
- 1MySql 查询流程_数据库查询的流程是
- 2家庭安防监控设备搭建_安防监控系统搭建
- 3ISE 关联 Modelsim 详细操作
- 4flex弹性布局(所有孩子设置宽度计算后超过父亲时)_弹性布局后能允许超出父盒子吗
- 5Elastic Search个人学习(4) 分词器 2 tokenizer与token filter_elastic search tokenizer
- 6STM32使用常见错误合集(正在更新版)_../core/src/stm32f1xx_it.c:209:23: error: 'hdma_sp
- 7深度学习 Lecture 4 Adam算法、全连接层与卷积层的区别、图计算和反向传播
- 8PYTHON中XGBOOST的使用_python xgboost
- 9Kafka入门学习_kafka myid
- 10LightGBM官方文档_lgbm官方文档
【深度学习】准备个人数据集、YOLOV5 模型的训练和测试_选择一个应用场景,自己准备数据集,用深度学习模型进行训练,调整(修改)模型,测试,
赞
踩
上一篇描述了在win10下,基于anaconda & pytorch 的深度学习环境的准备搭建过程,下面进行个人数据集的准备,YOLOV5的代码下载测试,训练个人数据集测试识别效果。
一、个人数据集的准备
做深度学习,YOLOV5模型的图像识别,我们需要大量的数据集来进行训练,才能达到准确识别的效果。
制作数据集需要用到 lebelimg 来将我们的数据图片做数据标注生成xml文件。
1.1 libelimg 的安装
(下面是安装过程,可以按步骤进行安装,也可以直接用exe程序 省去安装过程 - 已经上传到我的资源)
首先打开cmd命令行(快捷键:win+R)。进入cmd命令行控制台。输入如下的命令:
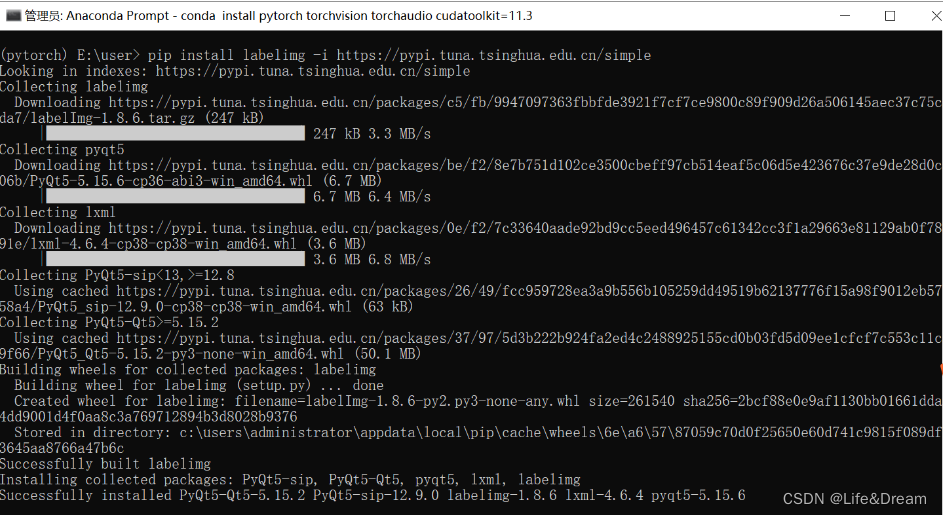
pip install labelimg -i https://pypi.tuna.tsinghua.edu.cn/simple
运行如上命令后,系统就会自动下载labelimg相关的依赖。由于这是一个很轻量的工具,所以下载起来很快。
1.2 使用labelimg 准备个人数据集
首先我们需要准备 - 需要打标注的数据集。建议新建一个名为VOC2007的文件夹(通常yolo模型中数据集都以这个为名称,统一不易出错 & 当然你想要个性一点起一个自己名字***也不是不行,在后面的训练中自己可以分清楚就OK),
里面创建一个名为JPEGImages的文件夹存放我们需要打标签的图片文件;再创建一个名为Annotations存放标注的标签文件;最后创建一个名为 predefined_classes.txt 的txt文件来存放所要标注的类别名称。
VOC2007的目录结构为:
├── VOC2007
│├── JPEGImages 存放需要打标签的图片文件
│├── Annotations 存放标注的标签文件
│├── predefined_classes.txt 定义自己要标注的所有类别(在我们定义类别比较多的时候,创建一个这样的txt文件来存放类别)
将要所有训练的数据集图片放到JPEGImages文件夹下,待标注。
(若有多个类别将要定义,将类名输入到predefined_classes.txt文件中,如图: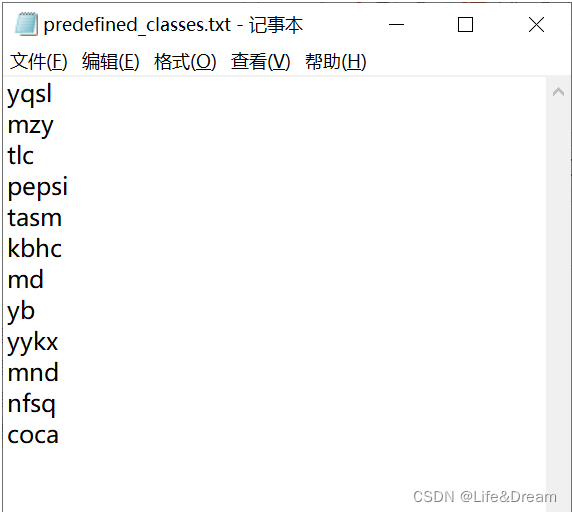
之后打开刚刚下载的labelimg(也可在python命令行终端输入labelimg打开)
(若直接使用exe程序 ,则直接打开就可以,如图:)
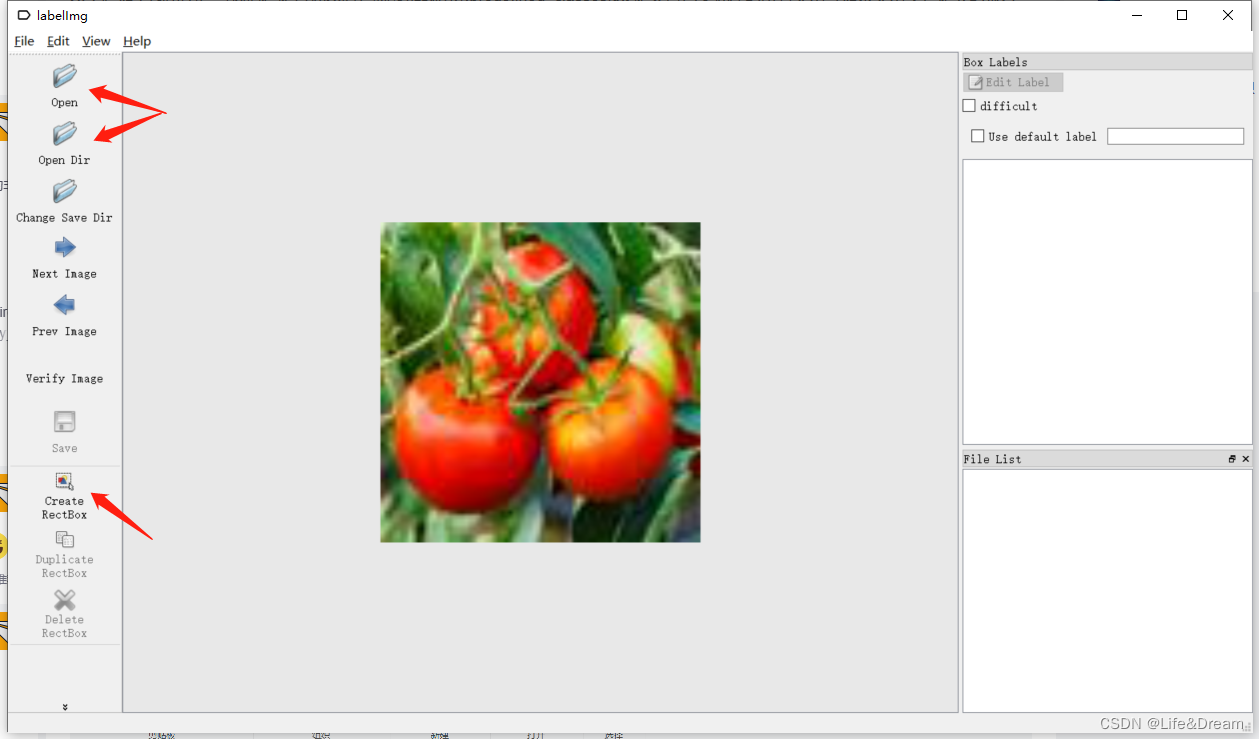
打开后为如下界面:(后面为标注程序,前面终端可显示你的操作记录)
下面介绍图中的我们常用的按钮。 待标注图片数据的路径文件夹,这里输入命令的时候就选定了JPEGImages。(当然这是可以换的)
待标注图片数据的路径文件夹,这里输入命令的时候就选定了JPEGImages。(当然这是可以换的) 保存类别标签的路径文件夹,这里我们选定了Annotations文件夹。
保存类别标签的路径文件夹,这里我们选定了Annotations文件夹。
常用快捷键如下:
A:切换到上一张图片
D:切换到下一张图片
W:调出标注十字架
del :删除标注框框
Ctrl+u:选择标注的图片文件夹
Ctrl+r:选择标注好的label标签存在的文件夹
开始标注:
先点击open打开单个图片,或者open air直接打开要标注图片所在文件夹
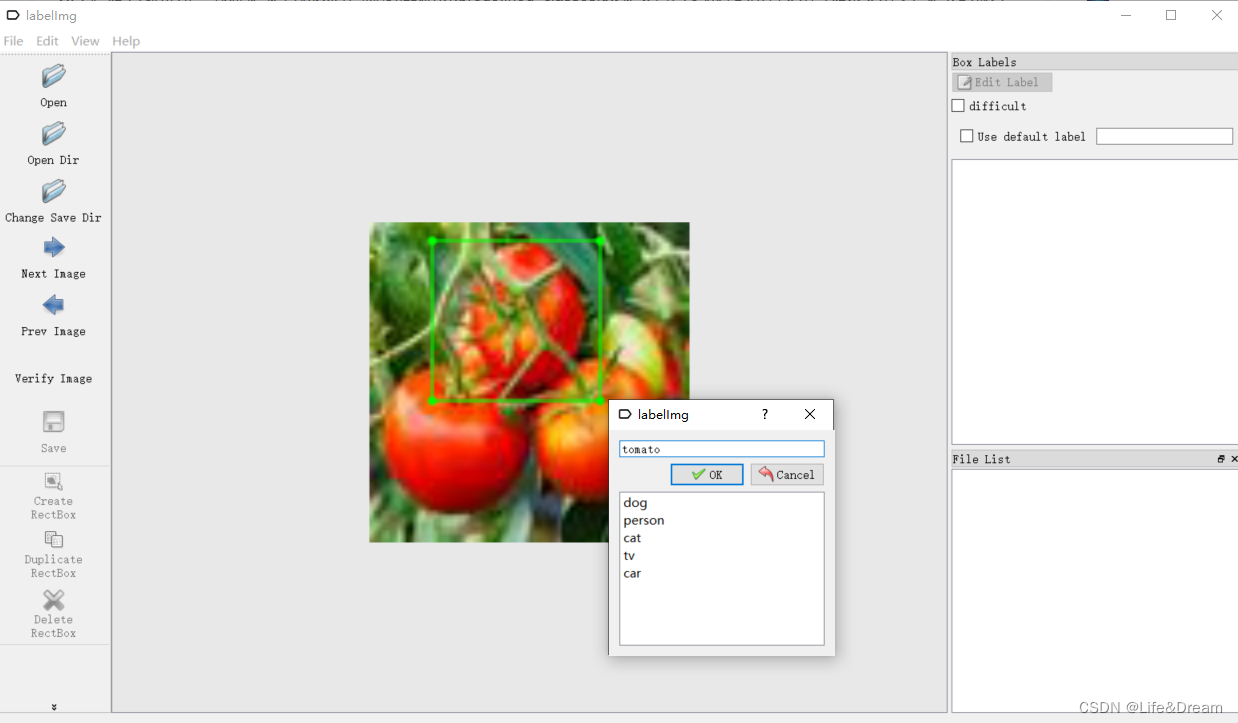
再点击create rectbox ,出现红色十字进行框选标注,框选后需要输入标注框的类名,即我们进行训练的类名。
最后点save ,我们所标注的xml文件就保存在了对应的文件夹。
按顺序将你要训练的图片一一标注即可。
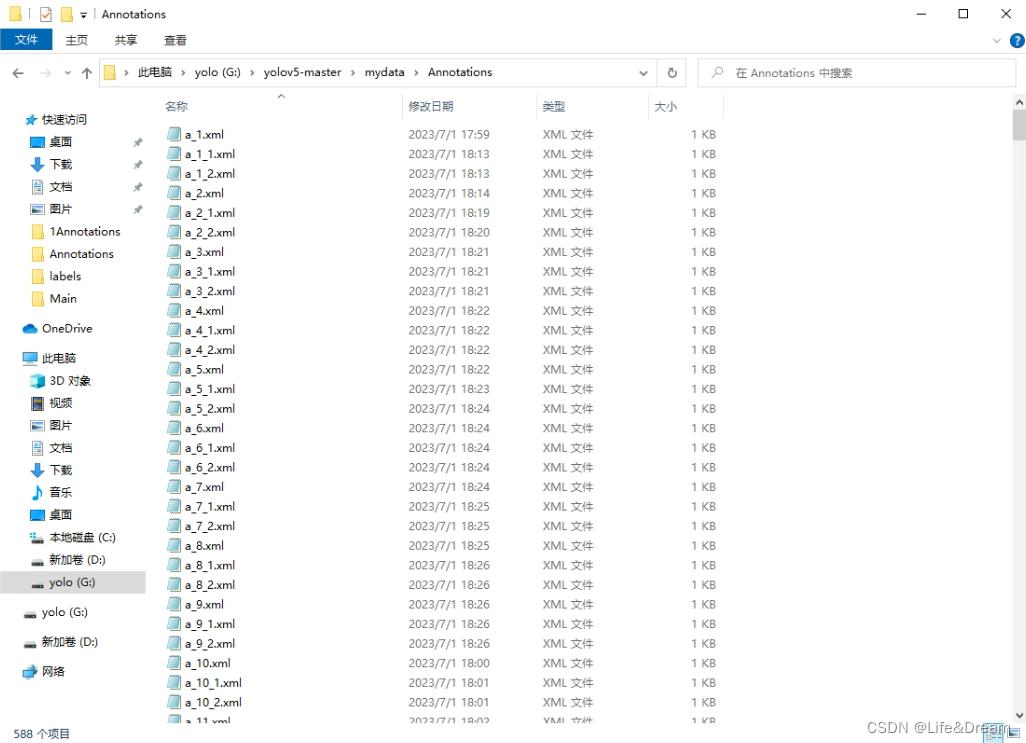
最终文件如图:
1.3 VOC标签格式转yolo格式并划分训练集和测试集
我们的数据集标签的格式是VOC(xml格式)的,而yolov5训练所需要的文件格式是yolo(txt格式)的,这里就需要对xml格式的标签文件转换为txt文件。同时训练自己的yolov5检测模型的时候,数据集需要划分为训练集和验证集。这里提供了一份代码将xml格式的标注文件转换为txt格式的标注文件,并按比例划分为训练集和验证集。先上代码再讲解代码的注意事项。
1.3.1 这个py脚本用于提取数据图片的名称,存放在对应的四个文件夹里。在下面的数据标注文件格式转换中用到
- # coding:utf-8
- #这里生成的文件在后面转换VOC - YOLO格式时用到
-
- import os
- import random
- import argparse
-
- parser = argparse.ArgumentParser()
- #xml文件的地址,根据自己的数据进行修改 xml一般存放在Annotations下
- parser.add_argument('--xml_path', default='Annotations', type=str, help='input xml label path')
- #数据集的划分,地址选择自己数据下的ImageSets/Main
- parser.add_argument('--txt_path', default='ImageSets/Main', type=str, help='output txt label path')
- opt = parser.parse_args()
-
- trainval_percent = 0.7 # 训练集和验证集所占比例。 这里没有划分测试集
- train_percent = 0.8 # 训练集所占比例,可自己进行调整
- xmlfilepath = opt.xml_path
- txtsavepath = opt.txt_path
- total_xml = os.listdir(xmlfilepath)
- if not os.path.exists(txtsavepath):
- os.makedirs(txtsavepath)
-
- num = len(total_xml)
- list_index = range(num)
- tv = int(num * trainval_percent)
- tr = int(tv * train_percent)
- trainval = random.sample(list_index, tv)
- train = random.sample(trainval, tr)
-
- file_trainval = open(txtsavepath + '/trainval.txt', 'w')
- file_test = open(txtsavepath + '/test.txt', 'w')
- file_train = open(txtsavepath + '/train.txt', 'w')
- file_val = open(txtsavepath + '/val.txt', 'w')
-
- for i in list_index:
- name = total_xml[i][:-4] + '\n'
- if i in trainval:
- file_trainval.write(name)
- if i in train:
- file_train.write(name)
- else:
- file_val.write(name)
- else:
- file_test.write(name)
-
- file_trainval.close()
- file_train.close()
- file_val.close()
- file_test.close()
-

1.3.2 将xml格式的标注文件转换为txt格式
这里用到的['train', 'val', 'test']三个文件是在上一个脚本生成的,其他注释我都放在代码里了。
^要注意的是‘dataSet_path’ 这个文件夹是在以后跑YOLO训练时候在自己的VOC.yaml 中用到的指向训练用数据的地址。(后面附上我的VOC.yaml 文件)
- # -*- coding: utf-8 -*-
- import xml.etree.ElementTree as ET
- import os
- from os import getcwd
-
- sets = ['train', 'val', 'test'] #后面获取图片路径用到的文件夹名称
- classes = ["10分", "80分", "30分", "95分"] # 改成自己的类别
- abs_path = os.getcwd()
- print(abs_path)
-
-
- def convert(size, box):
- dw = 1. / (size[0])
- dh = 1. / (size[1])
- x = (box[0] + box[1]) / 2.0 - 1
- y = (box[2] + box[3]) / 2.0 - 1
- w = box[1] - box[0]
- h = box[3] - box[2]
- x = x * dw
- w = w * dw
- y = y * dh
- h = h * dh
- return x, y, w, h
-
-
- def convert_annotation(image_id):
- in_file = open('G:/yolov5-master/mydata/Annotations/%s.xml' % (image_id), encoding='UTF-8') #自己 xml 文件地址
- out_file = open('G:/yolov5-master/mydata/labels/%s.txt' % (image_id), 'w') #生成的yolo(txt格式)存放文件夹路径
- tree = ET.parse(in_file)
- root = tree.getroot()
- size = root.find('size')
- w = int(size.find('width').text)
- h = int(size.find('height').text)
- for obj in root.iter('object'):
- difficult = obj.find('difficult').text
- # difficult = obj.find('Difficult').text
- cls = obj.find('name').text
- if cls not in classes or int(difficult) == 1:
- continue
- cls_id = classes.index(cls)
- xmlbox = obj.find('bndbox')
- b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
- float(xmlbox.find('ymax').text))
- b1, b2, b3, b4 = b
- # 标注越界修正
- if b2 > w:
- b2 = w
- if b4 > h:
- b4 = h
- b = (b1, b2, b3, b4)
- bb = convert((w, h), b)
- out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
-
-
- wd = getcwd()
- for image_set in sets:
- if not os.path.exists('G:/yolov5-master/mydata/labels/'):
- os.makedirs('G:/yolov5-master/mydata/labels/')
-
- image_ids = open('G:/yolov5-master/mydata/ImageSets/Main/%s.txt' % (image_set)).read().strip().split() #获取图片名称,这里的三个txt文件是上一个.py生成的
-
- if not os.path.exists('G:/yolov5-master/mydata/dataSet_path/'):
- os.makedirs('G:/yolov5-master/mydata/dataSet_path/')
-
- list_file = open('dataSet_path/%s.txt' % (image_set), 'w') #训练用到的数据集数据存放在dataSet_path文件夹下
- # 这行路径不需更改,这是相对路径
- for image_id in image_ids:
- list_file.write('G:/yolov5-master/mydata/images/%s.jpg\n' % (image_id))
- convert_annotation(image_id)
- list_file.close()
-
VOC.yaml
- train: G:/yolov5-master/mydata/dataSet_path/train.txt
- val: G:/yolov5-master/mydata/dataSet_path/val.txt
-
- nc: 4 #类别数量
-
-
- names: ["10分", "80分", "30分", "95分"] #所有 类 的名称
到这里训练用的数据集就准备完毕了。
二、克隆项目代码 & 必要的环境依赖
1.准备项目代码
YOLOv5的代码是开源的,我们可以从github上克隆其源码。
打开yolov5的github的官网(这个网站在国外打开是很慢的,需要一些魔法。若实在打不开也可以到这个网址下载gitee中的镜像库)
打开的官网界面如下,这个就是大神glenn-jocher开源的yolov5的项目。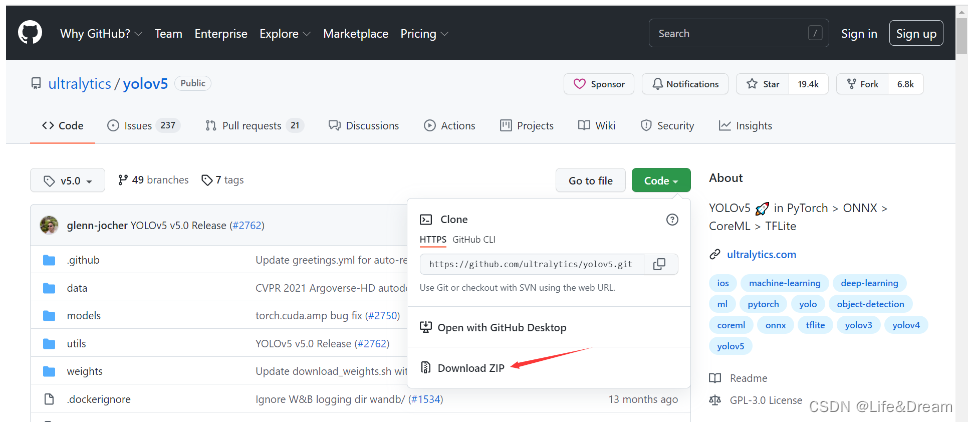
这个开源的项目通过大家的不断的完善和修复已经到了第5个分支,因此我们选择第五个版本来实验,首先点击左上角的master这个图标来选择项目的第5个分支,如下图所示,然后将版本选择好以后,点击右上角的code那个按键,将代码下载下来。至此整个项目就已经准备好了。
将我们下载好的yolov5的代码解压,然后用上个文章安装好的pycharm打开,打开之后整个代码目录如下图:(我已经进行过一些训练,有些自己的文件,所以文件目录可能有所不同)
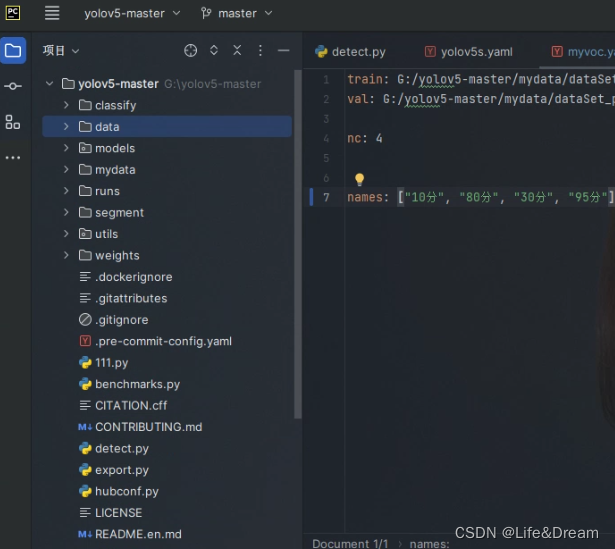
现在来对代码的整体目录做一个介绍:
data:主要是存放一些超参数的配置文件(这些文件(yaml文件)是用来配置训练集和测试集还有验证集的路径的,其中还包括目标检测的种类数和种类的名称);还有一些官方提供测试的图片。如果是训练自己的数据集的话,那么就需要修改其中的yaml文件。但是自己的数据集不建议放在这个路径下面,而是建议把数据集放到yolov5项目的同级目录下面。
models:里面主要是一些网络构建的配置文件和函数,其中包含了该项目的四个不同的版本,分别为是s、m、l、x。从名字就可以看出,这几个版本的大小。他们的检测测度分别都是从快到慢,但是精确度分别是从低到高。这就是所谓的鱼和熊掌不可兼得。如果训练自己的数据集的话,就需要修改这里面相对应的yaml文件来训练自己模型。
utils:存放的是工具类的函数,里面有loss函数,metrics函数,plots函数等等。
weights:放置训练好的权重参数。
detect.py:利用训练好的权重参数进行目标检测,可以进行图像、视频和摄像头的检测。
train.py:训练自己的数据集的函数。
test.py:测试训练的结果的函数。
requirements.txt:这是一个文本文件,里面写着使用yolov5项目的环境依赖包的一些版本,可以利用该文本导入相应版本的包。
以上就是yolov5项目代码的整体介绍。我们训练和测试自己的数据集基本就是利用到如上的代码。
2. 安装环境和依赖库
打开requirements.txt这个文件,可以看到里面有很多的依赖库和其对应的版本要求。
我们打开pycharm的命令终端,在中输入如下的命令。
( ^ 这里要注意,有些包需要特定的库支持才可以,需要安装VS , 这里我的电脑之前就装了VS2019 ,所以没有报错)
pip install -r requirements.txt
三、准备数据集和YOLOV5预训练权重文件
1. 数据集就是上面用labelimg标注并处理过的数据集
2. 获得预训练权重
一般为了缩短网络的训练时间,并达到更好的精度,我们一般加载预训练权重进行网络的训练。而yolov5的5.0版本给我们提供了几个预训练权重,我们可以对应我们不同的需求选择不同的版本的预训练权重。通过如下的图可以获得权重的名字和大小信息,可以预料的到,预训练权重越大,训练出来的精度就会相对来说越高,但是其检测的速度就会越慢。预训练权重可以通过这个网址进行下载(这依然是国外的网址,进不去的可以到这个网址下载镜像),本次训练自己的数据集用的预训练权重为yolov5s.pt。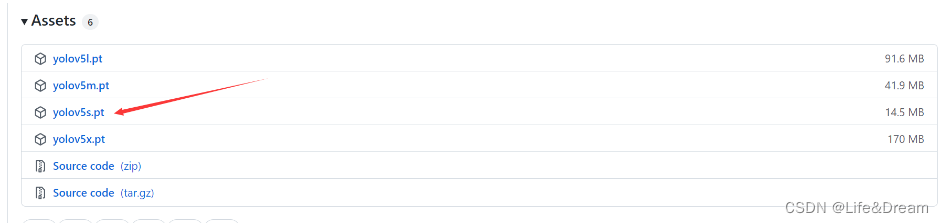
四、训练自己的模型
1.修改数据配置文件
预训练模型和数据集都准备好了,就可以开始训练自己的yolov5目标检测模型了,训练目标检测模型需要修改两个yaml文件中的参数。一个是data目录下的相应的yaml文件,一个是model目录文件下的相应的yaml文件。
【 修改data目录下的相应的yaml文件。找到目录下的voc.yaml文件,将该文件复制一份,将复制的文件重命名,最好和项目相关,这样方便后面操作。】
【我这里修改为myvoc.yaml。只保留了几行重要的代码,其他的都删掉了。即上面提到过的voc.yaml】
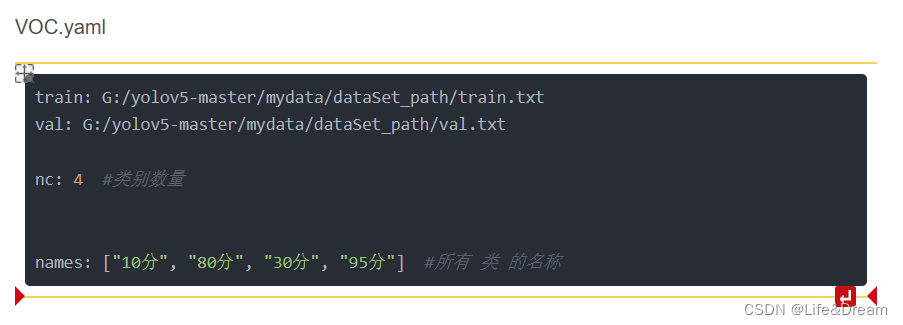
2. 修改模型配置文件
我们使用的是yolov5s.pt这个预训练权重,所以要使用models目录下的yolov5s.yaml文件中的相应参数(因为不同的预训练权重对应着不同的网络层数,所以用错预训练权重会报错)。同上修改data目录下的yaml文件一样,我们将yolov5s.yaml文件复制一份,然后将其重命名。
打开自己复制的yolov5s.yaml文件 ,这里我们只需要修改如图中的数字,表示识别的类别个数。
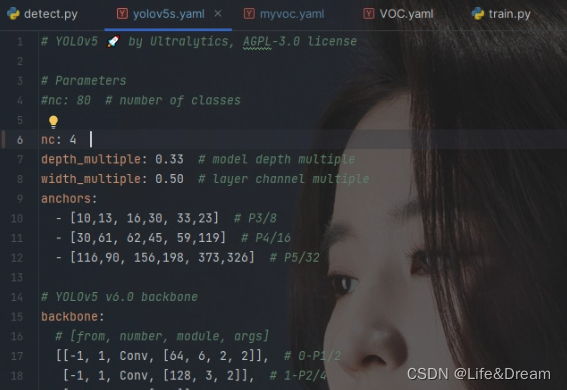
至此,相应的配置参数就修改好了。
3. 训练自己的模型启用tensorbord查看参数
上面的工作都做好之后,就可以正式开始我们YOLOV5的训练了
首先找到train.py这个文件。
然后找到主函数的入口,有模型的主要参数。模型的主要参数解析如下所示:
- > if name == ‘main’:
- > opt模型主要参数解析:
- > --weights:初始化的权重文件的路径地址
- > --cfg:模型yaml文件的路径地址
- > --data:数据yaml文件的路径地址
- > --hyp:超参数文件路径地址
- > --epochs:训练轮次
- > --batch-size:喂入批次文件的多少
- > --img-size:输入图片尺寸
- > --rect:是否采用矩形训练,默认False
- > --resume:接着打断训练上次的结果接着训练
- > --nosave:不保存模型,默认False
- > --notest:不进行test,默认False
- > --noautoanchor:不自动调整anchor,默认False
- > --evolve:是否进行超参数进化,默认False
- > --bucket:谷歌云盘bucket,一般不会用到
- > --cache-images:是否提前缓存图片到内存,以加快训练速度,默认False
- > --image-weights:使用加权图像选择进行训练
- > --device:训练的设备,cpu;0(表示一个gpu设备cuda:0);0,1,2,3(多个gpu设备)
- > --multi-scale:是否进行多尺度训练,默认False
- > --single-cls:数据集是否只有一个类别,默认False
- > --adam:是否使用adam优化器
- > --sync-bn:是否使用跨卡同步BN,在DDP模式使用
- > --local_rank:DDP参数,请勿修改
- > --workers:最大工作核心数
- > --project:训练模型的保存位置
- > --name:模型保存的目录名称
- > --exist-ok:模型目录是否存在,不存在就创建
其中最重要的,我们要(前三行)
将‘ 初始化的权重文件的路径地址’ 修改为自己预训练权重的路径(即yolov5s.pt 的路径)
将 模型yaml文件的路径地址 修改为自己对应的地址
将数据yaml文件的路径地址 修改为自己对应的地址
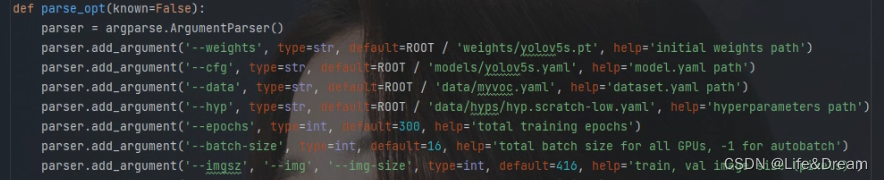
接下来运行train.py 就会训练自己的模型了,我们只需要静静的等待,去泡壶茶 或者 开一局王者放松一下也不是不行的~~~
五、测试
在“漫长的等待后~ ”,就会在主目录下产生一个run文件夹,我们用自己的数据集训练的权重文件就在run/train/exp/weights目录下。会产生两个权重文件,一个是最后一轮的权重文件last.pt,一个是最好的权重文件best.pt,接下来我们就要利用这个best.pt来做测试。除此以外还会产生一些验证文件的图片等一些文件。
找到主目录下的detect.py文件,打开该文件。
然后找到主函数的入口,这里面有模型的主要参数。模型的主要参数解析如下所示。
“”"
–weights:权重的路径地址
–source:测试数据,可以是图片/视频路径,也可以是’0’(电脑自带摄像头),也可以是rtsp等视频流
–output:网络预测之后的图片/视频的保存路径
–img-size:网络输入图片大小
–conf-thres:置信度阈值
–iou-thres:做nms的iou阈值
–device:是用GPU还是CPU做推理
–view-img:是否展示预测之后的图片/视频,默认False
–save-txt:是否将预测的框坐标以txt文件形式保存,默认False
–classes:设置只保留某一部分类别,形如0或者0 2 3
–agnostic-nms:进行nms是否也去除不同类别之间的框,默认False
–augment:推理的时候进行多尺度,翻转等操作(TTA)推理
–update:如果为True,则对所有模型进行strip_optimizer操作,去除pt文件中的优化器等信息,默认为False
–project:推理的结果保存在runs/detect目录下
–name:结果保存的文件夹名称
“”"
- f name == ‘main’:
- parser = argparse.ArgumentParser()
- parser.add_argument(‘–weights’, nargs=‘+’, type=str, default=‘yolov5s.pt’, help=‘model.pt path(s)’)
- parser.add_argument(‘–source’, type=str, default=‘data/images’, help=‘source’) # file/folder, 0 for webcam
- parser.add_argument(‘–img-size’, type=int, default=640, help=‘inference size (pixels)’)
- parser.add_argument(‘–conf-thres’, type=float, default=0.25, help=‘object confidence threshold’)
- parser.add_argument(‘–iou-thres’, type=float, default=0.45, help=‘IOU threshold for NMS’)
- parser.add_argument(‘–device’, default=‘’, help=‘cuda device, i.e. 0 or 0,1,2,3 or cpu’)
- parser.add_argument(‘–view-img’, action=‘store_true’, help=‘display results’)
- parser.add_argument(‘–save-txt’, action=‘store_true’, help=‘save results to *.txt’)
- parser.add_argument(‘–save-conf’, action=‘store_true’, help=‘save confidences in --save-txt labels’)
- parser.add_argument(‘–nosave’, action=‘store_true’, help=‘do not save images/videos’)
- parser.add_argument(‘–classes’, nargs=‘+’, type=int, help=‘filter by class: --class 0, or --class 0 2 3’)
- parser.add_argument(‘–agnostic-nms’, action=‘store_true’, help=‘class-agnostic NMS’)
- parser.add_argument(‘–augment’, action=‘store_true’, help=‘augmented inference’)
- parser.add_argument(‘–update’, action=‘store_true’, help=‘update all models’)
- parser.add_argument(‘–project’, default=‘runs/detect’, help=‘save results to project/name’)
- parser.add_argument(‘–name’, default=‘exp’, help=‘save results to project/name’)
- parser.add_argument(‘–exist-ok’, action=‘store_true’, help=‘existing project/name ok, do not increment’)
- opt = parser.parse_args()
这里需要将刚刚训练好的最好的权重传入到推理函数中去。然后就可以对图像视频进行推理了。
parser.add_argument(‘–weights’, nargs=‘+’, type=str, default=‘自己训练的权重路径/best.pt’, help=‘model.pt path(s)’)
对图片进行测试推理,将如下参数修改成图片的路径,然后运行detect.py就可以进行测试了。
parser.add_argument(‘–source’, type=str, default=‘你要做推理测试的路径’, help=‘source’)
推理测试结束以后,在run下面会生成一个detect目录,推理结果会保存在exp目录下。如图所示。
图片的推理结果如下所示。效果还是很不错的。
1
对视频进行测试,需要将图片的路径改为视频的路径。
利用摄像头进行测试只需将路径改写为0。
利用摄像头测试报错,解决方法之一(来源于@每天写bug):

解决方法:首先找到datasets.py这个py文件。
打开文件,找到第279行代码,给两个url参数加上str就可以了,如图所示,就可以完美运行电脑的摄像头了。
到这yolov5训练自己的模型就完成了,可以使用自己训练的权重去识别。
修改训练参数 以提高训练速度or识别精度,待下一章

