
- 1nodejs连接mongodb数据库警告问题 {useNewUrlParser: true,useUnifiedTopology: true}
- 2Eureka的作用、搭建Eureka注册中心、服务注册及服务发现_eureka的作用是什么
- 3【区分vue2和vue3下的element UI InputNumber 计数器组件,分别详细介绍属性,事件,方法如何使用,并举例】_el-input-number 属性
- 4hadoop的优化之CentOS篇_centos对hadoop性能影响大吗
- 5oracle硬盘亮黄灯,RH2288H V3服务器硬盘亮黄灯故障处理案例
- 6云计算:未来的技术趋势与应用
- 7uniapp--新昵称头像自动填写_uniapp 昵称和头像的输入
- 8Harbor本地仓库搭建003_Harbor常见错误解决_以及各功能使用介绍_镜像推送和拉取---分布式云原生部署架构搭建003
- 9java 性能优化:35 个小细节,让你提升 java 代码的运行效率_java性能优化要注意哪些
- 10Burpsuite超详细安装教程_burpsuite安装教程
什么是向量数据库_向量知识库是什么意思
赞
踩
什么是向量数据库
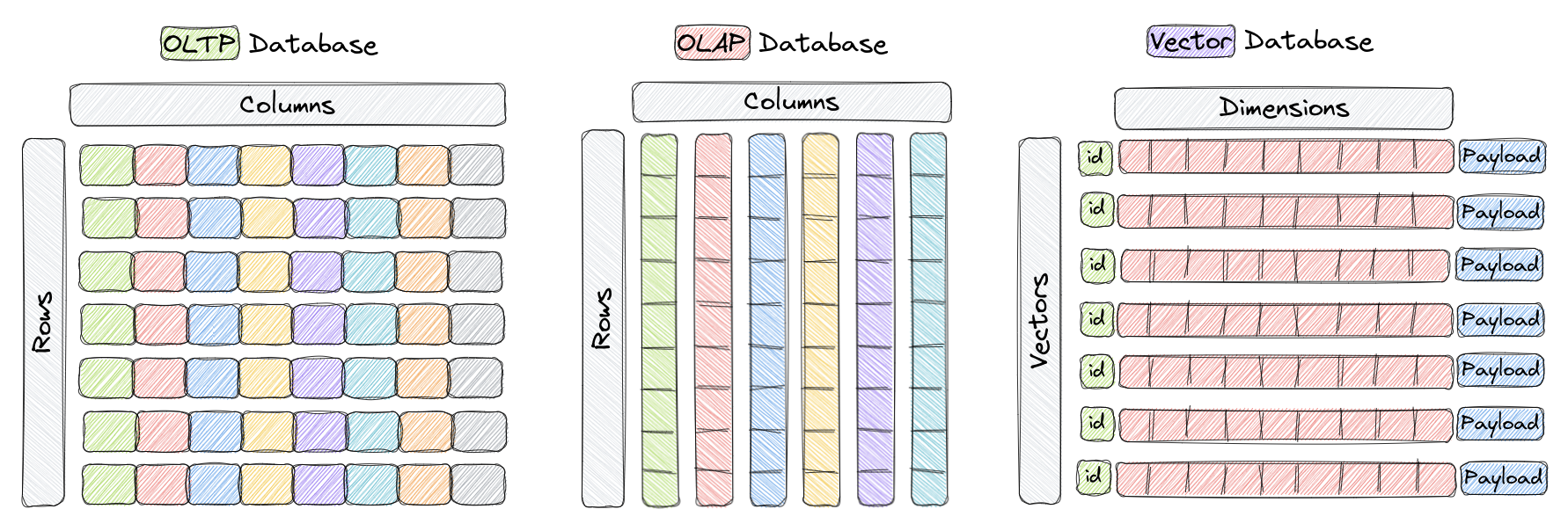
向量数据库是一种应用在高效存储和查询高维向量的数据库。在传统的OLTP和OLAP数据库中(如上图所示),数据按行和列组织(这些称为表),并根据这些列中的值执行查询。然而,在某些应用程序中,包括图像识别、自然语言处理和推荐系统,数据通常表示为高维空间中的向量,这些向量加上 id 和有效负载(Payload),组成我们存储在集合中的元素。
在搞清楚向量数据库之前,先需要知道什么是向量(vector)。
什么是向量
在AI领域中,向量是一个具有大小和方向的数学对象。它可以用来表示现实世界中的各种事物,例如图像、语音、文本等。
在机器学习和深度学习中,向量通常被用作表示数据的形式,其中每个向量的维度代表了不同的特征或属性。例如,在图像分类任务中,一个图像可以被表示为像素值组成的向量;在自然语言处理任务中,一句话可以被表示为单词嵌入(word embeddings)组成的向量。通过对这些向量进行计算和比较,机器可以从数据中提取出有用的信息,如相似性、聚类等。
比如人脸识别技术,计算机从照片或视频中提取出人脸的图像,然后将人脸图像转换为128维或者更高维度的向量。说到向量,就离不开embeddings。下面说下embeddings是什么。
什么是embeddings
embeddings是一个相对低维度的空间,可以将高维向量转换为低维度。embeddings使得机器学习更加高效,例如表示单词的稀疏向量。最理想的情况是,embeddings能够通过将语义上相似的输入放置在embeddings空间中,通过彼此靠近的向量来捕获输入的某些语义。可以在不同的模型中学习和重复使用嵌入。
什么是向量检索
向量搜索是一种使用机器学习模型在索引中检测对象间语义关系的方法,以找到具有相似特征的相关对象。
如果你想在你的网站上添加自然语言文本搜索、创建图像搜索或构建强大的推荐系统,那么你就需要考虑使用向量技术。
为什么需要向量数据库
上面的一些概念解释了之后,其实在 AI 领域中,向量数据库是为了更高效地存储和检索大规模高维度的向量数据而设计的。由于传统的数据库系统并不擅长处理向量数据,因此需要专门的向量数据库来支持各种应用场景,例如语义搜索、图像检索、推荐系统等。
与传统数据库不同,向量数据库可以使用特殊的索引结构和相似度度量方法,在高维度向量空间中快速查找相似的向量。例如,一些流行的向量数据库使用基于倒排索引和最邻近搜索(Approximate Nearest Neighbor Search)的技术,极大地加快了向量数据的查询速度。
向量数据库还提供了方便的 API 接口和工具库,使得用户可以轻松地将其集成到自己的应用程序中,并进行快速的向量搜索。因此,在许多需要处理大规模向量数据的 AI 应用中,向量数据库成为了不可或缺的组件。
接下来我们来看看怎么简单快速的入门向量数据库~

