
- 1Ubuntu如何下载geo的数据 Linux下载geo R安装Cairo_linux安装cairo
- 2C# winform 请求http ( get , post 两种方式 )_vbnet post get 服务器
- 3配置wpf的cefsharp控件(netcore3.1)_cefsharp.wpf.netcore
- 4简述C++ 多线程编程:实现并发性与性能的关键_c++ 多线程 性能
- 5Android 系统属性(SystemProperties)_sys.powerctl
- 6【AspectJX】Android 中快速集成使用一款 AOP 框架并附加数据埋点解决方案实现
- 7PyQt5 实战记录1 如何进行资源打包_pyqt5 打包 图片
- 8拥抱AI裁员8000!百年巨头IBM的“广进计划”开始了
- 9使用pytorch编写一个yolo模型的图像识别系统_pytorch图像识别
- 10opencv 简单美颜效果_java opencv 图片美化参数
推荐系统(一)协同过滤算法(CF)_itemcf jaccard
赞
踩
协同过滤算法是典型的基于领域的算法,具体来说协同过滤算法分为两种,基于用户的协同过滤算法和基于物品的协同过滤算法。
一.基于用户的协同过滤算法
算法步骤:
1.找到和目标用户兴趣相似的用户集合
2.找到这个用户集合中用户喜欢的,而目标用户没用点击过的物品推荐给目标用户
所以针对这个算法首先一个问题是如何找到和目标用户兴趣相似的用户集合。
用户相似度衡量指标
我们通过设定一个指标,来衡量其它用户和目标用户之间的相似性,这个指标一般可以是Jaccard或者
余弦相似度。
利用Jaccard计算相似度:
利用余弦相似度计算相似度:
其中,N(u)为用户u所喜欢的商品,N(v)为用户v所喜欢的商品。
利用这两个度量,我们可以计算任意两个用户之间的相似性。
算法具体实现
第一步,我们需要建立一个物品-用户倒排表

小写字母为物品,大写字母为用户,表示喜欢某一个物品的用户有哪些,比如第一行的含义为:喜欢a物品的用户有A和B
第二步,根据第一步计算出的物品-用户倒排表,我们可以计算出一个用户相似度的矩阵
利用这个矩阵,我们可以知道所有用户之间的相似度。
第三步,我们可以根据以下公式计算出用户u对物品i的兴趣程度

用户相似度度量指标优化
对于某些物品,是很多用户都会喜欢的,所以计算用户相似度的时候,不应该把这些极为热门的物品考虑进去,所以我们对计算相似度的指标进行优化,下面以预先相似度优化为例。

参数K对于算法度量指标的影响
K的含义是找到和目标用户最相似的K个用户
1.准确率和召回率
对于这两个指标来说,k的影响不是线性的,一般来说随K增大,准确率和召回率会有提升,但是当K大到一定程度后,可能又会出现下降。
2.流行度
一般来说,K越大,流行度会越高,在这里可以理解,当K大到为所有用户时,就是给目标用户推荐最热门的内容。
3.覆盖率
一般来说,K越大,覆盖率会越低,因为K增大,流行度增大,会导致只推荐热门内容,所以覆盖率就自然下降了。
二.基于物品的协同过滤算法
算法步骤:
1.计算物品之间的相似度
2.根据物品的相似度和用户的历史行为给用户生成推荐列表
物品相似度的度量

N(i)为喜欢物品i的用户,N(j)为喜欢物品j的用户。
这个度量可以理解为同时喜欢两个物品的用户占喜欢物品i用户的百分比。
但这里有一个问题就是,如果物品j非常热门,很多人都喜欢,那么无论N(i)为多少,wij都会接近于1.所以作为改进就有了下面的度量公式: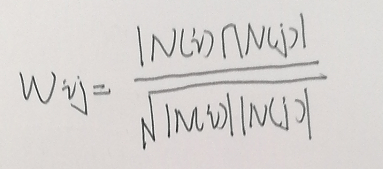
算法具体实现
首先,计算出用户-物品倒排表
再利用用户-物品倒排表来计算物品之间的相似度
最后,利用如下公式计算用户u对于物品j的兴趣程度

物品相似度的度量优化
由于某些用户可能会对大多数物品都感兴趣,所以我们必须减少这类用户对于物品相似度计算的影响。
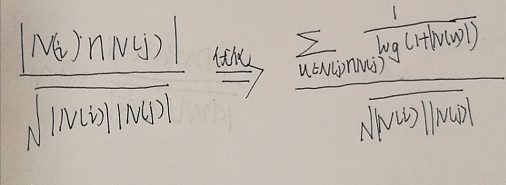
参数K对于算法度量指标的影响
这里k的含义为,用户所感兴趣的k个物品。利用这k个物品来找相似物品,再推荐给用户。
1.准确率和召回率
这里和基于用户的算法相同,k不对这两个指标产生完全正相关或负相关的影响
2.流行度
这里和基于用户的算法不同,k不对这个指标产生完全正相关或负相关的影响
3.覆盖率
这里和基于用户的算法相同,K的增加都会减少覆盖率
三.UserCF和ItemCF比较
1.特点
UserCF的推荐结果着重于反应和用户兴趣相似的小群体的热点,而ItemCF的推荐结果着重于维护用户的历史兴趣。换句话说UserCF的推荐更加社会化,而ItemCF的推荐更加个性化。
2.可解释性
ItemCF的可解释性比较强
3.存储空间的角度
UserCF适用于用户较少的场合,因为用户多的话维护用户相似度矩阵会消耗很大。ItemCF则正相反。
4.实时性的角度
如果物品更新的很快,如新闻,那么最好使用UserCF,因为如果使用ItemCF需要很快的更新物品相似度矩阵,技术上难以实现。
参考《推荐系统实践》( 项亮)

