
热门标签
热门文章
- 1基于matlab的船体三维模型仿真_三维海底建模matlab
- 2校园跑腿微信小程序的设计与实现(源码+LW)_微信小程序实现,界面设计
- 36.windows ubuntu 子系统 测序数据质量控制。
- 4Android官方资料--A/B System Updates_otapreopt_script
- 5区块链的基本介绍_区块链 csdn
- 6AI编程语言来了
- 7osgEarth地形压平案例 37. feature_elevation.earth_osg三维地形
- 8Recommend 4 popular Ai Chatbots--AigcToolify
- 9vs2017运行环境_玩转StyleGan:手把手教你安装并运行项目!
- 10Robotics: Aerial Robotics(空中机器人)笔记(一): 初识四旋翼无人机_无人机的状态估计与无人机定位的区别是什么
当前位置: article > 正文
TDNN时延神经网络
作者:菜鸟追梦旅行 | 2024-04-07 04:34:05
赞
踩
tdnn
近来在了解卷积神经网络(CNN),后来查到CNN是受语音信号处理中时延神经网络(TDNN)影响而发明的。本篇的大部分内容都来自关于TDNN原始文献【1】的理解和整理。该文写与1989年,在识别"B", "D", "G"三个浊音中得到98.5%的准确率,高于HMM的93.7%。是CNN的先驱。
普通神经网络识别音素
在讲TDNN之前先说说一般的神经网络的是怎样识别音素的吧。假设要识别三个辅音"B", "D", "G",那么我们可以设计这样的神经网络:
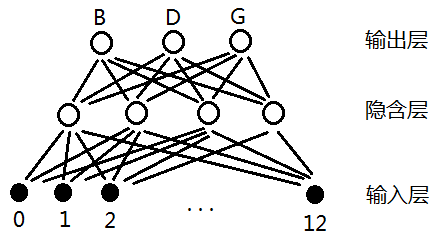
图1
其中输入0-12代表每一帧的特征向量(如13维MFCC特征)。那么有人可能会问了,即使在同一个因素"B"中,比如"B"包含20帧,那么第1帧与第15帧的MFCC特征也可能不一样。这个模型合理吗?事实上,"B"包含的20帧MFCC特征虽然有可能不一样,但变化不会太大,对于因素还是有一定区分度的,也就是说这个模型凑合凑合还能用,但效果不会非常好。GMM模型可以用这种模型来解释。
时延神经网络(TDNN)
考虑到上述模型只用了一帧特征,那么如果我们考虑更多帧,那么效果会不会好呢?
好
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/菜鸟追梦旅行/article/detail/376381
推荐阅读
相关标签

