
热门标签
热门文章
- 1编程报错:missing 1 required positional argument
- 2python aiml_使用Python AIML搭建聊天机器人的方法示例
- 3Spring Boot项目启动速度优化
- 4开源的页面生成器:拖拽即可生成小程序、H5页面和网站
- 5矩阵分解在自然语言处理中的应用:情感分析和文本摘要
- 6Python - 深度学习系列13- 显卡与CPU计算对比_显卡算法和处理器算法
- 7中文医学大模型“本草”(原名华驼):医学知识增强在中文大型语言模型指令微调上的初步探索...
- 8字节8年经验之谈 —— 聊一聊自动化测试为什么很难落地!
- 9数据库更新两张相关联的表
- 10Asp.Net Core文件上传IFormFile_asp.net core iformfile
当前位置: article > 正文
CNN-GRU、CNN-BIGRU预测_gru层数区别bigru
作者:菜鸟追梦旅行 | 2024-03-31 14:02:46
赞
踩
gru层数区别bigru
GRU(Gated Recurrent Unit)和BiGRU(Bidirectional Gated Recurrent Unit)是循环神经网络(RNN)的变种,用于处理序列数据。它们在处理长期依赖性和捕捉上下文信息方面具有优势。
GRU是一种门控循环单元,它通过使用更新门和重置门来控制信息的流动。更新门决定了多少旧的状态应该被保留,而重置门决定了多少旧的状态应该被忽略。GRU的结构相对简单,参数较少,因此训练速度较快。然而,由于没有显式的记忆单元,GRU可能无法捕捉到长期的依赖关系。
BiGRU是双向循环神经网络,它由两个独立的GRU组成,一个从前向后处理输入序列,另一个从后向前处理输入序列。通过在两个方向上处理序列,BiGRU能够捕捉到更多的上下文信息。它可以更好地处理双向依赖关系,并且在许多序列任务中表现出更好的性能。然而,BiGRU的训练速度相对较慢,因为它需要处理两个方向上的序列。
CNN-GRU和CNN-BiGRU是将卷积神经网络(CNN)与GRU或BiGRU结合起来的模型。CNN用于提取输入序列的局部特征,而GRU或BiGRU用于捕捉序列的长期依赖关系。CNN-GRU和CNN-BiGRU在文本分类和情感分析等任务中表现出良好的性能。相比之下,CNN-GRU在处理长期依赖关系方面可能稍逊于CNN-BiGRU,但训练速度更快。
实际应用 在回归预测中通过对比其效果图如下
CNN-GRU效果:
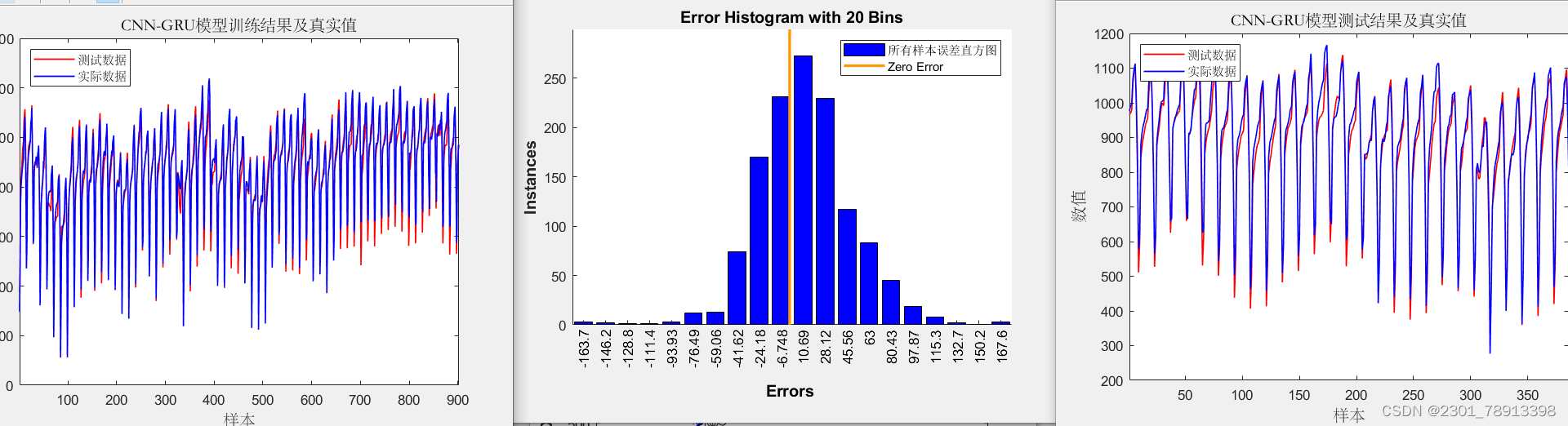
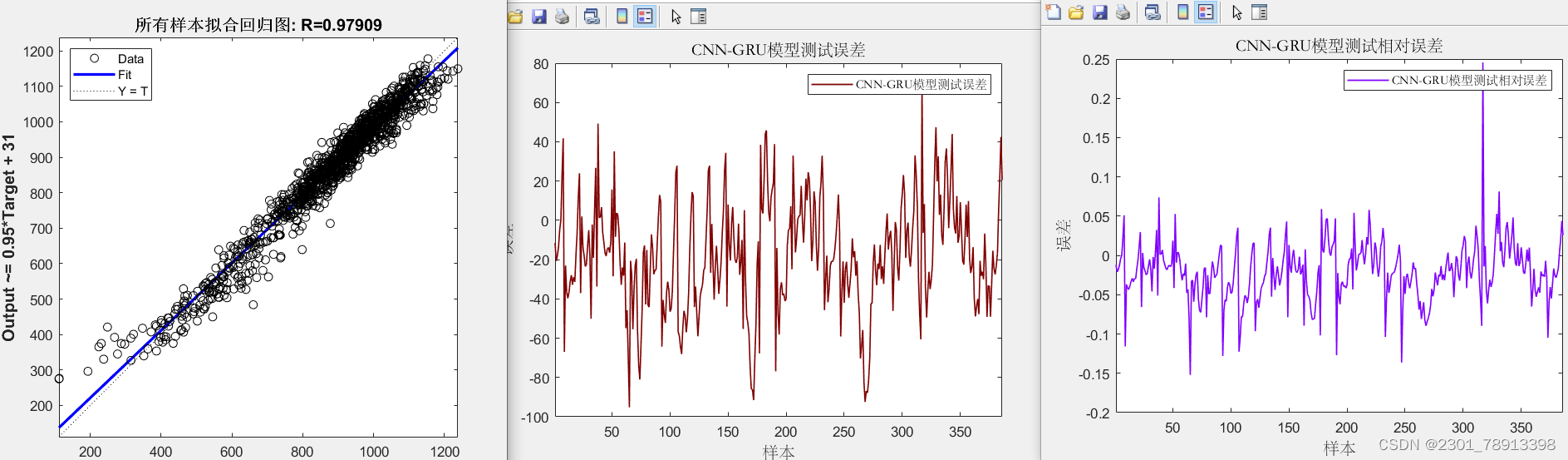
CNN-BIGRU效果相对CNN-GRU效果更好但运行速度稍慢:
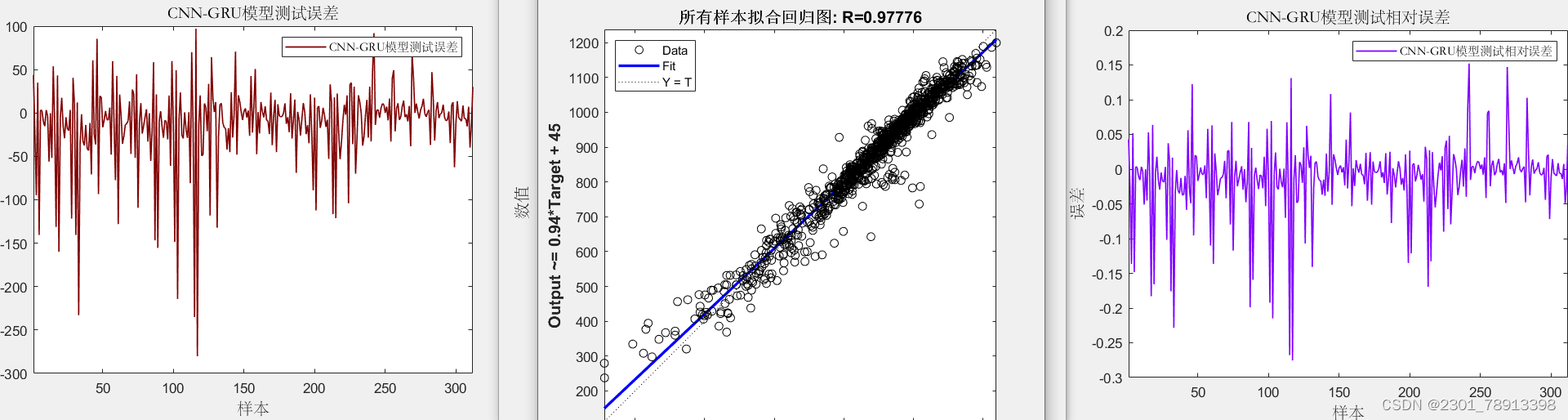
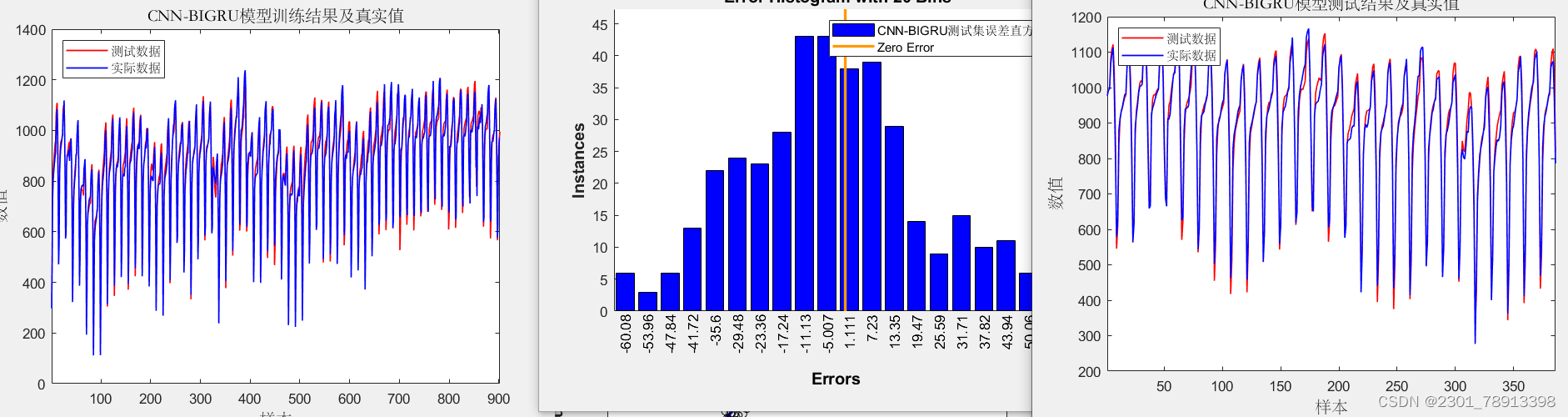
-
CNN-GRU模型结构:
- 卷积神经网络(CNN):CNN主要用于提取文本中的局部特征。它通过使用卷积层和池化层来捕捉输入文本中的局部模式。卷积层通过滑动窗口的方式在输入文本上进行滤波操作,提取出不同尺寸的特征。池化层则用于减少特征的维度,保留最重要的特征信息。
- 门控循环单元(GRU):GRU是一种循环神经网络(RNN)的变体,用于捕捉文本中的长程依赖关系。GRU通过使用门控机制来控制信息的流动,从而有效地解决了传统RNN中的梯度消失和梯度爆炸问题。GRU包含了更新门、重置门和隐藏状态,可以有效地捕捉文本中的上下文信息。
-
CNN-BiGRU模型结构:
- 卷积神经网络(CNN):CNN的作用与上述相同,用于提取文本中的局部特征。
- 双向门控循环单元(BiGRU):BiGRU是一种双向循环神经网络的变体,结合了前向和后向的GRU。它通过同时考虑文本的前向和后向上下文信息,更全面地理解文本中的语义和上下文关系。BiGRU的前向和后向GRU分别处理输入文本的正向和逆向序列,并将它们的隐藏状态进行拼接,得到最终的表示。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/菜鸟追梦旅行/article/detail/344818
推荐阅读
相关标签

