
- 1java登录界面 sql数据库_JavaWeb连接SQLServer数据库并完成一个登录界面及其功能设计。...
- 2三次握手和四次挥手机制_4次握手机制是什么
- 3嵌入式开发(S5PV210)——u-boot中如何确定启动方式_uboot判断芯片启动方式
- 4PyCharm使用教程(mac版教程)_mac pycharm使用教程
- 5鸿蒙(HarmonyOS)项目方舟框架(ArkUI)之MenuItem组件
- 6pip 升级包到指定版本和安装指定版本的包(转)_pip install --upgrade keras 只安装到了2.14.0
- 7执行任务Ubuntu使用crontab定时任务
- 8【Oracle 集群】RAC知识图文详细教程(三)--RAC工作原理和相关组件_oracle rac 支持用户会话故障自动切换
- 9python笔记(Django 基于中间件的权限管理,权限粒度控制)
- 10opencv-yolov8-目标检测_yolov8视频流目标检测
PiflowX新增Apache Beam引擎支持
赞
踩
参考资料:
Apache Beam 架构原理及应用实践-腾讯云开发者社区-腾讯云 (tencent.com)
在之前的文章中有介绍过,PiflowX是支持spark和flink计算引擎,其架构图如下所示:
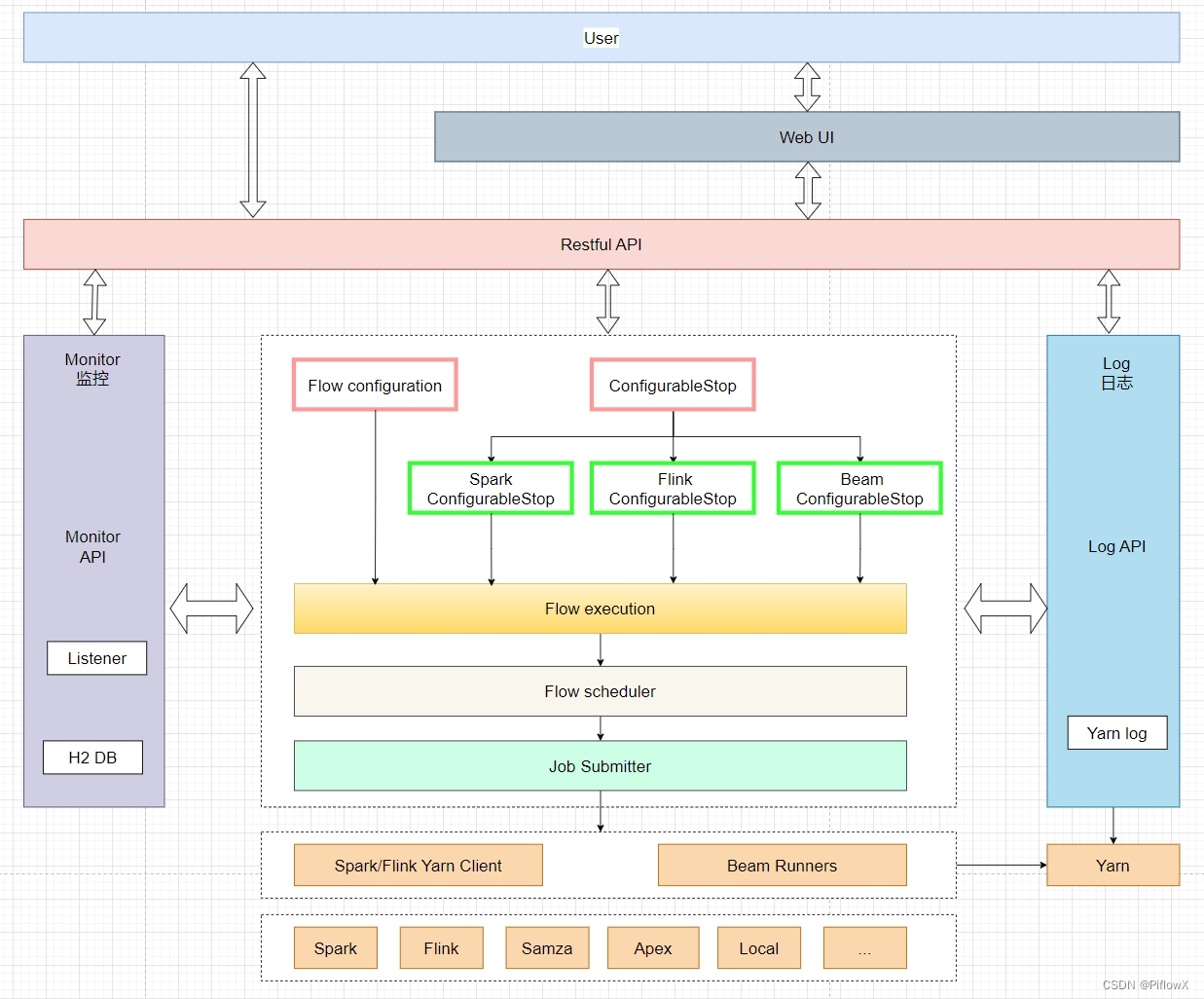
在piflow高度抽象的流水线组件的支持下,我们可以很轻松的扩展计算引擎的支持,比如spark和flink,当然还可以是apache beam。
什么是Apache Beam
Apache Beam 架构原理及应用实践-腾讯云开发者社区-腾讯云 (tencent.com)

大数据起源于 Google 2003年发布的三篇论文 GoogleFS、MapReduce、BigTable 史称三驾马车,可惜 Google 在发布论文后并没有公布其源码,但是 Apache 开源社区蓬勃发展,先后出现了 Hadoop,Spark,Apache Flink 等产品,而 Google 内部则使用着闭源的 BigTable、Spanner、Millwheel。这次 Google 没有发一篇论文后便销声匿迹,2016年2月 Google 宣布 Google DataFlow 贡献给 Apache 基金会孵化,成为 Apache 的一个顶级开源项目。然后就出现了 Apache Beam,这次不它不是发论文发出来的,而是谷歌开源出来的。2017年5月17日 发布了第一个稳定版本2.0。
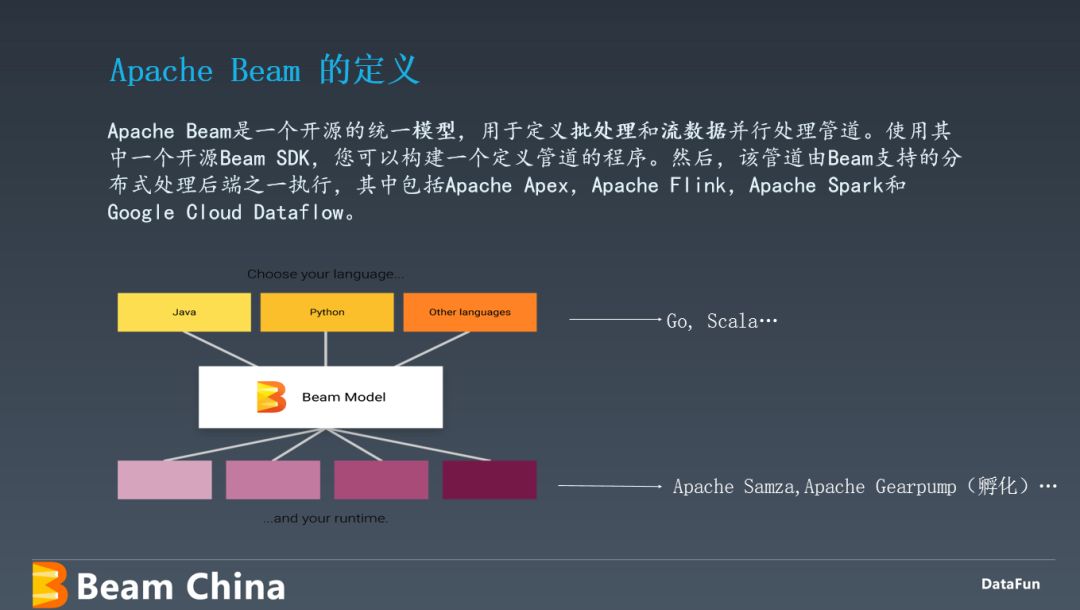
Apache Beam 的定义如上图,其定位是做一个统一前后端的模型。其中,管道处理和逻辑处理是自己的,数据源和执行引擎则来自第三方。那么,Apache Beam 有哪些好处呢?

① 统一数据源,现在已经接入的 java 语言的数据源有34种,正在接入的有7种。Python 的13种。这是部分的数据源 logo,还有一些未写上的,以及正在集成的数据源。基本涵盖了整个 IT 界每个时代的数据源,数据库。

② 统一编程模型,Beam 统一了流和批,抽象出统一的 API 接口。

③ 统一大数据引擎,现在支持性最好的是 flink,spark,dataflow 还有其它的大数据引擎接入进来。
等等。。。。。。
PiflowX新架构
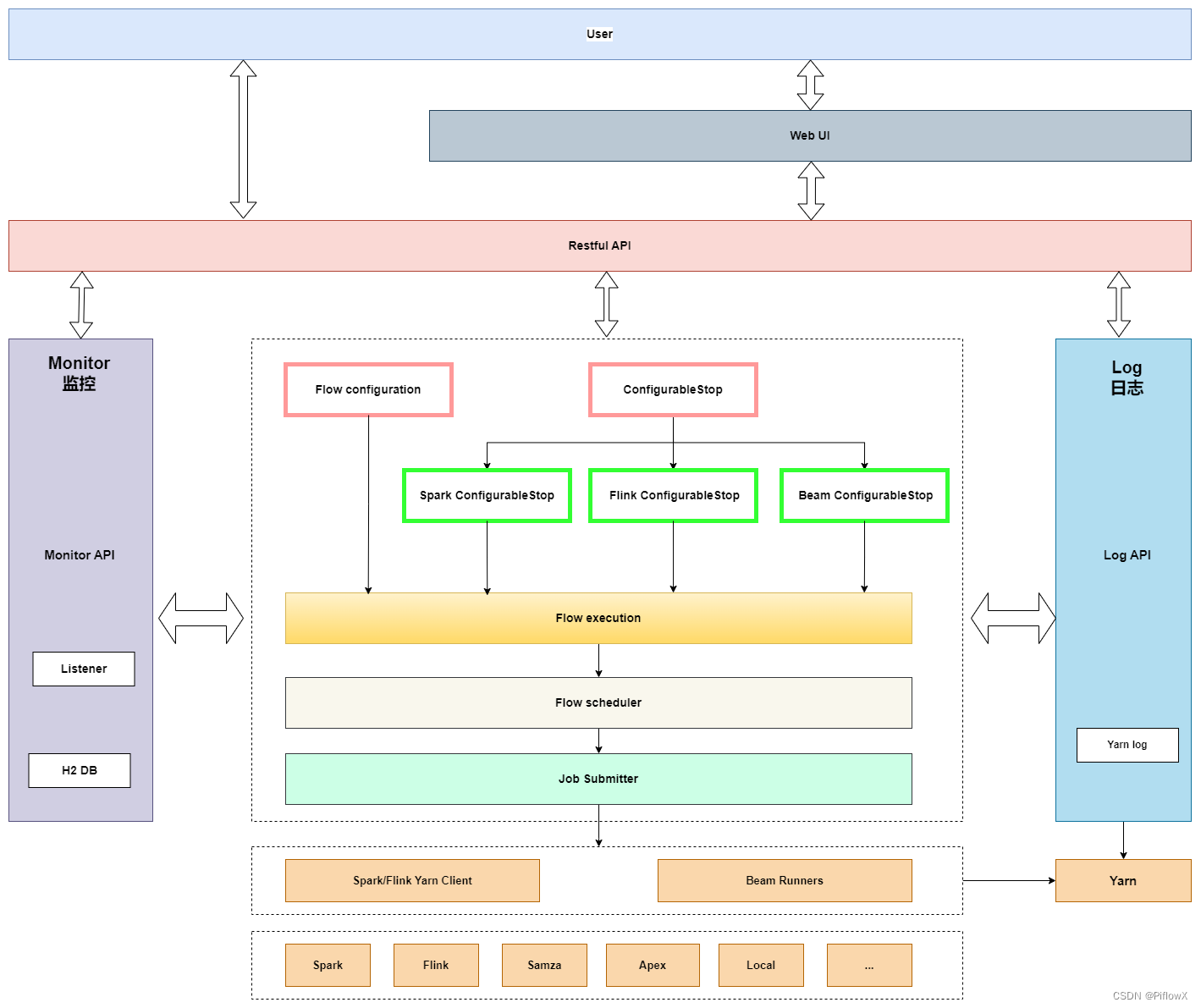
PiflowX可同时支持spark、flink和beam。借助beam的统一性,甚至可以一套逻辑同时运行在多种计算引擎下。
Beam引擎执行演示
登录页
首页
流水线首页
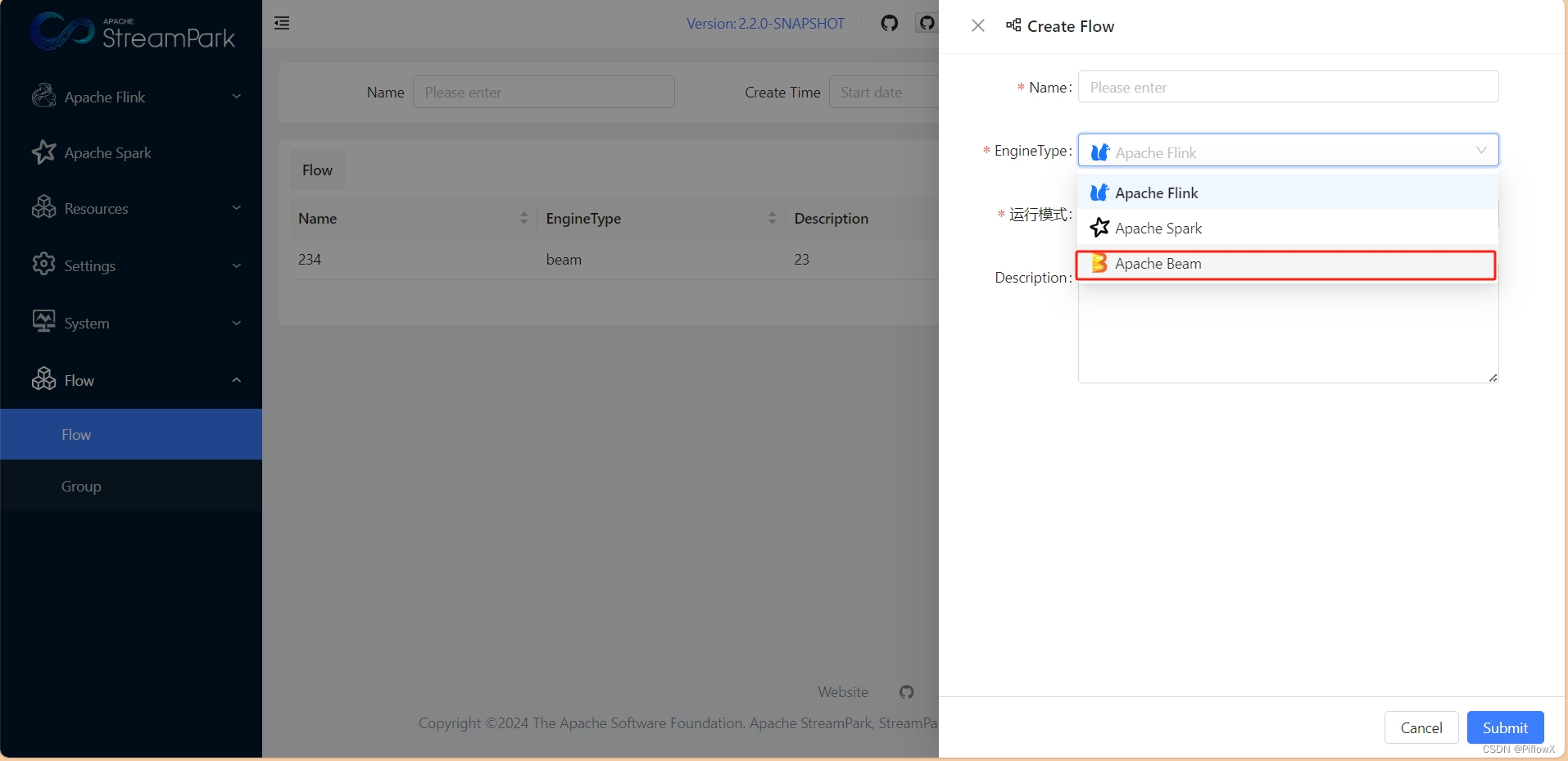
创建beam类型任务
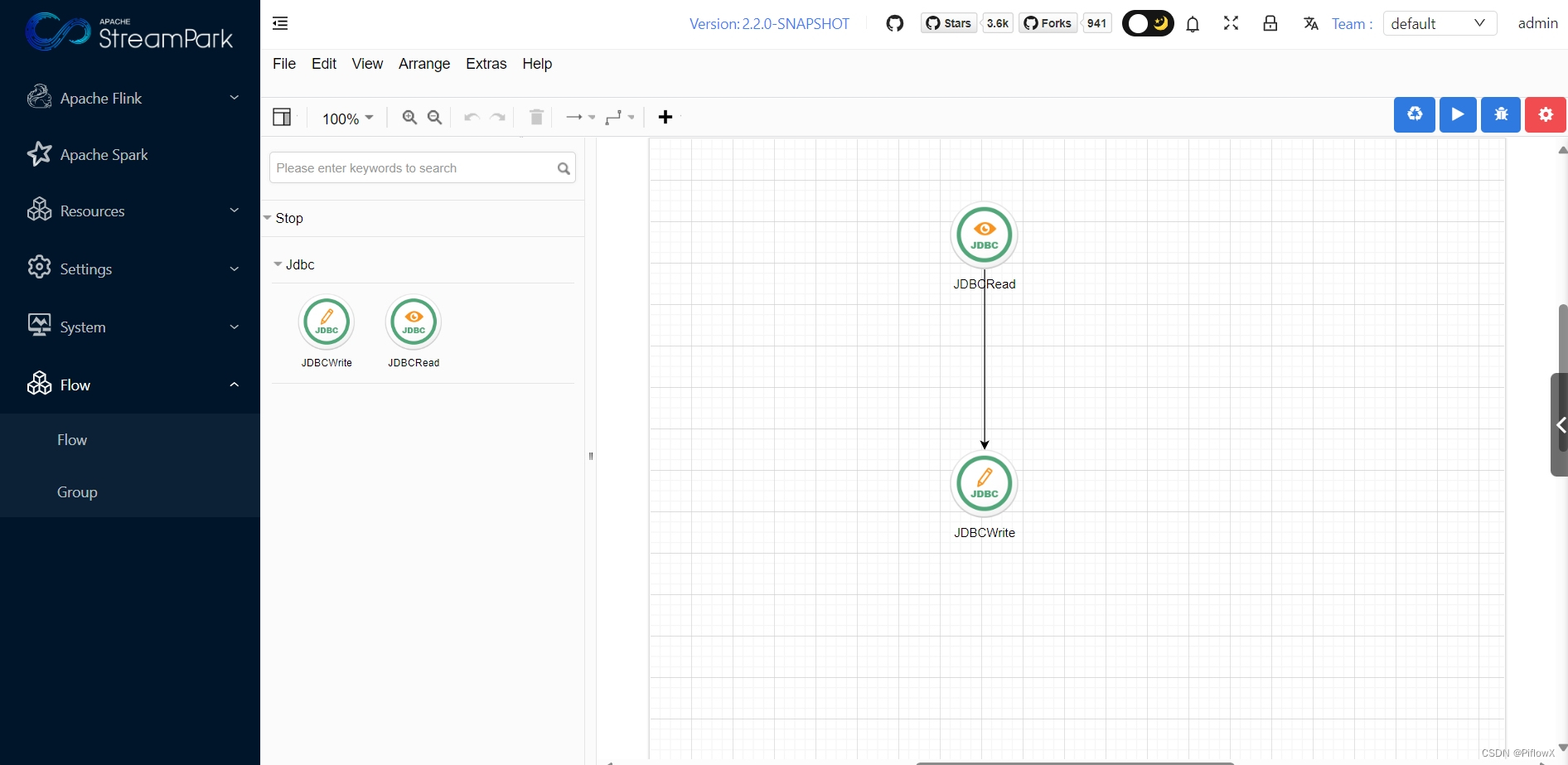
设计beam类型流水线
PiflowX新增Beam计算引擎

