
- 1【HMAC-SHA1算法以及工作原理】
- 2国外码农,Java大环境也那么卷吗?—— 俄罗斯、韩国、纽约、荷兰_国外为什么很少用java
- 3基于Arduino IDE开发的ESP8266(ESP-12F)项目4 ——中断及高级输入输出_esp8266 esp-12f
- 4向量数据库+知识图谱构建高效 RAG 系统
- 5深度学习每周学习总结P5(运动鞋识别)
- 6软件测试8月平均薪资出来了,我好像又被“平均”了…
- 7华为2021届实习面试(技术面+主管面)_华为隐私保护实习生技术面
- 8Word文档中实现:点击图片双击放大_word文档图片双击放大预览
- 9Node.js最佳实践--在2017如何成为一个更好的开发者_node开发实践
- 10eNSP基础实验交换机连接路由器(二层交换机和三层交换机)_ensp二层交换机是哪一个
Elasticsearch7.x——spring-boot-starter-data-elasticsearch详解
赞
踩
目录
spring-boot-starter-data-elasticsearch
1、概述
Spring Data Elasticsearch是Spring Data项目下的一个子模块。
查看 Spring Data的官网:http://projects.spring.io/spring-data/
Spring Data 的使命是给各种数据访问提供统一的编程接口,不管是关系型数据库(如MySQL),还是非关系数据库(如Redis),或者类似Elasticsearch这样的索引数据库。从而简化开发人员的代码,提高开发效率。
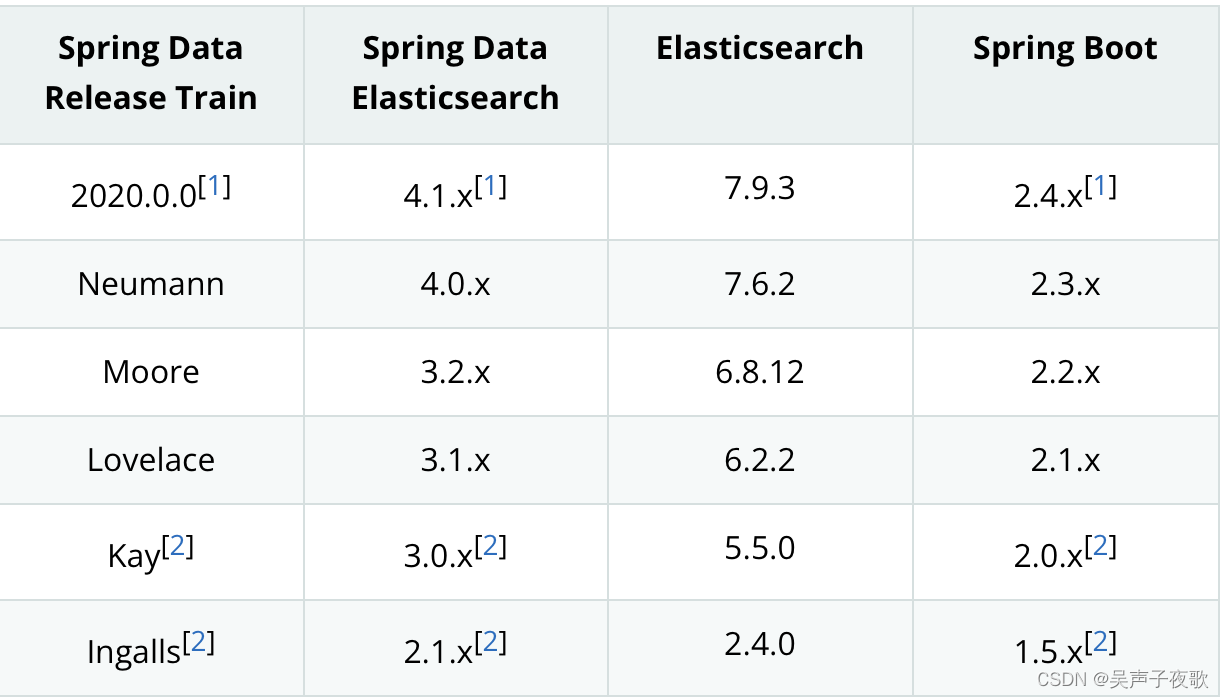
Spring Boot与Elasticsearch的对应版本:
引入依赖:
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.4.1</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
</dependencies>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
Elasticsearch的版本为7.16,所以选择2.4以上版本的SpringBoot。
2、配置
2.1、有密码
application.yml
es:
address: 127.0.0.1
port: 9200
scheme: http
username: elastic
password: 123456
- 1
- 2
- 3
- 4
- 5
- 6
@Configuration public class ElasticSearchConfig extends AbstractElasticsearchConfiguration { @Value("${es.address}") String address; @Value("${es.port}") Integer port; @Value("${es.scheme}") String scheme; @Value("${es.username}") String username; @Value("${es.password}") String password; @Override public RestHighLevelClient elasticsearchClient() { final CredentialsProvider credentialsProvider = new BasicCredentialsProvider(); credentialsProvider.setCredentials(AuthScope.ANY, new UsernamePasswordCredentials(username, password)); RestClientBuilder restClientBuilder = RestClient.builder(new HttpHost(address, port, scheme)) .setHttpClientConfigCallback(new RestClientBuilder.HttpClientConfigCallback() { @Override public HttpAsyncClientBuilder customizeHttpClient(HttpAsyncClientBuilder httpAsyncClientBuilder) { return httpAsyncClientBuilder.setDefaultCredentialsProvider(credentialsProvider); } }); RestHighLevelClient esClient = new RestHighLevelClient(restClientBuilder); return esClient; } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
2.1、无密码
@Configuration public class ElasticSearchConfig extends AbstractElasticsearchConfiguration { @Value("${es.address}") String address; @Value("${es.port}") Integer port; @Value("${es.scheme}") String scheme; @Value("${es.username}") String username; @Value("${es.password}") String password; @Override public RestHighLevelClient elasticsearchClient() { RestClientBuilder builder = null; builder = RestClient.builder(new HttpHost(address, port, scheme)); RestHighLevelClient client = new RestHighLevelClient(builder); return client; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
3、实体
@Document(indexName = "book", createIndex = true) public class Book { @Id @Field(type = FieldType.Long) private Long id; @Field(type = FieldType.Keyword, store = true) private String name; @Field(type = FieldType.Text, store = false, analyzer = "ik_smart") private String describe; @Field(type = FieldType.Text, analyzer = "ik_smart") private String author; @Field(type = FieldType.Double) private Double price; @Field(type = FieldType.Date, format = DateFormat.basic_date ) private Date createTime; public Long getId() { return id; } public void setId(Long id) { this.id = id; } public String getName() { return name; } public void setName(String name) { this.name = name; } public String getDescribe() { return describe; } public void setDescribe(String describe) { this.describe = describe; } public String getAuthor() { return author; } public void setAuthor(String author) { this.author = author; } public Double getPrice() { return price; } public void setPrice(Double price) { this.price = price; } public Date getCreateTime() { return createTime; } public void setCreateTime(Date createTime) { this.createTime = createTime; } @Override public String toString() { return "Book{" + "id=" + id + ", name='" + name + '\'' + ", describe='" + describe + '\'' + ", author='" + author + '\'' + ", price=" + price + ", createTime=" + createTime + '}'; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
@Document:作用在类,标记实体类为文档对象:indexName:索引名称,它可以包含一个SpEL模板表达式,如log-#{T(java.time.LocalDate).now().toString()}useServerConfiguration:创建索引时是否使用服务器端设置,默认false。shards:主分片数量,默认1.replicas:副本分片数量,默认1.refreshInterval:创建索引时的刷新间隔,默认值为“1s”。indexStoreType:创建索引时的索引存储类型,默认"fs"。createIndex:是否创建索引,默认true。versionType:版本管理,默认VersionType.EXTERNAL
@Id:作用在成员变量,标记一个字段作为id主键。@Transient:作用在成员变量,从Document中排除该字段。@GeoPointField:作用在成员变量,标记该字段为GeoPoint类型。@GeoShapeField:作用在成员变量,标记该字段为GeoShape类型。@Field:作用在成员变量,标记为文档的字段,并指定字段映射属性name/value:指定es中的field名称,默认为字段名称。type:字段类型,类型为枚举,默认为FieldType.AUTO。index:是否索引,默认为true。format:Date类型的格式化,枚举类型pattern:自定义格式化store:默认falsefielddata:默认falsesearchAnalyzer:默认""analyzer:默认""normalizer:默认""ignoreFields:默认{}includeInParent:默认falsecopyTo:默认{}ignoreAbove:默认-1coerce:默认truedocValues:默认trueignoreMalformed:默认falseindexOptions:默认IndexOptions.noneindexPhrases:默认falseindexPrefixes:默认{}norms:默认truenullValue:默认""positionIncrementGap:默认-1similarity:默认Similarity.DefaulttermVector:默认TermVector.nonescalingFactor:默认1maxShingleSize:默认-1storeNullValue:默认falsepositiveScoreImpact:默认trueenabled:默认trueeagerGlobalOrdinals:默认falsenullValueType:默认NullValueType.String
4、Respository
public interface BookRespository extends ElasticsearchRepository<Book, Long> {
}
- 1
- 2
- 3
4.1、接口层次关系
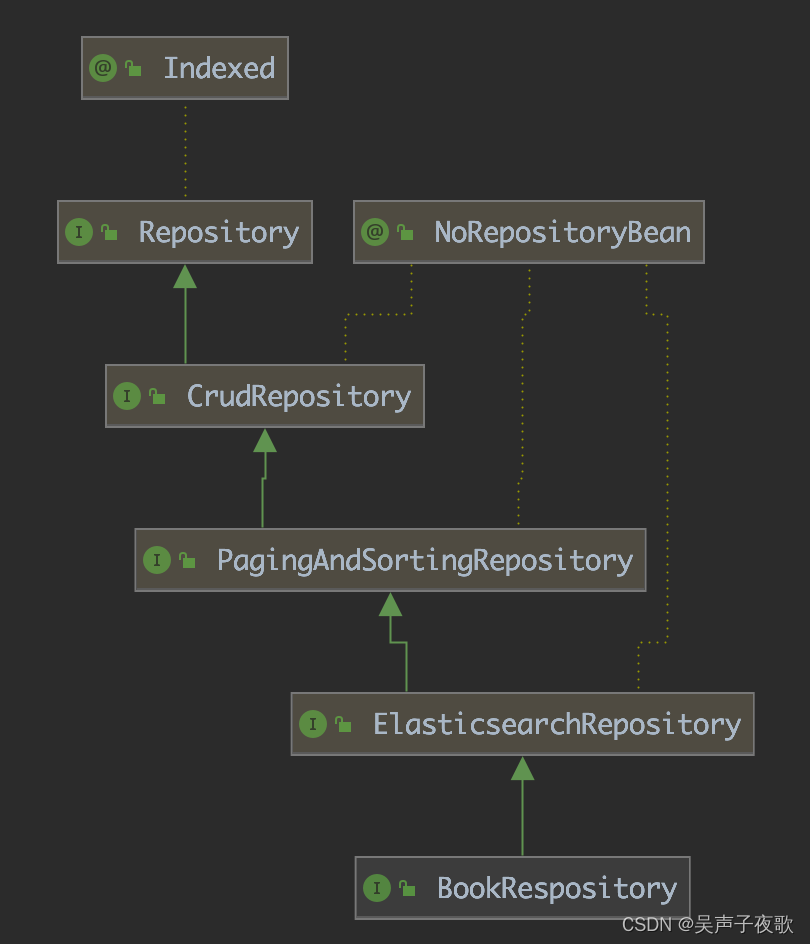
CrudRepository:
提供以Id为参数的CRUD功能:
@NoRepositoryBean public interface CrudRepository<T, ID> extends Repository<T, ID> { <S extends T> S save(S entity); <S extends T> Iterable<S> saveAll(Iterable<S> entities); Optional<T> findById(ID id); boolean existsById(ID id); Iterable<T> findAll(); Iterable<T> findAllById(Iterable<ID> ids); long count(); void deleteById(ID id); void delete(T entity); void deleteAll(Iterable<? extends T> entities); void deleteAll(); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
PagingAndSortingRepository:
在CRUD之上,提供分页和排序功能:
@NoRepositoryBean
public interface PagingAndSortingRepository<T, ID> extends CrudRepository<T, ID> {
Iterable<T> findAll(Sort sort);
Page<T> findAll(Pageable pageable);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
ElasticsearchRepository:
大部分方法在7.x中已经废弃:
@NoRepositoryBean public interface ElasticsearchRepository<T, ID> extends PagingAndSortingRepository<T, ID> { @Deprecated default <S extends T> S index(S entity) { return save(entity); } @Deprecated <S extends T> S indexWithoutRefresh(S entity); @Deprecated Iterable<T> search(QueryBuilder query); @Deprecated Page<T> search(QueryBuilder query, Pageable pageable); Page<T> search(Query searchQuery); Page<T> searchSimilar(T entity, @Nullable String[] fields, Pageable pageable); @Deprecated void refresh(); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
4.2、增删改查
4.2.1、新增
@Test
public void add() {
Book book = new Book();
book.setId(1l);
book.setAuthor("罗贯中");
book.setName("三国演义");
book.setPrice(42.56);
book.setCreateTime(new Date());
book.setDescribe("天下大势,分久必合,合久必分。");
bookRespository.save(book);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
4.2.2、修改
@Test
public void update() {
Book book = new Book();
book.setId(1l);
book.setAuthor("罗贯中");
book.setName("三国演义");
book.setPrice(55.55);
book.setCreateTime(new Date());
book.setDescribe("天下大势,分久必合,合久必分。");
bookRespository.save(book);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
4.2.3、批量新增
@Test public void add_all() { List<Book> list = new ArrayList<>(); Book book1 = new Book(); book1.setId(2l); book1.setAuthor("吴承恩"); book1.setName("西游记"); book1.setPrice(33.33); book1.setCreateTime(new Date()); book1.setDescribe("大师兄!师傅又丢了!"); list.add(book1); Book book2 = new Book(); book2.setId(3l); book2.setAuthor("曹雪芹"); book2.setName("红楼梦"); book2.setPrice(66.66); book2.setCreateTime(new Date()); book2.setDescribe("一朝春尽红颜老,花落人亡两不知。"); list.add(book2); Book book3 = new Book(); book3.setId(4l); book3.setAuthor("施耐庵"); book3.setName("水浒传"); book3.setPrice(35.22); book3.setCreateTime(new Date()); book3.setDescribe("招安"); list.add(book3); bookRespository.saveAll(list); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
4.2.4、删除
@Test
public void delete() {
bookRespository.deleteById(1l);
}
- 1
- 2
- 3
- 4
4.2.5、根据ID查询
@Test
public void findById() {
Optional<Book> optional = bookRespository.findById(2l);
System.out.println(optional.get());
}
- 1
- 2
- 3
- 4
- 5
4.2.6、查询所有
@Test
public void findAll() {
Iterable<Book> all = bookRespository.findAll();
all.forEach(System.out::println);
}
- 1
- 2
- 3
- 4
- 5
4.3、自定义方法
Spring Data 的另一个强大功能,是根据方法名称自动实现功能。
比如:方法名叫findByName,那么就是根据name查询,无需写实现类。
public interface BookRespository extends ElasticsearchRepository<Book, Long> {
/**
* 根据书名查询
* @param name
* @return
*/
List<Book> findByName(String name);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
@Test
public void findByName() {
List<Book> list = bookRespository.findByName("红楼梦");
list.forEach(System.out::println);
}
- 1
- 2
- 3
- 4
- 5
4.3.1、约定规则
当然,方法名称要遵循一定的约定:
And:findByNameAndPrice
{ "query": { "bool": { "must": [ { "query_string": { "query": "?", "fields": [ "name" ] } }, { "query_string": { "query": "?", "fields": [ "price" ] } } ] } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
Or:findByNameOrPrice
{ "query": { "bool": { "should": [ { "query_string": { "query": "?", "fields": [ "name" ] } }, { "query_string": { "query": "?", "fields": [ "price" ] } } ] } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
Is:findByName
{ "query": { "bool": { "must": [ { "query_string": { "query": "?", "fields": [ "name" ] } } ] } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
Not:findByNameNot
{ "query": { "bool": { "must_not": [ { "query_string": { "query": "?", "fields": [ "name" ] } } ] } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
Between:findByPriceBetween
{ "query": { "bool": { "must": [ { "range": { "price": { "from": ?, "to": ?, "include_lower": true, "include_upper": true } } } ] } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
LessThan:findByPriceLessThan
{ "query": { "bool": { "must": [ { "range": { "price": { "from": null, "to": ?, "include_lower": true, "include_upper": false } } } ] } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
LessThanEqual:findByPriceLessThanEqual
{ "query": { "bool": { "must": [ { "range": { "price": { "from": null, "to": ?, "include_lower": true, "include_upper": true } } } ] } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
GreaterThan:findByPriceGreaterThan
{ "query": { "bool": { "must": [ { "range": { "price": { "from": ?, "to": null, "include_lower": false, "include_upper": true } } } ] } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
GreaterThanEqual:findByPriceGreaterThan
{ "query": { "bool": { "must": [ { "range": { "price": { "from": ?, "to": null, "include_lower": true, "include_upper": true } } } ] } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
Before:findByPriceBefore
{ "query": { "bool": { "must": [ { "range": { "price": { "from": null, "to": ?, "include_lower": true, "include_upper": true } } } ] } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
After:findByPriceAfter
{ "query": { "bool": { "must": [ { "range": { "price": { "from": ?, "to": null, "include_lower": true, "include_upper": true } } } ] } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
Like:findByNameLike
{ "query": { "bool": { "must": [ { "query_string": { "query": "?*", "fields": [ "name" ] }, "analyze_wildcard": true } ] } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
StartingWith:findByNameStartingWith
{ "query": { "bool": { "must": [ { "query_string": { "query": "?*", "fields": [ "name" ] }, "analyze_wildcard": true } ] } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
EndingWith:findByNameEndingWith
{ "query": { "bool": { "must": [ { "query_string": { "query": "*?", "fields": [ "name" ] }, "analyze_wildcard": true } ] } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
Contains/Containing:findByNameContaining
{ "query": { "bool": { "must": [ { "query_string": { "query": "*?*", "fields": [ "name" ] }, "analyze_wildcard": true } ] } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
In(when annotated as FieldType.Keyword):findByNameIn(Collection<String>names)
{ "query": { "bool": { "must": [ { "bool": { "must": [ { "terms": { "name": [ "?", "?" ] } } ] } } ] } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
In:findByNameIn(Collection<String>names)
{ "query": { "bool": { "must": [ { "query_string": { "query": "\"?\" \"?\"", "fields": [ "name" ] } } ] } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
NotIn(when annotated as FieldType.Keyword):findByNameNotIn(Collection<String>names)
{ "query": { "bool": { "must": [ { "bool": { "must_not": [ { "terms": { "name": [ "?", "?" ] } } ] } } ] } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
NotIn:findByNameNotIn(Collection<String>names)
{ "query": { "bool": { "must": [ { "query_string": { "query": "NOT(\"?\" \"?\")", "fields": [ "name" ] } } ] } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
Near:findByStoreNear
Not Supported Yet !
- 1
True:findByAvailableTrue
{ "query": { "bool": { "must": [ { "query_string": { "query": "true", "fields": [ "available" ] } } ] } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
False:findByAvailableFalse
{ "query": { "bool": { "must": [ { "query_string": { "query": "false", "fields": [ "available" ] } } ] } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
OrderBy:findByAvailableTrueOrderByNameDesc
{ "query": { "bool": { "must": [ { "query_string": { "query": "true", "fields": [ "available" ] } } ] } }, "sort": [ { "name": { "order": "desc" } } ] }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
4.3.2、示例
按照价格区间查询:
List<Book> findByPriceBetween(Double from, Double to);
- 1
@Test
public void findByPriceBetween() {
List<Book> list = bookRespository.findByPriceBetween(20.00, 60.00);
list.forEach(System.out::println);
}
- 1
- 2
- 3
- 4
- 5
查询书名为三国演义或红楼梦,或者作者为吴承恩的书籍:
List<Book> findByNameInOrAuthorIn(List<String> names, List<String> authors);
- 1
@Test
public void findByNameInOrAuthorIn() {
List<String> names = new ArrayList<>();
names.add("三国演义");
names.add("红楼梦");
List<String> authors = new ArrayList<>();
authors.add("吴承恩");
List<Book> list = bookRespository.findByNameInOrAuthorIn(names, authors);
list.forEach(System.out::println);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
4.4、QueryBuilder查询(4.0后废弃)
基本方式是使用Respository的各种search方法,然后用QueryBuilder构建查询。4.0后已经废弃,推荐使用注解查询、ElasticsearchRestTemlate或者上面的方法名查询。
@Test
public void bash_search() {
MatchQueryBuilder builder = QueryBuilders.matchQuery("author", "吴承恩");
Iterable<Book> books = bookRespository.search(builder);
books.forEach(System.out::println);
}
- 1
- 2
- 3
- 4
- 5
- 6
4.4.1、分页查询
@Test public void page_search() { NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder(); queryBuilder.withQuery(QueryBuilders.matchAllQuery()); //初始化分页参数 int page = 0; int size = 2; queryBuilder.withPageable(PageRequest.of(0, 2)); Page<Book> books = bookRespository.search(queryBuilder.build()); //总条数 System.out.println(books.getTotalElements()); //总页数 System.out.println(books.getTotalPages()); //每页大小 System.out.println(books.getSize()); //当前页 System.out.println(books.getNumber()); //数据 books.getContent().forEach(System.out::println); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
4.4.2、排序查询
@Test
public void sort_search() {
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
queryBuilder.withQuery(QueryBuilders.matchAllQuery());
queryBuilder.withSort(SortBuilders.fieldSort("price").order(SortOrder.ASC));
Page<Book> books = bookRespository.search(queryBuilder.build());
books.getContent().forEach(System.out::println);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
4.4.3、桶聚合
@Test public void bucket_agg() { NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder(); //不查询任何字段 queryBuilder.withSourceFilter(new FetchSourceFilter(new String[]{""}, null)); //添加一个terms聚合,名称为name_agg,字段为name queryBuilder.addAggregation(AggregationBuilders.terms("name_agg").field("name")); //查询 AggregatedPage<Book> books = (AggregatedPage<Book>) bookRespository.search(queryBuilder.build()); //解析 ParsedStringTerms agg= (ParsedStringTerms) books.getAggregation("name_agg"); List<? extends Terms.Bucket> buckets = agg.getBuckets(); for (Terms.Bucket bucket : buckets) { System.out.println(bucket.getKeyAsString() + ":" + bucket.getDocCount()); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
4.4.4、嵌套聚合
@Test public void avg_agg() { NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder(); //不查询任何字段 queryBuilder.withSourceFilter(new FetchSourceFilter(new String[]{""}, null)); //添加一个terms聚合,名称为name_agg,字段为name queryBuilder.addAggregation( AggregationBuilders.terms("name_agg").field("name") .subAggregation(AggregationBuilders.avg("price_avg").field("price")) ); //查询 AggregatedPage<Book> books = (AggregatedPage<Book>) bookRespository.search(queryBuilder.build()); //获取聚合 ParsedStringTerms name_agg = (ParsedStringTerms) books.getAggregation("name_agg"); //获取桶 List<? extends Terms.Bucket> buckets = name_agg.getBuckets(); //遍历 for (Terms.Bucket bucket : buckets) { System.out.println(bucket.getKeyAsString() + ":" + bucket.getDocCount()); //获取子聚合 ParsedAvg price_avg = (ParsedAvg) bucket.getAggregations().asMap().get("price_avg"); System.out.println(price_avg.getValue()); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
4.4.5、其他查询
等值查询:
QueryBuilders.termQuery("name", "小李")
- 1
范围查询:
QueryBuilders.rangeQuery("age").gte(18).lte(50);
- 1
模糊查询:
QueryBuilders.boolQuery().must(QueryBuilders.wildcardQuery("name", "*小李*"));
- 1
多条件查询:
QueryBuilders.boolQuery()
.must(QueryBuilders.termQuery("name", "小李"))
.must(QueryBuilders.rangeQuery("age").gte(10).lte(50));
- 1
- 2
- 3
must查询:
List<String> list = Arrays.asList("北京", "上海", "杭州");
QueryBuilders.boolQuery()
.must(QueryBuilders.termQuery("name", "李明"))
.must(QueryBuilders.termsQuery("address", list))
.must(QueryBuilders.rangeQuery("age").gte(10).lte(50));
- 1
- 2
- 3
- 4
- 5
should查询:
QueryBuilders.boolQuery()
.should(QueryBuilders.wildcardQuery("name", "*小李*"))
.should(QueryBuilders.termQuery("address", "北京"));
- 1
- 2
- 3
bool组合查询:
QueryBuilders.boolQuery()
.must(QueryBuilders.termQuery("sex", "男"))
.should(QueryBuilders.wildcardQuery("name", "*小李*"))
.should(QueryBuilders.termQuery("address", "北京"))
.minimumShouldMatch(1);
- 1
- 2
- 3
- 4
- 5
有值查询:
QueryBuilders.boolQuery()
.must(QueryBuilders.existsQuery("name"))
.mustNot(QueryBuilders.existsQuery("tag"));
- 1
- 2
- 3
4.5、注解查询
4.5.1、@Query
使用@Query注解查询,设置为注释参数的String必须是有效的Elasticsearch JSON查询。
JSON字符串中使用?idnex进行参数占位,?表示该位置为参数,index表示参数下标,从0开始。
根据作者查询:
/** * { * "query": { * "match": { * "author": "曹雪芹" * } * } * } * @param name * @return */ @Query("{\n" + " \"match\": {\n" + " \"author\": \"?0\"\n" + " }\n" + "}") List<SearchHit<Book>> listBookByName(String name);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
@Test
public void annotation_test1() {
List<SearchHit<Book>> list = bookRespository.listBookByName("曹雪芹");
for (SearchHit<Book> hit : list) {
System.out.println(hit.getScore());
System.out.println(hit.getContent());
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
根据价格范围查询:
/** * { * "query": { * "range": { * "price": { * "gte": 10, * "lte": 40 * } * } * } * } * @param from * @param to * @return */ @Query("{\n" + " \"range\": {\n" + " \"price\": {\n" + " \"gte\": \"?0\",\n" + " \"lte\": \"?1\"\n" + " }\n" + " }\n" + "}") List<SearchHit<Book>> listBookByPriceRange(Double from, Double to);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
@Test
public void annotation_test2() {
List<SearchHit<Book>> list = bookRespository.listBookByPriceRange(10d, 40d);
for (SearchHit<Book> hit : list) {
System.out.println(hit.getScore());
System.out.println(hit.getContent());
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
4.5.2、@Highlight
@Highlight注解用于设置高亮查询,子注解@HighlightField用于指定高亮字段,@HighlightParameters用于配置高亮选项。
根据作者查询,并高亮作者:
/** * { * "query": { * "match": { * "author": "罗贯中" * } * }, * "highlight": { * "pre_tags": ["<span style='color:red'>"], * "post_tags": ["</span>"], * "fields": { * "author": {} * } * } * } */ @Query("{\n" + " \"match\": {\n" + " \"author\": \"?0\"\n" + " }\n" + "}") @Highlight( fields = { @HighlightField(name = "author") }, parameters = @HighlightParameters(preTags = "<span style='color:red'>", postTags = "</span>") ) List<SearchHit<Book>> listBookByNameHighlight(String name);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
@Test
public void annotation_highlight() {
List<SearchHit<Book>> list = bookRespository.listBookByNameHighlight("罗贯中");
for (SearchHit<Book> hit : list) {
System.out.println(hit.getScore());
System.out.println(hit.getContent());
List<String> hitHighlightField = hit.getHighlightField("author");
hitHighlightField.forEach(System.out::println);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
1.2039728
Book{id=1, name='三国演义', describe='天下大势,分久必合,合久必分。', author='罗贯中', price=55.55, createTime=Fri Oct 27 08:00:00 CST 2023}
<span style='color:red'>罗贯中</span>
- 1
- 2
- 3
5、ElasticsearchOperations接口
ElasticsearchOperations是Spring Data Elasticsearch抽象出来的操作接口,有两个实现类:
- ElasticsearchTemplate
- ElasticsearchRestTemplate
5.1、ElasticsearchTemplate
ElasticsearchTemplate底层依赖于Transport Client,在4.0版本后已被标记为废弃。
配置:
@Configuration public class TransportClientConfig extends ElasticsearchConfigurationSupport { @Bean public Client elasticsearchClient() throws UnknownHostException { Settings settings = Settings.builder().put("cluster.name", "elasticsearch").build(); TransportClient client = new PreBuiltTransportClient(settings); client.addTransportAddress(new TransportAddress(InetAddress.getByName("127.0.0.1"), 9300)); return client; } @Bean(name = {"elasticsearchOperations", "elasticsearchTemplate"}) public ElasticsearchTemplate elasticsearchTemplate() throws UnknownHostException { return new ElasticsearchTemplate(elasticsearchClient()); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
5.2、ElasticsearchRestTemplate
ElasticsearchRestTemplate底层依赖于High Level REST Client,所以配置也使用AbstractElasticsearchConfiguration,无须再次配置。
ElasticsearchRestTemplate中定义了一系列方法:
IndexOperations:定义索引级别上的操作,如创建或删除索引
public IndexOperations indexOps(Class<?> clazz);
public IndexOperations indexOps(IndexCoordinates index);
- 1
- 2
- 3
DocumentOperations:定义了基于实体id存储、更新和检索实体的操作。
public String doIndex(IndexQuery query, IndexCoordinates index); public <T> T get(String id, Class<T> clazz, IndexCoordinates index); public <T> List<T> multiGet(Query query, Class<T> clazz, IndexCoordinates index); protected boolean doExists(String id, IndexCoordinates index); public void bulkUpdate(List<UpdateQuery> queries, BulkOptions bulkOptions, IndexCoordinates index); public String delete(String id, @Nullable String routing, IndexCoordinates index); public void delete(Query query, Class<?> clazz, IndexCoordinates index); @Deprecated public void delete(DeleteQuery deleteQuery, IndexCoordinates index); public UpdateResponse update(UpdateQuery query, IndexCoordinates index); public List<IndexedObjectInformation> doBulkOperation(List<?> queries, BulkOptions bulkOptions, IndexCoordinates index);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
SearchOperations:定义使用查询搜索多个实体的操作
public long count(Query query, @Nullable Class<?> clazz, IndexCoordinates index);
public <T> SearchHits<T> search(Query query, Class<T> clazz, IndexCoordinates index);
public <T> SearchScrollHits<T> searchScrollStart(long scrollTimeInMillis, Query query, Class<T> clazz, IndexCoordinates index);
public <T> SearchScrollHits<T> searchScrollContinue(@Nullable String scrollId, long scrollTimeInMillis, Class<T> clazz, IndexCoordinates index);
public void searchScrollClear(List<String> scrollIds);
public SearchResponse suggest(SuggestBuilder suggestion, IndexCoordinates index);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
5.3、返回值类型
- SearchHit<T>
IdScoreSort ValuesHighlight fieldsInner hits(this is an embedded SearchHits object containing eventually returned inner hits)- The retrieved entity of type
- SearchHits<T>:
Number of total hitsTotal hits relationMaximum scoreA list of SearchHit<T> objectsReturned aggregations
- SearchPage<T>: Defines a Spring Data Page that contains a SearchHits element and can be used for paging access using repository methods.
- SearchScrollHits<T>: Returned by the low level scroll API functions in ElasticsearchRestTemplate, it enriches a SearchHits with the Elasticsearch scroll id.
- SearchHitsIterator<T>: An Iterator returned by the streaming functions of the SearchOperations interface.
5.4、IndexOperations(索引操作)
5.4.1、初始化索引
@Test public void createIndex() { IndexOperations indexOperations = elasticsearchRestTemplate.indexOps(Student.class); //是否存在 if (!indexOperations.exists()) { //根据绑定的实体类注解获取设置信息 Document settings = indexOperations.createSettings(); //创建索引 indexOperations.create(settings); //或者直接调用无参的create(),内部自动创建settings // indexOperations.create(); //根据实体类注解获取映射关系 Document mapping = indexOperations.createMapping(); //将mapping添加到索引中 indexOperations.putMapping(mapping); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
5.4.2、删除索引
@Test
public void deleteIndex() {
IndexOperations indexOperations = elasticsearchRestTemplate.indexOps(Student.class);
if (indexOperations.exists()) {
indexOperations.delete();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
5.4.3、获取索引信息
@Test public void createIndex() { IndexOperations indexOperations = elasticsearchRestTemplate.indexOps(Student.class); //是否存在 if (!indexOperations.exists()) { //根据绑定的实体类注解获取设置信息 Document settings = indexOperations.createSettings(); //创建索引 indexOperations.create(settings); //或者直接调用无参的create(),内部自动创建settings // indexOperations.create(); //根据实体类注解获取映射关系 Document mapping = indexOperations.createMapping(); //将mapping添加到索引中 indexOperations.putMapping(mapping); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
5.4.4、别名操作
@Test public void aliasTest() { IndexOperations indexOperations = elasticsearchRestTemplate.indexOps(Student.class); //一系列别名操作 AliasActions actions = new AliasActions(); //新增别名 actions.add( new AliasAction.Add( AliasActionParameters.builder() .withAliases("a") .withIndices("student") .build()) ); //删除别名 actions.add( new AliasAction.Remove( AliasActionParameters.builder() .withAliases("a") .withIndices("student") .build()) ); boolean flag = indexOperations.alias(actions); System.out.println(flag); //通过别名查询,返回key为包含该别名的index的map Map<String, Set<AliasData>> map = indexOperations.getAliases("a"); Set<AliasData> data = map.get("student"); data.forEach(e -> System.out.println(e.getAlias())); //通过index查询,返回返回key为包含该别名的index的map Map<String, Set<AliasData>> map1 = indexOperations.getAliasesForIndex("student"); Set<AliasData> data1 = map1.get("student"); data1.forEach(e -> System.out.println(e.getAlias())); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
5.4.5、索引模板操作
@Test public void templateTest() { IndexOperations indexOperations = elasticsearchRestTemplate.indexOps(Student.class); //新增模板 PutTemplateRequest request = PutTemplateRequest.builder("my-template", "pattern1", "pattern2") .withSettings( Document.create().append("index.number_of_shards", 3) ) .withMappings( Document.parse("{\n" + " \"_source\": {\n" + " \"enabled\": false\n" + " }\n" + "}") ) .withOrder(1) .withVersion(1) .build(); indexOperations.putTemplate(request); //获取模板 if (indexOperations.existsTemplate("my-template")) { TemplateData template = indexOperations.getTemplate("my-template"); System.out.println(template.getSettings().toJson()); System.out.println(template.getMapping().toJson()); } //删除模板 if (indexOperations.existsTemplate("my-template")) { boolean flag = indexOperations.deleteTemplate("my-template"); System.out.println(flag); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
5.5、增删改查
5.5.1、新增单个文档
@Test
public void add() {
Student student = new Student();
student.setAge(23);
student.setData("123");
student.setDesc("华为手机");
student.setId("1");
student.setName("张三");
Student save = elasticsearchRestTemplate.save(student);
System.out.println(save);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
5.5.2、批量新增文档
@Test
public void addAll(){
List<Student> list = new ArrayList<>();
list.add(new Student("2","李四","苹果手机","1",22));
list.add(new Student("3","王五","oppo手机","2",24));
list.add(new Student("4","赵六","voio手机","3",25));
list.add(new Student("5","田七","小米手机","4",26));
Iterable<Student> result = elasticsearchRestTemplate.save(list);
System.out.println(result);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
5.5.3、修改(全量替换)
@Test
public void update(){
Student student = new Student();
student.setId("1");
student.setAge(23);
student.setData("99");
student.setDesc("华为手机AND苹果手机");
student.setName("张三");
Student save = elasticsearchRestTemplate.save(student);
System.out.println(save);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
5.5.4、修改(部分修改)
@Test public void update2(){ //脚本更新 String script = "ctx._source.age = 27;ctx._source.desc = 'oppo手机and苹果电脑'"; UpdateResponse update = elasticsearchRestTemplate.update( UpdateQuery.builder("3").withScript(script).build(), IndexCoordinates.of("student") ); System.out.println(update.getResult()); //部分文档更新 UpdateResponse update1 = elasticsearchRestTemplate.update( UpdateQuery.builder("3").withDocument(Document.create().append("age", 99)).build(), IndexCoordinates.of("student") ); System.out.println(update1.getResult()); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
5.5.5、根据主键查询
/**
* 根据主键查查询
*/
@Test
public void searchById(){
Student student = elasticsearchRestTemplate.get("3", Student.class);
System.out.println(student);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
5.5.6、根据主键删除
@Test
public void deleteById() {
String id = elasticsearchRestTemplate.delete("5", Student.class);
System.out.println(id);
}
- 1
- 2
- 3
- 4
- 5
6、Query接口
在SearchOperations中定义的几乎所有方法都使用Query参数,该参数定义了要执行的查询以进行搜索。Query是一个接口,Spring Data Elasticsearch提供了三个实现:
CriteriaQueryStringQueryNativeSearchQuery
6.1、CriteriaQuery
基于CriteriaQuery的查询允许创建查询来搜索数据,而无需了解Elasticsearch查询的语法或基础知识。它们允许用户通过简单地链接和组合指定搜索文档必须满足的条件的条件对象来构建查询。
@Test
public void criteriaQuery() {
Criteria criteria = new Criteria("author").matches("吴承恩");
Query query = new CriteriaQuery(criteria);
SearchHits<Book> hits = elasticsearchRestTemplate.search(query, Book.class, IndexCoordinates.of("book"));
List<SearchHit<Book>> list = hits.getSearchHits();
for (SearchHit<Book> hit : list) {
System.out.println(hit.getContent());
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
Criteria代表一个查询条件,可以绑定一个字段,也可以是一个空条件。CriteriaEntry代表一个条件项,如果不止一个条件项,则条件项中的项组合在bool-must查询中,包含如下类型:EQUALSCONTAINSSTARTS_WITHENDS_WITHEXPRESSIONBETWEENFUZZYMATCHESMATCHES_ALLINNOT_INWITHINBBOXLESSLESS_EQUALGREATERGREATER_EQUALEXISTSGEO_INTERSECTSGEO_IS_DISJOINTGEO_WITHINGEO_CONTAINS
CriteriaChain代表一系列条件链,可以通过or()和and()将Criteria组合到条件链中。条件链是LinkedList,所以是有序的,且条件链中的所有条件都处在同一级别,嵌套查询需要使用subCrteria。
6.1.1、简单查询
@Test public void simple_criteria() { //EQUALS 等值查询 Criteria criteria = new Criteria("price").is(33.33); //EXISTS 存在查询 criteria = new Criteria("name").exists(); //BETWEEN 范围查询 criteria = new Criteria("price").between(20.0, 40.0); //CONTAINS 包含查询 支持keyword和text类型 criteria = new Criteria("describe").contains("师傅"); //ENDS_WITH 以..结尾 支持keyword和text类型 criteria = new Criteria("name").endsWith("记"); //STARTS_WITH 以..开始 支持keyword和text类型 criteria = new Criteria("name").startsWith("西"); //EXPRESSION 支持es的原生expression查询 criteria = new Criteria("name").expression("*游记"); //FUZZY 模糊查询 criteria = new Criteria("name").fuzzy("东游记"); //MATCH 匹配查询 默认使用OR运算符 criteria = new Criteria("describe").matches("丢了"); //MATCH_ALL 匹配查询 默认使用AND运算符 criteria = new Criteria("describe").matchesAll("丢了"); //IN 多值查询 仅支持keyword类型 criteria = new Criteria("name").in("三国演义", "西游记"); //NOT_IN 仅支持keyword类型 criteria = new Criteria("name").notIn("三国演义"); //LESS < criteria = new Criteria("price").lessThan(40.0); //LESS_EQUAL <= criteria = new Criteria("price").lessThanEqual(35.22); //GREATER > criteria = new Criteria("price").greaterThan(50.0); //GREATER_EQUAL >= criteria = new Criteria("price").greaterThanEqual(55.55); Query query = new CriteriaQuery(criteria); SearchHits<Book> hits = elasticsearchRestTemplate.search(query, Book.class, IndexCoordinates.of("book")); List<SearchHit<Book>> list = hits.getSearchHits(); for (SearchHit<Book> hit : list) { System.out.println(hit.getContent()); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
6.1.2、组合查询
就是构建条件链
And逻辑:
@Test public void and_criteria() { //条件:(20.0 < price < 80.0) && (name=三国演义) //组合条件时,默认情况下使用AND逻辑: Criteria criteria = new Criteria("price").greaterThan(20.0).lessThan(80.0); //等价于 criteria = new Criteria("price").greaterThan(20.0) .and("price").lessThan(80.0); //条件:(20.0 < price < 80.0) && (name=三国演义) && (author=罗贯中) criteria = new Criteria("price").between(20.0, 80.0) .and("name").is("三国演义") .and("author").is("罗贯中"); Query query = new CriteriaQuery(criteria); SearchHits<Book> hits = elasticsearchRestTemplate.search(query, Book.class, IndexCoordinates.of("book")); List<SearchHit<Book>> list = hits.getSearchHits(); for (SearchHit<Book> hit : list) { System.out.println(hit.getContent()); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
or逻辑:
@Test public void or_criteria() { //条件:(name=三国演义) OR (author=曹雪芹) Criteria criteria = new Criteria("name").is("三国演义") .or("author").matches("曹雪芹"); //条件:(name=三国演义) OR (name=西游记) criteria = new Criteria("name").matches("三国演义") .or("name").matches("西游记"); Query query = new CriteriaQuery(criteria); SearchHits<Book> hits = elasticsearchRestTemplate.search(query, Book.class, IndexCoordinates.of("book")); List<SearchHit<Book>> list = hits.getSearchHits(); for (SearchHit<Book> hit : list) { System.out.println(hit.getContent()); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
and和or逻辑组合:
@Test
public void and_or_criteria() {
//条件:(name=三国演义) && (author=罗贯中) || (name=西游记)
Criteria criteria = new Criteria("name").is("三国演义")
.and("author").matches("罗贯中")
.or("name").is("西游记");
Query query = new CriteriaQuery(criteria);
SearchHits<Book> hits = elasticsearchRestTemplate.search(query, Book.class, IndexCoordinates.of("book"));
List<SearchHit<Book>> list = hits.getSearchHits();
for (SearchHit<Book> hit : list) {
System.out.println(hit.getContent());
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
6.1.3、嵌套查询
如果要创建嵌套查询,则需要为此使用子查询。subCriteria()使用AND逻辑连接条件。
可以简单的理解为:每一个subCriteria()就开启了一个(),这个()和父条件之间使用AND连接。
@Test public void sub_criteria() { //示例一 //条件: (20.0 < price < 80.0) && (name=三国演义 || author=吴承恩) Criteria criteria = new Criteria("price").between(20.0, 80.0) .subCriteria(//添加子查询条件,默认and连接 new Criteria()//空条件 .or("name").is("三国演义")//以为第一个是空条件,所以此处or或and都可以 .or("author").is("吴承恩")//此处必须为or ); //上面构建的条件最原始的形态是:(20.0 < price < 80.0) && (空条件 || name=三国演义 || author=吴承恩) //示例二 //条件:(name=三国演义 && author=罗贯中) || (name=西游记 && author=吴承恩) criteria = new Criteria("name").is("三国演义") .subCriteria( new Criteria("author").is("罗贯中") ) .or( new Criteria("name").is("西游记") .subCriteria( new Criteria("author").is("吴承恩") ) ); //上面构建的条件最原始的形态是:(name=三国演义 && (author=罗贯中)) || (name=西游记 && (author=吴承恩)) //因为subCriteria使用and连接,所以只能这样写,非常反人类 Query query = new CriteriaQuery(criteria); SearchHits<Book> hits = elasticsearchRestTemplate.search(query, Book.class, IndexCoordinates.of("book")); List<SearchHit<Book>> list = hits.getSearchHits(); for (SearchHit<Book> hit : list) { System.out.println(hit.getContent()); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
6.1.4、GEO查询
略…
不推荐使用CriteriaQuery进行GEO查询。
6.2、StringQuery
将JSON字符串作为一个Elasticsearch查询。
6.2.1、简单查询
@Test public void string_query1() { /** * { * "query": { * "match": { * "author": "吴承恩" * } * } * } */ Query query = new StringQuery("{\n" + " \"match\": {\n" + " \"author\": \"吴承恩\"\n" + " }\n" + "}"); SearchHits<Book> hits = elasticsearchRestTemplate.search(query, Book.class, IndexCoordinates.of("book")); List<SearchHit<Book>> list = hits.getSearchHits(); for (SearchHit<Book> hit : list) { System.out.println(hit.getContent()); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
Book{id=2, name='西游记', describe='大师兄!师傅又丢了!', author='吴承恩', price=33.33, createTime=Fri Oct 27 08:00:00 CST 2023}
- 1
6.2.2、复杂查询
@Test public void string_query2() { /** * { * "query": { * "bool": { * "must": [ * { * "range": { * "price": { * "gte": 20.0, * "lte": 80.0 * } * } * } * ], * "should": [ * { * "terms": { * "name": [ * "三国演义", * "西游记" * ] * } * } * ], * "must_not": [ * { * "match": { * "author": "曹雪芹" * } * } * ] * } * } * } */ Query query = new StringQuery("{\n" + " \"bool\": {\n" + " \"must\": [\n" + " {\n" + " \"range\": {\n" + " \"price\": {\n" + " \"gte\": 20.0,\n" + " \"lte\": 80.0\n" + " }\n" + " }\n" + " }\n" + " ],\n" + " \"should\": [\n" + " {\n" + " \"terms\": {\n" + " \"name\": [\n" + " \"三国演义\",\n" + " \"西游记\"\n" + " ]\n" + " }\n" + " }\n" + " ],\n" + " \"must_not\": [\n" + " {\n" + " \"match\": {\n" + " \"author\": \"曹雪芹\"\n" + " }\n" + " }\n" + " ]\n" + " }\n" + "}"); SearchHits<Book> hits = elasticsearchRestTemplate.search(query, Book.class, IndexCoordinates.of("book")); List<SearchHit<Book>> list = hits.getSearchHits(); for (SearchHit<Book> hit : list) { System.out.println(hit.getContent()); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
Book{id=1, name='三国演义', describe='天下大势,分久必合,合久必分。', author='罗贯中', price=55.55, createTime=Fri Oct 27 08:00:00 CST 2023}
Book{id=2, name='西游记', describe='大师兄!师傅又丢了!', author='吴承恩', price=33.33, createTime=Fri Oct 27 08:00:00 CST 2023}
Book{id=4, name='水浒传', describe='招安', author='施耐庵', price=35.22, createTime=Fri Oct 27 08:00:00 CST 2023}
- 1
- 2
- 3
6.2.3、分页查询
@Test public void string_query3() { /** * { * "query": { * "range": { * "price": { * "gte": 20.0, * "lte": 80.0 * } * } * }, * "from": 0, * "size": 2 * } */ Query query = new StringQuery("{\n" + " \"range\": {\n" + " \"price\": {\n" + " \"gte\": 20.0,\n" + " \"lte\": 80.0\n" + " }\n" + " }\n" + "}", PageRequest.of(0, 2)); SearchHits<Book> hits = elasticsearchRestTemplate.search(query, Book.class, IndexCoordinates.of("book")); List<SearchHit<Book>> list = hits.getSearchHits(); for (SearchHit<Book> hit : list) { System.out.println(hit.getContent()); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
Book{id=1, name='三国演义', describe='天下大势,分久必合,合久必分。', author='罗贯中', price=55.55, createTime=Fri Oct 27 08:00:00 CST 2023}
Book{id=2, name='西游记', describe='大师兄!师傅又丢了!', author='吴承恩', price=33.33, createTime=Fri Oct 27 08:00:00 CST 2023}
- 1
- 2
6.2.4、排序查询
@Test public void string_query4() { /** * { * "query": { * "range": { * "price": { * "gte": 20.0, * "lte": 80.0 * } * } * }, * "sort": [ * { * "price": { * "order": "desc" * } * } * ], * "from": 0, * "size": 2 * } */ Query query = new StringQuery("{\n" + " \"range\": {\n" + " \"price\": {\n" + " \"gte\": 20.0,\n" + " \"lte\": 80.0\n" + " }\n" + " }\n" + "}", PageRequest.of(0, 2), Sort.by(Sort.Direction.DESC, "price")); SearchHits<Book> hits = elasticsearchRestTemplate.search(query, Book.class, IndexCoordinates.of("book")); List<SearchHit<Book>> list = hits.getSearchHits(); for (SearchHit<Book> hit : list) { System.out.println(hit.getContent()); List<Object> sortValues = hit.getSortValues(); sortValues.forEach(System.out::println); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
Book{id=3, name='红楼梦', describe='一朝春尽红颜老,花落人亡两不知。', author='曹雪芹', price=66.66, createTime=Fri Oct 27 08:00:00 CST 2023}
66.66
Book{id=1, name='三国演义', describe='天下大势,分久必合,合久必分。', author='罗贯中', price=55.55, createTime=Fri Oct 27 08:00:00 CST 2023}
55.55
- 1
- 2
- 3
- 4
6.2.5、高亮查询
@Test public void string_query4() { /** * { * "query": { * "match": { * "describe": "师傅" * } * }, * "highlight": { * "pre_tags": ["<strong>"], * "post_tags": ["</strong>"], * "fields": { * "describe": {} * } * } * } */ Query query = new StringQuery("{\n" + " \"match\": {\n" + " \"describe\": \"师傅\"\n" + " }\n" + "}"); HighlightQuery highlightQuery = new HighlightQuery( new HighlightBuilder() .field("describe") .preTags("<strong>") .postTags("</strong>") ); query.setHighlightQuery(highlightQuery); SearchHits<Book> hits = elasticsearchRestTemplate.search(query, Book.class, IndexCoordinates.of("book")); List<SearchHit<Book>> list = hits.getSearchHits(); for (SearchHit<Book> hit : list) { System.out.println(hit.getContent()); List<String> highlightField = hit.getHighlightField("describe"); highlightField.forEach(System.out::println); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
Book{id=2, name='西游记', describe='大师兄!师傅又丢了!', author='吴承恩', price=33.33, createTime=Fri Oct 27 08:00:00 CST 2023}
<strong>师傅</strong>又丢了!
- 1
- 2
6.3、NativeSearchQuery
NativeSearchQuery是在具有复杂查询或无法使用Criteria API表示的查询时使用的类,例如在构建查询和使用聚合时。它允许使用Elasticsearch库中所有不同的QueryBuilder实现,因此被命名为“原生”。
6.3.1、简单查询
@Test public void native_query1() { /** * { * "query": { * "match": { * "author": "曹雪芹" * } * } * } */ NativeSearchQuery query = new NativeSearchQuery( QueryBuilders.matchQuery("author", "曹雪芹") ); SearchHits<Book> hits = elasticsearchRestTemplate.search(query, Book.class, IndexCoordinates.of("book")); List<SearchHit<Book>> list = hits.getSearchHits(); for (SearchHit<Book> hit : list) { System.out.println(hit.getContent()); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
Book{id=3, name='红楼梦', describe='一朝春尽红颜老,花落人亡两不知。', author='曹雪芹', price=66.66, createTime=Fri Oct 27 08:00:00 CST 2023}
- 1
6.3.2、复杂查询
@Test public void native_query2() { /** * { * "query": { * "bool": { * "must": [ * { * "range": { * "price": { * "gte": 20.0, * "lte": 80.0 * } * } * } * ], * "should": [ * { * "terms": { * "name": [ * "三国演义", * "西游记" * ] * } * } * ], * "must_not": [ * { * "match": { * "author": "曹雪芹" * } * } * ] * } * } * } */ NativeSearchQuery query = new NativeSearchQuery( QueryBuilders.boolQuery() .must( QueryBuilders.rangeQuery("price").gte(20.0).lte(80.0) ) .should( QueryBuilders.termsQuery("name", "三国演义", "西游记") ) .mustNot( QueryBuilders.matchQuery("author", "曹雪芹") ) ); SearchHits<Book> hits = elasticsearchRestTemplate.search(query, Book.class, IndexCoordinates.of("book")); List<SearchHit<Book>> list = hits.getSearchHits(); for (SearchHit<Book> hit : list) { System.out.println(hit.getContent()); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
Book{id=1, name='三国演义', describe='天下大势,分久必合,合久必分。', author='罗贯中', price=55.55, createTime=Fri Oct 27 08:00:00 CST 2023}
Book{id=2, name='西游记', describe='大师兄!师傅又丢了!', author='吴承恩', price=33.33, createTime=Fri Oct 27 08:00:00 CST 2023}
Book{id=4, name='水浒传', describe='招安', author='施耐庵', price=35.22, createTime=Fri Oct 27 08:00:00 CST 2023}
- 1
- 2
- 3
6.3.3、分页查询
@Test public void native_query3() { /** * { * "query": { * "range": { * "price": { * "gte": 20.0, * "lte": 80.0 * } * } * }, * "from": 0, * "size": 2 * } */ NativeSearchQuery query = new NativeSearchQuery( QueryBuilders.rangeQuery("price").gte(20.0).lte(80.0) ); query.setPageable(PageRequest.of(0, 2)); SearchHits<Book> hits = elasticsearchRestTemplate.search(query, Book.class, IndexCoordinates.of("book")); List<SearchHit<Book>> list = hits.getSearchHits(); for (SearchHit<Book> hit : list) { System.out.println(hit.getContent()); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
Book{id=1, name='三国演义', describe='天下大势,分久必合,合久必分。', author='罗贯中', price=55.55, createTime=Fri Oct 27 08:00:00 CST 2023}
Book{id=2, name='西游记', describe='大师兄!师傅又丢了!', author='吴承恩', price=33.33, createTime=Fri Oct 27 08:00:00 CST 2023}
- 1
- 2
6.3.4、排序查询
@Test public void native_query4() { /** * { * "query": { * "range": { * "price": { * "gte": 20.0, * "lte": 80.0 * } * } * }, * "sort": [ * { * "price": { * "order": "desc" * } * } * ], * "from": 0, * "size": 2 * } */ NativeSearchQuery query = new NativeSearchQuery( QueryBuilders.rangeQuery("price").gte(20.0).lte(80.0) ) .addSort(Sort.by(Sort.Direction.DESC, "price")) .setPageable(PageRequest.of(0, 2)); SearchHits<Book> hits = elasticsearchRestTemplate.search(query, Book.class, IndexCoordinates.of("book")); List<SearchHit<Book>> list = hits.getSearchHits(); for (SearchHit<Book> hit : list) { System.out.println(hit.getContent()); List<Object> sortValues = hit.getSortValues(); sortValues.forEach(System.out::println); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
Book{id=3, name='红楼梦', describe='一朝春尽红颜老,花落人亡两不知。', author='曹雪芹', price=66.66, createTime=Fri Oct 27 08:00:00 CST 2023}
66.66
Book{id=1, name='三国演义', describe='天下大势,分久必合,合久必分。', author='罗贯中', price=55.55, createTime=Fri Oct 27 08:00:00 CST 2023}
55.55
- 1
- 2
- 3
- 4
6.3.5、高亮查询
@Test public void native_query5() { /** * { * "query": { * "match": { * "describe": "师傅" * } * }, * "highlight": { * "pre_tags": ["<strong>"], * "post_tags": ["</strong>"], * "fields": { * "describe": {} * } * } * } */ NativeSearchQuery query = new NativeSearchQuery( QueryBuilders.matchQuery("describe", "师傅") ); query.setHighlightQuery( new HighlightQuery( new HighlightBuilder() .field("describe") .preTags("<strong>") .postTags("</strong>") ) ); SearchHits<Book> hits = elasticsearchRestTemplate.search(query, Book.class, IndexCoordinates.of("book")); List<SearchHit<Book>> list = hits.getSearchHits(); for (SearchHit<Book> hit : list) { System.out.println(hit.getContent()); List<String> highlightField = hit.getHighlightField("describe"); highlightField.forEach(System.out::println); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
Book{id=2, name='西游记', describe='大师兄!师傅又丢了!', author='吴承恩', price=33.33, createTime=Fri Oct 27 08:00:00 CST 2023}
<strong>师傅</strong>又丢了!
- 1
- 2
6.3.5、聚合查询
@Test public void native_query6() { /** * { * "size": 0, * "aggs": { * "name_count": { * "terms": { * "field": "name" * } * } * } * } */ NativeSearchQuery query = new NativeSearchQuery( QueryBuilders.matchAllQuery() ); query.addAggregation( AggregationBuilders.terms("name_agg").field("name") ); SearchHits<Book> hits = elasticsearchRestTemplate.search(query, Book.class, IndexCoordinates.of("book")); Aggregations aggregations = hits.getAggregations(); ParsedStringTerms terms = aggregations.get("name_agg"); List<? extends Terms.Bucket> buckets = terms.getBuckets(); buckets.forEach(e -> System.out.println(e.getKeyAsString() + ":" + e.getDocCount())); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
三国演义:1
水浒传:1
红楼梦:1
西游记:1
- 1
- 2
- 3
- 4

