
- 1Eclipse表示:“正在使用或无法创建的工作区,请选择其他工作区。”如何解锁工作区?_workspace cannot be locked
- 2【OpenHarmony】使用手工编译的ohos-sdk_openharmony sdk
- 3Caused by: java.lang.IllegalArgumentException: hostname can't be null
- 4HarmonyOS 应用开发案例
- 5json schema validate
- 6微信小程序开发之菜品识别(调用百度AI菜品识别接口)_ai 菜品识别
- 7Vue应用axios实现Ajax请求_vue3 发起ajax获得数据
- 8Python中open函数的浅谈(相对路径/绝对路径)_python open 路径格式
- 9计算机有趣的指令,好玩的CMD命令行~
- 10基于JAVA协同过滤算法网上办公用品推荐购物商城系统设计与实现(Springboot框架)可行性分析_java 基于商品协同过滤算法
今日arXiv最热NLP大模型论文:大模型把《算法导论》学明白了
赞
踩
引言:探索自然语言描述算法的执行能力
在计算机科学的发展历程中,能够理解和执行自然语言描述的程序一直是一个长期追求的目标。随着大语言模型(LLMs)的出现,这一目标似乎触手可及。本文将探讨当前LLMs在理解和执行自然语言描述的算法方面的能力。
在本研究中,我们首先建立了一个算法测试集,源自著名的算法教材《算法导论》。我们选取了30个算法,生成了300个随机样本实例,并评估了流行的LLMs是否能够理解和执行这些算法。我们的实验结果显示,尤其是GPT-4模型,能够有效地执行自然语言描述的程序。这些模型能够准确地遵循算法的控制流,精确地执行每一步,并通过文本输出一致地维护和更新变量值。我们的研究结果为评估LLMs的代码执行能力提供了新的视角,并为进一步研究和应用LLMs的计算能力提供了启示。

论文标题:
Executing Natural Language-Described Algorithms with Large Language Models: An Investigation
论文链接:
https://arxiv.org/pdf/2403.00795.pdf
GPT-3.5研究测试:
https://hujiaoai.cn
GPT-4研究测试(遇到报警点击继续即可):
https://higpt4.cn
算法执行的挑战与机遇
1. 论文研究背景与目的
在计算机科学的长期追求中,执行自然语言描述的计算机程序一直是一个目标。随着大语言模型(LLMs)展现出增强的自然语言理解能力,这一目标的实现路径变得更加明晰。本研究旨在检验当今LLMs理解和执行自然语言描述算法的能力。通过建立一个算法测试集,我们可以系统地评估LLMs的代码执行能力,并为进一步研究和应用LLMs的计算能力提供参考。
2. 算法执行在AI中的重要性
算法是计算机的主要知识载体,传统上使用高级语言或伪代码来概述算法,以提高沟通效率。LLMs的出现,尤其是GPT-4,表明它们能够有效地执行自然语言描述的程序,只要不涉及重型数值计算。这表明,现有LLMs能够执行序列、选择和迭代语句,并模拟冯·诺伊曼机的核心功能。因此,我们可以通过自然语言提示指导这些模型执行复杂操作。
相关的操作如下表所示。正如提示所要求的,模型反复使用关键词生成句子,从生成的句子中选择一个词作为新的关键词(用不同颜色标注),并在满足迭代次数时停止。这些能力与执行程序所需的能力非常相似。

实验方法:评估LLMs的代码执行能力
1. 评估流程详述
在评估LLMs的代码执行能力时,我们首先建立了一个算法测试集,包含了从经典教材中选取的多个算法。我们随机抽取了每个算法的10个不同实例,以减少数据泄露的可能性。基于这个基准,我们将算法与问题输入转换为自然语言描述提示,并输入到LLMs中,尝试查看LLMs是否能够逐步准确执行算法,并产生正确的结果。
2. 采用的LLMs模型介绍
在我们的实验中,我们使用了三种流行的LLMs,分别是Text-Davinci-003、GPT-3.5-Turbo[1]和GPT-4[2]。这些模型通过OpenAI API访问,它们的温度参数均设置为0,以确保结果的一致性。所有结果均来自单次运行。
实验设置:构建算法测试集
1. 选择代表性算法
我们从经典教材《算法导论》[3]中首先挑选了26个代表性算法,形成了评估集CLRS-mini。这些算法涵盖了序列、选择和迭代控制流,嵌套循环和递归调用等多种编程结构,可以有效评估LLMs执行程序的能力。这些算法的时间复杂度均为多项式时间,并且只涉及整数/浮点数加法和整数乘法,因此我们预期当前的LLMs能够很好地处理这些任务。
为了进一步挑战当前的LLMs,我们还制定了另一个评估集CLRS-Numeric,它由4个密集数值运算算法组成,需要进行浮点数乘除和指数及三角函数的计算。
此外,除了上述的30种算法,我们还包含了两个算法任务——有效括号和最长公共子序列,以便与前人的工作[4]进行比较。有效括号的任务是验证由三种不同类型括号组成的序列是否平衡,这需要对栈进行操作。至于最长公共子序列,目标是计算给定两个序列的最长公共子序列的长度,需要两个嵌套循环来完成任务。
2. 设计算法提示
在我们设计程序提示时,目标是创建一个既严格又易于解释的提示结构。强调精确性,每个特定任务的指令都以清晰、无歧义的自然语言编写。如下面2张表所示,我们使用了“goto”语句来触发迭代行为,并使用自然语言来表达if/else分支选择,不同的分支通过索引标记如“i.”和“ii.”以及Python风格的空格缩进来表示。

上表显示了有效括号的提示和Text-Davinci-003的响应。这个任务检查括号序列是否匹配。一旦有括号不匹配,就返回无效。如果在最后,栈为空,则返回有效,否则仍然返回无效。在这个例子中,第二个元素与第一个元素不匹配,所以模型正确地返回无效并停止执行。最终结果“无效”是斜体显示,而停止词“halt”被标记为红色。

上表显示了二分查找的提示和GPT-4的响应。二分查找是一种用于在有序数组中查找关键字位置的搜索算法。它的工作原理是通过反复将搜索区间一分为二,直到找到目标值或确定该值不存在为止。搜索区间由两个索引定义,即下界和上界,这些界限在每次迭代中都会进行调整。在这个例子中,GPT-4正确地找到了元素“18”的位置,即第8个位置。
我们设计的算法提示的确受到了前人研究的启发,借鉴了鼓励模型尽可能地逐步思考、以及确保提示中使用的单词与它们所代表的行动之间的一致性等方法。但最大的不同之处,就是我们的方法主要依赖于自然语言来精确描述,因此只需要少量的操作定义。
3. 生成测试用例
为了测试LLMs的执行能力,我们为每个算法随机抽取了10个不同的实例。这样可以减少数据泄露的可能性。基于这些测试用例,我们将算法及其输入转换为自然语言描述的提示,输入到LLMs中,检验它们是否能够准确地逐步执行算法,并产生正确的结果。最终,我们将这些算法在三个流行的LLMs上进行了实验,包括Text-Davinci-003、GPT-3.5-Turbo和GPT-4,并系统地评估了它们作为自然语言程序解释器的能力。
实验结果:LLMs在执行自然语言描述算法中的表现
1. 与前人研究的比较:自然语言描述算法的优势
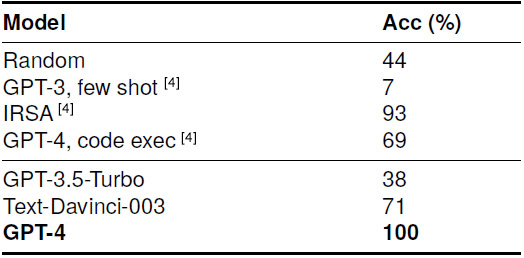
下表展示了有效括号任务的结果。之前,Jojic等人提出了IRSA方法^[4]^,达到了96%的准确率。我们通过自然语言程序提示,Text-Davinci-003和GPT-4模型都达到了100%的准确率,展示了我们方法在完美解决这个任务方面的有效性。

如下表所示,GPT-4模型是唯一在最长公共子序列任务中达到完全准确率的模型。尽管通过规范注意力,即删除无用的历史上下文,IRSA方法获得了93%的高准确率,但很明显,GPT-4模型展示了更强的处理这个复杂任务的能力。
2. GPT-4效果优异的分析
GPT-4模型在执行自然语言描述的算法时表现出色(见下表:评估集CLRS-mini的测试结果,包含7类任务/斜体、26种算法)。它能够准确地遵循算法的控制流程,精确地执行每一步,并进行计算。同时,LLMs能够通过文本输出一致地维护和更新变量的值。这表明现有的LLMs能够执行序列、选择和迭代语句,并模拟冯·诺依曼机的核心功能。

3. GPT-3.5模型的性能分析
与GPT-4相比,GPT-3.5-Turbo和Text-Davinci-003的性能略有不同(见上表)。GPT-3.5-Turbo的平均准确率为35.0%,而Text-Davinci-003的平均准确率为36.9%,但两者都远远落后于GPT-4。特别是在处理需要更多令牌完成的图算法时,GPT-3.5模型的性能下降明显。随着任务复杂性的增加,指令包含的信息量增加,控制流程变得更加复杂,所需的生成令牌数量也随之增加。然而,GPT-4成功地处理了这些复杂任务,凸显了其在模拟自然语言程序方面的能力。
4. 全军覆没的CLRS-Numeric评估集
在所有三个评估的模型中,观察到结果都是0%(下表),这揭示了当前LLMs在处理这种复杂数值运算时遇到的显著且普遍的挑战。检查生成的结果,我们发现GPT-4仍然按照指令逐步进行,并设法生成了一个格式良好的错误答案,这表明错误主要来自于计算错误。

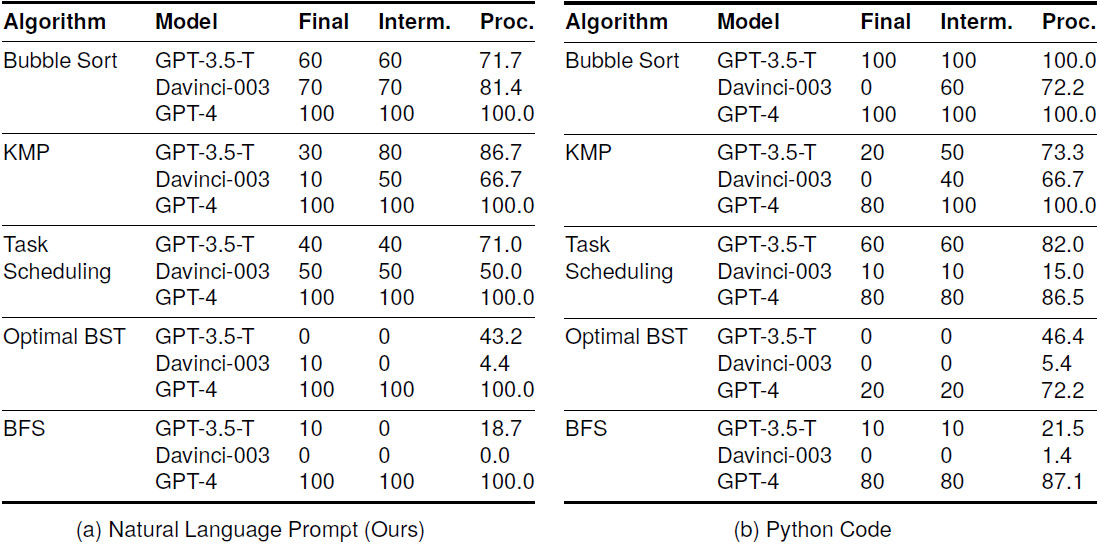
5. 中间结果:揭示模型性能差异的原因
下表中,我们选择5种可提取中间结果的算法,发现通过用“未解释”的Python代码替换详细的指令,中间准确度和过程准确度随着最终准确度显著下降,因为GPT-4的得分不再都是100%。对于GPT-3.5-Turbo和Text-Davinci-003,较低的最终准确度与较低的中间正确性相关联。这进一步证明了我们提出的方法的必要性。
讨论:LLMs在算法执行中的局限性与潜力
1. 数值运算的挑战
在算法执行过程中,LLMs面临的一个主要挑战是数值运算。由于LLMs主要是为了处理和理解自然语言而设计,它们在执行涉及复杂数值计算的任务时可能会遇到困难。例如,在处理最小二乘回归和离散傅立叶变换等算法时,LLMs需要准确计算数值结果,这对于以文本为基础的模型来说是一个挑战。
2. 模型理解与执行的差异
LLMs在理解算法描述和执行算法之间存在差异。虽然LLMs可以理解算法的自然语言描述,但将这些描述转换为准确的执行步骤需要模型具备一定的逻辑推理能力。在执行算法时,LLMs必须能够准确地遵循算法的控制流程,包括顺序执行、选择和迭代等结构。这要求模型不仅要理解算法的每个步骤,还要能够在没有外部编程环境的帮助下自主执行这些步骤。
结论与未来展望
1. 对LLMs未来发展的预测
预计LLMs在未来的发展中将更加注重提升其算法执行能力。随着模型结构和训练方法的不断进步,LLMs将能够更好地处理数值运算和复杂的算法执行任务。此外,结合外部工具和编程环境,LLMs可能会在执行自然语言描述的程序方面发挥更大的作用。
2. 算法执行能力对AI发展的影响
LLMs的算法执行能力对人工智能(AI)的发展具有重要影响。随着LLMs在这一领域的能力提升,它们将能够在更多的实际应用中发挥作用,例如自动编程、代码生成和算法优化等。这将推动AI技术的进一步融合和创新,为各行各业带来变革。同时,这也将促进对LLMs计算能力和逻辑推理能力的深入研究,为AI领域带来新的理论和实践进展。


参考资料
[1]Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul F. Christiano, Jan Leike, and Ryan Lowe. 2022. Training language models to follow instructions with human feedback. In NeurIPS.
[2]OpenAI. 2023. GPT-4 technical report. CoRR, abs/2303.08774.
[3]Thomas H Cormen, Charles E Leiserson, Ronald L Rivest, and Clifford Stein. 2022. Introduction to algorithms.
[4]Ana Jojic, Zhen Wang, and Nebojsa Jojic. 2023. GPT is becoming a turing machine: Here are some ways to program it. CoRR, abs/2303.14310.B
[5] Aarohi Srivastava, Abhinav Rastogi, Abhishek Rao, Abu Awal Md Shoeb, Abubakar Abid, Adam Fisch, Adam R. Brown, Adam Santoro, Aditya Gupta, Adrià Garriga-Alonso, Agnieszka Kluska, Aitor Lewkowycz, Akshat Agarwal, Alethea Power, Alex Ray, Alex Warstadt, Alexander W. Kocurek, Ali Safaya, Ali Tazarv, Alice Xiang, Alicia Parrish, Allen Nie, Aman Hussain, Amanda Askell, Amanda Dsouza, Ameet Rahane, Anantharaman S. Iyer, Anders Andreassen, Andrea Santilli, Andreas Stuhlmüller, Andrew M. Dai, Andrew La, Andrew K. Lampinen, Andy Zou, Angela Jiang, Angelica Chen, Anh Vuong, Animesh Gupta, Anna Gottardi, Antonio Norelli, Anu Venkatesh, Arash Gholamidavoodi, Arfa Tabassum, Arul Menezes, Arun Kirubarajan, AsherMullokandov, Ashish Sabharwal, Austin Herrick, Avia Efrat, Aykut Erdem, Ayla Karakas, and et al. 2022. Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. CoRR, abs/2206.04615.
[6] Rohan Anil, Andrew M. Dai, Orhan Firat, Melvin Johnson, Dmitry Lepikhin, Alexandre Passos, Siamak Shakeri, Emanuel Taropa, Paige Bailey, Zhifeng Chen, Eric Chu, Jonathan H. Clark, Laurent El Shafey, Yanping Huang, Kathy Meier-Hellstern, Gaurav Mishra, Erica Moreira, Mark Omernick, Kevin Robinson, Sebastian Ruder, Yi Tay, Kefan Xiao, Yuanzhong Xu, Yujing Zhang, Gustavo Hernandez Abrego, Junwhan Ahn, Jacob Austin, Paul Barham, Jan Botha, James Bradbury, Siddhartha Brahma, Kevin Brooks, Michele Catasta, Yong Cheng, Colin Cherry, Christopher A. Choquette-Choo, Aakanksha Chowdhery, Clément Crepy, Shachi Dave, Mostafa Dehghani, Sunipa Dev, Jacob Devlin, Mark Díaz, Nan Du, Ethan Dyer, Vlad Feinberg, Fangxiaoyu Feng, Vlad Fienber, Markus Freitag, Xavier Garcia, Sebastian Gehrmann, Lucas Gonzalez, Guy Gur-Ari, Steven Hand, Hadi Hashemi, Le Hou, Joshua Howland, Andrea Hu, Jeffrey Hui, Jeremy Hurwitz, Michael Isard, Abe Ittycheriah, Matthew Jagielski, Wenhao Jia, Kathleen Kenealy, Maxim Krikun, Sneha Kudugunta, Chang Lan, Katherine Lee, Benjamin Lee, Eric Li, Music Li, Wei Li, YaGuang Li, Jian Li, Hyeontaek Lim, Hanzhao Lin, Zhongtao Liu, Frederick Liu, Marcello Maggioni, Aroma Mahendru, Joshua Maynez, Vedant Misra, Maysam Moussalem, Zachary Nado, John Nham, Eric Ni, Andrew Nystrom, Alicia Parrish, Marie Pellat, Martin Polacek, Alex Polozov, Reiner Pope, Siyuan Qiao, Emily Reif, Bryan Richter, Parker Riley, Alex CastroRos, Aurko Roy, Brennan Saeta, Rajkumar Samuel, Renee Shelby, Ambrose Slone, Daniel Smilkov, David R. So, Daniel Sohn, Simon Tokumine, Dasha Valter, Vijay Vasudevan, Kiran Vodrahalli, Xuezhi Wang, Pidong Wang, Zirui Wang, Tao Wang, John Wieting, Yuhuai Wu, Kelvin Xu, Yunhan Xu, Linting Xue, Pengcheng Yin, Jiahui Yu, Qiao Zhang, Steven Zheng, Ce Zheng, Weikang Zhou, Denny Zhou, Slav Petrov, and Yonghui Wu. 2023. Palm2 technical report.


