
- 1uni-app h5生成环境发布自动去除console.log和debugger_uniapp 去除console debugger
- 2【Qt 学习之路】Qt制作密码框_qt 密码输入框
- 3自动售货机html代码,自动售货机系统源代码.doc
- 4CAS是什么_什么是cas
- 5如何在Windows上下载并安装Android Studio?
- 6CC2530 内部RC低速K晶振 外部32.768K晶振 取舍的问题_cc2530 32.768k
- 7分布式执行引擎ray入门--(2)Ray Data
- 8Qt Creator 安装 Beautifier
- 9java将某个数按比例分配应用题,[Java教程]按比例分配资源
- 10Android HIDL 介绍学习和实战应用
深度学习面经-part3(RNN、LSTM)
赞
踩
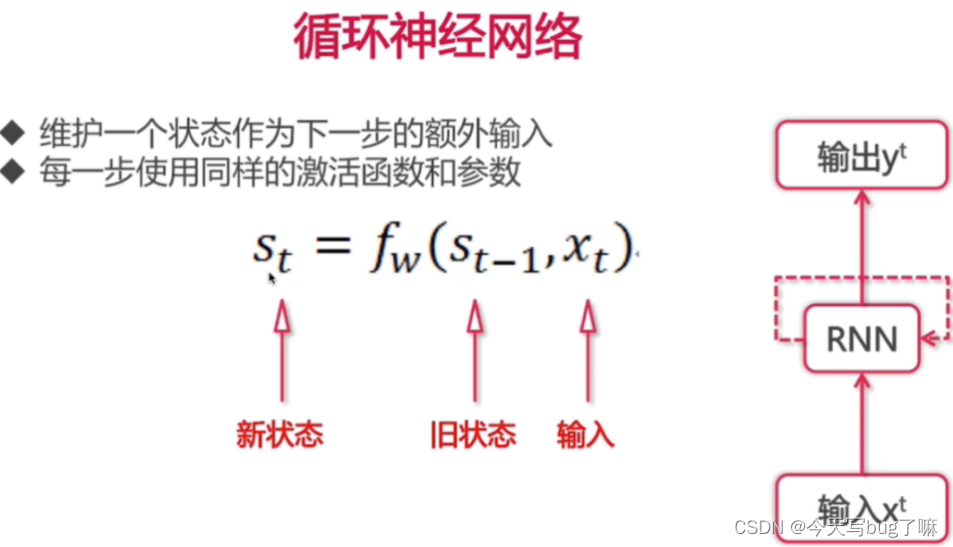
3.RNN
核心思想:像人一样拥有记忆能力。用以往的记忆和当前的输入,生成输出。
RNN 和 传统神经网络 最大的区别:在于每次都会将前一次的输出结果,带到下一次的隐藏层中,一起训练。
RNN应用场景:
1.文本生成 2.语音识别 3.机器翻译 4.生成图像描述 5.视频标记
缺点:
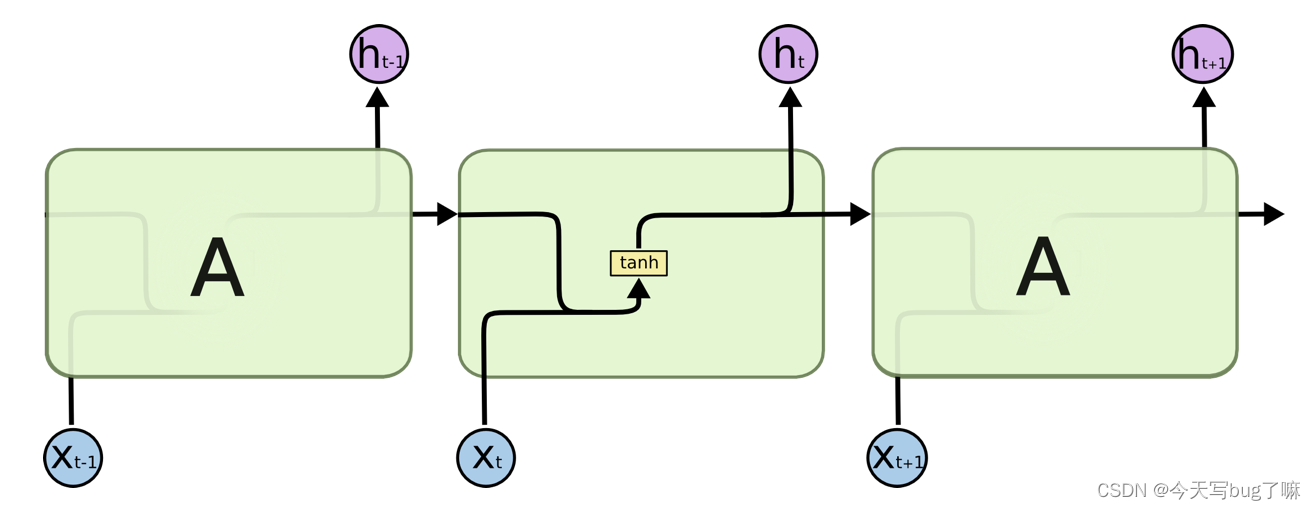
RNN 有短期记忆问题,无法处理很长的输入序列
训练 RNN 需要投入极大的成本
RNN 是一种死板的逻辑,越晚的输入影响越大,越早的输入影响越小,且无法改变这个逻辑。
3.1 RNNs训练和传统ANN训练异同点?
相同点:都使用BP误差反向传播算法。
不同点:
RNNs网络参数W,U,V是共享的,而传统神经网络各层参数间没有直接联系。
对于RNNs,在使用梯度下降算法中,每一步的输出不仅依赖当前步的网络,还依赖于之前若干步的网络状态。
3.2 为什么RNN 训练的时候Loss波动很大?
由于RNN特有的memory会影响后期其他的RNN的特点,梯度时大时小,lr没法个性化的调整,导致RNN在train的过程中,Loss会震荡起伏,为了解决RNN的这个问题,在训练的时候,可以设置临界值,当梯度大于某个临界值,直接截断,用这个临界值作为梯度的大小,防止大幅震荡。
3.3 RNN中为什么会出现梯度消失?
梯度消失现象:累乘会导致激活函数导数的累乘,如果取tanh或sigmoid函数作为激活函数的话,那么必然是一堆小数在做乘法,结果就是越乘越小。随着时间序列的不断深入,小数的累乘就会导致梯度越来越小直到接近于0,这就是“梯度消失“现象。
实际使用中,会优先选择tanh函数,原因是tanh函数相对于sigmoid函数来说梯度较大,收敛速度更快且引起梯度消失更慢。
3.4 如何解决RNN中的梯度消失问题?
1.选取更好的激活函数,如Relu激活函数。ReLU函数的左侧导数为0,右侧导数恒为1,这就避免了“梯度消失“的发生。但恒为1的导数容易导致“梯度爆炸“,但设定合适的阈值可以解决这个问题。
2.加入BN层,其优点:加速收敛.控制过拟合,可以少用或不用Dropout和正则。降低网络对初始化权重不敏感,且能允许使用较大的学习率等。
3.改变传播结构,LSTM结构可以有效解决这个问题。
3.5 CNN VS RNN

不同点
1.CNN空间扩展,神经元与特征卷积;RNN时间扩展,神经元与多个时间输出计算
2.RNN可以用于描述时间上连续状态的输出,有记忆功能,CNN用于静态输出。
3.6 Keras搭建RNN

4. LSTM
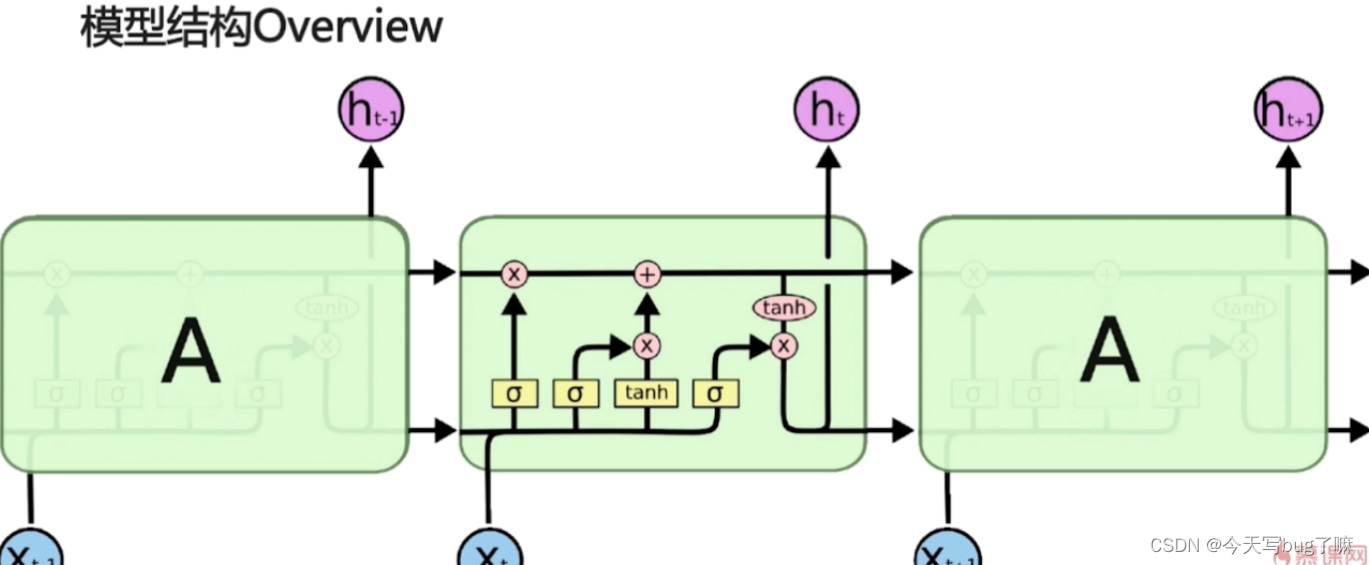
长短期记忆网络(Long Short-Term Memory)是一种时间循环神经网络,是为了解决一般的RNN存在的长期依赖问题而专门设计出来的,所有的RNN都具有一种重复神经网络模块的链式形式。
三个门(遗忘门,输入门,输出门),两个状态(Ct,ht)
遗忘门
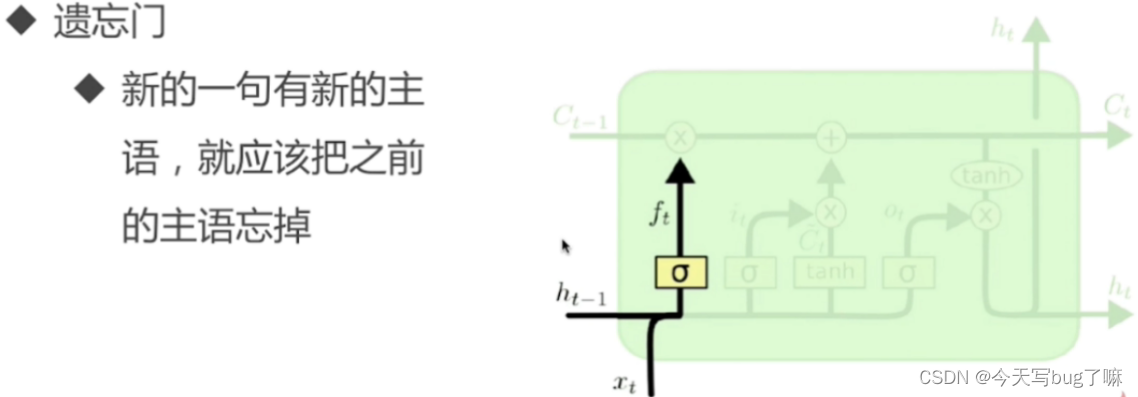
作用对象:细胞状态 。
两个输入:当前时刻的input、上一时刻同一block内所有Cell作为输入
作用:将细胞状态中的信息选择性的遗忘。上一时刻的单元状态Ht-1有多少能保留到当前时刻
Ft和Ct-1做点积操作,Ft确保Ct-1有哪些东西需要被遗忘调
输入层门
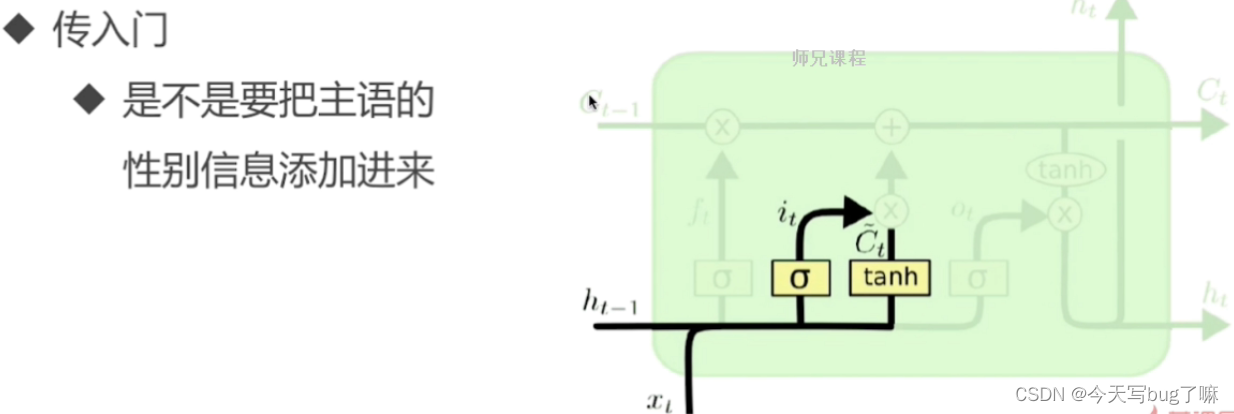
作用对象:细胞状态
作用:将新的信息选择性的记录到细胞状态中。决定当前时刻网络的输入Xt有多少能够保留到单元状态上。
两个输入:当前时刻的input、上一时刻同一block内所有Cell作为输入【例子中每层仅有单个Block,单个Cesll】
操作步骤:
步骤一:sigmoid 层称 “输入门层” 决定什么值我们将要更新
步骤二,tanh 层创建一个新的候选值向量加入到状态中
输出层门
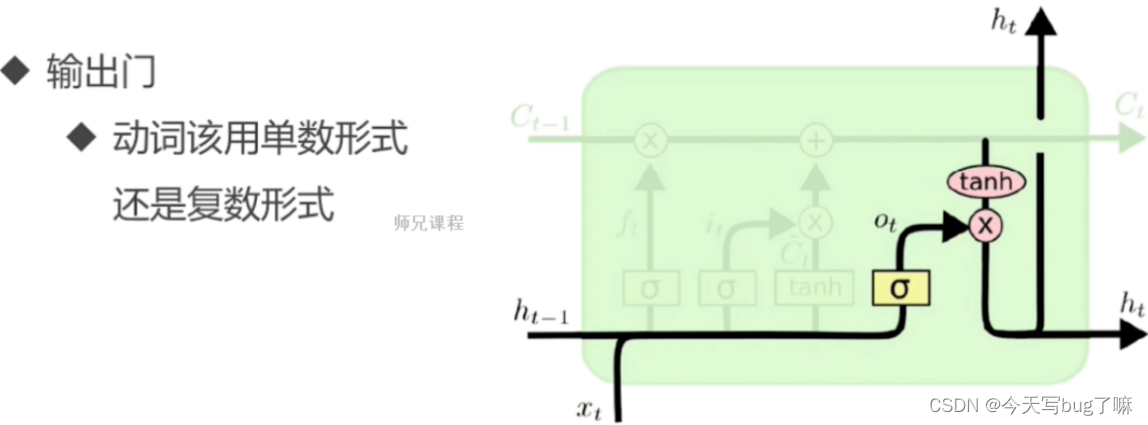
作用对象:隐层ht 作用:确定输出什么值。控制单元状态Ct多少输出到LSTM的当前输出值
操作步骤:
步骤一:通过sigmoid 层来确定细胞状态的哪个部分将输出。
步骤二:把细胞状态通过 tanh 进行处理,并将它和 sigmoid 门的输出相乘,最终我们仅仅会输出我们确定输出的那部分。
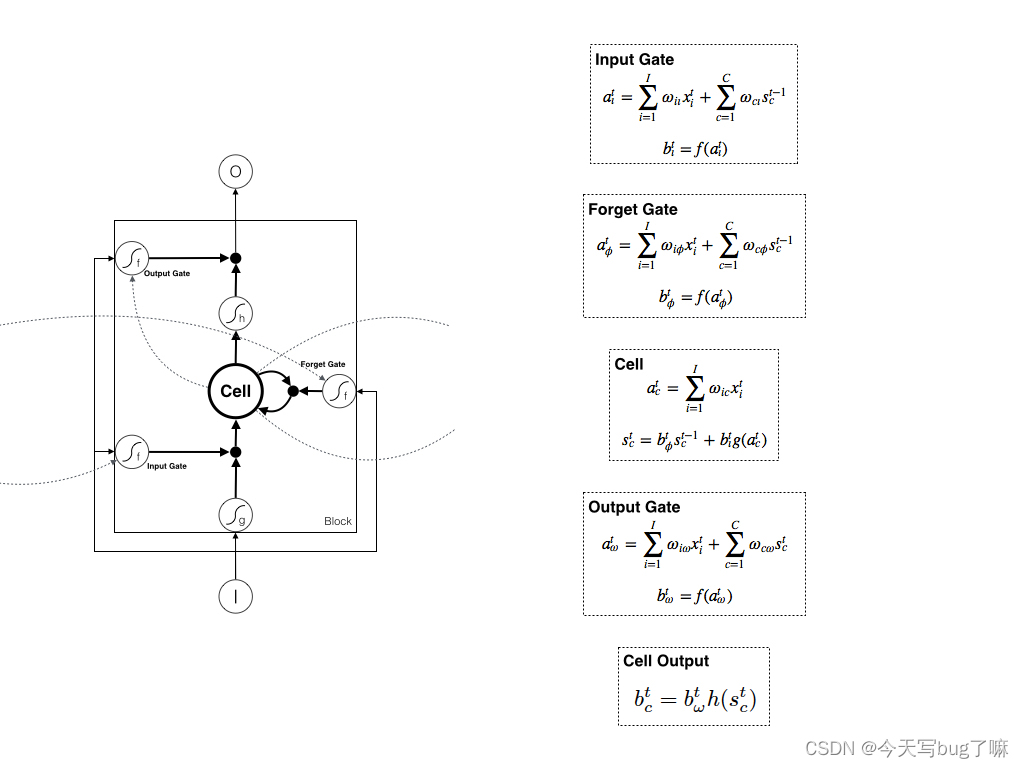
4.1 LSTM结构推导,为什么比RNN好?
推导forget gate,input gate,cell state, hidden information等的变化;因为LSTM有进有出且当前的cell informaton是通过input gate控制之后叠加的,RNN是叠乘,因此LSTM可以防止梯度消失或者爆炸。
4.2 为什么LSTM模型中既存在sigmoid又存在tanh两种激活函数,而不是选择统一一种sigmoid或者tanh?
sigmoid用在了各种gate上,产生0~1之间的值,一般只有sigmoid最直接了;
tanh用在了状态和输出上,是对数据的处理,这个用其他激活函数或许也可以。
4.3 LSTM中为什么经常是两层双向LSTM?
有些时候预测需要由前面若干输入和后面若干输入共同决定,这样会更加准确。
4.4 RNN扩展改进
4.4.1 Bidirectional RNNs
将两层RNNs叠加在一起,当前时刻输出(第t步的输出)不仅仅与之前序列有关,还与之后序列有关。例如:为了预测一个语句中的缺失词语,就需要该词汇的上下文信息。Bidirectional RNNs是一个相对较简单的RNNs,是由两个RNNs上下叠加在一起组成的。输出由前向RNNs和后向RNNs共同决定。
4.4.2 CNN-LSTMs
该模型中,CNN用于提取对象特征,LSTMs用于预测。CNN由于卷积特性,其能够快速而且准确地捕捉对象特征。LSTMs的优点:能够捕捉数据间的长时依赖性。
4.4.3 Bidirectional LSTMs
有两层LSTMs。 一层处理过去的训练信息,另一层处理将来的训练信息。
通过前向LSTMs获得前向隐藏状态,后向LSTMs获得后向隐藏状态,当前隐藏状态是前向隐藏状态与后向隐藏状态的组合。
4.4.4 GRU
(14年提出)是一般的RNNs的变型版本,其主要是从以下两个方面进行改进。
1.以语句为例,序列中不同单词处的数据对当前隐藏层状态的影响不同,越前面的影响越小,即每个之前状态对当前的影响进行了距离加权,距离越远,权值越小。
2.在产生误差error时,其可能是由之前某一个或者几个单词共同造成,所以应当对对应的单词weight进行更新。GRUs的结构如下图所示。GRUs首先根据当前输入单词向量word vector以及前一个隐藏层状态hidden state计算出update gate和reset gate。再根据reset gate、当前word vector以及前一个hidden state计算新的记忆单元内容(new memory content)。当reset gate为1的时候,new memory content忽略之前所有memory content,最终的memory是由之前的hidden state与new memory content一起决定。
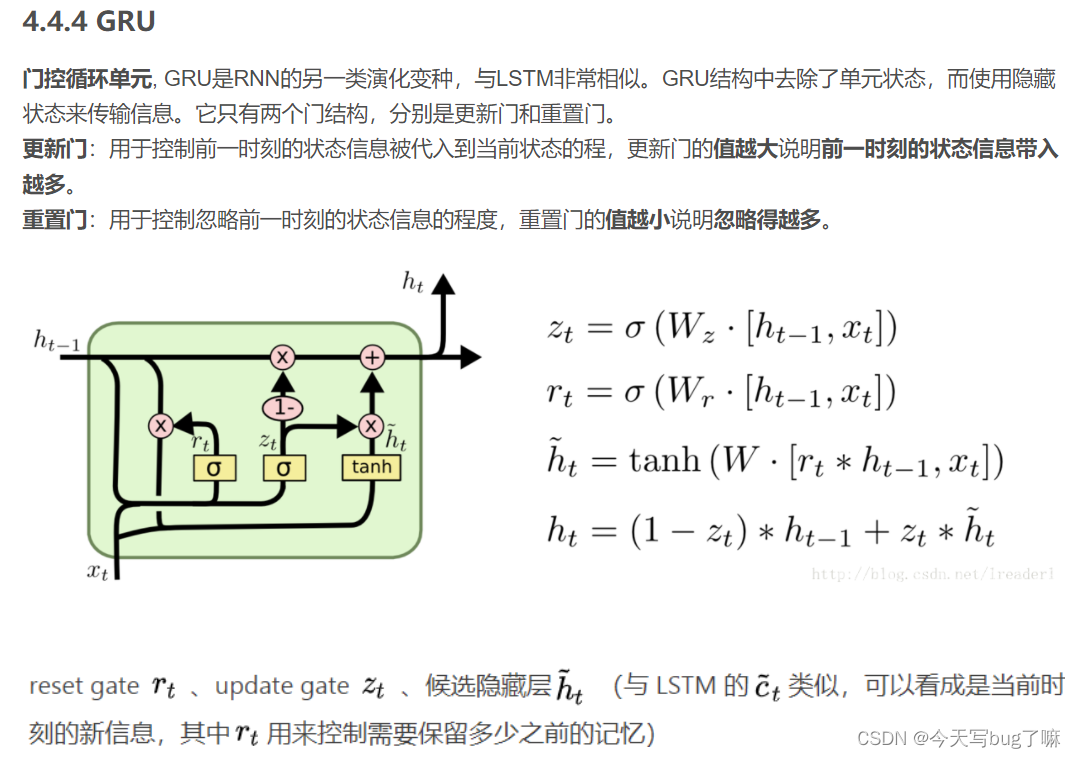
4.5 LSTM、RNN、GRU区别?

与LSTM相比,GRU内部少了一个”门控“,参数比LSTM少,但是却也能够达到与LSTM相当的功能。考虑到硬件的计算能力和时间成本,因而很多时候我们也就会选择更加实用的GRU。
4.6 LSTM是如何实现长短期记忆功能的?

4.7 LSTM的原理、写LSTM的公式、手推LSTM的梯度反向传播

4.7.1 正向传播

4.8 如何缓解梯度消失和梯度爆炸问题
- 使用门控循环单元(GRU)或长短期记忆网络(LSTM):这两种结构都是对 RNN 的改进,它们通过引入门控机制来控制信息的流动,从而缓解梯度消失和梯度爆炸的问题。GRU 和 LSTM 中的门控机制可以控制哪些信息应该被保留或遗忘,从而使模型更加稳定。
- 使用梯度裁剪:梯度裁剪是一种简单而有效的方法,可以防止梯度爆炸。在训练过程中,可以对梯度进行裁剪,使其不超过某个阈值。这样可以确保梯度不会变得过大,从而避免梯度爆炸。
- 使用正则化:正则化可以帮助控制模型的复杂度,从而缓解梯度消失和梯度爆炸的问题。常见的正则化方法包括 L1 和 L2 正则化、Dropout 等。
- 使用残差连接:残差连接是一种在深度神经网络中常用的技术,它可以帮助解决梯度消失和梯度爆炸的问题。在 RNN 中,可以在每个时间步的输出上添加一个残差连接,将当前时间步的输出与前一个时间步的输出相加,然后将结果作为当前时间步的输出。这样可以确保信息在模型中传递,从而缓解梯度消失和梯度爆炸的问题。
- 使用更好的初始化:在训练 RNN 时,初始化权重非常重要。如果权重初始化不当,可能会导致梯度消失或梯度爆炸。可以使用 Xavier 初始化或 He 初始化等方法来初始化权重,这些方法可以确保权重的分布更加均匀,从而缓解梯度消失和梯度爆炸的问题。

