
NLP_GPT生成式自回归模型_gpt模型自回归
赞
踩
介绍
自回归(Autoregressive)是自然语言处理模型的一种训练方法,其核心思想是基于已有的序列(词或字符)来预测下一个元素。在GPT中,这意味着模型会根据给定的上文来生成下一个词,如图所示。

在GPT模型的训练和推理这两个相互独立的过程中,“自回归”的含义是不同的。
- 训练过程中的“自回归”:在训练阶段,GPT通过大量文本数据进行学习。模型会接收一个词序列作为输入,然后预测下一个词。损失函数主要用于衡量模型预测与实际词之间的差异。在训练过程中,模型将不断调整其参数,以最小化损失函数。这个过程会持续进行,直到模型在预测任务上达到一定的性能。训练过程中也常常使用教师强制来加快模型的收敛速度。
- 推理过程中的“自回归”:在推理阶段,我们利用训练好的 GPT 模型来生成文本。首先,我们提供一个初始的种子文本(即提示或指令),然后模型会根据这个种子文本生成下一个词。生成的词将被添加到文本中,继续输入模型,模型会接着生成下一个词,以此类推。这个过程会一直进行,直到生成一定长度的文本或遇到特定的结束符。
在生成文本时,GPT通常会根据词的概率分布来选择下一个词。这可以通过多种策略实现,如贪婪搜索-总是选择概率最高的词,集束搜索-同时考虑多个可能的词序列,采样方法根据词的概率分布随机选择词等。
GPT是生成式自回归模型,生成式自回归模型是生成式模型的一种。生成式模型和判别式模型是两种主要的机器学习模型。
- 生成式模型(Generative Model):生成式模型不仅关心输入和输出之间的关系,同时也会考虑数据生成的机制。它会对数据的分布进行建模,并试图了解数据是如何生成的。生成式模型能够模拟新的数据实例,比如高斯混合模型、隐马尔可夫模型、朴素贝叶斯分类器等。
- 判别式模型(Discriminative Model):判别式模型主要关注输入与输出之间的关系,直接学习从输入到输出的映射或者决策边界,不考虑数据的生成过程,比如逻辑回归、支持向量机、神经网络等。
自回归模型(Autoregressive Model)是生成式模型的一种特例,它预测的新目标值是基于前面若干个已生成值的。自回归模型在时间序列分析、语音信号处理、自然语言处理等领域有广泛应用。在序列生成问题中,自回归模型特别重要,比如在机器翻译、文本生成、语音合成等任务中,Transformer的解码器、GPT等模型就是基于自回归原理的。
问题:Transformer和GPT都是神经网络,从定义上应该是判别式模型才对?
Transformer和GPT都是神经网络模型,属于深度学习的范畴。神经网络模型在形式上是判别式模型,因为它们直接学习从输入到输出的映射关系,不考虑数据的生成过程。但是,在处理生成任务,比如文本生成、语音合成等任务时,神经网络模型可以使用自回归的方式进行生成,此时它们的行为更像生成式模型,所以称之为生成式自回归模型是可以的。
用自回归机制来逐词生成翻译结果
继续使用同样的中英翻译数据集,还是使用之前的Transformer模型,这里我们只是加一个用贪婪搜索进行生成式解码的函数,然后在测试过程中调用这个函数重新测试。
代码调整的第一步:定义一个贪婪解码器函数。
# 定义贪婪解码器函数 def greedy_decoder(model, enc_input, start_symbol): # 对输入数据进行编码,并获得编码器输出以及自注意力权重 enc_outputs, enc_self_attns = model.encoder(enc_input) # 初始化解码器输入为全零张量,大小为 (1, 5),数据类型与 enc_input 一致 dec_input = torch.zeros(1, 5).type_as(enc_input.data) # 设置下一个要解码的符号为开始符号 next_symbol = start_symbol # 循环 5 次,为解码器输入中的每一个位置填充一个符号 for i in range(0, 5): # 将下一个符号放入解码器输入的当前位置 dec_input[0][i] = next_symbol # 运行解码器,获得解码器输出、解码器自注意力权重和编码器 - 解码器注意力权重 dec_output, _, _ = model.decoder(dec_input, enc_input, enc_outputs) # 将解码器输出投影到目标词汇空间 projected = model.projection(dec_output) # 找到具有最高概率的下一个单词 prob = projected.squeeze(0).max(dim=-1, keepdim=False)[1] next_word = prob.data[i] # 将找到的下一个单词作为新的符号 next_symbol = next_word.item() # 返回解码器输入,它包含了生成的符号序列 dec_outputs = dec_input return dec_outputs

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
上述代码定义了一个贪婪解码器函数greedy_decoder。该函数将模型model、编码器输入 enc_input及开始符号start_symbol作为输入。贪婪解码器通过寻找具有最高概率的单词作为下一个生成单词,从而生成一个单词序列。其中的关键部分是解码器会循环 5次,每次为解码器输入中的一个位置填充一个刚刚生成的符号,然后将这个符号和之前生成的符号一起,作为解码器输入序列dec_input输入下一次的解码器调用过程,直至循环结束。
代码调整的第二步:使用贪婪解码器进行测试,生成翻译文本。
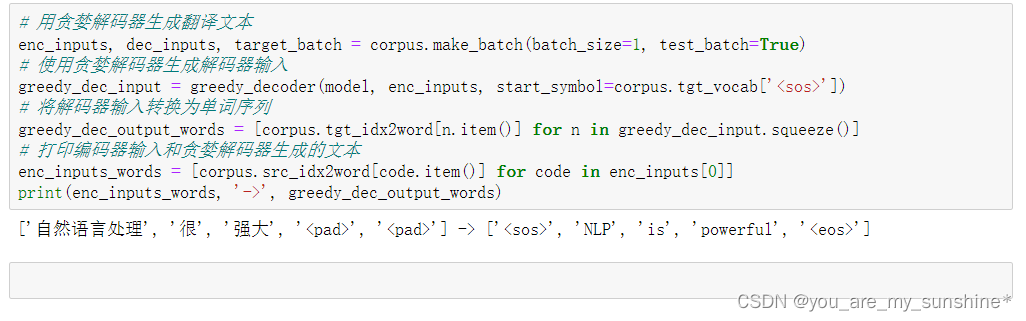
# 用贪婪解码器生成翻译文本
enc_inputs, dec_inputs, target_batch = corpus.make_batch(batch_size=1, test_batch=True)
# 使用贪婪解码器生成解码器输入
greedy_dec_input = greedy_decoder(model, enc_inputs, start_symbol=corpus.tgt_vocab['<sos>'])
# 将解码器输入转换为单词序列
greedy_dec_output_words = [corpus.tgt_idx2word[n.item()] for n in greedy_dec_input.squeeze()]
# 打印编码器输入和贪婪解码器生成的文本
enc_inputs_words = [corpus.src_idx2word[code.item()] for code in enc_inputs[0]]
print(enc_inputs_words, '->', greedy_dec_output_words)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
看到贪婪解码器逐词推演生成的文本,只修改了这么一点点内容,效果就变得这么好了。
完整代码
import numpy as np # 导入 numpy 库 import torch # 导入 torch 库 import torch.nn as nn # 导入 torch.nn 库 d_k = 64 # K(=Q) 维度 d_v = 64 # V 维度 # 定义缩放点积注意力类 class ScaledDotProductAttention(nn.Module): def __init__(self): super(ScaledDotProductAttention, self).__init__() def forward(self, Q, K, V, attn_mask): #------------------------- 维度信息 -------------------------------- # Q K V [batch_size, n_heads, len_q/k/v, dim_q=k/v] (dim_q=dim_k) # attn_mask [batch_size, n_heads, len_q, len_k] #---------------------------------------------------------------- # 计算注意力分数(原始权重)[batch_size,n_heads,len_q,len_k] scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(d_k) #------------------------- 维度信息 -------------------------------- # scores [batch_size, n_heads, len_q, len_k] #----------------------------------------------------------------- # 使用注意力掩码,将 attn_mask 中值为 1 的位置的权重替换为极小值 #------------------------- 维度信息 -------------------------------- # attn_mask [batch_size, n_heads, len_q, len_k], 形状和 scores 相同 #----------------------------------------------------------------- scores.masked_fill_(attn_mask, -1e9) # 对注意力分数进行 softmax 归一化 weights = nn.Softmax(dim=-1)(scores) #------------------------- 维度信息 -------------------------------- # weights [batch_size, n_heads, len_q, len_k], 形状和 scores 相同 #----------------------------------------------------------------- # 计算上下文向量(也就是注意力的输出), 是上下文信息的紧凑表示 context = torch.matmul(weights, V) #------------------------- 维度信息 -------------------------------- # context [batch_size, n_heads, len_q, dim_v] #----------------------------------------------------------------- return context, weights # 返回上下文向量和注意力分数
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
# 定义多头自注意力类 d_embedding = 512 # Embedding 的维度 n_heads = 8 # Multi-Head Attention 中头的个数 batch_size = 3 # 每一批的数据大小 class MultiHeadAttention(nn.Module): def __init__(self): super(MultiHeadAttention, self).__init__() self.W_Q = nn.Linear(d_embedding, d_k * n_heads) # Q的线性变换层 self.W_K = nn.Linear(d_embedding, d_k * n_heads) # K的线性变换层 self.W_V = nn.Linear(d_embedding, d_v * n_heads) # V的线性变换层 self.linear = nn.Linear(n_heads * d_v, d_embedding) self.layer_norm = nn.LayerNorm(d_embedding) def forward(self, Q, K, V, attn_mask): #------------------------- 维度信息 -------------------------------- # Q K V [batch_size, len_q/k/v, embedding_dim] #----------------------------------------------------------------- residual, batch_size = Q, Q.size(0) # 保留残差连接 # 将输入进行线性变换和重塑,以便后续处理 q_s = self.W_Q(Q).view(batch_size, -1, n_heads, d_k).transpose(1,2) k_s = self.W_K(K).view(batch_size, -1, n_heads, d_k).transpose(1,2) v_s = self.W_V(V).view(batch_size, -1, n_heads, d_v).transpose(1,2) #------------------------- 维度信息 -------------------------------- # q_s k_s v_s: [batch_size, n_heads, len_q/k/v, d_q=k/v] #----------------------------------------------------------------- # 将注意力掩码复制到多头 attn_mask: [batch_size, n_heads, len_q, len_k] attn_mask = attn_mask.unsqueeze(1).repeat(1, n_heads, 1, 1) #------------------------- 维度信息 -------------------------------- # attn_mask [batch_size, n_heads, len_q, len_k] #----------------------------------------------------------------- # 使用缩放点积注意力计算上下文和注意力权重 context, weights = ScaledDotProductAttention()(q_s, k_s, v_s, attn_mask) #------------------------- 维度信息 -------------------------------- # context [batch_size, n_heads, len_q, dim_v] # weights [batch_size, n_heads, len_q, len_k] #----------------------------------------------------------------- # 通过调整维度将多个头的上下文向量连接在一起 context = context.transpose(1, 2).contiguous().view(batch_size, -1, n_heads * d_v) #------------------------- 维度信息 -------------------------------- # context [batch_size, len_q, n_heads * dim_v] #----------------------------------------------------------------- # 用一个线性层把连接后的多头自注意力结果转换,原始地嵌入维度 output = self.linear(context) #------------------------- 维度信息 -------------------------------- # output [batch_size, len_q, embedding_dim] #----------------------------------------------------------------- # 与输入 (Q) 进行残差链接,并进行层归一化后输出 output = self.layer_norm(output + residual) #------------------------- 维度信息 -------------------------------- # output [batch_size, len_q, embedding_dim] #----------------------------------------------------------------- return output, weights # 返回层归一化的输出和注意力权重
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
# 定义逐位置前馈网络类 class PoswiseFeedForwardNet(nn.Module): def __init__(self, d_ff=2048): super(PoswiseFeedForwardNet, self).__init__() # 定义一维卷积层 1,用于将输入映射到更高维度 self.conv1 = nn.Conv1d(in_channels=d_embedding, out_channels=d_ff, kernel_size=1) # 定义一维卷积层 2,用于将输入映射回原始维度 self.conv2 = nn.Conv1d(in_channels=d_ff, out_channels=d_embedding, kernel_size=1) # 定义层归一化 self.layer_norm = nn.LayerNorm(d_embedding) def forward(self, inputs): #------------------------- 维度信息 -------------------------------- # inputs [batch_size, len_q, embedding_dim] #---------------------------------------------------------------- residual = inputs # 保留残差连接 # 在卷积层 1 后使用 ReLU 激活函数 output = nn.ReLU()(self.conv1(inputs.transpose(1, 2))) #------------------------- 维度信息 -------------------------------- # output [batch_size, d_ff, len_q] #---------------------------------------------------------------- # 使用卷积层 2 进行降维 output = self.conv2(output).transpose(1, 2) #------------------------- 维度信息 -------------------------------- # output [batch_size, len_q, embedding_dim] #---------------------------------------------------------------- # 与输入进行残差链接,并进行层归一化 output = self.layer_norm(output + residual) #------------------------- 维度信息 -------------------------------- # output [batch_size, len_q, embedding_dim] #---------------------------------------------------------------- return output # 返回加入残差连接后层归一化的结果
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
# 生成正弦位置编码表的函数,用于在 Transformer 中引入位置信息 def get_sin_enc_table(n_position, embedding_dim): #------------------------- 维度信息 -------------------------------- # n_position: 输入序列的最大长度 # embedding_dim: 词嵌入向量的维度 #----------------------------------------------------------------- # 根据位置和维度信息,初始化正弦位置编码表 sinusoid_table = np.zeros((n_position, embedding_dim)) # 遍历所有位置和维度,计算角度值 for pos_i in range(n_position): for hid_j in range(embedding_dim): angle = pos_i / np.power(10000, 2 * (hid_j // 2) / embedding_dim) sinusoid_table[pos_i, hid_j] = angle # 计算正弦和余弦值 sinusoid_table[:, 0::2] = np.sin(sinusoid_table[:, 0::2]) # dim 2i 偶数维 sinusoid_table[:, 1::2] = np.cos(sinusoid_table[:, 1::2]) # dim 2i+1 奇数维 #------------------------- 维度信息 -------------------------------- # sinusoid_table 的维度是 [n_position, embedding_dim] #---------------------------------------------------------------- return torch.FloatTensor(sinusoid_table) # 返回正弦位置编码表
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
# 定义填充注意力掩码函数 def get_attn_pad_mask(seq_q, seq_k): #------------------------- 维度信息 -------------------------------- # seq_q 的维度是 [batch_size, len_q] # seq_k 的维度是 [batch_size, len_k] #----------------------------------------------------------------- batch_size, len_q = seq_q.size() batch_size, len_k = seq_k.size() # 生成布尔类型张量 pad_attn_mask = seq_k.data.eq(0).unsqueeze(1) # <PAD>token 的编码值为 0 #------------------------- 维度信息 -------------------------------- # pad_attn_mask 的维度是 [batch_size,1,len_k] #----------------------------------------------------------------- # 变形为与注意力分数相同形状的张量 pad_attn_mask = pad_attn_mask.expand(batch_size, len_q, len_k) #------------------------- 维度信息 -------------------------------- # pad_attn_mask 的维度是 [batch_size,len_q,len_k] #----------------------------------------------------------------- return pad_attn_mask
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
# 定义编码器层类 class EncoderLayer(nn.Module): def __init__(self): super(EncoderLayer, self).__init__() self.enc_self_attn = MultiHeadAttention() # 多头自注意力层 self.pos_ffn = PoswiseFeedForwardNet() # 位置前馈神经网络层 def forward(self, enc_inputs, enc_self_attn_mask): #------------------------- 维度信息 -------------------------------- # enc_inputs 的维度是 [batch_size, seq_len, embedding_dim] # enc_self_attn_mask 的维度是 [batch_size, seq_len, seq_len] #----------------------------------------------------------------- # 将相同的 Q,K,V 输入多头自注意力层 , 返回的 attn_weights 增加了头数 enc_outputs, attn_weights = self.enc_self_attn(enc_inputs, enc_inputs, enc_inputs, enc_self_attn_mask) #------------------------- 维度信息 -------------------------------- # enc_outputs 的维度是 [batch_size, seq_len, embedding_dim] # attn_weights 的维度是 [batch_size, n_heads, seq_len, seq_len] # 将多头自注意力 outputs 输入位置前馈神经网络层 enc_outputs = self.pos_ffn(enc_outputs) # 维度与 enc_inputs 相同 #------------------------- 维度信息 -------------------------------- # enc_outputs 的维度是 [batch_size, seq_len, embedding_dim] #----------------------------------------------------------------- return enc_outputs, attn_weights # 返回编码器输出和每层编码器注意力权重
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
# 定义编码器类 n_layers = 6 # 设置 Encoder 的层数 class Encoder(nn.Module): def __init__(self, corpus): super(Encoder, self).__init__() self.src_emb = nn.Embedding(len(corpus.src_vocab), d_embedding) # 词嵌入层 self.pos_emb = nn.Embedding.from_pretrained( \ get_sin_enc_table(corpus.src_len+1, d_embedding), freeze=True) # 位置嵌入层 self.layers = nn.ModuleList(EncoderLayer() for _ in range(n_layers))# 编码器层数 def forward(self, enc_inputs): #------------------------- 维度信息 -------------------------------- # enc_inputs 的维度是 [batch_size, source_len] #----------------------------------------------------------------- # 创建一个从 1 到 source_len 的位置索引序列 pos_indices = torch.arange(1, enc_inputs.size(1) + 1).unsqueeze(0).to(enc_inputs) #------------------------- 维度信息 -------------------------------- # pos_indices 的维度是 [1, source_len] #----------------------------------------------------------------- # 对输入进行词嵌入和位置嵌入相加 [batch_size, source_len,embedding_dim] enc_outputs = self.src_emb(enc_inputs) + self.pos_emb(pos_indices) #------------------------- 维度信息 -------------------------------- # enc_outputs 的维度是 [batch_size, seq_len, embedding_dim] #----------------------------------------------------------------- # 生成自注意力掩码 enc_self_attn_mask = get_attn_pad_mask(enc_inputs, enc_inputs) #------------------------- 维度信息 -------------------------------- # enc_self_attn_mask 的维度是 [batch_size, len_q, len_k] #----------------------------------------------------------------- enc_self_attn_weights = [] # 初始化 enc_self_attn_weights # 通过编码器层 [batch_size, seq_len, embedding_dim] for layer in self.layers: enc_outputs, enc_self_attn_weight = layer(enc_outputs, enc_self_attn_mask) enc_self_attn_weights.append(enc_self_attn_weight) #------------------------- 维度信息 -------------------------------- # enc_outputs 的维度是 [batch_size, seq_len, embedding_dim] 维度与 enc_inputs 相同 # enc_self_attn_weights 是一个列表,每个元素的维度是 [batch_size, n_heads, seq_len, seq_len] #----------------------------------------------------------------- return enc_outputs, enc_self_attn_weights # 返回编码器输出和编码器注意力权重
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
# 生成后续注意力掩码的函数,用于在多头自注意力计算中忽略未来信息 def get_attn_subsequent_mask(seq): #------------------------- 维度信息 -------------------------------- # seq 的维度是 [batch_size, seq_len(Q)=seq_len(K)] #----------------------------------------------------------------- # 获取输入序列的形状 attn_shape = [seq.size(0), seq.size(1), seq.size(1)] #------------------------- 维度信息 -------------------------------- # attn_shape 是一个一维张量 [batch_size, seq_len(Q), seq_len(K)] #----------------------------------------------------------------- # 使用 numpy 创建一个上三角矩阵(triu = triangle upper) subsequent_mask = np.triu(np.ones(attn_shape), k=1) #------------------------- 维度信息 -------------------------------- # subsequent_mask 的维度是 [batch_size, seq_len(Q), seq_len(K)] #----------------------------------------------------------------- # 将 numpy 数组转换为 PyTorch 张量,并将数据类型设置为 byte(布尔值) subsequent_mask = torch.from_numpy(subsequent_mask).byte() #------------------------- 维度信息 -------------------------------- # 返回的 subsequent_mask 的维度是 [batch_size, seq_len(Q), seq_len(K)] #----------------------------------------------------------------- return subsequent_mask # 返回后续位置的注意力掩码
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
# 定义解码器层类 class DecoderLayer(nn.Module): def __init__(self): super(DecoderLayer, self).__init__() self.dec_self_attn = MultiHeadAttention() # 多头自注意力层 self.dec_enc_attn = MultiHeadAttention() # 多头自注意力层,连接编码器和解码器 self.pos_ffn = PoswiseFeedForwardNet() # 位置前馈神经网络层 def forward(self, dec_inputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask): #------------------------- 维度信息 -------------------------------- # dec_inputs 的维度是 [batch_size, target_len, embedding_dim] # enc_outputs 的维度是 [batch_size, source_len, embedding_dim] # dec_self_attn_mask 的维度是 [batch_size, target_len, target_len] # dec_enc_attn_mask 的维度是 [batch_size, target_len, source_len] #----------------------------------------------------------------- # 将相同的 Q,K,V 输入多头自注意力层 dec_outputs, dec_self_attn = self.dec_self_attn(dec_inputs, dec_inputs, dec_inputs, dec_self_attn_mask) #------------------------- 维度信息 -------------------------------- # dec_outputs 的维度是 [batch_size, target_len, embedding_dim] # dec_self_attn 的维度是 [batch_size, n_heads, target_len, target_len] #----------------------------------------------------------------- # 将解码器输出和编码器输出输入多头自注意力层 dec_outputs, dec_enc_attn = self.dec_enc_attn(dec_outputs, enc_outputs, enc_outputs, dec_enc_attn_mask) #------------------------- 维度信息 -------------------------------- # dec_outputs 的维度是 [batch_size, target_len, embedding_dim] # dec_enc_attn 的维度是 [batch_size, n_heads, target_len, source_len] #----------------------------------------------------------------- # 输入位置前馈神经网络层 dec_outputs = self.pos_ffn(dec_outputs) #------------------------- 维度信息 -------------------------------- # dec_outputs 的维度是 [batch_size, target_len, embedding_dim] # dec_self_attn 的维度是 [batch_size, n_heads, target_len, target_len] # dec_enc_attn 的维度是 [batch_size, n_heads, target_len, source_len] #----------------------------------------------------------------- # 返回解码器层输出,每层的自注意力和解 - 编码器注意力权重 return dec_outputs, dec_self_attn, dec_enc_attn
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
# 定义解码器类 n_layers = 6 # 设置 Decoder 的层数 class Decoder(nn.Module): def __init__(self, corpus): super(Decoder, self).__init__() self.tgt_emb = nn.Embedding(len(corpus.tgt_vocab), d_embedding) # 词嵌入层 self.pos_emb = nn.Embedding.from_pretrained( \ get_sin_enc_table(corpus.tgt_len+1, d_embedding), freeze=True) # 位置嵌入层 self.layers = nn.ModuleList([DecoderLayer() for _ in range(n_layers)]) # 叠加多层 def forward(self, dec_inputs, enc_inputs, enc_outputs): #------------------------- 维度信息 -------------------------------- # dec_inputs 的维度是 [batch_size, target_len] # enc_inputs 的维度是 [batch_size, source_len] # enc_outputs 的维度是 [batch_size, source_len, embedding_dim] #----------------------------------------------------------------- # 创建一个从 1 到 source_len 的位置索引序列 pos_indices = torch.arange(1, dec_inputs.size(1) + 1).unsqueeze(0).to(dec_inputs) #------------------------- 维度信息 -------------------------------- # pos_indices 的维度是 [1, target_len] #----------------------------------------------------------------- # 对输入进行词嵌入和位置嵌入相加 dec_outputs = self.tgt_emb(dec_inputs) + self.pos_emb(pos_indices) #------------------------- 维度信息 -------------------------------- # dec_outputs 的维度是 [batch_size, target_len, embedding_dim] #----------------------------------------------------------------- # 生成解码器自注意力掩码和解码器 - 编码器注意力掩码 dec_self_attn_pad_mask = get_attn_pad_mask(dec_inputs, dec_inputs) # 填充位掩码 dec_self_attn_subsequent_mask = get_attn_subsequent_mask(dec_inputs) # 后续位掩码 dec_self_attn_mask = torch.gt((dec_self_attn_pad_mask \ + dec_self_attn_subsequent_mask), 0) dec_enc_attn_mask = get_attn_pad_mask(dec_inputs, enc_inputs) # 解码器 - 编码器掩码 #------------------------- 维度信息 -------------------------------- # dec_self_attn_pad_mask 的维度是 [batch_size, target_len, target_len] # dec_self_attn_subsequent_mask 的维度是 [batch_size, target_len, target_len] # dec_self_attn_mask 的维度是 [batch_size, target_len, target_len] # dec_enc_attn_mask 的维度是 [batch_size, target_len, source_len] #----------------------------------------------------------------- dec_self_attns, dec_enc_attns = [], [] # 初始化 dec_self_attns, dec_enc_attns # 通过解码器层 [batch_size, seq_len, embedding_dim] for layer in self.layers: dec_outputs, dec_self_attn, dec_enc_attn = layer(dec_outputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask) dec_self_attns.append(dec_self_attn) dec_enc_attns.append(dec_enc_attn) #------------------------- 维度信息 -------------------------------- # dec_outputs 的维度是 [batch_size, target_len, embedding_dim] # dec_self_attns 是一个列表,每个元素的维度是 [batch_size, n_heads, target_len, target_len] # dec_enc_attns 是一个列表,每个元素的维度是 [batch_size, n_heads, target_len, source_len] #----------------------------------------------------------------- # 返回解码器输出,解码器自注意力和解码器 - 编码器注意力权重 return dec_outputs, dec_self_attns, dec_enc_attns
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
# 定义 Transformer 模型 class Transformer(nn.Module): def __init__(self, corpus): super(Transformer, self).__init__() self.encoder = Encoder(corpus) # 初始化编码器实例 self.decoder = Decoder(corpus) # 初始化解码器实例 # 定义线性投影层,将解码器输出转换为目标词汇表大小的概率分布 self.projection = nn.Linear(d_embedding, len(corpus.tgt_vocab), bias=False) def forward(self, enc_inputs, dec_inputs): #------------------------- 维度信息 -------------------------------- # enc_inputs 的维度是 [batch_size, source_seq_len] # dec_inputs 的维度是 [batch_size, target_seq_len] #----------------------------------------------------------------- # 将输入传递给编码器,并获取编码器输出和自注意力权重 enc_outputs, enc_self_attns = self.encoder(enc_inputs) #------------------------- 维度信息 -------------------------------- # enc_outputs 的维度是 [batch_size, source_len, embedding_dim] # enc_self_attns 是一个列表,每个元素的维度是 [batch_size, n_heads, src_seq_len, src_seq_len] #----------------------------------------------------------------- # 将编码器输出、解码器输入和编码器输入传递给解码器 # 获取解码器输出、解码器自注意力权重和编码器 - 解码器注意力权重 dec_outputs, dec_self_attns, dec_enc_attns = self.decoder(dec_inputs, enc_inputs, enc_outputs) #------------------------- 维度信息 -------------------------------- # dec_outputs 的维度是 [batch_size, target_len, embedding_dim] # dec_self_attns 是一个列表,每个元素的维度是 [batch_size, n_heads, tgt_seq_len, src_seq_len] # dec_enc_attns 是一个列表,每个元素的维度是 [batch_size, n_heads, tgt_seq_len, src_seq_len] #----------------------------------------------------------------- # 将解码器输出传递给投影层,生成目标词汇表大小的概率分布 dec_logits = self.projection(dec_outputs) #------------------------- 维度信息 -------------------------------- # dec_logits 的维度是 [batch_size, tgt_seq_len, tgt_vocab_size] #----------------------------------------------------------------- # 返回逻辑值 ( 原始预测结果 ), 编码器自注意力权重,解码器自注意力权重,解 - 编码器注意力权重 return dec_logits, enc_self_attns, dec_self_attns, dec_enc_attns
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
sentences = [
['哒哥 喜欢 爬山', 'DaGe likes hiking'],
['我 爱 学习 人工智能', 'I love studying AI'],
['深度学习 改变 世界', ' DL changed the world'],
['自然语言处理 很 强大', 'NLP is powerful'],
['神经网络 非常 复杂', 'Neural-networks are complex'] ]
- 1
- 2
- 3
- 4
- 5
- 6
from collections import Counter # 导入 Counter 类 # 定义 TranslationCorpus 类 class TranslationCorpus: def __init__(self, sentences): self.sentences = sentences # 计算源语言和目标语言的最大句子长度,并分别加 1 和 2 以容纳填充符和特殊符号 self.src_len = max(len(sentence[0].split()) for sentence in sentences) + 1 self.tgt_len = max(len(sentence[1].split()) for sentence in sentences) + 2 # 创建源语言和目标语言的词汇表 self.src_vocab, self.tgt_vocab = self.create_vocabularies() # 创建索引到单词的映射 self.src_idx2word = {v: k for k, v in self.src_vocab.items()} self.tgt_idx2word = {v: k for k, v in self.tgt_vocab.items()} # 定义创建词汇表的函数 def create_vocabularies(self): # 统计源语言和目标语言的单词频率 src_counter = Counter(word for sentence in self.sentences for word in sentence[0].split()) tgt_counter = Counter(word for sentence in self.sentences for word in sentence[1].split()) # 创建源语言和目标语言的词汇表,并为每个单词分配一个唯一的索引 src_vocab = {'<pad>': 0, **{word: i+1 for i, word in enumerate(src_counter)}} tgt_vocab = {'<pad>': 0, '<sos>': 1, '<eos>': 2, **{word: i+3 for i, word in enumerate(tgt_counter)}} return src_vocab, tgt_vocab # 定义创建批次数据的函数 def make_batch(self, batch_size, test_batch=False): input_batch, output_batch, target_batch = [], [], [] # 随机选择句子索引 sentence_indices = torch.randperm(len(self.sentences))[:batch_size] for index in sentence_indices: src_sentence, tgt_sentence = self.sentences[index] # 将源语言和目标语言的句子转换为索引序列 src_seq = [self.src_vocab[word] for word in src_sentence.split()] tgt_seq = [self.tgt_vocab['<sos>']] + [self.tgt_vocab[word] \ for word in tgt_sentence.split()] + [self.tgt_vocab['<eos>']] # 对源语言和目标语言的序列进行填充 src_seq += [self.src_vocab['<pad>']] * (self.src_len - len(src_seq)) tgt_seq += [self.tgt_vocab['<pad>']] * (self.tgt_len - len(tgt_seq)) # 将处理好的序列添加到批次中 input_batch.append(src_seq) output_batch.append([self.tgt_vocab['<sos>']] + ([self.tgt_vocab['<pad>']] * \ (self.tgt_len - 2)) if test_batch else tgt_seq[:-1]) target_batch.append(tgt_seq[1:]) # 将批次转换为 LongTensor 类型 input_batch = torch.LongTensor(input_batch) output_batch = torch.LongTensor(output_batch) target_batch = torch.LongTensor(target_batch) return input_batch, output_batch, target_batch # 创建语料库类实例 corpus = TranslationCorpus(sentences)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
import torch # 导入 torch
import torch.optim as optim # 导入优化器
model = Transformer(corpus) # 创建模型实例
criterion = nn.CrossEntropyLoss() # 损失函数
optimizer = optim.Adam(model.parameters(), lr=0.0001) # 优化器
epochs = 5 # 训练轮次
for epoch in range(epochs): # 训练 100 轮
optimizer.zero_grad() # 梯度清零
enc_inputs, dec_inputs, target_batch = corpus.make_batch(batch_size) # 创建训练数据
outputs, _, _, _ = model(enc_inputs, dec_inputs) # 获取模型输出
loss = criterion(outputs.view(-1, len(corpus.tgt_vocab)), target_batch.view(-1)) # 计算损失
if (epoch + 1) % 1 == 0: # 打印损失
print(f"Epoch: {epoch + 1:04d} cost = {loss:.6f}")
loss.backward()# 反向传播
optimizer.step()# 更新参数
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15

# 定义贪婪解码器函数 def greedy_decoder(model, enc_input, start_symbol): # 对输入数据进行编码,并获得编码器输出以及自注意力权重 enc_outputs, enc_self_attns = model.encoder(enc_input) # 初始化解码器输入为全零张量,大小为 (1, 5),数据类型与 enc_input 一致 dec_input = torch.zeros(1, 5).type_as(enc_input.data) # 设置下一个要解码的符号为开始符号 next_symbol = start_symbol # 循环 5 次,为解码器输入中的每一个位置填充一个符号 for i in range(0, 5): # 将下一个符号放入解码器输入的当前位置 dec_input[0][i] = next_symbol # 运行解码器,获得解码器输出、解码器自注意力权重和编码器 - 解码器注意力权重 dec_output, _, _ = model.decoder(dec_input, enc_input, enc_outputs) # 将解码器输出投影到目标词汇空间 projected = model.projection(dec_output) # 找到具有最高概率的下一个单词 prob = projected.squeeze(0).max(dim=-1, keepdim=False)[1] next_word = prob.data[i] # 将找到的下一个单词作为新的符号 next_symbol = next_word.item() # 返回解码器输入,它包含了生成的符号序列 dec_outputs = dec_input return dec_outputs
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
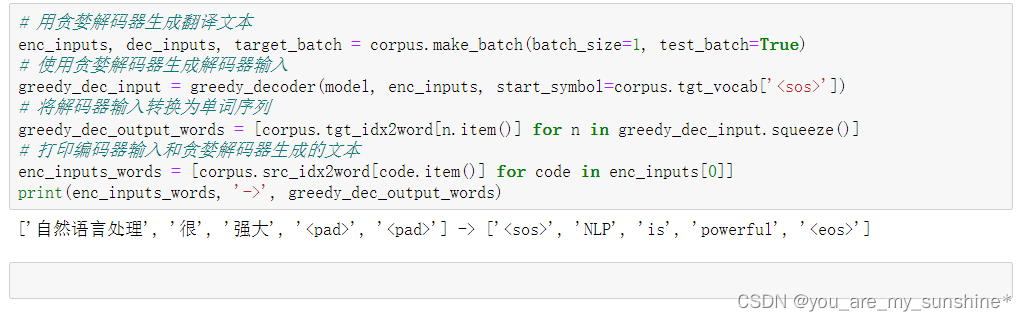
# 用贪婪解码器生成翻译文本
enc_inputs, dec_inputs, target_batch = corpus.make_batch(batch_size=1, test_batch=True)
# 使用贪婪解码器生成解码器输入
greedy_dec_input = greedy_decoder(model, enc_inputs, start_symbol=corpus.tgt_vocab['<sos>'])
# 将解码器输入转换为单词序列
greedy_dec_output_words = [corpus.tgt_idx2word[n.item()] for n in greedy_dec_input.squeeze()]
# 打印编码器输入和贪婪解码器生成的文本
enc_inputs_words = [corpus.src_idx2word[code.item()] for code in enc_inputs[0]]
print(enc_inputs_words, '->', greedy_dec_output_words)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
小结
GPT 模型基于 Transformer架构,使用单向(从左到右)的Transformer 解码器进行预训练。预训练过程在大量无标签文本上进行,目标是通过给定的上下文预测下一个单词。
GPT模型中,采用了生成式自回归这种基于已有序列来预测下一个元素的方法。在训练阶段,模型通过大量文本数据学习生成下一个词的能力;在预测阶段,模型利用训练好的参数来生成一段连贯的文本。
学习的参考资料:
(1)书籍
利用Python进行数据分析
西瓜书
百面机器学习
机器学习实战
阿里云天池大赛赛题解析(机器学习篇)
白话机器学习中的数学
零基础学机器学习
图解机器学习算法
动手学深度学习(pytorch)
…
(2)机构
光环大数据
开课吧
极客时间
七月在线
深度之眼
贪心学院
拉勾教育
博学谷
慕课网
海贼宝藏
…

