
- 1MAC安装JDK1.8_jdk1.8 181 for mac下载
- 2常见集成学习算法模型&LightGBM示例_集成学习lr
- 3计算机 未保存,电脑突然关机wps没保存怎么办
- 4邮箱投递简历,如何正确书写正文和主题?_发简历到邮箱的主题和正文怎么写
- 5『九章数据』新能源乘用车L2渗透率超过50%,城市NOA势不可挡
- 6Python所有方向的入门和进阶路线,20年老师傅告诉你方法_python 进阶编程
- 7大模型的魔法_softverbalizer
- 8基于深度学习,机器学习,卷积神经网络,OpenCV的交通标志识别交通标志检测_基于卷积神经网络的交通标志识别系统的设计与实现用什么数据库做动态网页
- 9postgresql 触发器知识点_create or replace function returns trigger as
- 10Linux中shell一些实用的脚本,7个非常实用的 Shell 拿来就用脚本实例!,
mysql查询过程_MySQL查询执行过程
赞
踩
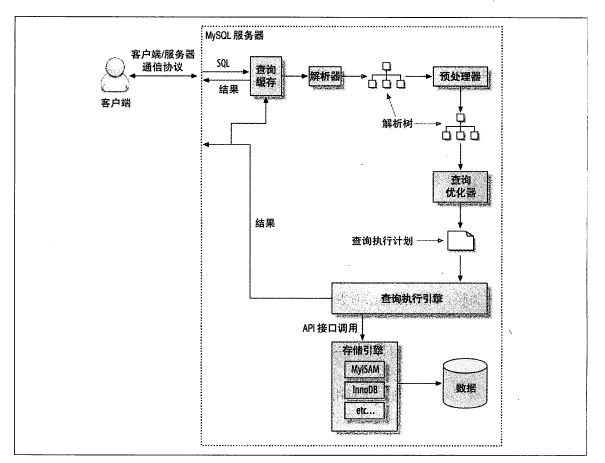
MySQL查询执行路径
1. 客户端发送一条查询给服务器;
2. 服务器先会检查查询缓存,如果命中了缓存,则立即返回存储在缓存中的结果。否则进入下一阶段;
3. 服务器端进行SQL解析、预处理,再由优化器生成对应的执行计划;
4. MySQL根据优化器生成的执行计划,调用存储引擎的API来执行查询;
5. 将结果返回给客户端。
查询缓存(query cache)
在解析一个查询语句之前,如果查询缓存是打开的,那么MySQL会优先检查这个查询是否命中查询缓存中的数据。这个检查是通过一个对大小写敏感的哈希查找实现的。查询和缓存中的查询即使只有一个字节不同,那也不会匹配缓存结果,这种情况查询会进入下一个阶段的处理。
如果当前的查询恰好命中了查询缓存,那么在返回查询结果之前MySQL会检查一次用户权限。这仍然是无须解析查询SQL语句的,因为在查询缓存中已经存放了当前查询需要访问的表信息。如果权限没有问题,MySQL会跳过所有其他阶段,直接从缓存中拿到结果并返回给客户端。这种情况下,查询不会被解析,不用生成执行计划,不会被执行。
缓存配置参数:
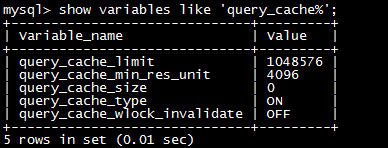
query_cache_limit: MySQL能够缓存的最大结果,如果超出,则增加 Qcache_not_cached的值,并删除查询结果
query_cache_min_res_unit: 分配内存块时的最小单位大小
query_cache_size: 缓存使用的总内存空间大小,单位是字节,这个值必须是1024的整数倍,否则MySQL实际分配可能跟这个数值不同(感觉这个应该跟文件系统的blcok大小有关)
query_cache_type: 是否打开缓存OFF: 关闭ON: 总是打开
query_cache_wlock_invalidate: 如果某个数据表被锁住,是否仍然从缓存中返回数据,默认是OFF,表示仍然可以返回
语法解析器和预处理器
首先,MySQL通过关键字将SQL语句进行解析,并生成一棵对应的“解析树”。MySQL解析器将使用MySQL语法规则验证和解析查询。例如,它将验证是否使用错误的关键字,或者使用关键字的顺序是否正确等,再或者它还会验证引号是否能前后正确的匹配。
预处理器则根据一些MySQL规则进一步检查解析树是否合法,例如,这里讲检查数据表和数据列是否存在,还会解析名字和别名,看看它们是否有歧义。
下一步预处理器会验证权限,这通常很快,除非服务器上有非常多的权限设置。
查询优化器
现在语法树被认为合法的了,并且由优化器将其转化为执行计划。一条查询可以由很多种执行方式,最后都返回相同的结果。优化器的作用就是找到这其中最好的执行计划。
MySQL使用基于成本的优化器,它将尝试预测一个查询使用某种执行计划的成本,并选择其中成本最小的一个。最初,成本的最小单位是随机读取一个4K数据页的成本,后来成本计算公式变得更加复杂,并且引入了一些“因子”来估算某些操作的代价,如当执行一次where条件比较的成本。可以通过查询当前会话的last_query_cost的值来得知MySQL计算的当前查询的成本。
有很多种原因会导致MySQL优化器选择错误的执行计划,比如:
1. 统计信息不准确。
2. 执行计划中的成本估算不等同于实际的执行计划的成本。
3. MySQL的最优可能与你想的最优不一样。
4. MySQL从不考虑其他并发的查询,这可能会影响当前查询的速度。
5. MySQL也不是任何时候都是基于成本的优化,有时候也会基于一些固定的规则。
6. MySQL不会考虑不受其控制的成本,例如执行存储过程或者用户自定义的函数的成本。
MySQL的查询优化使用了很多优化策略来生成一个最优的执行的计划。优化策略可以分为两种,静态优化和动态优化。静态优化可以直接对解析树进行分析,并完成优化。例如优化器可以通过一些简单的代数变换将where条件转换成另一种等价形式。静态优化不依赖于特别的数值,如where条件中带入的一些常数等。静态优化在第一次完成后就一直有效,即使使用不同的参数重复查询也不会变化,可以认为是一种“编译时优化”。
相反,动态优化则和查询的上下文有关。也可能和很多其他因素有关,例如where条件中的取值、索引中条目对应的数据行数等,这些需要每次查询的时候重新评估,可以认为是“运行时优化”。
下面是一些MySQL能够处理的优化类型:
1. 重新定义关联表的顺序
数据表的关联并不总是按照在查询中指定的顺序进行,决定关联的顺序是优化器很重要的一部分功能。
2. 将外连接转化成内连接
并不是所有的outer join语句都必须以外连接的方式执行。诸多因素,例如where条件、库表结构都可能会让外连接等价于一个内连接。MySQL能够识别这点并重写查询,让其可以调整关联顺序。
3. 使用等价变换规则
MySQL可以使用一些等价变换来简化并规范表达式。它可以合并和减少一些比较,还可以移除一些恒成立和一些恒不成立的判断。例如:(5=5 and a>5)将被改写为a>5。类似的,如果有(a5 and b=c and a=5。
4. 优化count()、min()和max()
索引和列是否为空通常可以帮助MySQL优化这类表达式。例如,要找到一列的最小值,只需要查询对应B-tree索引最左端的记录,MySQL可以直接获取索引的第一行记录。在优化器生成执行计划的时候就可以利用这一点,在B-tree索引中,优化器会讲这个表达式最为一个常数对待。类似的,如果要查找一个最大值,也只需要读取B-tree索引的最后一个记录。如果MySQL使用了这种类型的优化,那么在explain中就可以看到“select tables optimized away”。从字面意思可以看出,它表示优化器已经从执行计划中移除了该表,并以一个常数取而代之。
类似的,没有任何where条件的count(*)查询通常也可以使用存储引擎提供的一些优化,例如,MyISAM维护了一个变量来存放数据表的行数。
5. 预估并转化为常数表达式
6. 覆盖索引扫描
当索引中的列包含所有查询中需要使用的列的时候,MySQL就可以使用索引返回需要的数据,而无需查询对应的数据行。
7. 子查询优化
MySQL在某些情况下可以将子查询转换成一种效率更高的形式,从而减少多个查询多次对数据进行访问。
8. 提前终止查询
在发现已经满足查询需求的时候,MySQL总是能够立即终止查询。一个典型的例子就是当使用了limit子句的时候。除此之外,MySQL还有几种情况也会提前终止查询,例如发现了一个不成立的条件,这时MySQL可以立即返回一个空结果。

上面的例子可以看出,查询在优化阶段就已经终止。
9. 等值传播
10. 列表in()的比较
在很多数据库系统中,in()完全等同于多个or条件的字句,因为这两者是完全等价的。在MySQL中这点是不成立的,MySQL将in()列表中的数据先进行排序,然后通过二分查找的方式来确定列表中的值是否满足条件,这是一个o(log n)复杂度的操作,等价转换成or的查询的复杂度为o(n),对于in()列表中有大量取值的时候,MySQL的处理速度会更快。
查询执行引擎
在解析和优化阶段,MySQL将生成查询对应的执行计划,MySQL的查询执行引擎则根据这个执行计划来完成整个查询。这里执行计划是一个数据结构,而不是和很多其他的关系型数据库那样会生成对应的字节码。
相对于查询优化阶段,查询执行阶段不是那么复杂:MySQL只是简单的根据执行计划给出的指令逐步执行。在根据执行计划逐步执行的过程中,有大量的操作需要通过调用存储引擎实现的接口来完成,这些接口就是我们称为“handler API”的接口。实际上,MySQL在优化阶段就为每个表创建了一个handler实例,优化器根据这些实例的接口可以获取表的相关信息,包括表的所有列名、索引统计信息等。
返回结果给客户端
查询执行的最后一个阶段是将结果返回给客户端。即使查询不需要返回结果给客户端,MySQL仍然会返回这个查询的一些信息,如查询影响到的行数。
如果查询可以被缓存,那么MySQL在这个阶段,会将结果存放到查询缓存中。
MySQL将结果返回客户端是一个增量、逐步返回的过程。例如,在关联表操作时,一旦服务器处理完最后一个关联表,开始生成第一条结果时,MySQL就可以开始向客户端逐步返回结果集了。
这样处理有两个好处:服务器无需存储太多的结果,也就不会因为要返回太多的结果而消耗太多的内存。另外,这样的处理也让MySQL客户端第一时间获得返回的结果。
结果集中的每一行都会以一个满足MySQL客户端/服务器通信协议的封包发送,再通过TCP协议进行传输,在TCP传输过程中,可能对MySQL的封包进行缓存然后批量传输。

