
- 1MySQL Online DDL原理解读_algorithm=inplace, lock=none; 在线ddl原理
- 2Pycharm安装pyqt5以及创建一个GUI界面_pycharm pygui
- 3如何配合使用Perforce Helix Core与虚幻引擎4(UE4)_ue4什么时候发布的
- 4MySQL Online DDL 方案剖析
- 5【NLP】使用 Keras 保存和加载深度学习模型_keras加载模型
- 6ROS2探索(二)executor_rclcpp::executors::multithreadedexecutor
- 7Android 快速发布开源项目到jcenter_将android工程上传到jcenter仓库
- 8redis的常用命令及使用特点_列举5个redis服务器端常用命令及作用
- 9讯飞AI接入微信公众号_网站接入讯飞ai
- 10web安全渗透漏洞检测表_系统漏洞检查表
LLaMA:开放高效的基础语言模型_llama 数据配比
赞
踩
论文:https://arxiv.org/abs/2302.13971
Github:https://github.com/facebookresearch/llama
一、导言
本文介绍了LLaMA,这是一个包含从7B到65B大小的模型的集合。本文在万亿个Tokens上训练了模型,并且在不使用任何私有数据集的情况下达到了较好的效果。特别地,在绝大多数榜单上,LLaMA-13B模型的效果超过了GPT3(175B),LLaMA- 65B的效果与Chinchilla-70B、PaLM-540B具有可比性。
亮点:本文的主要亮点在于训练数据完全来源于公开数据集,具有可复制性;同时Meta AI将该模型进行开源,用于科研。
二、方法
LLaMA采用的模型架构与GPT系列一样,也是Decoder only架构,并借鉴了缩放定律。
2.1 预训练数据
本文采用的预训练数据采样配比如下,均为公开的数据源,部分数据在别的LLM模型中出现过。
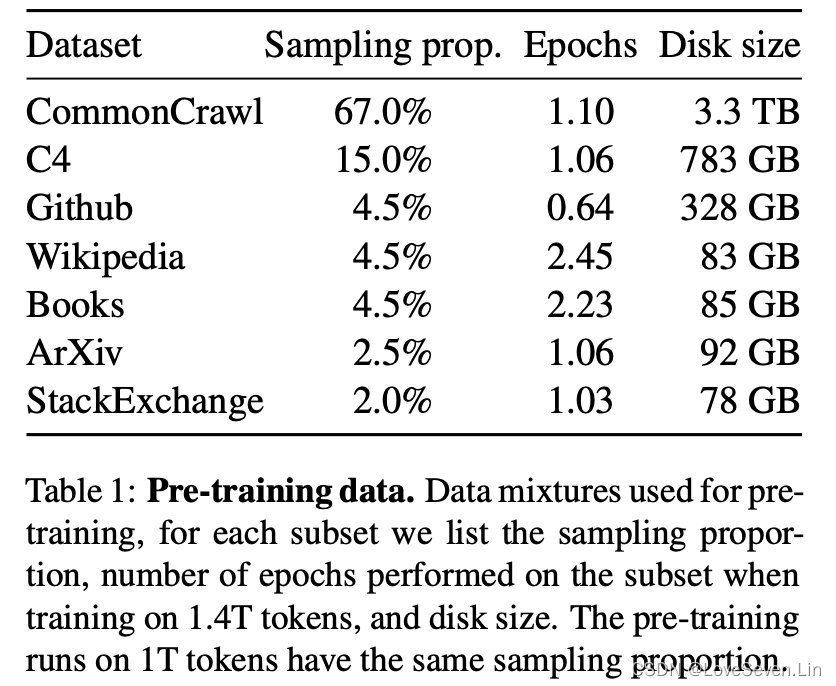
English CommonCrawl [67%]
本文采用CCNet pipeline (Wenzek et al., 2020)预处理五个CommonCrawl,范围从2017年到2020年,这个过程在行层面对数据进行了删除。本文训练了一个fastText线性分类器来移除非英语页面,并采用n-gram语言模型过了低质量的内容。此外,本文训练了一个线性分类器来对维基百科中用作参考的页面和随机抽取的页面进行分类,丢掉了未用作参考的页面。
C4 [15%]
经过探索性实验,本文发现多样化预处理的CommonCrawl数据集能提升模型表现,因此把C4数据集纳入本文的数据。C4数据集的预处理主要包括去重和语言识别步骤:跟CCNet主要的不同是质量过滤,这里主要依赖启发式算法,包括在一个页面中标点符号的存在或者单词和句子的数目。
Github [4.5%]
本文采用谷歌BigQuery上公开的Github数据集。本文只保留在Apache, BSD和MIT许可下发布的项目。利用基于行长、字符比例的启发式算法过滤低质量文件,并利用正则表达式的方法删除模版,如headers。最后,在文件层面去重。
Wikipedia [4.5%]
我们添加了2022年6月至8月的维基百科数据,涵盖20种语言,这些语言使用了拉丁文或者西里尔字母。我们移除了超链接、评论和其他格式化模板。
Gutenberg and Books3 [4.5%]
我们包含了两个书本库,Gutenberg和Books3,我们在书本层面进行了去重,移除了重叠超过90%内容的书本。
ArXiv [2.5%]
我们处理arXiv的Latex文件,将科学数据添加到数据集。删除了第一节的内容以及书目。还删除了.tex文件中的注释,以及用户写的定义和宏,以提高不同论文的一致性。
Stack Exchange [2%]
我们导出Stack Exchange的数据,这是一个高质量的网页覆盖了从计算机科学到化学的问答。我们保留了28个最大的网站,去掉了文中HTML标签,并按分数从高到低排序。
Tokenizer
采用BPE编码。将数字分割成单个数字,并退回字符来分解位置的UTF-8字符。
最后我们总共得到1.4T个tokens,除了Wikipedia和Books,其他数据只使用一次,在上main训练了2个epoch。
2.2 架构
下面主要讲本文模型架构的不同和灵感来源。
Pre-normalization [GPT3]
为了提升训练的稳定性,在每个Transformer子层的输入采用了归一化,而不是对输出进行归一化。采用RMSNorm归一化函数。
SwiGLU activation function [PaLM]
采用SwiGLU代替ReLU,并将PaLM中的4d维度替换为2/3*4d。
Rotary Embeddings [GPTNeo]
删除绝对位置嵌入,采用旋转位置嵌入(RoPE)。
超参数如下:
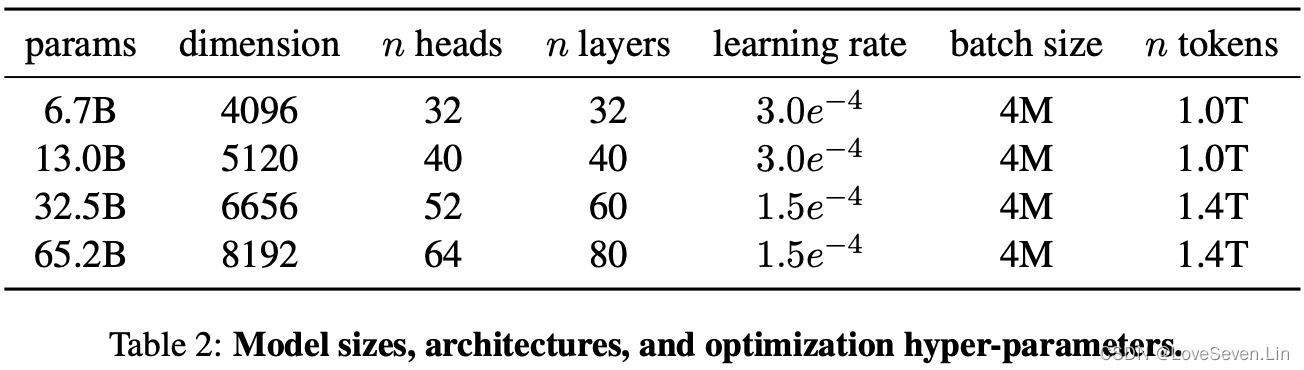
2.3 Optimizer

2.4 高效措施
1. 采用因果多头注意力算子来减少内存使用和耗时,它通过不存储注意力权重和不计算由于语言模型任务的因果性质而被遮盖的key/query分数而实现;
2. 减少方向传递中重新计算的激活量。
三、主要结果
比较Zero-shot和Few-shot的结果。
Zero-shot:提供任务的文字描述和一个测试案例,模型开放式生成答案或对提议进行排名;
Few-shot:提供任务的几个例子。
我们将LLaMA与其他基础模型进行比较:
3.1 常识推理
在常识推理八个数据集上进行zero-shot的测试,效果如下:
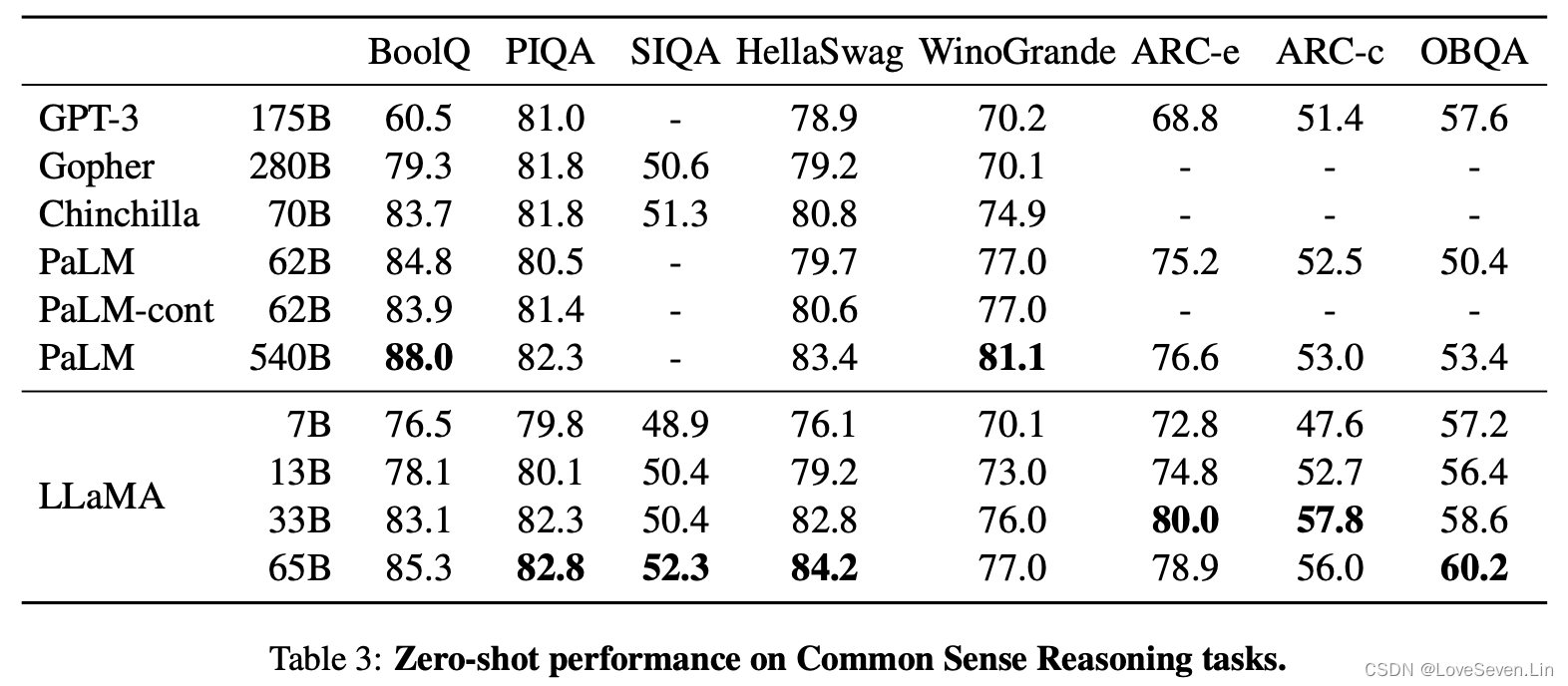
除了在BoolQ和WinoGrande数据集上PaLM比LLaMA好,其他数据集上LLaMA的表现较好。LLaMA-13B在大多数的基准上都超过了GPT3,虽然参数量只有后者的10分之一。
3.2 闭卷问答
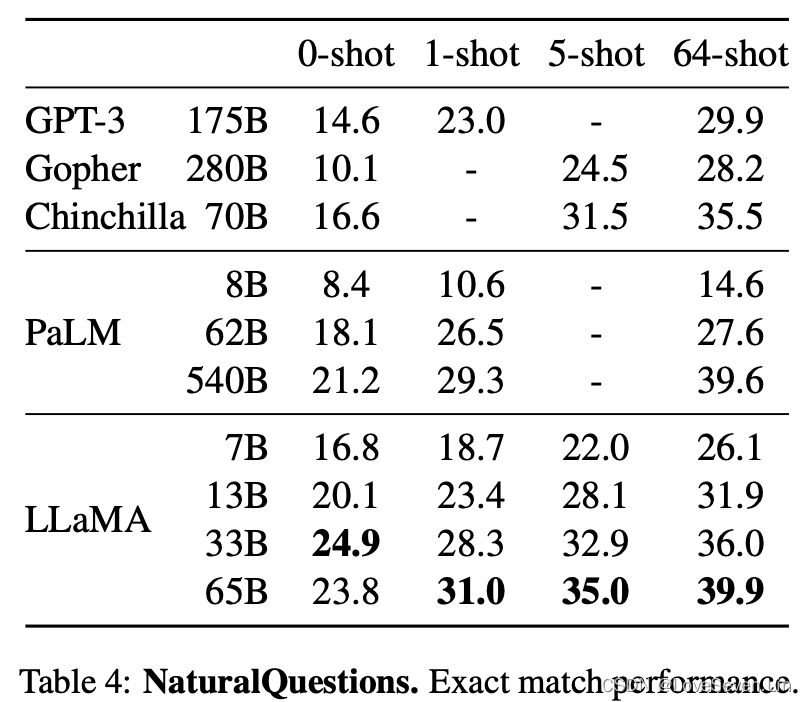
模型在Natural Questions和TriviaQA上的表现如下:
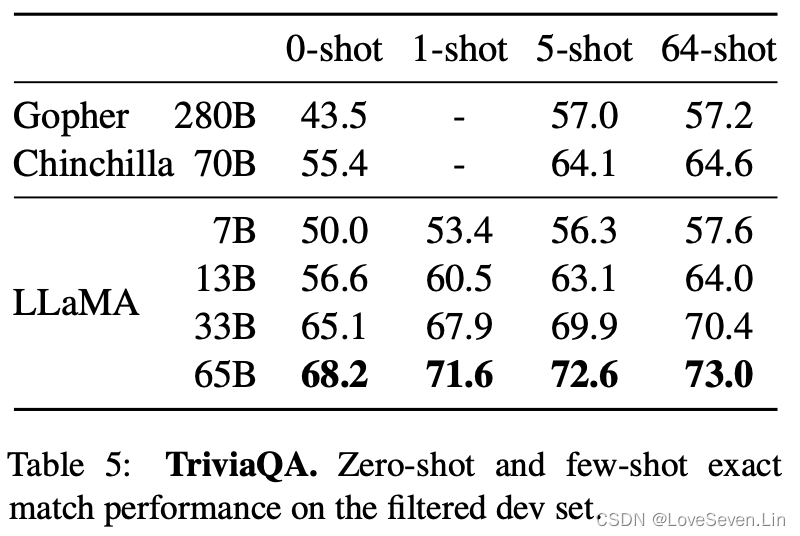
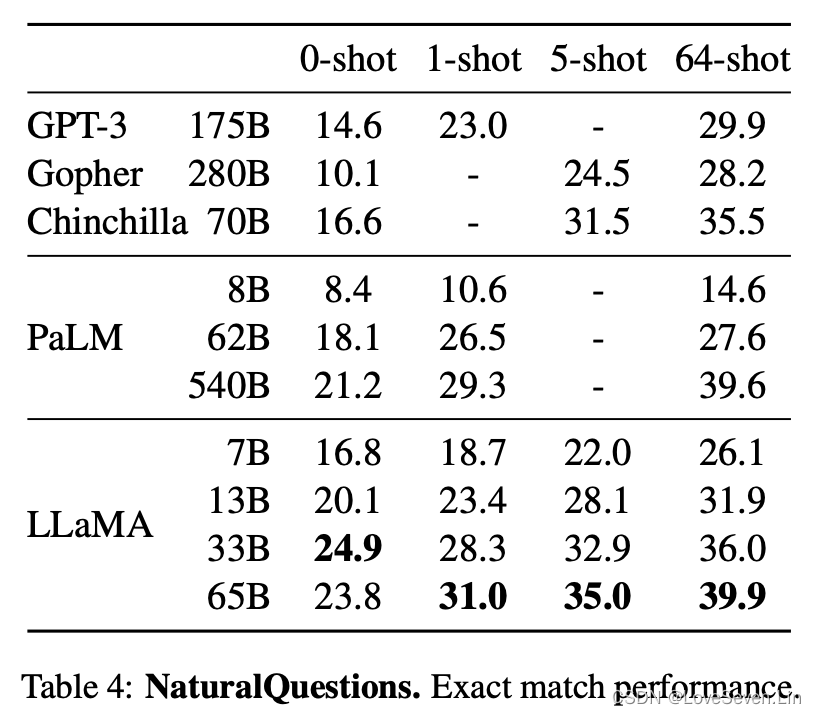 LLaMA在两个数据集上的zero shot和few shot都取得了最好的效果;并且LLaMA-13B在两个数据集上的效果与GPT3和Chinchilla相当,虽然参数量只有后者的5-10分之一。
LLaMA在两个数据集上的zero shot和few shot都取得了最好的效果;并且LLaMA-13B在两个数据集上的效果与GPT3和Chinchilla相当,虽然参数量只有后者的5-10分之一。
3.3 阅读理解
模型在RACE数据集上的效果展示如下:
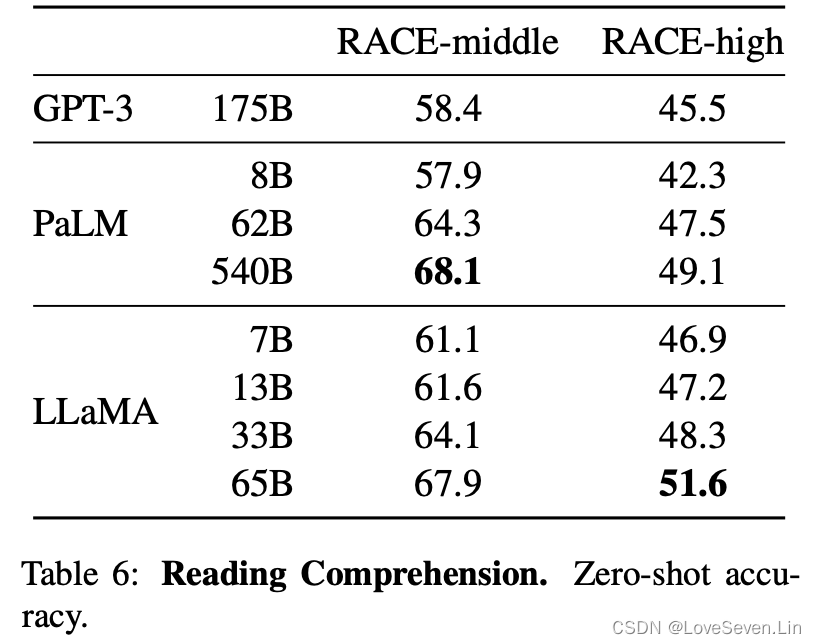
在这个基准上,LLaMA-65与PaLM表现不相上下,LLaMA-13B的表现略优于GPT3。
3.4 数学推理
我们在MATH和GSM8K数据集上测试模型数学推理的效果。MATH是12K用Latex写的初中和高中数学问题;GSM8K是中学数学题。模型效果如下:
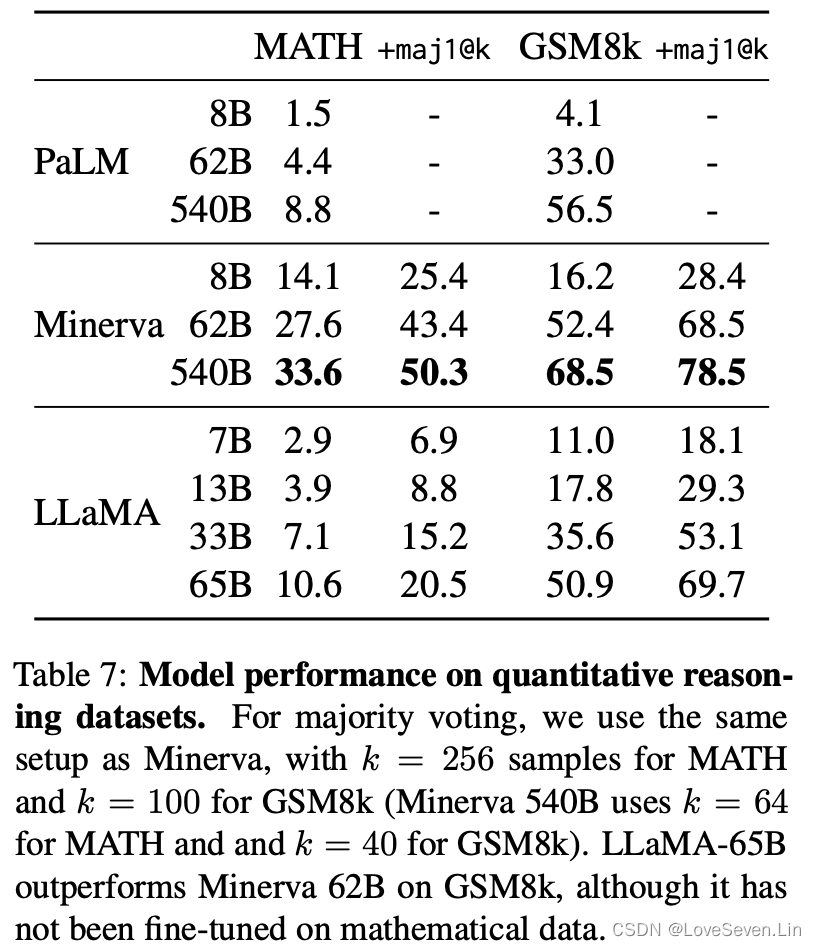
Minerva系列模型是PaLM在38.5B来自arXiv和MATH数学网页上提取的tokens上训练得到的模型。maj1@k是模型生成k个样本,然后进行投票表决。从效果上看,在GSM8K数据集上,LLaMA-65B比Minerva-62B效果要好,即使LLaMA-65B没有在相应数据上进行过微调。
3.5 代码生成
在HumanEval和MBPP上测试了模型效果,效果如下:
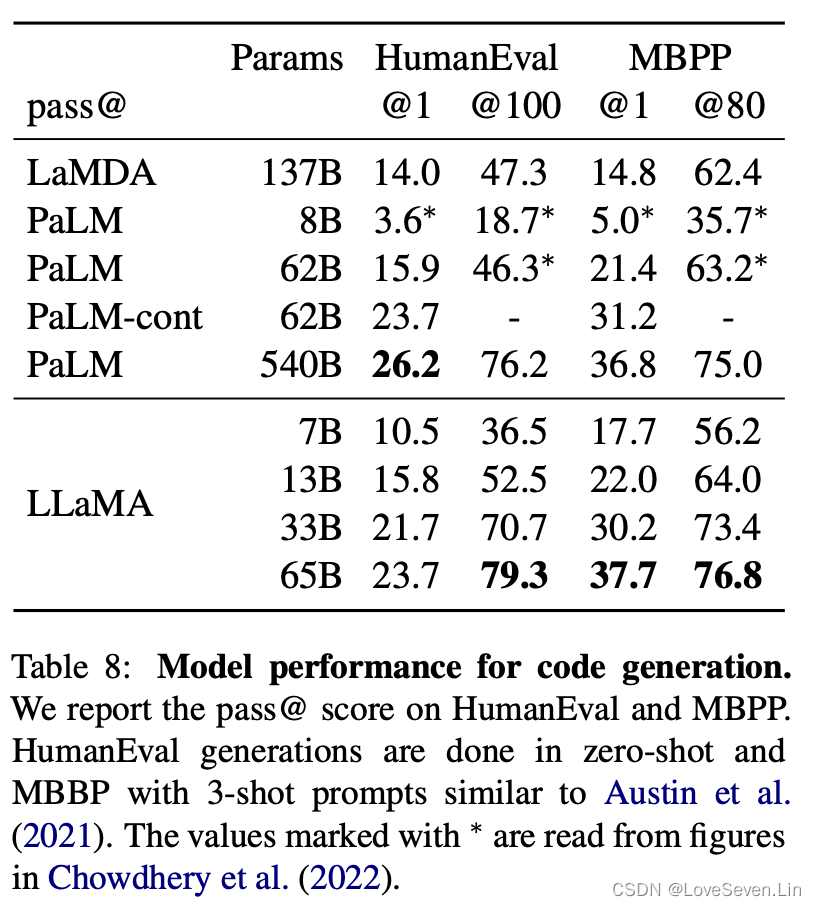
其中,LaMDA是未在代码上进行微调的模型。可以看到LLaMA-65B的效果最好。从中也可看到,经过代码微调的模型在效果上会有大的提升。
3.6 海量多任务语言理解(MMLU)
MMLU是选择题构成的数据集,包括humanities, STEM, social sciences和Other四类。
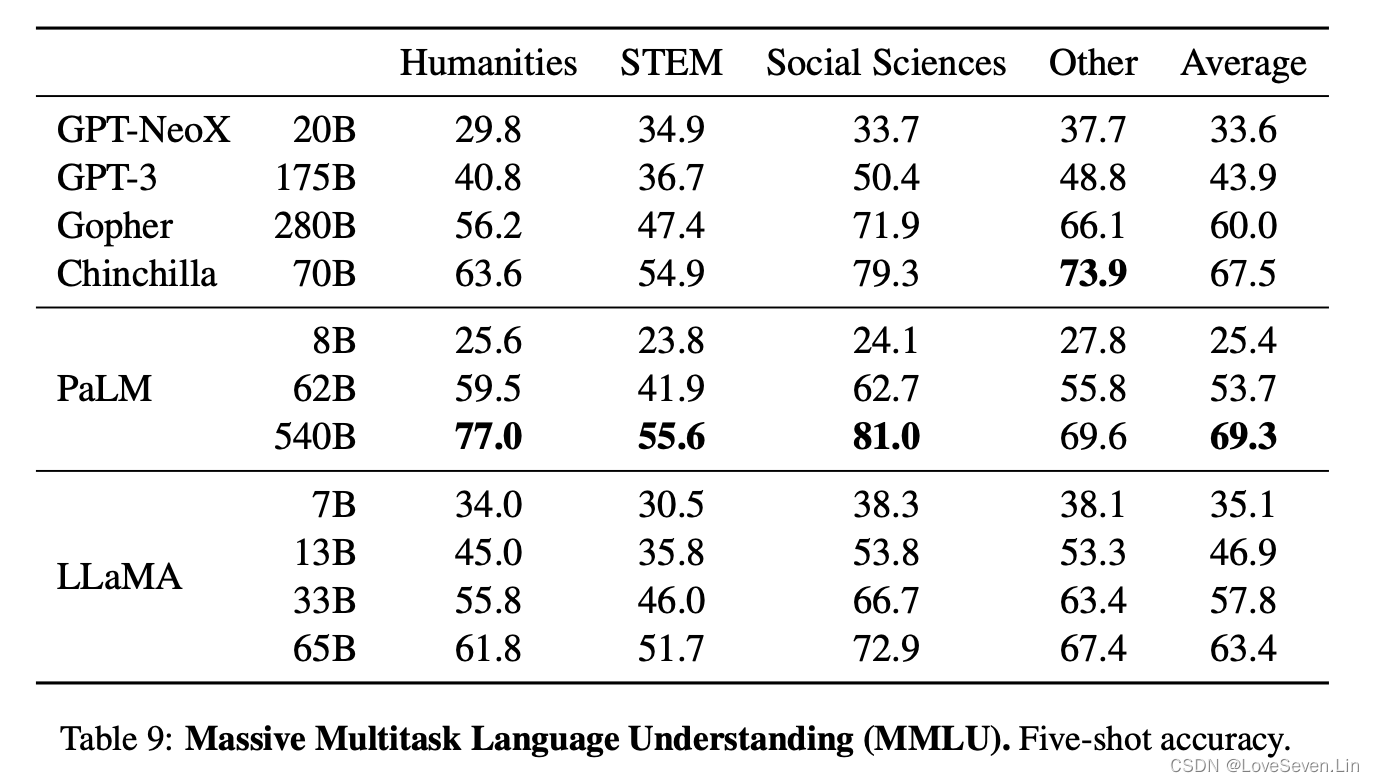
从效果来看,LLaMA-65B的效果不如PaLM-540B和Chinchilla-70B,原因可能是LLaMA在预训练中使用的书籍和学术数据太少,ArXiv, Gutenberg和Books3加起来才177GB,而其他两个模型使用超过2TB的书籍。
3.7 训练期间的演变
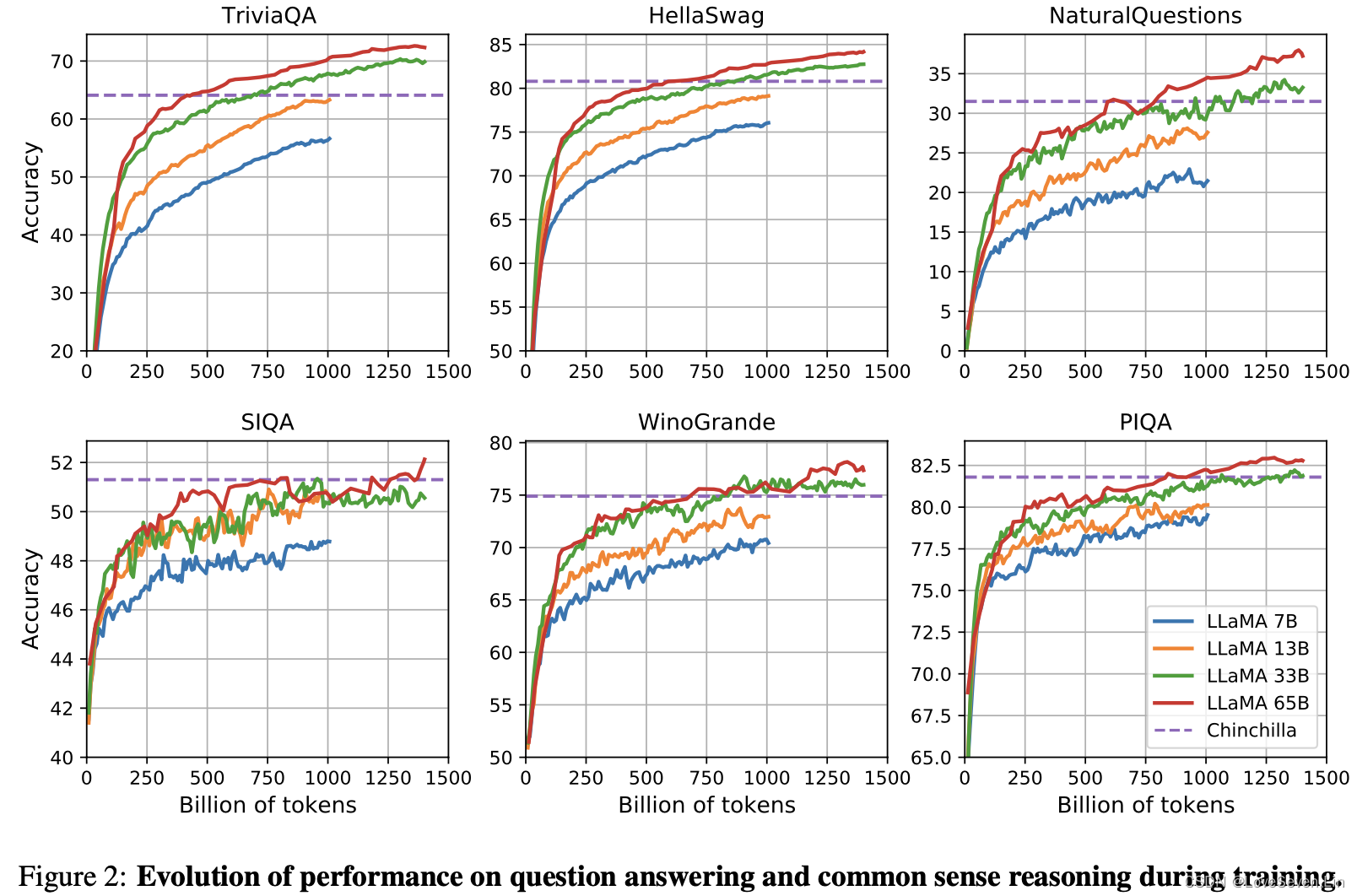
通过训练期间的变化观察到,除了SIQA和WinoGrande以外,其他基准在训练过程中会随着tokens数目的增加不断提升。但在SIQA上,随着训练的进行,模型在该基准上的表现反而变差了,可能表示该基准是不可靠的;在WinoGrande上,模型效果并未与训练困惑度呈现正相关。
四、指令微调
本文按照Chung et al. (2022)的协议在LLaMA上进行了指令微调,得到LLaMA-I,效果如下:
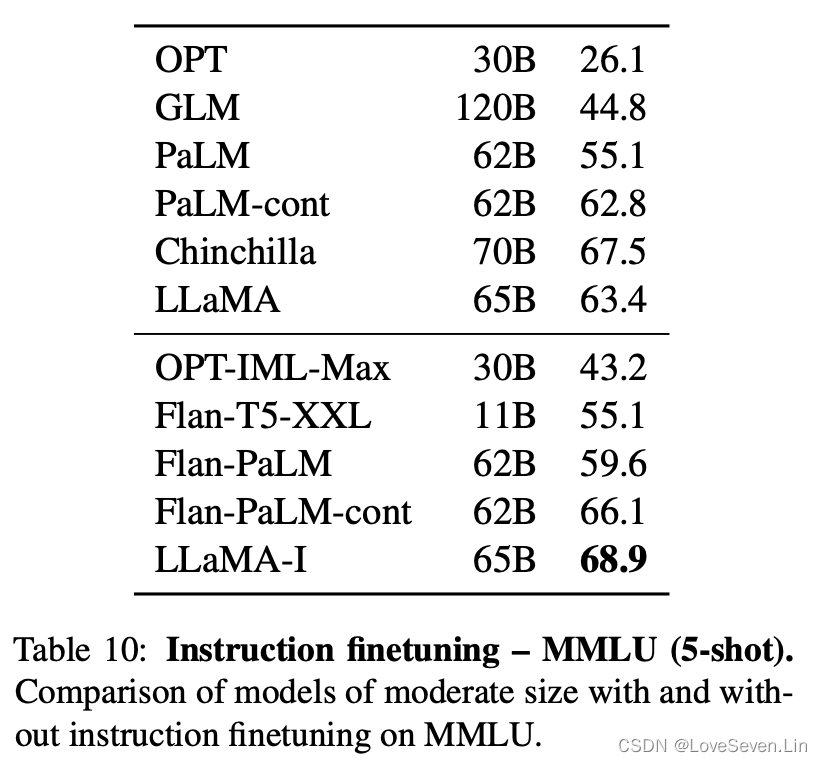
可以看到,少量的指令微调能够显著提升模型在MMLU上的表现,但距离GPT code-davinci-002的77.4的分数还是差距较大。
五、偏见、毒性和错误信息
大模型已经被证明可以重现或放大数据中的偏见,产生有毒或者令人反感的信息,由于本模型的训练数据大部分都来自网络,因此需要了解LLaMA的潜在危害,需要对大模型进行评估。
5.1 RealToxicityPrompts
大模型可以生成侮辱、仇恨言论或威胁。由于模型生成的有毒内容覆盖范围广,这使得全面评估具有挑战性。RealToxicityPrompts包含模型必须完成的100k条提示,然后通过向PerspectiveAPI发出请求自动评估得分,由于无法控制第三方,因此没法同之前的模型进行比较。LLaMA系列模型在该基准上的得分如下:
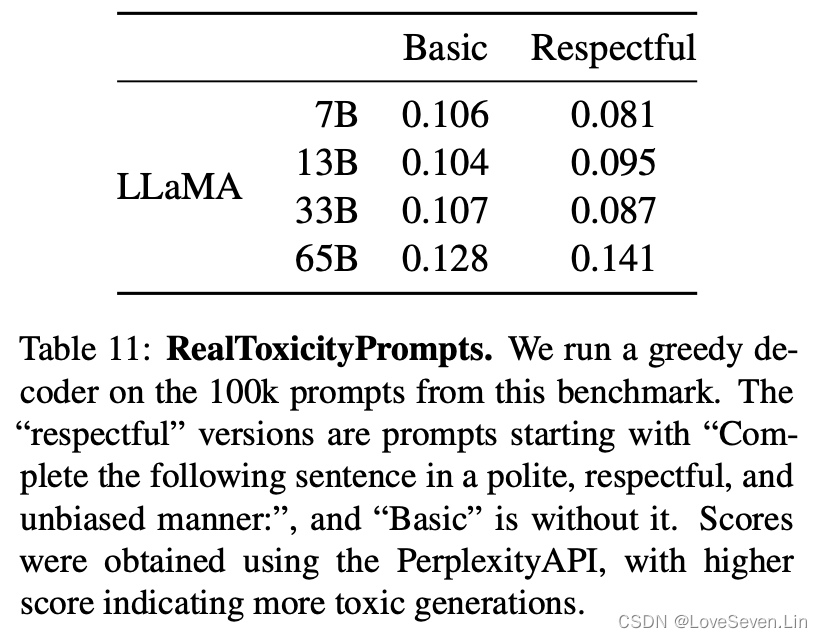
从模型效果看,模型生成有害信息随着随着模型规模的增大而增加,因此在同一家族的模型中,必须在模型规模和模型生成信息的有毒性之间做一个权衡。
5.2 CrowS-Pairs
我们在CrowS-Pairs上评估模型的偏见,分数越高代表生成的偏见越严重。
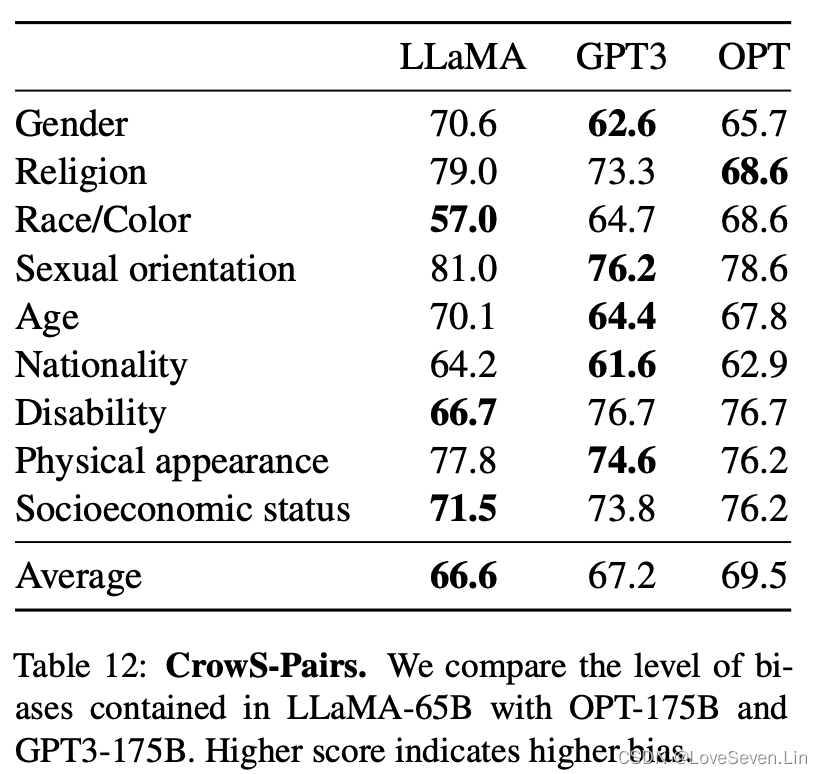
从模型效果看,LLaMA模型的平均得分最低,偏见程度最低。但细分到个别类别,在宗教类别中,LLaMA的分数远比OPT要高,随后是年龄和性别,我们推测这些偏见来自CommonCrawl,即使是经过了多轮的过滤。
5.3 WinoGender
为了继续研究模型的偏见问题,我们在WinoGender上继续研究性别类别上的偏差。WinoGender目的是看模型是否能捕捉到与职业相关的性别偏见。我们评估了三个代词时的表现:he/his/him, she/her/her, they/their/them。
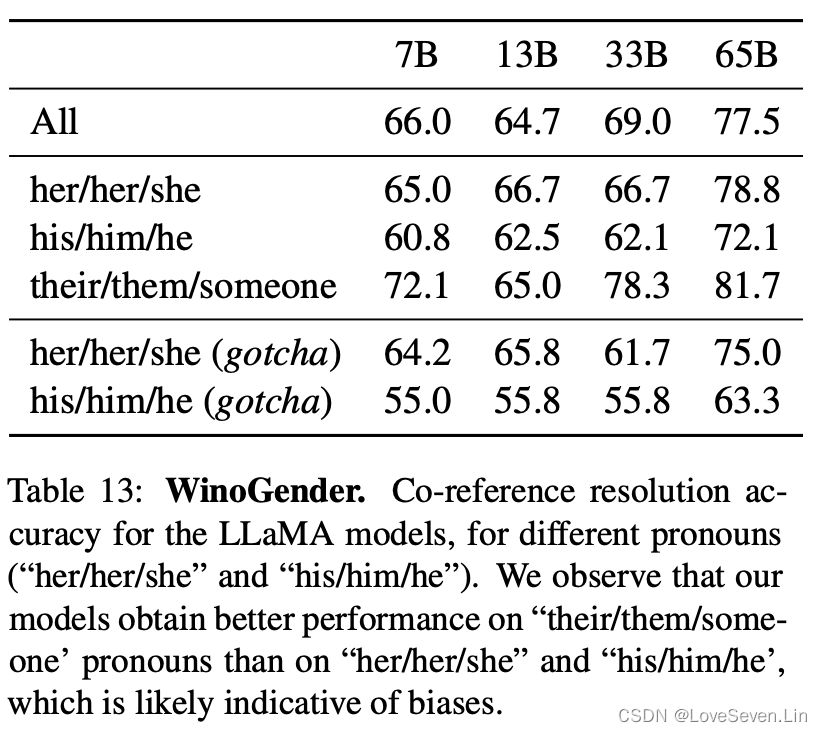
从结果上看,模型在they/their/them上的表现好于其他两个,表示模型可能存在性别上的偏见。
5.4 TruthfulQA
为了评测模型的真实性,Lin et al. (2021)关于“真实”的定义是指在真实世界的正确,而不是仅在信仰体系或传统背景下才正确的主张。
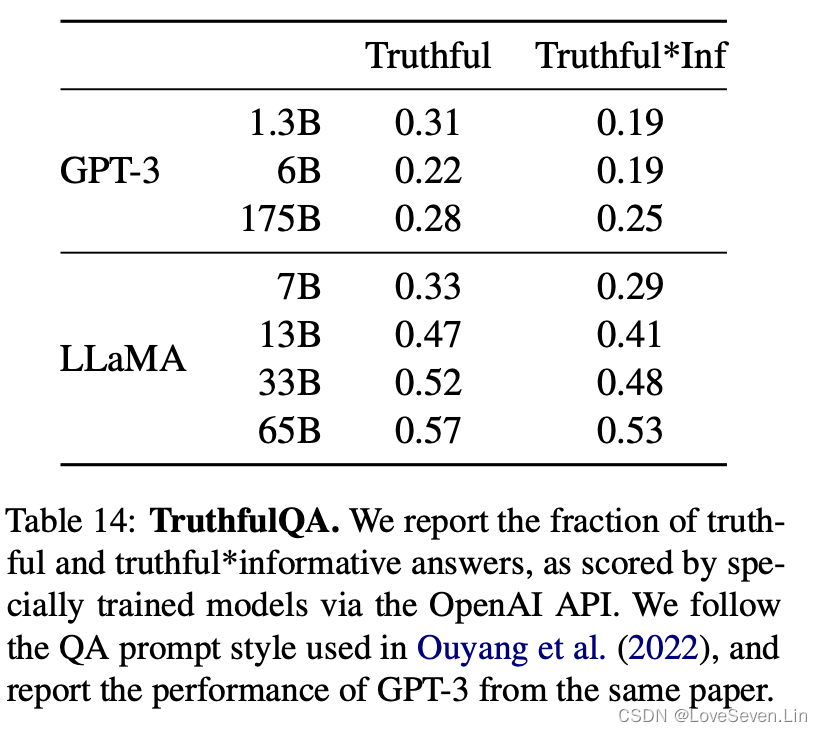
从模型效果来看,LLaMA模型的效果显著好于GPT3,但是正确率仍然较低,证明模型仍然会产生幻觉。

