
- 1利用MATLAB进行数学建模_2、用给定的多项式,如,产生一组数据(),再在上添加随机干扰(可用rand产生(0,1)均匀
- 2鸿蒙:@Link装饰器-父子双向同步
- 3夸张!NLP顶会EMNLP 2023投稿近5000篇!奖项出炉:北大、腾讯摘最佳长论文
- 4HarmonyOS 发送http网络请求_harmonyos的get网络请求带参数
- 5毕设分享 基于STM32的毕业设计题目项目汇总 - 100例_基于stm32的100个毕业设计
- 6PyTorch 深度学习(GPT 重译)(三)
- 7android正则表达式及Pattern Matcher使用_android pattern 符号/
- 8可以直接用于HTML中的特殊字符表 unicode字符集_html引入unicode文件
- 9抗侧力构件弹性位移如何计算_高层住宅结构YJK前处理计算参数设置(一)
- 10[HarmonyOS][鸿蒙专栏开篇]快速入门OpenHarmony的LiteOS微内核_openharmony源码学习从内核开始吗
十一、MYSQL 基于MHA的高可用集群
赞
踩
目录
7、进行检测工作,检测ssh免密和主从,在manager上执行:
2、在master停掉MySQL服务,观察manager的日志
3、在master上可以看到虚拟的VIP,已经消失,查看从节点,可以看到VIP,如下图
1、先将mysql1设置成master(mysql2)的从服务器,设置只读
2、关掉当前master(mysql2)的同步功能,否则从服务器会报错
4、检查无密码认证和 MySQL 主从状态是否正常,启动MHA
能力有限,不足之处,请大家批评指正。
上一章安装了mysql以及搭建了主从复制。接下来搭建MHA基于MySQL的高可用
一、MHA概述
1、简介
目前mysql高可用方面是一个相对成熟的解决方案,MHA是一套优秀的MySQL故障切换和主从复制的高可用软件
在MySQL故障切换过程中,MHA能做到0-30秒之内完成数据库的故障切换操作,并且在进行故障切换过程中,MHA能够最大程度上保证数据的一致性,已达到真正意义上的高可用。
MHA里有两个角色,一个是MHA Node(数据节点)另一个是MHA Manager(管理节点)。
MHA MAster节点可以单独部署在一台独立的机器上管理多个master-slave集群,也可以部署在一台slave节点上,MHA Manager会定时探测集群中的master节点,当master出现故障时,它可以自动将最新数据的slave提升为master,然后将所有其他的slave重新指向新的master。整个故障转移过程对应用程序完全透明。
MHA Node运行在每台MySQL服务器上,它通过监控具备解析清理logs功能的脚本来加快故障转移的。
2、MHA 特点
自动故障切换过程中,MHA总会试图从宕机的主服务器上保存二进制日志,最大程度的保证数据不丢失。但是并不总是可行的,例如,如果主服务器硬件故障或者无法通过SSH访问,MHA则无法保存二进制日志,只能进行故障转移而丢失了最新的数据。此时,使用MySQL5.5的半同步复制,可以大大降低数据丢失的风险,MHA可以与半同步复制结合起来,如果只有一个slave已经收到了最新的二进制日志,MHA可以将最新的二进制日志应用于其他所有的slave服务器上,因此可以保证所有节点的数据一致性,有时候可故意设置从节点慢于主节点,当发生意外删除数据库导致数据丢失时,可从 从节点二进制日志中恢复。
3、MHA 工作原理(流程)
MHA 有3个部分
- 核心是主从
- Manager管理节点:管理数据库集群信息,定义、触发故障切换
- Node数据节点:主要负责保存日志,比较中继日志,选择主备
MHA会通过Node监控MySQL数据库服务的节点信息,定期检测和返回Master角色的健康状态(健康检查),MHA通过将VIP定义在Master节点上,并且数据库的访问也是从此VIP进入,当Master异常时,MHA会进行“故障切换”,就是VIP漂移。
工作原理:
- 从宕机崩溃的master保存二进制日志事件(binlog events)
- 识别含有最新更新的slave
- 应用差异的中继日志(relay log)到其他slave
- 应用从master保存的二进制日志事件
- 提升一个slave为新的master
- 使其他slave连接新的master进行复制
二、MHA高可用结构部署
1、环境准备
| 服务器 | IP | MHA |
| 192.168.134.132 | Master | node |
| 192.168.134.133 | Slave | manager |
| 192.168.134.134 | Slave | node |
| 192.168.134.100/24 | VIP |
- #首先检查软件是否已经安装
- 1、如果是rpm安装的,可以用rpm -qa |grep 软件包名字 检查
- 2、如果是yum方式安装的,可以用 yum list installed |grep 软件包名字 检查
- #1、所有节点安装MHA node 相关依赖:
- yum -y install epel-release
- yum -y install perl-DBD-MySQL perl-DBI ncftp
- #2、安装mha node:
- yum -y install https://github.com/yoshinorim/mha4mysql-node/releases/download/v0.58/mha4mysql-node-0.58-0.el7.centos.noarch.rpm
- #scp传到其他机器
- scp -r mha4mysql-node-0.58-0.el7.centos.noarch.rpm root@192.168.134.133:/usr/local/MHA/
- #安装
- [root@rabbitmq_2 MHA]# rpm -ivh mha4mysql-node-0.58-0.el7.centos.noarch.rpm
- 准备中... ################################# [100%]
- 正在升级/安装...
- 1:mha4mysql-node-0.58-0.el7.centos ################################# [100%]
- 所有从节点rpm安装 Node组件之后,会在/usr/bin 下有这几个脚本文件
- save_binary_logs 保存和复制 master 的二进制日志
- apply_diff_relay_logs 识别差异的中继日志事件并将其差异的事件应用于其他的 slave
- filter_mysqlbinlog 去除不必要的 ROLLBACK 事件

2、安装MHA 监控manager
安装在192.168.134.133机器上
- #下载地址
- yum -y install https://github.com/yoshinorim/mha4mysql-manager/releases/download/v0.58/mha4mysql-manager-0.58-0.el7.centos.noarch.rpm
- #下载好了之后,先安装依赖
- [root@rabbitmq_2 yum-root-nm0sqp]# yum -y install epel-release
- [root@rabbitmq_2 yum-root-nm0sqp]# yum -y install perl-Config-Tiny perl-Time-HiRes perl-Parallel-ForkManager perl-Log-Dispatch perl-DBD-MySQL ncftp
- 已加载插件:fastestmirror, langpacks
- Loading mirror speeds from cached hostfile
- * base: mirrors.163.com
- * epel: ftp.yz.yamagata-u.ac.jp
- * extras: mirrors.163.com
- * updates: mirrors.aliyun.com
- 软件包 perl-Config-Tiny-2.14-7.el7.noarch 已安装并且是最新版本
- 软件包 4:perl-Time-HiRes-1.9725-3.el7.x86_64 已安装并且是最新版本
- 软件包 perl-Parallel-ForkManager-1.18-2.el7.noarch 已安装并且是最新版本
- 软件包 perl-Log-Dispatch-2.41-1.el7.1.noarch 已安装并且是最新版本
- 软件包 perl-DBD-MySQL-4.023-6.el7.x86_64 已安装并且是最新版本
- 软件包 2:ncftp-3.2.5-7.el7.x86_64 已安装并且是最新版本
- 无须任何处理
- [root@rabbitmq_2 yum-root-nm0sqp]#
- # manager包安装
- [root@rabbitmq_2 yum-root-nm0sqp]# rpm -ivh mha4mysql-manager-0.58-0.el7.centos.noarch.rpm
- 准备中... ################################# [100%]
- 软件包 mha4mysql-manager-0.58-0.el7.centos.noarch 已经安装
- [root@rabbitmq_2 yum-root-nm0sqp]#
- # Manager组件安装之后,会在/usr/bin 有以下脚本
- [root@rabbitmq_2 bin]# ls |grep masterha
- masterha_check_repl #检查 MySQL 复制状况
- masterha_check_ssh # 检查 MHA 的 SSH 配置状况
- masterha_check_status #检测当前 MHA 运行状态
- masterha_conf_host #添加或删除配置的 server 信息
- masterha_manager #启动 manager的脚本
- masterha_master_monitor #检测 master 是否宕机
- masterha_master_switch #控制故障转移(自动或者手动)
- masterha_secondary_check #
- masterha_stop #关闭manager
3、在manager管理机器上配置管理节点:
- #创建相关目录
- mkdir /home/mha/conf #配置文件
- mkdir /home/mha #工作目录
- mkdir /home/mha/log #日志目录
- mkdir /home/mha/bin #脚本路径
-
- #编写配置文件
- vim /home/mha/conf/mysql_mha.cnf
- #添加
- [server default]
- #mha访问数据库的账号与密码
- user=mha
- password=xxxxxx
- port=3306
- #使用ssh登录时的用户
- ssh_user=root
- #指定mha的工作目录
- manager_workdir=/home/mha/
- #指定管理日志路径
- manager_log=/home/mha/log/manager.log
- #指定master节点存放binlog的日志文件的目录 log_bin=mysql_bin默认是在/var/lib/mysql
- master_binlog_dir=/var/lib/mysql
- #指定mha在远程节点上的工作目录
- remote_workdir=/home/mha/
- #指定主从复制的mysq用户和密码
- repl_user=repl
- repl_password=123456
- #指定检测间隔时间
- ping_interval=3
- ping_type=insert//更高效
- #指定一个脚本,该脚本实现了在主从切换之后,将虚拟ip漂移到新的master上
- master_ip_failover_script=/home/mha/bin/master_ip_failover
- #设置手动切换时的切换脚本位置
- master_ip_online_change_script=/home/mha/bin/master_ip_online_change
- #指定用于二次检查节点状态的节点,这里不要配置主节点的ip,否则主节点网络断掉或者机器断电就无法切换
- secondary_check_script=/usr/bin/masterha_secondary_check -s 192.168.134.133 -s 192.168.134.134
- #用于故障切换的时候发送邮件提醒的脚本,不用就注释掉
- #report_script=/home/mha/bin/send_mail
- log_level=debug //日志格式
-
-
-
- [server1]
- hostname=192.168.134.132
- port=3306
-
- [server2]
- hostname=192.168.134.133
- port=3306
-
- no_master=1
- ignore_fail=1
-
-
-
- [server3]
- hostname=192.168.134.134
-
- port=3306
- candidate_master=1
- #设置为候选master,设置该参数以后,发生主从切换以后将会将此从库提升为主库,即使这个主库不是集群中最新的slave
- check_repl_delay=0
4、编master_ip_failover脚本写
- #!/usr/bin/env perl
-
- use strict;
- use warnings FATAL => 'all';
-
- use Getopt::Long;
-
- my (
- $command, $orig_master_host, $orig_master_ip,$ssh_user,
- $orig_master_port, $new_master_host, $new_master_ip,$new_master_port,
- $orig_master_ssh_port,$new_master_ssh_port,$new_master_user,$new_master_password
- );
-
- # 这里定义的虚拟IP配置要注意,这个ip必须要与你自己的集群在同一个网段,否则无效
- my $vip = '192.168.134.100/24';
- my $key = '1';
- # 这里的网卡名称 “ens33” 需要根据你机器的网卡名称进行修改
- # 如果多台机器直接的网卡名称不统一,有两种方式,一个是改脚本,二是把网卡名称修改成统一
- # 我这边实际情况是修改成统一的网卡名称
- my $ssh_start_vip = "sudo /sbin/ifconfig ens33:$key $vip";
- my $ssh_stop_vip = "sudo /sbin/ifconfig ens33:$key down";
- my $ssh_Bcast_arp= "sudo /sbin/arping -I bond0 -c 3 -A $vip";
-
- GetOptions(
- 'command=s' => \$command,
- 'ssh_user=s' => \$ssh_user,
- 'orig_master_host=s' => \$orig_master_host,
- 'orig_master_ip=s' => \$orig_master_ip,
- 'orig_master_port=i' => \$orig_master_port,
- 'orig_master_ssh_port=i' => \$orig_master_ssh_port,
- 'new_master_host=s' => \$new_master_host,
- 'new_master_ip=s' => \$new_master_ip,
- 'new_master_port=i' => \$new_master_port,
- 'new_master_ssh_port' => \$new_master_ssh_port,
- 'new_master_user' => \$new_master_user,
- 'new_master_password' => \$new_master_password
-
- );
-
- exit &main();
-
- sub main {
- $ssh_user = defined $ssh_user ? $ssh_user : 'root';
- print "\n\nIN SCRIPT TEST====$ssh_user|$ssh_stop_vip==$ssh_user|$ssh_start_vip===\n\n";
-
- if ( $command eq "stop" || $command eq "stopssh" ) {
-
- my $exit_code = 1;
- eval {
- print "Disabling the VIP on old master: $orig_master_host \n";
- &stop_vip();
- $exit_code = 0;
- };
- if ($@) {
- warn "Got Error: $@\n";
- exit $exit_code;
- }
- exit $exit_code;
- }
- elsif ( $command eq "start" ) {
-
- my $exit_code = 10;
- eval {
- print "Enabling the VIP - $vip on the new master - $new_master_host \n";
- &start_vip();
- &start_arp();
- $exit_code = 0;
- };
- if ($@) {
- warn $@;
- exit $exit_code;
- }
- exit $exit_code;
- }
- elsif ( $command eq "status" ) {
- print "Checking the Status of the script.. OK \n";
- exit 0;
- }
- else {
- &usage();
- exit 1;
- }
- }
-
- sub start_vip() {
- `ssh $ssh_user\@$new_master_host \" $ssh_start_vip \"`;
- }
- sub stop_vip() {
- `ssh $ssh_user\@$orig_master_host \" $ssh_stop_vip \"`;
- }
-
- sub start_arp() {
- `ssh $ssh_user\@$new_master_host \" $ssh_Bcast_arp \"`;
- }
- sub usage {
- print
- "Usage: master_ip_failover --command=start|stop|stopssh|status --ssh_user=user --orig_master_host=host --orig_master_ip=ip --orig_master_port=port --new_master_host=host --new_master_ip=ip --new_master_port=port\n";
- }
-
- #给脚本添加可执行权限
- chmod 777 master_ip_failover
-
- #在所有节点都创建 MHA 工作目录
- mkdir /home/mha
5、在master上创建mha这个用户来访问数据库节点:
- mysql -uroot -p'xxxxxx'
- create user 'mha'@'%' identified with mysql_native_password by 'xxxxxx';
- grant all privileges on *.* to 'mha'@'%';
- flush privileges;
-
- #如果提示报错,看报错内容,应该是密码策略的问题,把密码策略改了就可以
- mysql> create user 'mha'@'%' identified with mysql_native_password by 'xxxxxx';
- ERROR 1819 (HY000): Your password does not satisfy the current policy requirements
- mysql>
-
- mysql> set global validate_password.policy=0;
- Query OK, 0 rows affected (0.00 sec)
-
-
- mysql> set global validate_password.length=4;
- Query OK, 0 rows affected (0.00 sec)
-
-
- mysql> flush privileges;
- Query OK, 0 rows affected (0.00 sec)
-
-
- mysql> create user 'mha'@'%' identified with mysql_native_password by 'xxxxxx';
- Query OK, 0 rows affected (0.00 sec)
6、配置无密码认证
- vim /etc/hosts
- 192.168.134.132 rabbitmq_1
- 192.168.134.133 rabbitmq_2
- 192.168.134.134 slave
-
- 1、在 master 上配置到所有数据库节点的无密码认证
- #前3行每台都要执行 ssh开始找一台执行即可
- ssh-keygen -t rsa #一直回车
- cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
- chmod 600 ~/.ssh/authorized_keys
-
- [root@rabbitmq_1 home]#
- ## 到slave1的免密登录
-
- #把其他节点得公钥信息写入本地authorized_keys 我是每台机器都执行了执行即可
- ssh 192.168.134.133 cat ~/.ssh/id_rsa.pub >>~/.ssh/authorized_keys
- ssh 192.168.134.134 cat ~/.ssh/id_rsa.pub >>~/.ssh/authorized_keys
- #测试
- #在192.168.134.132上
- ssh 192.168.134.133
- ssh 192.168.134.134
- #在192.168.134.133上
- ssh 192.168.134.132
- ssh 192.168.134.134
- #在192.168.134.134上
- ssh 192.168.134.132
- ssh 192.168.134.133
7、进行检测工作,检测ssh免密和主从,在manager上执行:
- [root@rabbitmq_2 conf]# masterha_check_ssh --conf=/home/mha/conf/mysql_mha.cnf
- Sat May 13 15:40:18 2023 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping.
- Sat May 13 15:40:18 2023 - [info] Reading application default configuration from /home/mha/conf/mysql_mha.cnf..
- Sat May 13 15:40:18 2023 - [info] Reading server configuration from /home/mha/conf/mysql_mha.cnf..
- Sat May 13 15:40:18 2023 - [info] Starting SSH connection tests..
- Sat May 13 15:40:19 2023 - [debug]
- Sat May 13 15:40:18 2023 - [debug] Connecting via SSH from root@192.168.134.132(192.168.134.132:22) to root@192.168.134.134(192.168.134.134:22)..
- Sat May 13 15:40:18 2023 - [debug] ok.
- Sat May 13 15:40:20 2023 - [debug]
- Sat May 13 15:40:18 2023 - [debug] Connecting via SSH from root@192.168.134.134(192.168.134.134:22) to root@192.168.134.132(192.168.134.132:22)..
- Sat May 13 15:40:19 2023 - [debug] ok.
- Sat May 13 15:40:20 2023 - [info] All SSH connection tests passed successfully.
-
- [root@rabbitmq_2 bin]# masterha_check_repl --conf=/home/mha/conf/mysql_mha.cnf
-
- MySQL Replication Health is OK.
- 就说明检测没问题
8、检测没问题 就在master主节点上 手动配置VIP
- #配置VIP
- [root@rabbitmq_1 bin]# ifconfig ens33:1 192.168.134.100
- #查看配置
- [root@rabbitmq_1 bin]# ifconfig
- #删除VIP
- [root@rabbitmq_1 bin]# ifconfig ens33:1 del 192.168.134.100
-
9、检测没有报错,就可以在manager上启动MHA
- 启动
- [root@rabbitmq_2 log]# nohup masterha_manager --conf=/home/mha/conf/mysql_mha.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /home/mha/log/manager.log 2>&1 &
- [1] 12544
- #或者
- [root@rabbitmq_2 conf]# nohup masterha_manager --conf=/home/mha/conf/mysql_mha.cnf &> /home/mha/log/manager.log &
- [1] 3897
-
- --conf=/home/mha/conf/mysql_mha.cnf #指定配置文件
- --ignore_last_failover #就是当有节点宕掉时,也能启动MHA
- --remove_dead_master_conf #当master服务器失效时,发生主从切换后,会把旧的master的ip从主配置文件删
- </dev/null> #生成的所有信息会导到nul1下或者/var/log/masterha/app1/manager.log日志文件中
- 2>&1& #把2错误性的输出 重定向为标准性输山,"&"开启后台运行
-
- 查看日志
- Checking the Status of the script.. OK
- Sat May 13 17:11:57 2023 - [info] OK.
- Sat May 13 17:11:57 2023 - [warning] shutdown_script is not defined.
- Sat May 13 17:11:57 2023 - [info] Set master ping interval 1 seconds.
- Sat May 13 17:11:57 2023 - [info] Set secondary check script: /usr/bin/masterha_secondary_check -s 192.168.134.133 -s 192.168.134.134
- Sat May 13 17:11:57 2023 - [info] Starting ping health check on 192.168.134.132(192.168.134.132:3306)..
- Sat May 13 17:11:57 2023 - [info] Ping(SELECT) succeeded, waiting until MySQL doesn't respond..
- 查看MHA状态
- [root@rabbitmq_2 log]# masterha_check_status --conf=/home/mha/conf/mysql_mha.cnf
- mysql_mha (pid:12544) is running(0:PING_OK), master:192.168.134.132
- 关闭
- [root@rabbitmq_2 log]# masterha_stop --conf=/home/mha/conf/mysql_mha.cnf
- Stopped mysql_mha successfully.
- [1]+ 退出 1 nohup masterha_manager --conf=/home/mha/conf/mysql_mha.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /home/mha/log/manager.log 2>&1
- [root@rabbitmq_2 log]#
三、故障模拟测试
故障切换备选主库的算法:
1、一般判断从库的是从(position/GTID)判断优劣,数据有差异,最接近于master的slave,成为备选主。
2、数据一致的情况下,按照配置文件顺序,选择备选主库。
3、设定有权重(candidate_master=1),按照权重强制指定备选主。
默认情况下如果一个slave落后master 100M的relay logs的话,即使有权重,也会失效。
如果check_repl_delay=0的话,即使落后很多日志,也强制选择其为备选主。
#测试
1、先在manager上监控日志
[root@rabbitmq_2 log]# tail -f manager.log2、在master停掉MySQL服务,观察manager的日志
[root@rabbitmq_1 bin]# systemctl stop mysqld.service3、在master上可以看到虚拟的VIP,已经消失,查看从节点,可以看到VIP,如下图
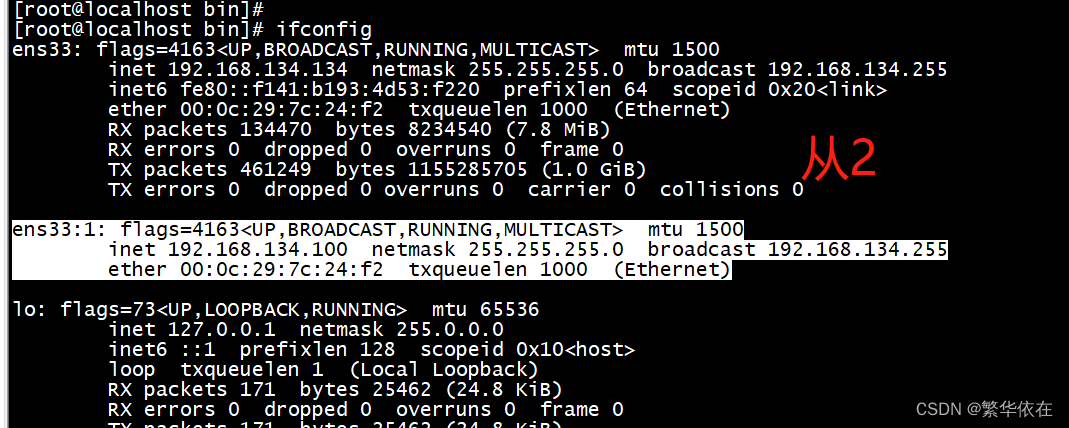
4、查看manager日志
-
- ----- Failover Report -----
-
- mysql_mha: MySQL Master failover 192.168.134.132(192.168.134.132:3306) to 192.168.134.134(192.168.134.134:3306) succeeded
-
- #这句话意思是 Master 宕掉了
-
- Master 192.168.134.132(192.168.134.132:3306) is down!
-
- Check MHA Manager logs at rabbitmq_2:/home/mha/log/manager.log for details.
-
- Started automated(non-interactive) failover.
- Invalidated master IP address on 192.168.134.132(192.168.134.132:3306)
- The latest slave 192.168.134.134(192.168.134.134:3306) has all relay logs for recovery.
-
- #这个为新的Master
- Selected 192.168.134.134(192.168.134.134:3306) as a new master.
- 192.168.134.134(192.168.134.134:3306): OK: Applying all logs succeeded.
- 192.168.134.134(192.168.134.134:3306): OK: Activated master IP address.
- Generating relay diff files from the latest slave succeeded.
- 192.168.134.134(192.168.134.134:3306): Resetting slave info succeeded.
- Master failover to 192.168.134.134(192.168.134.134:3306) completed successfully.
5、MHA发生切换之后
在工作目录会生成一个成功或者失败的标记 mysql_mha.failover.complete
- 下一次要启动mha之前要把这些标记文件删除,否则mha无法正常启动,因为有了这些标记文件,mha认为已经切换结束
- [root@rabbitmq_2 mha]# ls
- bin conf log mysql_mha.failover.complete
四、将宕机的MySQL,恢复为master
在线切换时 vip 的管理的脚本(可选)
- #!/usr/bin/env perl
-
- use strict;
- use warnings FATAL => 'all';
-
- use Getopt::Long;
- use MHA::DBHelper;
- use MHA::NodeUtil;
- use Time::HiRes qw( sleep gettimeofday tv_interval );
- use Data::Dumper;
-
- my $_tstart;
- my $_running_interval = 0.1;
- my (
- $command,
- $orig_master_is_new_slave, $orig_master_host, $orig_master_ip, $orig_master_port, $orig_master_user, $orig_master_password, $orig_master_ssh_user,
- $new_master_host, $new_master_ip, $new_master_port, $new_master_user, $new_master_password, $new_master_ssh_user,
- );
-
- my $vip = '192.168.134.100';
- my $brdc = '192.168.134.255';
- my $ifdev = 'ens33';
- my $key = '1';
- my $ssh_start_vip = "/usr/sbin/ip addr add $vip/24 brd $brdc dev $ifdev label $ifdev:$key;/usr/sbin/arping -q -A -c 1 -I $ifdev $vip;iptables -F;";
- my $ssh_stop_vip = "/usr/sbin/ip addr del $vip/24 dev $ifdev label $ifdev:$key";
-
-
- GetOptions(
- 'command=s' => \$command,
- 'orig_master_is_new_slave' => \$orig_master_is_new_slave,
- 'orig_master_host=s' => \$orig_master_host,
- 'orig_master_ip=s' => \$orig_master_ip,
- 'orig_master_port=i' => \$orig_master_port,
- 'orig_master_user=s' => \$orig_master_user,
- 'orig_master_password=s' => \$orig_master_password,
- 'orig_master_ssh_user=s' => \$orig_master_ssh_user,
- 'new_master_host=s' => \$new_master_host,
- 'new_master_ip=s' => \$new_master_ip,
- 'new_master_port=i' => \$new_master_port,
- 'new_master_user=s' => \$new_master_user,
- 'new_master_password=s' => \$new_master_password,
- 'new_master_ssh_user=s' => \$new_master_ssh_user,
- );
-
- exit &main();
-
- sub current_time_us {
- my ( $sec, $microsec ) = gettimeofday();
- my $curdate = localtime($sec);
- return $curdate . " " . sprintf( "%06d", $microsec );
- }
-
- sub sleep_until {
- my $elapsed = tv_interval($_tstart);
- if ( $_running_interval > $elapsed ) {
- sleep( $_running_interval - $elapsed );
- }
- }
-
- sub get_threads_util {
- my $dbh = shift;
- my $my_connection_id = shift;
- my $running_time_threshold = shift;
- my $type = shift;
- $running_time_threshold = 0 unless ($running_time_threshold);
- $type = 0 unless ($type);
- my @threads;
-
- my $sth = $dbh->prepare("SHOW PROCESSLIST");
- $sth->execute();
-
- while ( my $ref = $sth->fetchrow_hashref() ) {
- my $id = $ref->{Id};
- my $user = $ref->{User};
- my $host = $ref->{Host};
- my $command = $ref->{Command};
- my $state = $ref->{State};
- my $query_time = $ref->{Time};
- my $info = $ref->{Info};
- $info =~ s/^\s*(.*?)\s*$/$1/ if defined($info);
- next if ( $my_connection_id == $id );
- next if ( defined($query_time) && $query_time < $running_time_threshold );
- next if ( defined($command) && $command eq "Binlog Dump" );
- next if ( defined($user) && $user eq "system user" );
- next
- if ( defined($command)
- && $command eq "Sleep"
- && defined($query_time)
- && $query_time >= 1 );
-
- if ( $type >= 1 ) {
- next if ( defined($command) && $command eq "Sleep" );
- next if ( defined($command) && $command eq "Connect" );
- }
-
- if ( $type >= 2 ) {
- next if ( defined($info) && $info =~ m/^select/i );
- next if ( defined($info) && $info =~ m/^show/i );
- }
-
- push @threads, $ref;
- }
- return @threads;
- }
-
- sub main {
- if ( $command eq "stop" ) {
- ## Gracefully killing connections on the current master
- # 1. Set read_only= 1 on the new master
- # 2. DROP USER so that no app user can establish new connections
- # 3. Set read_only= 1 on the current master
- # 4. Kill current queries
- # * Any database access failure will result in script die.
- my $exit_code = 1;
- eval {
- ## Setting read_only=1 on the new master (to avoid accident)
- my $new_master_handler = new MHA::DBHelper();
-
- # args: hostname, port, user, password, raise_error(die_on_error)_or_not
- $new_master_handler->connect( $new_master_ip, $new_master_port,
- $new_master_user, $new_master_password, 1 );
- print current_time_us() . " Set read_only on the new master.. ";
- $new_master_handler->enable_read_only();
- if ( $new_master_handler->is_read_only() ) {
- print "ok.\n";
- }
- else {
- die "Failed!\n";
- }
- $new_master_handler->disconnect();
-
- # Connecting to the orig master, die if any database error happens
- my $orig_master_handler = new MHA::DBHelper();
- $orig_master_handler->connect( $orig_master_ip, $orig_master_port,
- $orig_master_user, $orig_master_password, 1 );
-
- ## Drop application user so that nobody can connect. Disabling per-session binlog beforehand
- #$orig_master_handler->disable_log_bin_local();
- #print current_time_us() . " Drpping app user on the orig master..\n";
- #FIXME_xxx_drop_app_user($orig_master_handler);
-
- ## Waiting for N * 100 milliseconds so that current connections can exit
- my $time_until_read_only = 15;
- $_tstart = [gettimeofday];
- my @threads = get_threads_util( $orig_master_handler->{dbh},
- $orig_master_handler->{connection_id} );
- while ( $time_until_read_only > 0 && $#threads >= 0 ) {
- if ( $time_until_read_only % 5 == 0 ) {
- printf
- "%s Waiting all running %d threads are disconnected.. (max %d milliseconds)\n",
- current_time_us(), $#threads + 1, $time_until_read_only * 100;
- if ( $#threads < 5 ) {
- print Data::Dumper->new( [$_] )->Indent(0)->Terse(1)->Dump . "\n"
- foreach (@threads);
- }
- }
- sleep_until();
- $_tstart = [gettimeofday];
- $time_until_read_only--;
- @threads = get_threads_util( $orig_master_handler->{dbh},
- $orig_master_handler->{connection_id} );
- }
-
- ## Setting read_only=1 on the current master so that nobody(except SUPER) can write
- print current_time_us() . " Set read_only=1 on the orig master.. ";
- $orig_master_handler->enable_read_only();
- if ( $orig_master_handler->is_read_only() ) {
- print "ok.\n";
- }
- else {
- die "Failed!\n";
- }
-
- ## Waiting for M * 100 milliseconds so that current update queries can complete
- my $time_until_kill_threads = 5;
- @threads = get_threads_util( $orig_master_handler->{dbh},
- $orig_master_handler->{connection_id} );
- while ( $time_until_kill_threads > 0 && $#threads >= 0 ) {
- if ( $time_until_kill_threads % 5 == 0 ) {
- printf
- "%s Waiting all running %d queries are disconnected.. (max %d milliseconds)\n",
- current_time_us(), $#threads + 1, $time_until_kill_threads * 100;
- if ( $#threads < 5 ) {
- print Data::Dumper->new( [$_] )->Indent(0)->Terse(1)->Dump . "\n"
- foreach (@threads);
- }
- }
- sleep_until();
- $_tstart = [gettimeofday];
- $time_until_kill_threads--;
- @threads = get_threads_util( $orig_master_handler->{dbh},
- $orig_master_handler->{connection_id} );
- }
-
-
-
- print "Disabling the VIP on old master: $orig_master_host \n";
- &stop_vip();
-
-
- ## Terminating all threads
- print current_time_us() . " Killing all application threads..\n";
- $orig_master_handler->kill_threads(@threads) if ( $#threads >= 0 );
- print current_time_us() . " done.\n";
- #$orig_master_handler->enable_log_bin_local();
- $orig_master_handler->disconnect();
-
- ## After finishing the script, MHA executes FLUSH TABLES WITH READ LOCK
- $exit_code = 0;
- };
- if ($@) {
- warn "Got Error: $@\n";
- exit $exit_code;
- }
- exit $exit_code;
- }
- elsif ( $command eq "start" ) {
- ## Activating master ip on the new master
- # 1. Create app user with write privileges
- # 2. Moving backup script if needed
- # 3. Register new master's ip to the catalog database
-
- # We don't return error even though activating updatable accounts/ip failed so that we don't interrupt slaves' recovery.
- # If exit code is 0 or 10, MHA does not abort
- my $exit_code = 10;
- eval {
- my $new_master_handler = new MHA::DBHelper();
-
- # args: hostname, port, user, password, raise_error_or_not
- $new_master_handler->connect( $new_master_ip, $new_master_port,
- $new_master_user, $new_master_password, 1 );
-
- ## Set read_only=0 on the new master
- #$new_master_handler->disable_log_bin_local();
- print current_time_us() . " Set read_only=0 on the new master.\n";
- $new_master_handler->disable_read_only();
-
- ## Creating an app user on the new master
- #print current_time_us() . " Creating app user on the new master..\n";
- #FIXME_xxx_create_app_user($new_master_handler);
- #$new_master_handler->enable_log_bin_local();
- $new_master_handler->disconnect();
-
- ## Update master ip on the catalog database, etc
- print "Enabling the VIP - $vip on the new master - $new_master_host \n";
- &start_vip();
- $exit_code = 0;
- };
- if ($@) {
- warn "Got Error: $@\n";
- exit $exit_code;
- }
- exit $exit_code;
- }
- elsif ( $command eq "status" ) {
-
- # do nothing
- exit 0;
- }
- else {
- &usage();
- exit 1;
- }
- }
-
- # A simple system call that enable the VIP on the new master
- sub start_vip() {
- `ssh $new_master_ssh_user\@$new_master_host \" $ssh_start_vip \"`;
- }
- # A simple system call that disable the VIP on the old_master
- sub stop_vip() {
- `ssh $orig_master_ssh_user\@$orig_master_host \" $ssh_stop_vip \"`;
- }
-
- sub usage {
- print
- "Usage: master_ip_online_change --command=start|stop|status --orig_master_host=host --orig_master_ip=ip --orig_master_port=port --orig_master_user=user --orig_master_password=password --orig_master_ssh_user=sshuser --new_master_host=host --new_master_ip=ip --new_master_port=port --new_master_user=user --new_master_password=password --new_master_ssh_user=sshuser \n";
- die;
- }
因故障切换后发送报警的脚本(可选)
- vim send_mail
-
- #!/bin/bash
- # 脚本的日志文件
- LOGFILE="/home/mha/log/email.log"
- :>"$LOGFILE"
- exec 1>"$LOGFILE"
- exec 2>&1
- SMTP_server='smtp.123.com'
- username='123@456.com'
- password='111*'
- from_email_address='123@456.com'
- to_email_address='***@***,***@***'
-
- message_subject_utf8="MHA集群主库故障转移提醒"
-
- HTML_PATH=html_path
- echo "<h2 style="color:red">">$HTML_PATH
- echo "MHA集群主节点发生故障,进行节点故障转移,请及时解决查看!!!">>$HTML_PATH
- echo "</h2>">>$HTML_PATH
- echo "<p>以下为MHA集群的相关信息:</p>">>$HTML_PATH
- echo "<table border="1" cellspacing="0" width="700"><tr><th>节点</th><th>角色</th> <th>作用</th></tr><tr><td>10.6.110.170</td><td>MHA manager</td> <td>MHA监控节点</td></tr><tr><td>10.8.40.77</td><td>master/master.bak</td> <td>主库或者主备</td></tr><tr><td>10.8.40.68</td><td>master/master.bak</td> <td>主库或者主备</td></tr><tr><td>10.6.119.241</td><td>slave</td> <td>从库</td></tr><tr><td>10.8.40.79</td><td>VIP</td> <td>虚拟ip</td></tr></table>">>$HTML_PATH
- echo "<br>">>$HTML_PATH
- echo "<h4>详细错误日志路径为:10.6.110.170:/data1/mysql_mha/manager.log</h4>">>$HTML_PATH
- message_body_utf8=$(cat $HTML_PATH)
-
- #message_body_utf8="mysql的MHA集群主节点发生故障,进行节点故障转移,请及时解决查看!!!"
- # 转换邮件标题为GB2312,解决邮件标题含有中文,收到邮件显示乱码的问题。
- message_subject_gb2312=`iconv -t GB2312 -f UTF-8 << EOF
- $message_subject_utf8
- EOF`
- [ $? -eq 0 ] && message_subject="$message_subject_gb2312" || message_subject="$message_subject_utf8"
- # 转换邮件内容为GB2312,解决收到邮件内容乱码
- message_body_gb2312=`iconv -t GB2312 -f UTF-8 << EOF
- $message_body_utf8
- EOF`
- [ $? -eq 0 ] && message_body="$message_body_gb2312" || message_body="$message_body_utf8"
- # 发送邮件
- sendEmail='/usr/bin/sendEmail'
- set -x
- $sendEmail -s "$SMTP_server" -xu "$username" -xp "$password" -f "$from_email_address" -t "$to_email_address" -u "$message_subject" -m "$message_body" -o message-content-type=html -o message-charset=gb2312
- #同时配置了企业微信通知
- sh /data1/mysql_mha/send_wechat
-
两个脚本修改完 都需要授权可执行文件。
1、先将mysql1设置成master(mysql2)的从服务器,设置只读
- mysql> CHANGE MASTER TO MASTER_HOST='192.168.134.134',MASTER_PORT=3306,MASTER_LOG_FILE='mysql-bin.000006',MASTER_LOG_POS=155, MASTER_USER='repl',MASTER_PASSWORD='123456';
- mysql> start slave;
- 设置为只读
- mysql> set global read_only=1;
2、关掉当前master(mysql2)的同步功能,否则从服务器会报错
- mysql> stop slave;
- mysql> reset slave;
3、手动修改manager上的app1.cnf配置
- 将刚刚手动宕机 Mysql1 库作为主库继续提供服务,注意手动切换 VIP 不会漂移。重新检查数据库主从状态是否正常
- [server1]
- hostname=192.168.134.132
- port=3306
- candidate_master=1
- check_repl_delay=0
4、检查无密码认证和 MySQL 主从状态是否正常,启动MHA
nohup masterha_manager --conf=/home/mha/conf/mysql_mha.cnf &> /home/mha/log/manager.log &5、查看当前主库master
- [root@rabbitmq_2 mha]# masterha_check_status --conf=/home/mha/conf/mysql_mha.cnf
- mysql_mha (pid:6045) is running(0:PING_OK), master:192.168.134.134
6、关闭MHA
- [root@rabbitmq_2 mha]# masterha_stop --conf=/home/mha/conf/mysql_mha.cnf
- Stopped mysql_mha successfully.
7、在manager上手动关闭当前master
- [root@rabbitmq_2 mha]# masterha_master_switch --conf=/home/mha/conf/mysql_mha.cnf --master_state=dead --dead_master_host=192.168.134.134
-
- 可能会报错,目前不知道咋回事,可以检查下master的状态 是否已经停掉了
- [root@rabbitmq_2 bin]# masterha_check_status --conf=/home/mha/conf/mysql_mha.cnf
- mysql_mha is stopped(2:NOT_RUNNING).
8、在manager上手动设置新的master
- [root@rabbitmq_2 bin]# masterha_master_switch --conf=/home/mha/conf/mysql_mha.cnf --master_state=alive --new_master_host=192.168.134.132 --orig_master_is_new_slave
- 会提示你让你输入yes
- Wed May 17 17:55:58 2023 - [info] * Switching slaves in parallel..
- Wed May 17 17:55:58 2023 - [info]
- Wed May 17 17:55:58 2023 - [info] Unlocking all tables on the orig master:
- Wed May 17 17:55:58 2023 - [info] Executing UNLOCK TABLES..
- Wed May 17 17:55:58 2023 - [info] ok.
- Wed May 17 17:55:58 2023 - [info] Starting orig master as a new slave..
- Wed May 17 17:55:58 2023 - [info] Resetting slave 192.168.134.134(192.168.134.134:3306) and starting replication from the new master 192.168.134.132(192.168.134.132:3306)..
- Wed May 17 17:55:58 2023 - [info] Executed CHANGE MASTER.
- Wed May 17 17:55:58 2023 - [info] Slave started.
- Wed May 17 17:55:58 2023 - [info] All new slave servers switched successfully.
- Wed May 17 17:55:58 2023 - [info]
- Wed May 17 17:55:58 2023 - [info] * Phase 5: New master cleanup phase..
- Wed May 17 17:55:58 2023 - [info]
- Wed May 17 17:55:58 2023 - [info] 192.168.134.132: Resetting slave info succeeded.
- Wed May 17 17:55:58 2023 - [info] Switching master to 192.168.134.132(192.168.134.132:3306) completed successfully.
9、启动MHA
10、检查状态 看看master是否切换成功
五、遇到的问题
1、
执行masterha_check_repl --conf=/home/mha/conf/mysql_mha.cnf出现问题

解决:
- Sat May 13 16:14:10 2023 - [error][/usr/share/perl5/vendor_perl/MHA/MasterMonitor.pm, ln427] Error happened on checking configurations. Can't exec "/home/mha/bin/master_ip_failover": 没有那个文件或目录 at /usr/share/perl5/vendor_perl/MHA/ManagerUtil.pm line 68.
- Sat May 13 16:14:10 2023 - [error][/usr/share/perl5/vendor_perl/MHA/MasterMonitor.pm, ln525] Error happened on monitoring servers.
- Sat May 13 16:14:10 2023 - [info] Got exit code 1 (Not master dead).
- 解决:我在创建脚本时候加了.sh 配置文件没加,检测时候找不到脚本
2、
执行masterha_check_ssh --conf=/home/mha/conf/mysql_mha.cnf出现问题
- Fri Feb 19 14:41:24 2021 - [error][/usr/share/perl5/vendor_perl/MHA/SSHCheck.pm, ln63]
- Fri Feb 19 14:41:23 2021 - [debug] Connecting via SSH from root@10.8.40.77(10.8.40.77:22) to sysadm@10.6.119.241(10.6.119.241:22)..
- Permission denied (publickey,gssapi-keyex,gssapi-with-mic,password).
- Fri Feb 19 14:41:24 2021 - [error][/usr/share/perl5/vendor_perl/MHA/SSHCheck.pm, ln111] SSH connection from root@10.8.40.77(10.8.40.77:22) to sysadm@10.6.119.241(10.6.119.241:22) failed!
- Fri Feb 19 14:41:25 2021 - [debug]
-
- 解决:
- 是因为mha的manager和slave在一台机器上,所以/etc/mha/mysql_mha.cnf最后一个注释掉,即把与manager在一台机器上的[server3]注释即可
3、启动MHA时报错
- [root@rabbitmq_2 log]# nohup masterha_manager --conf=/home/mha/conf/mysql_mha.cnf &> /home/mha/log/manager.log
- Sat May 13 16:52:45 2023 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping.
- Sat May 13 16:52:45 2023 - [info] Reading application default configuration from /home/mha/conf/mysql_mha.cnf..
- Sat May 13 16:52:45 2023 - [info] Reading server configuration from /home/mha/conf/mysql_mha.cnf..
- Cannot write to '/var/home/mha/log/manager.log': 没有那个文件或目录 at /usr/share/perl5/vendor_perl/Log/Dispatch/File.pm line 109.
-
- 解决:
- 是因为我的日志文件路径写错了,修改路径即可
4、当主库挂了 MHA日志报错

解决:
是因为我配置文件中,检查节点IP 指向了MHA Manager的IP 所以报这个错误,把地址改了 就可以了。
5、
报错mysqlbinlog 错误(此图引用其他博主内容,我的报错忘了留存)

解决办法: (所有节点)做软连接
- [root@node2 ~]# which mysqlbinlog
- /usr/local/mysql/bin/mysqlbinlog
- [root@node2 ~]# ln -s /usr/local/mysql/bin/mysqlbinlog /usr/bin/mysqlbinlog
-
- [root@node2 ~]# which mysql
- /usr/local/mysql/bin/mysql
- [root@node2 ~]# ln -s /usr/local/mysql/bin/mysql /usr/local/bin/mysql
6、
报错:[/usr/share/perl5/vendor_perl/MHA/ServerManager.pm, ln492] Server 192.168.134.133(192.168.134.133:3306) is dead, but must be alive! Check server settings.
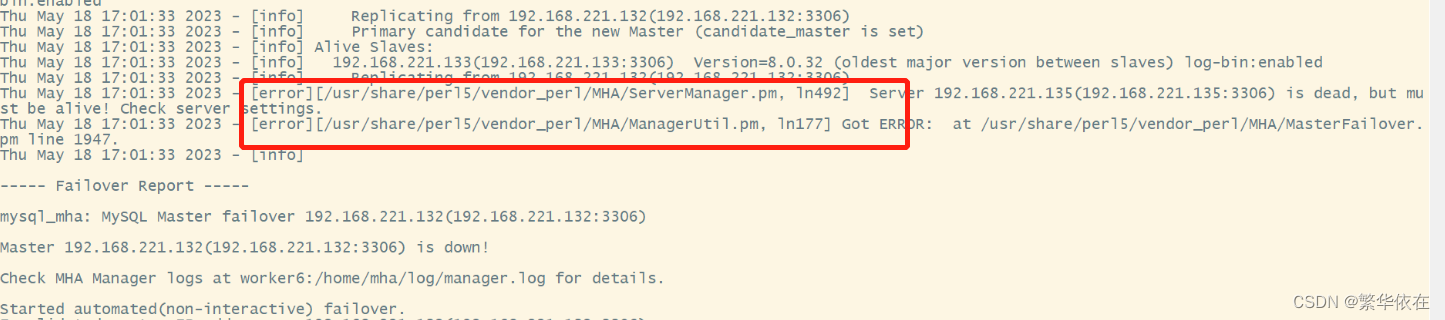
解决:
- 1、#删除MHA管理机上的这个文件
- [root@centos7-04 ~]# rm -rf /home/mha/app1.failover.complete
- 2、关闭防火墙
- 3、重启master的服务


