
- 106 Python numpy matplotlib 绘制立体玫瑰花_python绘制立体玫瑰花
- 2vmware升级处理vib包冲突的问题
- 3基于深度学习的自动车牌识别(详细步骤+源码)
- 4软件测试面试题汇总_界面测试题及设计题。请找出下面界面中所存在的问题并分别列出;用黑盒测试的
- 5超简单: nexus3.13 安装 ---Windows服务器安装过程和基本使用_nexus安装报错could not open scmanager.
- 62021年不可错过的40篇AI论文!
- 7element UI 中表单输入框的样式修改,深度选择器_element ui :deep修改分页器中输入框的大小css
- 8点击别处不让input光标消失_使用onclick但不影响光标
- 9博弈论-策略式博弈矩阵、扩展式博弈树 习题 [HBU]
- 10jQuery简单的翻书特效插件-jBooklet_html 使用jquery插件booklet实现左右翻页
【WEB搜索技术】课程学习大纲与学习感悟_web信息检索作业
赞
踩
WEB搜索技术课程大纲总结与学习感悟
1.导论
(1)Web搜索的定义
①Web搜索
是指在以环球网World Wide Web为典型代表的网络上检索、过滤和推荐信息的理论、方法、技术、系统和服务,也称网络搜索。
(2)Web搜索的发展背景
①搜索引擎
按其工作方式主要可分为3种:
1)全文搜索引擎(Full Text Search Engine)
2)目录索引类搜索引擎(Search Index/Directory)
3)元搜索引擎(Meta Search Engine)
(3)Web搜索的挑战性
①数据海量
②数据稀疏
③媒体多样
④大量并发请求
⑤数据特征演进——如话题的演变
⑥主观客观交叉
(4)Web搜索的科学价值
①Web搜索所研究的是一个崭新的科学问题
②Web搜索既要考虑信息的客观性,又要考虑信息的主观性。
③Web搜索强有力地带动了相关学科,特别是智能学科的发展
(5)1.5 Web搜索的研究状况
①理论研究
1)文本搜索,基于Markov过程的n-gram模型和Salton的向量空间模型(VSM:Vector Space Model)是目前普遍采用的特征表达模型。
2)而词频-倒文档频度法(TF-IDF)、信息增益法(IG)、CHI统计量法、互信息法(MI)等提供了有效的特征选择方法。
3)主成分分析(PCA)、线性鉴别分析(LDA)和奇异值分解(Singular Value Decomposition,SVD)等方法被用于特征降维,并衍生出了潜在语义索引(LSI:Latent Semantic Index)的重要概念。
4)贝叶斯分类器、支撑向量机、自组织映射、k近邻、以及向量相似度等模型提供了多样性的分类方法。
②语音搜索方面的研究
1)第一种技术路线是先利用ASR (Automatic Speech Recognition)技术将语音文档转换成文本文档,然后再用文本过滤的方法进行处理。
a.TDT测试中的技术就属于这一类。
b.这类技术的主要问题是系统的精度和速度受到语音识别的制约。
2)第二种是基于音频检索、语音关键词定位和语音鉴别(说话人识别、语种鉴别、性别鉴别等)等技术抽取语音文档的声学特征向量,然后进行内容识别和过滤。
a.这种技术直接针对内容识别和过滤的任务要求,有更深的研究潜力。关于Web语音内容过滤系统,在TDT技术体系之外,基于音频检索的技术比较常见。
③图像搜索的理论研究
1)此项研究与物体图像识别、计算机视觉等关系密切。
2)在物体图像识别和图像检索方面
a.提出了以星群模型(constellation model)、二维多分辩率隐马尔可夫模型(2DMHMM)和高斯混合离散余弦变换模型(GMM-DCT)等为代表的有效方法;
b.在视频检索和计算机视觉方面,镜头切分、故事切分、关键帧提取、场景分析、动态特征提取、视频聚类等关键技术已经取得许多突破。
2.搜索引擎基础
(1)搜索引擎体系结构
①文本这种信息媒体永远是最基本,也是最高级的
②Web文本检索涉及许多问题,主要包括:
1)Web信息采集、文本组织索引、文本内容表示、用户查询方法、相关文本排序、文本聚类、文本分类等。
2)文本的采集、组织和整理是文本检索首先要解决的问题
3)从某种意义上讲,Web信息检索的实质就是针对用户的查询请求,将所收集的文档按相关度由高到低顺序排列的过程。
4)文本聚类和分类是文本检索系统赖以提高质量和效率的关键技术
(2)信息采集子系统
①搜索器:
1)要尽可能多、尽可能快地搜集各种类型的新信息,还要定期更新已经搜集过的旧信息,以避免出现死链。
2)关注重点:
a.侧重用户需求:及时、数量多、有用
b.侧重搜索引擎系统需求:高效
c.收集的内容:网页、链接关系
②两种搜集信息的策略:
1)从一个起始URL集合开始,顺着这些URL中的超链接(Hyperlink),以宽度优先、深度优先或启发式方式循环地在互联网中发现信息。它沿着任何网页中的所有URL“爬”到其他网页,重复这个过程,并把搜集到的所有网页存储起来。
2)将Web空间按照域名、IP地址或国家域名划分,每个搜索器负责一个子空间的穷尽搜索。
③性能需求
1)及时性Freshness:
a.不同的数据源,更新频率不同
a)分钟级:微博、新闻门户网站
b)日级:博客
b.累积式抓取 (cumulative crawling)
a)实时性要求低,通常用于索引的建立
b)耗时较长 (百度:1个月左右)
c)依据互联网链接结构进行抓取
c.增量式抓取 (incremental crawling)
a)实时性要求高,通常用于索引的更新
b)随时进行 (Google 新闻:分钟级)
c)依据链接结构进行抓取,也可以进行定向抓取
2)全面性 quantity
3)高效性 effectiveness
(3)内容索引子系统
①索引器:
1)分析索引系统程序对收集回来的网页进行分析,提取相关网页信息
a.网页所在URL、编码类型、页面内容包含的关键词、关键词位置、生成时间、大小、与其他网页的链接关系等
2)根据一定的相关度算法进行大量复杂计算,得到每一个网页针对页面内容中及超链接中每一个关键词的相关度(或重要性),然后用这些相关信息建立网页索引数据库。
②常见的存储结构
1)顺序存储方法:顺序存储方法是将数据在物理位置上进行连续的存储。
2)链接存储方法:链接存储方法不要求数据在物理位置上连续存放,各个数据结点之间用指针进行连接。
3)索引存储方法:索引表由若干索引项组成。索引项的一般形式是关键字、地址。
4)散列存储方法“”该方法的基本思想是;根据结点的关键字直接计算出该结点的存储地址。散列存储类似于Hash表,即根据记录中的关键字特点设计一种Hash函数(也叫散列函数)和处理冲突的方法来确定记录的存储位置,将记录散列在存储介质上,这样的文件被称作散列文件。
③文本的索引:
1)为了提高查询速度,最好对网页中所包含的所有词汇(term)都建立索引,指出它所在的网页和位置。
2)倒排文件(inverted file)就是实现这类全文索引的一种流行技术。
a.词汇表(vocabulary) :文本中所有不同词汇的集合。
b.位置表(occurrences):由词汇在文本中出现的地址列表(posting list)构成,每个词汇一个列表。
c.在多文档的情况下,词的地址列表由文档标识符和文档内的位置(从文档头开始的偏移)构成。
(4)内容检索子系统
①检索器:
1)根据用户的查询在索引库中快速检出文档,进行文档与查询的相关度评价,对将要输出的结果进行排序,并实现某种用户相关性反馈机制。
2)主要过程如下:检索器对用户接口 UI(User Interface)提出的查询要求进行递归分析,在 UI中一般采用基本语法来组织要检索的条件。
3)理解并按照用户的信息需求进行查询与文档的内容相关性计算
(5)链接分析子系统
①目的:评价网页质量
②2个公认的准则
1)各个网页都希望链接到高质量的其他网页
2)高质量网页具有更多的入链
3.信息采集*
(1)网页采集系统体系结构
①基本功能:无序->有序
②典型的采集子系统架构:
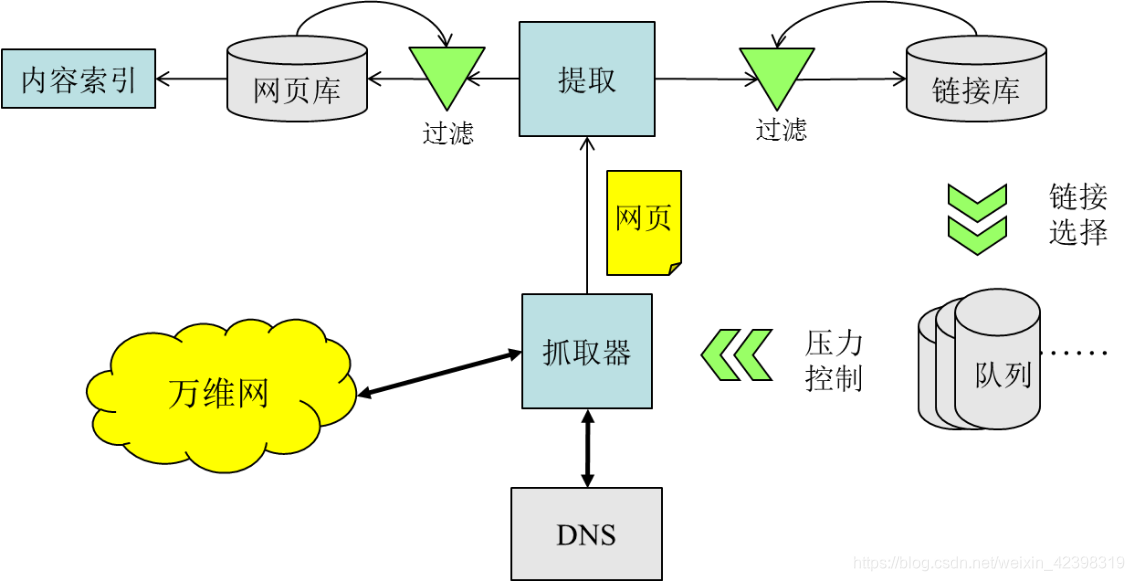
③网页采集子系统:
1)采集子系统
a.采集URL并组装plain-html页面
b.压力控制
2)选取子系统
a.决策采集的对象和顺序
3)过滤子系统
a.低价值page/link挖掘和控制
b.资源增长趋势、成本和效益估算
④如何评价采集子系统的性能?
1)全(Coverage) 新(Freshness) 快(Fast) 省(Efficiency)
2)常用性能指标
a.覆盖率:收录全部互联网有价值资源。
b.更新率:及时更新存储副本,和实际保持一致。
c.时效性:迅速发现和收录互联网上新发布的资源。
d.有效性:提高存储和采集的价值比例,节约成本。
e.其他:对站点友好,遵守公开协议和双方约定
(2)采集前端
①万维网中的各种应用协议
1)超文本传输协议(HTTP)
2)http://www.w3.org/Protocols/rfc2616/rfc2616.html
3)会话 = request + response
4)格式 = header+body
5)工具 = wget、libcurl、浏览器插件
6)方法 = GET/HEAD/POST …
7)其他:https,ftp,Usenet,email
②提升性能:
1)同步采集 v.s. 异步采集
a.异步I/O模型并不能减少单个页面的采集速度,但是大大提高了采集器的并发能力。
2)DNS预解析
a.DNS解析是重量级的操作
b.本地缓存经常被穿透
c.预存全部站点的IP记录
d.独立维护和更新
③采集控制:合作共赢
1)搜索引擎同时具有网站流量的生产者和消费者身份
a.生产者:为网站带来用户,提升影响和价值
b.消费者:消耗网站流量,带来带宽、服务器开销
2)Sitemap:协助搜索引擎了解网站内容
3)Robots.txt,meta robots:控制搜索引擎采集
4)Meta robots
a.可以提供页面级更精细的控制
b.支持多种语义,但不支持针对不同UA分别设置
c.noindex – 禁止检索这张网页
d.nofollow – 禁止采集该网页的出链
e.noarchive – 禁止保存快照
f.nosnippet – 禁止展示摘要
g.noodp – 禁止展示第三方(DMOZ)摘要
5)仅是建议标准,各大搜索引擎支持程度不同
④采集控制:压力控制
1)被动控制
a.网站针对搜索引擎的IP/UA封禁
a)服务器防攻击策略自动触发
b)管理员人为对spider进行封禁:Spider对站点访问量过大;Robots不知名,认可度差;有其他robots冒名顶替
2)主动控制
a.制定站点级别的压力上限
b.站点规模、质量;正常用户访问量;站点访问速度和访问时间等
(3)链接调度
①链接调度设计思路回顾
1)链式反应:以种子站点作为链接自我膨胀的起点。
a.知名站点的首页
b.网页目录资源:http://www.dmoz.org/;http://www.alexa.com/
②累积式采集
1)定期从种子出发开始扩散、完全替换
2)优点:实现简单,广度优先或者深度优先即可
3)缺点:周期长,代价大;时效性、更新率问题
4)适用范围:
a.网页快照库的初始化和重建
b.定向采集站点的档案收录
c.典型采集策略
d.广度优先、深度优先
③增量式采集
1)动态维护现有网页集合,在原来的基础上对新增和变化网页进行收集
2)优点:节约带宽资源
3)缺点:
a.策略复杂,难以确定理想的采集顺序。
b.采集目标多样,需要兼顾覆盖率,更新率,时效性需求。
4)适用范围:搜索引擎日常采集
5)链接调度策略的优化目标
a.已发现链接的采集
b.继续发现新的链接
c.已采集网页的更新
6)链接调度策略的约束条件:
a.站点压力控制,对外友好
b.有效性控制,避免浪费存储和带宽
④链接调度策略面临的挑战
1)多种采集需求争抢有限的流量
2)垃圾和无用内容充斥网络,不需遍历,提高收益
a.链接关系特征(PageRank, 链接文本, …)
b.页面特征:内容丰富程度,主题集中程度
c.站内分析:目录深度,URL模式
d.站间重复:镜像,转载次数
e.已有类似网页信息(同一网站、目录等)
f.用户行为信息(访问量、查询与主题相关度等)
g.对于采集新网页,只需考虑按重要性排序;对于更新旧网页,还要考虑合适的时机。
a)如何判断更新
b)HTTP头:Last-modified
c)页面内容:link、content
d)更新策略
e)更新周期的判断:泊松过程
f)统一更新策略和个性化更新策略
(4)重复与低质量检测
①重复与低质量检测的主要对象
1)空内容页(出错页面等)
2)功能性操作页面(登录页面等)
3)已失效页面或有权限限制
4)多种URL形式对应同一资源
②重复与低质量检测的必要性
1)我们到底需要多少索引?
2)索引量和搜索满意度之间的关系可以量化吗?
a.百度的实验结果:90%的需求仅通过10%的索引就能满足。
b.谷歌的实验结果:把当前索引量翻倍,对各项效果评估几乎没有提高。
c.没有被索引的网页,总能造出一些查询,使它是唯一满足的资源。
③重复页面内容检测
1)有规律重复:站内副本,站点镜像。
2)无规律重复:转载(允许)、采集(打压)。
3)算法
a.I-Match算法
b.Shingle算法
c.SImhash算法
④链接去重策略
1)做法:每采集一个URL,打一个标记.如何快速从URL集合众找到这个URL?
2)Hash:
a.Address=Hash(URL)
b.普通的Hash算法:难设计,冲突率很高
c.Bloom Filter——常用的算法
(5)网页解析
①HTML与DOM-Tree
②视觉分块
1)区域大小、位置
2)是否可见
③块语义和功能判断
④信息抽取
1)标题、主体、边框、链接
2)页面类型
3)作者、时间、导航
⑤主体内容识别
1)单页面分析
a.视觉信息
b.功能信息
c.Text/Tag比
d.Rule-based
2)多页面分析
a.页面模板聚类
b.找信息量最大的子树
(6)开源采集程序
①Nutch
采集,解析,索引构建(Lucene)
②Libcurl
③Wget
④Heritrix
(7)正则表达式
4.内容索引子系统
索引子系统的主要功能
完成从文本内容到词项的转换
提供高效、准确的索引查询服务
高效利用系统资源完成信息存储
重点:
系统和算法设计如何高效率的利用系统资源(有损优化/无损优化)
系统和算法设计如何与用户需求密切结合
系统和算法设计如何体现可扩展性
(1)词项(Term)的获取
①词项(Term)
1)索引子系统处理的最小语义单位
a.英文:以空格加以分割,从文本串切分为词项;其他处理:标点符号处理等
2)中文:需要分词过程;其他处理:编码识别、全、半角处理等
②词项的作用
1)作为语义的最小单位出现
a.需要符合网络数据/用户的表述习惯:芙蓉姐姐
b.有可能存在字面冗余(overlap)的情况:清华大学
2)作为倒排索引的索引项出现
a.选取合理的词项数目以高效利用系统资源
b.数目太大:词项编码长,冗余信息多,浪费空间
c.数目太小:词项对应的条目长,I/O压力大
③倒排索引结构
1)搜索引擎和信息检索系统组织文本数据的主要数据结构形式
2)与人类的长期记忆原理类似
3)适合于关键词查找的交互方式索引的数据结构
④英文处理
1)去除停用词(stop word)
a.停用词:出现频率高,语义信息量小的词
a)Be, of, the, …
b.在尽量保存有用内容的前提下,减少索引空间浪费,保证系统运行效率
c.极大精简索引结构:去除停用词后,倒排索引可以缩小40%,显著降低I/O负担
d.取词干(stemming)
2)词干(stem):删除词的词缀后剩余的部分
a.Compute, computer, computing => comput
b.同一词根的不同变形缩减为同一个概念
c.合并索引项:保证语义不变的情况下缩小索引规模
⑤中文处理
1)去除停用词:的,是,和,在
a.风险:停用词的歧义性 如:的确,和平,存在
b.不同搜索引擎处理策略不同
2)中文分词问题
a.分词就是将连续的字序列按照一定的规范重新组合成词序列的过程
b.基于词典的分词方法
c.基于理解的分词方法
d.基于统计的分词方法
3)中文分词中的技术问题
a.交集型歧义(overlapping ambiguity)
a)字符串ABC中,AB,BC同时为词
b)使用语言的过程基本上就是选词组句的过程
c)一些解决方案
i.合并成新词(词组)
ii.从语言习惯统计规律上看,哪种分割的可能性大
iii.在语境中,哪种分割方式造成的孤立字少
b.覆盖型歧义(combination ambiguity)
a)字符串AB中,AB, A, B同时为词
b)中华人民共和国,中国科学院
c)如何处理:多粒度分词
c.未登录词识别
a)词典不可能包括所有的词
b)人名、地名、机构名、新词
c)如何处理:对(新出现的)文本语料进行统计分析
⑥面向搜索引擎需求的分词技术
1)分词算法的时间性能要比较高
a.不能采用复杂的语法分析(如消岐算法)
2)分词正确率的提高不一定带来检索性能的提高
a.多粒度分词,适当引入冗余信息
3)未登录词识别的准确率比召回率更重要
a.未登录词往往与实体的名称相关联
4)采用与网络应用实际相匹配的用户词典
a.词典质量直接影响分词精度
5)多粒度分词
a.确保查询的语义扩展能力
6)用户查询的处理与网络数据的处理采用同样的分词方式
a.确保一定的容错性
⑦词项列表构建
1)词项数目的规模:Zipf’s Law (齐普夫定律)
a.有损优化:不必将所有词项加入内存中的词项列表,(在内存中)忽略最不常用的词项
(2)索引的数据结构
①原始数据需要存放
1)目的:防止存储索引的硬件崩溃
a.保证具备重建索引的能力
b.硬件崩溃时有发生,累计式抓取周期过长
2)存储结构与压缩
3)词项出现信息记录(Hit record)
a.给定文档,给定词项,记录词项在该文档中某次特定出现的信息
②索引结构
1)倒排索引
2)正排索引
3)并行存储结构
a.在有限的磁盘存储量限制下增加存储总量
b.在有限的磁盘I/O性能限制下增加索引吞吐效率
c.并行单元称为“桶”(barrel),“环”(circle)或“碎片”(shard)
a)按文档分桶
i.正排索引:直接访问对应DocID的桶
ii.倒排索引:访问所有桶,获得对应WordID的文档列表(不完整)和Hit lists 。每个Word的倒排索引可能有N个。
iii.按文档分桶优点:
每个桶可以独立处理查询请求 ii)每个桶可以保存文档的其他信息(如PageRank) iii)网络传输量小
(只需传输查询需求和对应的每个桶的查询结果)
iv.按文档分桶缺点:
i)需要等待所有桶处理完查询请求,以 避免重要文档丢失 ii)处理包含K个词项的查询,需进行O(K*N) 次磁盘查找操作
b)按词项分桶
i.每个桶包含1/N的词项,以及这部分词项对应的所有文档
ii.倒排索引:直接访问对应WordID的桶
iii.正排索引:访问所有桶,获得对应DocID的词项列表(不完整)和Hit lists
iv.按词项分桶优点:
i)对包含K个词项的查询
ii)至多需要K个桶共同进行处理
iii)只需进行O(K) 次磁盘查找操作
v.按词项分桶缺点:
i)网络传输量大(需要传输整个词项 对应的倒排表)
ii)需要在索引结构之外存储文档的 其他信息
(3)索引系统运行方式
①文档预处理
1)分配文档ID、HTML解析、锚文本重新定位、分词
②索引建立
1)构建正排索引
2)由正排索引构建倒排索引
③性能优化:索引压缩
1)优点:节约空间,有效利用I/O,增加硬盘寿命
2)缺点:额外占用计算资源,传统的压缩算法可能导致索引随机读写的困难
3)方案:主要针对位置信息进行压缩
④性能优化:缓存服务器
1)保存常用索引项
2)保存常用同现词项的文档列表求交结果
3)Google: 缓存命中率30-60%,
a.取决于索引更新频率,查询流特点等。
4)本质:时间局部性原理的存在
a.容易被缓存命中的查询词,经 常是热门的,同时也是资源消 耗量大的
5)HTML关键域倒排索引
a.关键域:Title, anchor, keyword, …
b.对于大部分用户查询,Web资源是足够的
(4)开源索引系统
①Lucene – Nutch kernel
②MG4J - Managing Gigabytes for Java
1)Managing Gigabytes for Java
2)MG4J通过内插编码(interpolative coding)技术,为大量的文档集合构建一个被压缩的全文本索引。
3)与Lucene 主要区别是,它提供了cluster 功能,具有更OO的设计方式。
4)由 H.Witten,Alistair Moffat和Timothy所写,名字是《管理十亿字节:压缩并且索引文档和图片》
③Terrier - Information Retrieval Platform
1)Terrier是一个高度灵活,高效的开源搜索引擎,易于部署在大型的文件集合。Terrier实现非常优秀的索引和搜索功能,为开发大型检索应用程序提供了一个理想的平台。
2)它支持多索引策略比如:multi-pass、single-pass 和 大型MapReduce索引。
④Indri (Lemur - Search Engine )
1)Lemur(狐猴)系统是CMU和UMass联合推出的一个用于自然语言模型和信息检索研究的系统,可以使用结构化查询、跨语言检索、过滤、聚类等。
2)Lemur可以在Windows或者Unix环境下使用,在Windows下需要安装cygwin来模拟Unix环境。
3)Lemur还提供了一个 GUI程序以及用户交互的界面的CGI,Java程序可以直接看到检索的结果,需要安装Java 虚拟机,CGI程序需要Perl的解释器。
⑤Xapian - Search Engine Library
1)Xapian由C++编写,但可以绑定到Perl、Python、PHP、Java、Tcl、C# 和Ruby甚至更多的语言。
2)Xapian应用STL编程,使用了引用计数型智能指针、容器和迭代器,甚至连命名也跟STL相似。
3)具有高度可移值性,当移植到其它平台时,一般来说是需要重新编译。官方说法是可以运行在Linux、Mac OS X、FreeBSD、NetBSD、OpenBSD、Solaris、HP-UX、Tru64和IRIX,甚至其它的Unix平台,集Windows。
⑥Sphinx - 基于SQL的全文检索引擎
1)基于SQL的全文检索引擎
a.可以结合MySQL,PostgreSQL做全文搜索
b.提供比数据库本身更专业的搜索功能,使得应用程序更容易实现专业化的全文检索。
2)Sphinx特别为一些脚本语言设计搜索API接口
a.PHP,Python,Perl,Ruby接口
b.为MySQL也设计了一个存储引擎插件。
3)Sphinx 高效性
a.单一索引最大可包含1亿条记录,在1千万条记录情况下的查询速度为毫秒级。
b.创建100万条记录的索引只需 3~4分钟,创建1000万条记录的索引可以在50分钟内完成,而只包含最新10万条记录的增量索引,重建一次只需几十秒。
⑦FirteX – 中科院计算所发布
1)FirteX是一个功能强大、高性能、灵活的全文索引和检索平台。
2)主要目标是研究文本索引的快速构建(Index Construction),动态文档集的索引维护(Index Maintenance),短语查询(Phrase Query),Top-k查询的快速处理(Top-k Query Process)以及各种检索模型(IR Model)等。高性能和灵活的架构也使FirteX可以应用在产品搜索,桌面搜索,站内搜索,新闻搜索,Blog搜索,学术搜索以及大规模搜索引擎等领域中。
5.内容检索子系统
(1)文本信息检索模型
①基本概念
1)文本检索的本质问题:
a.根据用户提出的需求从文本集中找出最相关的文档。
b.一个文本检索系统的基本模型就是对上述问题进行建模。
2)模型中包含如下三个基本问题:
a.用户如何提出需求(最流行的方法:提交多个关键词)
b.相关文档如何定义和计算(句法层面;语义层面)
c.检索结果如何反馈(相关度排序;文档质量排序;段落检索;QA检索)
②模型1:布尔模型(Boolean model)
1)目前商用检索系统中采用得最多的模型
2)查找那些对于某个查询为“真”的文档
3)假设查询是由关键词及逻辑关系符构成的Boolean表达式,而文档被视为索引词的集合。
a.文档与其索引词的集合是否满足查询的Boolean表达式。
b.Q = (K1 AND K2) OR (K3 AND (NOT K4)) = {Doc1, Doc2, Doc3}
4)缺点:
a.检索策略是基于二元决策的。即一个文档与查询之间要么就是相关的,要么就是不相关的,没有相关程度的度量。
b.虽然Boolean表达式可以通过关键词表达比较精确的语义,但是人们常常不容易将一个信息需求转换成Boolean表达式。
5)不能单纯采用Boolean模型
a.不当的查询导致很少的检索结果
b.对大量的相关结果无法排序
c.可结合链接分析、用户反馈等方法进行网页质量分析,基于质量进行网页排序
③模型2:向量空间模型(Vector space model)
1)VSM利用索引词出现的绝对和相对频度,对索引词赋予非二值的权重来表达文档和查询,从而使得它们之间的相关性成为一个连续的度量指标。
2)文本集中每个不同的索引词构成向量空间的一个维度。这样,所有m个不同的索引词便构成了m维的特征向量。
a.文档dj的特征向量dj=[w1j, w2j, …,wmj]。
b.查询q的特征向量q=[w1q, w2q, …,wmq]。
3)向量夹角的余弦cos(q,dj)
4)向量之间的相关系数r(q,dj)
5)索引词的权重计算
a.对能够表达文档特征的词给予更高的权重。
b.一个词对于表达文档特征的重要程度取决于两个方面
a)该词在本篇文档中出现的频度,出现的次数越多越重要;
b)该词在其他文档中出现的频度,越不易于在其他文档出现越重要。
c)基于这一原则,人们提出了TF-IDF索引词权重计算方法。
i.词频TF( term frequency)
ii.倒文档频度IDF(inverse document frequency)
④模型3:概率模型(Probabilistic model)
1)通过概率方法来解决文本检索问题
a.给定一个用户查询,一定存在一个文档集合(理想答案集合R)只包含相关文档,而不包含不相关文档。
b.如果给出R的特性描述,我们将不难获得R中的文档。因此可以将检索过程转变为对R的特性描述。
c.因为这些特性在用户提交查询的时候是未知的,因此需要给出最初的猜测。通过这个猜测可以获得对R的初步的描述,并借此获得第一个检索结果:一个文档的集合。
d.通过与用户的交互,获得对R描述的改进,从而可以获得一个新的文档集合。通过重复上述过程,可以期望对R的描述不断被改善,最终达到满意。
2)基本假设:
a.给定一个用户查询q和一个文档dj,概率模型试图估计dj与q的相关性。
3)概率模型采用几率比的方法
(2)网页排序
①排序依据(ranking evidence)
1)现有的搜索引擎
a.基本上仍然采用boolean检索
b.外加上百种排序因素
c.小部分服务器采用其他检索模型,用于测试
2)网页排序依据
a.查询内容与网页内容相似度
b.网页质量评估
c.用户偏好情况
d.竞价排名情况
3)查询与网页内容相似度计算
a.VSM和概率模型都是计算相似度
a)查询与网页内容相似度
b)网页与网页相似度 – 文档聚类
b.查询输入: 词少, 网页内容: 词多 =>不对称
a)多用于文档检索: 查询提交的是文档
c.其他相似度计算:
a)尽量精确匹配: 信息与通信工程学院
b)精确匹配的次数
c)查询词出现的位置: 标题,正文,其他位置
d.网页质量评估----超链接分析
a)通过超链接分析来改进排序结果是Web文本检索与数据库文本检索的一个十分重要的区别。
i.指向一个网页的超链接的数量代表着网页的流行度和质量。
ii.两个网页包含较多的相同的链接或被相同的网页所指向常常意味着它们之间具有某种密切的关系
b)基于超链接分析的网页排序算法已经有多种:
i.典型算法PageRank[Brin 98]和HITS[Klei 98]
e.网页质量评估----网页内容评估
a)网页内容是否有信息量
b)是否是垃圾页面
i.关键词堆砌
ii.是否用作弊
4)用户偏好情况
a.依据:用户对网页内容的偏好体现在其点击行为上,基于用户的点击行为改进检索结果
b.方法:用户群体分析:进行查询q时,大多数用户点击的内容是与查询q相关的内容
c.用户个体分析:用户长久的点击行为体现其偏好建立用户的“背景”信息模型
a)分析用户对查询结果的点击情况
b)兼顾各种用户的信息需求
5)竞价排名
a.依据:广告客户付费的多少,用户点击情况的历史记录
b.方法:通常使用特殊标记区分竞价结果与非竞价结果
a)通常需要控制结果中的竞价结果与非竞价结果比例
c.问题:如何在满足用户信息需求和获得广告收益之间取得折衷?
②合并排序依据
6.链接分析子系统
链接分析子系统的主要功能
- 依靠链接分析算法实现页面质量评估
- 依靠链接结构分析扩充文档描述内容
- 索引结构支持
- 检索算法应用
(1)万维网链接结构特性
①使用有向图表征万维网链接结构
1)万维网链接结构图:Web Graph
2)顶点:网页(网站)
3)边:超链接
4)有向图
②万维网链接结构图的顶点规模
1)难以给出精确的估计
a.增长、变化迅速
b.动态页面、动态链接:搜索结果页面、AJAX页面
2)站点级别的估计:
a.中国境内(不含.edu.cn域名)323万个
3)网页级别的估计:
a.中国境内(不含教育网)336亿个
b.Google:Knows 1 trillion Web Pages
(2)PageRank算法设计及实现
①超链接分析
1)通过超链接分析来改进排序结果是Web文本检索与数据库文本检索的一个十分重要的区别。
a.指向一个网页的超链接的数量代表着网页的流行度和质量。
b.两个网页包含较多的相同的链接或被相同的网页所指向常常意味着它们之间具有某种密切的关系
2)基于超链接分析的网页排序算法已经有多种:
a.典型算法PageRank[Brin 98]和HITS[Klei 98]
②PageRank
1)模拟用户在Web上可用Markov链建模的“冲浪”行为
(3)HITS算法设计及实现
①HITS (Hypertext Induced Topic Search)
②与PageRank不同,是与查询相关的网页质量评价算法
1)收到查询q后,系统返回一个网页的集合R
2)R中的任意节点指向的节点和指向R中任意节点的节点构成集合X,R与X共同构成一个基本集合V
3)构造图G = (V , E),E为节点间的有向链接
4)评价网页的两个测度: a(authority)和h(hub)
(4)链接分析算法问题:
①小规模数据可能分析无效
7.多媒体信息检索技术*
(1)图像检索
①基本概念
1)图像文档
a.图片
b.视频 – 帧图像序列
c.格式多样,常包含文本和语音信息
2)查询的两种方法:
a.关键词查询:采用现有的文本检索的技术架构,但先要对图像进行文本标注
b.示例查询:提交基于视觉特征的准确的查询请求,但提交查询不够方便,匹配算法的计算量大,常用哈希方法
3)图像检索系统中的关键技术
有不变性特征提取、图像的分类、图像索引等
4)物体识别、文字识别、人脸检测与识别在图像检索中有特别重要的意义
②传统图像特征提取方法
1)几何不变性(geometric invariance)
a.平移,旋转,尺度……
2)光度不变性(photometric invariance)
a.亮度,曝光……
3)常见算法:
a.HOG
b.SIFT
c.SURF
d.ORB
e.LBP
f.HAAR
③文本自动标注
1)自动地对图像中包含的各种物体进行标注,甚至能够标注其中包含的抽象概念
2)从大类标注做起
a.图形类/照片类 城市/风景 室内/室外
b.对检索有帮助,但信息颗粒太大,信息量太少
3)基于区域划分的标注
4).基于one-vs-all二值分类器的标注
5)有监督的多类标注
④图像过滤
1)不良图像过滤
2)OCR技术
⑤图像快速检索——hash技术
1)用一个hash值代表一个图像。
2)每个不同图像的hash值尽量不同
3)对于同一图像内容(可能有细微变化),hash值相同
4)基本算法:
a.平均哈希算法(aHash)
b.感知哈希算法(pHash)
c.差异哈希算法(dHash)
⑥aHash
1)此算法是基于比较灰度图每个像素与平均值来实现的,最适用于缩略图,放大图搜索。
2)步骤:
a.缩放图片:为了保留结构去掉细节,去除大小、横纵比的差异,把图片统一缩放到8*8,共64个像素的图片。
b.转化为灰度图:把缩放后的图片转化为256阶的灰度图。
c.计算平均值: 计算进行灰度处理后图片的所有像素点的平均值。
d.比较像素灰度值:遍历灰度图片每一个像素,如果大于平均值记录为1,否则为0.
e.得到信息指纹:组合64个bit位,顺序随意保持一致性即可。
f.对比指纹:计算两幅图片的指纹,计算汉明距离(从一个指纹到另一个指纹需要变几次),汉明距离越大则说明图片越不一致,反之,汉明距离越小则说明图片越相似,当距离为0时,说明完全相同。(通常认为距离>10 就是两张完全不同的图片
⑦PHash
1)平均哈希算法过于严格,不够精确,更适合搜索缩略图,为了获得更精确的结果可以选择感知哈希算法,它采用的是DCT(离散余弦变换)来降低频率的方法
2)步骤
a.缩小图片:32 * 32是一个较好的大小,这样方便DCT计算
b.转化为灰度图:把缩放后的图片转化为256阶的灰度图。
c.计算DCT:DCT把图片分离成分率的集合
d.缩小DCT:DCT是3232,保留左上角的88,这些代表的图片的最低频率
e.计算平均值:计算缩小DCT后的所有像素点的平均值。
f.进一步减小DCT:大于平均值记录为1,反之记录为0.
g.得到信息指纹:组合64个信息位,顺序随意保持一致性即可。
h.对比指纹:计算两幅图片的指纹,计算汉明距离(从一个指纹到另一个指纹需要变几次),汉明距离越大则说明图片越不一致,反之,汉明距离越小则说明图片越相似,当距离为0时,说明完全相同。(通常认为距离>10 就是两张完全不同的图片)
⑧dHash
1)相比pHash,dHash的速度要快的多,相比aHash,dHash在效率几乎相同的情况下的效果要更好,它是基于渐变实现的。
2)步骤:
a.缩小图片:收缩到9*8的大小,72个像素点
b.转化为灰度图:把缩放后的图片转化为256阶的灰度图。
c.计算差异值:dHash算法工作在相邻像素之间,这样每行9个像素之间产生了8个不同的差异,一共8行,则产生了64个差异值
d.获得指纹:如果左边的像素比右边的更亮,则记录为1,否则为0.
⑨局部敏感哈希LSH
1)原始数据空间中的两个相邻数据点通过相同的映射或投影变换后,这两个数据点在新的数据空间中仍然相邻的概率很大,而不相邻的数据点被映射到同一个桶的概率很小
2)LSH条件
3)问题
a.在海量Hash数据(N个数,值均为m位的二进制)中,如何查找与给定Hash数据近似的所有Hash值。(近似:只有n位数据不同,n<<m)m一般为2的若干次幂。
b.最笨的办法:与所有Hash值进行异或操作。统计其异或值的非0个数。O(N)
c.进一步考虑, n<<m,将所有Hash数据的m位二进制平均分为n+1份,则匹配结果中的各个Hash,至少有一份与给定Hash值得对于区间相同。
(2)视频检索
①基本概念
1)视频检索已成为一个与图像检索相对独立的技术领域
2)2001年TREC会议启动了视频检索任务TRECVID
a.镜头切分、高层特征抽取、检索系统、视频摘要等
3)视频:帧(静态图像)的序列,其切分和组织方法:
a.物理层次:镜头切分,同一地点连续拍摄的视频帧的序列为一个镜头
b.语义层次:场景或故事为单位,但往往依赖于镜头切分
4)目前的视频语义切分主要将新闻视频作为研究对象
a.切分辅助信息:主持人镜头、字幕、受访人镜头、说话人的声音、语音内容、背景音乐等
b.镜头切分后,可挑选一个代表帧:关键帧
5)高层语义特征
a.场景特征:反映全局的场景
b.物体特征:刻画语义对象
c.运动特征:目标跟踪
d.音频特征
(3)音频检索
①基本概念
1)音频检索起步较晚,但目前已经成为一个新热点
2)语音类音频检索的自然策略:
a.语音识别-》文本检索
b.全文的转换或关键词的转换
3)直接基于声学特征进行检索的策略越来越受到重视
4)音频检索也有两种基本模式
a.基于示例/基于查询词
5)音频检索的困难
a.音频信号种类繁多,环境噪声差异性大
②非语音音频检索
1)非语音音频,如音乐、鸟鸣、狗叫、虎啸、马达声等无法通过语音识别的方法进行文本标注
2)其检索问题需要采取与语音检索不同的技术来解决,可用机器学习的方法建立声学模型与语义模型之间的联系
3)相关的研究主要有音频分类、音频检索以及图像视频检索
4)音频分类研究重点
a.分类的性能主要取决于声学特征的选取
a)MFCC比LPC更有效
5)音频检索研究重点
a.QBE:哼唱查询(Query by Humming)
b.QBK:研究的焦点聚集在声音的语义建模,[Buchanan 05] 提出了一个完整的声学—语义框架和一套建模方法
③查询与索引的匹配
1)索引: 音乐文档中显著的容易被人记忆的多个段落的旋律
2)由于用户的哼唱常包含错误,因此查询与索引的匹配需采用有弹性的方法
a.基于最小编辑距离的动态规划方法被普遍应用
3)面向3级轮廓线的递归式最小编辑距离计算方法
a.设旋律A和B的轮廓线分别为(a1,…,am)和(b1,…,bn),则A和B的子串(a1,…,ai)和(b1,…,bj)之间最小编辑距离为
④查询提交及结果的匹配
1)用户查询的提交
a.在客户端录制用户的查询,将其传到服务器后进行旋律提取
b.在客户端就完成旋律提取,而只向服务器提交表示旋律的字符序列
2)检索结果的反馈
a.按照匹配度从高到低的顺序反馈,为了提高用户的感受度,应当设置匹配度阈值
8.信息过滤
(1)8.1 引言
①从本质上讲,信息过滤是“流环境”下的二元分类问题
1)“流环境”:过滤系统处于信息持续新生的环境之中,新的数据源源不断地流经过滤系统。
2)二元分类:一类是需要筛选出来的,一类是用户不关心的
以模式分类为技术核心,高效高精度地处理数据流。
②IF研究重点:
1)分类器的选择
a.针对特定的应用环境选择分类器模型。
b.目前研究较多的是朴素Bayes模型、向量相似度(模板匹配)模型、SVM、k-NN等。
2)分类器的学习及优化
a.生成式算法、区分式算法
b.计算效率,类别模型的增量学习和自动演进,半监督学习、特征降维技术
3) 垃圾信息过滤系统
4) 话题检测与追踪(TDT)系统
在新闻媒体等数据流中进行话题的检测和追踪,以便从中进行重要信息的筛选。这项研究长期受到美国国防部DARPA的支持,被认为是从网络媒体自动获取重要情报的关键技术。
(2)8.2 基本方法
①8.2.1 Bayes分类器
1)Bayes分类器将分类问题看作统计决策问题,以最小错误率为目标进行分类。
a.前提:事先获得各个类别的概率分布,决策时利用Bayes公式计算确定样本特征值(向量)条件下各类别的后验概率。
②8.2.2 向量距离分类器
1)常用的距离:
a.欧氏距离
b.切比雪夫距离
c.闵可夫斯基距离(Minkowski Distance)
d.标准化欧氏距离 (Standardized Euclidean distance )
e.巴氏距离(Bhattacharyya Distance)
f.夹角余弦(Cosine)
g.杰卡德相似系数(Jaccard similarity coefficient)
h.皮尔逊系数(Pearson Correlation Coefficient)
③8.2.3 k近邻分类器
1)Bayes分类器在理论上可以达到最小分类错误率,但前提是准确估计各类别的先验概率及其条件分布函数
2)向量距离(相似度)分类器可以看作是Bayes分类器的简化,它用各类别数据的均值向量、方差向量、协方差矩阵等参数近似描述它们的分布特性,利用向量之间的各种距离或相似度公式进行分类。
3)模板匹配法(template matching),即将特征向量看作模板。
马氏距离与Bayes的关系
假设各个类别的先验概率都相同
假设P(x|ci)为Gauss分布,不要求x的各维之间相互独立且所有的分布具有相同的方差
④8.2.4 SVM
1)k-NN分类器也需要进一步研究:
a.如何选择特征样本
b.如何选择合适的距离测度
c.如何对各个特征样本的投票加权
d.另外,当系统中类别数较多是,k-NN模型是不太适用的,因为各类都要选择足够数量的特征样本,导致系统需要比较的特征样本数量过多。
a)这个问题在信息过滤等二元分类应用中不存在。
2)而要求分类面对所有样本正确分类,就是要求它满足:
a.满足上述条件且使||w||2最小的分类超平面就是最优分类超平面。
b.在两类数据中离分类超平面最近的点就是使等式成立的那些点,它们位于与分类超平面平行的超平面上“支撑”着分类超平面,故被称为支撑向量。
⑤8.2.5系统性能评价
1)信息过滤系统的评价指标主要包括分类器的精度和速度。
a.速度取决于分类器算法的复杂程度,在实际应用中与计算机的硬件性能关系很大。
b.精度通过与人工标注结果(ground truth)进行比较来计算。
2)对于二元分类问题,常用的精度指标有:
a.准确率
b.召回率
c.F-measure
d.break-even点
(3)8.3 模型学习
①8.3.1 生成式与区分式学习
1)模型学习算法被分为生成式和区分式两大类。
a.Bayes、向量距离等分类器采用生成式学习算法
b.SVM等分类器采用区分式学习算法
2)生成式学习算法
a.典型应用:利用EM算法对GMM的参数进行估计。
b.共同特征:每个类模型只用本类的样本进行估计,估计的准则是使模型产生这些训练样本(总体)的可能性最大。
c.早期的模型学习主要采用生成式算法
3)区分式的模型:
a.在很多场合会取得更高的分类精度。
b.区分式学习成为一种与生成式学习同样重要的方法。
c.两者有不同的特点,适用于不同的场合。
②8.3.2 降维变换
1)降维变换的学习也是模型学习的内容。
a.降维变换技术:在信号分析中著名的Fourier变换、Wavelet变换等就经常被用于降维。但是这些基函数固定的变换是不需通过数据学习的。
2)需要进行学习的降维变换是指变换核(基函数)随被处理数据集变化以获得最佳变换效果的变换,因此它们也常被称为自适应变换。
a.主成分分析PCA(Principal Component Analysis)是最早被提出的自适应变换
b.当前流行的还有独立成分分析ICA(Independent Component Analysis)、线性鉴别分析LDA(Linear Discriminative Analysis)、Hilbert-Huang变换等。
c.这些自适应变换也存在生成式和区分式之分。
d.很多研究还在尝试将两类学习进行结合,以获得互补的效果。
③8.3.3 半监督学习
1)问题:样本不足 / 标注样本不足。
a.找到有效的方法,使得只手工标注少数数据,就能较准确地对全部数据进行自动标注,进而为模型学习提供丰富的数据。
2)三大类半监督学习算法
a.第一类是从聚类算法发展而来的基于限制条件的半监督聚类算法,该类算法在聚类过程中利用已标注的数据来引导聚类。
b.第二类是从经典监督学习中演进而来的,典型代表是自学习算法。该算法在对标注样本进行学习之后,首先处理那些有较高置信度的未标注样本,然后迭代地把这些估计加入到标注样本集中
c.第三类是基于图的算法。该类算法将数据看作图上的结点,将数据间的(已知的)相似性看作结点间的初始边长(权重),应用图的理论对数据进行聚类。
④8.3.4 演进式学习
(4)8.4 垃圾邮件及垃圾短信过滤
①8.4.1 垃圾邮件过滤系统
1)垃圾邮件(spam)过滤系统
a)各类国内外相关科研计划
b)自然科学基金、863计划、科技支撑计划
c)TREC在2005年专门设立了一个Spam任务,对垃圾邮件过滤的系统技术进行公开测试
b.TREC Spam评测的技术是基于内容识别的,这不同于目前在市场上普遍应用的技术,如黑白名单过滤、基于地址分析及跟踪的启发式过滤等。
c.文本分类器是TREC Spam技术的核心,统计学习算法是研究的重点。
2)两个指标:
a.一是Ham邮件被放到Ham目录的概率
a)Ham错分百分比hm%:被错分到Spam目录中的ham占ham总数的百分比
b)反映的是过滤器产生的副作用的大小,它所代表的是用户丢失有用甚至重要信息的风险
b.二是Spam邮件被放到Spam目录的概率
a)Spam错分百分比sm%:被错分到Ham目录中的spam占spam总数的百分比
b)直接反映过滤器在检测垃圾邮件方面的欠缺程度,它所代表的危害是给用户带来的不便和骚扰
c.通常认为ham的错分比spam的错分更有害,因此会更加重视hm%。
3)多数系统根据计算得到的一个邮件为spam的可能性(分数score)进行过滤
a.若可能性大于事先设定的阈值t,则将其投入spam目录,否则投入ham目录。
b.提高t有利于降低hm%,但会升高sm%;反之,降低t有利于降低sm%,但会升高hm%。
c.给出每封邮件的score,可以通过改变t值获得sm%相对hm%的函数关系,或者反之。
②8.4.2 垃圾短信的过滤
1)短信的基本特点:
a.长度短,最长不能超过140个ASCII字符或70个汉字。中文短信平均长度在10到20个汉字之间。
b.文本具有不完整(省略、指代、简化等)、不规范(用词另类、语法随意等)
2)短信分类不统一
a.运营商:订阅(由SP提供的)/ 手写(由手机用户手工输入的)
b.用户:私人 / 广告
c.安全部门:合法 / 非法
d.发送形式:SP->MU / U -> U / U -> MU
e.发送内容:普通短信 / 垃圾短信 / 异常短信
f.细分类:聊天短信、问候短信、祝福短信、娱乐短信、新闻短信、理财短信
3)对于短信分类,基于规则的方法和基于统计的方法有明显的互补性
4)基于正则表达式的规则匹配
a.正则表达式(Regular Expression)
a)由数学家Stephen Kleene于1956年提出
b)在许多脚本语言中得到支持,如Perl、PHP、JaveScript, 已经被国际组织ISO和Open Group标准化。
c)正则表达式由模式修正符(Modifier)、元字符(Meta-characters)、子模式(Sub-patterns)、量词(Quantifiers)和断言(Assertions)等元素组成,通过一系列模式对字符串进行匹配。而模式是一组描述字符串特征的字符,是正则表达式的基本元素。
d)快速地分析大量的文本以找到特定的字符模式,提取、编辑、替换或删除字符串。
5)短信的统计分类
a.特征抽取——对短信进行结构化描述
b.特征选择与压缩
c.类模型学习
d.分类器设计
(5)8.5 话题检测与追踪系统
研究如何在互联网中进行(新)话题的检测并对其后续报道进行追踪
TDT(Topic Detection and Tracking)
话题(topic)特指在特定时间特定地点发生的事件(event),而非一般意义的事件类。例:“汶川地震”是一个事件,而“地震”属于事件类。
一个话题或事件,会有多个相关的报道(story)。
TDT系统的输入是文本流。文本流可能已经被预先划分为一个个的报道,也可能尚未划分。
TDT系统需要完成已知事件的跟踪、未知事件的检测和报道流的划分等任务。
①8.5.1 报道分割
1)将一个连续的文本流划分为一个个报道。分割器;找出相邻报道之间的边界。
2)起因
从新闻广播中(通过语音识别)自动生成的文稿进行事件的检测和跟踪。
3)文本分割
a.算法的评价
a)一方面是直接评价其对报道边界定位的准确性
b)另一方面是间接评价其对事件追踪的支持能力。
b.基于HMM进行报道分割
c.基于局部语境分析LCA(Local Context Analysis)进行报道分割
d.将视频分割应用于报道分割
4)文本分割包含的关键要素
a.源自一对语言模型的基于内容的特征,用于帮助判断话题是否大幅改变。
a)构成:在线的自适应语言模型和离线的静态语言模型
b)前者随着当前处理的文本而动态变化,后者是事先用大量的语料训练完成的。
c)通过比较两个语言模型对文本流所表现出的性能的变化,获得话题边界的启发信息。
b.用于表示局部语境的语言学和结构特征的词汇特征。
a)以更精细的粒度对与分割边界相关的词进行判断。
c.一种新的机器学习算法,它可以增量式地选择最佳的词汇特征,并将它们与语言模型所提供的信息相结合形成一个统一的统计模型。
a)增量式地构建一个越来越详细的模型,对分割边界设置的正确性进行概率估计。
②8.5.2 事件检测
1)回顾式检测 / 在线式检测
2)定义:
a.在几个连续的新闻流中标识出新的或是以前没有标识的事件。
3)本质:
无监督的学习任务(没有标注的训练样本)。
4)模式:
检测可以是回顾式的,也可以是在线的。
a.回顾式检测系统的输入是整个文本集,要求的输出是对文本集一簇簇的划分,它将文本集分割成一个个的事件组。
b.在线检测系统的输入是按时间顺序的报道流,即实时产生的新闻事件。
c.系统对每个报道仅输出Yes或No,指示其是否为新事件的第一个报道。同时还要给出每个决策的置信度。
5)事件检测的方法可以有多种:
a.从词的相似性和时间的邻近性上考虑
b.从词的分布特性变动性考虑
c.根据自适应语言模型预测精度的变化考虑
③8.5.3 事件追踪
1)将新产生的报道与系统已知的事件联系起来。
2)给定目标事件的条件下判断每个后续报道是否在讨论这个目标事件
3)事件追踪的任务:给定几个描述某一事件的报道,把所有描述该事件的后续报道都标识出来。
4)基于检索的方法:
a.利用训练样本(某一事件的若干个报道)提取出一个对事件的查询及其置信度阈值,然后对后续报道按检索方式进行匹配。每一个已知事件都会得到一个查询,因此一个后续报道到来后,要与多个查询进行匹配,以确定其属于哪个事件的报道。
5)基于简单的相关反馈:
a.将Nt个“正”训练样本和100Nt个“负”训练样本提供给一个相关反馈系统,由它构造出10至100个对该事件的查询词。再将这个查询应用于训练集合,以获得置信度的阈值。
6)基于分类器进行事件追踪:
a.k-NN分类器得到了较多的应用,每个事件的所有“正”“负”样本都被高效地存储和索引。每当一个报道到来时,都被表转换为向量,与以往的所有报道相比。然后通过最接近的k个报道的向量进行投票。
7)k-NN的变种:
a.在总体的漏检率和虚警率之间获得更好的平衡。利用正负两种样本分别建立两个尺寸(邻居数)不一定相同的邻域,然后分别计算两个邻域的相似度S+和S-后再进行比较
④小 结
1)信息过滤主要特征:用户的需求相对固定,而信息源是流动变化的。
2)在信息过滤系统中,较少有与用户的交互,因此相比检索系统而言要求有更高的搜索(分类)精度。
3)信息过滤系统有十分重要的应用价值。目前常见的系统包括垃圾邮件/垃圾短信过滤、热点话题检测与追踪、新产品信息过滤等。
4)信息过滤系统的核心技术是能够同时保证精度和速度的高性能分类器,因此特征抽取及降维、类模型学习等便成为需要解决的关键问题。
9.信息推荐
9.1 引言
(1)Information Retrieval
①被检索的文档相对稳定
②用户查询需求不同
(2)Information Filter
①信息资源动态变化
②用户需求相对固定
(3)Information Recommendation
①信息资源动态变化
②用户的需求不确切,只能通过历史数据和相关数据进行挖掘(预测)
(4)信息推荐技术:
①基于内容(content based)
1)首先对用户和商品的描述信息分别进行建模,然后通过比较两类模型之间关联度(相似度)来进行推荐
2)与检索技术类似
②基于关联(association based)
1)不需要任何关于用户或商品的描述信息,而是通过历史上的交易或评价数据挖掘用户之间、商品之间、用户-商品之间的关联性,进而预测用户对商品的态度。
2)不需要关于用户和商品的描述信息外,通常也不需要领域知识。
3)关联规则挖掘(Association Rules Mining)算法
4)协同过滤(Collaborative Filtering) 算法。
(1)关联规则挖掘
①数据挖掘的一个重要研究方向。
②起源
1993年,IBM的R. Agrawal等人首次提出在大型商品交易数据库中挖掘商品项(Item)之间的关联规则的问题,并提出了一种高效的挖掘算法Apriori [Agra 93]。
③多种改进算法,以进一步减小计算量或内存的占用量。
④应用
关联规则挖掘算法最初主要应用在大型超市的商品关系的挖掘等方面,随着电子商务等应用的普及,挖掘用户需求和兴趣进而进行信息推荐已经成为关联规则挖掘算法的另一重要应用。
(2)协同过滤算法
①来自信息推荐系统。
②主要思想
通过他人对某一商品已知的需求来预测一个用户对该商品未知的需求。基本原则是历史上的需求类似,则当前的需求也类似。
③算法的核心
通过历史数据找出与被预测用户有类似需求的用户(组)。
1)根据具体的计算策略,协同过滤算法又可分为基于用户(User based)和基于项目(Item based)两大类。
9.2 关联规则挖掘的基本算法
9.2.1 基本定义
(1) 同时满足最小支持度阈值和最小置信度阈值的规则称为强规则。挖掘关联规则问题就是产生支持度和可信度分别大于用户给定的最小支持度和最小可信度的关联规则,也就是产生强规则的问题。
9.2.2 Apriori 关联规则挖掘算法
(1)关联规则挖掘可以分解为两个步骤:
①首先找出D中满足minSup的k项集,由这些项集生成关联规则;
②然后找出置信度不小于minConf的规则。
(2)频繁项集的向下封闭性:
①频繁项集的所有非空子集也必须是频繁项集。
(3)Apriori算法把由频繁k-1项集的集合Fk-1生成频繁k项集的集合Fk的过程分为连接和剪枝两步
1.连接和剪枝
(1)连接步
(2)剪枝步
2.递推挖掘算法
(1)首先产生频繁1项集L1,然后是频繁2项集L2,直到某个r值使得Lr为空,算法停止。
3.Apriori算法的两大缺点:
(1)可能产生大量的候选集
(2)需要重复扫描数据库
4.Apriori算法:
(1)输入:事务数据库D,最小支持度minsup。
(2)输出:频繁项目集合L。
(3)符号: X,项目集合;Li,i-项频繁项集集合。
(4)步骤:
①(1)L1={X | XD, support(X)minsup};
②(2)for (k=2; Lk-1!= ; k=k+1){
③(3) Ck=apriori_gen(Lk-1, minsup);
④(4) for all transactions tD{
⑤(5) support©=support©+1, CCk}
⑥(6) Lk={C | CCk, support©minsup};}
⑦(7)L=Lk;
5.算法的优化:
(1)剪枝技术原理:
1)一个项集是频繁项集当且仅当它的所有子集都是频繁项集。
2)如果Ck中某个候选项集有一个(k-1)子集不属于Lk-1,则这个项集就可以被裁剪掉。
(2)散列
①用于生成频繁2项集L2上
(3)划分
①把数据库从逻辑上分成几个互不相交的块
(4)采样
9.2.3 基于FPT的算法
(1)从Apriori算法的执行过程可以看出该类算法有两个缺点:
①1)挖掘中的关键步骤—寻找频繁k项集非常耗时。
②2)在算法中频繁项集的长度每增加一个,都要遍历一次数据库。
(2)韩家炜[Han 00]提出一种利用频繁模式树FPT(Frequent Pattern Tree)进行频繁模式挖掘的FP-growth算法
①1)采用FPT存放数据库的主要信息,算法只需扫描数据库两次。
②2)不需要产生候选项集,从而减少了产生和测试候选项集所耗费的大量时间。
③3)采用分而治之的方式对数据库进行挖掘,在挖掘过程中,大大减少了搜索空间。
9.3 可信关联规则及其挖掘算法
① 在数据分布严重倾斜(一小部分项目出现的非常频繁,绝大多数项目很少出现)的情况下,会遇到最小支持度难以设定的问题。
1)支持度稍一偏高,就会漏掉很多重要的置信度较高的关联规则;
2)支持度稍一偏低,就会产生大量的虚假规则。
② 抑制虚假规则的产生
1)[Omie 03]提出了all-confidence兴趣度测度
2)[Xiong 03]提出h-confidence兴趣度测度
3)可信关联规则
9.3.1 相关定义
①同现的定义
②可信关联规则的支持度与亲密度/共现度
1)Credibility measure(可信度度量)
2)其他度量
a.Lift Measure(作用度度量)
b.Correlation Measure(相关度度量)
a)Pearson’s correlation
b)coefficient
c.Cosine Measure(余弦度量)
3)h-confidence ( h-置信度)
4)不同度量的应用
a.所有度量都可以用于模式或规则中两两项目之间的度量
a)Correlation Measure 、Cosine 和Credibility效果较好
b.对模式或规则的所有项目进行度量
a)Credibility、h-confidence及Lift
c.不同度量的限定能力:
9.3.2用邻接矩阵求2项可信集
9.3.3由k项可信集生成(k+1)项可信集
9.3.4基于极大团的可信关联规则挖掘算法MaxCliqueMining、
9.4基于FPT的超团模式快速挖掘算法
9.4.1 相关定义
9.4.2 基于FPT的超团模式和极大超团模式挖掘
9.5 协同过滤推荐的基本算法
WEB搜索课程学习总结
1.导论
在这部分的学习中,首先了解了:Web搜索的定义,Web搜索是指在以环球网World Wide Web为典型代表的网络上检索、过滤和推荐信息的理论、方法、技术、系统和服务,也称网络搜索。
其次,学习了web搜索的挑战性、科学价值和研究现状的相关内容,了解到Web搜索强有力地带动了相关学科;同时,在理论研究、语音搜索、图像搜索等相关的关键技术上取得了许多突破;我发现其中的很多内容,如贝叶斯分类、支持向量机SVM、主成分分析,HMM隐马尔科夫模型等内容在我学习的《模式识别》课程中都有详细的介绍。
2.搜索引擎基础
在这部分的学习中,首先了解了搜索引擎体系结构;从某种意义上讲,Web信息检索的实质就是针对用户的查询请求,将所收集的文档按相关度由高到低顺序排列的过程。
其次,学习了信息采集子系统、内容索引子系统、内容检索子系统、链接分析子系统的基本构成、目的和关键内容。
其中,我收获最多的部分是老师介绍的几种常见的存储系统:顺序存储方法:将数据在物理位置上进行连续的存储;链接存储方法:不要求数据在物理位置上连续存放,各个数据结点之间用指针进行连接;索引存储方法和散列存储方法:根据结点的关键字直接计算出该结点的存储地址。散列存储类似于Hash表,即根据记录中的关键字特点设计一种Hash函数(也叫散列函数)和处理冲突的方法来确定记录的存储位置,将记录散列在存储介质上,这样的文件被称作散列文件。
在我的大创项目中,使用Hash方法对传输的信息进行加密,我们使用MD5可以实现传输信息的加密,具有单向性的特征;因此在本章的学习中,我了解到除了信息加密外,Hash方法在检索、索引中也具有很重要的地位。
3.信息采集系统
在这部分的学习中,首先了解了:网页采集系统体系结构的基本功能是将网页从无序到有序的排列和它的性能评价指标为全新快省。
其次,学习了采集过程中可以使用异步采集的方式提升性能,以及采集控制和链接调度的相关技术。
最后,学习了重复页面的检测和网页解析,还了解到许多开源的采集程序,并系统的学习了正则表达式的使用。
其中,我收获最多的部分是:重复页面的检测和正则表达式的使用。一直以来,我都以为索引量越多、用户的满意率会更高,但是在本课的学习中,我认识到索引量和搜索满意度之间的关系不可以量化,即使提升了索引量,效果评估也不一定会变好。正则表达式的学习,让我在对网页中的信息进行爬取时,如虎添翼,能够更好地面对各种信息采集需求。

