- 1chatgpt赋能python:Python选择指南:如何选择适合你的Python版本和框架
- 220170706wdVBA保存图片到本地API
- 3使用Java和Redis实现消息队列_java redis消息队列实现
- 4程序员转正述职报告/总结_员工述职表 前端开发工作不足怎么写
- 5太厉害了!突围金三银四面试季!Java校招面试指南_java大四校招
- 6如何进行函数的递归调用?
- 7工作协调能力如何提升?|智测优聘总结_如何提高组织协调能力
- 8mysql dump 转excel_使用mysqldump备份单表数据,并使用navicat导出单表中部分字段到excel...
- 9Jstat详解_jstat -gcutil
- 10画图工具总结
一、大数据技术基础——分布式文件系统HDFS
赞
踩
目录
3.3.NameNode维护文件:fsimage与editlog
1.引入
1.1.传统存储系统面临的难题
1.2.解决之道
2.Hadoop集群架构
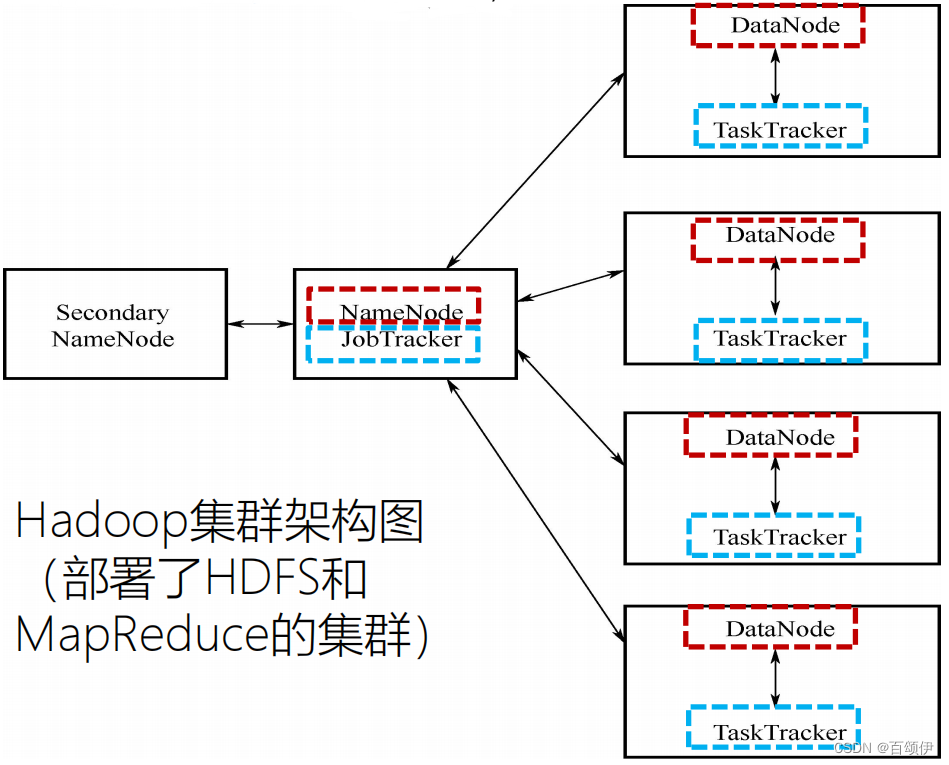
图2-1 Hadoop集群架构
NameNode和DataNode为存储节点(HDFS) JobTracker和TaskTracker为计算节点(MapReduce)
NameNode存储元数据,管理文件系统的命名空间(包括文件目录组织、属性维护、访问控制信息、文件操作日志记录、文件到块的映射信息、块当前所在的位置等),DataNode存储实际的数据。
JobTracker将任务拆分为多个小的任务,TaskTracker完成分配到的小任务。
3.HDFS 1.0
3.1.概念
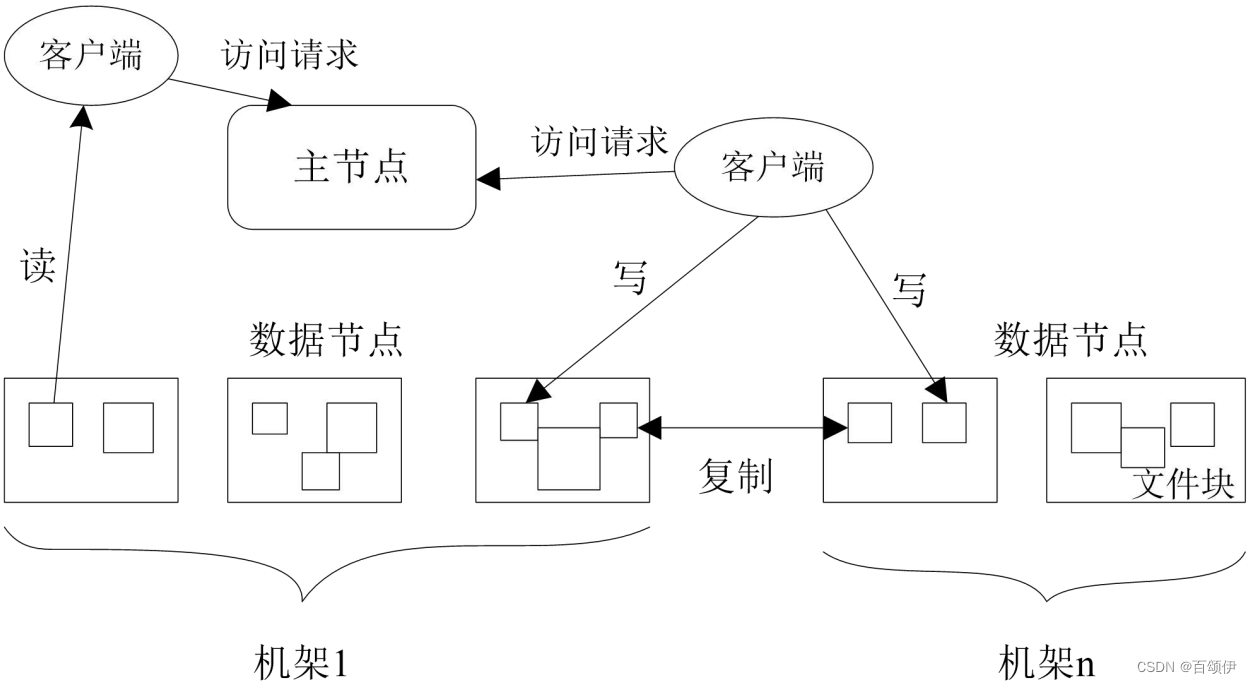
图3-1 HDFS的结构
3.2.Block块
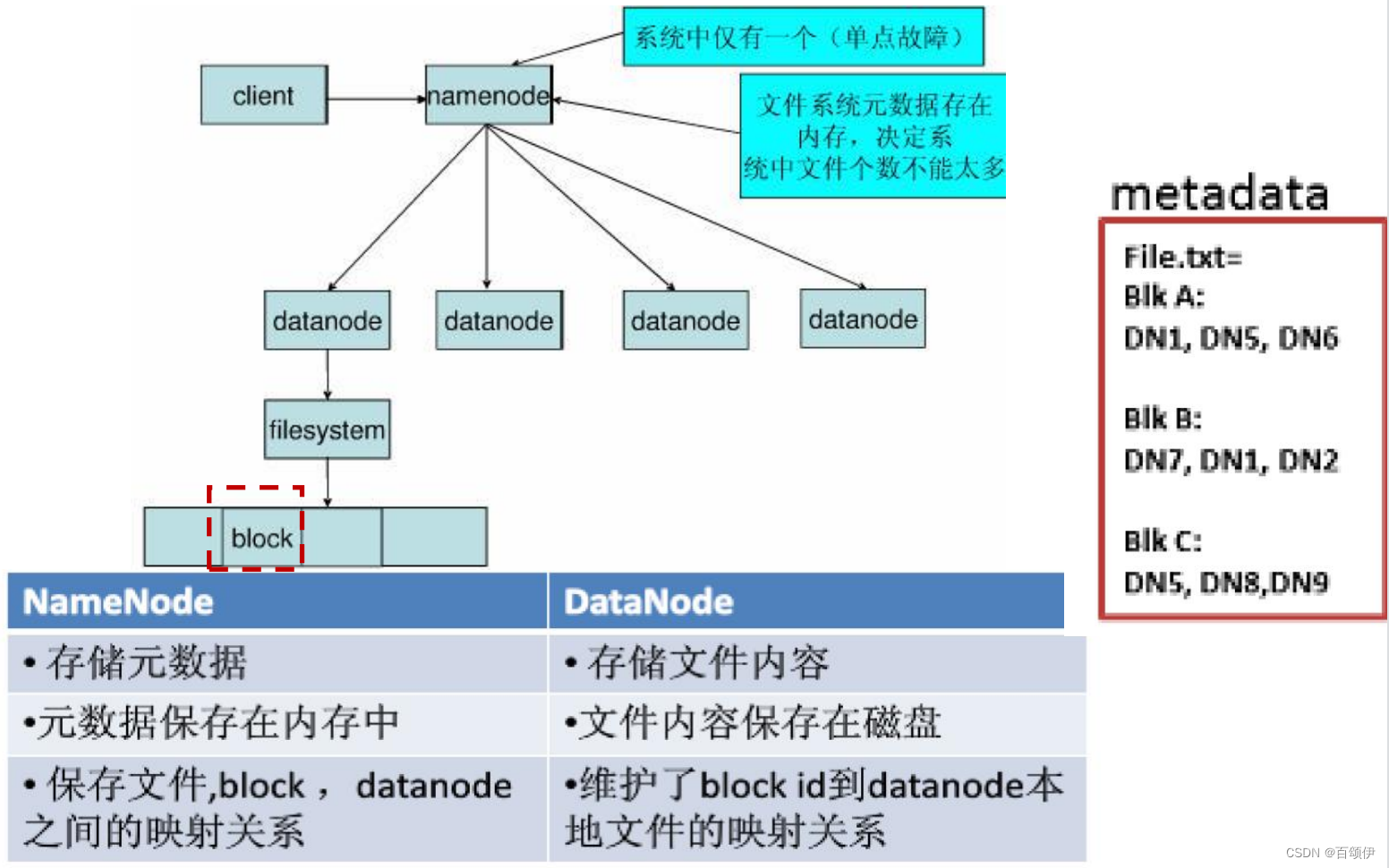
图3-2 名称节点和数据节点
3.3.NameNode维护文件:fsimage与editlog
NameNode存在内存中,当断电后就丢失,因此也要进行持久化存储。
fsimage就是在某一时刻,整个HDFS的快照,就是这个时刻HDFS上:所有的文件块和目录,分别的状态,位于哪些个DataNode ,各自的权限,各自的副本个数。
Editlog记录客户端对HDFS所有的更新操作,比如说移动数据,或者删除数据。
NameSpace镜像文件(fsimage),操作日志文件(edit log)这些信息被Cache在RAM内存中,这两个文件也会被持久化存储在本地硬盘。
比如,在1:00:00时刻记录了一个快照fsimage,那么从1:00:00到1:59:59期间的所有对HDFS更新的操作都会记录在editlog中。当NameNode发生故障时,重启服务器,Fsimage加上Editlog的数据就会恢复元数据。
3.4.DataNode
每个DataNode会周期性的向Namenode发送心跳消息,报告自己所在DataNode的使用状态和block信息。
- 如果在一定时间后还接受不到DN的心跳,那么NN认为DN已经宕机 ,这时候NN准备要把DN上的数据块进行重新的复制。
- DN还会向NN发送当前节点的使用状态以便NN进行DN选择策略。
两种策略类型:轮询(round-robin)和可用空间(available space ):
- DN向NN发送Block信息:有可能DN上的数据块会被修改,需告知NN会进行相应的同步修改。
3.5.HDFS1.0架构的局限性
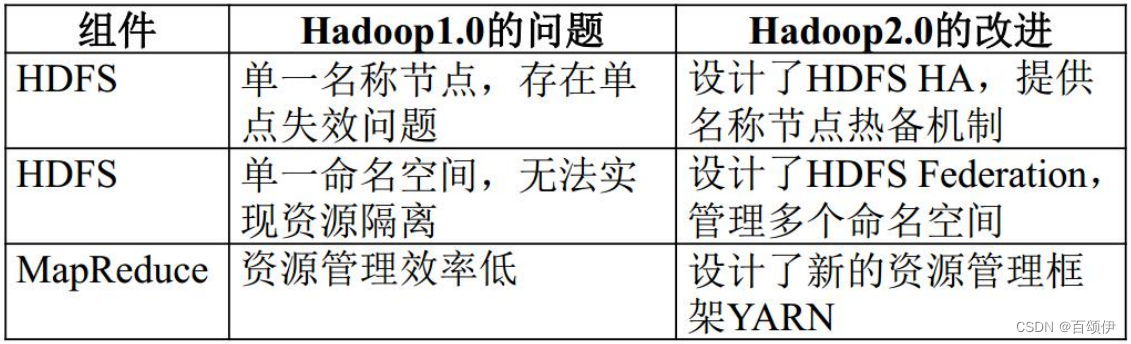
表3-1 HDFS 1.0和HDFS 2.0架构对比
3.6. SecondaryNamenode
- 长时间添加数据到editlog中,会导致该文件数据过大,效率降低。
- 恢复元数据时间过长。
- NameNode节点完成,效率过低。
因此,引入一个新的节点SecondaryNamenode,专门用于FsImage和editlog的合并。
- SecondaryNamenode不是NN的备份节点而是助手节点。通常,SecondaryNamenode 运行在一个单独的物理机上,因为合并操作需要占用大量的CPU时间以及和Namenode相当的内存。
- 触发SecondaryNameNode的CheckPoint的两个机制:定时时间到、edit log中数据写满;
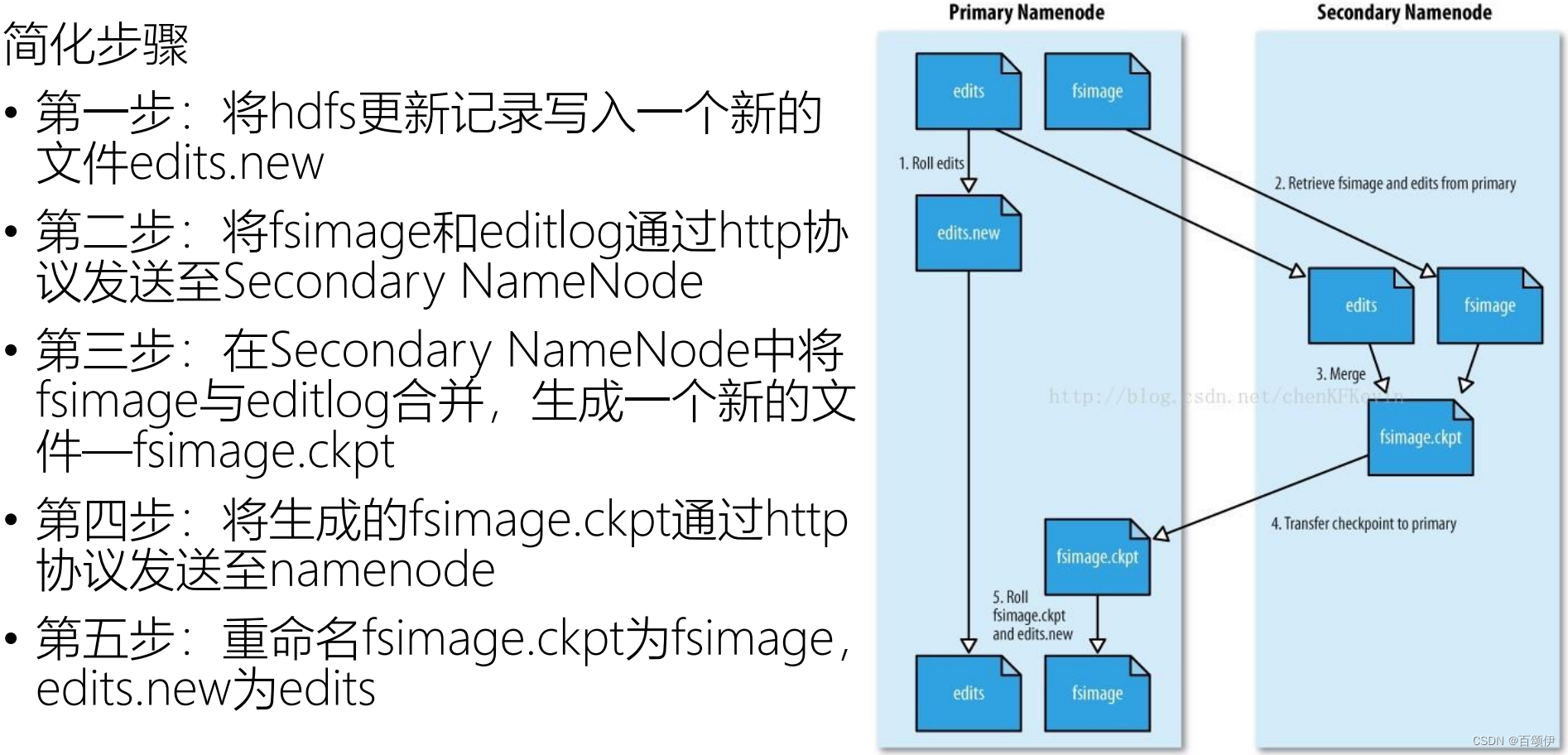
图3-3 SecondaryNamenode工作流程
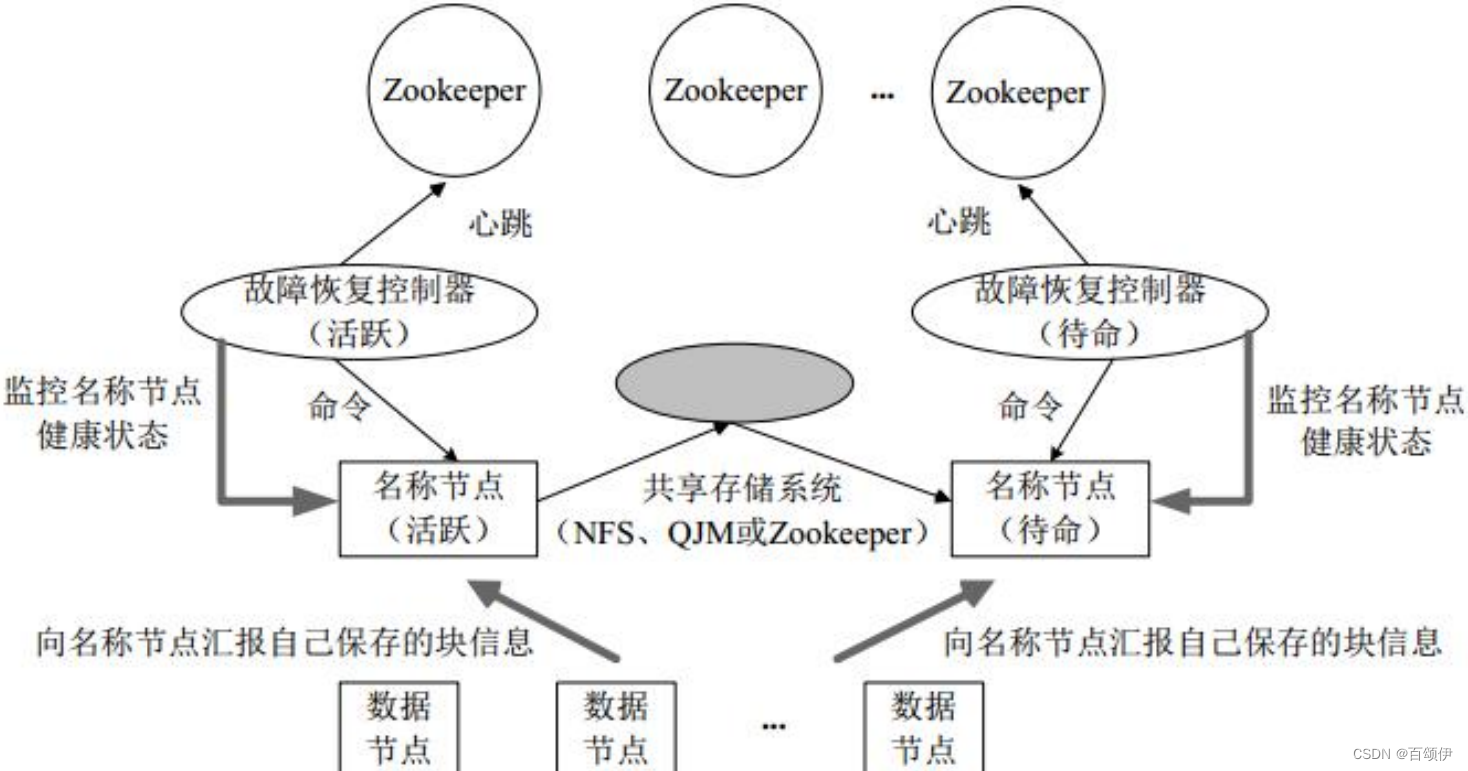
4.2.联邦架构
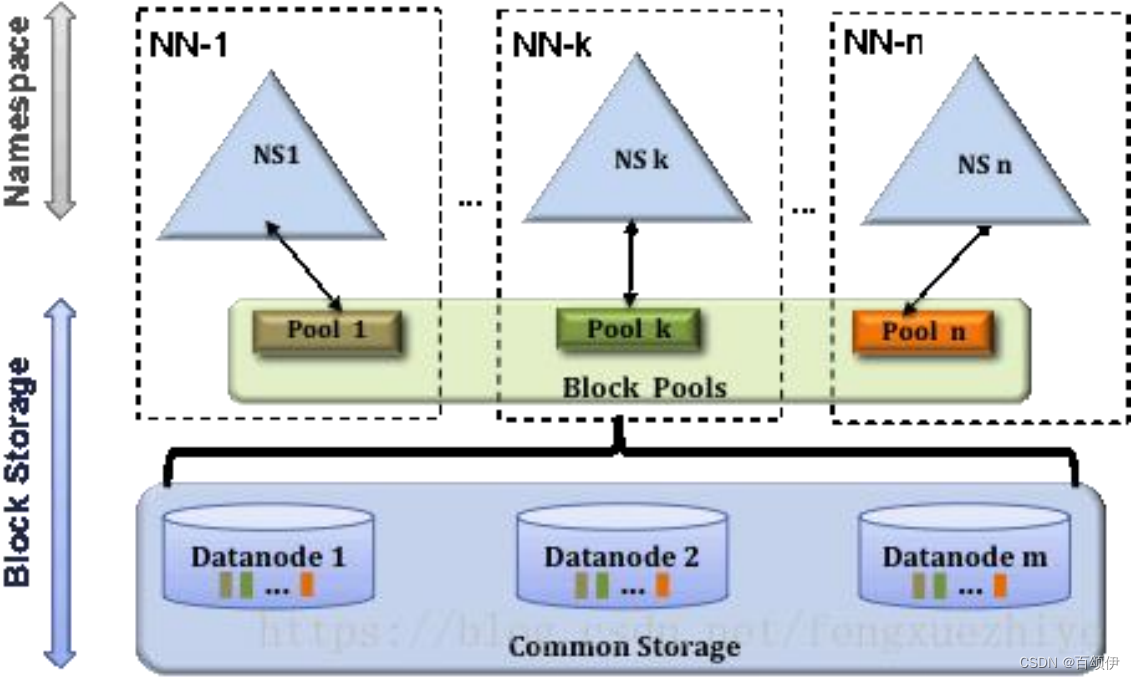
图4-2 HDFS联邦架构
5.HDFS读写入数据流程
5.1.写入数据流程
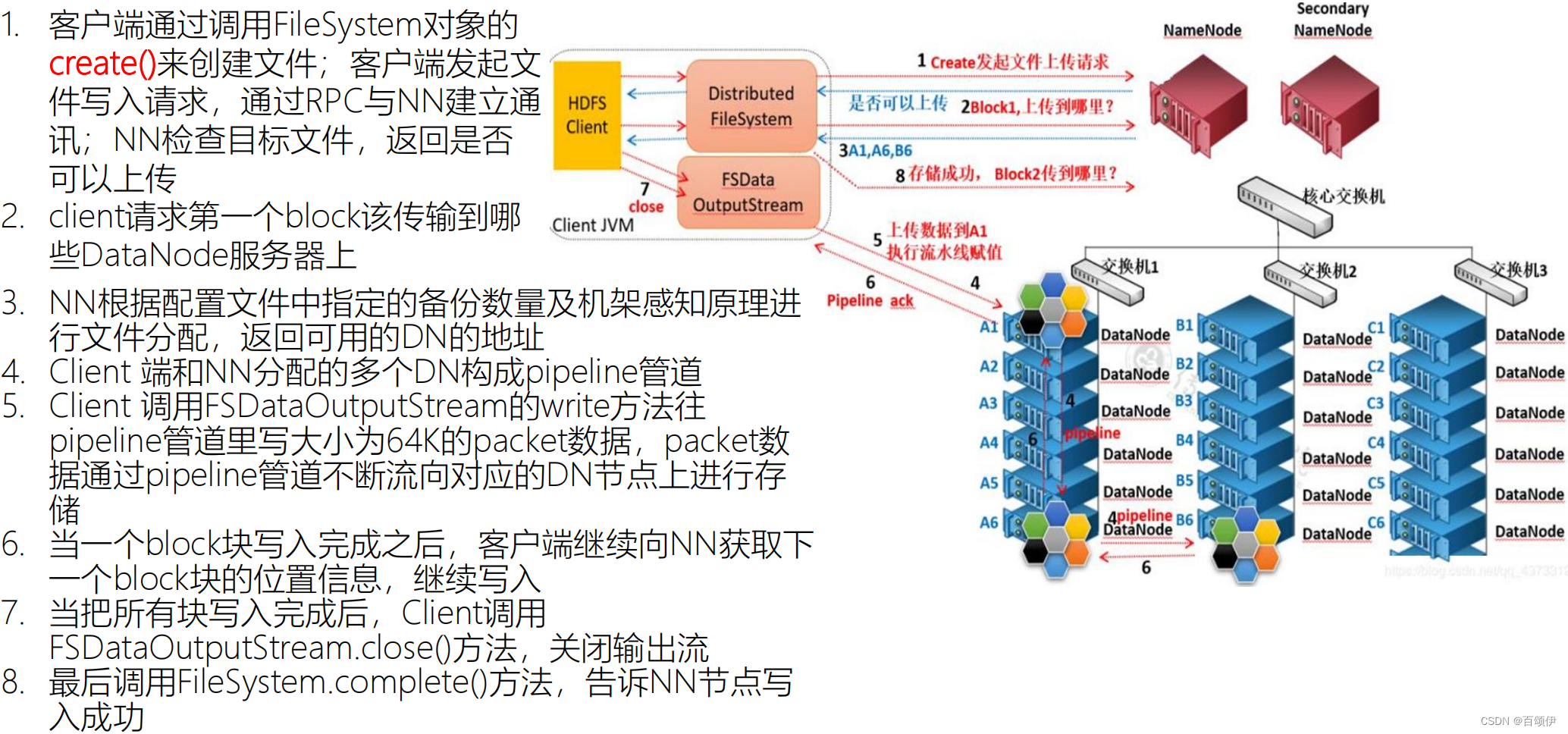
图5-1 HDFS写入数据流程
5.2.读取数据流程
而读取文件的时候,NN尽量让client读取离它最近的DataNode上的副本,降低带宽消耗和读取时延。
 图5-2 HDFS读取数据流程
图5-2 HDFS读取数据流程
5.3.HDFS的存储机制
5.3.1.HDFS数据副本放置策略
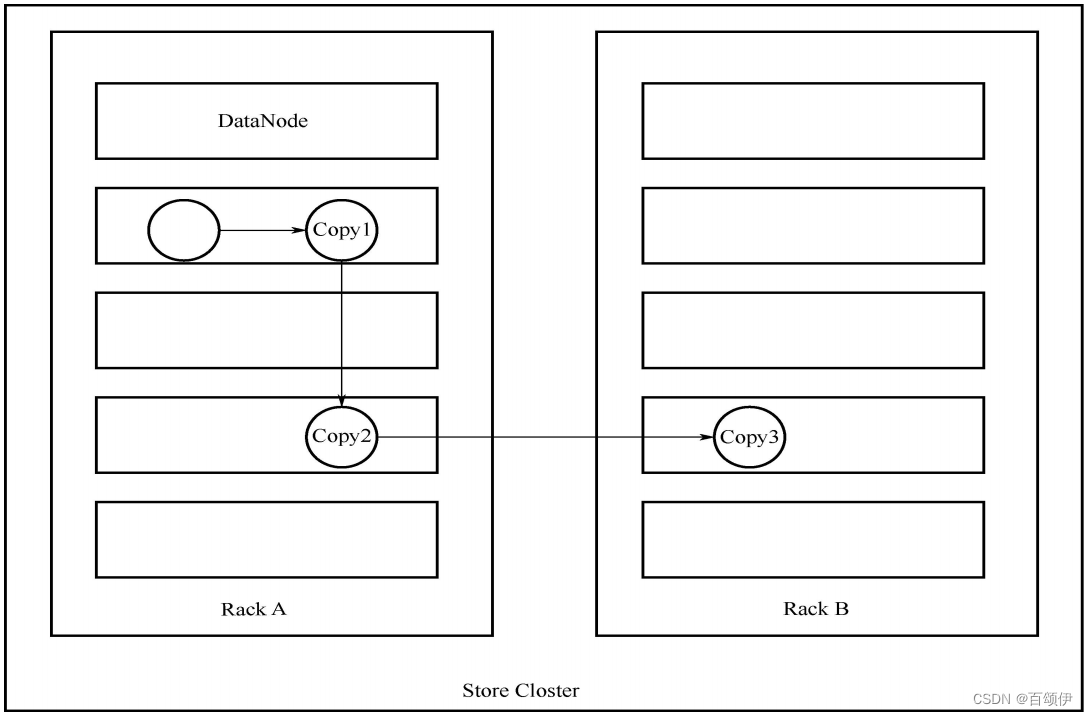
图5-3 当副本系数是3时的HDFS数据副本放置情况
5.3.2.HDFS的异构存储
Hadoop 从 2.4 后开始支持异构存储:
- 经常被计算或者读取的热数据为了保证性能需要存储在内存。
-
当一些数据变为冷数据后不经常会用到的数据会变为归档数据,可以使用大容量性能要差一些的存储设备来存储来减少存储成本。
- Lazy_persist:一个副本保存在内存RAM_DISK中,其余副本保存在磁盘DISK中;将副本写入RAM_DISK,然后缓慢的持久化到DISK。
-
ALL_SSD:所有副本都保存在SSD中。
-
Hot: 存储和计算都热; 所有副本保存在磁盘中,这也是默认的存储策略。
-
One_SSD:一个副本保存在SSD中,其余副本保存在磁盘DISK中。
-
Warm: 半冷半热; 一个副本保存在DISK磁盘上,其余副本保存在ARCHIVE归档存储上。
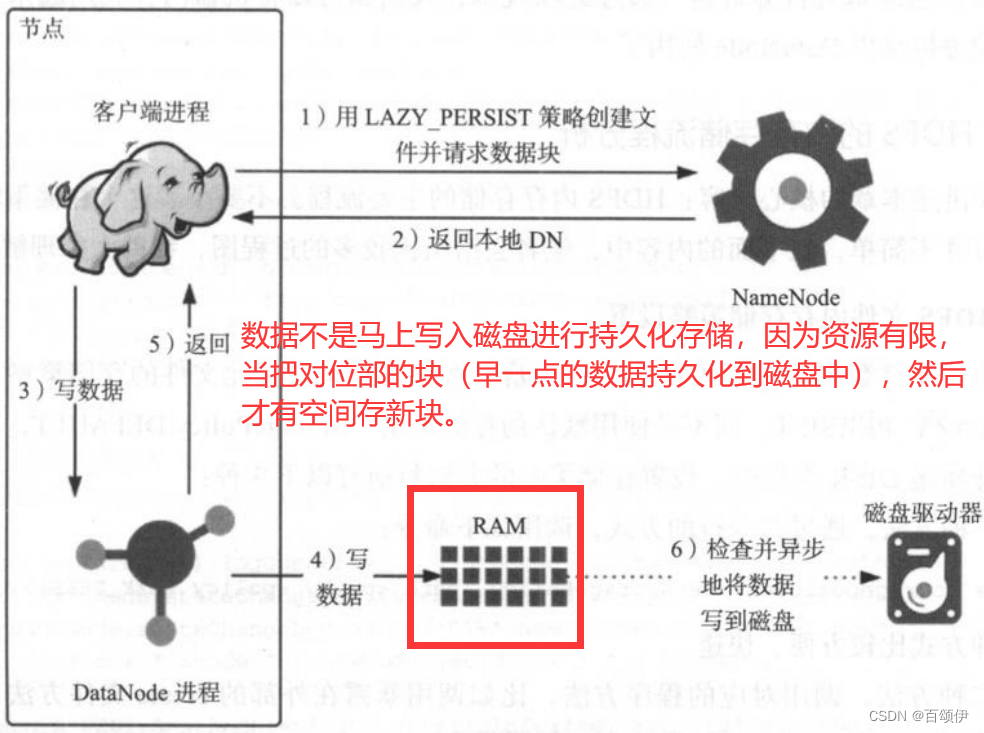 图5-4 HDFS的LAZY_PERSIST内存存储
图5-4 HDFS的LAZY_PERSIST内存存储
这样做的好处是,满足我们大部分情况是新数据更容易被读取使用。
6.HDFS常用命令
配置好Hadoop集群之后,可以通过浏览器登录“http://[NameNodeIP]:50070”访问HDFS文件系统。