
热门标签
热门文章
- 1学习FPGA的正确路径_lgr的fgga二氧化碳
- 2HarmonyOS 开发基础(四) 子父组件双向绑定_父组件子组件双向数据同步鸿蒙
- 3鸿蒙开发与安卓开发的区别?_鸿蒙开发跟安卓开发有区别吗
- 4随机梯度下降(SGD)与经典的梯度下降法的区别_随机梯度下降和梯度下降的区别
- 5Monitor模式和AP模式下获取WiFi的CSI信号_使用intel 5300网卡监听
- 6小程序第一章作业(简易计算器)
- 7用AnythingLLM构建专属知识库_anythingllm 设置
- 8Android ble(低功耗蓝牙)开发基础代码及常见问题_connectgatt
- 9IOS系统中微信、浏览器、手机端输入框input无法输入_微信浏览器输入框input不显示
- 10python都需要安装哪些库_matplotlib还需要安装哪些库来编写tiff文件?
当前位置: article > 正文
特征工程特征预处理归一化与标准化、鸢尾花种类预测代码实现_特征工程 分类预测
作者:菜鸟追梦旅行 | 2024-03-30 12:56:58
赞
踩
特征工程 分类预测
一、特征预处理
特征工程目的:把数据转换成机器更容易识别的数据
scikit-learn:提供几个常见的实用程序函数和转换器类,以将原始特征向量更改为更适合下游估计器的表示形式。即通过一些转换函数将特征数据转换成更加适合算法模型的特征数据过程
特征的单位或大小相差较大,或某特征的方差相比其他的特征要大出几个数量级,容易影响(支配)目标结果,使得一些算法无法学习到其它的特征,故需要进行归一化/标准化处理
需要用到一些方法进行无量纲化,使不同规格的数据转换到同一规格,包括归一化和标准化
二、归一化
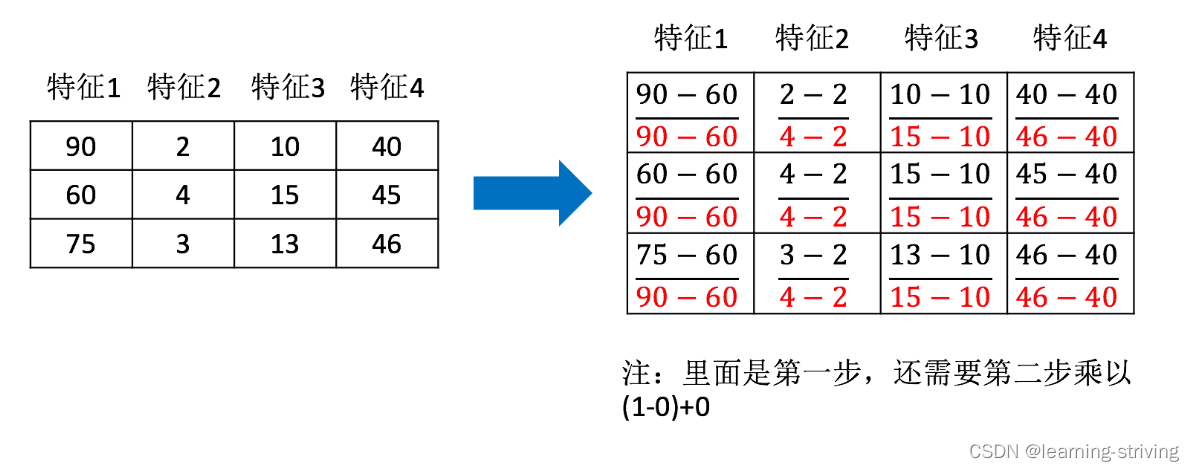
归一化:通过对原始数据进行变换把数据映射到(默认为[0,1])之间
公式如下

作用于每一列,max为一列的最大值,min为一列的最小值,那么 X'' 为最终结果,mx,mi分别为指定区间值默认mx为1,mi为0,举例如下
使用API函数如下
- sklearn.preprocessing.MinMaxScaler (feature_range=(0,1)… ):feature_range指定范围
- MinMaxScalar.fit_transform(X)
- X:numpy array格式的数据[n_samples,n_features]
- 返回值:转换后的形状相同的array
- MinMaxScalar.fit_transform(X)
代码如下,海伦约会数据dating.txt文件见文末网盘链接
- import pandas as pd
- from sklearn.preprocessing import MinMaxScaler
-
- data = pd.read_csv("../data/dating.txt")
- print(data)
- transfer = MinMaxScaler(feature_range=(0, 1)) # 实例化一个转换器类
- minmax_data = transfer.fit_transform(data[['milage', 'Liters', 'Consumtime']]) # 调用fit_transform
- print("最小值最大值归一化处理后的结果:\n", minmax_data)
- -------------------------------------------------------------
- 输出:
- milage Liters Consumtime target
- 0 40920 8.326976 0.953952 3
- 1 14488 7.153469 1.673904 2
- 2 26052 1.441871 0.805124 1
- 3 75136 13.147394 0.428964 1
- 4 38344 1.669788 0.134296 1
- .. ... ... ... ...
- 995 11145 3.410627 0.631838 2
- 996 68846 9.974715 0.669787 1
- 997 26575 10.650102 0.866627 3
- 998 48111 9.134528 0.728045 3
- 999 43757 7.882601 1.332446 3
-
- [1000 rows x 4 columns]
- 最小值最大值归一化处理后的结果:
- [[0.44832535 0.39805139 0.56233353]
- [0.15873259 0.34195467 0.98724416]
- [0.28542943 0.06892523 0.47449629]
- ...
- [0.29115949 0.50910294 0.51079493]
- [0.52711097 0.43665451 0.4290048 ]
- [0.47940793 0.3768091 0.78571804]]

最大值最小值是变化的,容易受异常点影响,所以该方法鲁棒性较差,只适合传统精确小数据场景
三、标准化
标准化:通过对原始数据进行变换把数据变换到均值为0,标准差为1范围内的数据
公式如下

作用于每一列,mean为平均值,σ为标准差
- 对归一化来说:若出现异常点,影响了最大值和最小值,那么结果显然会发生改变
- 对标准化来说:若出现异常点,由于具有一定数据量,少量的异常点对于平均值的影响并不大,从而方差改变较小
API如下
- sklearn.preprocessing.StandardScaler( ):处理之后每列来说所有数据都聚集在均值0附近标准差差为1
- StandardScaler.fit_transform(X)
- X:numpy array格式的数据[n_samples,n_features]
- 返回值:转换后的形状相同的array
- StandardScaler.fit_transform(X)
- from sklearn.preprocessing import StandardScaler
- import pandas as pd
- data = pd.read_csv("../data/dating.txt")
- print(data)
- transfer = StandardScaler() # 实例化一个转换器
- minmax_data = transfer.fit_transform(data[['milage', 'Liters', 'Consumtime']]) # 调用fit_transform
- print("最小值最大值标准化处理后的结果:\n", minmax_data)
- print("每一列特征的平均值:\n", transfer.mean_)
- print("每一列特征的方差:\n", transfer.var_)
- -------------------------------------------------------
- 输出:
- milage Liters Consumtime target
- 0 40920 8.326976 0.953952 3
- 1 14488 7.153469 1.673904 2
- 2 26052 1.441871 0.805124 1
- 3 75136 13.147394 0.428964 1
- 4 38344 1.669788 0.134296 1
- .. ... ... ... ...
- 995 11145 3.410627 0.631838 2
- 996 68846 9.974715 0.669787 1
- 997 26575 10.650102 0.866627 3
- 998 48111 9.134528 0.728045 3
- 999 43757 7.882601 1.332446 3
-
- [1000 rows x 4 columns]
- 最小值最大值标准化处理后的结果:
- [[ 0.33193158 0.41660188 0.24523407]
- [-0.87247784 0.13992897 1.69385734]
- [-0.34554872 -1.20667094 -0.05422437]
- ...
- [-0.32171752 0.96431572 0.06952649]
- [ 0.65959911 0.60699509 -0.20931587]
- [ 0.46120328 0.31183342 1.00680598]]
- 每一列特征的平均值:
- [3.36354210e+04 6.55996083e+00 8.32072997e-01]
- 每一列特征的方差:
- [4.81628039e+08 1.79902874e+01 2.46999554e-01]
标准化在已有样本足够多的情况下比较稳定,适合大数据场景
四、鸢尾花种类预测
近邻算法API
- sklearn.neighbors.KNeighborsClassifier(n_neighbors=5,algorithm='auto')
- n_neighbors:int,可选(默认= 5),k_neighbors查询默认使用的邻居数
- algorithm:{‘auto’,‘ball_tree’,‘kd_tree’,‘brute’}:快速k近邻搜索算法,默认参数为auto,可以理解为算法自己决定合适的搜索算法。除此之外,用户也可以自己指定以下搜索算法进行搜索
- ball tree:是为了克服kd树高纬失效而发明的,其构造过程是以质心C和半径r分割样本空间,每个节点是一个超球体。
- kd_tree:构造kd树存储数据以便对其进行快速检索的树形数据结构,kd树也就是数据结构中的二叉树。以中值切分构造的树,每个结点是一个超矩形,在维数小于20时效率高。
- brute:是蛮力搜索,也就是线性扫描,当训练集很大时,计算非常耗时
Iris数据集
- 实例数量: 150 (三个类各有50个)
- 属性数量: 4 (数值型,数值型,帮助预测的属性和类)
- 属性,特征值
- sepal length:萼片长度(厘米)
- sepal width:萼片宽度(厘米)
- petal length:花瓣长度(厘米)
- petal width:花瓣宽度(厘米)
- 种类,目标值
- Iris-Setosa:山鸢尾
- Iris-Versicolour:变色鸢尾
- Iris-Virginica:维吉尼亚鸢尾
代码如下
- from sklearn.datasets import load_iris
- from sklearn.model_selection import train_test_split
- from sklearn.preprocessing import StandardScaler
- from sklearn.neighbors import KNeighborsClassifier # 导入模块
- # 1.获取数据集
- iris = load_iris()
- # 2.数据基本处理
- # x_train,x_test,y_train,y_test为训练集特征值、测试集特征值、训练集目标值、测试集目标值
- x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=22) # 划分数据集
- # 3.特征工程:标准化
- transfer = StandardScaler() # 实例化转换器
- x_train = transfer.fit_transform(x_train) # 调用方法,标准化
- x_test = transfer.transform(x_test)
- # 4.机器学习(模型训练)
- estimator = KNeighborsClassifier(n_neighbors=2) # 实例化一个估计器,n_neighbors为选定参考的邻居数
- estimator.fit(x_train, y_train) # 模型训练
- # 5.模型评估
- # 方法1:比对真实值和预测值
- y_predict = estimator.predict(x_test)
- print("预测结果为:", y_predict)
- print("比对真实值和预测值:", y_predict == y_test)
- # 方法2:直接计算准确率
- score = estimator.score(x_test, y_test)
- print("准确率为:", score)
- -----------------------------------------------
- 输出:
- 预测结果为: [0 2 1 2 1 1 1 2 1 0 2 1 2 2 0 2 1 1 1 1 0 2 0 1 2 0 2 2 2 2]
- 比对真实值和预测值: [ True True True True True True True True True True True True
- True True True True True True False True True True True True
- True True True True True True]
- 准确率为: 0.9666666666666667
海伦约会数据dating.txt获取下载:https://pan.baidu.com/s/1JFrp-3YQyH_zFBwWulNqmQ?pwd=68ww
学习导航:http://xqnav.top/
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/菜鸟追梦旅行/article/detail/340758
推荐阅读

相关标签

