
用pytorch实现DDPG算法_ddpg中actor-critic网络为什么要有目标网络和当前网络
赞
踩
DDPG算法原理的示意以及程序实现
- 基本原理与结构:
DDPG算法是Actor-Critic (AC) 框架下的一种在线式深度强化学习算法,因此算法内部包括Actor网络和Critic网络,每个网络分别遵从各自的更新法则进行更新,从而使得累计期望回报最大化。
DDPG算法将确定性策略梯度算法和DQN算法中的相关技术结合在一起,之前我们在讲DQN算法时,详细说明了其中的两个重要的技术:经验回放和目标网络。具体而言,DDPG算法主要包括以下三个关键技术:
(1)经验回放:智能体将得到的经验数据(s,a,r,s,)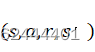 放入Replay Buffer中,更新网络参数时按照批量采样。
放入Replay Buffer中,更新网络参数时按照批量采样。
(2)目标网络:在Actor网络和Critic网络外再使用一套用于估计目标的目标 Actor网络和目标 Critic网络。在更新目标网络时,为了避免参数更新过快,采用软更新方式。
(3)噪声探索:确定性策略输出的动作为确定性动作,缺乏对环境的探索。在训练阶段,给Actor网络输出的动作加入噪声,从而让智能体具备一定的探索能力。
DDPG算法属于AC(Actor-critic)架构,且具有四个网络,即Critic当前网络、Critic目标网络和Actor的当前网络、Actor目标网络,Actor策略网络与DQN相似,但具有确定性策略,因此不需要ϵ−贪婪法这样的选择方法。而对经验回放池中采样的下一状态S′使用贪婪法选择动作A′,这部分工作由于用来估计目标Q值,因此可以放到Actor目标网络完成。Actor策略网络基于经验回放池提供的S′,A′计算目标Q值,Critic策略网络用于评估。而Critic目标网络计算出目标Q值一部分后,Critic当前网络会计算目标Q值,并进行网络参数的更新,并定期将网络参数复制到Critic目标网络。
简化的模型如下:
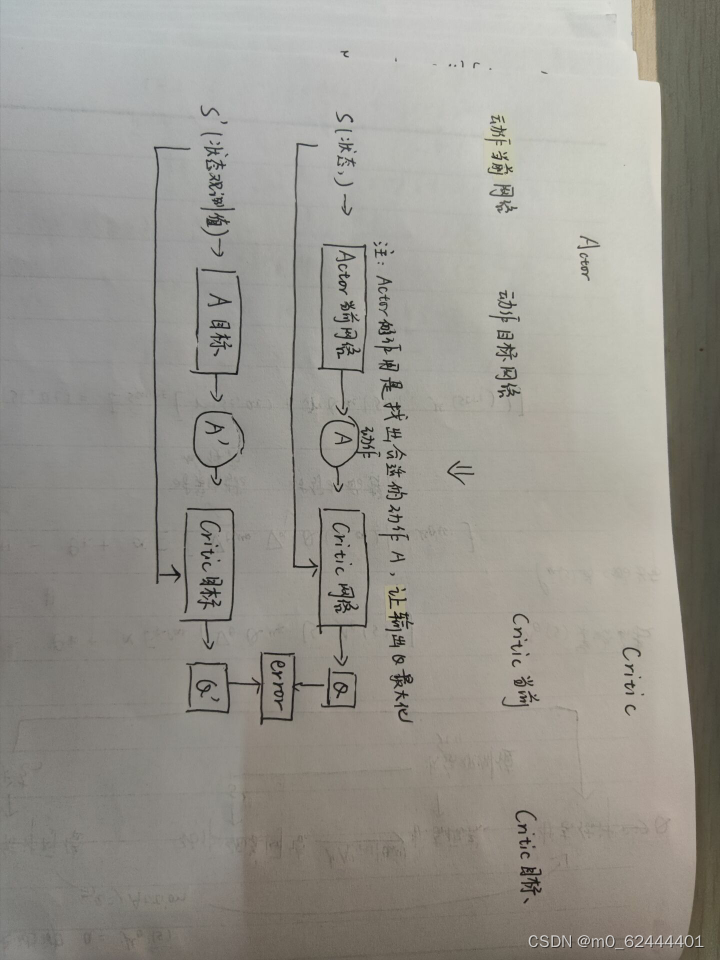
这四个网络的作用分别如下:
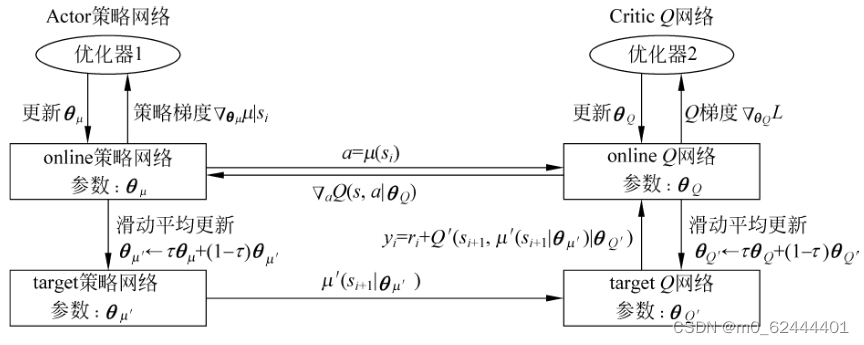
Actor当前网络:负责策略网络参数θ![]() 的迭代更新,即
的迭代更新,即
![]()
负责根据当前状态S选择当前动作A,用于和环境交互生成S',R![]() 。
。
Actor目标网络:负责根据经验回放池中采样的下一状态S'![]() (或叫st+1
(或叫st+1![]() )选择最优下一动作A'
)选择最优下一动作A'![]() 。网络参数θ'
。网络参数θ'![]() 定期从θ
定期从θ![]() 复制。用于预测下一状态的行为取值。
复制。用于预测下一状态的行为取值。
Critic当前网络:输出为当前状态 s![]() 和实际执行的动作 a
和实际执行的动作 a ![]() ,其输出首先用于计算损失函数,公式为:
,其输出首先用于计算损失函数,公式为:![]()
还用于 Actor 部分的参数更新,即:
![]()
Critic目标网络: 输入为下一状态st+1![]() 和 Actor 目标网络中输出的策略
和 Actor 目标网络中输出的策略![]() ,输出用于计算 TD 目标,即:
,输出用于计算 TD 目标,即:
![]()
详细结构图如下:

具体算法流程如下:

2 代码实现:
代码分为两个部分,一是Training,用来完成DDPG算法测试,二是DDPG_brain,实现算法网络结构。
Training的主要结构:①获取环境的参数②建立DDPG网路③还原环境参数,进行训④打印训练结果。
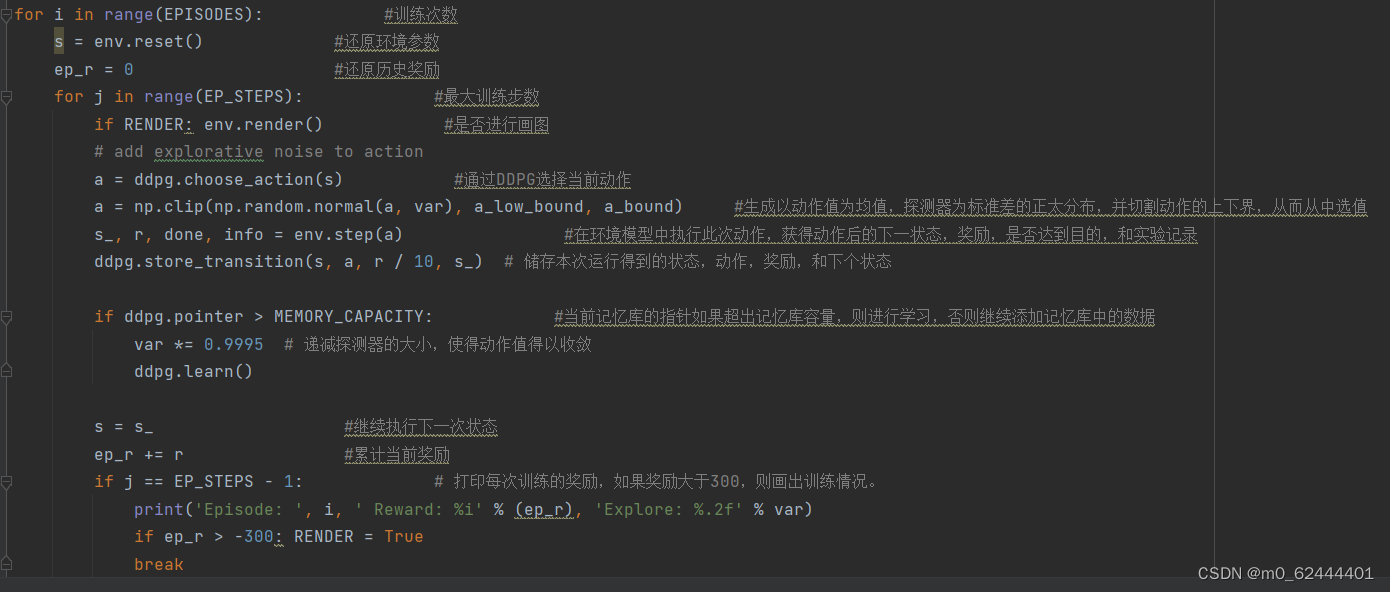
DDPG的主要结构:

__init__方法用来初始化网络模型,获取记忆库等
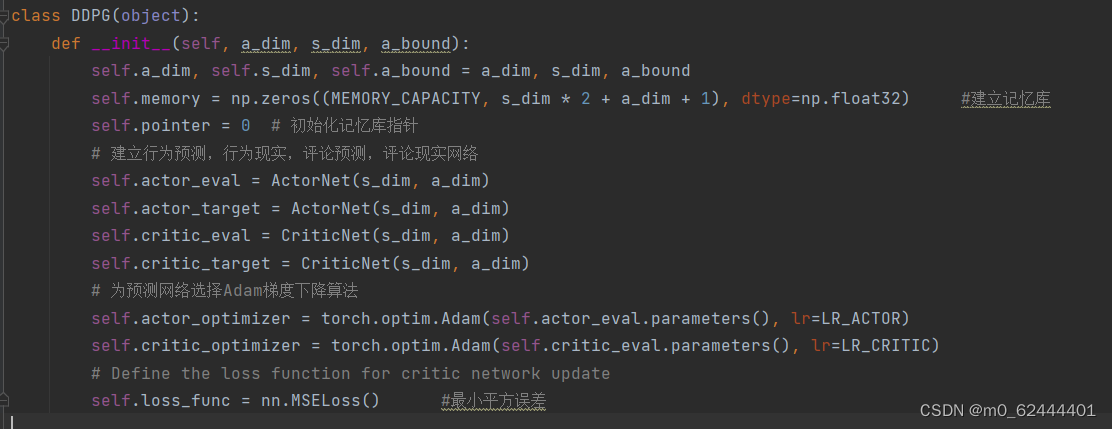
Store_transition用来存储训练结果。

Choose_action 用来选择行为

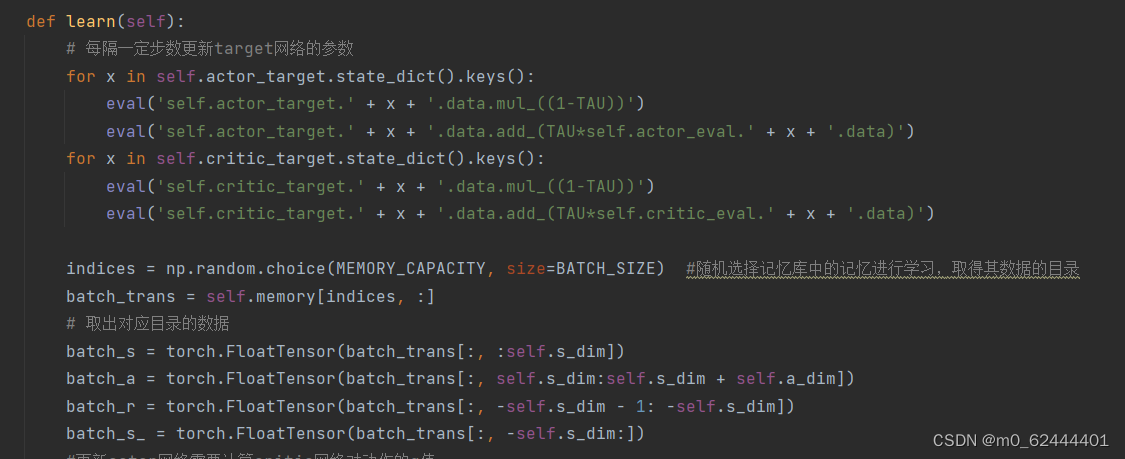
Learn进行网络的学习
 3.个人理解:
3.个人理解:
DDPG算法的目的是为了得到一个输出正确动作的神经网络,而这个网络无法获得动作后的收益,也就是无法获得机器学习中的y_label,所以需要critic网络对动作后的收益进行估计,也就是获得动作的q值,让action网络利用critic得到的q值进行学习,从而获得最大的q值(收益)。而critic网络如何知道当前动作会产生多大的q值(收益)呢,它需要知道当前动作从环境中获得了多少奖励,并且需要知道这个动作后的未来可能获得的奖励有多少(不能鼠目寸光),将这两种奖励以某种权重叠加得到q值告知action网络,从而完成对action网络的更新。那么如何更新critic网络的参数呢,也就是说如何让critic网络看清真正的q值呢,我们最初的训练好的网络什么都不知道,但它也会对action网络进行指导,也就是探索者机制,action网络进行更新后获得了更多的数据集,从而获得了一些q值,选择其中最大的q值作为奖励,将这些奖励加入到critic网络的更新中,就可以让critic网络明白什么是奖励。

