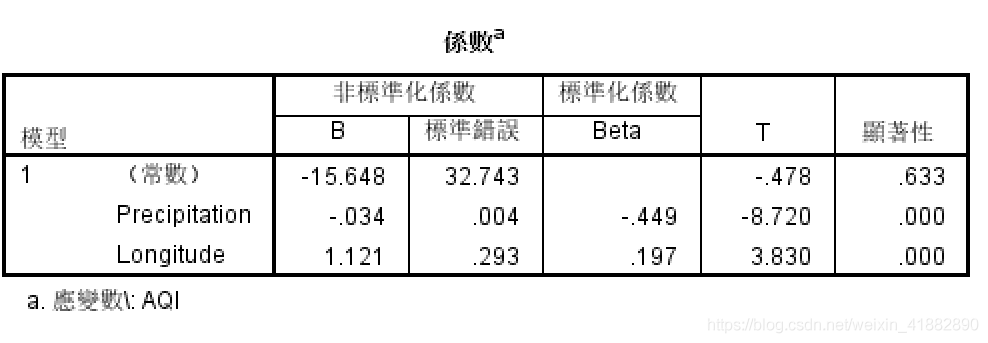
综上所有的输出结果,说明 AQI、Precipitation与Longitude 的拟合效果还挺理想的。
SPSS 给出的回归方程: Y = -15.6 -0.034 * Precipitation + 1.12 * Longitude

