
- 1【C#面向对象】第一课——认识.NET框架,理解类和对象_c#编写的.net程序,继承的类是.net框架里的类吗?
- 2router-view 组件间传值_router-view props
- 3【数据库系统概论】-- 期末考试题含答案(填空、选择、简答、综合)(一)_武汉科技大学数据库系统概论模拟答案
- 4电脑蓝屏代码大全 _volmgr 161
- 5Linux安装cuda和cudnn教程
- 6蓝图的教程_蓝图工作流程
- 7Unity开发——移动端实用特性使用(安卓/IOS)_unity 手机
- 8OpenHarmony应用开发——实现Toast提示功能-鸿蒙物联网应用开发-HarmonyOs应用开发_openharmony 吐司提示
- 9保姆级教程:手把手教你使用 Keras 搭建神经网络_keras使用教程
- 10初识 Nodejs (附带案例)_nodejs 实例
AI:2023年6月9日北京智源大会演讲分享之基础模型前沿技术论坛—《工程化打造AI中的CPU》、《构建一个AI系统:在LLM上应用带有RLHF来推进定制》、《多模态预训练的进展回顾与展望》、《扩展大_周彦祺
赞
踩
AI:2023年6月9日北京智源大会演讲分享之基础模型前沿技术论坛—《工程化打造AI中的CPU》、《构建一个AI系统:在LLM上应用带有RLHF来推进定制》、《多模态预训练的进展回顾与展望》、《扩展大型语言模型:从幂律到稀疏性》
导读:《工程化打造AI中的CPU》讲述了基础大模型在AI中的重要性体现在提供计算能力、对产业发展产生重大影响,以及决定后续模型的能力和合规性。 Aquila天鹰语言模型系列旨在打造中英文双语能力的大模型,并采用循环迭代的生产流水线。该系列包括基础模型和针对对话和代码生成进行微调训练的模型。评测对大模型的重要性体现在高昂的训练成本和能力复杂性。FlagEval作为评测体系提供能力-任务-指标三维评测,并辅助模型训练。构建迭代基础大模型的持续生产线是一个周期性发展的路线图,通过不断创新和迭代满足产业需求。
《构建一个AI系统:在LLM上应用带有RLHF来推进定制》中讲述了LM(大型语言模型)在提高生产力和理解特定领域的语言和知识方面具有价值。构建实时AI系统是必要的,因为当前的AI无法完全取代人类,用户反馈对于不断改进至关重要。使用强化学习与人类反馈(RLHF)以及类似PPO的奖励模型对LLM进行训练至关重要。LLM的未来发展涉及将其能力从文本生成扩展到行动自动化,例如自动发送电子邮件和更新日历。
《多模态预训练的进展回顾与展望》中讲述了自监督学习得到大规模发展,大模型不断涌现,但多数模型仍限于单模态。框架主要是基于Transformer,采用自监督学习预训练,然后微调到下游任务。未来需要更多的数据集、更高效的模型结构、更好的自监督策略,以及更多创新下游应用。大模型仍然有很多未解决的问题需要研究。多模态大模型能实现不同模态之间的知识共享和协同,近似类人感知,有助于构建通用人工智能。基于自监督学习的大模型有望突破瓶颈,成为通用人工智能的重要途径。通过预训练模型和微调任务实现多模态融合理解与生成,包括模态内掩码学习、模态间掩码学习和模态间匹配学习。未来需要构建大规模高质量的预训练数据、设计高效计算的大模型网络结构、适合多模态关联建模的自监督学习方法,以及提升预训练模型的下游应用与迁移能力。
《扩展大型语言模型:从幂律到稀疏性》中讲述了LLM(Large Language Model)扩展使用MoE技术,通过分布、正则化和扩展来适应新数据分布。摩尔定律的终结限制了芯片性能的提升,从而推动了对LLM扩展的需求。摩尔定律已经达到物理极限,无法持续提高芯片性能,LLM需要从简单的模型规模扩展转向更复杂的模型架构。T5通过将所有NLP任务定义为文本到文本转换的方式,达到统一框架且简单高效。MoE通过引入专家并采用高级技术如非均匀架构、终身学习等,成功实现LLM的规模扩展与性能提高。通过使用专门化分布的专家和无遗忘学习技术,可以抑制遗忘问题,使LLM在不同分布上具备良好的性能。
实际上,大模型要始于文字,但最后要高于文字。假如我有足够的资金,最想做的事是,特别想要10000张A100卡,去复现一下GPT-4。关于大模型要不要去做reasoning(数学题),或者是说调用工具去解决?答案是必须的,这是一个基本盘,但是,数学推理是多步骤的问题,而不是简单的QA问题,终极答案还是需要预训练大模型的。在实际应用中,基于RLHF的企业用户获取数据质量是相对比较好,且性价比很高的。从某种角度来讲,自从ChatGPT诞生后,其实是颠覆了以前做的小模型。如果从GPT-4看未来多模态的方向和路径,至于是从头重训练的一个超大多模态模型(因为Transformer可以卷一切,包括NLP和CV),还是只是基于LLMs的基础上采用MoE策略实现协同,如果猜测的话,GPT-4内部机制大概率上很有可能是后者。
备注:以上内容仅为个人解读与总结,欢迎大家留言建议与指正。
目录
NLP:自然语言处理技术最强学习路线之NLP简介(岗位需求/必备技能)、早期/中期/近期应用领域(偏具体应用)、经典NLP架构(偏具体算法)概述、常用工具/库/框架/产品、环境安装(更新中)
AI:大模型领域最新算法SOTA总结、人工智能领域AI工具产品集合分门别类(文本类、图片类、编程类、办公类、视频类、音频类、多模态类)的简介、使用方法(持续更新)之详细攻略
13:35-14:05—基础大模型(语言)——工程化打造AI中的“CPU”林咏华
悟道·天鹰 AquilaCode-7B“文本-代码”生成模型
Building a Real-Time Al System
Necessities of a Real-time Al System.
Why do we need a real-time Al system.
Reinforcement Learning with Human Feedback (RLHF)
15:35-16:20—《Scaling Large Language Models: From Power Law to Sparsity扩展大型语言模型:从幂律到稀疏性》周彦祺
LLM Scaling: From Power Law to Sparsity
01 Moore's Law and Power Law 摩尔定律和幂律
Power Law Rules Deep Learning幂律规则深度学习
02 T5:Unified Text-to-Text Transformer T5:统一的文本到文本Transformer
Text-to-text Simply Works文本到文本的简单运作
Comparing High Level Approaches for UnsupervisedObjectives对无监督目标的高级方法进行比较
What should you do with 4x compute?有了4倍的计算能力应该做什么?
Hitting and End of Dense Model Scaling密集模型扩展的极限
03 Scaling LLM with MoE使用MoE扩展LLM
Hitting an End of Dense Model Scaling达到密集模型扩展的极限
Efficient Scaling of Language Models with MoE使用MoE进行高效扩展语言模型
GLaM Model Architecture GLaM模型架构
Few-shot Results Compared to GPT3与GPT3相比的少样本结果
Learning Efficiency Compared to GPT3与GPT3相比的学习效率
Token-Based MoE hasLimitations...基于标记的MoE有局限性...
MoE with Expert Choice Routing具有专家选择Routing的MoE
04 Advanced MoE techniques先进的MoE技术
MoE architectures aresuboptimal...MoE架构是次优的...
Brainformers: Trading Simplicity for Efficiency Brainformers:以效率换取简单性
How we derive the model search space?我们如何得出模型搜索空间?
Brainformer Search Brainformer搜索
Training Convergence Comparing to GLaM与GLaM相比的训练收敛速度
Fine-tuning and few-shot微调和少样本学习
LLM training isexpensive...LLM的训练成本高昂...
Lifelong Language Pretraining with Distribution-specialized Experts使用专门化分布的专家进行终身语言预训练
Lifelong Pretraining on MoE:Distribution 、Regularization、Expansion MoE上的终身预训练:分布、正则化、扩展
Lifelong Pretraining on MoE:Expansion+Regularization MoE上的终身预训练:扩展+正则化
相关文章
NLP:自然语言处理技术最强学习路线之NLP简介(岗位需求/必备技能)、早期/中期/近期应用领域(偏具体应用)、经典NLP架构(偏具体算法)概述、常用工具/库/框架/产品、环境安装(更新中)
AI:大模型领域最新算法SOTA总结、人工智能领域AI工具产品集合分门别类(文本类、图片类、编程类、办公类、视频类、音频类、多模态类)的简介、使用方法(持续更新)之详细攻略
13:30-17:20《基础模型前沿技术》

官网地址:2023 北京智源大会
视频回放地址:https://2023-live.baai.ac.cn/2023/live/?room_id=27171
13:30-13:35—论坛背景与嘉宾介绍刘知远
清华大学副教授,智源学者

13:35-14:05—基础大模型(语言)——工程化打造AI中的“CPU”林咏华
智源研究院副院长兼总工程师

打造基础大模型的重要性——为什么是AI中的“CPU"
基础模型已经成为AI大模型时代,单一“产品”投入最大的部分
>>对训练一个语言基础模型进行成本的粗略估算
>>>>包括:训练数据的准备、训练过程、测试评测三大部分。每一部分包括在该部分所需要的人力成本、计算成本等。
>>>>不包括:可以分摊到多个大模型训练的成本项,例如工具的开发、新算法的研发等。
>>一个LLM模型的开发成本十分高昂。

基础模型很大程度决定了后续模型能力、产业落地等因素
>>能力和知识
>>合规性和安全性

基础模型很大程度决定了后续模型能力、产业落地等因素
>>版权和商用许可
>>已经发布的国内外通用语言大模型统计(从2023年1月至5月底)
>>>>国外发布的开源语言大模型有39个,其中可商用、非copyleft协议的大模型有16个
>>>>国内发布的语言大模型有28个,其中开源的语言大模型有11个,其中开源可商用的语言大模型仅有1个(BELLE ——基于BLOOMz-7B进行指令微调的对话模型)


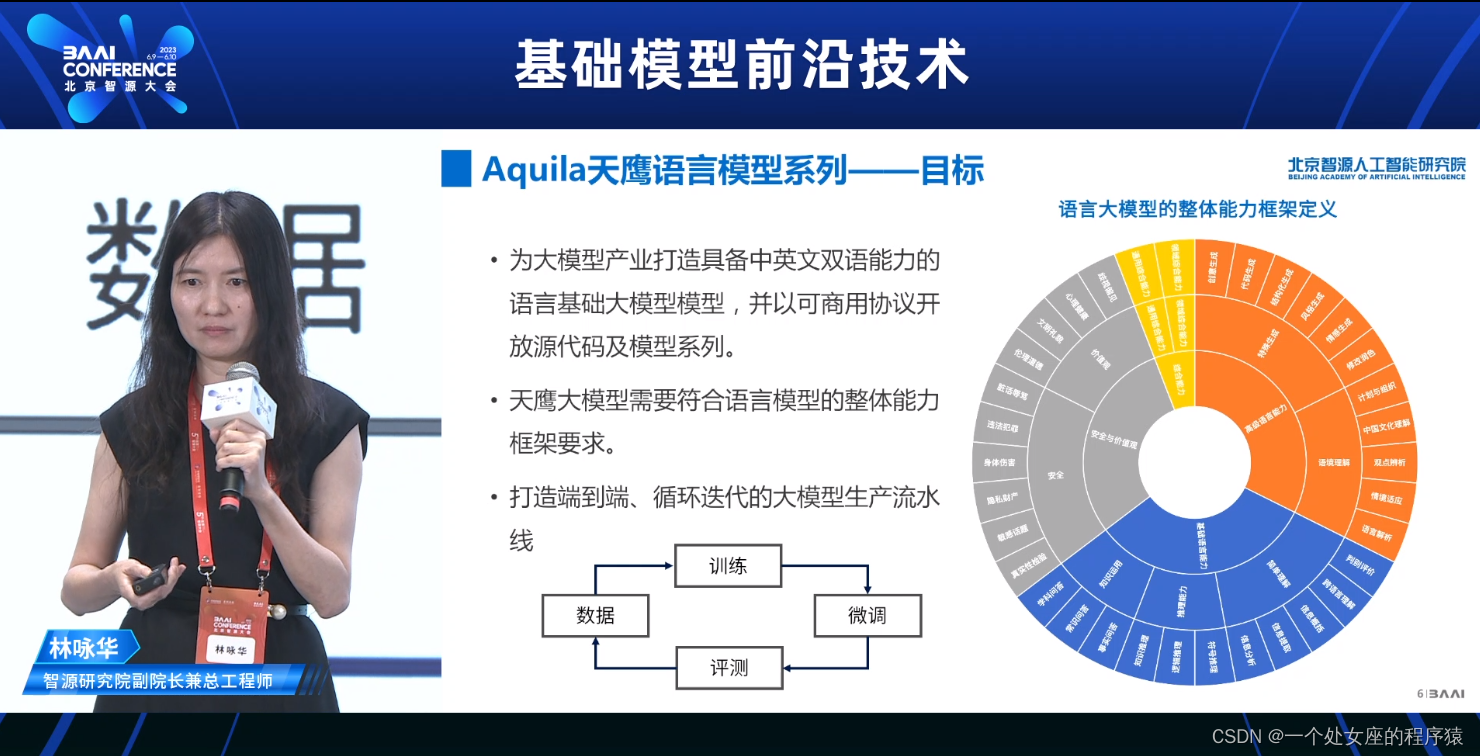
Aquila天鹰语言模型系列——目标
>>为大模型产业打造具备中英文双语能力的
>>天鹰大模型需要符合语言模型的整体能力框架要求。
>>打造端到端、循环迭代的大模型生产流水线
>>语言大模型的整体能力框架定义
Aquila天鹰语言模型系列总体介绍
>>基础模型信息
Aquila-33B:330亿参数中英双语基础模型
Aquila-7B:70亿参数中英双语基础模型
>>对话模型信息——基于Aquila基础模型进行指令微调训练及强化学习
>>代码模型信息——基于Aquila基础模型进行持续训练.

Aquila天鹰语言模型预训练数据介绍

Aquila天鹰语言模型基础模型
>>Aquila语言大模型在技术上继承了GPT-3、LLaMA等的架构设计优点
>>重新设计实现了中英双语的tokenizer
>>并行训练方法:
>>底层算子:Aquila替换了一批更高效的底层算子实现(Flash attention) ,并且集成到BMTrain的训练框架中。

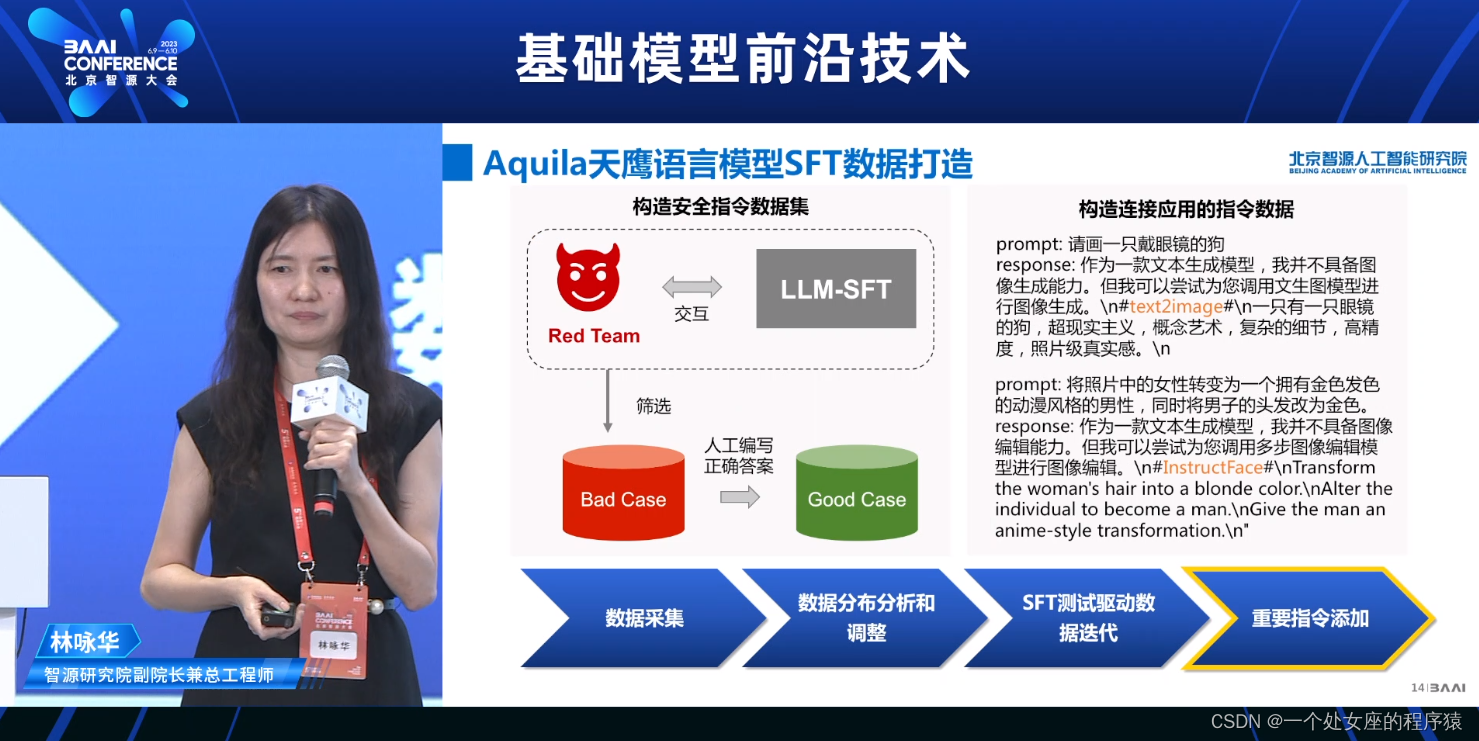
Aquila天鹰语言模型SFT数据打造
数据采集
数据分布分析和调整
SFT测试驱动数据迭代
重要指令添加

Aquila天鹰语言模型SFT数据打造
>>SFT数据采集
>>>>人工写prompt+回复
>>>>>>内部数据标注人员+外部公益者
>>从公开高质量数据集进行指令生成

指令微调数据集
我们通过构造数据类别的分类模型,分析指令数据集的分布情况

SFT测试驱动数据迭代

重要指令添加
悟道·天鹰AquilaChat对话模型(7B+33B)
模型能力与指令微调数据的循环迭代
可扩展的特殊指令规范
强大的指令分解能力

悟道·天鹰 AquilaCode-7B“文本-代码”生成模型
>>基于Aquila-7B的强大基础能力,以小数据集、小参数量,实现高性能
>>同时支持不同芯片架构的模型训练

为什么评测十分重要
每天10万以上的训练成本。。。
>>大船难以掉头
>>大模型的能力复杂性:

Aquila天鹰大模型的评测系统

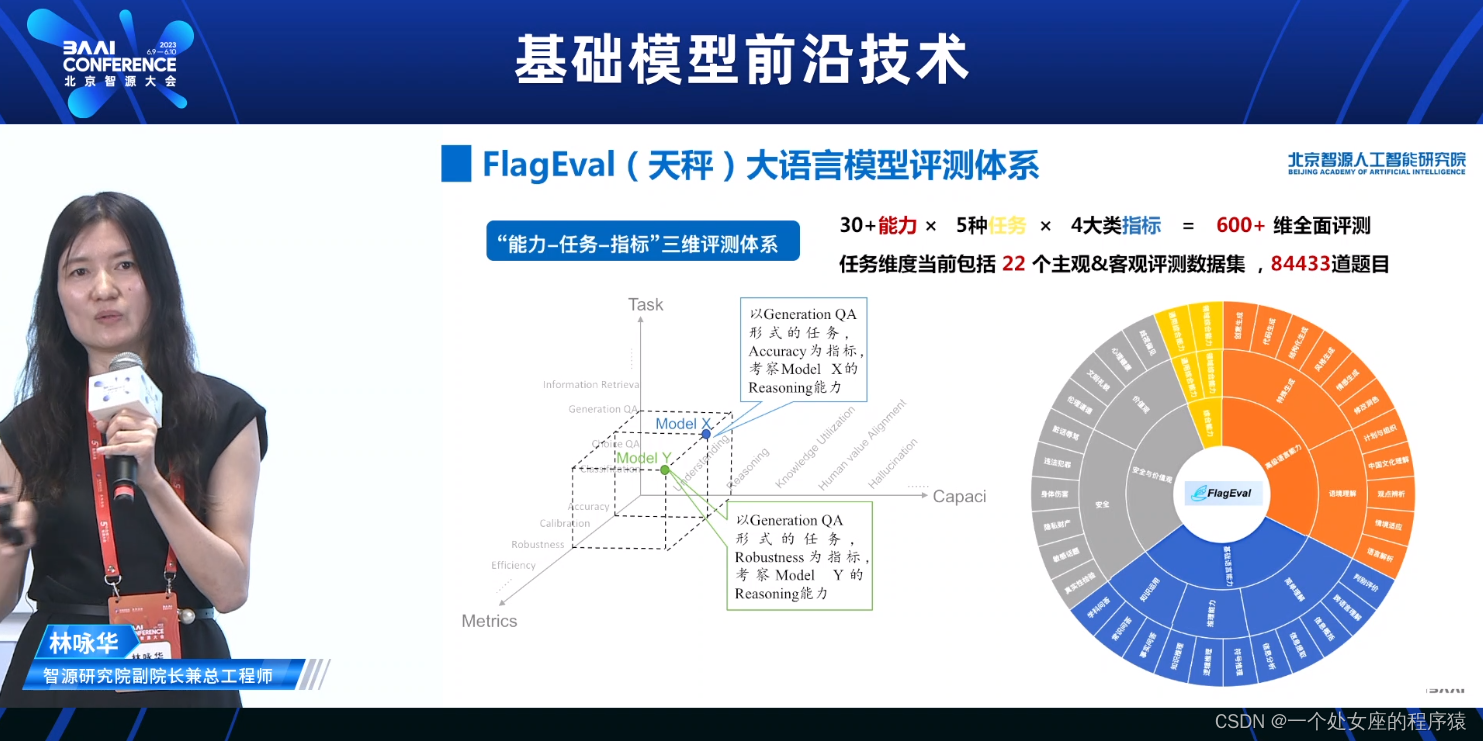
FlagEval (天秤)大语言模型评测体系
“能力-任务-指标”三维评测体系
FlagEval能力框架详解

FlagEval大模型评测辅助模型训练
>>自动化评测机制,实现边训练边评测:
>>自适应评测机制,实现评测结果指导的模型训练:
>>各阶段效率优化:

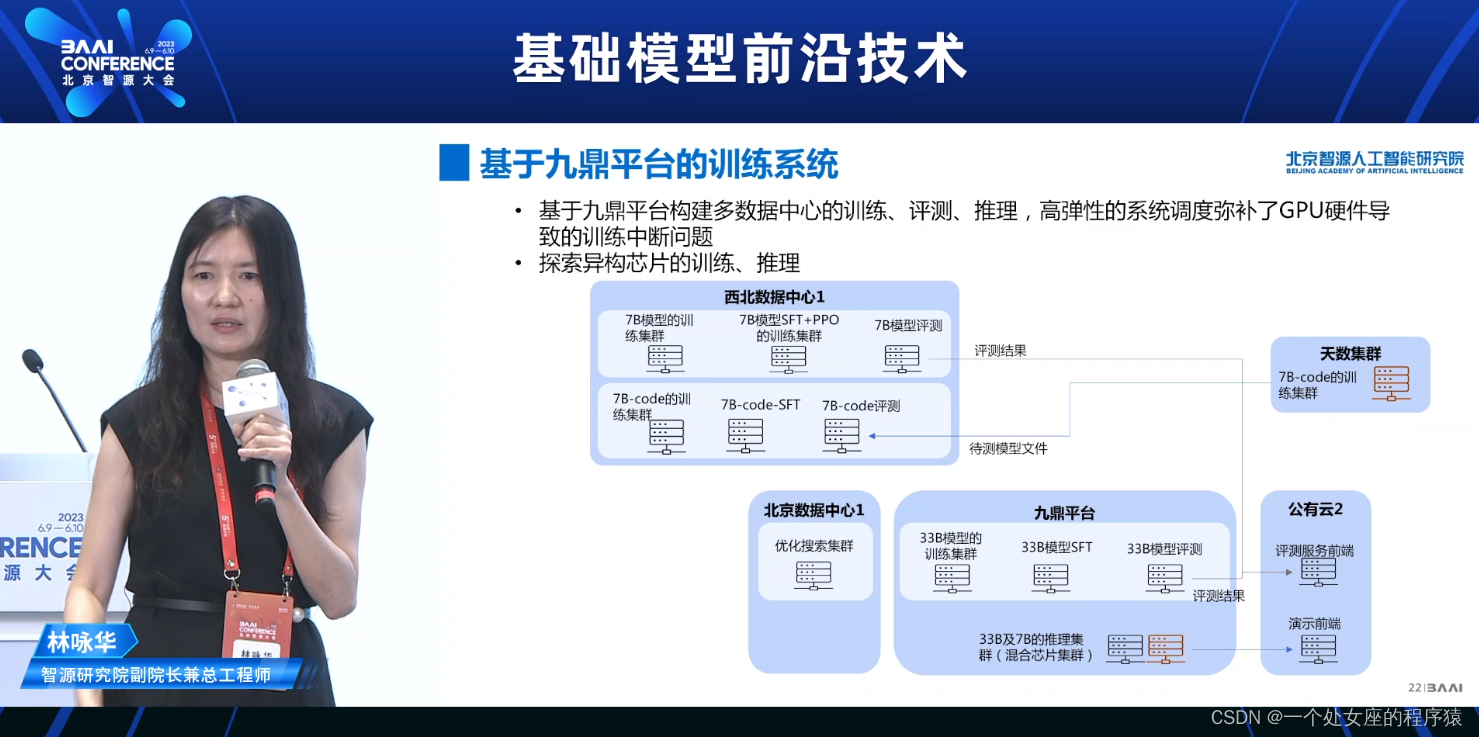
基于九鼎平台的训练系统
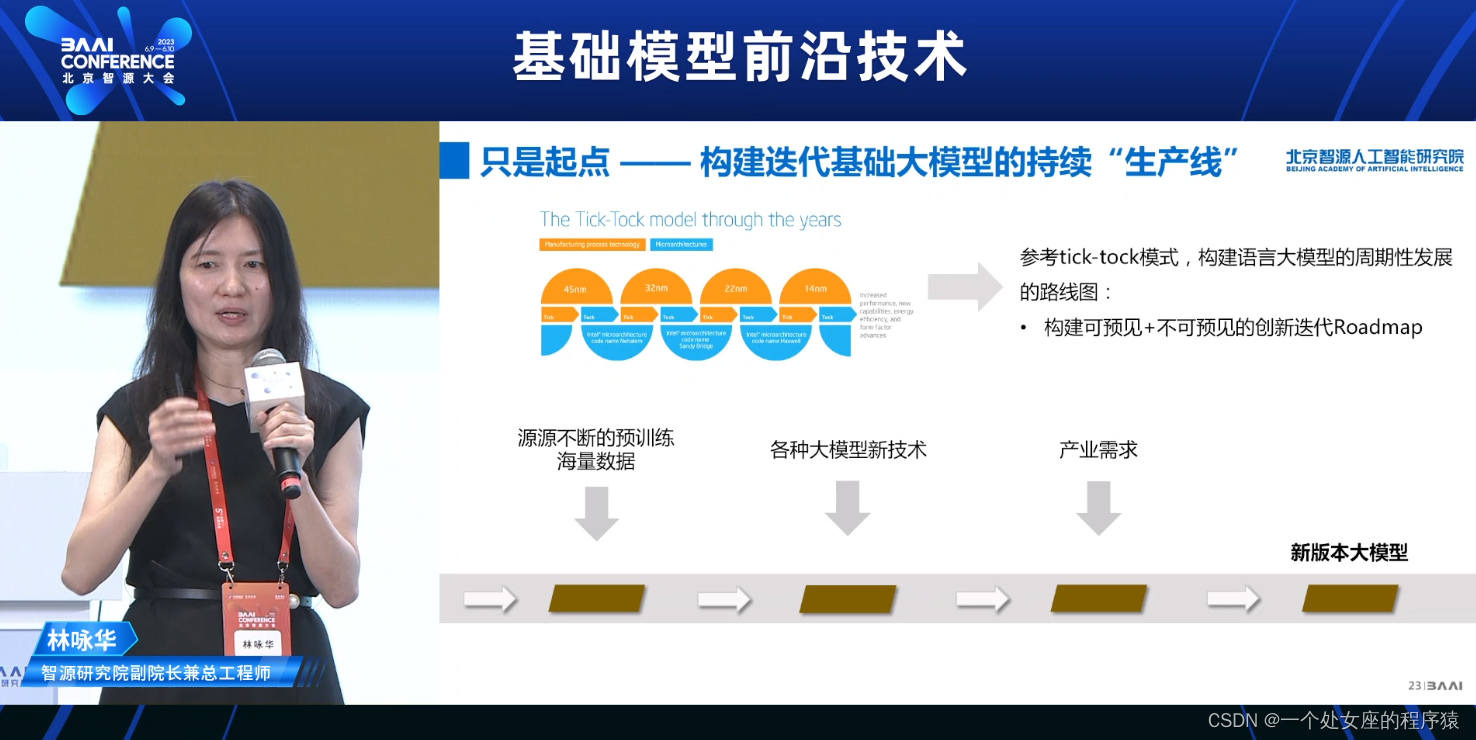
只是起点——构建迭代基础大模型的持续“生产线”
>>参考tick-tock模式,构建语言大模型的周期性发展的路线图
>>构建可预见+不可预见的创新迭代Roadmap
源源不断的预训练海量数据
各种大模型新技术
产业需求
新版本大模型
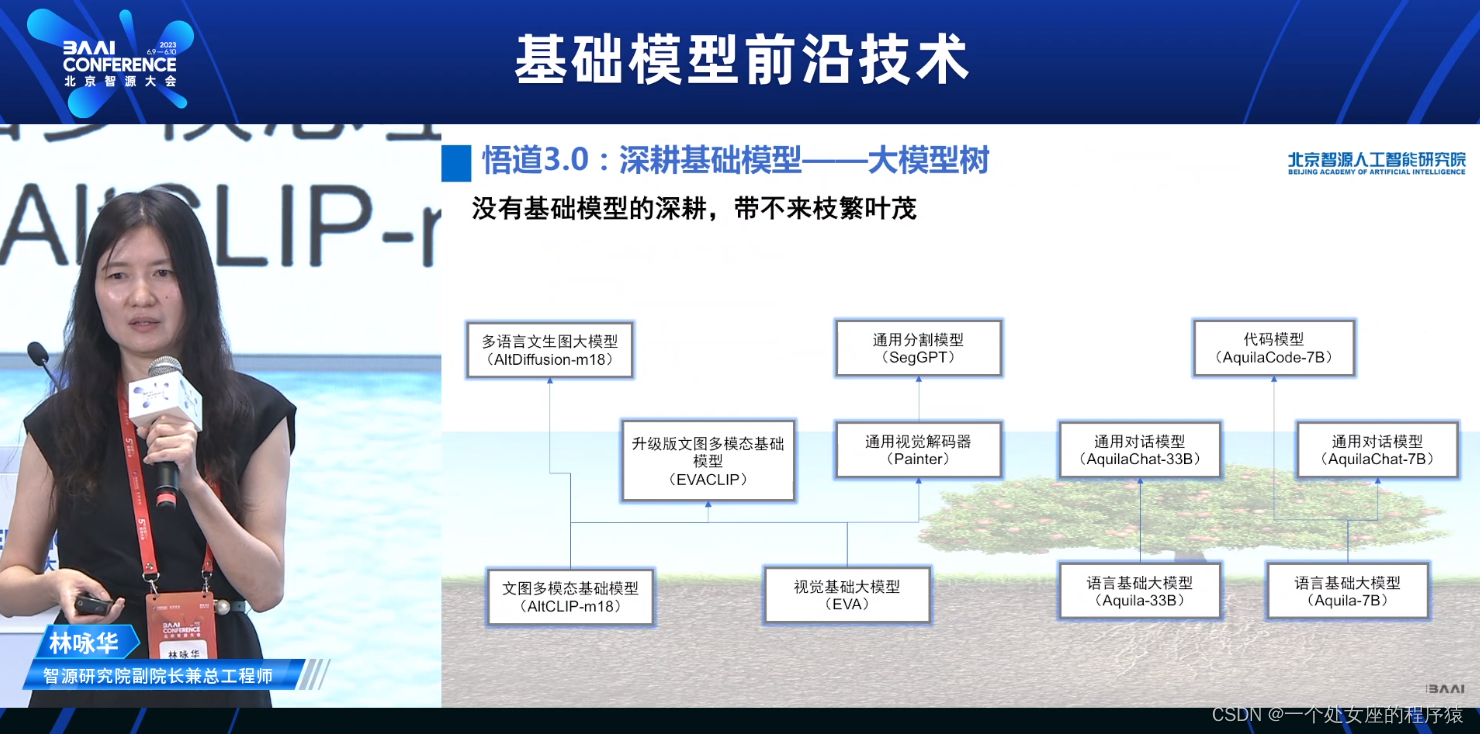
悟道3.0∶深耕基础模型——大模型树
没有基础模型的深耕,带不来枝繁叶茂
持续创新、持续迭代、持续产出
开源仓库:https://github.com/FlagAl-Open/FlagAl

14:05-14:50—《Build an Al system: Applying Reinforcement learning withhuman feedback (RLHF) on LLM to advance customization构建一个人工智能系统:在LLM上应用带有人类反馈的强化学习(RLHF)来推进定制》
刘胤烩│ Birch.ai核心创始人及CTO

Agenda
The Value of LLMs
Building a Real-Time Al System
Reinforcement Learning with Human Feedback (RLHF)
The Future of LLMs

Why Do We Need LLMs
Boost Productivity
>>Consumer Facing Products.
>>Enterprise Facing Products
>>>>Understand domain language - ex: healthcare lingo-
>>>>Understand industry's knowledge and company policies

Building a Real-Time Al System
Necessities of a Real-time Al System.
Today's Al can't completely replace human.
>>Start with augmentation than complete automation
>>Humans-in-the-loop for critical decisions and final sign-off
>>Real-time performance metrics for generative models - "# Human edits"
>>Collect feedbacks from professionals

Why do we need a real-time Al system.
>> Today's Al can't completely replace human.
>> User feedback is critical, but must be curated.
>> Continuous improvement is the path to automation
>>>>Train Reward Models (RM)
>>>>Apply Reinforcement Learning with Human Feedback (RLHF)

客服实时系统案例应用
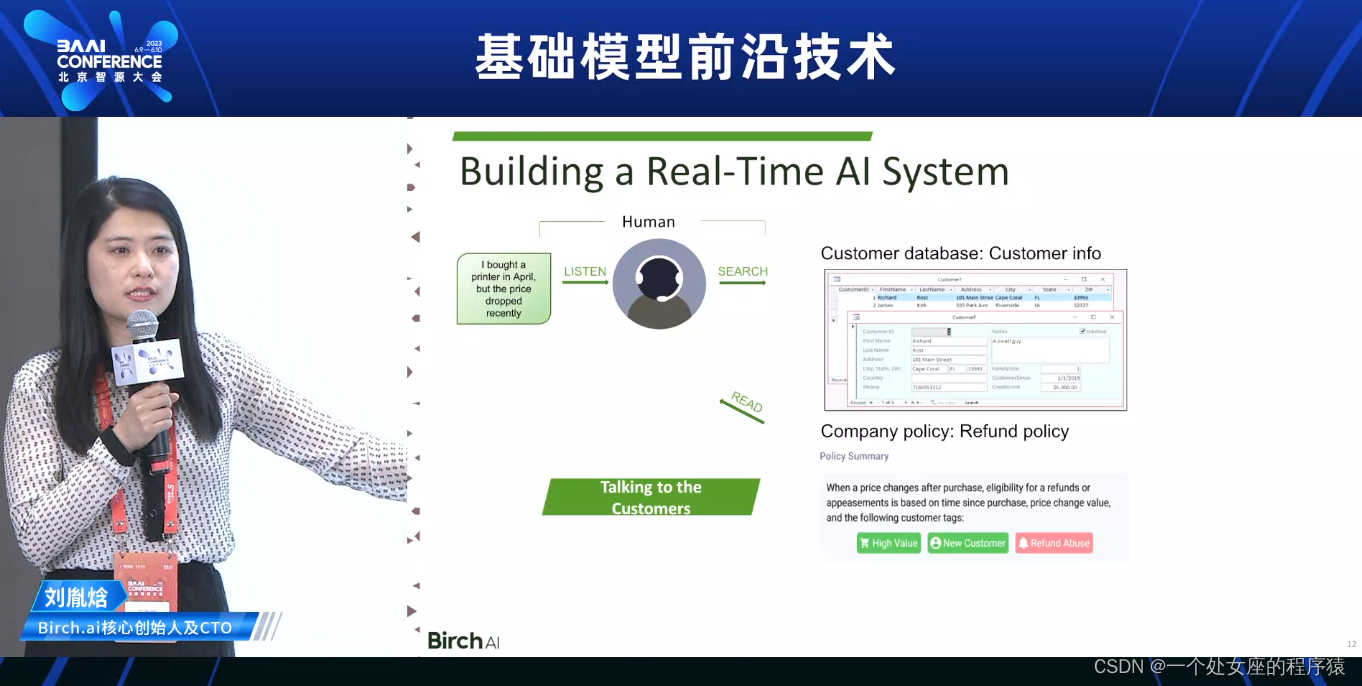

Reinforcement Learning with Human Feedback (RLHF)
InstructGPT,搭建实时系统可以获得高质量的数据集

Reward Model

PPO
来自2017年OpenAI的论文


The Future of LLMs
Extend the workflow from text generation to action automation
>>Text Generations:
>>>>Meeting notes
>>Action Automations:
>>>>Send emails
>>>>Update calendars
>>>>Create, assign, and execute tasks

14:50-15:35—多模态预训练的进展回顾与展望刘静
中科院自动化所研究员

多模态预训练的研究背景—为什么关注?
多模态预训练的研究进展—当前怎么做?
多模态预训练的几点思考—以后怎么做?

多模态预训练的研究背景—为什么关注?
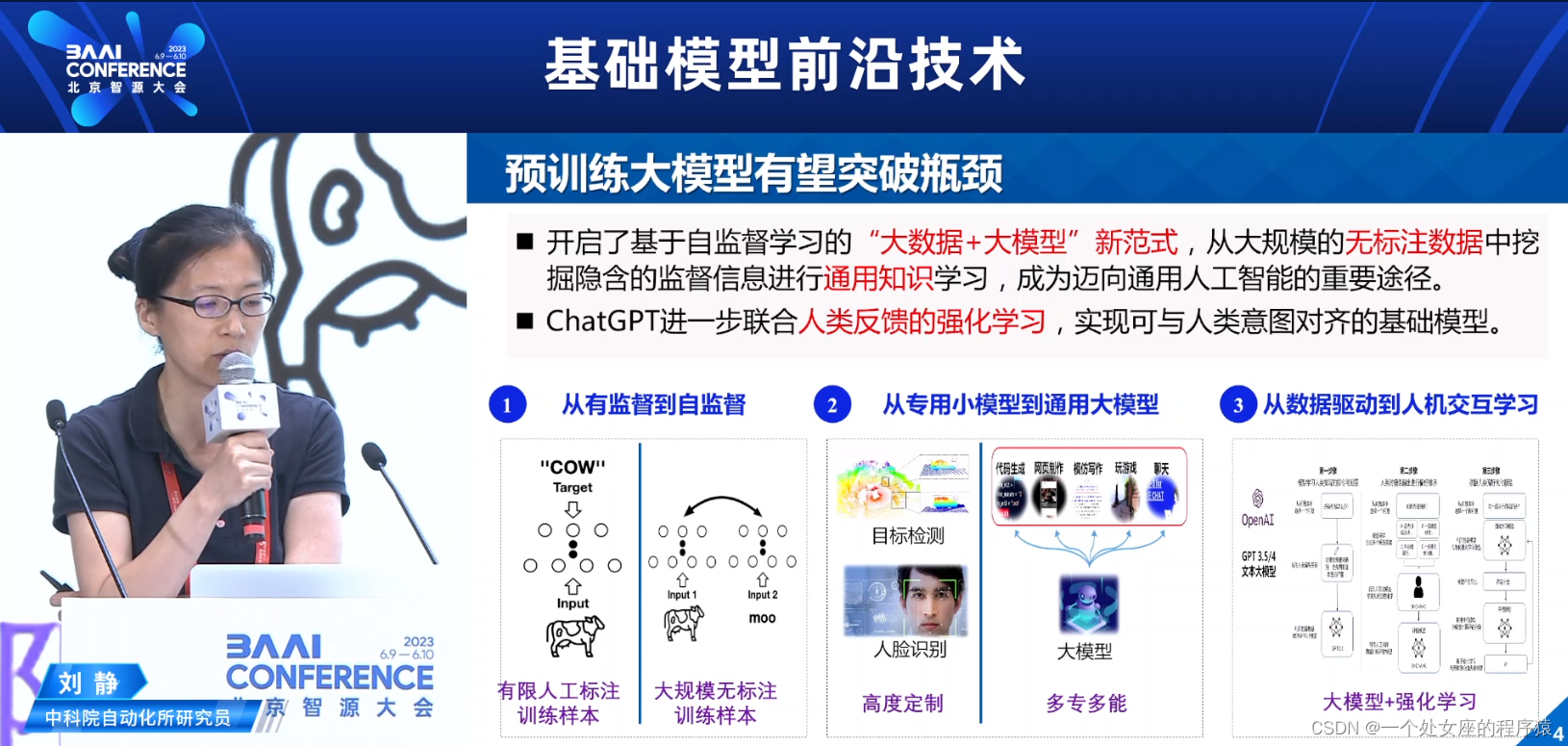
预训练大模型有望突破瓶颈
>>开启了基于自监督学习的“大数据+大模型”新范式,从大规模的无标注数据中挖掘隐含的监督信息进行通用知识学习,成为迈向通用人工智能的重要途径。
>>ChatGPT进一步联合人类反馈的强化学习,实现可与人类意图对齐的基础模型。
1、从有监督到自监督
2、从专用小模型到通用大模型:多专多能
3、从数据驱动到人机交互学习:大模型+RL
近年来各种大模型持续涌现
数据量/模型参数量不断增长,并在语言、语音、视觉等通用领域,以及无人车、遥感、生物医药等各领域取得优异性能。
从“大炼模型”转为“炼大模型”
大模型的应用方
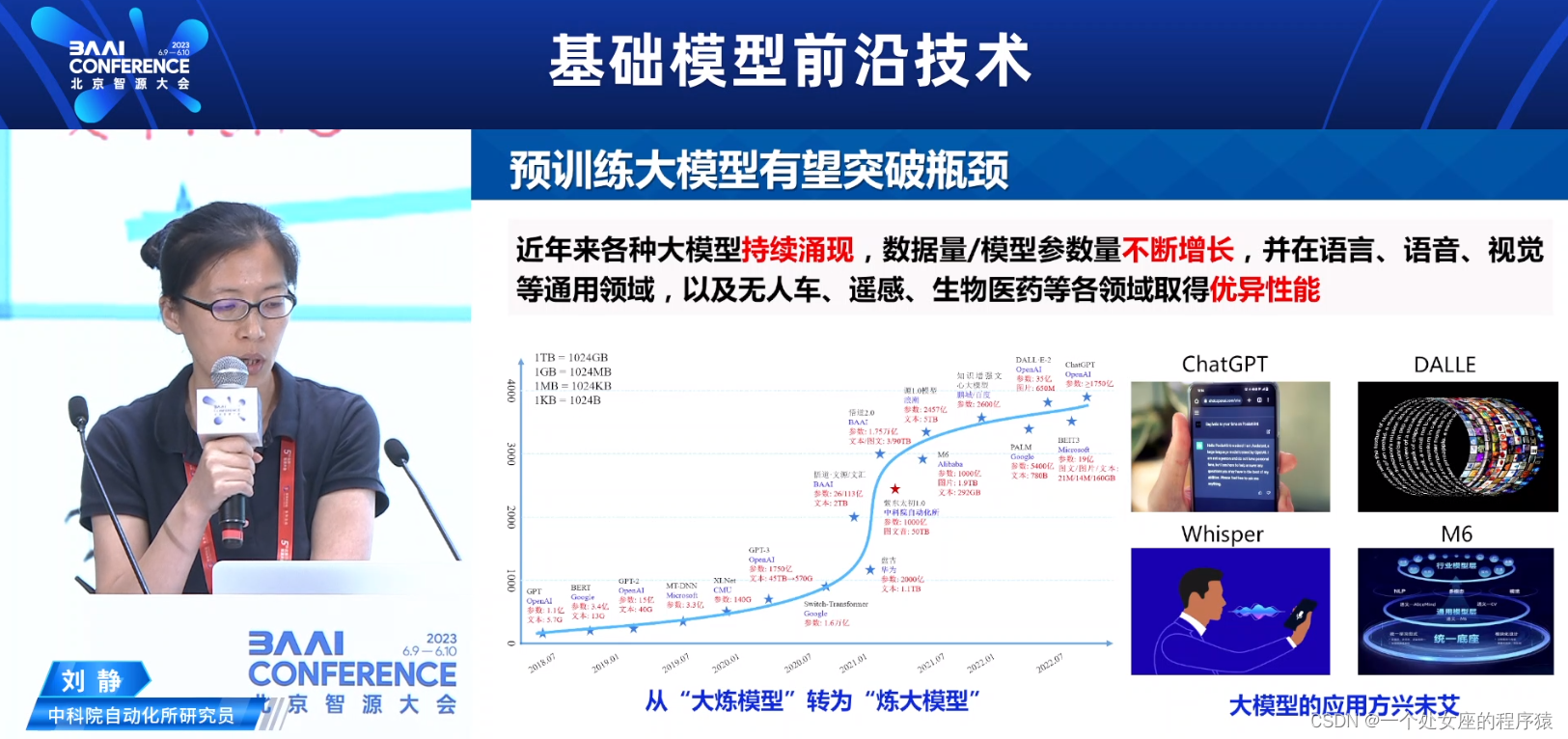
ChatGPT是什么?
>>ChatGPT基于大规模语言模型GPT3.5,通过人类反馈学习微调而来的对话生成大模
,通过人类反馈学习微调而来的对话生成大模,而是以自然语言为交互的通用语言处理平台。
>>>>超出预期的交互体验
>>>>通用的意图理解能力
>>>>强大的连续对话能力
>>>>智能的交互修正能力
>>>>较强的逻辑推理能力

ChatGPT以产品为导向,众多技术与成果的集大成者
大模型技术与人类反馈强化学习融合,实现知识逻辑涌现和人类价值观模拟,探索出了发展通用人工智能新路径,成为真正改变AI领域重大突破

大模型从单模态迈向多模态成为必然
面向图文音数据的多模态预训练模型是利
用全网多模态大数据来实现类人多模念感认知的重要途径,有望推动语音、语言、视觉等多领域协同发展
>>多模态数据无处不在:互联网90%以上是图像与音视频数据,文本不到10%
>>多模态协同更符合人类感知与表达方式:让机器实现类人“看懂、听懂、能说、会读”

多模态预训练的研究进展—当前怎么做?

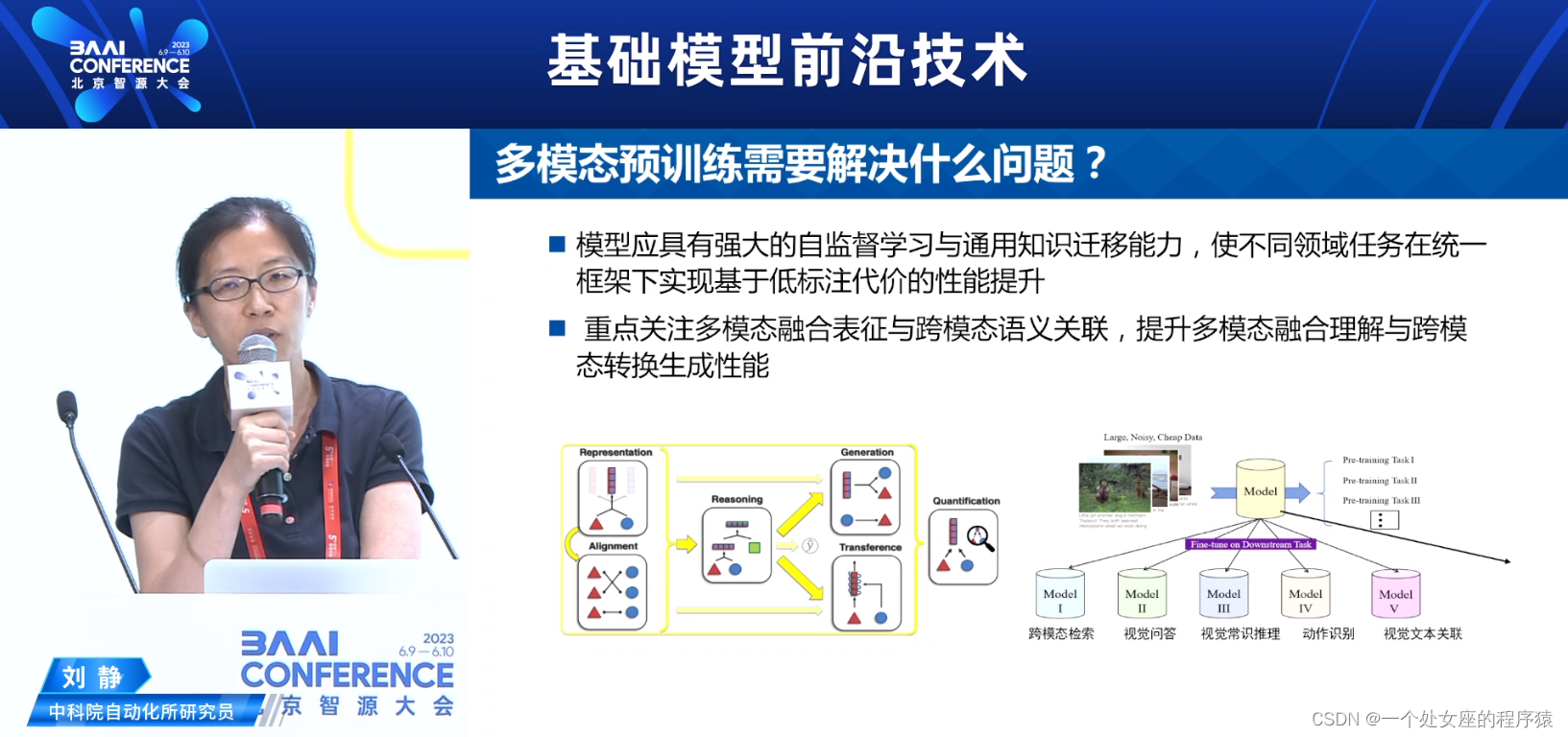
多模态预训练需要解决什么问题?
模型应具有强大的自监督学习与通用知识迁移能力,使不同领域任务在统一框架下实现基于低标注代价的性能提升
重点关注多模态融合表征与跨模态语义关联,提升多模态融合理解与跨模态转换生成性能
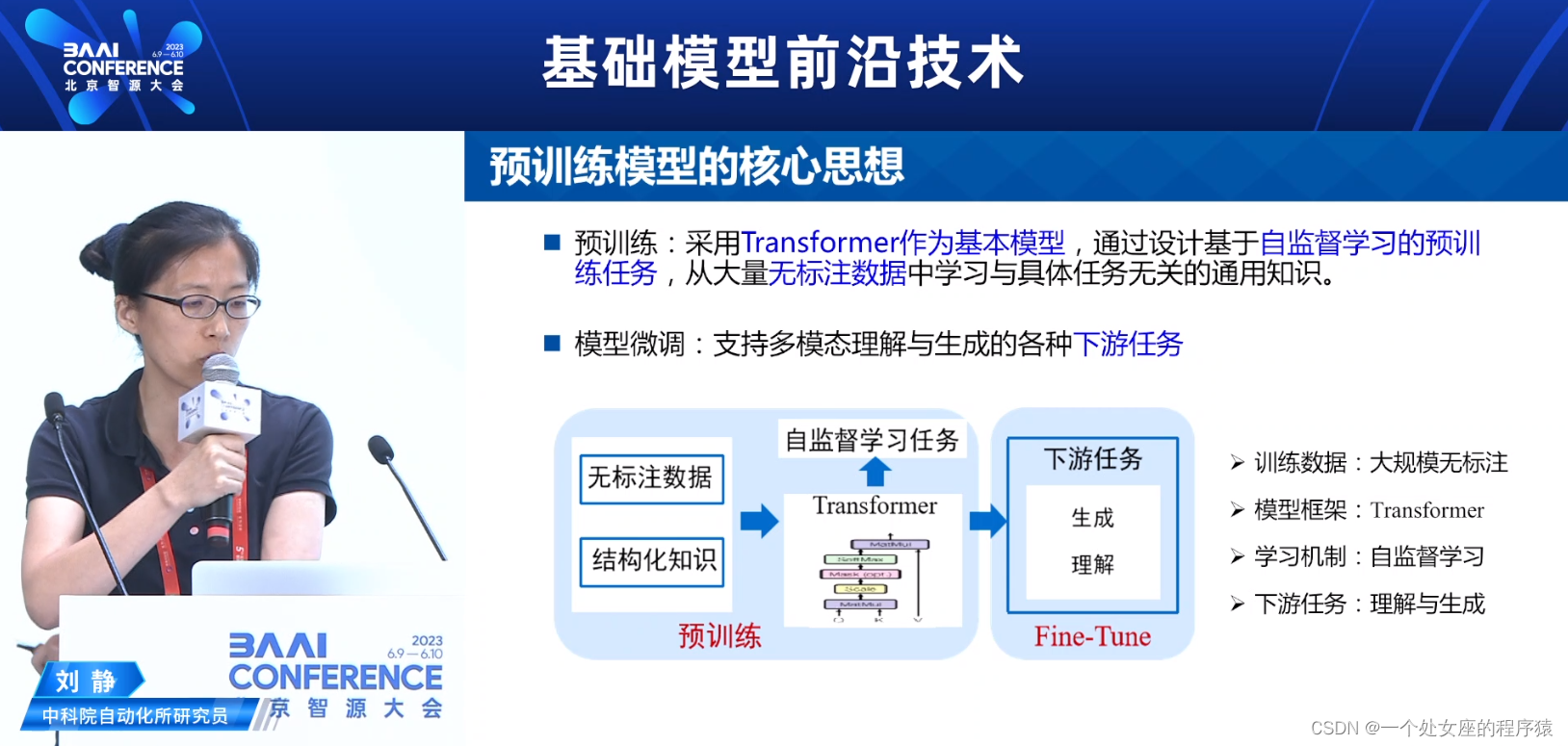
预训练模型的核心思想
预训练:采用Transformer作为基本模型,通过设计基于自监督学习的预训练任务,从大量无标注数据中学习与具体任务无关的通用知识。
>>>>训练数据:大规模无标注、结构化知识
>>>>模型框架:Transformer
>>>>学习机制:自监督学习
模型微调Fine-Tune:支持多模态理解与生成的各种下游任务
>>>>下游任务:理解与生成
多模态预训练数据集
无标注成本的网络数据
>>图像文本数据:图像及其相关文本(标签、描述、评论等)
>>视频文本数据:视频及其相关文本(标签、描述、字幕、语音等)
>>音频文本数据

万级别强关联人工标注→百万/亿级别弱关联无标注

多模态预训练—基础模型Transformer
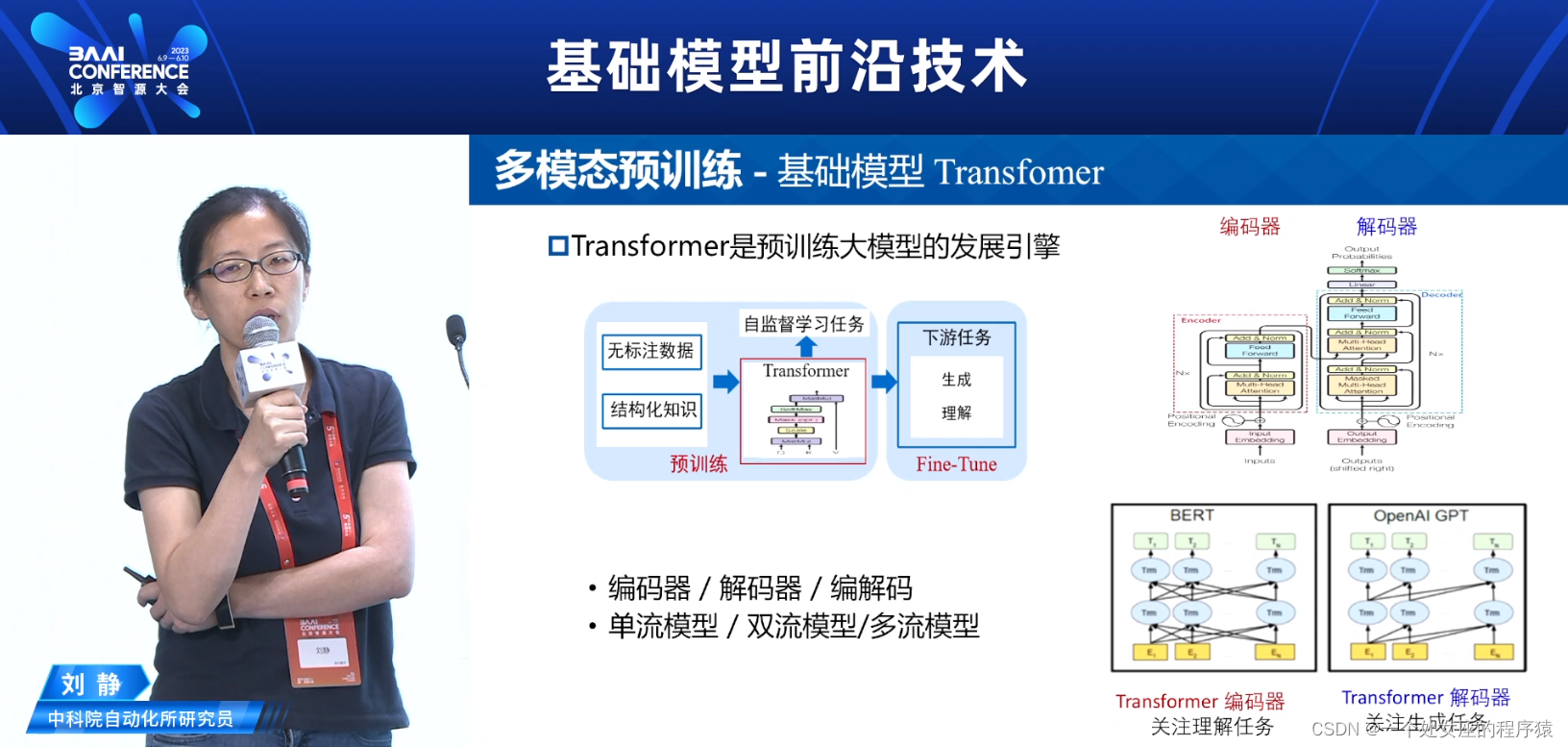
基于Transformer Encoder—理解任务
单流:视觉和文本模态一起输入编码器,代表性工作有VL-BERT,UNITER
双流:视觉和文本模态先单独编码,然后跨模态交互,代表性工作有ViLBERT,CLIP

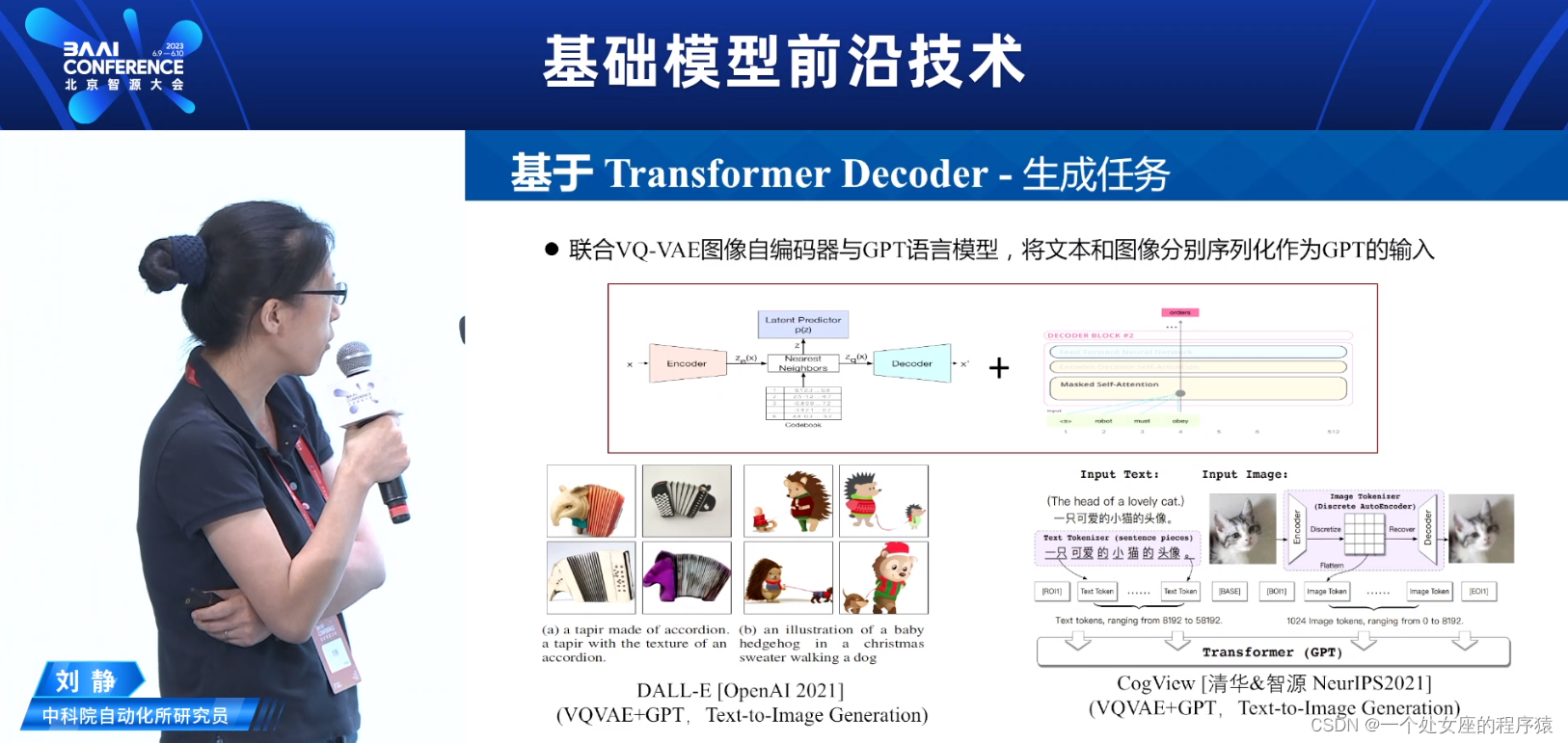
基于Transformer Decoder—生成任务
联合VQ-VAE图像自编码器与GPT语言模型,将文本和图像分别序列化作为GPT的输入
基于Encoder + Decoder—理解+生成
通过decoder更好的学习不同模态之间关联关系,提升理解判别能力

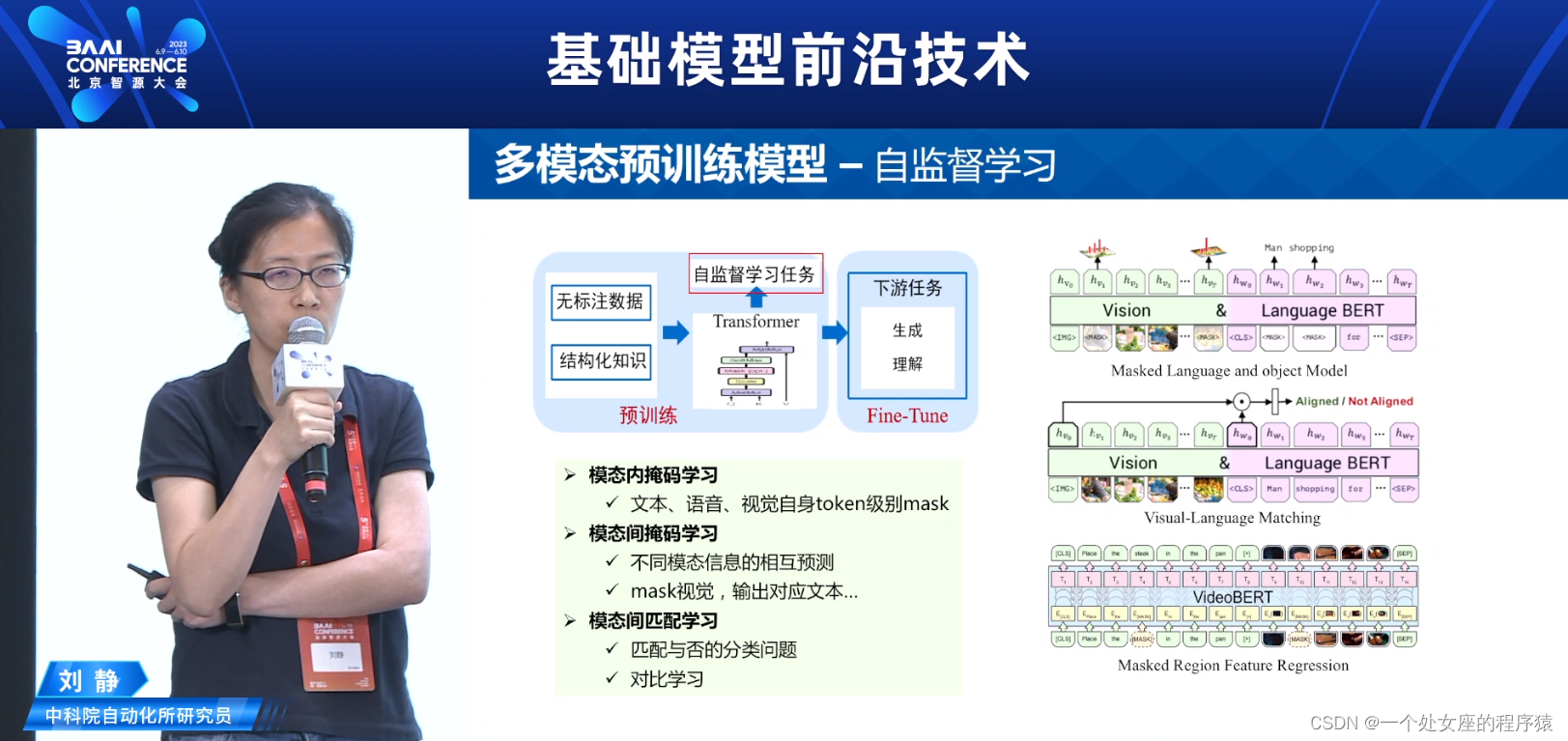
多模态预训练模型-自监督学习
>>模态内掩码学习
>>>>文本、语音、视觉自身token级别mask
>>模态间掩码学习
>>>>不同模态信息的相互预测
>>>>mask视觉,输出对应文本..
>>模态间匹配学习
>>>>匹配与否的分类问题
>>>>对比学习
多模态下游任务—模型微调
>>预训练模型的最终目标是提高下游任务的性能
>>如何将预训练模型强大的表示能力迁移到特定数据下的特定任务中,显得尤为重要
>>模型微调
√ Pretraining+ Finetune
√Pretraining+Prompt-Tuning
√Pretraining + Adaptor-Tuning
√Pretraining +LoRA
>>多模态下游任务
√生成:文本/语音/视觉内容生成
√理解:跨模态检索/问答/推理

更大更强的多模态预训练模型

更大更强的多模态预训练模型
>>强大的语言模型:预训练时尽可能冻结语言模型,保留原模型知识
>>更大的视觉模型:利用大规模的图文弱关联数据以及图像数据
>>更大规模的预训练数据:大量图像-文本、视频-文本以及网页数据
>>更多模态形式的数据:图像、视频、音频、文本、红外、雷达。。。

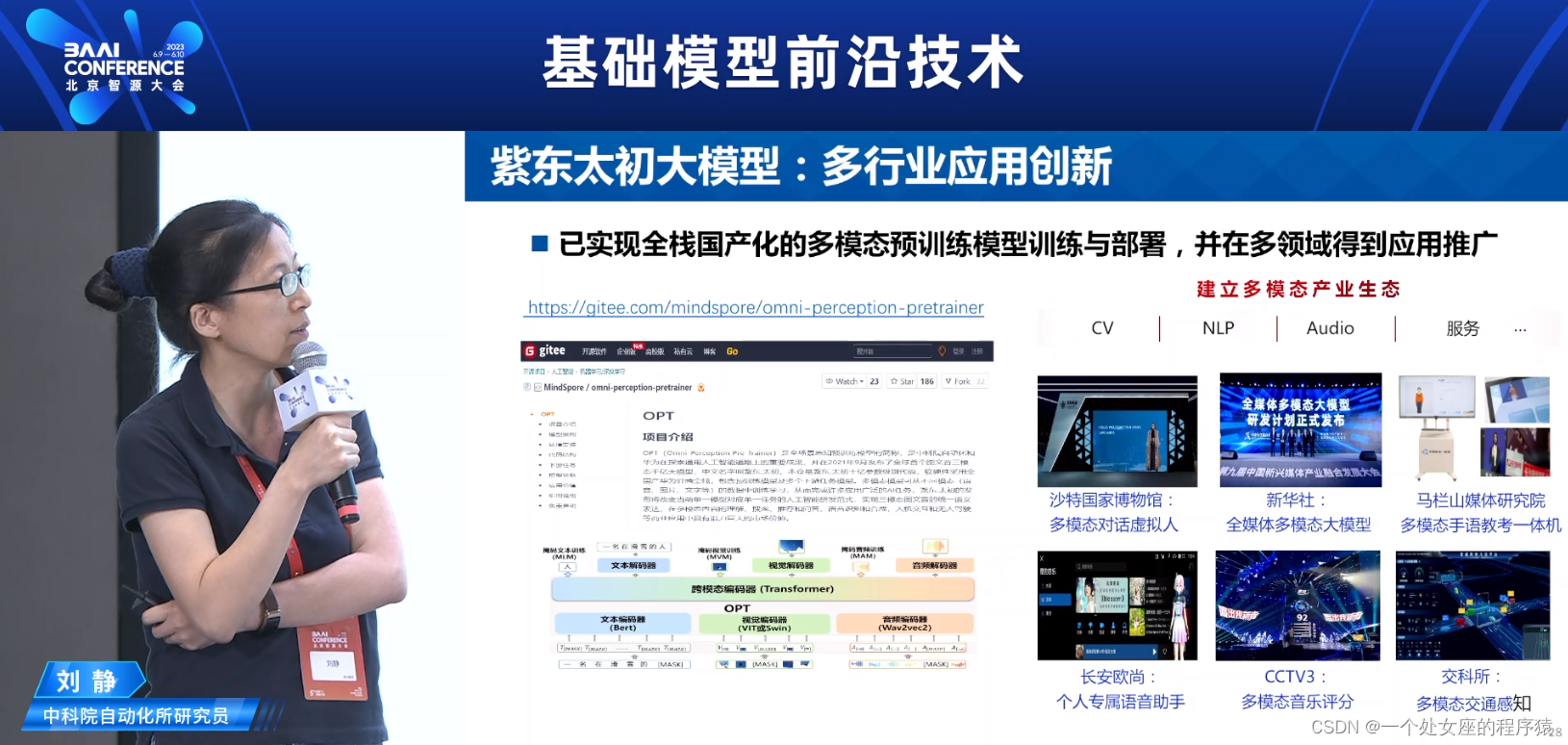
图文音三模态大模型-紫东太初
国际首个千万级规模图文音多模态数据集在图文/文音/视频等20+下游任务数据集上取得SOTA


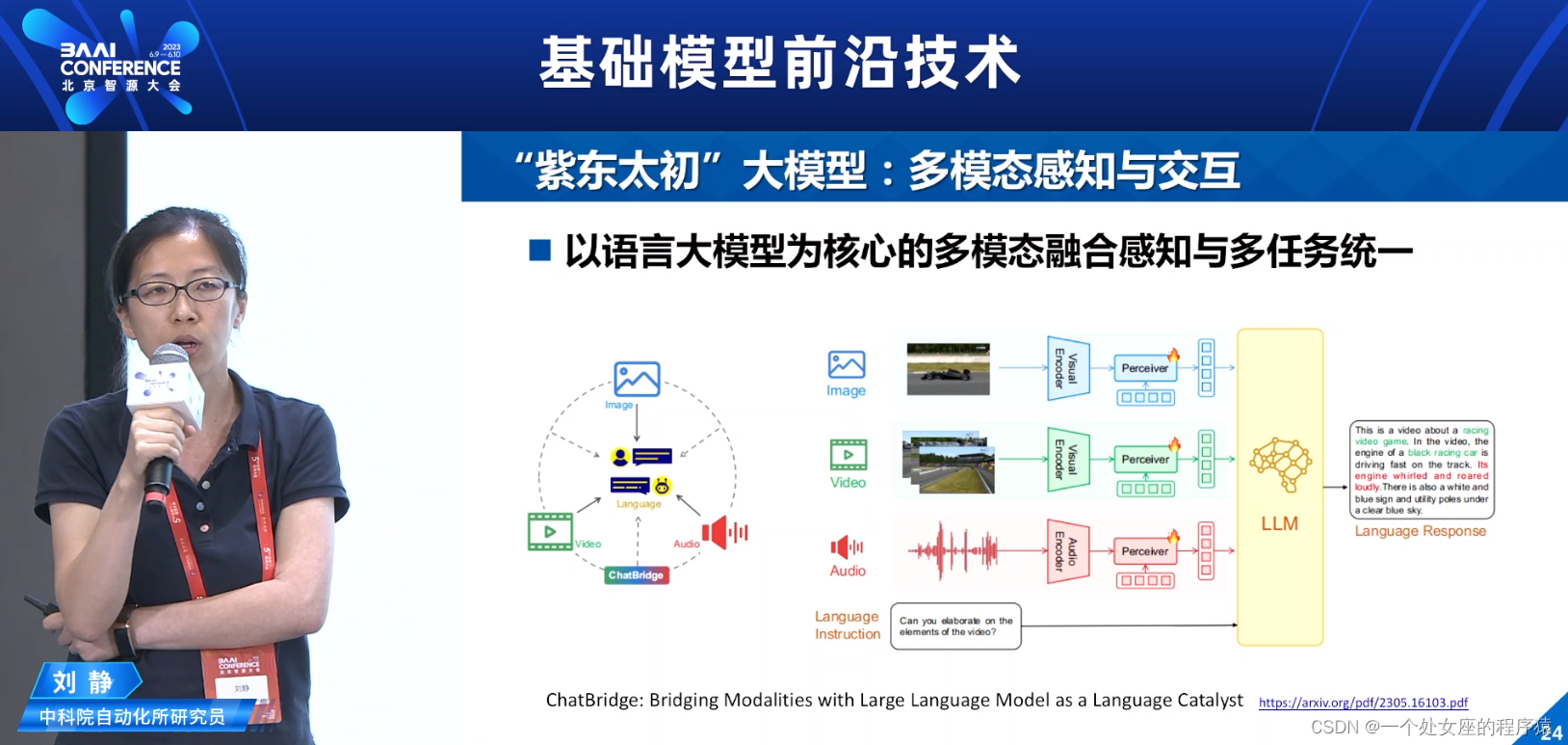
“紫东太初”大模型:多模态感知与交互
以语言大模型为核心的多模态融合感知与多任务统
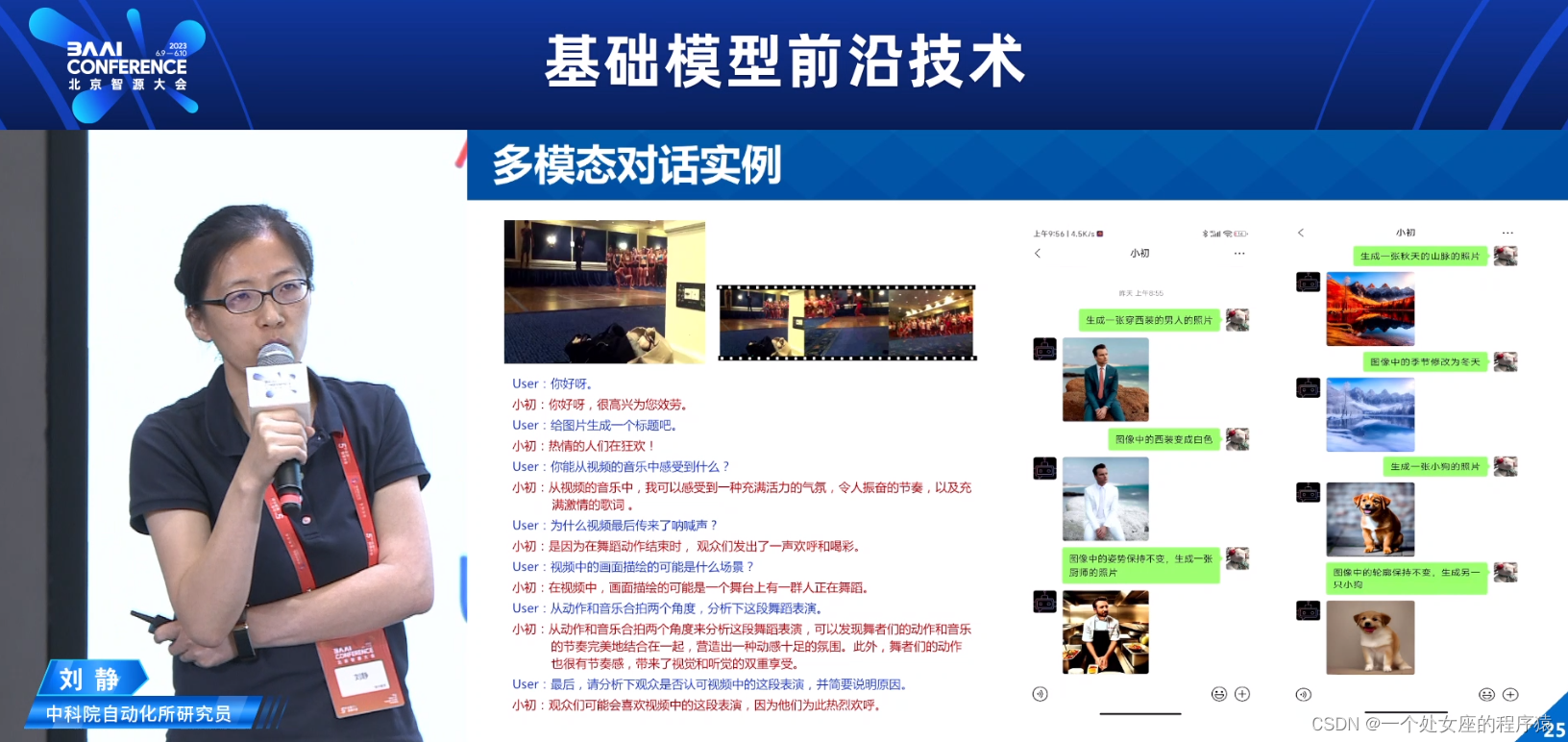
多模态对话实例
多模态关联分析实例

多模态描述实例

紫东太初大模型:多行业应用创新
多模态预训练的几点思考—以后怎么做?
几点思考
“大数据+大模型”简洁粗暴但有效的路子还未走到尽头,但终将走到尽头
●大规模、高质量的预训练数据
>>构建大规模不同模态间的对齐数据(弱监督、半监督)>引入知识来筛选大数据
●高效计算的大模型网络结构
>>改进或替代Transformer的高效模型
>>超大规模模型分布式并行训练
>>与下游任务兼容的更优模型
>>显示知识嵌入与隐式知识学习

●适合多模态关联建模的自监督学习
>>单模态、部分模态、全模态混合训练
>>如何实现多模态信息之间更细粒度的对齐建模
>>联合无监督强化学习,引入环境反馈

●预训练模型的下游应用与迁移能力
>>模型压缩与推理加速为特定场景应用提供可能
>>多模态应用更为丰富,如何拓展更多创新下游应用


后ChatGPT时代人工智能科研方向
>>研究大模型∶
大模型的原理、能力来源、可解释可控性研究;探索大模型的能力边界;研究大模型的能力外延和拓展
>>利用大模型
赋能各个研究任务和研究方向,例如赋能科学研究AI4Science,赋能各行各业AI+
>>治理大模型:
让大模型的发展安全可信可控,确保隐私安全,符合人类根本利益,防止其做出危害人类、破坏社会发展的事情

后ChatGPT时代的多模态大模型
>>未来AGI必然是与人类智能相仿,高效协同的多模态智能
>>从多模态信息中学习知识,实现不同模态之间的知识迁移、相互补全、相互验证。
>>充分利用现有语言大模型的认知推理能力,构建通用、安全、可信的多模态大模型
>>上下游任务与所有可能的技术路线之间,将进行各种形式的排列组合拼插,多模态应用创新层出不穷
>>>>跨模态的知识挖掘
>>>>多模态信息展示生成(如产品、年报、课程、演讲)
>>>>多模态融合理解与推理(图文试题、读书看报)
>>>>虚拟现实/混合现实中的自动内容创建
>>>>领域虚拟角色(如虚拟导购、虚拟教师)
>>>>多模态感知决策一体化的新一代机器人技术

15:35-16:20—《Scaling Large Language Models: From Power Law to Sparsity扩展大型语言模型:从幂律到稀疏性》周彦祺
T5作者之一,谷歌研究科学家
LLM Scaling: From Power Law to Sparsity

Agenda议程
01 Moore's Law and Power Law摩尔定律和幂律
02 T5: Unified Text-to-Text Transformer T5:统一的文本到文本转换器
03 Scaling LLM with MoE 使用MoE扩展LLM
04 Advanced MoE techniques 先进的MoE技术
05 Q&A

01 Moore's Law and Power Law 摩尔定律和幂律

The End of Moore's Law摩尔定律的终结
Gordon Moore postulated that the number oftransistors that can be packed into a givenunit of space will double every two years.
Nowadays we are reaching the physicallimits of Moore's Law because the hightemperature of transistors makes it impossible to create smaller circuits.
Of course, chips performance are not justbounded by transistors, but also bounded bymemory bandwidth (memory wall), andother reasons...
戈登·摩尔提出,在给定空间中可以装入的晶体管数量每两年翻一番。
现在我们正接近摩尔定律的物理极限,因为晶体管的高温使得创建更小的电路成为不可能。
当然,芯片的性能不仅受到晶体管的限制,还受到内存带宽(内存墙)等其他原因的限制。

Power Law Rules Deep Learning幂律规则深度学习

Exploring the Limits of TransferLearning with a Unified Text-to-Text Transformer通过统一的文本到文本转换器探索迁移学习的极限

02 T5:Unified Text-to-Text Transformer T5:统一的文本到文本Transformer
Text-to-text Simply Works文本到文本的简单运作
将每个问题都定义为以文本作为输入并生成文本作为输出。
Formulate every problem as takingtext as input and producing text as output.

C4 DatasetC4数据集
从公开可用的Common Crawl获取源数据,这是一个网络爬取的数据集。
Common Crawl包含很多嘈杂的“网页提取文本”
数据集在外部是完全可用和可再现的
Source data from Common Crawl, a publicly-available web scrape.
>> Common Crawl includes very noisy "web extracted text"
>> Dataset is completely useable and reproducible externally
应用大量的过滤:
删除不以. , ! " ... 结尾的行
删除短行
删除带有不良短语(例如冒犯性词语,"服务条款","lorem ipsum"等)的行
在文档之间进行句子级去重复
等等
Apply lots of filtering:
>> Remove lines that don't end in . , ! " ...
>> Remove short lines
>> Remove lines with bad phrases (e.g. offensive terms, "terms of service"""lorem ipsum"...)
>> Sentence-level deduplication across documents
>> etc.
生成约750 GB的干净英文文本+其他语言中的大量文本。
yielding→~750 GB of clean English text + large amounts in other languages.

Experiment实验
we chose parameters and strategies to simplify the pipeline as much as possible.
我们选择参数和策略,以尽可能简化流程。

Objective目标

Model Architectures模型架构
Dark grey lines
correspond to fully-visible masking and light grey lines correspond to causalmasking.
深灰色线表示完全可见掩码,浅灰色线表示因果掩码。

Comparing High Level Approaches for UnsupervisedObjectives对无监督目标的高级方法进行比较

What should you do with 4x compute?有了4倍的计算能力应该做什么?
Training for longer, training a larger model, and ensembling all provide orthogonal boosts in performance
更长时间的训练、训练更大的模型和集成都可以提供性能上的正交增强

Scalling Up 扩展

Hitting and End of Dense Model Scaling密集模型扩展的极限

03 Scaling LLM with MoE使用MoE扩展LLM

Hitting an End of Dense Model Scaling达到密集模型扩展的极限
“GLaM: Efficient Scaling of Language Models with Mixture-of-Experts", Nan Du and others, ICML 2022.
“GLaM:用混合专家的方式有效扩展语言模型”,Nan Du等人,ICML 2022。

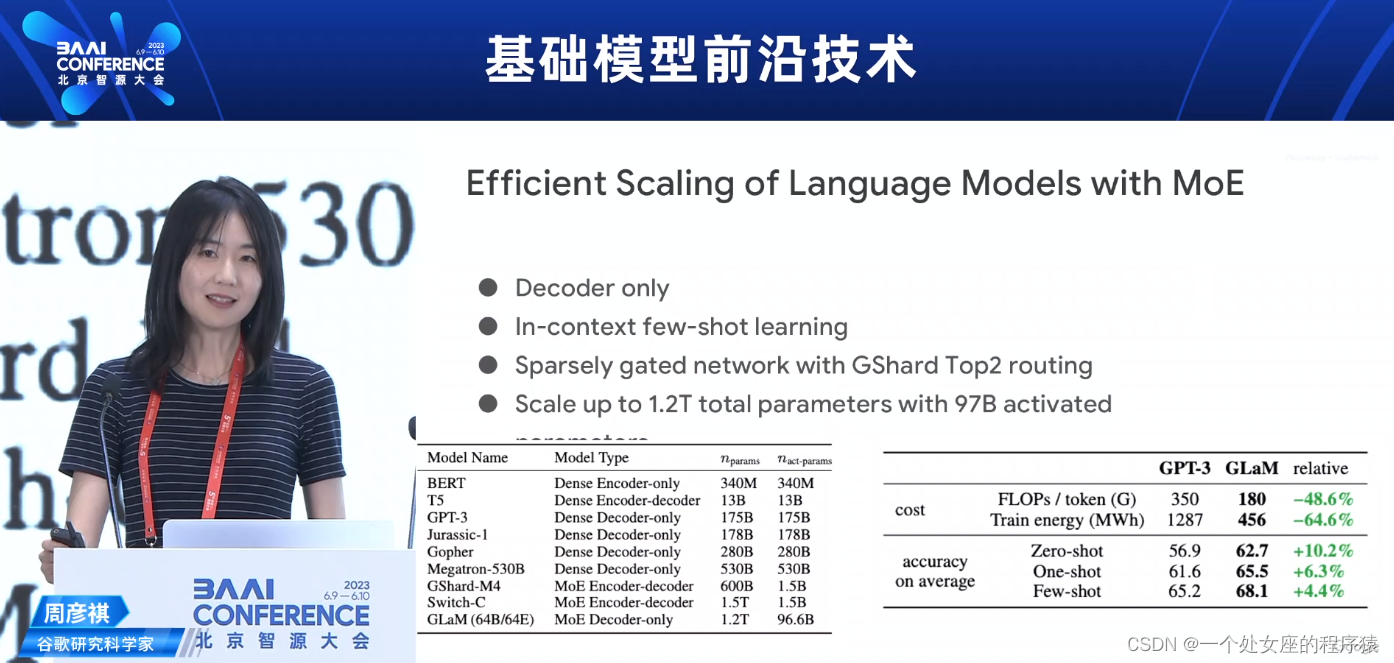
Efficient Scaling of Language Models with MoE使用MoE进行高效扩展语言模型
>>Decoder only
>>ln-context few-shot learning
>>Sparsely gated network with GShard Top2 routing
>>Scale up to 1.2T total parameters with 97B activated
仅解码器
ln-context少样本学习
使用GShard Top2路由的稀疏门控网络
总参数量扩展到1.2T,激活参数量为970B
GLaM Model Architecture GLaM模型架构
>>Sparsely activated FFNs
>>GShard top2 gating function
>>lnterleaving dense layers with sparselayers.
稀疏激活的前馈神经网络
GShard Top2门控函数
将密集层与稀疏层交替排列。

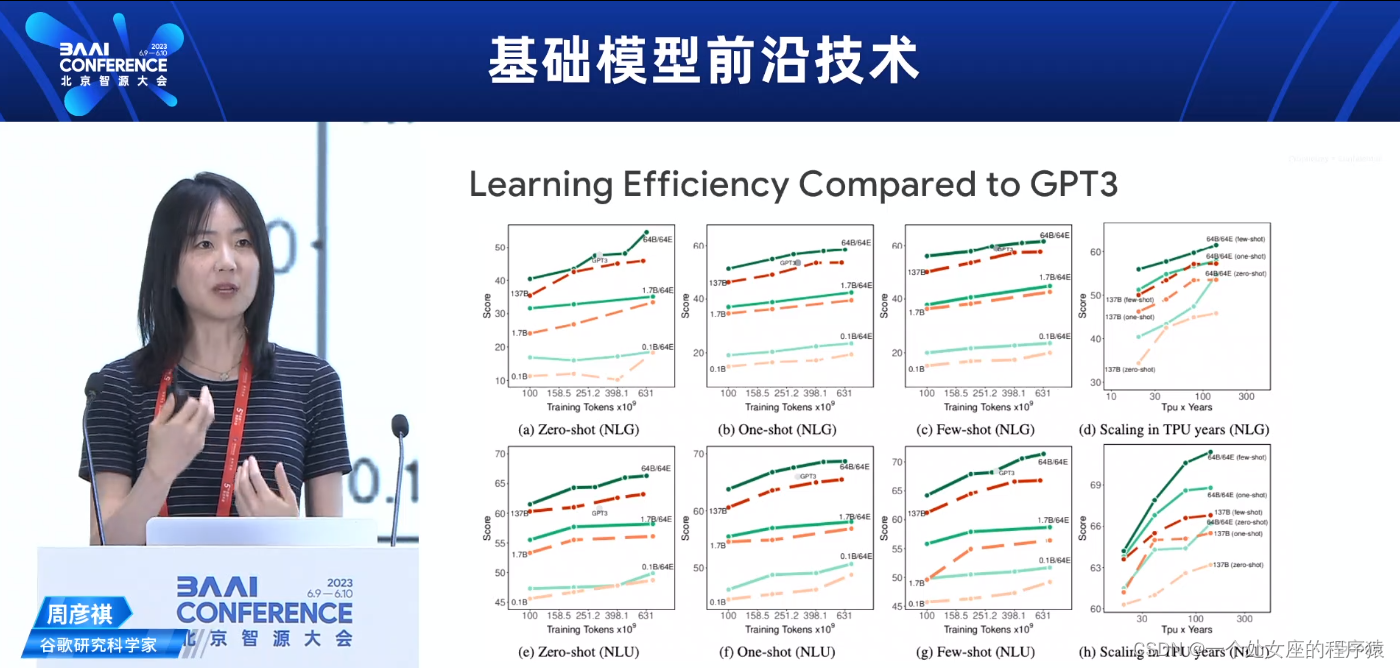
Few-shot Results Compared to GPT3与GPT3相比的少样本结果
Average few-shot performance on NLU and NLG tasks when scaling FLOPs (activated parameters)
在缩放FLOPs(激活参数)时的NLU和NLG任务的平均少样本性能

Learning Efficiency Compared to GPT3与GPT3相比的学习效率
Token-Based MoE hasLimitations...基于标记的MoE有局限性...

MoE with Expert Choice Routing具有专家选择Routing的MoE
>> Each expert selects top-k tokens independently.
>> Perfect load balancing
>> Tokens can be received by a variable number of experts.
每个专家独立选择前k个标记。
完美的负载均衡
标记可以由可变数量的专家接收。

Expert Choice Gather专家选择聚合

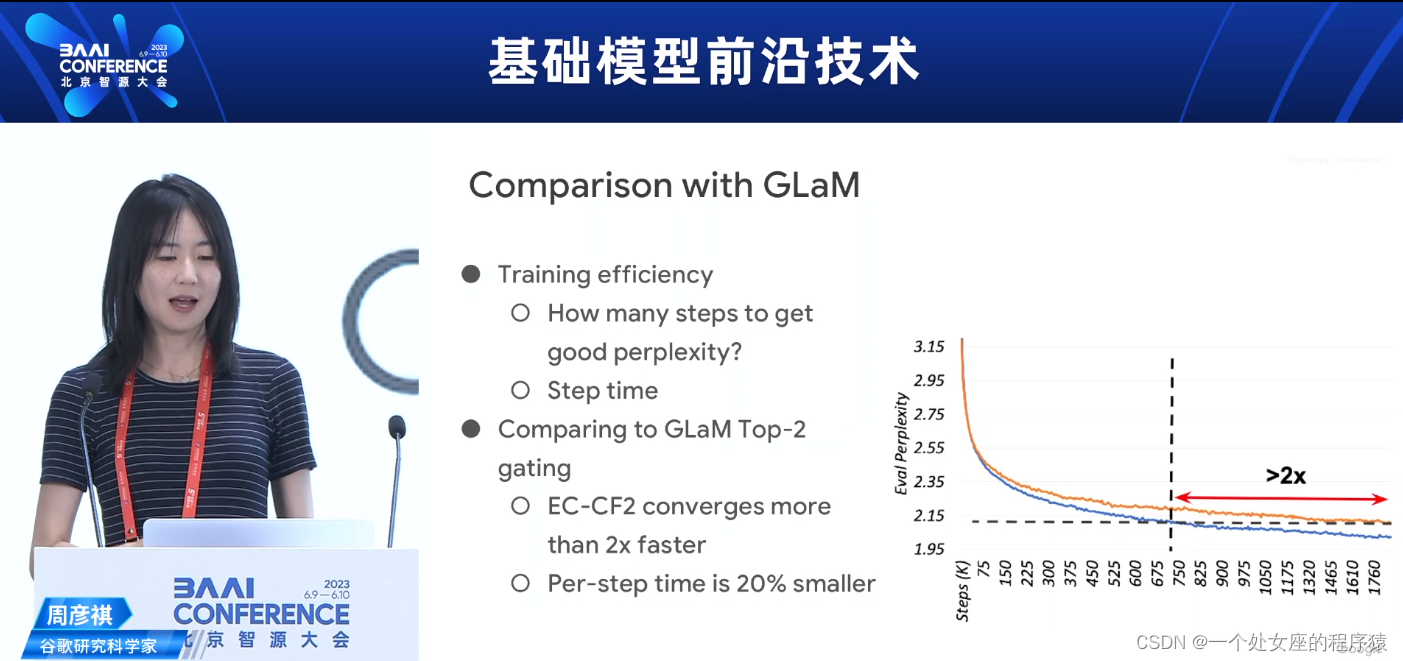
Comparison with GLaM 与GLaM的比较
训练效率
达到良好困惑度需要多少步骤?
步骤时间
>> Training efficiency
>>>> How many steps to get good perplexity?
>>>> Step time
与GLaM Top-2门控比较
EC-CF2的收敛速度比2倍快
每步时间减少20%
>> Comparing to GLaM Top-2gating
>>>> EC-CF2 converges more than 2x faster
>>>> Per-step time is 20%smaller
Comparison with GLaM 与GLaM的比较
基准:
>>Baselines:
>>>>Switch Transformer Top-1
>>>>GShard Top-2
>>lmproves average scores by 1-2%
>>8B/64E outperforms T5 11B dense
>>100M/32E has better fine-tuningperformance than 100M/64E or10OM/128E.
平均分数提高了1-2%
8B/64E的性能优于T5 11B的密集模型
100M/32E的微调性能优于100M/64E或10OM/128E。

04 Advanced MoE techniques先进的MoE技术

MoE architectures aresuboptimal...MoE架构是次优的...

Brainformers: Trading Simplicity for Efficiency Brainformers:以效率换取简单性
>>Existing MoE architectures scale poorly in terms of step time.
>>Propose a non-uniform architecture, rooting from low-rank, multi-expert primitives.
>>Demonstrate 2x faster training convergence and 5x faster step time than GLaM.
现有的MoE架构在步骤时间上扩展性差。
提出一种非均匀架构,以低秩多专家原语为基础。
展示比GLaM更快的训练收敛速度和更快的步骤时间,速度提升5倍。

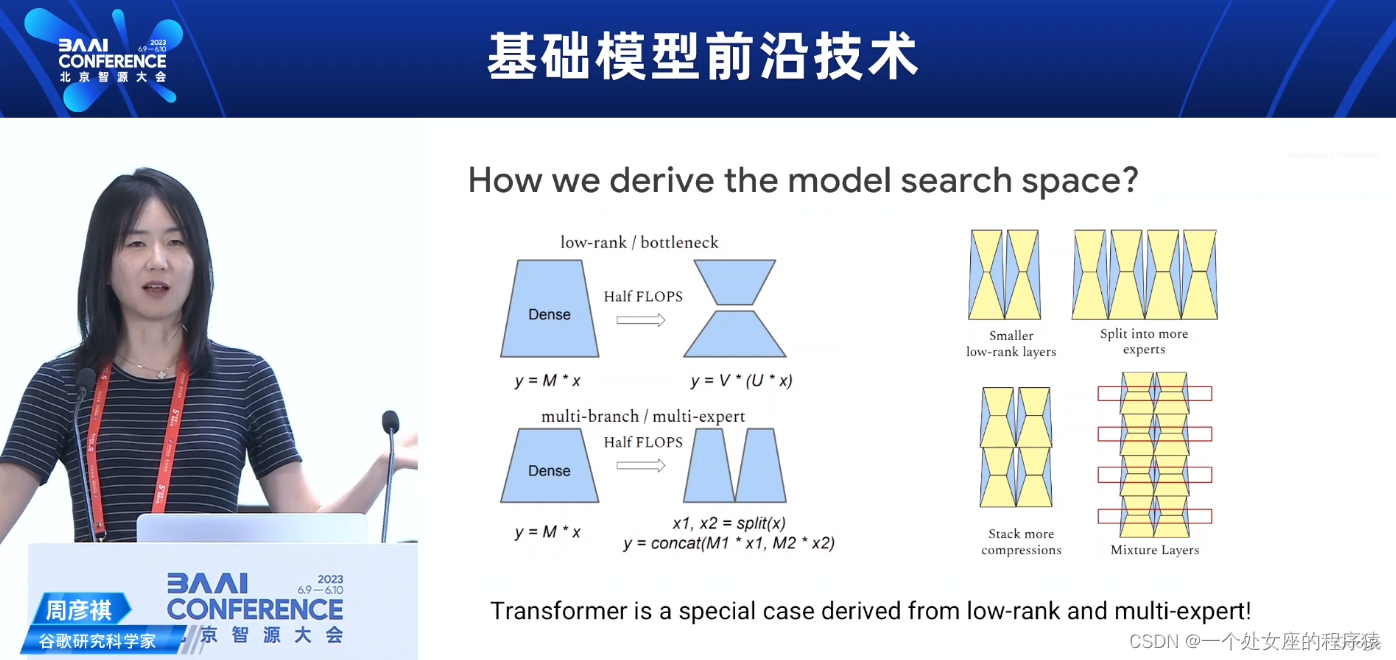
How we derive the model search space?我们如何得出模型搜索空间?
Transformer是从低秩和多专家派生出来的特殊情况!
Transformer is a special case derived from low-rank and multi-expert!
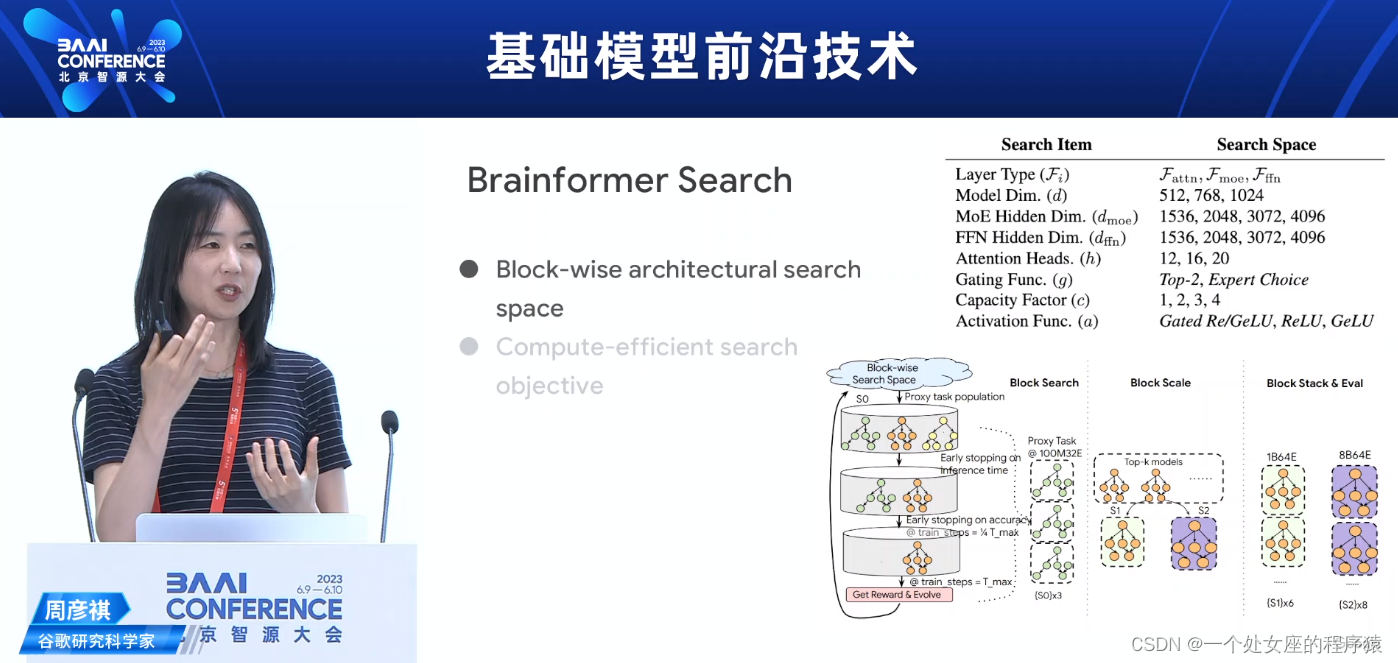
Brainformer Search Brainformer搜索
Block-wise architectural searchspace
Compute-efficient search objective
基于块的架构搜索空间
计算高效的搜索目标

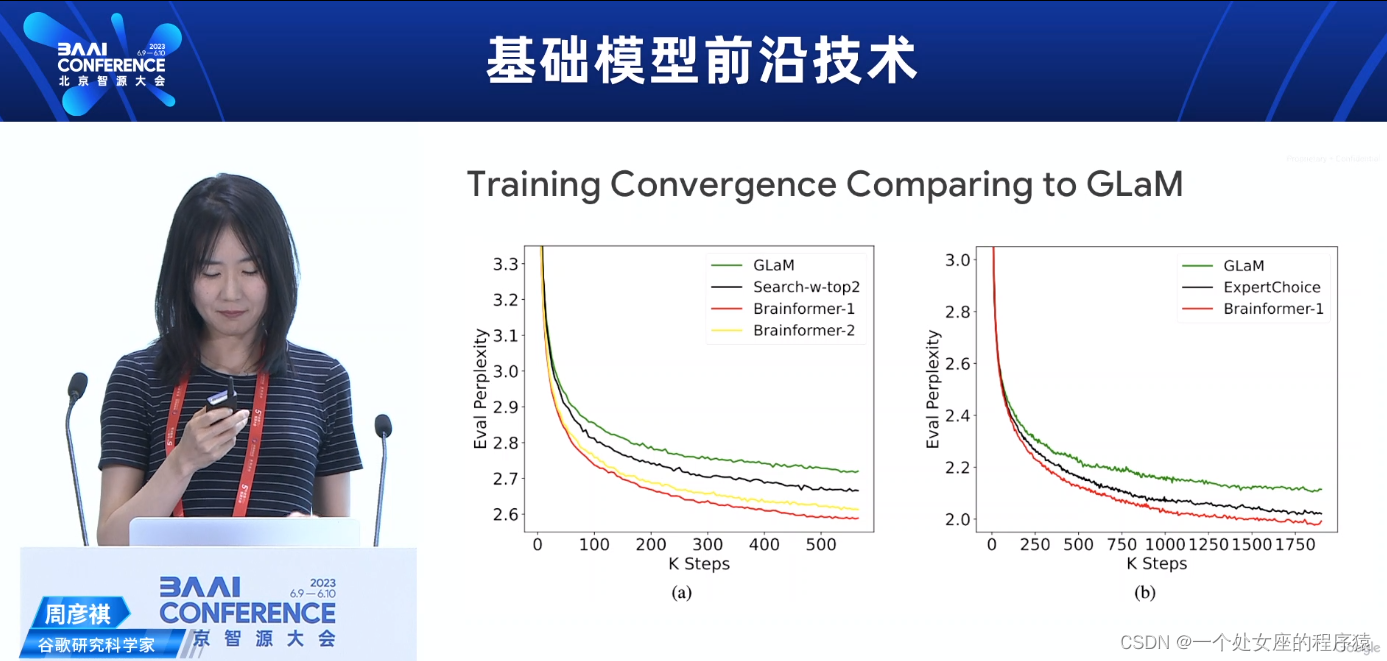
Training Convergence Comparing to GLaM与GLaM相比的训练收敛速度

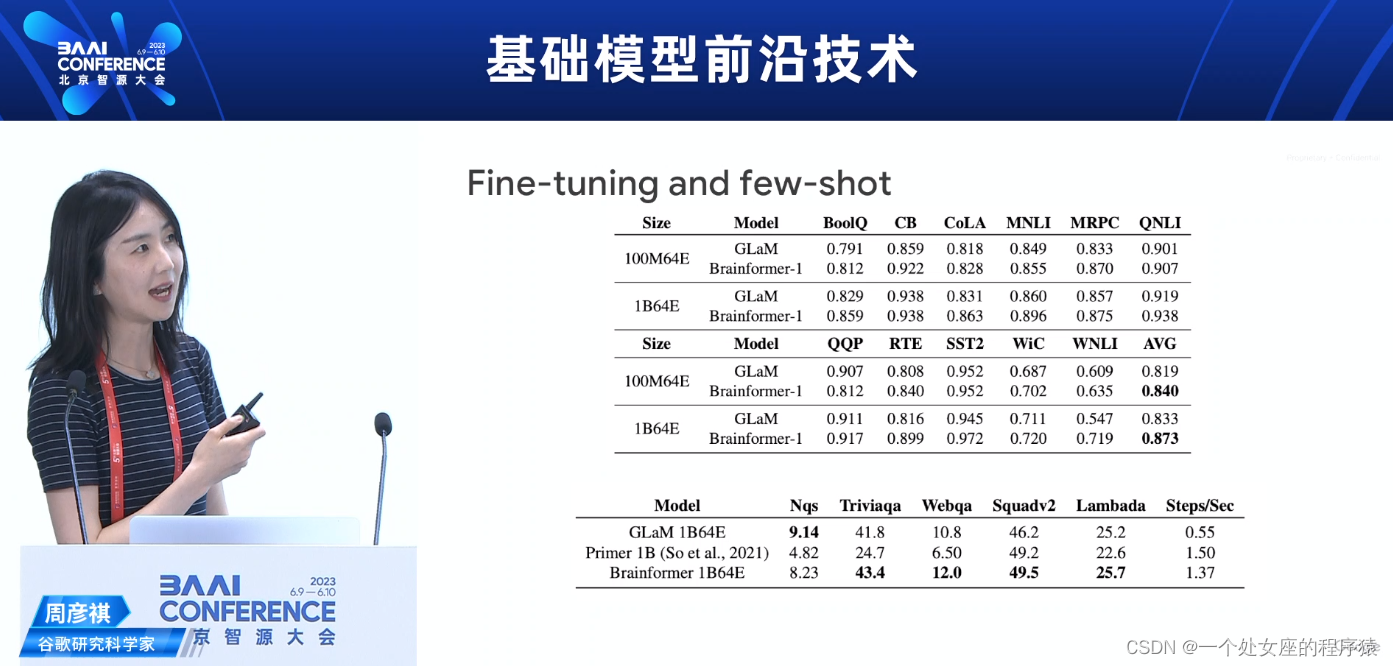
Fine-tuning and few-shot微调和少样本学习
LLM training isexpensive...LLM的训练成本高昂...

Motivation动机
>> Use case 1: temporal datasets
>>>> Keep datasets updated with language trends
Collect new samples every couple of months
Google search, forum, dialog, wikipedia, github, etc.
>>>> Train on large datasets is timelresource consuming
>>>> Train on new samples will be cheap
用例1:时间相关数据集
跟踪语言趋势,保持数据集更新
每隔几个月收集新样本
谷歌搜索、论坛、对话、维基百科、GitHub等等。
在大型数据集上训练耗时资源
在新样本上训练将更加廉价
>> Use case 2: general pretrainining dataset->datasets for dialogue
>>>> Need finetuning on a new mixture of dataset for a target domain, like chatbot.
>>>> There will be forgetting.
用例2:通用预训练数据集->用于对话的数据集
需要在针对目标领域的新数据混合中进行微调,比如聊天机器人。
会出现遗忘现象。

Forgetting遗忘
>> Distribution of original dataset: A
>> Distribution of new samples: B
>> Distribution shift A →B
>> Performance on both A & B matter!
>> >> Building general models is the trend.
原始数据集的分布:A
新样本的分布:B
分布从A到B发生变化
A和B上的性能都很重要!
构建通用模型是趋势。
>> "Forgetting issue": if we only train on B, performance on A willdrop
>> >> Assumption: new data comes in a sequence, we may not have "access" to old
data.
"遗忘问题":如果我们只在B上进行训练,A上的性能会下降
假设:新数据按序列进入,我们可能无法“访问”旧数据。

Lifelong Language Pretraining with Distribution-specialized Experts使用专门化分布的专家进行终身语言预训练
>> Distribution based MoE
>>>> Progressively add more experts for new data distribution
>>>> Add regularization to mitigate forgetting.
基于分布的MoE
逐渐增加更多专家以适应新数据分布
添加正则化以减轻遗忘。

Lifelong Pretraining on MoE:Distribution 、Regularization、Expansion MoE上的终身预训练:分布、正则化、扩展
>>Distribution A →B=c
>>>>Simulation on Tarzan:"A”= wiki/web,""B” = non-English,"C” = dialog
分布A → B=c
在Tarzan上进行模拟:“A”= 维基/网络,“B”= 非英语,“C”= 对话
>>“Regularization”
>>>>We don't want models to overfit B
>>>>We don't want model weights to be updated too far from A
>>>>Fit B, while regularize model from A
“正则化”
我们不希望模型过度拟合B
我们不希望模型权重过于偏离A
在适应B的同时对模型进行正则化
>>“Expansion”
>>>>Allow models to expand (expert) layers when fitting new distributions
“扩展”
允许模型在适应新分布时扩展(专家)层

Lifelong Pretraining on MoE:Expansion+Regularization MoE上的终身预训练:扩展+正则化
>>Expand experts for new distributions
>>Partially freeze old experts/gatings
>>Train with"Learning without Forgetting”(LwF) loss
为新分布扩展专家
部分冻结旧的专家/门控
使用“无遗忘学习”(LwF)损失进行训练

Forgetting ls Suppressed遗忘被抑制
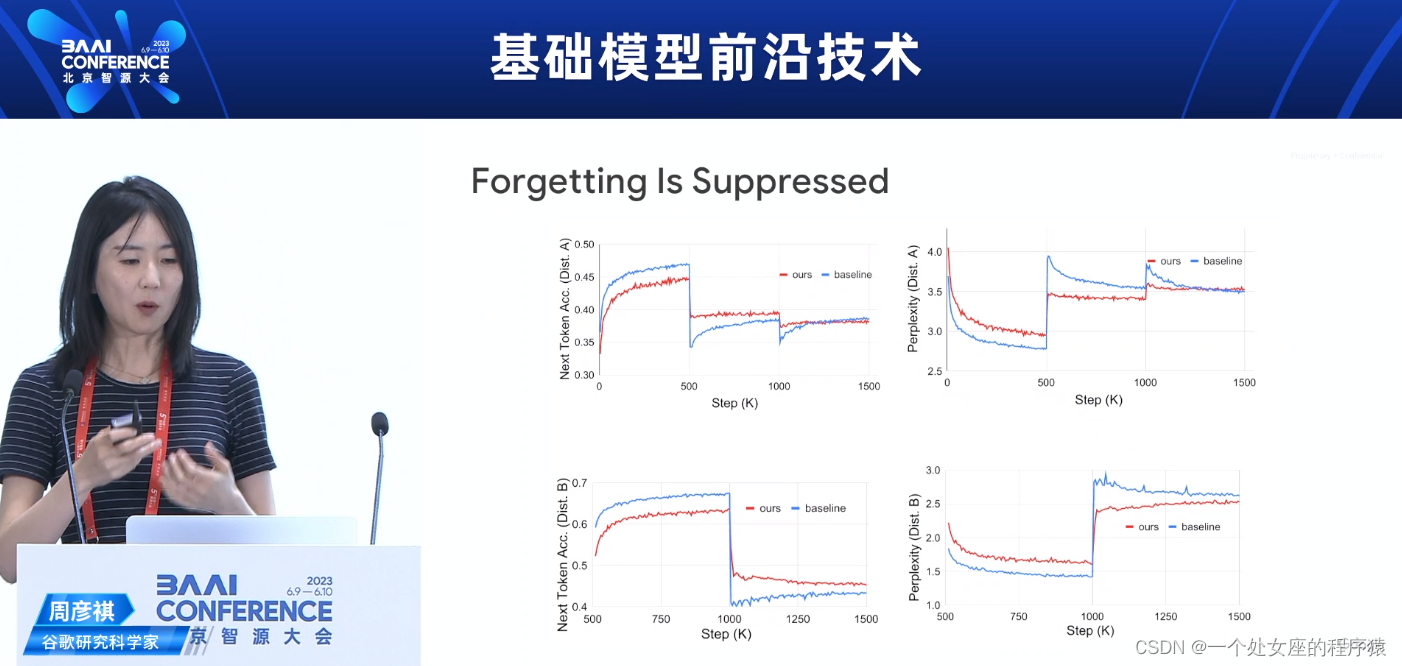
Final Results最终结果

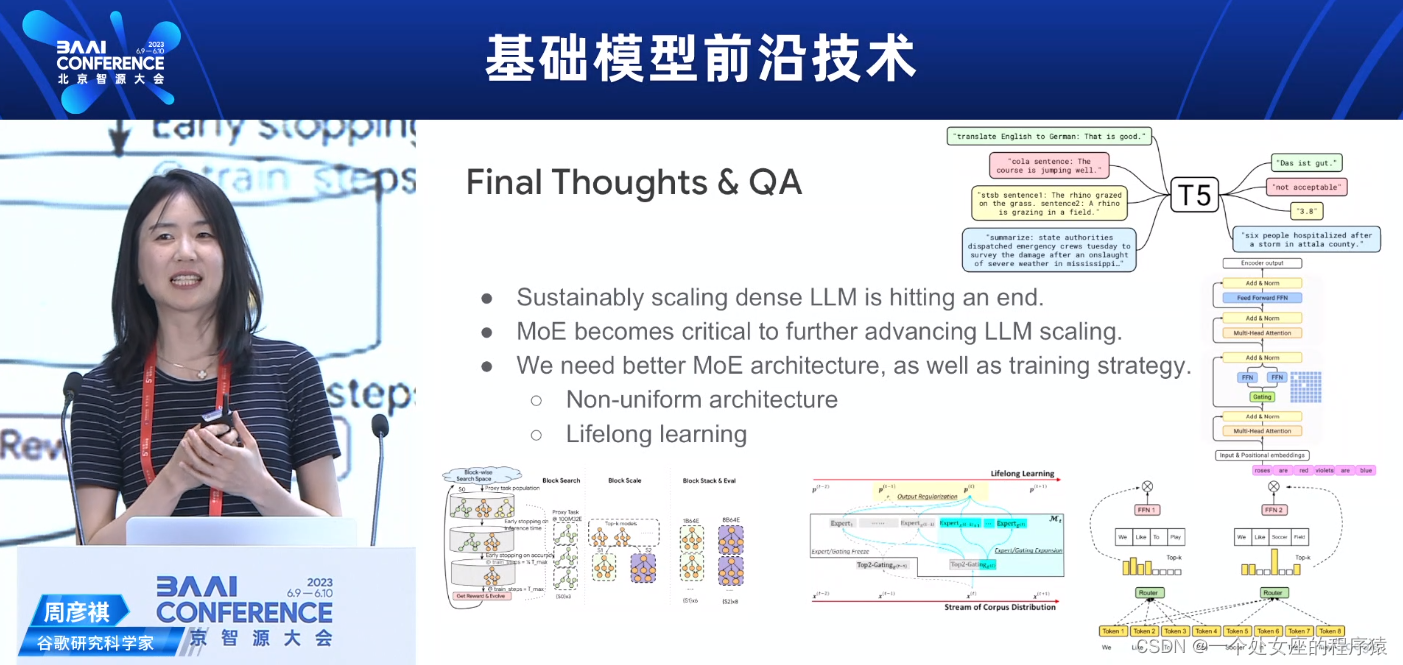
Final Thoughts & QA 最后的思考和问答
>>Sustainably scaling dense LLM is hitting an end.
>>MoE becomes critical to further advancing LLM scaling.
持续扩展密集LLM已经达到了极限。
MoE变得对进一步推进LLM扩展至关重要。
>>We need better MoE architecture, as well as training strategy.
>>>>Non-uniform architecture
>>>>Lifelong learning
我们需要更好的MoE架构,以及训练策略。
非均匀架构
终身学习
16:20-17:20—圆桌讨论
更新中……

