
- 12023年跨年代码(新年祝福语生成器)
- 2关于Unity3D的一些优化_3d的顶点优化的点不在线上
- 3github无法连接的问题_github连不上
- 4pyqt事件循环_pyqt qeventloop
- 5基于Java家政服务预约网站系统设计与实现(Springboot框架)毕业设计论文提纲参考
- 6threejs 拖拽事件会触发点击事件_three防止拖拽触发点击事件
- 7mac电脑m1 arm架构安装虚拟机教程_the installer has detected an unsupported architec
- 8AI大模型“重塑”智能座舱,这些新机会已经显现
- 9YOLO系列的演进,从v1到v7(一)
- 10树莓派snowboy报错IOError: [Errno Invalid sample rate] -9997以及import snowboydetect<不是from . import snowboy
Opencv与python实现多目标跟踪 (一) - PaddleDetection目标检测_python 调用 paddledetection
赞
踩
前主流的Tracking By Detecting方式的多目标追踪(Multi-Object Tracking, MOT)算法主要由两部分组成:Detection+Embedding。Detection部分即针对视频,检测出每一帧中的潜在目标。Embedding部分则将检出的目标分配和更新到已有的对应轨迹上(即ReID重识别任务)。根据这两部分实现的不同,又可以划分为SDE系列和JDE系列算法。
对于传统的多目标跟踪,使用到的数据集是MOT16,MOT17这样的数据集格式,种类有如下这几种:
dataset/mot |——————image_lists |——————caltech.10k.val |——————caltech.all |——————caltech.train |——————caltech.val |——————citypersons.train |——————citypersons.val |——————cuhksysu.train |——————cuhksysu.val |——————eth.train |——————mot16.train |——————mot17.train |——————prw.train |——————prw.val |——————Caltech |——————Cityscapes |——————CUHKSYSU |——————ETHZ |——————MOT16 |——————MOT17 |——————PRW

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
其中数据格式如下:
MOT17
|——————images
| └——————train
| └——————test
└——————labels_with_ids
└——————train
- 1
- 2
- 3
- 4
- 5
- 6
所有数据集的标注是以统一数据格式提供的。各个数据集中每张图片都有相应的标注文本。给定一个图像路径,可以通过将字符串images替换为labels_with_ids并将.jpg替换为.txt来生成标注文本路径。在标注文本中,每行都描述一个边界框,格式如下:
[class] [identity] [x_center] [y_center] [width] [height]
- 1
注意:
class为类别id,支持单类别和多类别,从0开始计,单类别即为0。identity是从1到num_identities的整数(num_identities是数据集中所有视频或图片序列的不同物体实例的总数),如果此框没有identity标注,则为-1。[x_center] [y_center] [width] [height]是中心点坐标和宽高,注意他们的值是由图片的宽度/高度标准化的,因此它们是从0到1的浮点数。
这种数据从格式来看,似乎与目标检测yolov格式相似,但其中的图像,不是单一的场景下的一张图片,而是一段连续视频帧下,截取连续几帧的图片。
相对自定义数据集来说,做目标跟踪的数据标注成本要大很多,因此本文介绍一种分二阶段实现多目标跟踪的方法,
分为目标检测和目标跟踪二步完成
- 1
PaddleDetection 快速使用介绍
完成多目标跟踪,首先就是训练一个目标检测的模型,基于单帧检测的目标,使用算法,来判断其他帧检测的对象是否为同一物体,进而实现持续的视频跟踪。
目标检测模型使用cv2.dnn来加载这个模型,cv2.dnn可以加载多个类型的模型(格式),具体cv2.dnn模块说明参考下面这个链接:
这里以PaddleDetection的模型为列,将模型转为onnx
1.首先是下载必要的文件和框架。
git clone https://github.com.cnpmjs.org/PaddlePaddle/PaddleDetection --depth 1
- 1
cd PaddleDetection
python setup.py install
- 1
- 2
pip install pycocotools paddle2onnx onnxruntime onnx
- 1
快速目标检测,主要用到这几个文件:
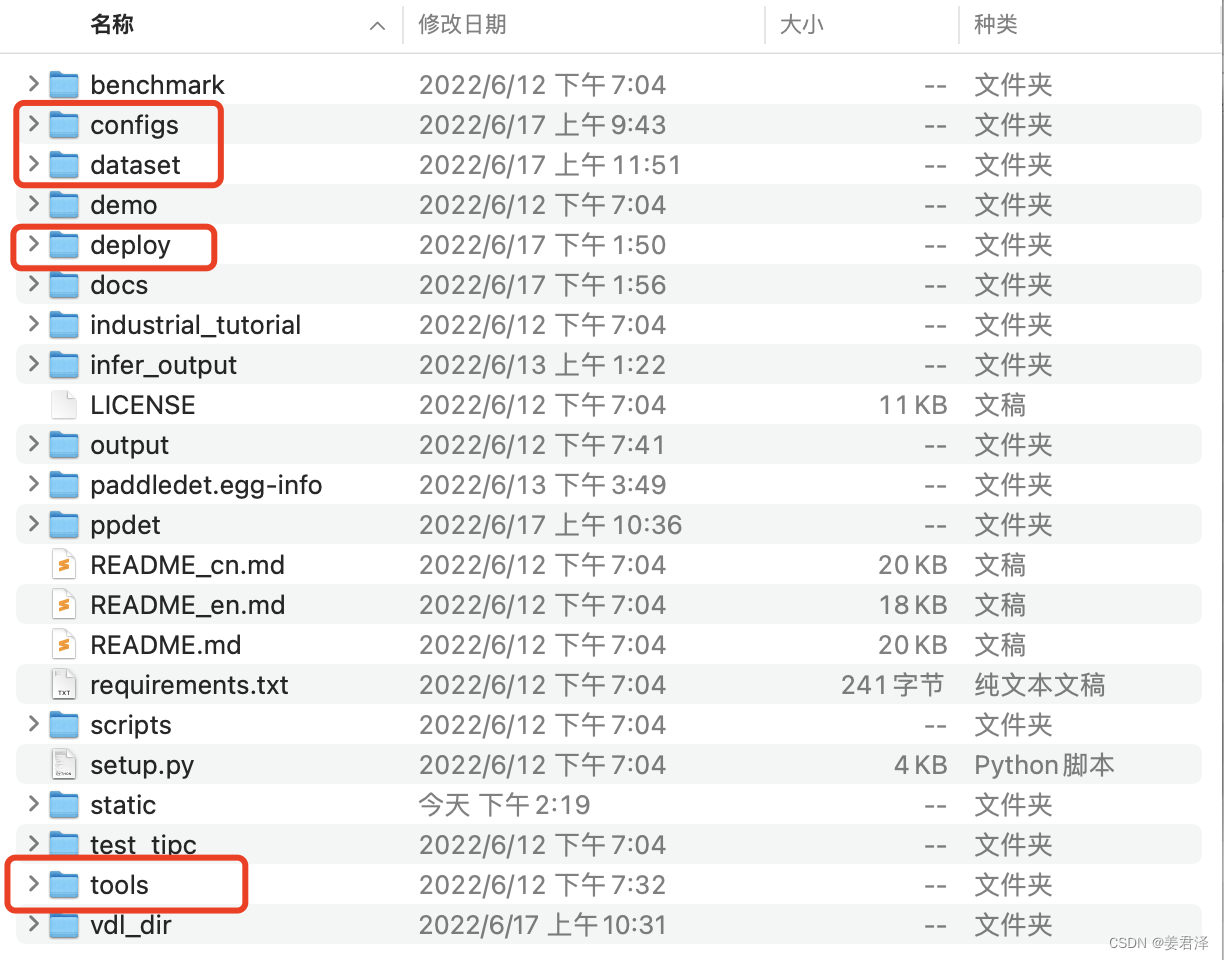
- configs:保存的是各种模型所有包含的配置参数(包含优化器配置参数,数据的格式参数,模型参数等)
- dataset:对应不同目标检测数据类型的文件夹,我们的数据集都放到这里
- deploy:有一个文件deploy/python/infer.py 可以推导视频类的数据做目标检测
- tools:这个文件就对应这模型的训练,评估,推导和导出模型
训练
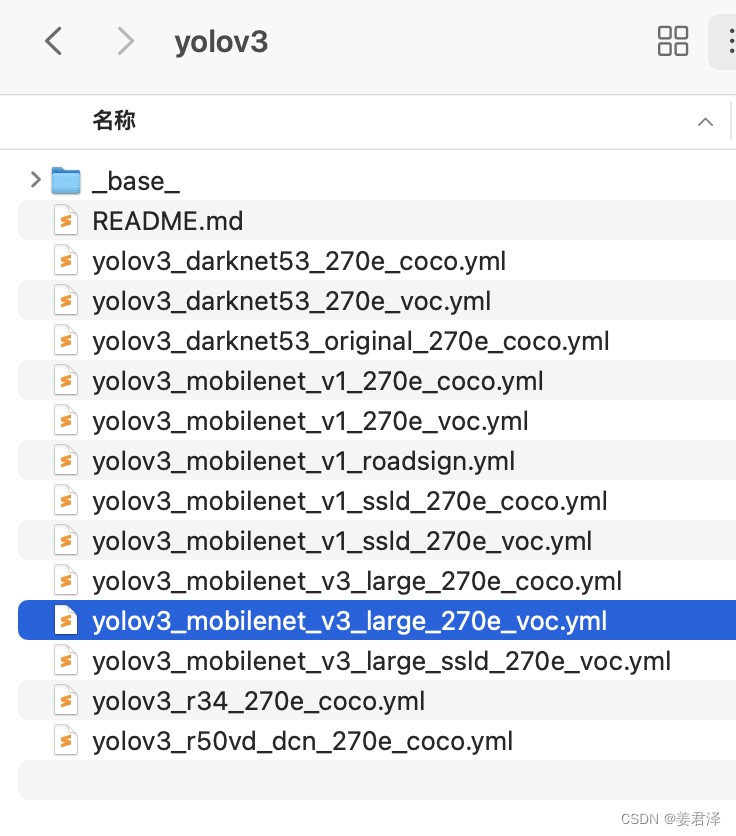
以yolov3_mobilenet_v3_large_270e_voc为例:
首先到configs找到
只需要修改红色框这个数据参数:
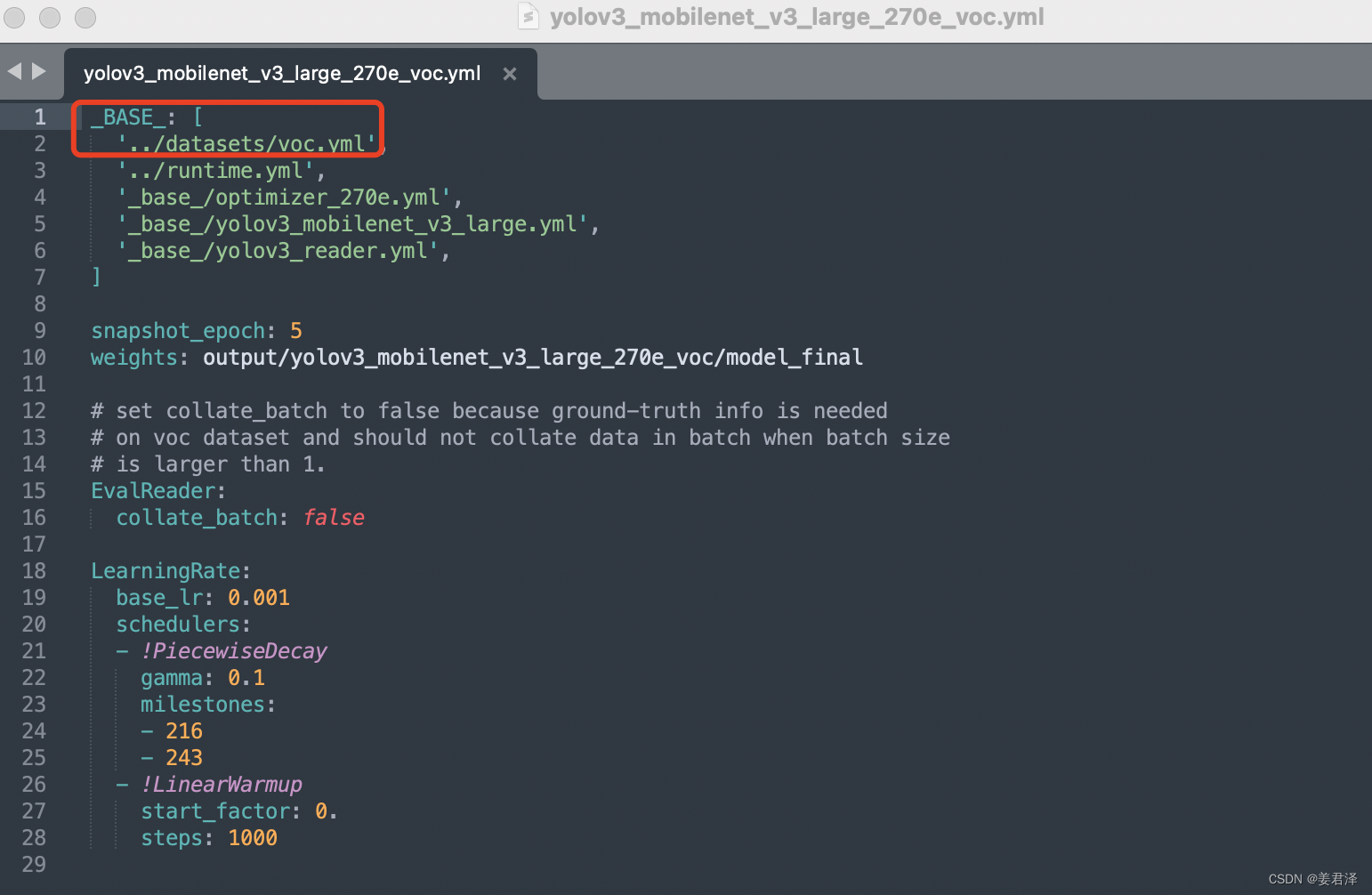 voc.yml参数需要修改的部分如下;
voc.yml参数需要修改的部分如下;
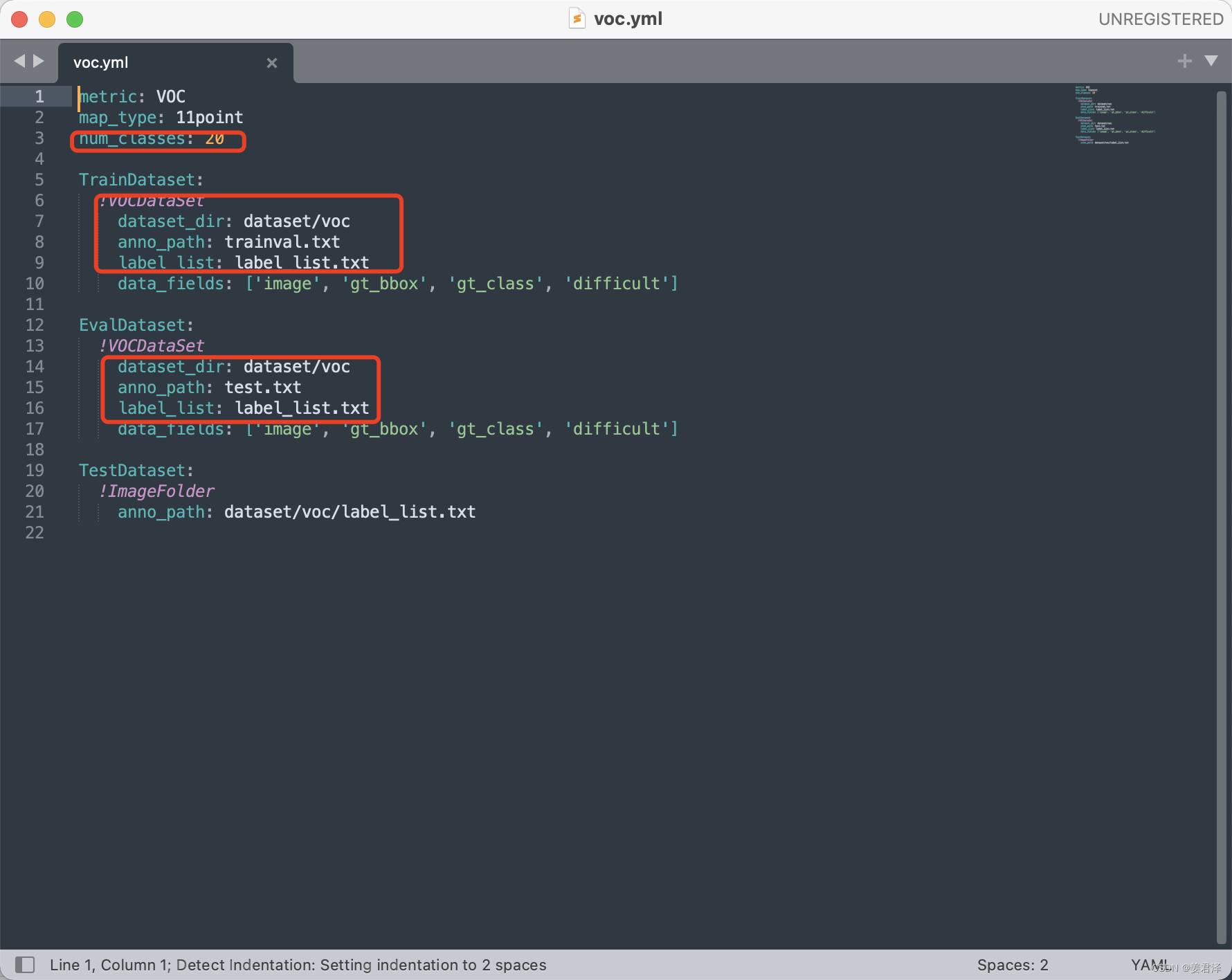
自己的分类类别数,以及数据集路径,需要将自己定义的数据集转换成合适的格式,比如这里的voc格式。
训练
python tools/train.py -c configs/yolov3/yolov3_mobilenet_v3_large_270e_voc.yml --eval -o use_gpu=true --use_vdl=True --vdl_log_dir=vdl_dir/scalar
- 1
use_gpu:是否使用GPU
vdl_log_dir:训练loss可视化配置
如果需要切换GPU,在tools/train.py增加二行代码:

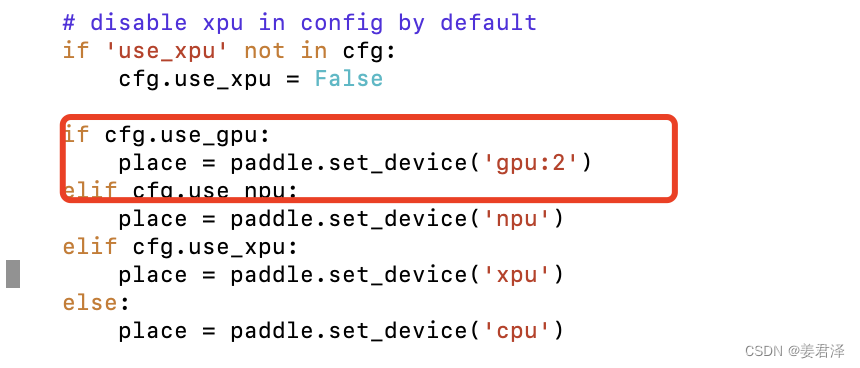
可视化
输入下面这个命令就可以查看自己训练可视化结果了
visualdl --logdir ./log --port 8080
- 1
得到模型参数与优化器参数在PaddleDetection/output里,前缀model_final为最好的模型结果
评估(验证)
python tools/eval.py -c configs/yolov3/yolov3_mobilenet_v3_large_270e_voc.yml -o use_gpu=true weights=output/yolov3_mobilenet_v3_large_270e_voc/model_final.pdparams
- 1
推导(预测)
python tools/infer.py -c configs/yolov3/yolov3_mobilenet_v3_large_270e_voc.yml -o weights=output/yolov3_mobilenet_v3_large_270e_voc/model_final.pdparams --infer_img=demo/1.jpg
- 1
导出模型
python tools/export_model.py -c configs/yolov3/yolov3_mobilenet_v3_large_270e_voc.yml -o weights=https://paddledet.bj.bcebos.com/models/ppyoloe_crn_l_300e_coco.pdparams
- 1
导出的模型在PaddleDetection/output_inference里

PaddleDetection模型转ONNX
首先就是训练一个目标检测的模型
用cv2.dnn加载这个模型,要知道cv2.dnn可以加载那些类型的模型(格式)
这里以PaddleDetection模型为列,将模型转为onnx
Detection注意:因为现在升级到2.0后,使用export.py导出的也会是叫model.pdmodel和model.pdiparams,
只有使用export.py导出的模型才是预测模型(只包含前向计算),可以被paddle2onnx导出。使用训练生成的model.pdmodel和
model.pdiparams是不可以被paddle2onnx导出的。
paddle2onnx --model_dir saved_inference_model \
--model_filename model.pdmodel \
--params_filename model.pdiparams \
--save_file model.onnx \
--enable_dev_version True
- 1
- 2
- 3
- 4
- 5

- saved_inference_model:就是导出模型到output_inference文件下的模型文件夹
ONNX模型的验证
ONNX官方工具包提供了API可验证模型的正确性,主要包括两个方面,一是算子是否符合对应版本的协议,二是网络结构是否完整。# check by ONNX
import onnx
# onnx_file = save_path + '.onnx'
# onnx_file ='onnx-model/detectionmodel.onnx'
save_path = 'onnx-model/'
onnx_file = save_path + 'detectionmodel.onnx'
onnx_model = onnx.load(onnx_file)
onnx.checker.check_model(onnx_model)
print('The model is checked!')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
加载onnx模型
def loadcv2dnnNetONNX(onnx_path):
net = cv2.dnn.readNetFromONNX(onnx_path)
net.setPreferableBackend(cv2.dnn.DNN_BACKEND_OPENCV)
net.setPreferableTarget(cv2.dnn.DNN_TARGET_CPU)
print('load successful')
return net
- 1
- 2
- 3
- 4
- 5
- 6
- 7

