
热门标签
热门文章
- 1面向 AI 的编程 -- 爬虫实战:爬取某乎粉丝_ai爬虫
- 2ASM Disk Group Will not Mount In Presence Of Duplicate Disks / Devices: ORA-15032, ORA-15017, ORA-15...
- 3AI助力90.4%双11前端模块自动生成_基于ai javascript可视化编辑器
- 4【Bert】(六)句子关系判断--源码解析(bert基础模型)_max_position_embeddings
- 5浅谈sysfs系统--文件和目录的创建_zsfs文件为此系统的信息文件,在exit或quit的时候会自动创建在sfs_cache文件夹下。
- 6gateway集成sentinel配置nacos持久化GatewayFlowRule规则后--GatewayFlowRule规则失效(规则的时间单位和时间粒度失效)_在nacos中持久化的规则 加载了 但是不展示
- 7算法·动态规划Dynamic Programming
- 8Pytorch的安装教程从0开始_pytorch 安装
- 9DevOps 发展史_devops发展史
- 10WOT全球技术创新大会2022即将召开,亮点抢先看
当前位置: article > 正文
transformer--解码器_transformer解码器
作者:菜鸟追梦旅行 | 2024-04-06 14:53:47
赞
踩
transformer解码器
在编码器中实现了编码器的各种组件,其实解码器中使用的也是这些组件,如下图:

解码器组成部分:
- 由N个解码器层堆叠而成
- 每个解码器层由三个子层连接结构组成
- 第一个子层连接结构包括一个多头自注意力子层和规范化层以及一个残差连接
- 第二个子层连接结构包括一个多头注意力子层和规范化层以及一个残差连接
- 第三个子层连接结构包括一个前馈全连接子层和规范化层以及一个残差连接
解码器层code
- # 解码器层的类实现
- class DecoderLayer(nn.Module):
- def __init__(self, size, self_attn, src_attn, feed_forward,dropout) -> None:
- """
- size : 词嵌入维度
- self_attn:多头自注意对象,需要Q=K=V
- src_attn:多头注意力对象,这里Q!=K=V
- feed_forward: 前馈全连接层对象
- """
- super(DecoderLayer,self).__init__()
-
- self.size = size
- self.self_attn = self_attn
- self.src_attn = src_attn
- self.feed_forward = feed_forward
- # 根据论文图使用clones克隆三个子层对象
- self.sublayer = clones(SublayerConnection(size,dropout), 3)
-
- def forward(self, x, memory, source_mask, target_mask):
- """
- x : 上一层的输入
- memory: 来自编码器层的语义存储变量
- source_mask: 源码数据掩码张量,针对就是输入到解码器的数据
- target_mask: 目标数据掩码张量,针对解码器最后生成的数据,一个一个的推理生成的词
- """
-
- m = memory
-
- # 将x传入第一个子层结构,第一个子层结构输入分别是x和self_attn函数,因为是自注意力机制,所以Q=K=V=x
- # 最后一个参数是目标数据掩码张量,这时要对目标数据进行掩码,因为此时模型可能还没有生成任何目标数据,
- # 比如在解码器准备生成第一个字符或词汇时,我们其实已经传入第一个字符以便计算损失
- # 但是我们不希望在生成第一个字符时模型能利用这个信息,因为我们会将其遮掩,同样生成第二个字符或词汇时
- # 模型只能使用第一个字符或词汇信息,第二个字符以及以后得信息都不允许被模型使用
- x = self.sublayer[0](x, lambda x: self.self_attn(x,x,x,target_mask))
-
- # 紧接着第一层的输出进入第二个子层,这个子层是常规的注意力机制,但是q是输入x;k、v是编码层输出memory
- # 同样也传入source_mask, 但是进行源数据遮掩的原因并非是抑制信息泄露,而是遮蔽掉对结果没有意义的的字符而产生的注意力
- # 以此提升模型的效果和训练速度,这样就完成第二个子层的处理
- x = self.sublayer[1](x, lambda x: self.src_attn(x,m,m,source_mask))
-
- # 最后一个子层就是前馈全连接子层,经过他的处理后就可以返回结果,这就是解码器层的结构
- return self.sublayer[2](x,self.feed_forward)

测试代码全放到最后
测试结果:
解码器
解码器的作用:根据编码器的结果以及上一次预测的结果,对下一次可能出现的值进行特征表示
- # 解码器
- class Decoder(nn.Module):
- def __init__(self,layer,N) -> None:
- """ layer: 解码器层, N:解码器层的个数"""
- super(Decoder,self).__init__()
- self.layers = clones(layer,N)
- self.norm = LayerNorm(layer.size)
-
- def forward(self, x, memory,source_mask, target_mask):
- # x:目标数据的嵌入表示
- # memory:编码器的输出
- # source_mask: 源数据的掩码张量
- # target_mask: 目标数据的掩码张量
-
- for layre in self.layers:
- x = layer(x,memory,source_mask,target_mask)
-
- return self.norm(x)
测试代码放到最后代码
结果:
- de_result.shape : torch.Size([2, 4, 512])
- de_result : tensor([[[-0.0569, 0.3506, -0.4071, ..., -1.0797, 0.4819, 1.5599],
- [ 0.2342, 0.0497, 0.8868, ..., 1.8162, 0.1724, -0.0384],
- [-0.0438, -0.8501, 1.2952, ..., 0.5489, 0.1530, 1.2819],
- [-2.7741, 0.4939, 1.5461, ..., -0.7539, 0.6964, -0.4137]],
-
- [[ 1.1773, -0.7767, 1.2400, ..., 0.4109, -0.0105, 1.3137],
- [ 0.0067, -0.5182, 0.1695, ..., -1.0328, -1.6252, 1.3039],
- [-0.8350, -0.8536, -0.4261, ..., -1.2965, 0.1531, 0.2299],
- [-0.2015, 0.5470, -0.9219, ..., -0.1534, 1.3922, -0.2488]]],
- grad_fn=<AddBackward0>)
输出部分
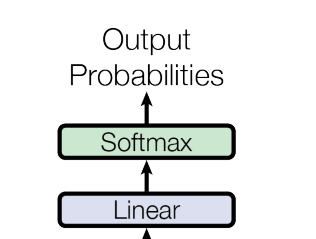
线性层的作用:
通过对上一步的线性变化得到指定维度的输出,也就是转换维度的作用,
softmax层的作用:
使最后一维的向量中的数字缩放到0-1的概率值域内,并满足他们的和为1
code
- # 输出
- class Generator(nn.Module):
- def __init__(self,d_mode, vocab_size) -> None:
- """
- d_mode: 词嵌入
- vocab_size: 词表大小
- """
- super(Generator,self).__init__()
-
- self.project = nn.Linear(d_mode, vocab_size)
-
- def forward(self, x):
- return F.log_softmax(self.project(x),dim=-1)
输出:
- gen_result.shape : torch.Size([2, 4, 1000])
- gen_result: tensor([[[-7.3236, -6.3419, -6.6023, ..., -6.8704, -6.2303, -6.9161],
- [-7.3549, -7.2196, -8.2483, ..., -6.5249, -6.9905, -6.4151],
- [-6.7272, -6.5778, -7.1534, ..., -6.3917, -7.4114, -6.7917],
- [-6.7106, -7.3387, -7.4814, ..., -6.7696, -6.8284, -7.5407]],
-
- [[-7.0403, -6.6602, -6.6994, ..., -6.5930, -7.5068, -7.0125],
- [-6.4951, -7.2265, -7.4753, ..., -7.0645, -7.2771, -7.2495],
- [-7.5860, -7.3894, -8.1477, ..., -6.7407, -6.4232, -8.4255],
- [-7.4713, -6.9773, -7.0890, ..., -7.6705, -7.1161, -7.3006]]],
- grad_fn=<LogSoftmaxBackward0>)
测试代码
-
- import numpy as np
- import torch
- import torch.nn.functional as F
- import torch.nn as nn
- import matplotlib.pyplot as plt
- import math
- import copy
- from inputs import Embeddings,PositionalEncoding
- from encode import subsequent_mask,attention,clones,MultiHeadedAttention,PositionwiseFeedForward,LayerNorm,SublayerConnection,Encoder,EncoderLayer
- # encode 代码在前面几节
-
- # 解码器层的类实现
- class DecoderLayer(nn.Module):
- def __init__(self, size, self_attn, src_attn, feed_forward,dropout) -> None:
- """
- size : 词嵌入维度
- self_attn:多头自注意对象,需要Q=K=V
- src_attn:多头注意力对象,这里Q!=K=V
- feed_forward: 前馈全连接层对象
- """
- super(DecoderLayer,self).__init__()
-
- self.size = size
- self.self_attn = self_attn
- self.src_attn = src_attn
- self.feed_forward = feed_forward
- # 根据论文图使用clones克隆三个子层对象
- self.sublayer = clones(SublayerConnection(size,dropout), 3)
-
- def forward(self, x, memory, source_mask, target_mask):
- """
- x : 上一层的输入
- memory: 来自编码器层的语义存储变量
- source_mask: 源码数据掩码张量,针对就是输入到解码器的数据
- target_mask: 目标数据掩码张量,针对解码器最后生成的数据,一个一个的推理生成的词
- """
-
- m = memory
-
- # 将x传入第一个子层结构,第一个子层结构输入分别是x和self_attn函数,因为是自注意力机制,所以Q=K=V=x
- # 最后一个参数是目标数据掩码张量,这时要对目标数据进行掩码,因为此时模型可能还没有生成任何目标数据,
- # 比如在解码器准备生成第一个字符或词汇时,我们其实已经传入第一个字符以便计算损失
- # 但是我们不希望在生成第一个字符时模型能利用这个信息,因为我们会将其遮掩,同样生成第二个字符或词汇时
- # 模型只能使用第一个字符或词汇信息,第二个字符以及以后得信息都不允许被模型使用
- x = self.sublayer[0](x, lambda x: self.self_attn(x,x,x,target_mask))
-
- # 紧接着第一层的输出进入第二个子层,这个子层是常规的注意力机制,但是q是输入x;k、v是编码层输出memory
- # 同样也传入source_mask, 但是进行源数据遮掩的原因并非是抑制信息泄露,而是遮蔽掉对结果没有意义的的字符而产生的注意力
- # 以此提升模型的效果和训练速度,这样就完成第二个子层的处理
- x = self.sublayer[1](x, lambda x: self.src_attn(x,m,m,source_mask))
-
- # 最后一个子层就是前馈全连接子层,经过他的处理后就可以返回结果,这就是解码器层的结构
- return self.sublayer[2](x,self.feed_forward)
-
-
-
- # 解码器
- class Decoder(nn.Module):
- def __init__(self,layer,N) -> None:
- """ layer: 解码器层, N:解码器层的个数"""
- super(Decoder,self).__init__()
- self.layers = clones(layer,N)
- self.norm = LayerNorm(layer.size)
-
- def forward(self, x, memory,source_mask, target_mask):
- # x:目标数据的嵌入表示
- # memory:编码器的输出
- # source_mask: 源数据的掩码张量
- # target_mask: 目标数据的掩码张量
-
- for layre in self.layers:
- x = layer(x,memory,source_mask,target_mask)
-
- return self.norm(x)
-
- # 输出
- class Generator(nn.Module):
- def __init__(self,d_mode, vocab_size) -> None:
- """
- d_mode: 词嵌入
- vocab_size: 词表大小
- """
- super(Generator,self).__init__()
-
- self.project = nn.Linear(d_mode, vocab_size)
-
- def forward(self, x):
- return F.log_softmax(self.project(x),dim=-1)
-
-
-
-
- if __name__ == "__main__":
- # 词嵌入
- dim = 512
- vocab =1000
- emb = Embeddings(dim,vocab)
- x = torch.LongTensor([[100,2,321,508],[321,234,456,324]])
- embr =emb(x)
- print("embr.shape = ",embr.shape)
- # 位置编码
- pe = PositionalEncoding(dim,0.1) # 位置向量的维度是20,dropout是0
- pe_result = pe(embr)
- print("pe_result.shape = ",pe_result.shape)
-
-
-
- # 编码器测试
- size = 512
- dropout=0.2
- head=8
- d_model=512
- d_ff = 64
-
- c = copy.deepcopy
- x = pe_result
-
-
- self_attn = MultiHeadedAttention(head,d_model,dropout)
- ff = PositionwiseFeedForward(d_model,d_ff,dropout)
- # 编码器层不是共享的,因此需要深度拷贝
- layer= EncoderLayer(size,c(self_attn),c(ff),dropout)
-
- N=8
- mask = torch.zeros(8,4,4)
-
- en = Encoder(layer,N)
- en_result = en(x,mask)
- print("en_result.shape : ",en_result.shape)
- print("en_result : ",en_result)
-
-
- # 解码器层测试
- size = 512
- dropout=0.2
- head=8
- d_model=512
- d_ff = 64
-
- self_attn = src_attn = MultiHeadedAttention(head,d_model,dropout)
- ff = PositionwiseFeedForward(d_model,d_ff,dropout)
-
- x = pe_result
- mask = torch.zeros(8,4,4)
- source_mask = target_mask = mask
- memory = en_result
-
- dl = DecoderLayer(size,self_attn,src_attn,ff,dropout)
- dl_result = dl(x,memory,source_mask,target_mask)
- print("dl_result.shape = ", dl_result.shape)
- print("dl_result = ", dl_result)
-
- # 解码器测试
-
- size = 512
- dropout=0.2
- head=8
- d_model=512
- d_ff = 64
- memory = en_result
- c = copy.deepcopy
- x = pe_result
-
-
- self_attn = MultiHeadedAttention(head,d_model,dropout)
- ff = PositionwiseFeedForward(d_model,d_ff,dropout)
- # 编码器层不是共享的,因此需要深度拷贝
- layer= DecoderLayer(size,c(self_attn),c(self_attn),c(ff),dropout)
-
- N=8
- mask = torch.zeros(8,4,4)
- source_mask = target_mask = mask
-
-
- de = Decoder(layer,N)
- de_result = de(x,memory,source_mask, target_mask)
- print("de_result.shape : ",de_result.shape)
- print("de_result : ",de_result)
-
-
- # 输出测试
- d_model = 512
- vocab =1000
- x = de_result
-
- gen = Generator(d_mode=d_model,vocab_size=vocab)
- gen_result = gen(x)
- print("gen_result.shape :", gen_result.shape)
- print("gen_result: ", gen_result)
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/菜鸟追梦旅行/article/detail/372617
推荐阅读
相关标签

