
- 1第三方打码平台超级鹰图文识别,md5算法加密_打码鹰
- 2uni-app 人脸识别 App端_uniapp人脸采集
- 3泰克Tektronix TDS3034C示波器
- 4【论文笔记】RobotGPT: Robot Manipulation Learning From ChatGPT
- 5VSCode搭建Go语言开发环境_"{ \"resource\": \"/c:/work/go/code/vscode/hello/m
- 6分布式一致性算法(Paxos&Raft)_c# raft
- 7java中计算符号_java中的八种运算符及详解
- 8全球100位最佳工程师,开发人员,编码人员和企业家,可以在线关注他们的github,推特,网站等_mosh hamedani简介
- 9c语言 printf(“%#x”, a)中“#”含义_c语言%#
- 10vue源码系列3响应式系统上_vue响应式ui框架,源代码
面试经典-MySQL篇
赞
踩
一、MySQL组成
- MySQL数据库的连接池:由一个线程来监听一个连接上请求以及读取请求数据,解析出来一条我们发送过去的SQL语句
- SQL接口:负责处理接收到的SQL语句
- 查询解析器:让MySQL能看懂SQL语句
- 查询优化器:选择最优的查询路径
- 执行器:根据执行计划调用存储引擎的接口
- 存储引擎接口:真正执行SQL语句
二、InnoDB的数据更新过程
首先InnoDB存储引擎有一个重要内存结构为缓冲池,假设我们执行如下sql:
update users set name='xxx' where id=10
- 1
那么底层将有如下几个步骤:
- 看看“id=10”这一行数据是否在缓冲池里,如果不在的话,直接从磁盘里加载到缓冲池里来
- 对这行记录加独占锁
- 假设“id=10”这行数据的name原来是“zhangsan”,现在我们要更新为“xxx”,先把要更新的原来的值“zhangsan”和“id=10”这些信息,写入到undo日志文件中去
- 更新buffer pool中的缓存数据,现在已经把内存里的数据进行了修改,但是磁盘上的数据还没修改
- 这个时候,就必须要把对内存所做的修改写入到一个redo日志
- 提交事务的时候将redo日志写入磁盘中
三、MySQL自己的日志文件(binlog)
- binlog叫做归档日志,他里面记录的是“对users表中的id=10的一行数据做了更新操作,更新以后的值是什么”
- 提交事务的时候,同时会写入binlog到磁盘文件中去
四、MySQL核心结构
- Buffer Pool
Buffer Pool本质其实就是数据库的一个内存组件,默认情况下是128MB,还是有一点偏小了,我们实际生产环境下完全可以对Buffer Pool进行调整。数据库启动时会在Buffer Pool中划分出来一个一个的缓存页,一个缓存页的大小和磁盘上的一个数据页的大小是一一对应起来的,都是16KB,每个数据页中有很多行数据。
- free链表
他是一个双向链表数据结构,只要你一个缓存页是空闲的, 那么他的描述数据块就会被放入这个free链表中,当你需要把磁盘上的数据页读取到Buffer Pool中的缓存页里去的时候,我们需要从free链表里获取一个描述数据块,然后就可以获取对应的空闲缓存页,接着我们就可以把磁盘上的数据页读取到对应的缓存页里去,最后把那个描述数据块从free链表里去除就可以了。
- 数据页缓存哈希表
我们在执行增删改查的时候,肯定是先看看这个数据页有没有被缓存,用表空间号+数据页号,作为一个key,然后缓存页的地址作为value。
- flush链表
凡是被修改过的缓存页,都会把他的描述数据块加入到flush链表中去,flush的意思就是这些都是脏页,后续都是要flush刷新到磁盘上去的。
五、事务
四大事务问题:
- 脏写:事务B更新好的值被事务A回滚为事务A原先的值。
- 脏读:事务B去查询了事务A修改过的数据,但是此时事务A还没提交
- 不可重复读:事务A执行过程中事务B执行并提交,导致事务A两次读到的值不一样
- 幻读:事务A一开始查出了10条数据,事务B新增了2条数据,并且提交了,此时事务A再查发现查出了12条数据
四大隔离级别:
- read uncommitted(读未提交):不允许发生脏写的,可能发生脏读,不可重复读,幻读。
- read committed(读已提交):不会发生脏写和脏读,可能会发生不可重复读和幻读问题
- repeatable read(可重复读):不会发生脏写和脏读和不可重复读,可能会幻读问题
- serializable(串行化):不会发生脏写和脏读和不可重复读和幻读
MySQL默认设置的事务隔离级别是可重复读,而且MySQL的可重复读级别是可以避免幻读发生的,原理就是下面的MVCC机制。
六、MVCC机制
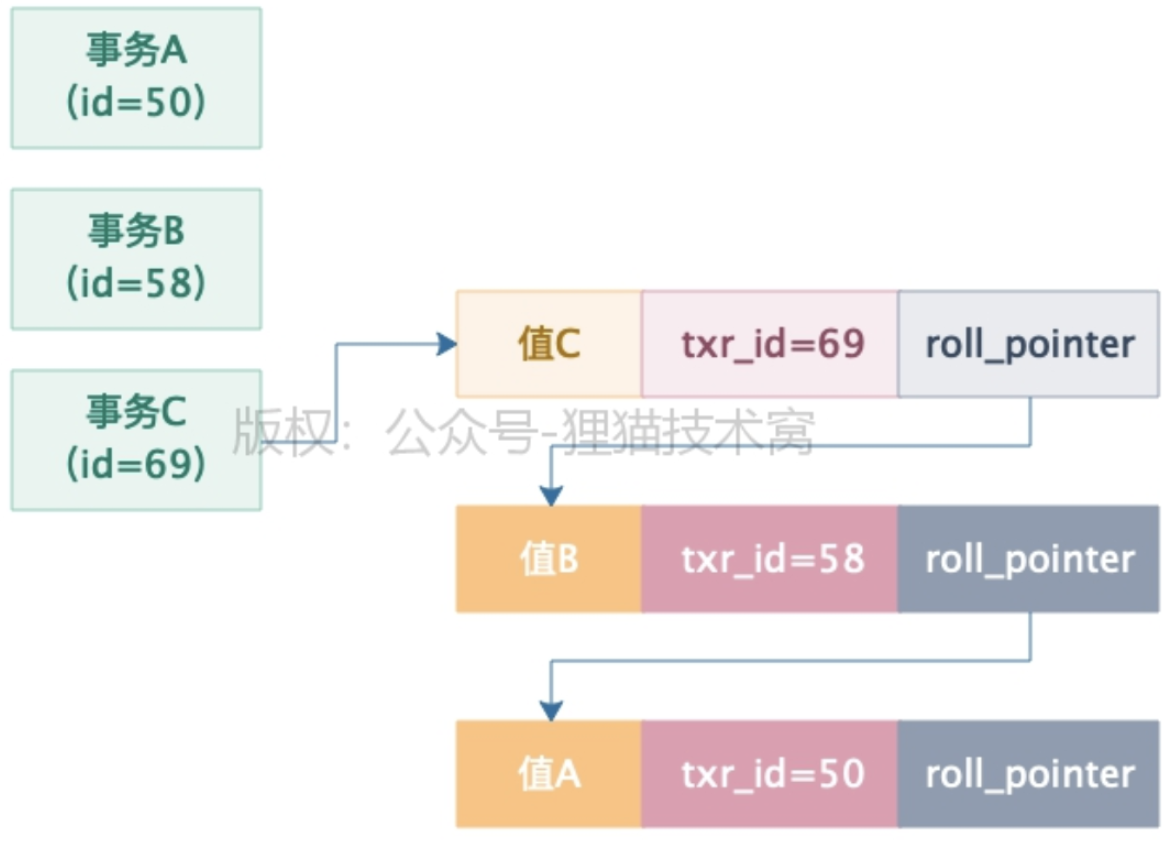
Mysql事务通过MVCC机制得以实现,我们每条数据其实都有两个隐藏字段,一个是trx_id,一个是roll_pointer,这个trx_id就是最近一次更新这条数据的事务id,roll_pointer就是指向你了你更新这个事务之前生成的undo log链。
执行一个事务的时候,就给你生成一个ReadView(视图),ReadView包含以下信息:
- m_ids:此时有哪些事务在MySQL里执行还没提交的
- min_trx_id:m_ids里最小的值
- max_trx_id:mysql下一个要生成的事务id,就是最大事务id
- creator_trx_id:你这个事务的id
下面演示一下MVCC机制的执行步骤:
- 一个是事务A(id=45),一个是事务B(id=59),事务B是要去更新这行数据的,事务A是要去读取这行数据的值
- 现在事务A直接开启一个ReadView,这个ReadView里的m_ids就包含了事务A和事务B的两个id,45和59,然后min_trx_id就是45,max_trx_id就是60,creator_trx_id就是45,是事务A自己。
- 这个时候事务A第一次查询这行数据,会走一个判断,就是判断一下当前这行数据的txr_id是否小于ReadView中的min_trx_id,此时发现txr_id=32,是小于ReadView里的min_trx_id就是45的
- 说明你事务开启之前,修改这行数据的事务早就提交了,所以此时可以查到这行数据
- 接着事务B开始动手了,他把这行数据的值修改为了值B,然后这行数据的txr_id设置为自己的id,也就是59,同时roll_pointer指向了修改之前生成的一个undo log,接着这个事务B就提交了
- 这个时候事务A再次查询,此时查询的时候,会发现一个问题,那就是此时数据行里的txr_id=59,那么这个txr_id是大于ReadView里的min_txr_id(45),同时小于ReadView里的max_trx_id(60)的
- 说明更新这条数据的事务,很可能就跟自己差不多同时开启的,于是会看一下这个txr_id=59,是否在ReadView的m_ids列表里?
- 果然,在ReadView的m_ids列表里,有45和59两个事务id,直接证实了,这个修改数据的事务是跟自己同一时段并发执行然后提交的,所以对这行数据是不能查询的
- 顺着这条数据的roll_pointer顺着undo log日志链条往下找,就会找到最近的一条undo log,trx_id是32,此时发现trx_id=32,是小于ReadView里的min_trx_id(45)的
- 说明这个undo log版本必然是在事务A开启之前就执行且提交的,那么读这条数据就可以了
- 总结来说:一个事务可以读到事务ID等于自身和比自己事务ID小的事务更新的值,但是也不是所有的事务ID比自己小的事务更新的值都能读到,还不能不在m_ids中
七、锁机制
- 当有一个事务加了独占锁之后,此时其他事务再要更新这行数据只能生成独占锁在后面等待。
- 当有人在更新数据的时候,其他的事务可以读取这行数据吗?默认情况下需要加锁吗?不用!因为有人在更新数据的时候,然后你要去读取这行数据,直接默认就是开启mvcc机制的。
- 那么假设万一要是你在执行查询操作的时候,就是想要加锁呢?那也是ok的,MySQL首先支持一种共享锁,就是S锁,这个共享锁的语法如下:select * from table lock in share mode,如果此时有别的事务在更新这行数据,已经加了独占锁了,此时你的共享锁能加吗?当然不行了,共享锁和独占锁是互斥的!此时你这个查询就只能等着了。
- 那么如果你先加了共享锁,然后别人来更新要加独占锁行吗?当然不行了,共享锁和独占锁是互斥的!此时你这个查询就只能等着了。
- 那么如果你在加共享锁的时候,别人也加共享锁呢?此时是可以的,你们俩都是可以加共享锁的,共享锁和共享锁是不会互斥的。
八、索引
MySQL的索引是用B+树来组成的,索引分为两种:
- 聚簇索引
如果一颗大的B+树索引数据结构里,叶子节点就是数据页自己本身,那么此时我们就可以称这颗B+树索引为聚簇索引!这个聚簇索引默认是按照主键来组织的,所以你在增删改数据的时候,一方面会更新数据页,另一方面其实会给你自动维护B+树结构的聚簇索引。
- 二级索引
比如你基于name字段建立了一个索引,那么此时你插入数据的时候,就会重新搞一颗B+树,B+树的叶子节点也是数据页,但是这个数据页里仅仅放主键字段和name字段。针对select * from table where name='xx’这样的语句,你先根据name字段值在name字段的索引B+树里找,找到叶子节点也仅仅可以找到对应的主键值,而找不到这行数据完整的所有字段。
索引使用原则:
- 等值匹配规则
就是你where语句中的几个字段名称和联合索引的字段完全一样,而且都是基于等号的等值匹配,那百分百会用上我们的索引
- 最左侧列匹配
这个意思就是假设我们联合索引是KEY(class_name, student_name, subject_name),那么不一定必须要在where语句里根据三个字段来查,其实只要根据最左侧的部分字段来查,也是可以的。
- 最左前缀匹配原则
即如果你要用like语法来查,比如select * from student_score where class_name like ‘1%’,查找所有1打头的班级的分数,那么也是可以用到索引的。
- 范围查找规则
你的where语句里如果有范围查询,那只有对联合索引里最左侧的列进行范围查询才能用到索引!
- 等值匹配+范围匹配的规则
联合索引是KEY(class_name, student_name, subject_name),如果你要是用select * from student_score where class_name=‘1班’ and student_name>‘’ and subject_name<‘’,首先可以用class_name在索引里精准定位到一波数据,接着这波数据里的student_name都是按照顺序排列的,所以student_name>'‘也会基于索引来查找,但是接下来的subject_name<’'是不能用索引的。为什么呢?因为student_name在不相同的情况下,subject_name是无序的,所以不能走索引,只能全表扫描。
执行计划的几个级别:
- const
直接就可以通过聚簇索引或者二级索引+聚簇索引回源,轻松查到你要的数据。这里有一个要点,你的二级索引必须是unique key唯一索引,才是属于const方式的
- ref
select * from table where name=x的语句,name是个普通二级索引,不是唯一索引,如果你用name IS NULL这种语法的话,即使name是主键或者唯一索引,还是只能走ref方式
- range
select * from table where age>=x and age <=x,假设age就是一个普通索引,此时就必然利用索引来进行范围筛选
- index
只要遍历二级索引就可以拿到你想要的数据,而不需要回源到聚簇索引的访问方式
- all
全表扫描


